基本¶
ようこそ!
本書は、主要な Dataiku DSS コンセプトのハンズオンの概要を提供することを目的とする Dataiku Data Science Studio(DSS)チュートリアルシリーズの最初のドキュメントです。
弊社はすべてのチュートリアルを通して、ある架空のオンライン T シャツ小売店 Haiku T-Shirt の案件について紹介します。そして、この T シャツ店のエンタープライズデータを使用して、Dataiku との協業の基本的なステップについて説明します。
このチュートリアルでは、Haiku T-Shirt の注文ログを Dataiku DSS にロードし、データの大まかなレビューを実施し、 レビューの中で特定されたスクリーニングルールを適用して、更新されたデータセットを作成します。
前提条件¶
このチュートリアルでは、ご自身のコンピュータから 1 つのファイルを Dataiku DSS にアップロードします。最初に、`注文 CSV ファイルをダウンロードする <https://downloads.dataiku.com/public/website-additional-assets/data/orders.csv>`_ことから開始します。
プロジェクトの作成¶
ステップ 1 は、新しい Dataiku DSS Project を作成することです。 ご自分のローカルのファイルシステムに、基本チュートリアルプロジェクトの Zip エクスポートをダウンロード してください。 次に、Dataiku のホームページから、+New Project をクリックし、リストから Import Project を選択して、先ほどダウンロードした Zip ファイルを選択してください。
これにより、新しいプロジェクトが作成され、プロジェクトのホームページに進みます。
Note
Key concept: project
1 つの Dataiku DSS プロジェクトは、特定のアクティビティに関するすべての作業のコンテナになります。 プロジェクトホームはコマンドセンターとして機能します。ユーザーはここで、プロジェクト全体のステータスを確認したり、最近のアクティビティを表示したり、また、コメント、タグ、そしてプロジェクトの To-Do リストを通して、コラボレーションすることが可能です。
各プロジェクトには名前と一意のプロジェクト ID が付いています。プロジェクト名は変更可能ですが、プロジェクト ID は変更できません。
データセットの作成¶
では、私たちの最初の Dataset をロードしましょう!プロジェクトホームで、+Import your first dataset をクリックします。
Dataiku DSSでは、幅広いデータソースに接続できます。このチュートリアルでは、先ほど Dataiku の Web サイトからダウンロードした orders ファイルをアップロードします。Upload your files をクリックします。
アップロードダイアログが表示されます。Add a file をクリックして、ダウンロードした orders.csv ファイルを選択して、検証します。 ファイルがアップロードされます。
次に、Dataiku DSS が CSV 形式を正常に検出したかどうか、Preview ボタンをクリックして確認しましょう。
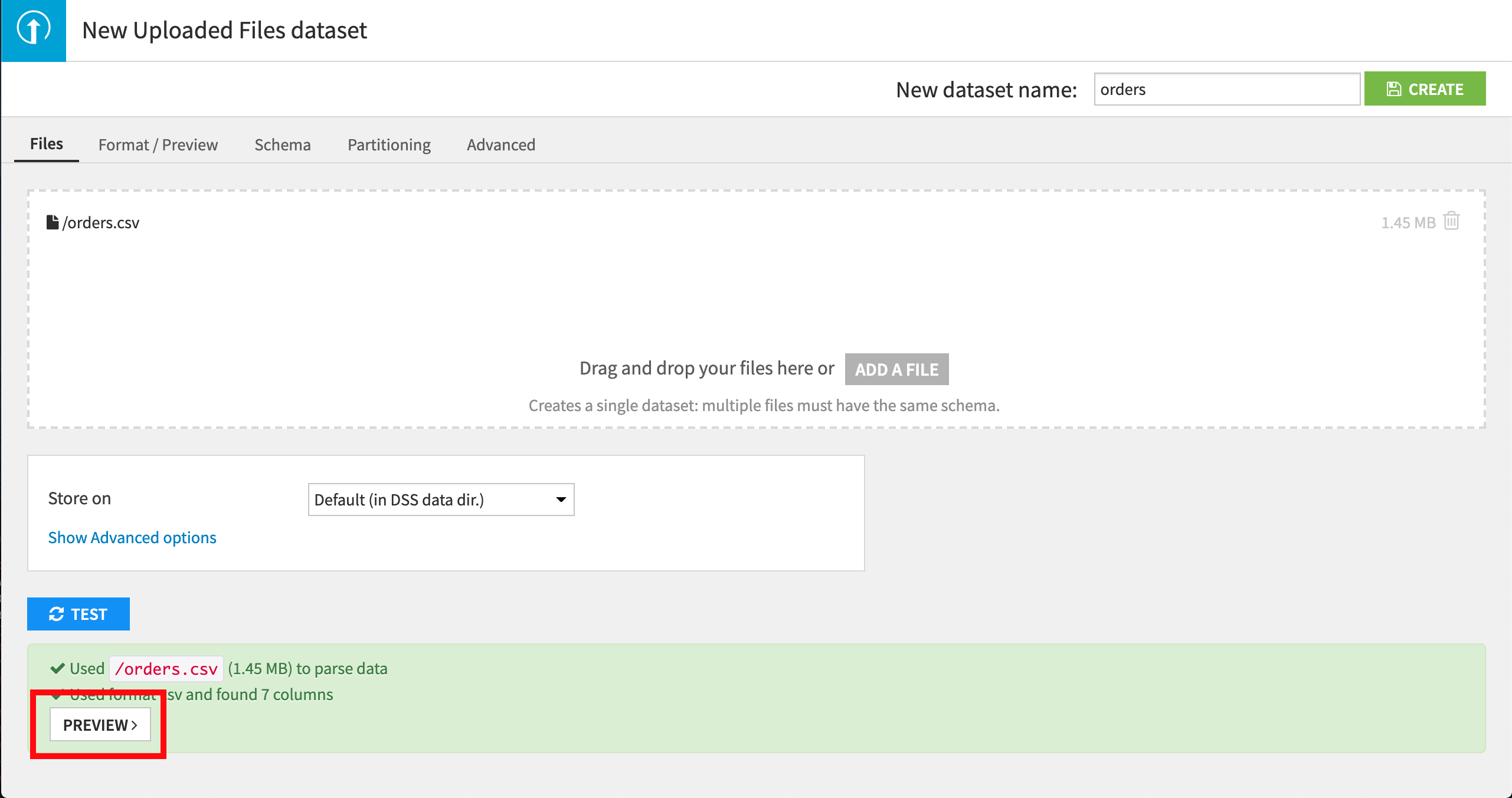
Dataiku DSS は、ファイルにコンマ区切り記号で区切られた値が含まれていることを自動的に検出します。ユーザーは、データが列(機能)と行(レコードまたは観測)から成る表形式であることを見ることができます。
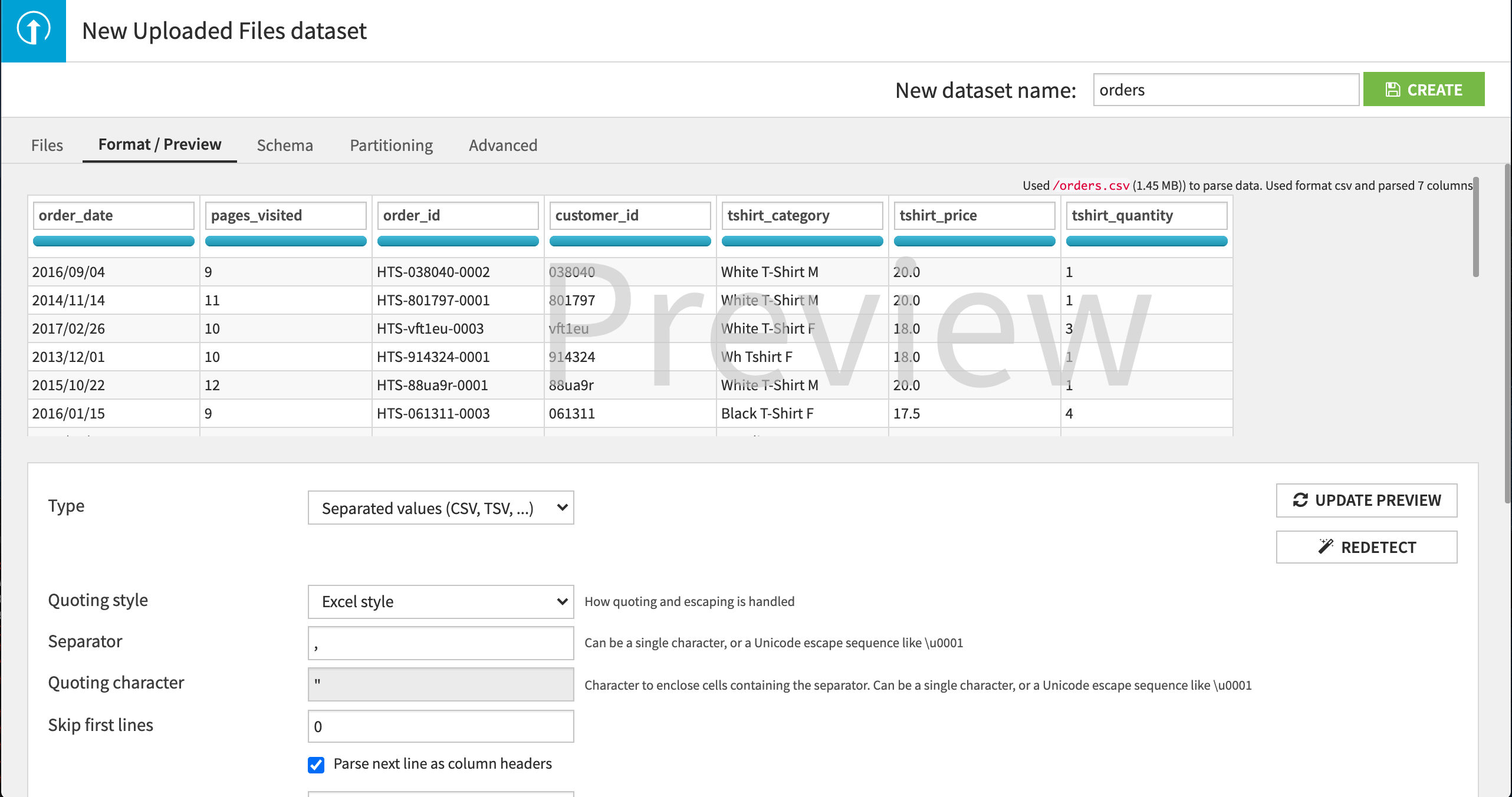
画面最上部のフィールドに、デフォルトのデータセット名 orders が提供されています。これで問題ないので、Create ボタンを押すか、ショートカット Ctrl-S を使って作業を保存します。 新しいデータセットが作成され、ユーザーはその orders データセットの Explore ページに進みます。
Note
- Key concept: dataset
Dataiku DSS では、Dataset とは、ユーザーの持っている、任意の表形式のデータ断片のことです。
orders.csvのような CSV ファイルはデータセットです。Excel ファイルの 1 シートもデータセットです。もっと一般的にいえば、企業(およびユーザー)は、自分のすべてのデータを保管するためのシステムを持っています。企業またはユーザーは、データを Excel ファイル、リレーショナル データベース、あるいは、データ量がもっと膨大な場合は、`分散型ストレージシステム <https://en.wikipedia.org/wiki/Clustered_file_system>`_に保管することができます。
大抵の場合、データセットを作成することは、Dataiku DSS に、どうすればデータにアクセスできるかを情報提供しているだけに過ぎません。これらの external または source データセットは、元データの場所を記憶しています。データは、DSS にはコピーされません。DSS の中のデータセットは、元システムのデータのビューです。
先に作成した uploaded files データセットは、少し特殊です。なぜなら、この特定のケースに関しては、データは DSS にコピーされるからです(これをホストする別のデータベースがまだないため)。
データセットに関する詳細については、`主要な Dataiku DSS コンセプト <https://www.dataiku.com/learn/guide/getting-started/universes-and-concepts.html>`_を参照してください。
データの調査¶
データセットの Explore ページは、データのビューを表形式で提供します。ユーザーはここからデータの調査を開始できます。
サンプリング¶
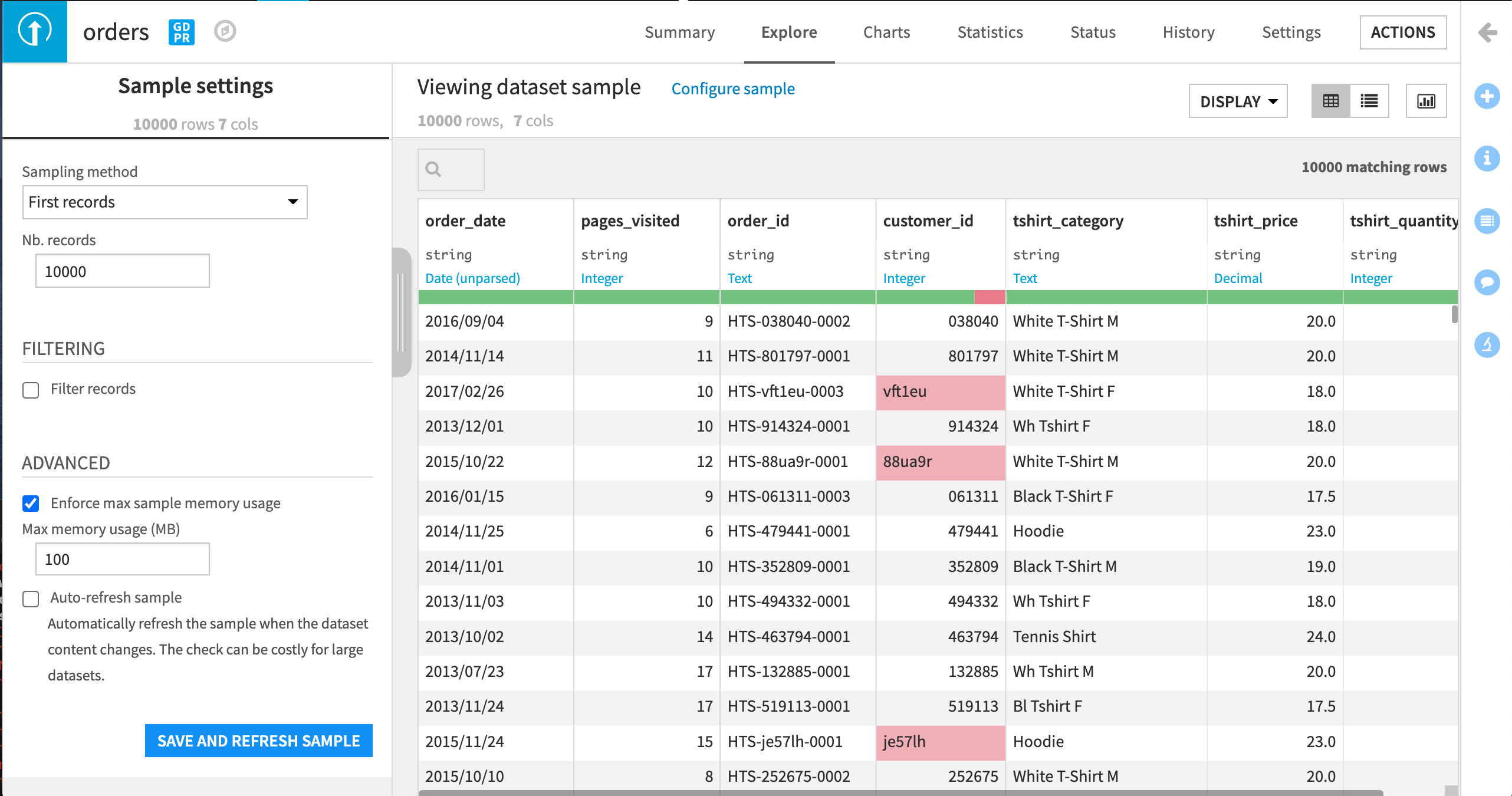
データを参照したり、これにインタラクティブに作業するとき、Dataiku DSS はデータのサンプルしか表示しません。このサンプルは、データそのものが膨大でも、データセットを表示できるようにします。ユーザーが、サンプルのサイズとサンプリング方法をコントロールします。(Dataiku DSS は先頭レコードだけを取得すべきでしょうか?これは速いですが、結果的に偏ったサンプルになる可能性があります。それとも、ランダムなサンプルを抽出すべきですか?)これらの設定を表示するには、Configure sample をクリックしてください。左側のパネルが開きます。
ストレージ型と意味¶
各列は名前で識別され、また、元データの保管方法を示す storage type があります(文字列、整数、小数値、日付…)。CSV ファイルでは、すべてのストレージ型が文字列です。(これはただのテキストだからです)。
Dataiku DSS は、青色で示されている meaning も検出します。これは、この列の値の性質を反映する “semantic” 型です。Dataiku DSS は、組み込みの意味を多数持っています(例:整数、米国の州、IPアドレス、Eメール等)。ここでは、Dataiku DSS は、tshirt_price 列の値は Decimal (10進数)の意味であり、tshirt_quantity の列の値は Integerの意味であることを推測しました。列の意味は、Dataiku DSS が任意の値をその列に有効とみなすかどうかに影響します。 意味の下には、ゲージがあります。これは、列値の割合が、意味にマッチしていないように見える(赤)か、完全に欠落している(グレー)ことを示します。
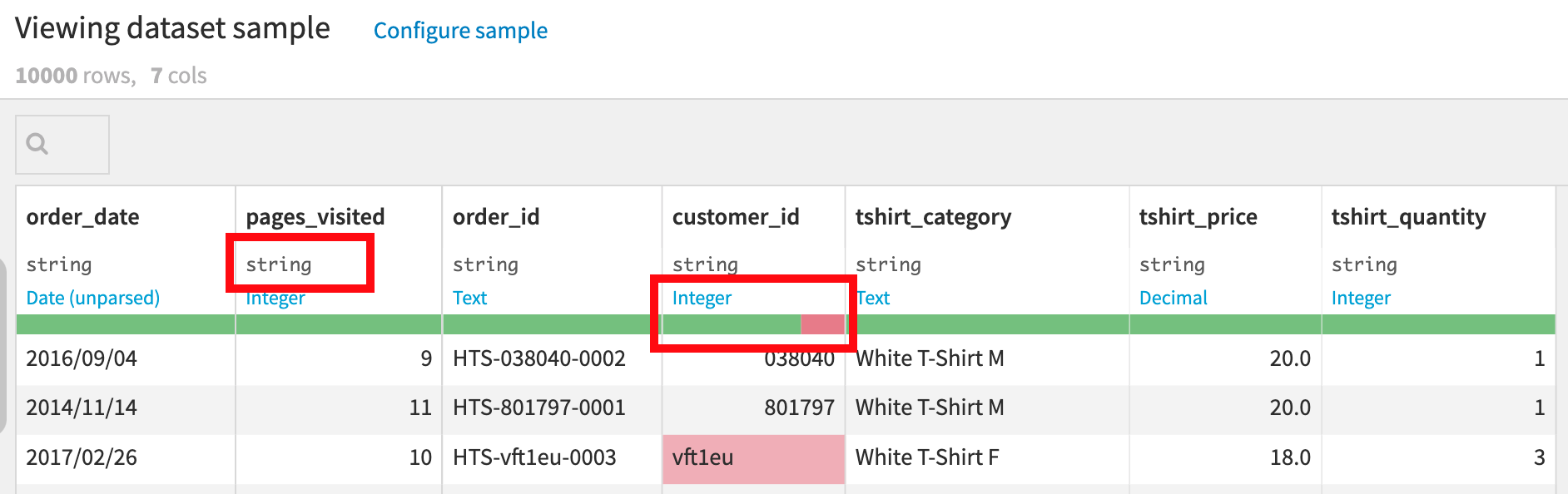
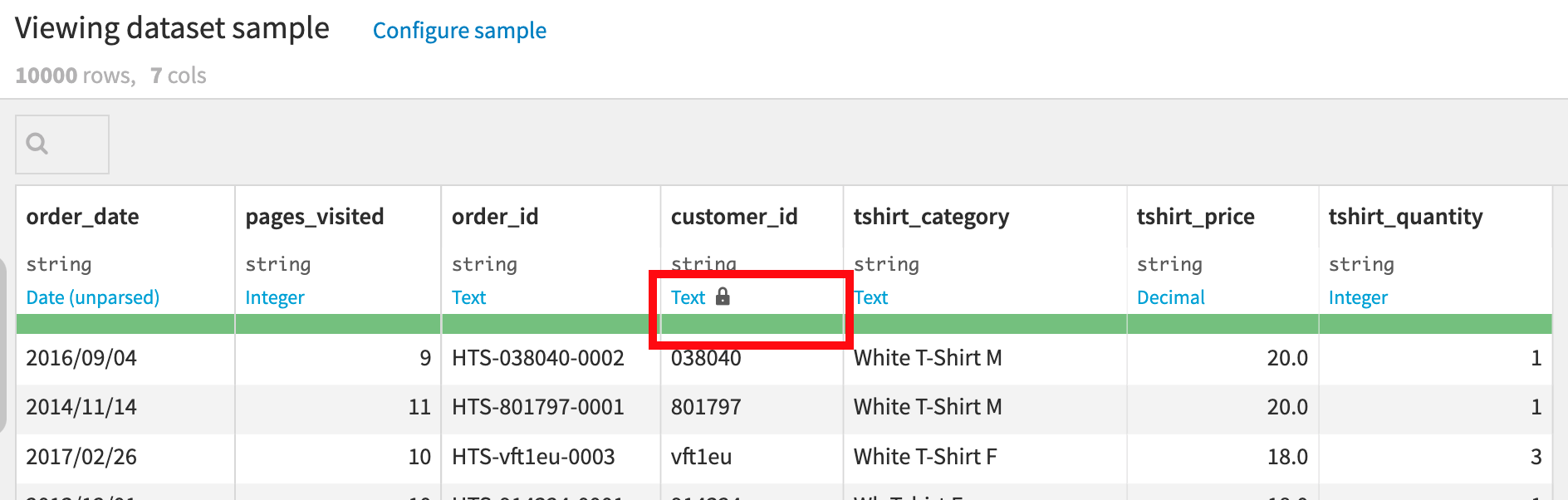
Dataiku DSS は、 customer_id のほとんどの値が整数であるという事実に基づいて、customer_id に関しては Integer の意味を検出します。 ゲージは、この値にマッチしない、少ない数の値に関しては赤色を示します。ユーザーはこれを見て、値が真に無効なカスタマー ID なのか(そして、この場合は本当にそうです)、Integer が customer_id の意味にしては制限的すぎるのかどうかを判別することができます。 意味をクリックして Text を選択し、これを更新してください。 するとこの customer_id のゲージが完全に緑色になりました。
グラフ¶
インプットデータセットを調査するために、グラフを使用できます。例えば、各タイプの T シャツがどのくらいの頻度で注文されているのかを知りたい場合などです。
Charts タブをクリックします。
Count of records を Y 変数としてドラッグアンドドロップします。
tshirt_category を X 変数としてドラッグアンドドロップします。
DSS は、tshirt_category ごとに、Count of records の縦棒グラフを示します。
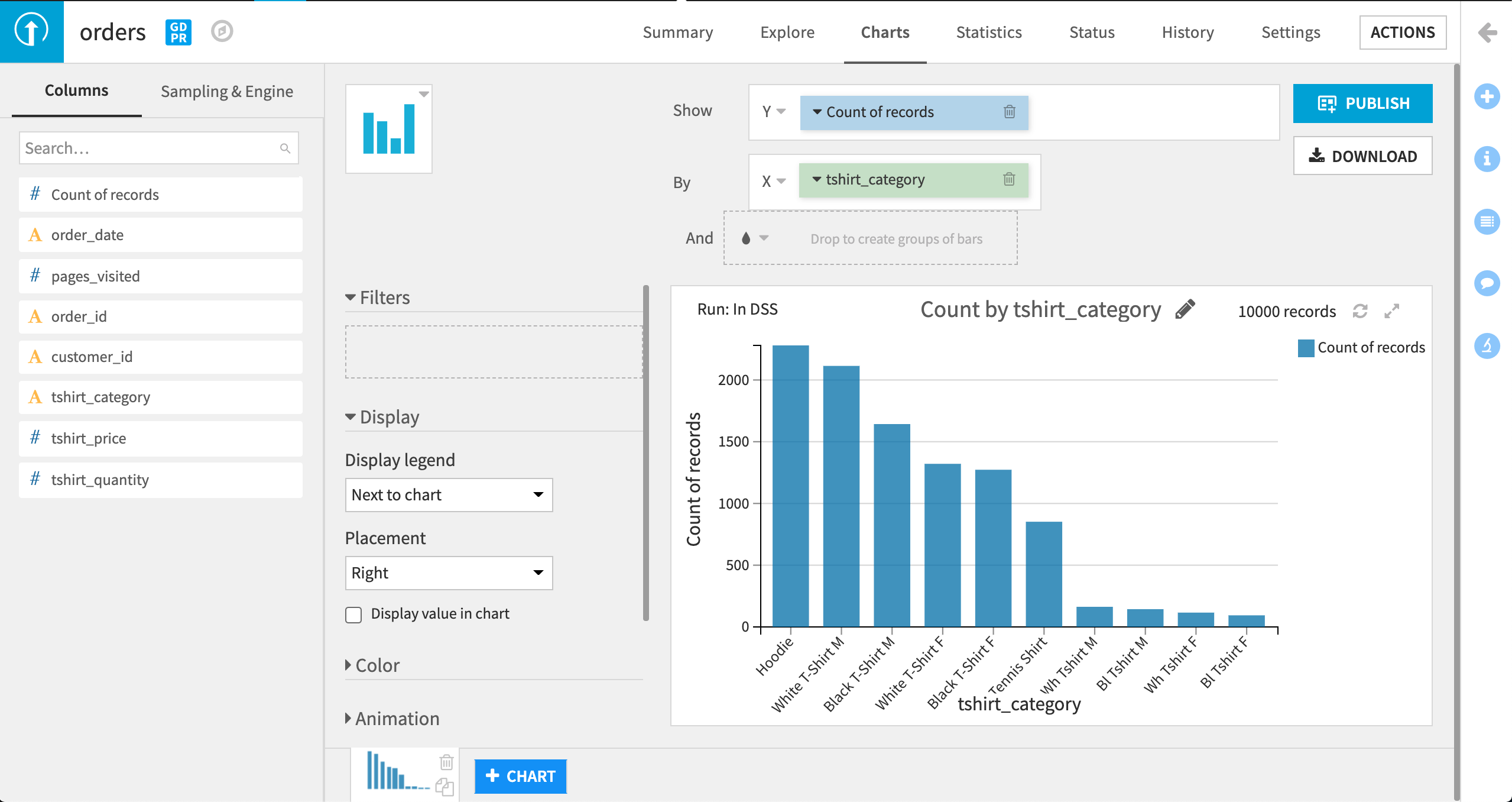
このグラフから、tshirt_category の値が一貫して記録されていないことが明らかになりました。 黒シャツの色が、時には “Black” として記録され、また、時には “Bl” として記録されていました。 同様に、白シャツが、時には “White” として記録され、また、時には “Wh” として記録されていました。
これらの問題には、recipe を使ってデータを preparing することで対処しましょう。
ビジュアルレシピを使ったデータ準備¶
最初のステップ¶
:ref:`下記の動画<prep-01>`は、次の項で説明するステップを網羅しています。
Note
- Key concept: recipe
Dataiku DSS レシピは、1 つ以上のインプットデータセットを実行する一連のアクションのセットであり、結果として、1 つ以上のアウトプットデータセットを生成します。レシピには、visual または code のどちらかです。
ビジュアルレシピでは、ビジュアルインターフェースで使用可能な、事前パッケージングされた複数のオペレーションを通して、インプットデータセットをインタラクティブに迅速に変換できます。 コードレシピでは、コーディング技能のあるユーザーが、ビジュアルレシピ機能を超えて、サポートされる任意の言語(`SQL、Python、R など<https://www.dataiku.com/learn/portals/code.html>`_)を使用して、変換をコントロールすることができます。
Dataiku では、”coders” と “clickers” が、コードレシピとビジュアルレシピを使って、同じプロジェクトでシームレスに共同することが可能です。
orders データセットの右上隅にある Actions ボタンをクリックして、Prepare を選択します。
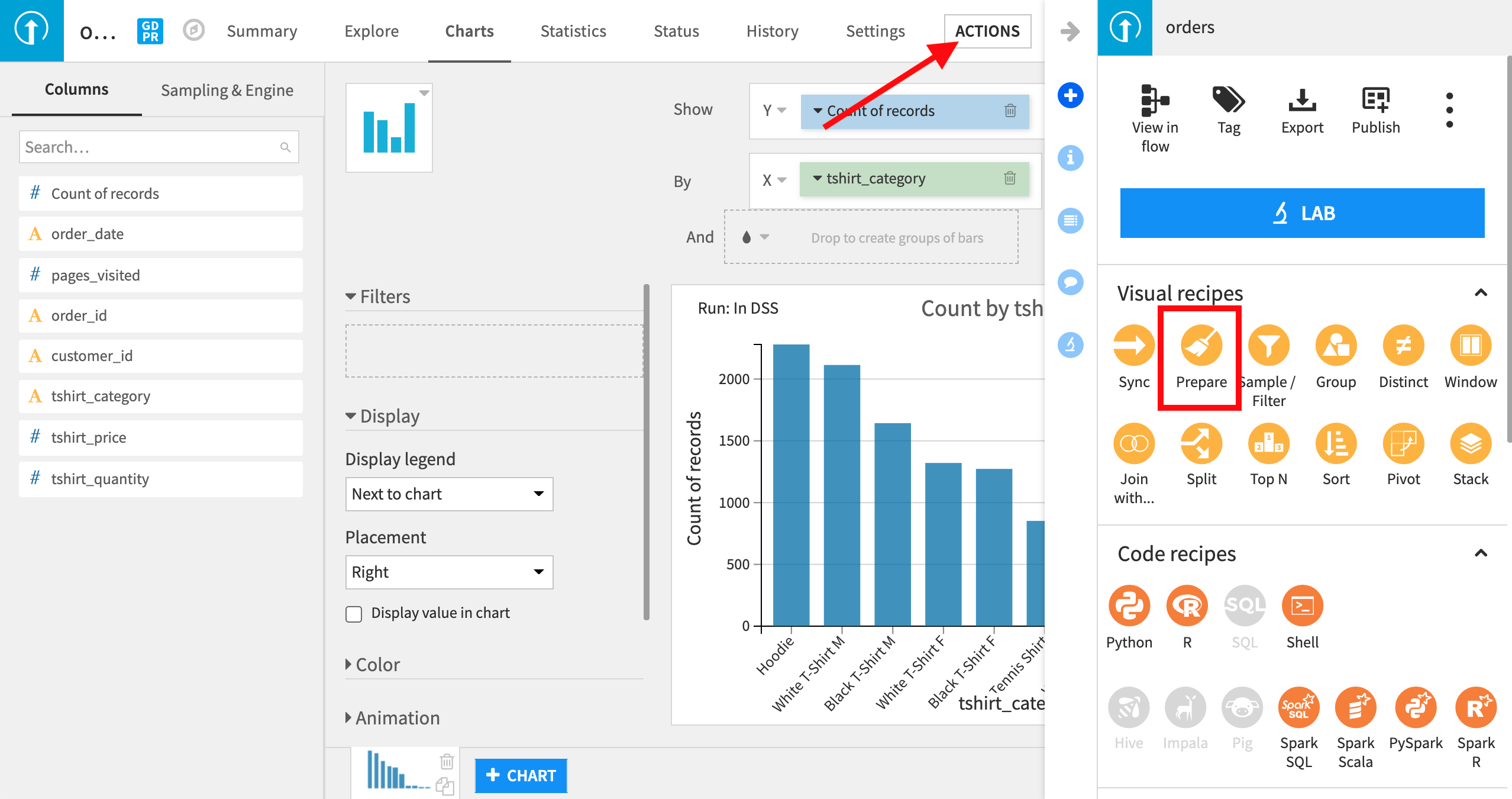
Prepare Recipe では、データセットに実行すべき一連のステップまたはアクションを定義できます。Prepare Recipe に追加できるステップのタイプは広範囲に及んでおり、パワフルです。Prepare Recipe の一環として、列をドラッグアンドドロップして並び変えることもできます。
レシピを作成するときには、インプットデータセット(最初の列と値の入ったもの)とアウトプットデータセット(準備済みの列と値の入ったもの)を提供する必要があります。 また、アウトプットデータをどこに保管するかを決定するために、”Store into” の値も設定できます。この例では、アウトプットはローカルのファイルシステム上に書き込まれていますが、インフラストラクチャが存在するのであれば、リレーショナルデータベースや分散型ファイルシステムに書き込むことも可能です。 Dataiku DSS は、orders_prepared のデフォルトのアウトプットデータセット名を提供します。 Create recipe をクリックします。
tshirt_category のコーディングを標準化するために、Dataiku は値を再コーディングします。列名をクリックすると、ドロップダウンが開くので、Analyze を選択します。分析ボックスが開きます。これを使って列内のデータの簡単なサマリを表示できます(例えば、DSS によって表示されているデータのサンプルに関してなど)。また、分析ボックスは、さまざまなデータクレンジングのアクションを実行する機能も提供しています。
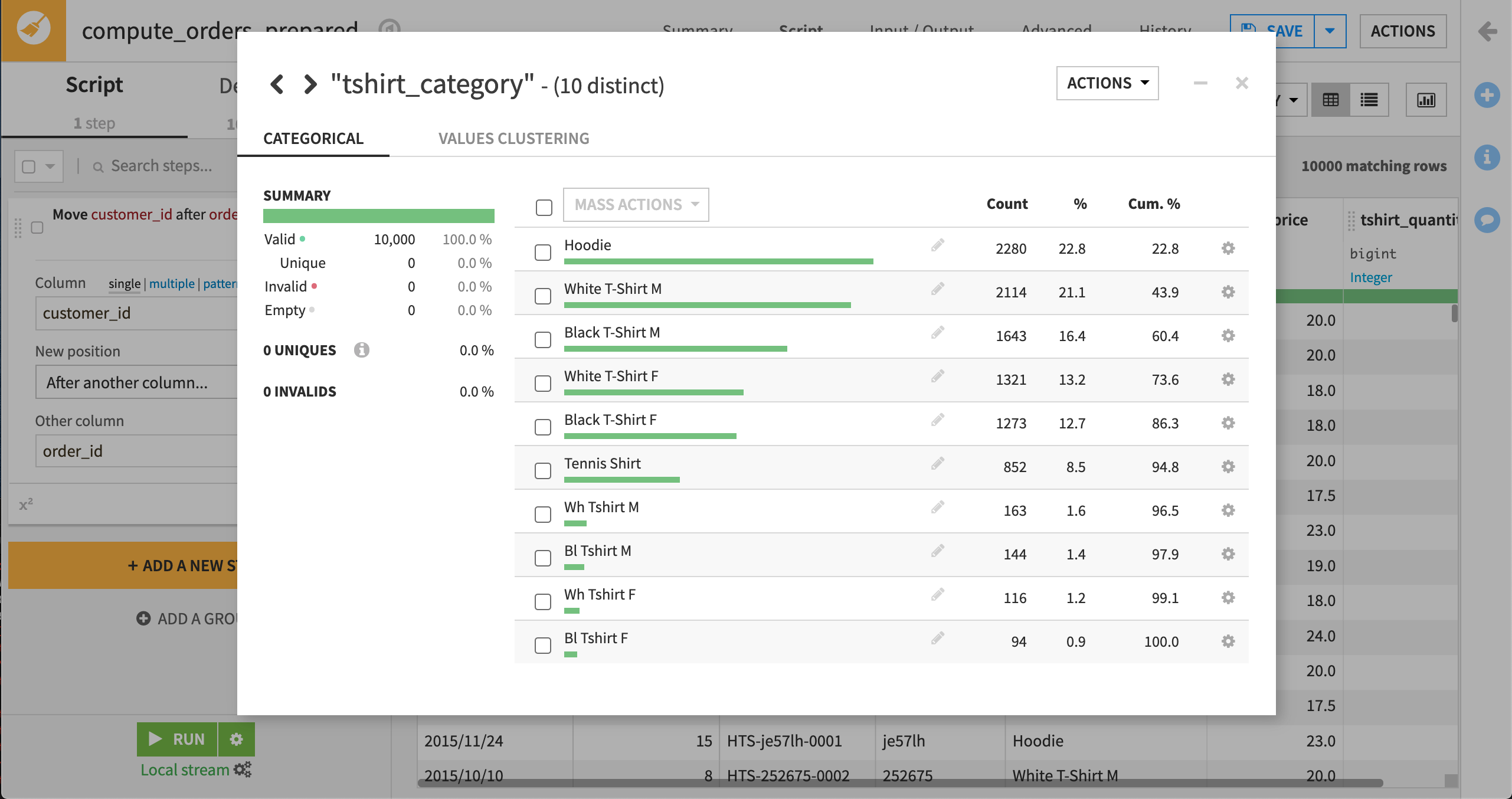
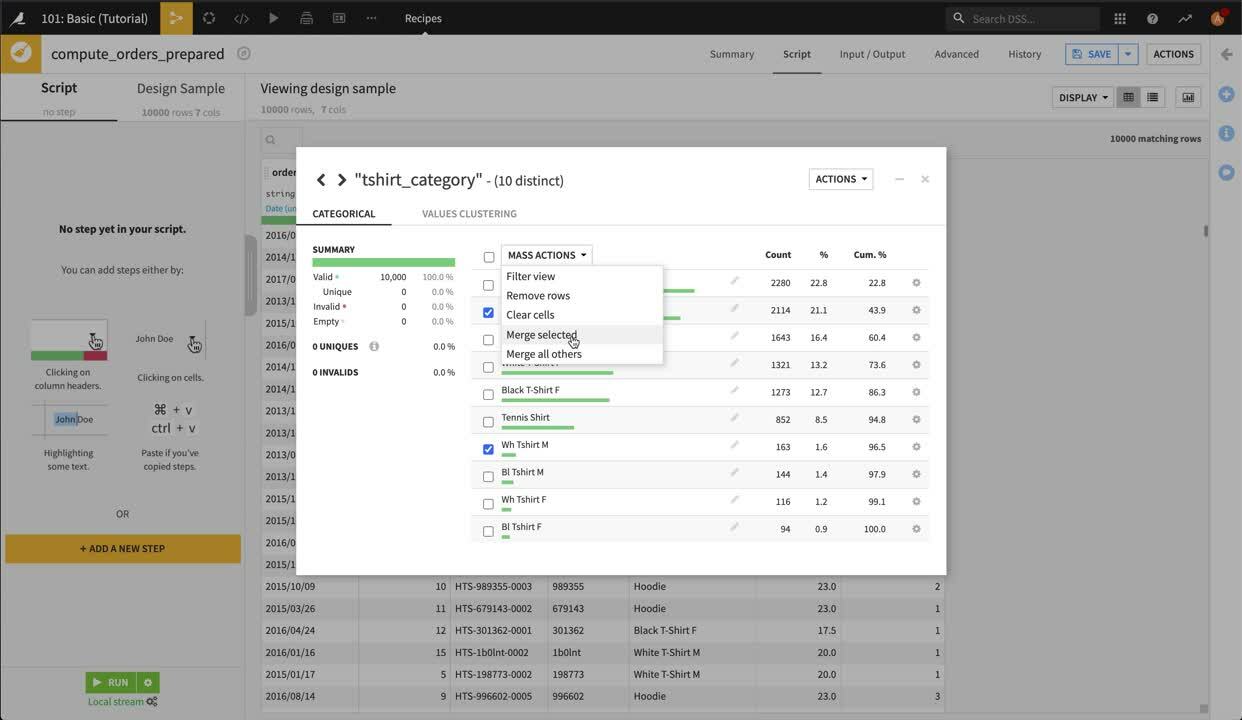
White T-Shirt M と Wh Tshirt M を選択して、 “Mass Actions”ドロップダウンから Merge selected を選択します。 値を White T-Shirt M で置換することを選択して、Merge をクリックします。 必要に応じて、このプロセスを他のカテゴリにも繰り返し行ってください。
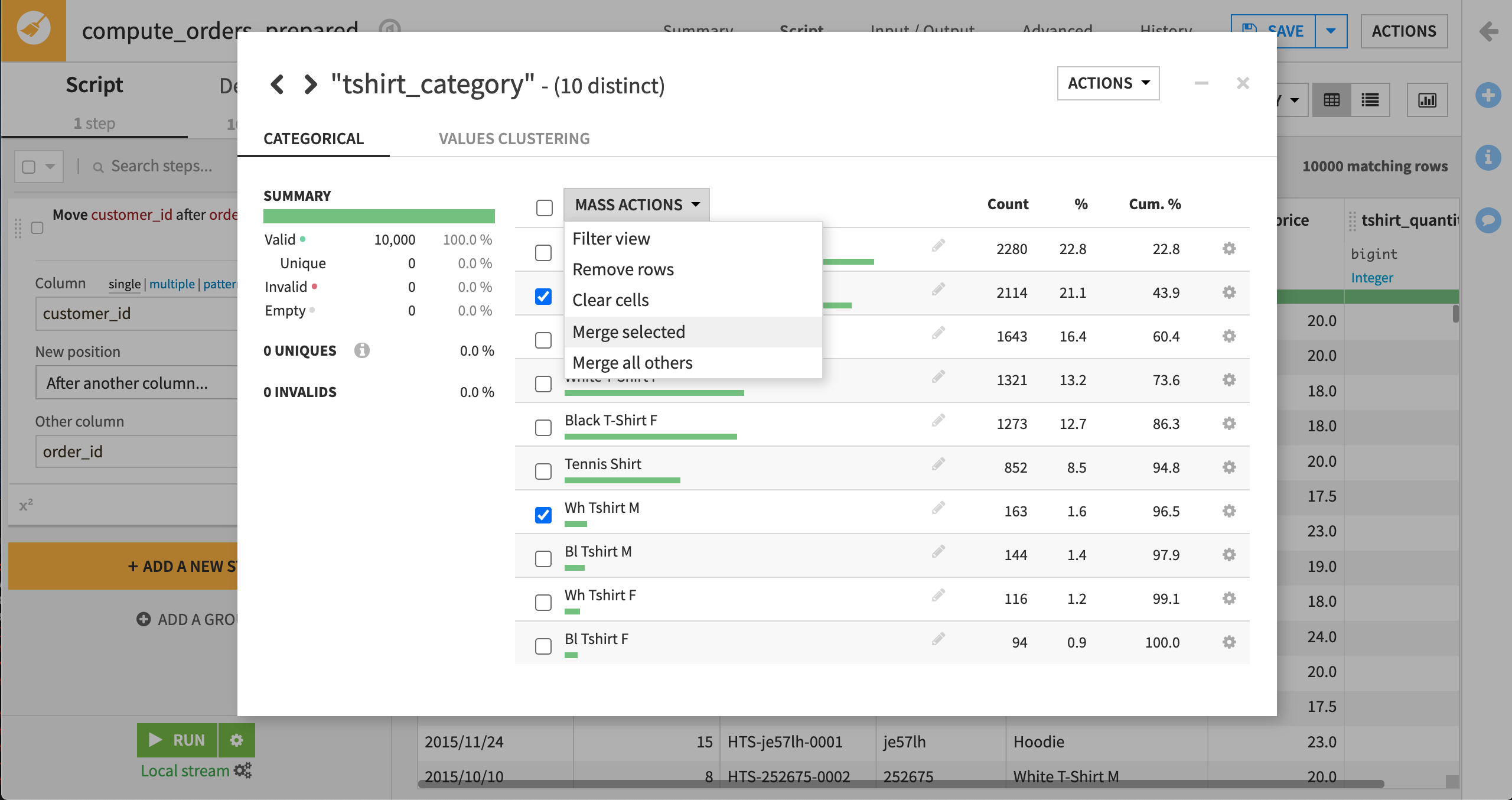
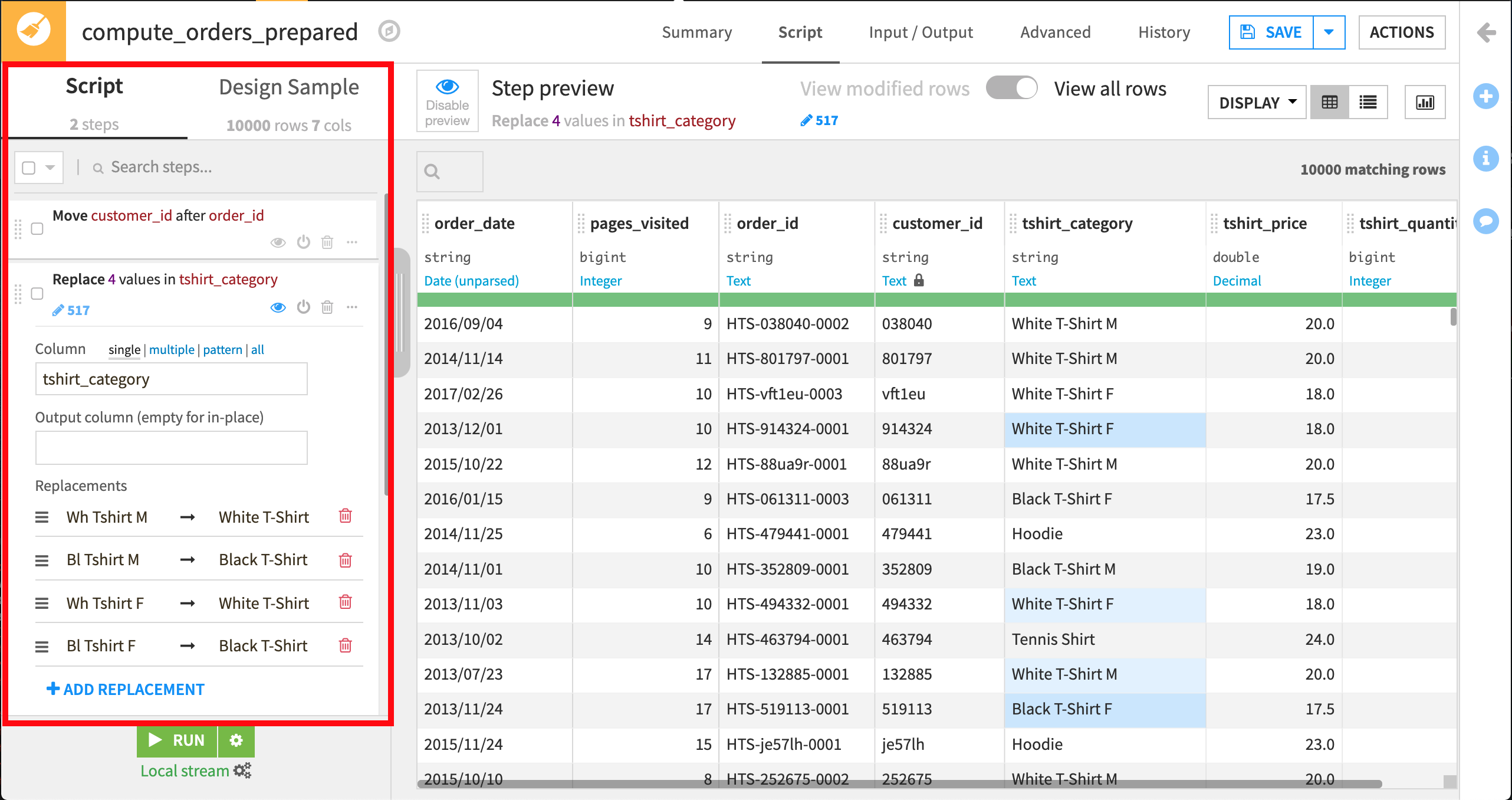
Analyze(分析)ダイアログを閉じて、Prepare(準備)**Script** に “Replace” ステップが追加されたことを確認してください。これで、スクリプトにステップ1が追加されました。
“Replace” ステップは、サンプルの中の517行に影響を与え、”Wh Tshirt M” の値を “White T-Shirt M” に置換し、”Bl Tshirt M” を “Black T-Shirt M” に置換し、 “Wh Tshirt F” を “White T-Shirt F” に置換し、”Bl Tshirt F” を適切な tshirt_category の “Black T-Shirt F” に置換します。 このステップは、スクリプトの中で明示的に作成できますが、Analyze ダイアログは、このステップをビルドするための迅速で直感的なショートカットを提供しています。
Note
Key concept: preparation script
準備レシピを使用しているとき、ユーザーは、スクリプトに登録されているアクションまたはステップのシーケンスをビルドしていることになります。このシーケンスの各ステップは、プロセッサと呼ばれ、1回のデータ変換を反映します。
元データは絶対に変更されることはありませんが、ユーザーはデータのサンプル(デフォルトで 10,000 行)への変更を視覚化します。
データセット全体に変換を適用して、クリーンアップ後のデータでアウトプットを作成するには、後述のとおり、Run the recipe する必要があります。
準備スクリプトには多くのメリットがあります。
第一に、これは強化された Cancel(キャンセル)メニューのようなものであることです。ユーザーは、以前に追加したどのステップも変更または削除できます。
第二に、これは操作の履歴であり、データセットがどのように変更されてきたかを、今後の参考のためにユーザーに示します。
プロセッサのパワーに関する詳細は、:doc:`チュートリアル:ラボからフローまで <../lab/index>`ので学びます。
現時点で、一部の値が黄色で表示されています。これは、”Step preview” モードになっているからです。このモードでは、ステップが何を変更するのかを見ることができます。黄色で示されている値は、Dataiku の “Replace” ステップで変更された値です。
データが処理後にどのように表示されるのかを見たければ、トップバーで **Disable preview**(緑の目)ボタンをクリックしてください。
The following video goes through what we just covered
さらなる準備¶
order_date を処理してみましょう。インプット日付は構文解析されていないので、これらを使用したい場合には処理する(”parsed”)必要があります。日付の処理は困難であることで有名ですが、DSS はこれを非常に容易にします。
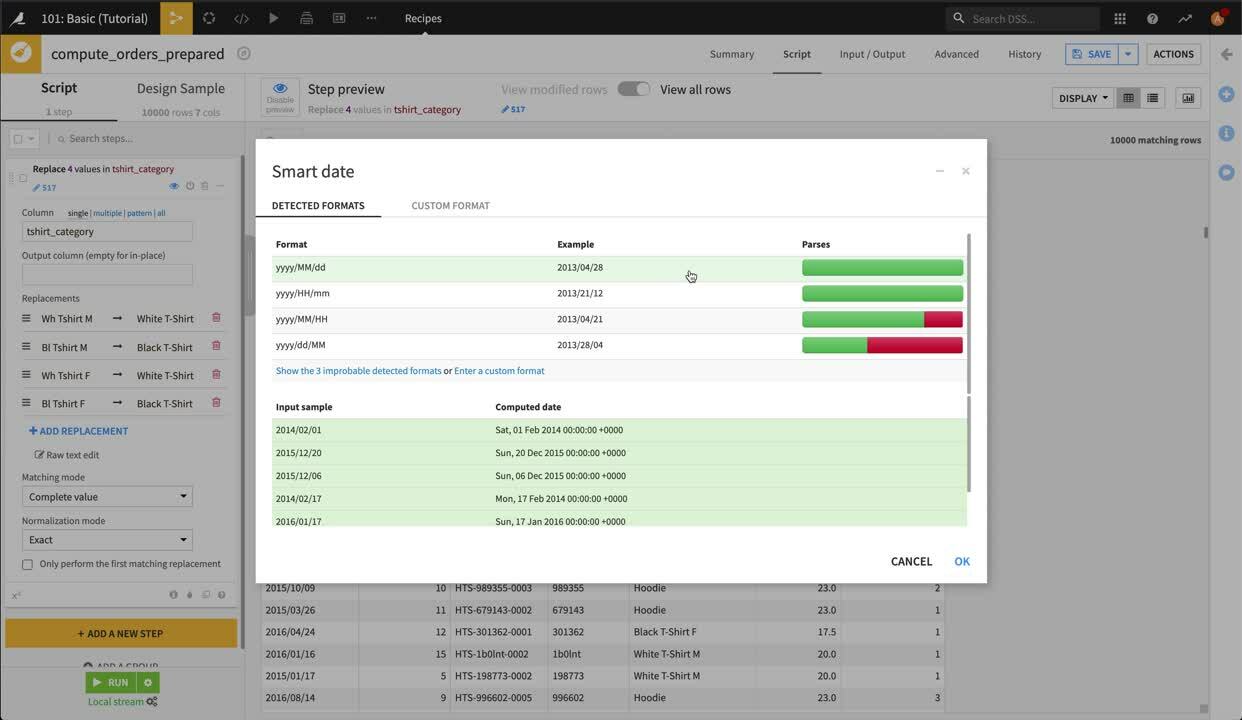
列のドロップダウンを開いて、Parse date を選択します。Smart Date ダイアログが開き、ご自分のデータの日付に最も該当しそうな形式が表示され、その日付が構文解析された後にどのように表示されるかが、データセットからのサンプル値を使って示されます。この場合、データは yyyy/MM/dd 形式で表示されます。この形式を選択して OK をクリックしてから、Prepare Script(スクリプト準備)に “Parse date” ステップが追加されたことを確認してください。
デフォルトでは、”Parse date” は新しい列 order_date_parsed を作成します。Dataiku では構文解析された日付を order_date 列の中にとどめておきたいので、スクリプトステップで “Output column” テキストボックスをクリアしましょう。これは、所定位置で日付を構文解析する効果を持っています。
The following video goes through what we just covered
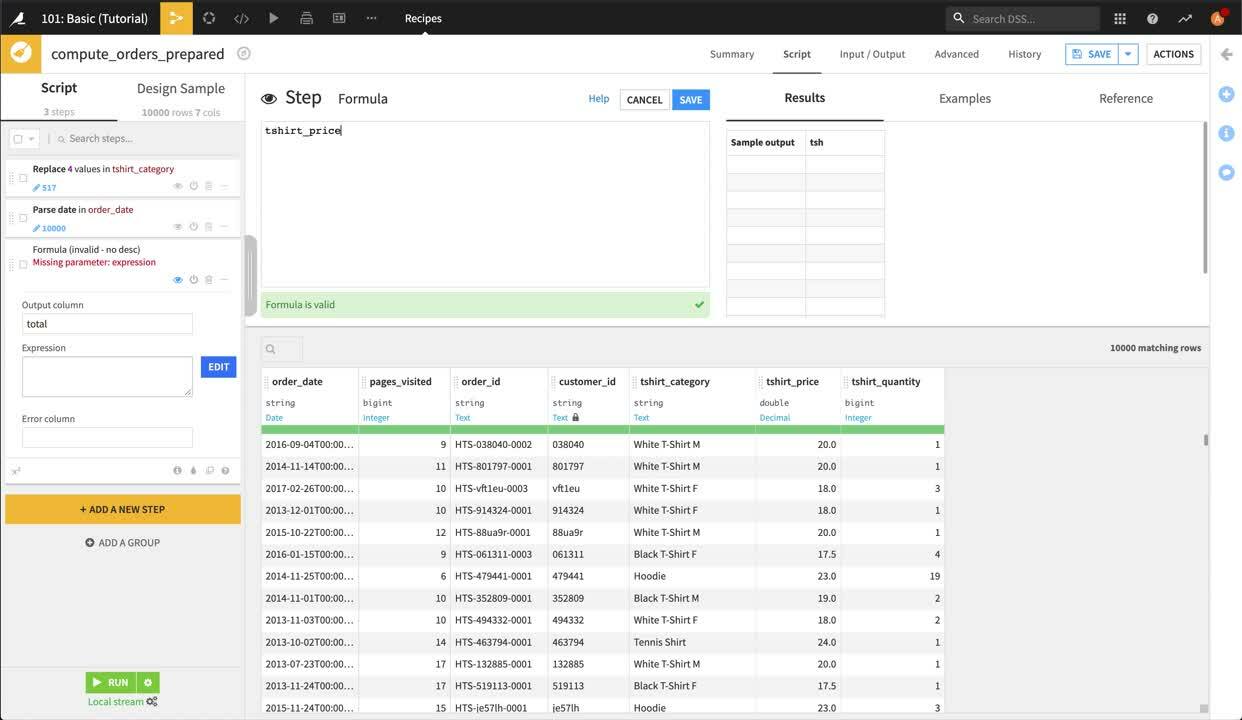
最後に、各注文の価額を計算しましょう。 orders データセットには、各注文に含まれる T シャツ数と各 T シャツの価格が含まれていますが、各注文の価額を分析できるようにするためには、各注文の合計を計算する必要があります。これには、Formula ステップを使用します。DSS フォーミュラは、計算を実行したり、文字列を操作したり、その他多数の操作を行うための非常にパワフルな式言語です。
今回は、列ヘッダーをクリックしてステップを追加することはしません。代わりに、processors library を使用します。これは、80 以上あるすべてのデータ準備プロセッサを参照します。
左のバーにある黄色の +Add a New Step ボタンをクリックします。
Formula を選択します(これは検索できます)。
新しい列の名前として、
totalを入力します。式に、
tshirt_price * tshirt_quantityと入力します。(または、Edit をクリックして、アドバンストフォーミュラエディターを起動し列名をオートコンプリートすることもできます。)どこでもよいのでクリックして、新しい total 列が表示されていることを確認してください。
もう価格と数量は必要なくなったので、これらの列は削除することができます。
列ヘッダーをクリックします。
Delete を選択します。
The following video goes through what we just covered
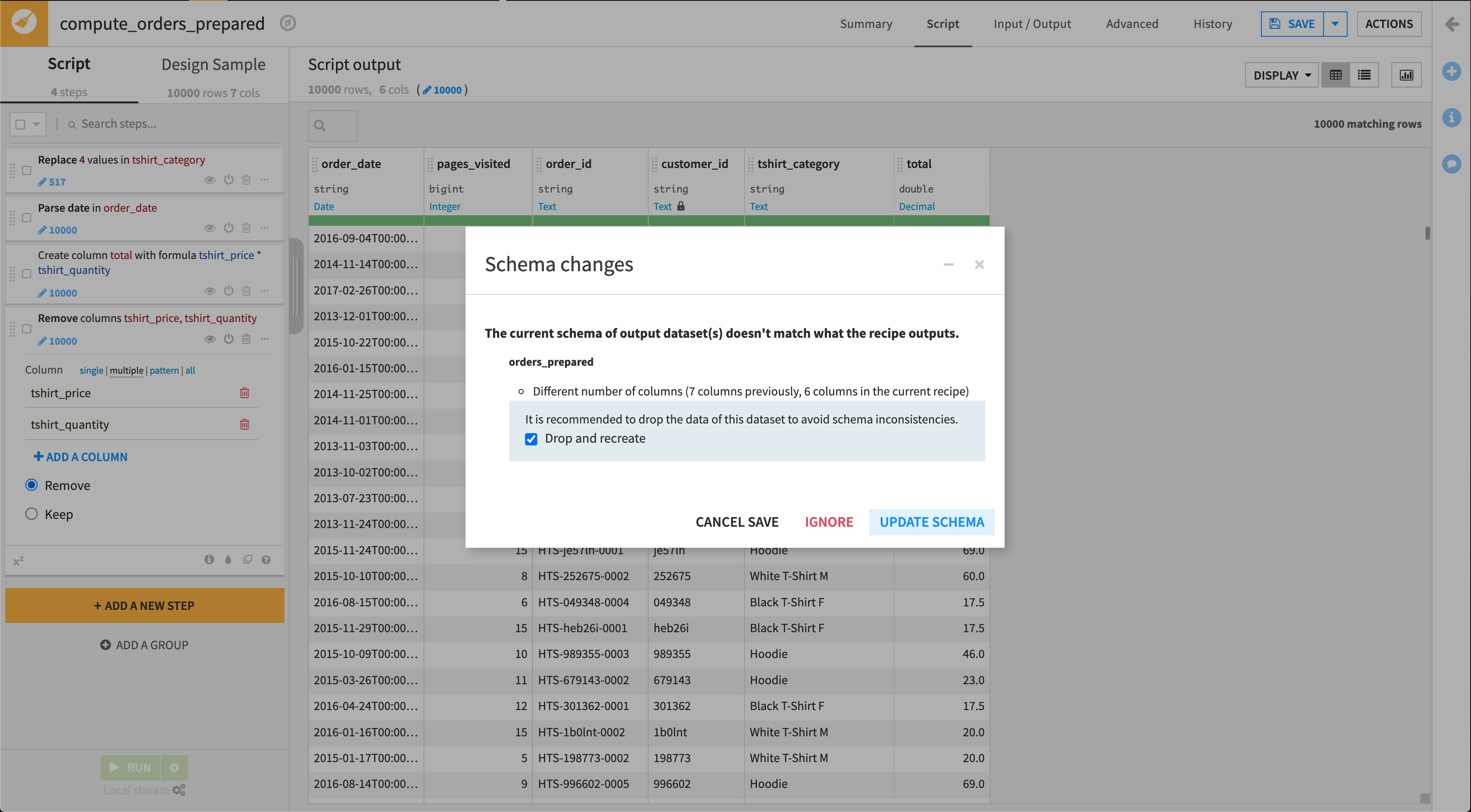
レシピの中で可視されるデータはサンプルに過ぎず、ご自身の Prepare Script(スクリプト準備)のデザインに対する即時のビジュアルフィードバックを提供するためであることを思い出してください。Prepare Script(スクリプト準備)が完成したら、今度はインプットデータセット全部に対して Run the recipe する必要があります。ページの下の左隅にある Run をクリックします。Dataiku DSS は、このレシピのランタイムに独自のエンジンを使用していますが、ユーザーのインフラストラクチャやレシピのタイプ次第では、`計算が実行される場所 <https://www.dataiku.com/learn/guide/getting-started/dss-concepts/where-does-it-all-happen.html>`_を選択できる場合があります。
ユーザーはさらに、schema を更新するように促されます。 データセットのスキーマとは、列のリストに、その列のストレージ型と意味を追加したものをいいます。 最初にこのレシピを作成したとき、デフォルトのアウトプットスキーマは、インプットスキーマと全く同じでした。なぜなら、レシピの中にステップがなかったからです。 以来、列合計を作成して、tshirt_price および tshirt_quantity の列を削除しているので、Dataiku DSS に、スキーマ更新を許可する必要があります。
ジョブが完了したら、Explore dataset orders_prepared をクリックして、アウトプットデータセットにアクセスしてください。
アウトプットデータセットの調査¶
Prepare Recipe では、DSS は列のストレージ型を、その検出された意味に従って自動的に選択しました。したがって、pages_visited は、アウトプットデータセットの中では bigint、total は double 型として書き込まれました。
この時点で当然生じる疑問としては、どのカテゴリの T シャツが最も人気がありか、ということです。 これに回答するには、クリーンアップされたデータと、単純な棒グラフで始めることができます。 Charts タブをクリックします。 total を Y 変数、tshirt_category を X 変数として選択します。
この結果生成された棒グラフは、平均すると、テニスシャツの注文が他の T シャツの注文よりも多かったことを示しています。 しかし、顧客の支出の合計はどうでしょう?
total**ドロップダウンを開いて、集計方法として**Sum を選択します。 すると、視点が変わります。 テニスシャツの各注文は比較的高額ですが、テニスシャツの注文数は、比較的少なくなっています。 フード付きスウェットと男性用 T シャツの方がよく注文されており、これらの注文の合計価額は、テニスシャツのそれを超えていました。
The following video goes through what we just covered
インタラクティブ統計¶
データセットの Statistics ページを使って、EDA(exploratory data analysis:探索的データ分析)を行うことも可能です。Statistics ページでは、Worksheets および Cards を作成することによって、データに関する統計レポートを生成できます。
Note
Key concept: Worksheet
DSS では、Worksheet は EDA タスクのビジュアルなサマリです。データセットでは、Statistics タブをクリックすると複数のワークシートを作成できます。
ワークシートのヘッダーは、新しいカードを作成するためのボタンと、ワークシートをカスタマイズするためのオプションを提供するメニュー項目から構成されています。例えば、ワークシートをコンテナの中で実行するオプション、ワークシートで使用するデータセットをサンプリングする方法を指定するオプション、統計テストに対するグローバルな信頼水準を変更するオプション、 ワークシートを複製するオプションなどがあります。
ワークシートに関する詳細については、参考ドキュメントの中にある`ワークシートインターフェース <https://doc.dataiku.com/dss/latest/statistics/interface.html>`_を参照してください。
1つのワークシートで、+New Card ボタンをクリックして、複数のカードを作成できます。
Note
Key concept: Card
DSS では、Card は、特定の EDA タスクを実行するために使用されます。例えば、データセットについて説明したり、基盤となる母集団に関して推定を下したり、次元削減の効果を分析することができます。
1 つのワークシートに多くのカードを含めて、カードがワークシートヘッダーの下に表示されるようにすることができます。すべてのカードには設定メニューがあり、カード設定を編集したり、 JSON ペイロードやレスポンスを表示する(パブリック API を使用する目的で)などを行うことができます。一部のカードには複数のセクションも含まれており、各セクションにそれぞれ専用の設定メニューが付いています。
カードに関する詳細については、参考ドキュメントの中にある`カードの要素 <https://doc.dataiku.com/dss/latest/statistics/interface.html#card-elements>`_を参照してください。
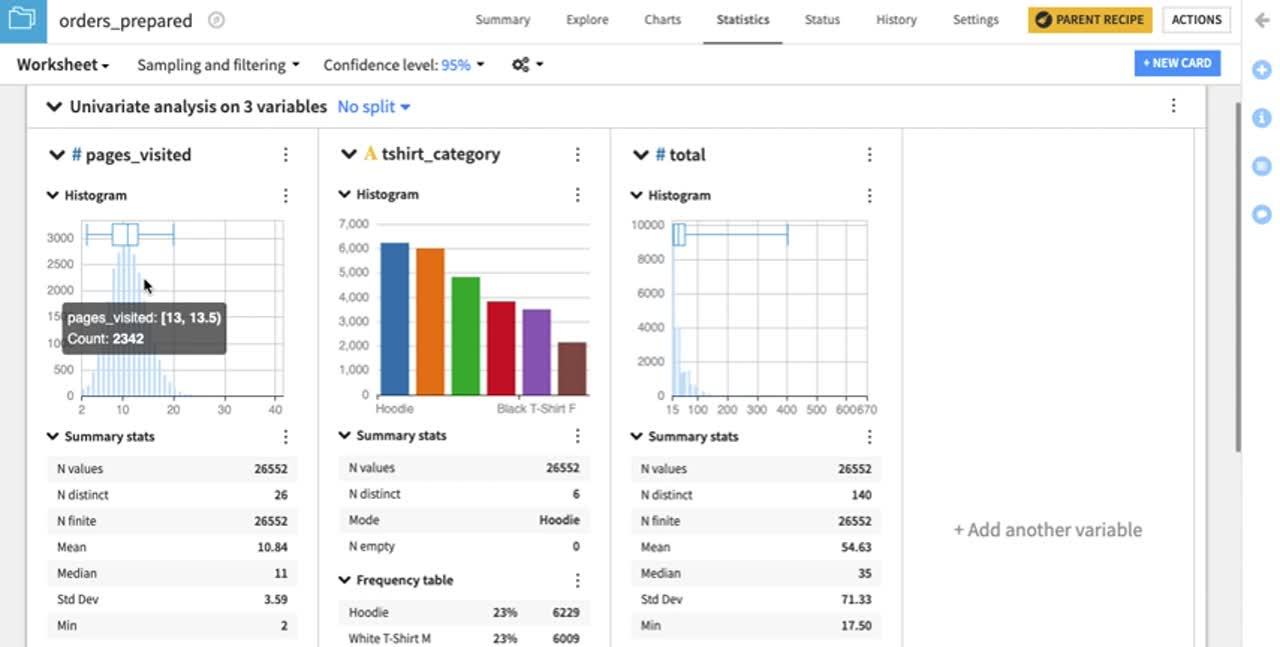
EDA タスクを実行するカードでワークシートを作成しましょう。例えば、pages_visited、tshirt_category、total の各変数に関する *orders_prepared*データセットの 2 列横並びのサマリを表示したい場合:
Statistics タブをクリックして、+Create Your First Worksheet をクリックします。
Univariate analysis ボックスを選択して、”Univariate analysis” ウィンドウを開きます。
ウィンドウの 1 番目の列から、 pages_visited、tshirt_category、および total を選択して、”Variables to describe” の横の “plus” ボタンをクリックします。
DSS は、数値変数(pages_visited と total)とカテゴリ変数(tshirt_category)に適切な統計の “Options”(ウィンドウの 3 番目の列)を自動的に選択します。これらのうち、必要のないオプションは、任意で選択解除できます。

Create Card をクリックします。
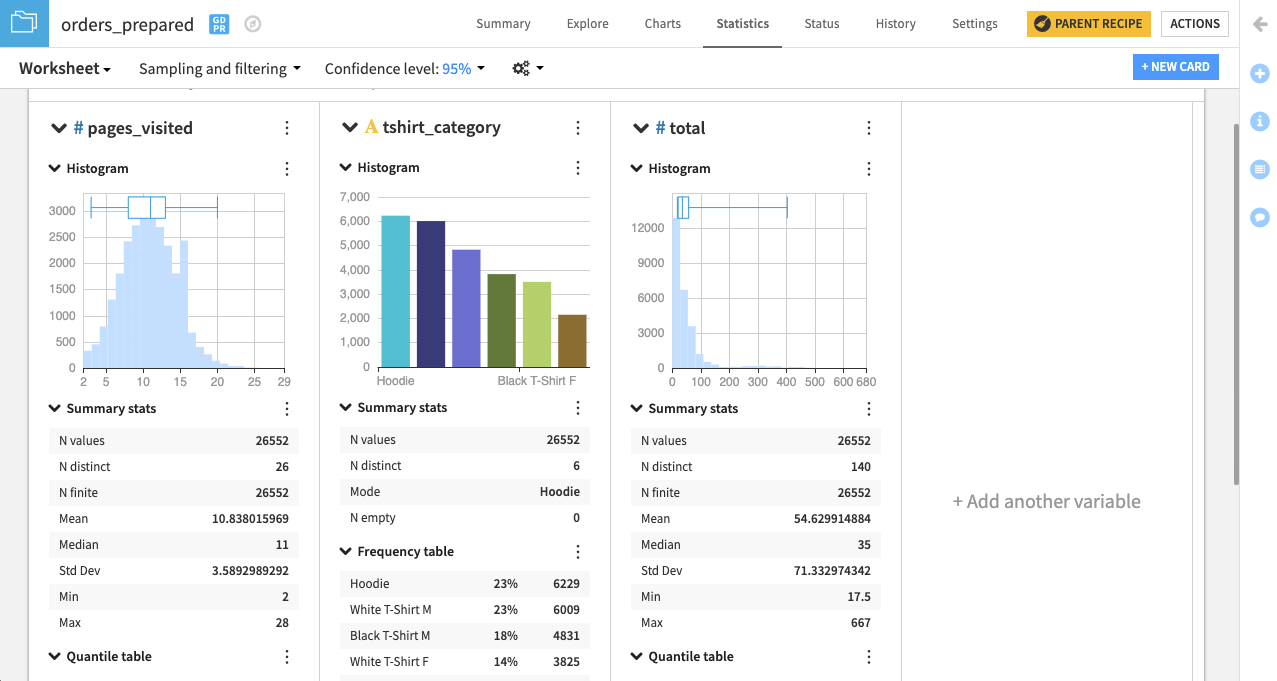
DSS は、各変数につき 1 つのセクションを設けたカードを作成します。各セクションの中の統計グラフと記述統計の種類は、その変数がカテゴリであるか、数値であるかに応じて決定します。例えば、カテゴリ変数 tshirt_category には棒グラフ(またはカテゴリのヒストグラム)が付くのにに対し、pages_visited と total にはそれぞれ、数値のヒストグラムとボックスプロットが挿入されています。また、数値変数には変位値の表が適用されるのに対し、カテゴリ変数には頻度の表が適用されます。
DSS はデフォルトにより、データセットの中の先頭レコードのサンプルに関するワークシート統計を計算します。この設定は、Sampling and filtering の横のドロップダウンの矢印をクリックすることによって変更可能です。
また、total 変数が指数分布に従っているかどうかをチェックすることもできます。このインタラクティブな統計機能を使用すれば、Fit Distribution カードを使って、一変量の確率分布のパラメータを概算できます。
“Worksheet” ウィンドウから +New Card ボタンをクリックして、Fit curves & distributions を選択します。
Fit Distribution カードを選択します。
total を “Variable” として選択し、また、Exponential を “Distribution” として選択します。
Create Card をクリックします。
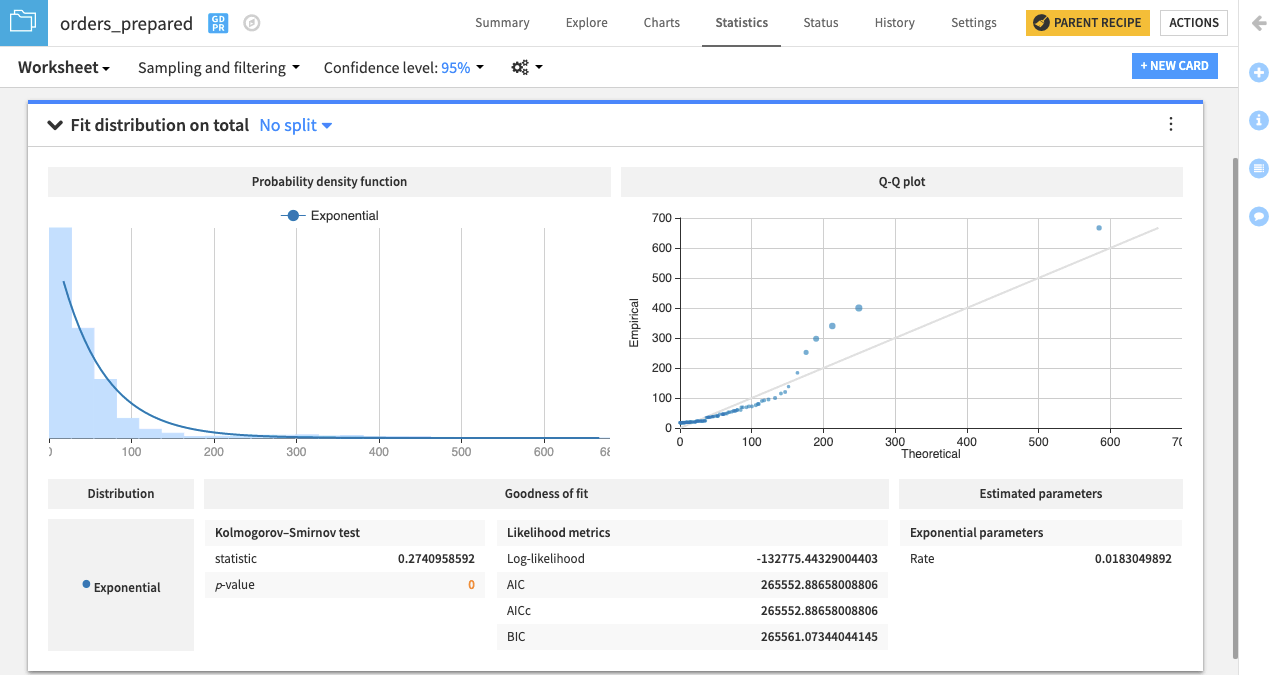
DSS は、データへの指数分布のフィットを示すカードを作成します。また、フィットされた分布の変位値に対してデータの変位値を比較する Q-Q プロットもあります。観測点が等値線から遠く離れている場合、データが指数分布から引き出されたものではないことが示唆されます。
Statistics ページの完全な機能の詳細については、参考ドキュメントの`インタラクティブ統計 <https://doc.dataiku.com/dss/latest/statistics/index.html>`_の項を参照してください。:doc:`../statistics/index`チュートリアルに従って、ハンズオンで練習することもできます。
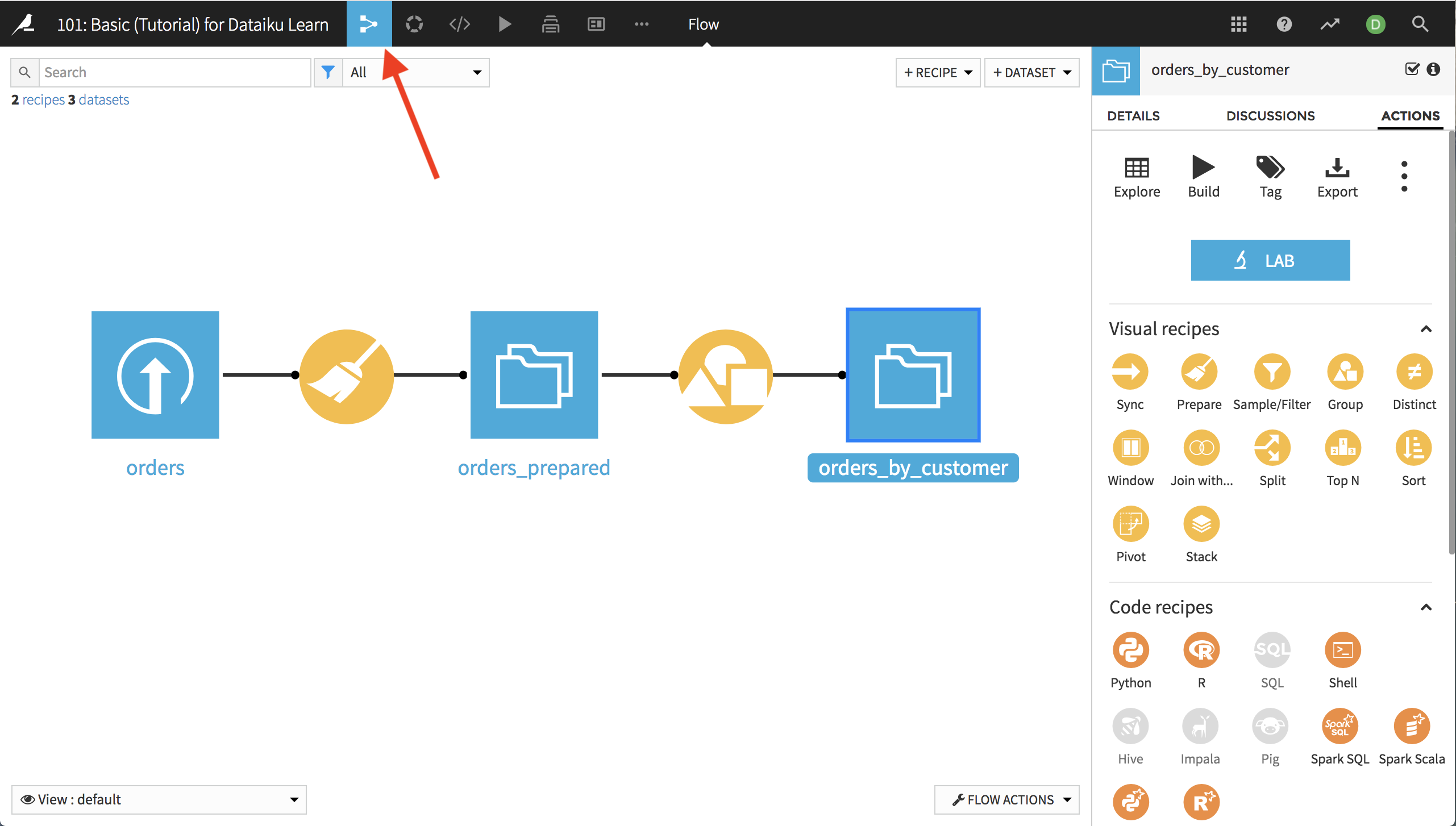
注文を顧客別にグループ化¶
Dataiku の最終的な目標は、Haiku T-Shirts の顧客を理解することです。そのため、過去のすべての注文を顧客別にグループ化して、顧客の過去のインタラクションを集約します。
orders_prepared データセットを開いたまま、右上隅にある**Actions** メニューを探してください。 このメニューから、ビジュアルレシピのリストの中にある Group を選択します。 Group Recipe を使って、いくつかの列の値を、1 つ以上の keys の値ごとに集約することができます。
customer_id 別にグループ化することを選択します。 この新しいデータセットのデフォルト名は、あまりわかりやすくないので、orders_by_customer に変更してください。 **Create Recipe**をクリックします。
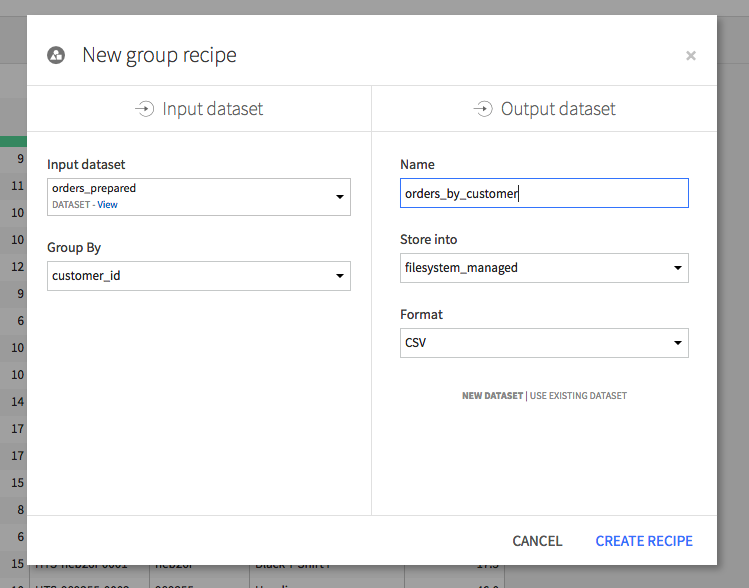
Group Recipe には、複数のステップがあります(左側)。中核となるステップは Group(グループ化)ステップです。このステップでは、どの列を集計するか、何の集計を実行したいかを選択します。
order_id などの一部の列は、新しいデータセットには必要ありません。それ以外の列に関しては、次の選択を行います。
order_date: Min
pages_visited: Avg
total: Sum
これにより、ある特定の顧客が注文した最初の日付(order_date の最小値)、1 回の訪問で訪問した平均ページ数、その顧客のすべての注文の合計金額がわかります。
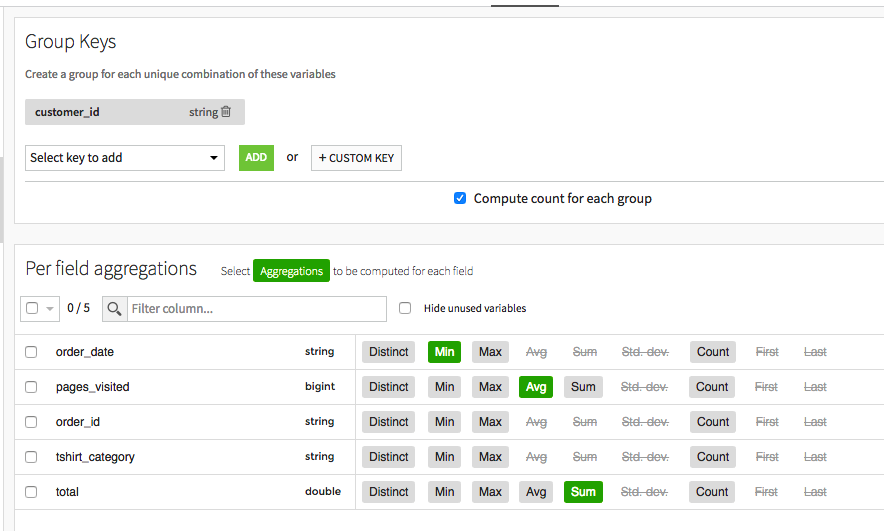
Output(アウトプット)ステップでは、オプションで、アウトプット列の名前を変更できます。では、order_date_min の名前を `first_order_date`に変更しましょう。
Run をクリックして新しいグループ化されたデータセットを作成し、実行が完了したら、新しいデータセットを Explore(調査)してください。
The following video goes through what we just covered
フローの調査¶
ページの最上部のプロジェクト名の横にあるフローアイコンをクリックして、プロジェクト Flow に移動します。フローは、プロジェクトパイプラインのビジュアル表示です。ほうき印の Preparation Recipeがあり、その後にアウトプットデータセットがあり、その後に Group Recipe があり、そのアウトプットデータセットがその後に続きます。