ラボからフローへ¶
おめでとうございます!
今あなたは:doc:Haiku Tシャツ注文記録 <../basics/index> をお持ちです。これで顧客データの結合準備完了です。
このチュートリアルでは Haiku Tシャツの顧客データを準備した注文データに結合します。 それからさらなる分析のためインタラクティブなラボを使い、結合したデータをエンリッチ化します。
あなたのプロジェクトを作成¶
「ラボからフローへ」チュートリアルプロジェクトの zip エクスポート をあなたのローカルファイルシステムにダウンロードします。 それから Dataiku ホームページから +New Project をクリックしリストから Import Project を選択します。次にダウンロードした zip ファイルを選択してください。
Go to Flow をクリックします。
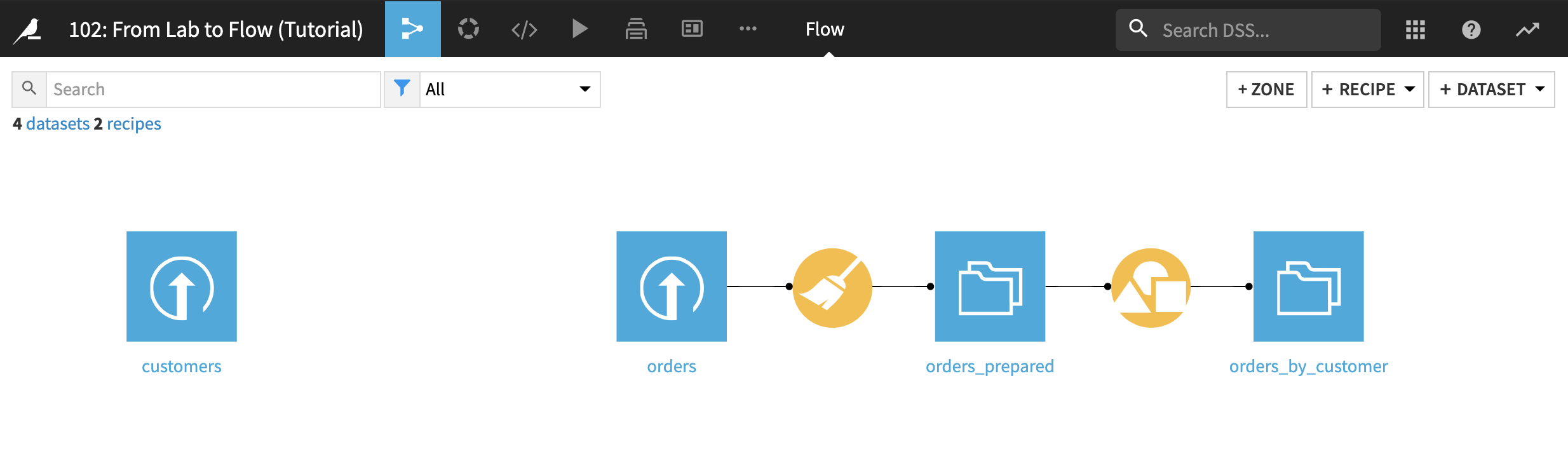
フローには、前のチュートリアルで orders データセットの作成と準備に使ったステップが入っています。 次のセクションで説明する新しいデータセット customers もあります。
または、`customers.csv ファイルのコピー <https://downloads.dataiku.com/public/website-additional-assets/data/customers.csv> をダウンロード`_ してそれをプロジェクトにアップロードすると :doc:`基本チュートリアル <../basics/index>`で開始したのと同じプロジェクトで続行できます。
注文データで顧客を増やすための結合レシピを使う¶
以下のビデオ でこのセクションの内容を説明します。
Flow にあるアイコンをダブルクリックして customers データセットを開きます。
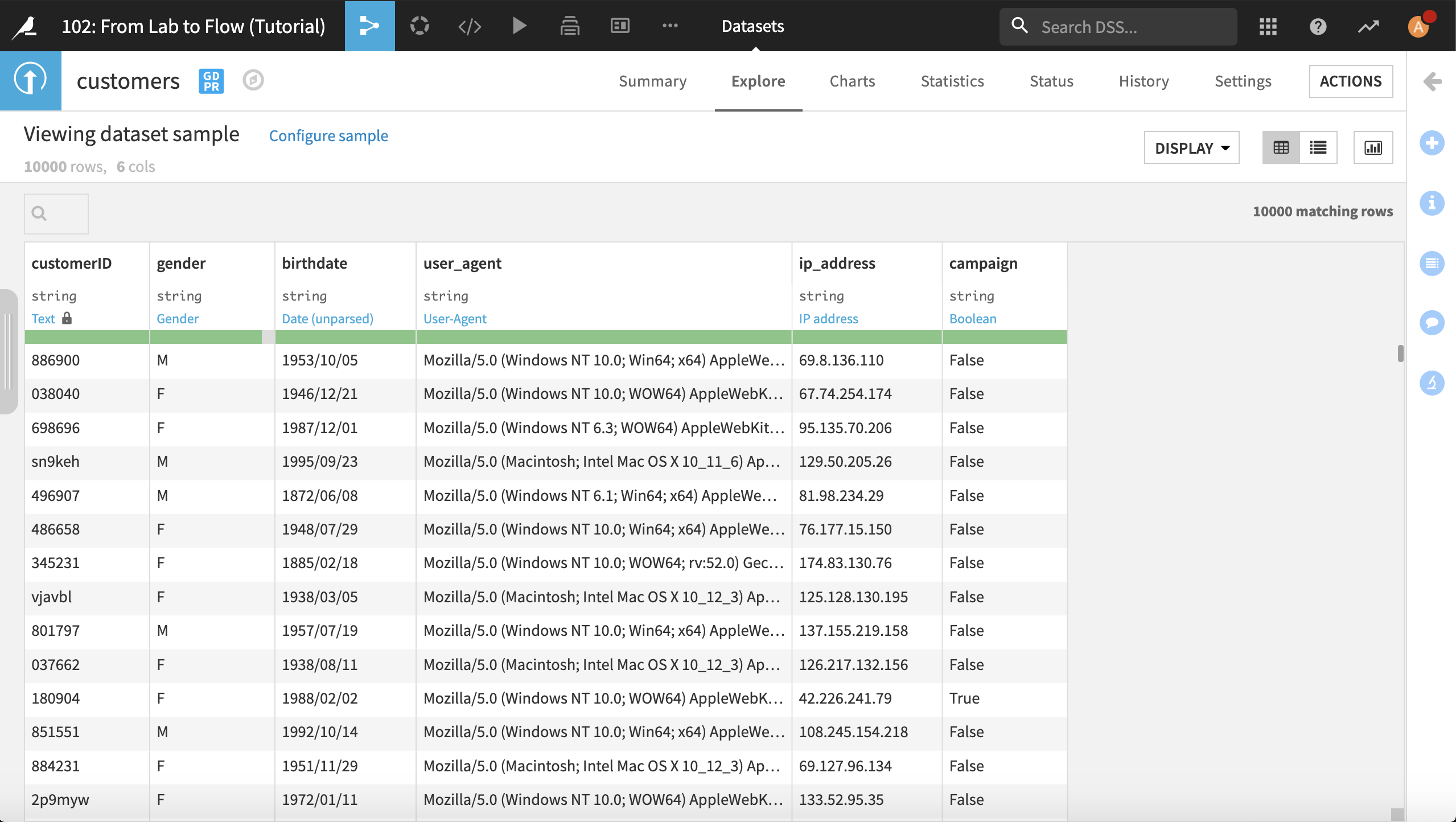
このデータセットの各行は、個々の顧客と記録を表示します。
一意の顧客 ID
顧客の性別
顧客の生年月日
顧客が最もよく使っているユーザー手段
顧客の IP アドレス
顧客が Haiku T-Shirt のマーケティングキャンペーンに参加しているかどうか
これで、顧客が注文した合計に関する情報で customers データセットをエンリッチ化させる準備ができました。 Actions メニューのビジュアルレシピ一覧から Join with… を選択します。
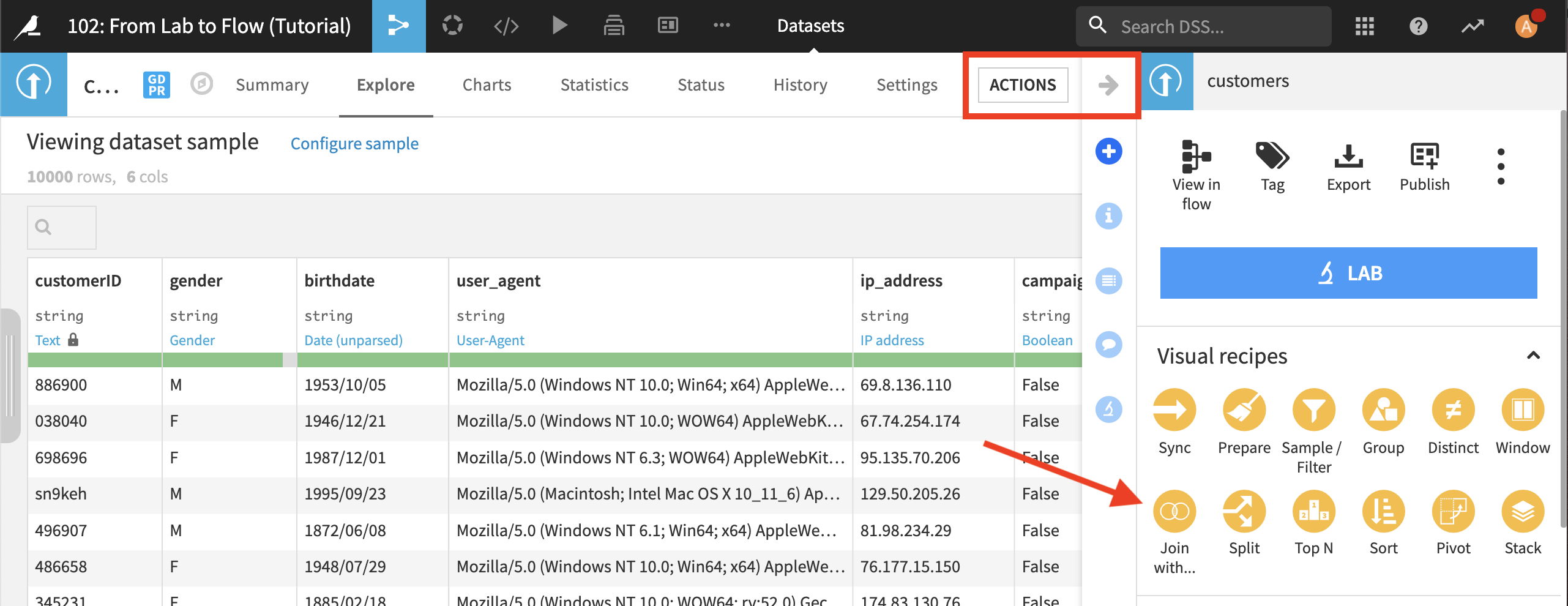
2番目の入力データセットとして orders_by_customer を選択します。出力データセットの名前を customers_orders_joined に変更します。 Create Recipe をクリックします。
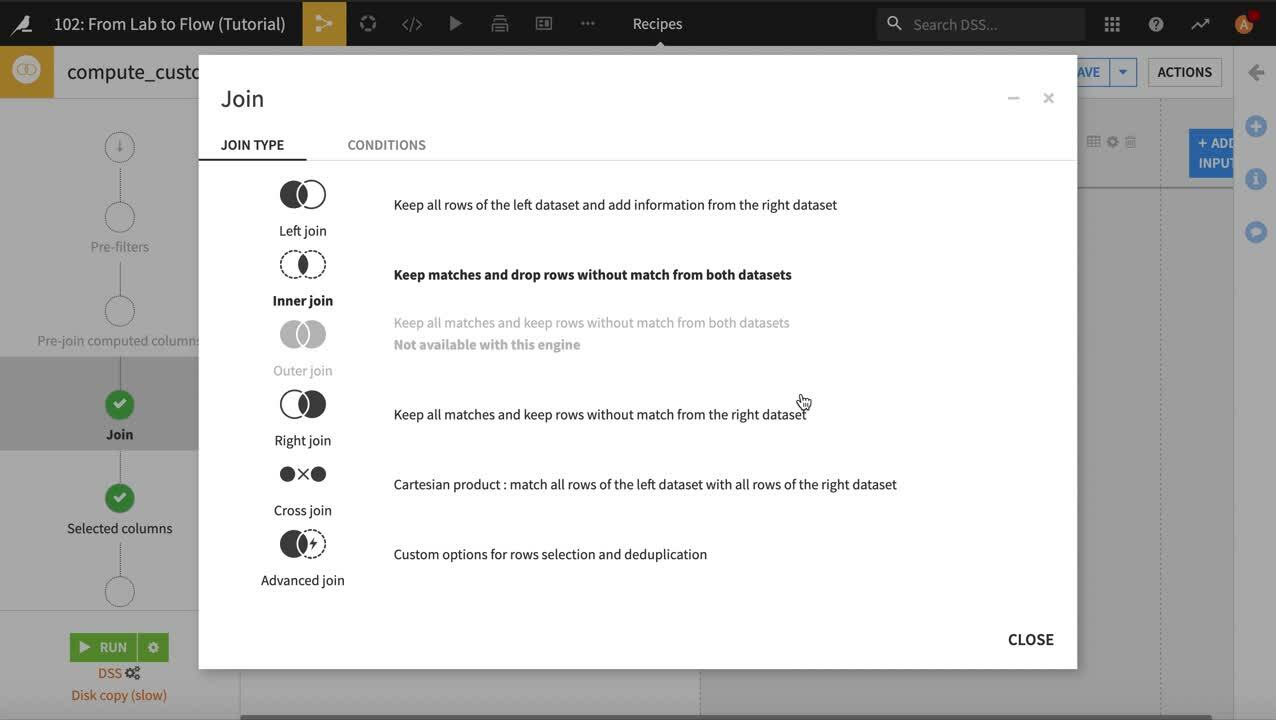
結合レシピには複数のステップがあります (左側のナビゲーションバーに表示)。核となるステップは Join です。データセット間で行を一致させる方法を選択します。 この場合、customerID と customer_id の同じ値を持つ*customers* と *orders_by_customer*から行を一致させたいと私たちは考えています。 列名が異なる場合でも、Dataiku DSS は結合キーを自動で検出することにご注意ください。

デフォルトでは、結合レシピは左結合を実行し、右側に一致する情報がなくても左側のデータセットの全行が保持されます。 1つ以上の注文を行った顧客のみを処理するため結合タイプを変更しましょう。
Left Join インジケータをクリックします
結合詳細が開きます。Join Type をクリックします
Inner join をクリックし、結合タイプを内部結合に変えるため Close します。内部結合では一致するデータセットの行のみが保持されます。これにより、注文を行った顧客のみが保持され、それ以外の顧客はこの分析から除外されます。

Note
Types of joins
2つのデータセットを結合するには複数の方法があります。どの方法を選択するかはデータと分析の目的によって異なります。
Left join は、左側のデータセットの全行を保持し、一致があれば右側のデータセットから情報を追加します。 これは左側のデータセットの行にすべての情報を保持する必要があり、右側のデータセットが追加の、場合によっては不完全な情報を持っている場合に便利です。
Inner join は両方のデータセットで一致する行のみを保持します。 これは、両方のデータセットの完全な情報を持つ行のみがダウンフローに役立つ場合に便利です。
Outer join は一致する行を結合して両方のデータセットの全行を保持します。 これは両方のデータセットの全情報を保持しなければならない場合に便利です。
Right join は左結合のようですが、右側のデータセットの全行を保持し、一致があれば左側のデータセットから情報を追加します。
Cross join は左側のデータセットの全行と右側のデータセットの全行を一致させるデカルト積です。 これはあるデータセットの全行を別のデータセットの全行と比較する場合に役立ちます。
Advanced join は他に適切なオプションがない場合に備え、行選択と重複除外のカスタムオプションを提供します。
デフォルトでは結合レシピは左結合を実行します。
私たちは*customer_id* を除く両方のデータセットの全列を出力データセットに引き継ごうと考えています (*customers*データセットの*customerID*列で十分なため)。
Selected columns ステップをクリックします
orders_by_customer データセットの customer_id 列のチェックを外します
Run をクリックしてレシピを実行します。列を削除したため、スキーマの更新が必要であることを DSS が警告します。Update Schema をクリックしてスキーマ変更を承諾します。レシピが動作します。完了したら画面下の Explore dataset customers_orders_joined をクリックして customers_orders_joined データセットを探索します。
The following video goes through what we just covered.
..これは Vidyard の tshirts-customers-join-01 ビデオです
ラボを知る¶
これまであなたは、レシピを使ったデータセット作成方法と、データセットが Flow でどのようにデータパイプラインを作成するのかについて学習してきました。このチュートリアルでは、Lab と呼ばれる専用環境でフロー外のデータに関する準備作業を行なう方法が見られます。
Lab で使用可能なツールを確認しましょう。customers_orders_joined データセットで Actions をクリックして次に Lab をクリックします。 Lab パネルが開きます。
Note
Key concept: Lab
Lab は、予備データ探索やクレンジング、あるいは機械学習モデルの作成などができるあなたの**drafting** (設計)場所です。ラボ環境には以下が揃っています:
data preparation、charts、machine learning モデルの設計ができる Visual analysis ツール
あなたが選択した言語でデータをインタラクティブに探索できるようにする Code Notebooks
一部のタスクは、ラボ環境でもフロー内のレシピを使っても実行できることに留意してください。その主な違いとレシピを補完的に使う方法を次に示します:
ラボ環境がフローのデータセットに接続されているため、不要な項目で Flow を過度に混雑させずに設計や準備作業を簡単に整理できます。このフローにより、作業を安定させ、将来的に自分や同僚が再利用できるようになります。
ラボで作業する場合、元のデータセットは変更されず新しいデータセットも作成されません。代わりに、データに対して実行する変更結果を対話形式でビジュアル化できます(サンプルの大抵の場合)。この双方向性の速度は、データ内容をすばやく評価できる快適な空間を提供します。
作業に満足したら、それをコードまたはビジュアルレシピとしてフローにデプロイできます。新しく作成されたレシピとその関連出力データセットは元のデータセットパイプラインに追加されます。そのため future data reconstruction or automation ですべての研究成果が利用可能になるのです。 .
このチュートリアルでは、ラボの Visual analysis ツールを使います。
New Analysis をクリックします。解析用に名前を指定するよう求められます。ここではデフォルト名の Analyze customers_orders_joined のままにしておきます。
この Visual analysis ツールには、メインタブが 3 つあります。
Script。インタラクティブなデータ準備
Charts。チャート作成
Models。機械学習モデル作成
このチュートリアルでは最初の2つのタブについて説明します。モデリングは、次のチュートリアルのトピックで扱います。
インタラクティブにあなたのデータを準備する。¶
以下のビデオ でこのセクションの内容を説明します。
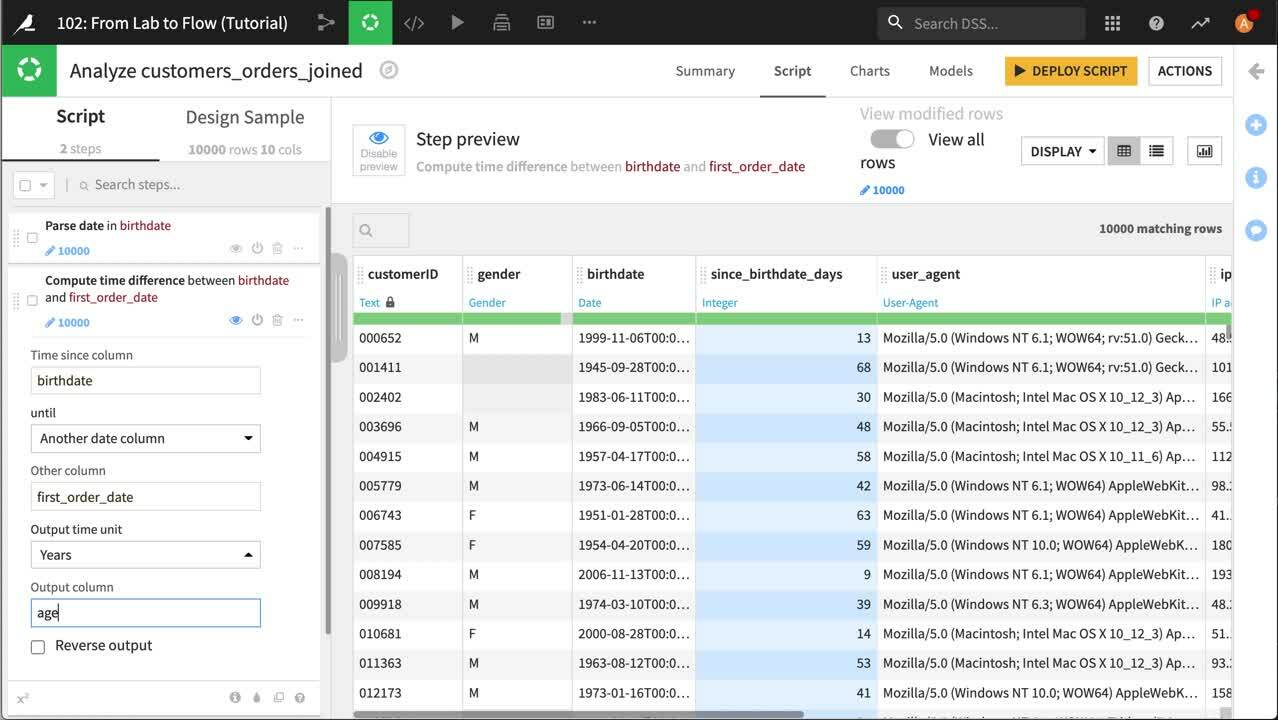
まずは birthdate 列を解析しましょう。 以前やりましたね。ですから簡単ですよ。列のドロップダウンを開いて Parse date を選択します。それから、解析された日付が元の birthdate 列に置き換わるようにスクリプトステップの出力列をクリアします。
顧客の誕生日と最初の注文日から、初めての注文日のときの年齢を計算できます。 birthdate 列のドロップダウンから Compute time since を選択します。 これは Prepare Script (スクリプトを準備) に新規の Compute time difference ステップを作成します。いくらか編集するだけです。
Another date column にするには “until” を選択します
Choose to be the first_order_date 列にするには “Other column” を選択します
“Output time unit” を Years に変更します
それから Output column 名を age_first_order に編集します。
年齢分布が問題ないかどうかを調べるため、新しい列 age_first_order ヘッダードロップダウンから Analyze を選択します。 結果的に 120 歳をはるかに超える数多くの異常値があることがわかりました。これらは不良データを示しています。分析ダイアログで Actions ボタンをクリックし、1.5 IQR (四分位範囲) 外の値をクリアするために選択します。 これでこれらの値が欠損と設定されます。
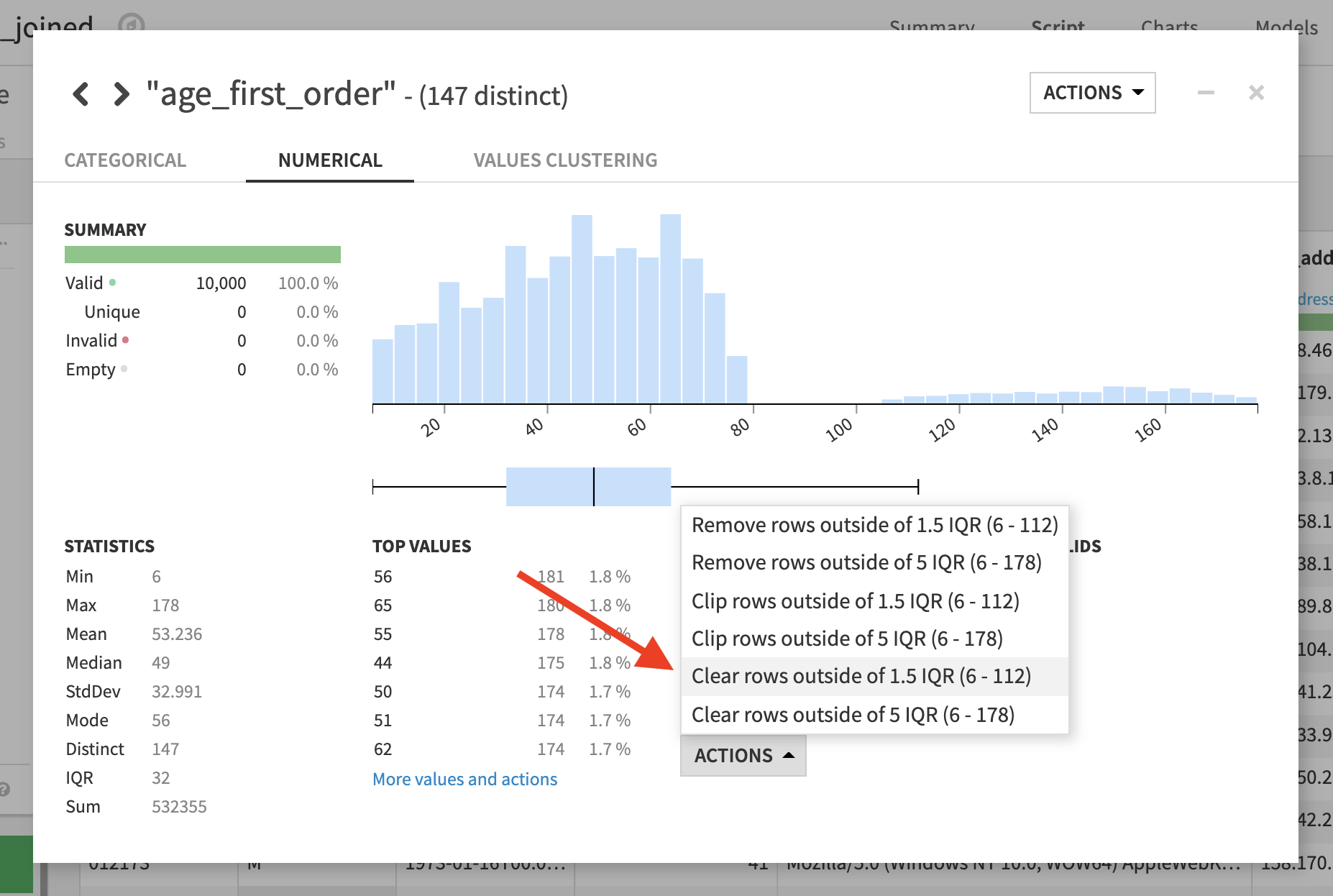
今は、分布はより妥当なものになりましたが、100を超える疑わしい値がいくらか残っています。 これらの値は上限を設定することで削除できます。分析ダイアログを閉じます。スクリプトでステップ Clear values outside [6.000,112.0] in age_first_order をクリックして拡張します。上限を 100 に設定します
最後に、今私たちは age_first_order を算出したので、もう birthdate や first_order_date は不要です。ではそれらをスクリプトから取り除きましょう。 列のドロップダウンを開き Delete を選択します。 これは準備スクリプトに新しい Remove ステップを作成します。
The following video goes through what we just covered.
今から user_agent と ip_address 列を処理してデータをエンリッチ化しましょう。
ユーザエージェントの活用¶
以下のビデオ でこのセクションの内容を説明します。
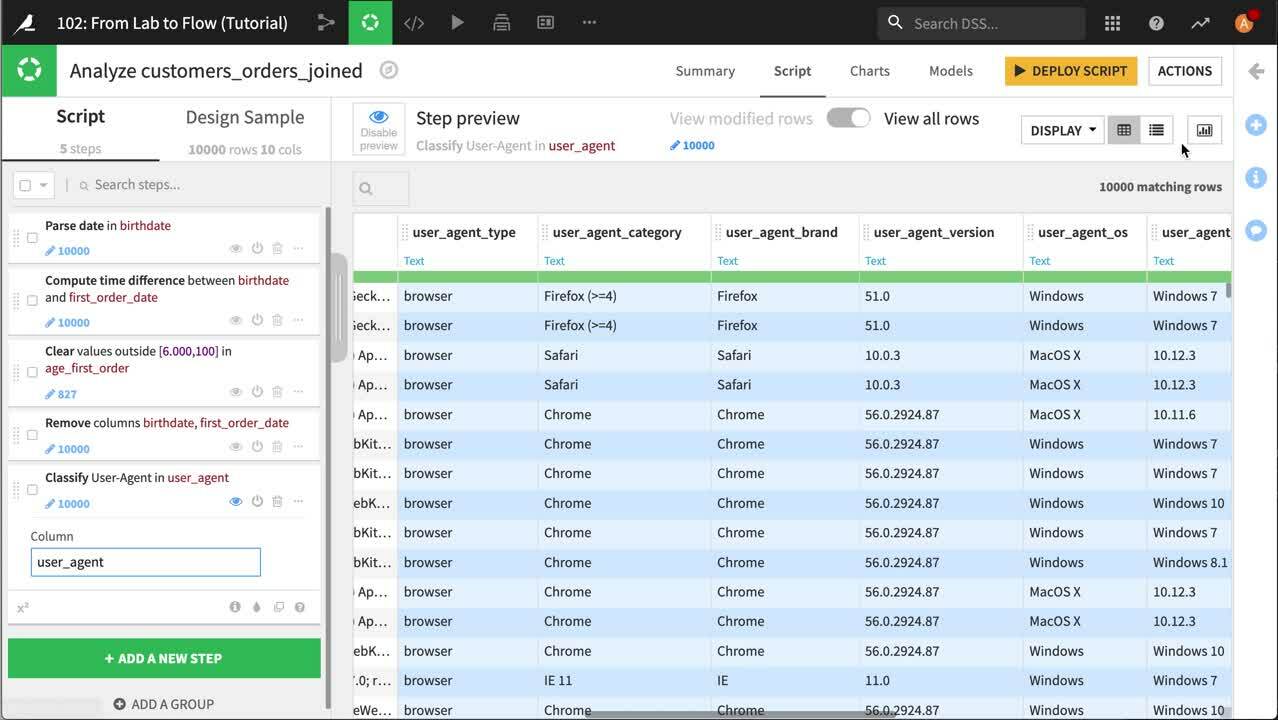
user_agent 列はブラウザと OS についての情報が入っています。また、この情報を別の列に取り出して、今後の解析で使えるようにしたいと考えています。
Dataiku は user_agent 列が ユーザー手段 についての情報を伝えることを認識しています。そのため列見出しのドロップダウンを開いて Classify User-Agent を選択するだけで済みます。 これにより、スクリプトを準備に新しいステップと、データセットに7つの新しい列が追加されます。 このチュートリアルでは、user_agent_brand のみ取り上げます。これはブラウザと OS を指定する*user_agent_os* を特定します。そのため不要な列は削除します。 Columns view アイコンをクリックして削除したい列を選択します。Actions ボタンをクリックし Delete を選択します。列のビューは簡単に複数の列を一度に消去できます。
The following video goes through what we just covered.
IP アドレスの活用¶
以下のビデオ でこのセクションの内容を説明します。
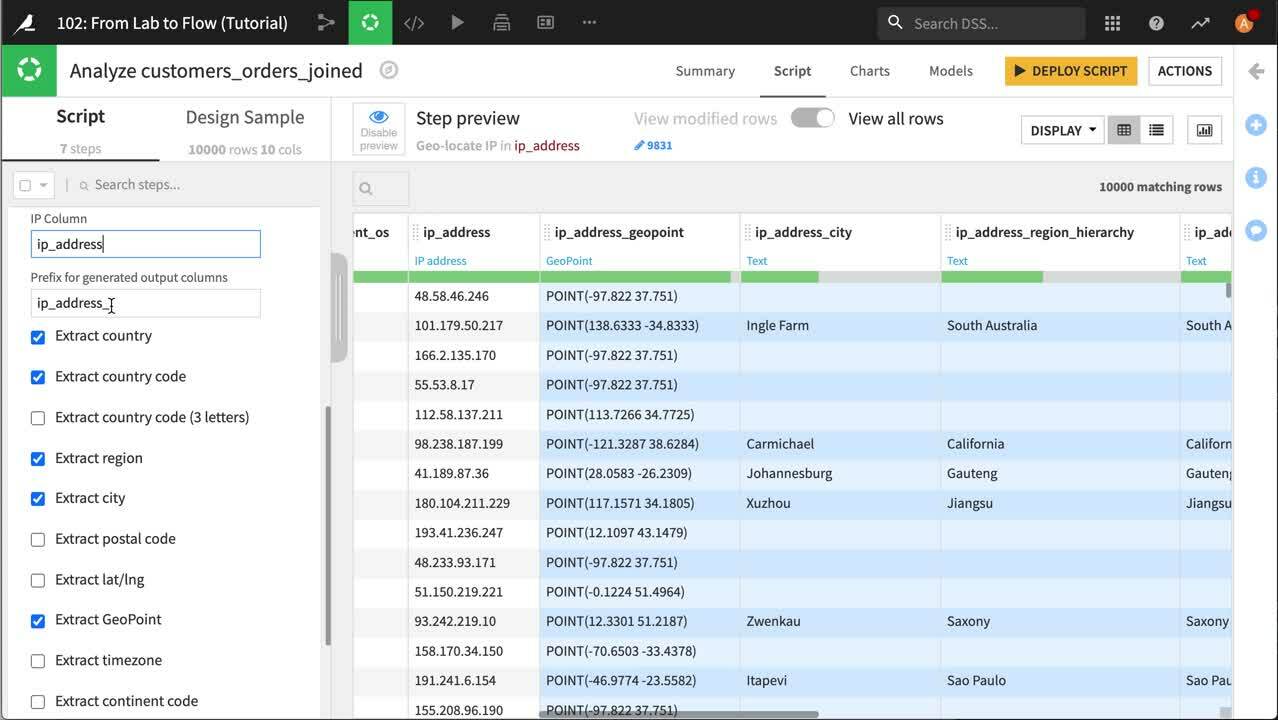
Dataiku は ip_address 列を`IP アドレス <https://en.wikipedia.org/wiki/IP_address>`_ の値を含むものと認識しています。そのため列見出しのドロップダウンを開いて Resolve GeoIP を選択できます。 これにより、スクリプトに新しいステップが追加され、データセットには各IPアドレスの一般的な地理的位置を示す新しい列が7つ追加されます。 このチュートリアルでは、私たちは国と GeoPoint (IP アドレスのおおよその経度と緯度) のみを取り上げます。そのため スクリプトステップでは、Extract country code、Extract region、**Extract city**の選択を外します。 最後に ip_address 列を削除します。
The following video goes through what we just covered.
ラベル列の作成¶
今度は多くの収益を生み出している顧客にラベルを作成します。
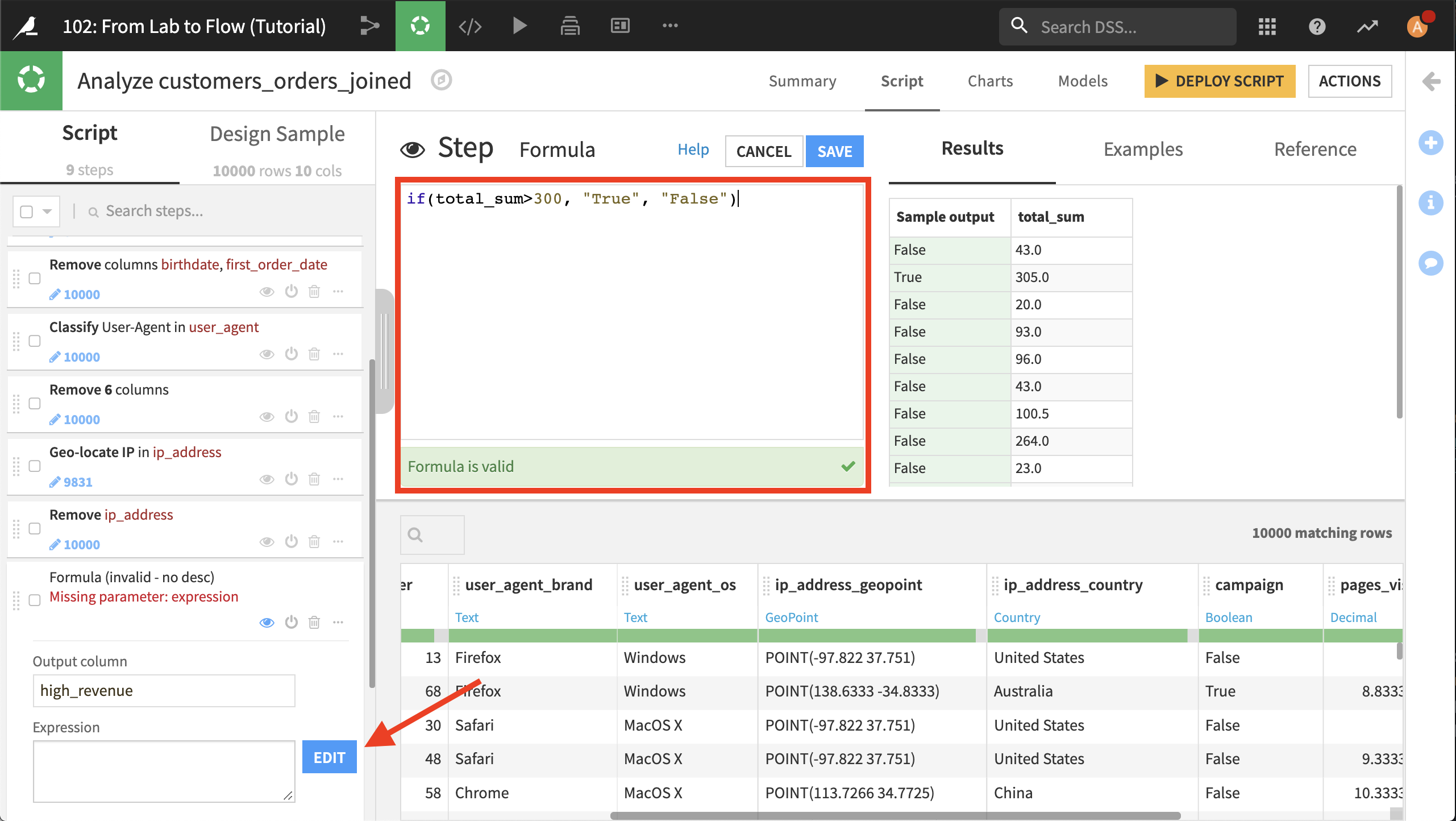
合計注文数が300を超える顧客を “high revenue” 顧客と見なしましよう。スクリプトの +Add a New Step をクリックし、Formula を選択します。出力列名として high_revenue と打ちます。 Edit ボタンをクリックし、エクスプレッションエディタを開きます。それから式として if(total_sum>300, "True", "False") と打ちます。 Dataiku が式を検証します。Save を押します。
Note
Formula Processor 用の構文は リファレンスドキュメンテーション にあります。
データをチャートでビジュアル化¶
以下のビデオ でこのセクションの内容を説明します。
ビジュアル化はデータを探索し、価値ある知見を得る鍵となることが多いため、ここでは豊富なデータ上にチャートをいくつか作成します。
解析の Charts タブをクリックすると、チャート作成用のビジュアル化画面が表示されます。
Note
Key concept: Charts in analysis
最初のチュートリアルでは、データセットのチャートをすでに使いました。ビジュアル分析でチャートを作成する場合、チャートは実際にビジュアル分析の一部として定義されている準備スクリプトを使います。
つまり、Script タブで新しい列の作成やデータのクリーンアップができます。またこの新しいデータやクリーンアップされたデータのグラフ化をすぐに Charts タブで開始できます。これにより、準備ステップの結果を表示するための非常に生産的で効率的なループが生まれます。
人気のあるユーザー手段¶
私たちは user_agent から顧客が使っているブラウザを抽出したので、最も人気のあるブラウザはどれなのか知りたくなるのは当然です。 それをビジュアル化する一般的な方法は、円グラフまたはドーナツグラフを使うことです。
チャートタイプツールをクリックします。Basics カテゴリで Donut を選択します。 By ボックスへ user_agent_brand を、また Show ボックスへ Count of records をクリックしてドラッグします。
The following video goes through what we just covered.
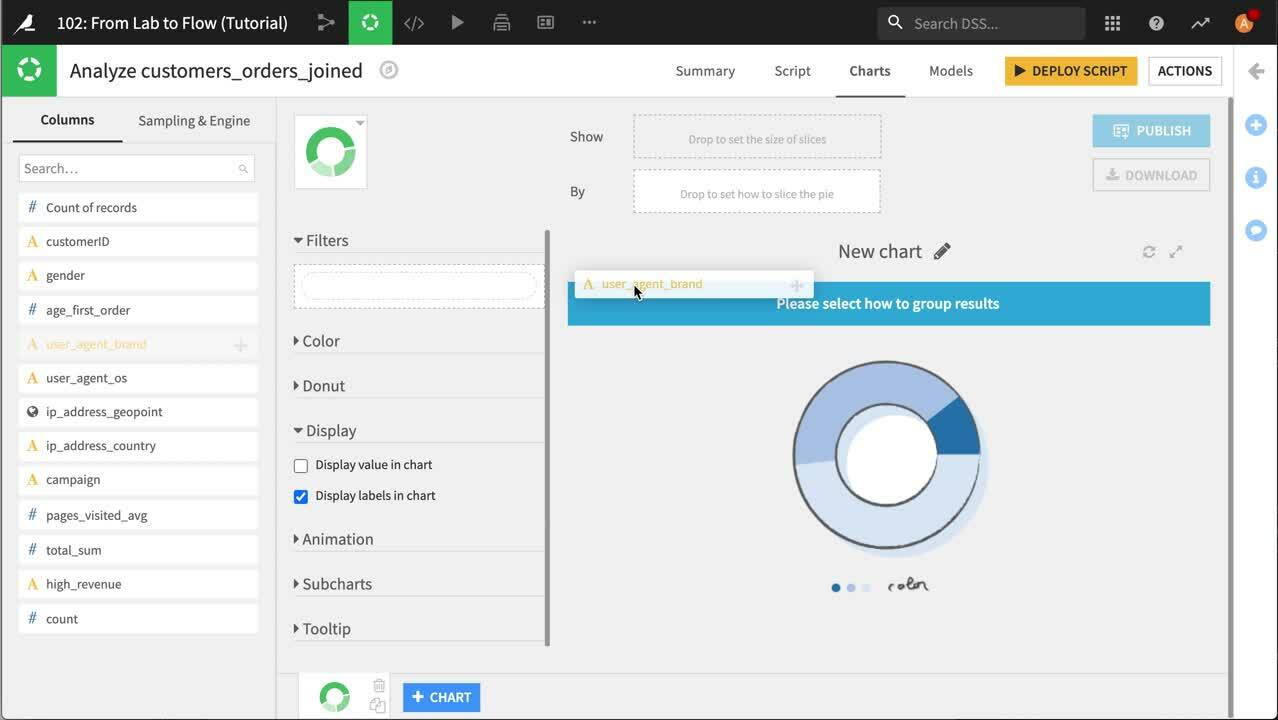
これは注文した顧客の 3/4 近くが Chrome を使っていることを示しています。 ドーナツグラフは各ブラウザの全体に対する相対的シェアをうまく示していますが、私たちはOSもビジュアル化に含めたいと考えます。
チャートタイプツールをクリックします。基本カテゴリで Stacked 棒グラフを選択します。 Count of records と user_agent_brand が自動で棒グラフに入ります。 And ボックスへ user_agent_os をクリックしてドラッグします。
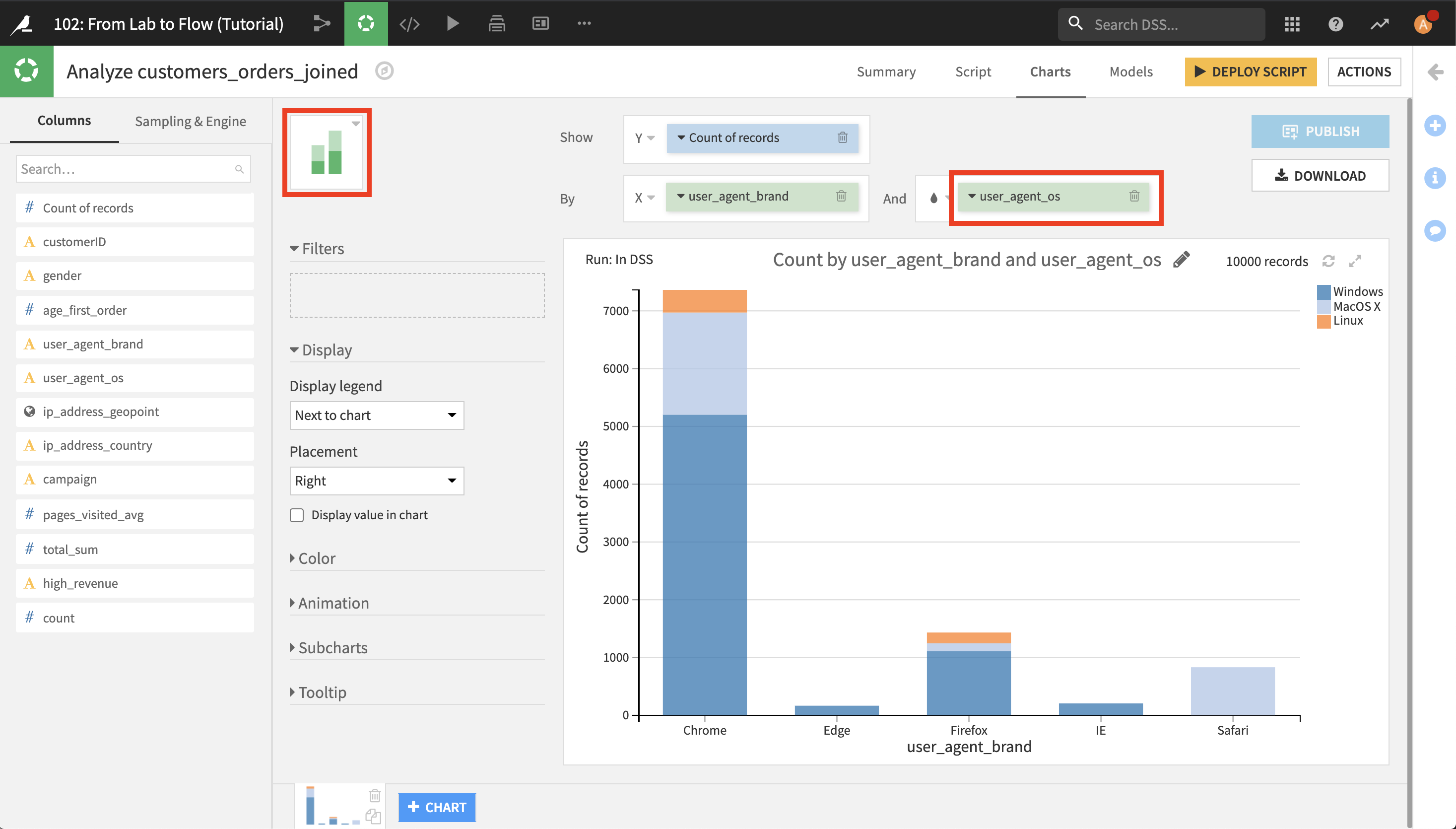
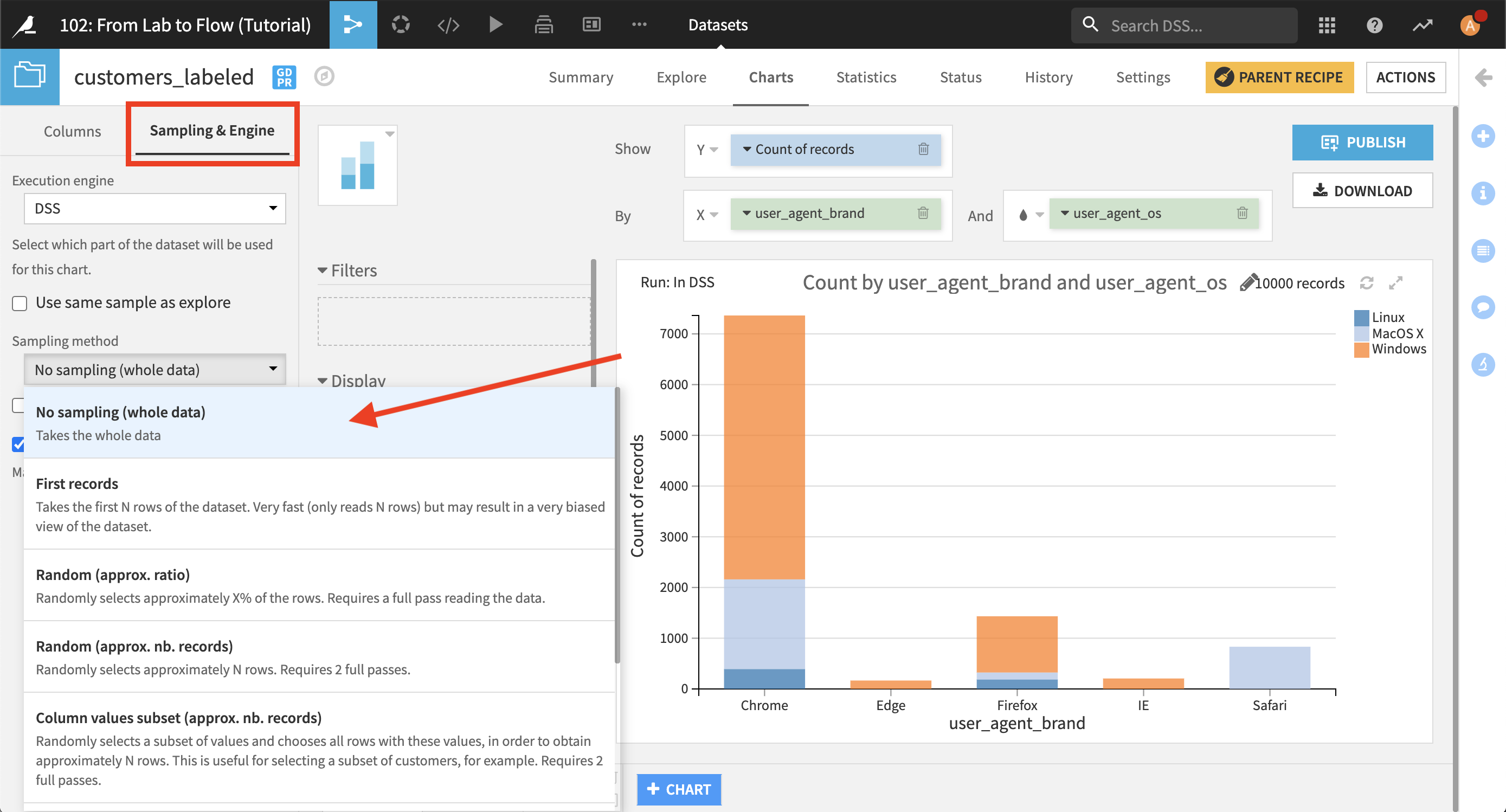
OSを追加するとより詳細にデータを把握できるようになります。 予想通り、IE と Edge は Windows でしか利用できず、Safari は MacOS のみの利用となっています。はっきりしているのは Safari と Firefox を合わせると MacOS で Chrome を使っている顧客数が約 2 倍になっていることです。 Linux 上での Chrome と Firefox の利用には類似の関係があります。
年齢とキャンペーンによる売上高¶
個々のデータセットでは得られなかったけれども Haiku Tシャツのデータを組み合わせることで得られる多くの知見があります。 まず、顧客の年齢、Tシャツキャンペーンに参加しているか、また支払金額に関係があるか見てみましょう。
以下のビデオ でこのセクションの内容を説明します。
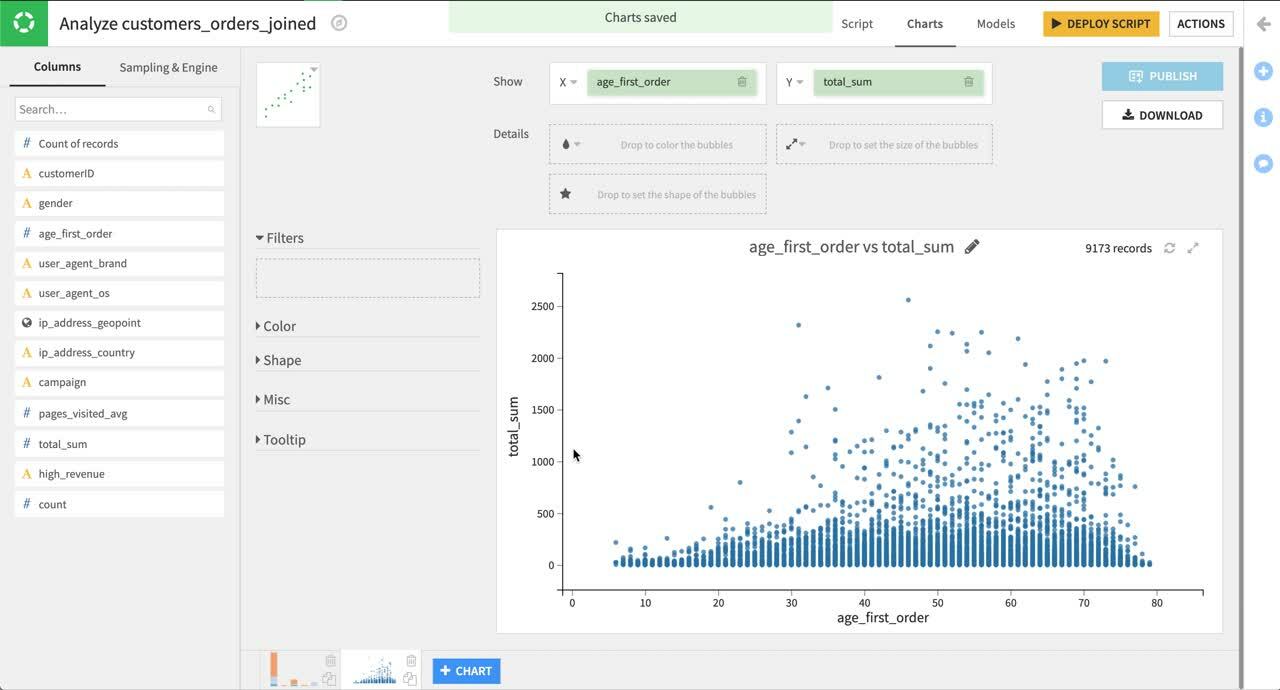
画面下中央の +Chart をクリックします。チャートタイプツールから Scatters カテゴリに移動し、Scatter Plot チャートを選択します。 X 列として age_first_order、Y 列として total_sum を選択します。 列として campaign を選択し、プロットのバブルに色を付けます。 列として count を選択しバブルの大きさを設定します。
デフォルトのバブルサイズは大きすぎるためバブルが重なります。 サイズのドロップダウンメニューで基礎円半径を 5 から 1 へ変更します。
散布図を見ると、年配の顧客やキャンペーンに参加している顧客が最もお金を使う傾向にあるとわかります。バブルの大きさを見ると、そこそこ価値のある顧客の中には、小さな買い物をたくさんした人や大きめの買い物をした人もいることがわかります。
The following video goes through what we just covered.
地域別で見る売上高¶
ip_address からロケーションを抽出したので、Haiku T-Shirt の顧客の出身地を知りたいと思うのは不自然なことではありません。 これはマップでビジュアル化できます。
以下のビデオ でこのセクションの内容を説明します。
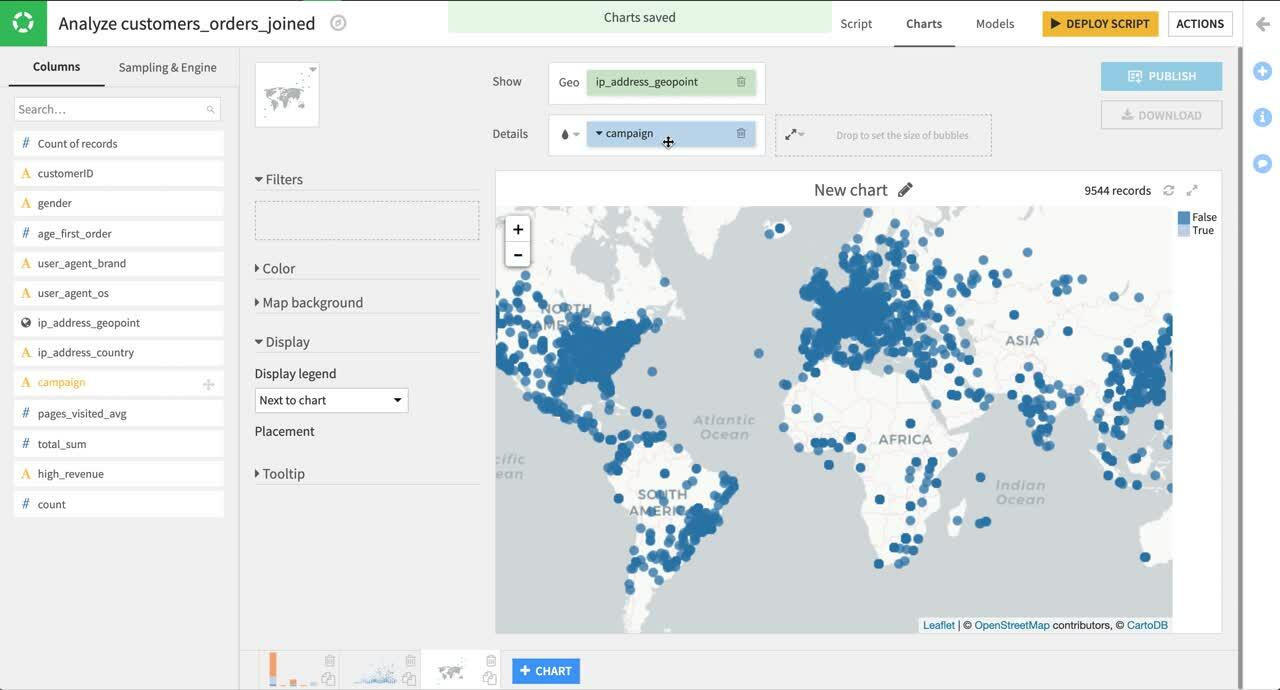
+Chart をクリックします。 Maps カテゴリと Scatter Map プロットを選択します。 ip_address_geopoint を Geo フィールドとして選択します。
これにより注文がどこからなされているかが一目でわかります。 注文合計に関する情報と T シャツのマーケティングキャンペーンに顧客が参加しているかどうかをマップに追加すると、データについてより多くの知識が得られます。
列として campaign を選択し、バブルに色を付けます。 列として total_sum を選択し、バブルの大きさを設定します。
デフォルトのバブルサイズは大きすぎるためバブルが重なります。 サイズのドロップダウンメニューで基礎円半径を 5 から 2 へ変更します。 この方がはるかに見栄えがよくどの顧客がどこにいるかすぐにわかります。
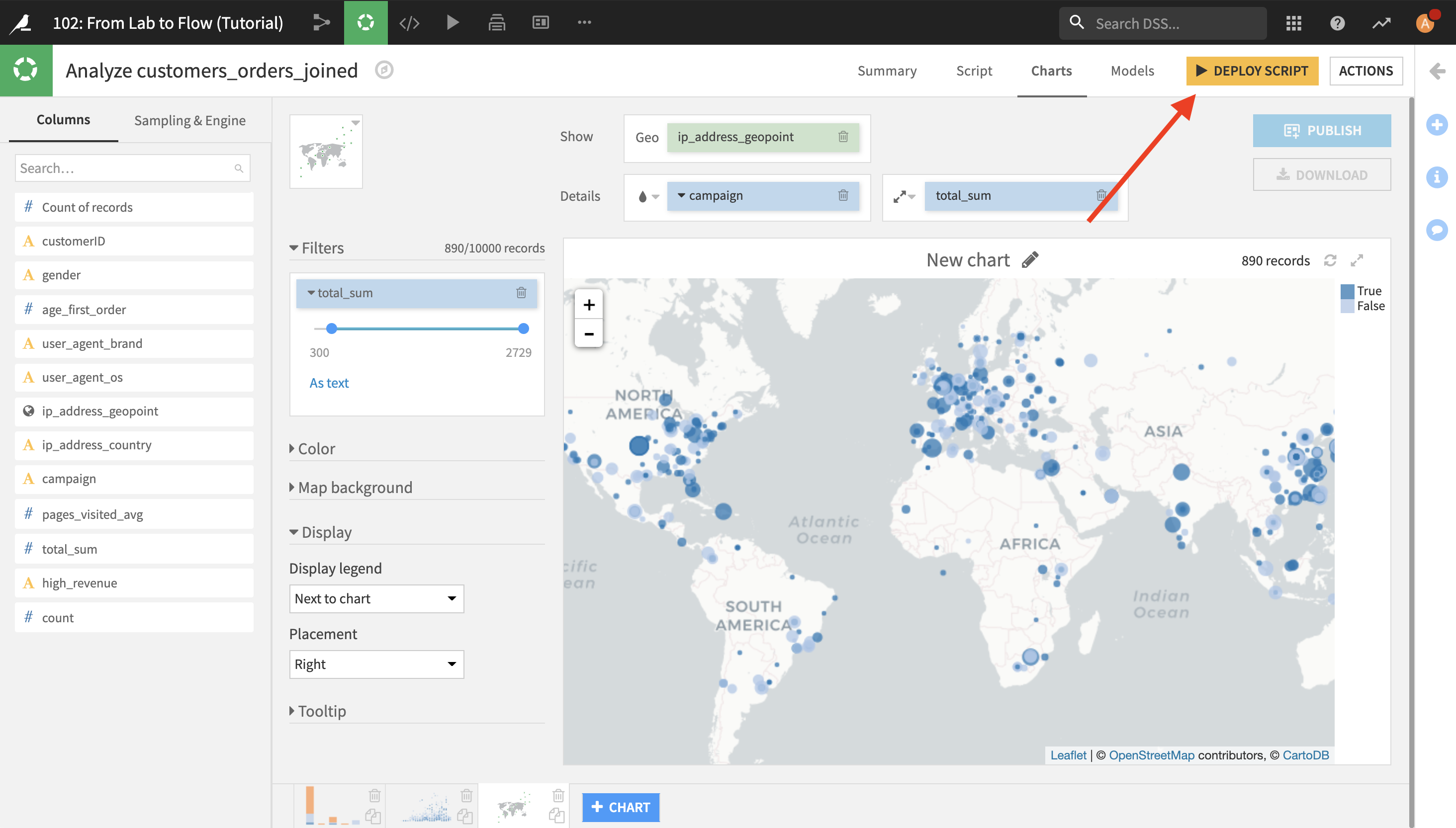
最大の売上高に注目したければ、total_sum を Filters ボックスにドラッグし、下限の値をクリックして編集し下限値として 300 と打ちます。 これにより、消費額が300未満の全顧客がマップからフィルタされます。
The following video goes through what we just covered.
分析でチャートを使う場合、チャートはデータの sample に基づいて作成されることにご注意ください。 左の Sampling and Engine パネルのタブでサンプルを変更できますが、DSS はそのたびに最新の準備を再適用する必要があるため、非常に大規模なデータセットではあまり効率的ではありません。
また、ダッシュボードで分析のチャートをチームと共有することはできません。ダッシュボードで共有できるのはデータセット上に構築されたチャートのみです。ビジネスに関する知見を得てチームと共有したい場合は、deploy your script をしてください。
フローにラボワークをデプロイ¶
あなたがこれまで行ってきた作業、つまりデータとチャートのクリーニングは、データのサンプルを使って行いました。それにより、Dataiku DSS は非常に反応性の高い対話性を提供できるようになりました。ラボで行った作業をフローにデプロイして、次のことができるようにするときがきました。
Dataiku はすべてのデータ準備を入力データセット全体に適用し、結果データを新しいデータセットに保存します。
新しく作成されたデータセット(およびそのビルドレシピ)は、将来簡単に再構築できるように、フロー系統に追加されます (例: 入力データが変更された場合)。
以下のビデオ でこのセクションの内容を説明します。
これを行うには、画面の右上隅に移動して Deploy Script をクリックします。
スクリプトをPreparation Recipeとしてデプロイするためのポップアップが表示されます。 デフォルトでは、ラボで作成されたチャートは新しいデータセットに引き継がれるため、サンプルではなく出力データ全体でグラフを閲覧できます。 出力データセットの名前を customers_labeled に変更します。
Deploy をクリックしてレシピと出力データセットを作成します。 レシピを保存しフローに移動します。 たった今ラボから展開した準備レシピと新しい出力データセットを閲覧できます。
フロー内のデータセットのアイコンは、空であることを示すためにアウトライン化されます。これはあなたが、完全な出力データセット構築のためのレシピをまだ実行していないためです。 データセットを選択し、Action パネルで Build をクリックします。するとダイアログが開き、このデータセットのみを構築 (非再帰) するか、このデータセットにつながるデータセットを再構築するか (再帰) を尋ねます。 入力データセットは最新のため非再帰型で十分です。 Build Dataset をクリックします。
ジョブが完了したらデータセットを開きます。準備スクリプトが全データに適用されました。
データセット全体を使うために積み上げ棒グラフを構成しましょう。Charts タブに移動し Sampling & Engine をクリックします。Use same sample as explore のチェックを外します。 サンプリングメソッドとして No sampling (whole data) を選択します。Save and Refresh Sample をクリックします。
Note
Chart Engines and Sampling
チャートを表示するため、DSS は表示する値を計算する必要があります。計算はエンジンが行います。データセットの種類に応じて、さまざまなエンジンを複数使えます。
DSS はデフォルトでビジュアル化のパフォーマンス向上のためデータを前処理する組み込みエンジンを使います。この組み込みエンジンは数百万レコードまでのデータセットに対し効率的です。
巨大なデータセットを処理するときは、DSS がこれらの計算をすべて外部の処理エンジンにプッシュダウンできるようにデータセットを保存することをおすすめします。これは、データセットが stored in a SQL database または Impala や Hive が使える場合です。データベース内チャート作成についての詳細情報は 抜取りデータと全データ をご覧ください。
The following video goes through what we just covered.
もっと知る¶
おめでとうございます。現在*orders* と customers データセットが結合されました。顧客価値の予測モデルを構築する準備ができたのです。
チュートリアル: 機械学習 に進んでそのやり方を学びましょう 。