機械学習モデルのスコアリング¶
本書は:doc:`チュートリアル:機械学習 <../machine-learning/index>`のパート 2 です。 本書は、パート 1 で終わったところからの続きですので、お読みになる前に、必ずパート 1 を完了したか確認してください。
パート 2 では、予測モデルを使って新しいレコードをスコアリングする方法について学習します。
以下のステップについて網羅します。
フローにモデルをデプロイする
このデプロイされたモデルを使って、別のデータセットからのレコードをスコアリングする
このワークフローで Dataiku DSS によって使用されているさまざまなコンポーネントを理解する
それでは始めましょう!¶
パート1では、既に弊社でその過去の長期的な行動を観測したことのある顧客の “high revenue potential” を予測するようにモデルをトレーニングしました。これらは customers_labeled データセットに保管されました。
今回は、初回購入した新規顧客に関して、今後彼らが高収益をもたらす顧客になるかどうかを予測したいと思います。これが customers_unlabeled_prepared データセットです。このデータセットには、まだこれらの顧客が高収益をもたらす顧客になるかどうかの兆候は示されていません。
前提条件¶
始めに、`チュートリアル:機械学習 <../machine-learning/index>`プロジェクトのドキュメントに戻りましょう。フローに移動し、customers_labeled データセットをクリックして、LAB ボタンをクリックします。
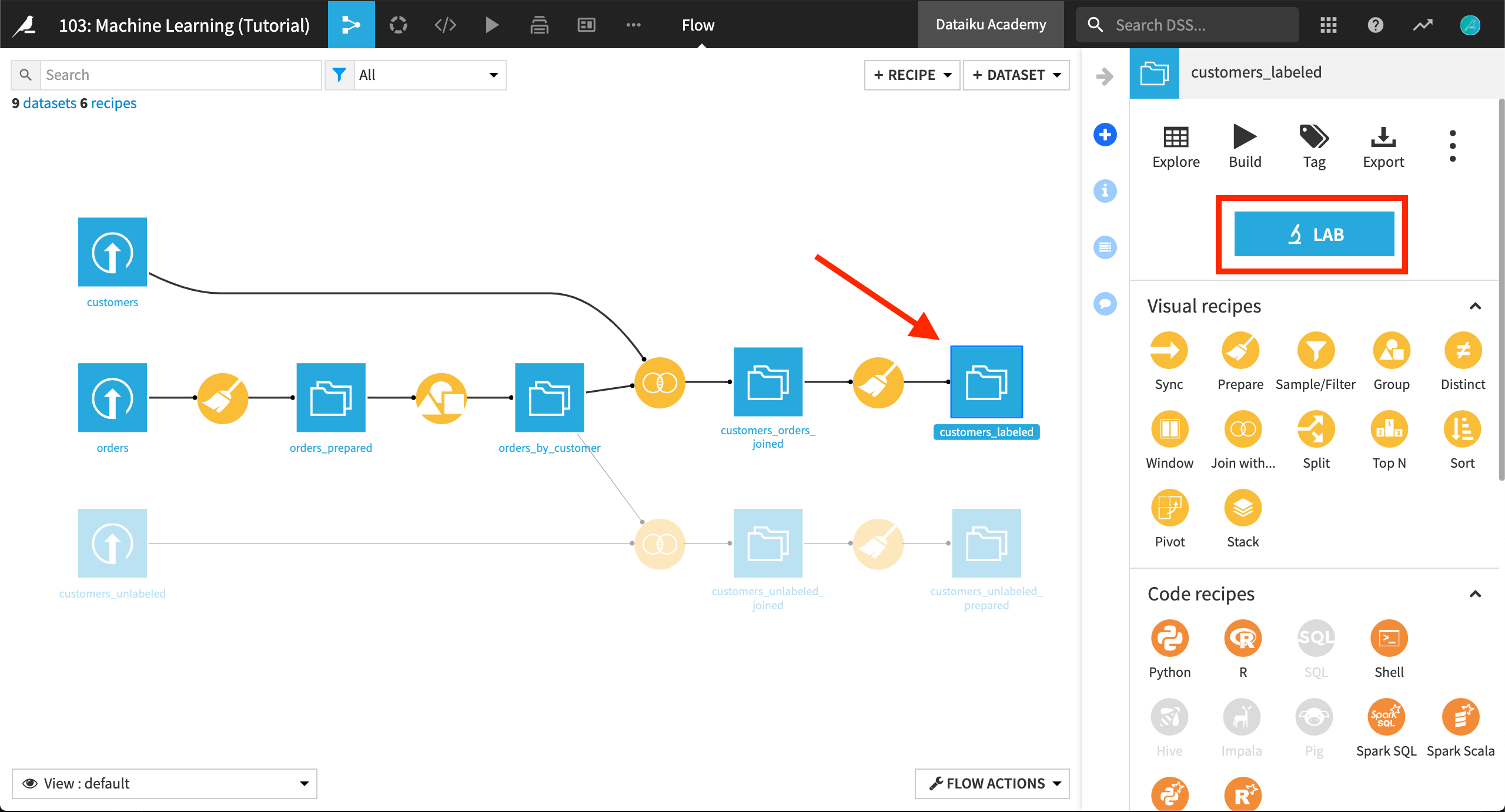
Visual Analysis Lab は、`パート1 <../machine-learning/index>`ドキュメントの最後にやったところまでのままになっており、対応する空の Script があります。 Models タブを開くと、前回トレーニングした6つのモデルが見えるはずです。ご自分の最良のモデルをクリックしてください – 最後のランダムフォレストです。
The following video goes through what we just covered
Note
Naming and describing models
メイン Results ビューから、モデルを “star” することができます。 特定のモデルの個別のサマリの中に入ると、ユーザーは、モデル名を編集して、モデルの説明を入力できます。このように自分の最良のモデルを文書に記録しておくことで、他の人にも検索可能にして、もっと簡単に理解できるように支援できます。
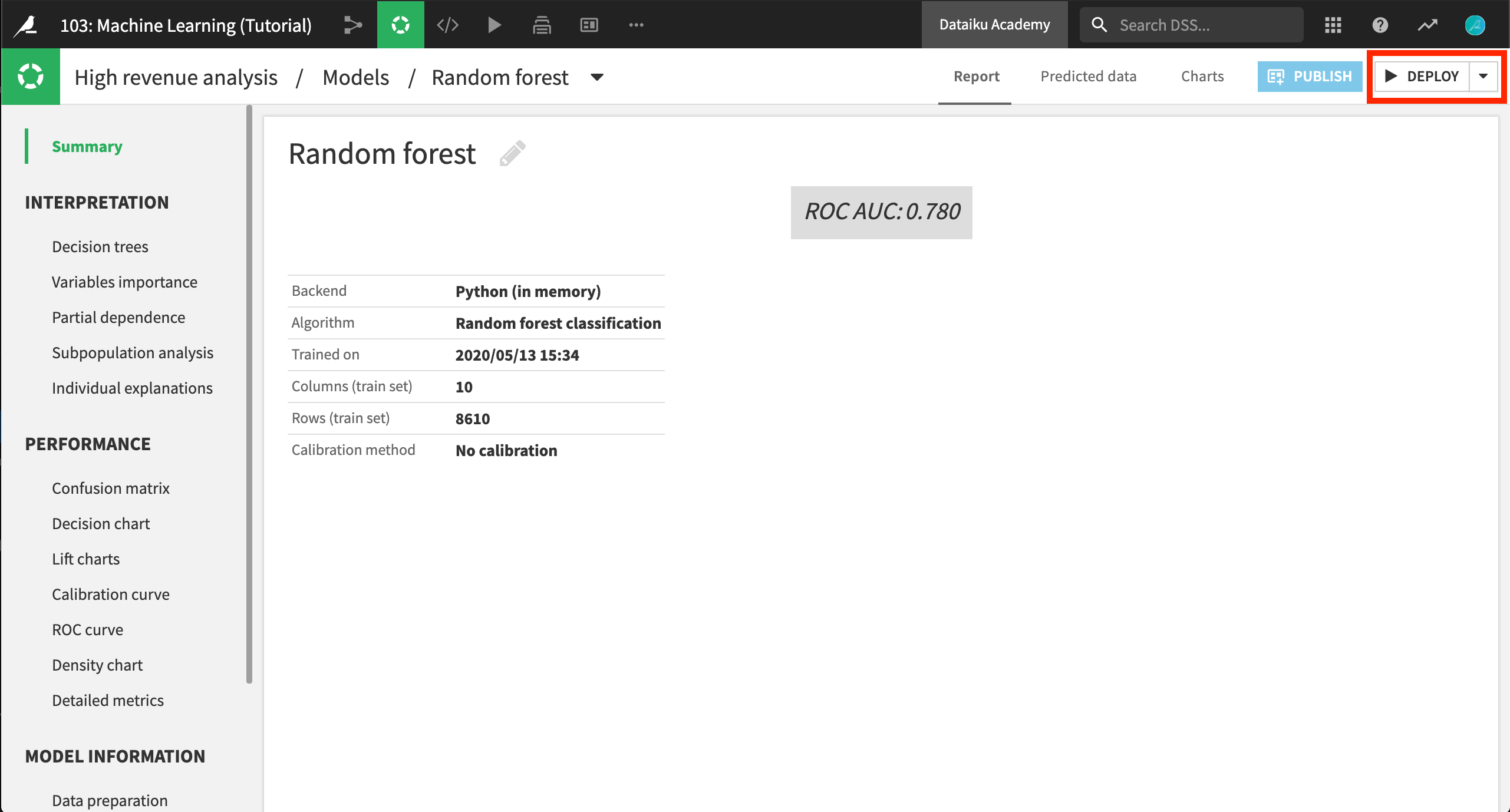
モデルのデプロイ¶
では、これからこのモデルをフローに deploy*します。このフローでは、このモデルを使って別のデータセットを *score*できます。右上の **Deploy* ボタンをクリックします。
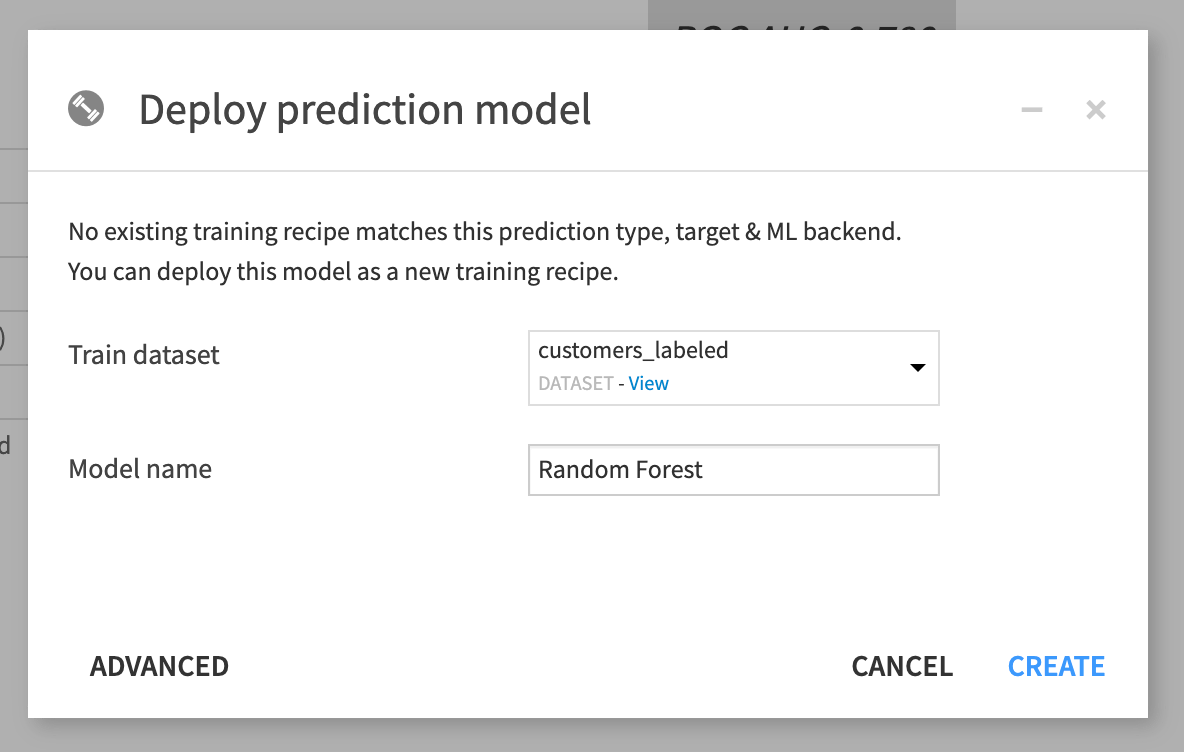
新しい重要なポップアップが表示されます。このポップアップを使って、新しい **Train recipe**を作成できます。Dataiku DSS では、トレーニングレシピとは、フローにモデルを自動的にデプロイするための方法です。このフローで、ユーザーはこのモデルを使って新しいレコードに関する予測を生成できます。
この演習では多くのモデルをデプロイしないので、モデル名をもっと管理しやすい Random Forest に変更して、Create ボタンをクリックしましょう。
するとまたフローに戻ります。2つの新しい緑色のアイテムが表示されています。1つ目のアイテムは実際の train recipe で、2つ目のアイテムは、そのアウトプットである *model*です。モデルアイコンをクリックして、右側のパネルを見て下さい。
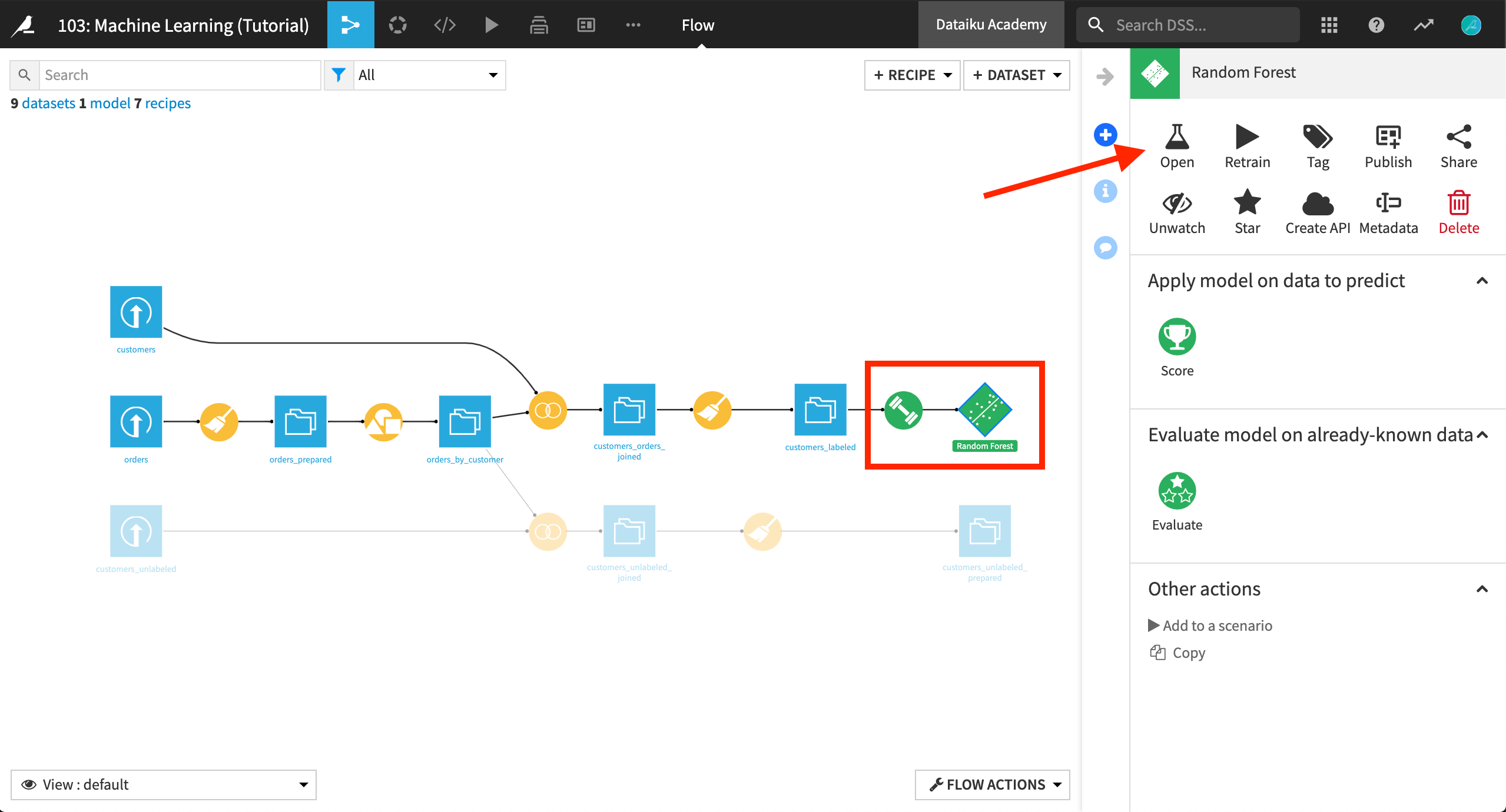
このパネルでは、いくつかの興味深い機能にアクセスできます。Open**を選択すると、ビューにリダイレクトされます。これは、以前の分析ベンチの **Models ビューに似ていますが、異なるのが、ユーザーがデプロイすることを選択したモデル(ランダムフォレスト)だけにフォーカスしていることです。
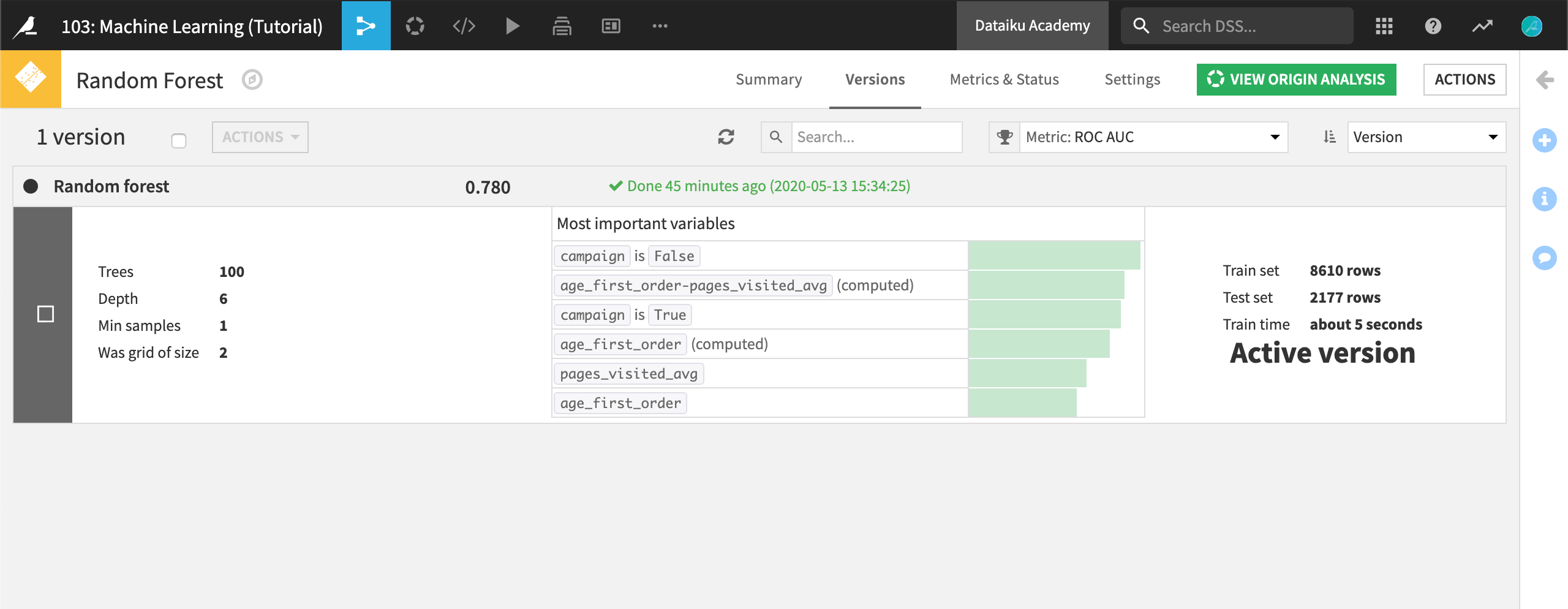
このチュートリアルではあまり詳細には踏み込みませんが、モデルが Active version**とマーキングされていることに注目してください。データが時間とともに進化することが見込まれる場合(現実にはその可能性は非常に高いでしょう!)には、この画面から自分のモデルを *train again*ことができます。(**Actions をクリックして、次に Retrain をクリックしてください。)この場合、モデルの新しいバージョンが入手可能になり、ユーザーは、自分の使用したいモデルのバージョンを選択できます。
フローに戻って、モデルアウトプットのアイコンをクリックしてください。 Open ボタンの近くに、**Retrain**ボタンが見えるはずです。これは、前述した機能へのショートカットです。ユーザーは、新しいトレーニングデータでモデルを更新して、新しいバージョンを有効化することができます。
最後に、Score が、このモデルを使用するために私たちが探している目的のアイコンになります。
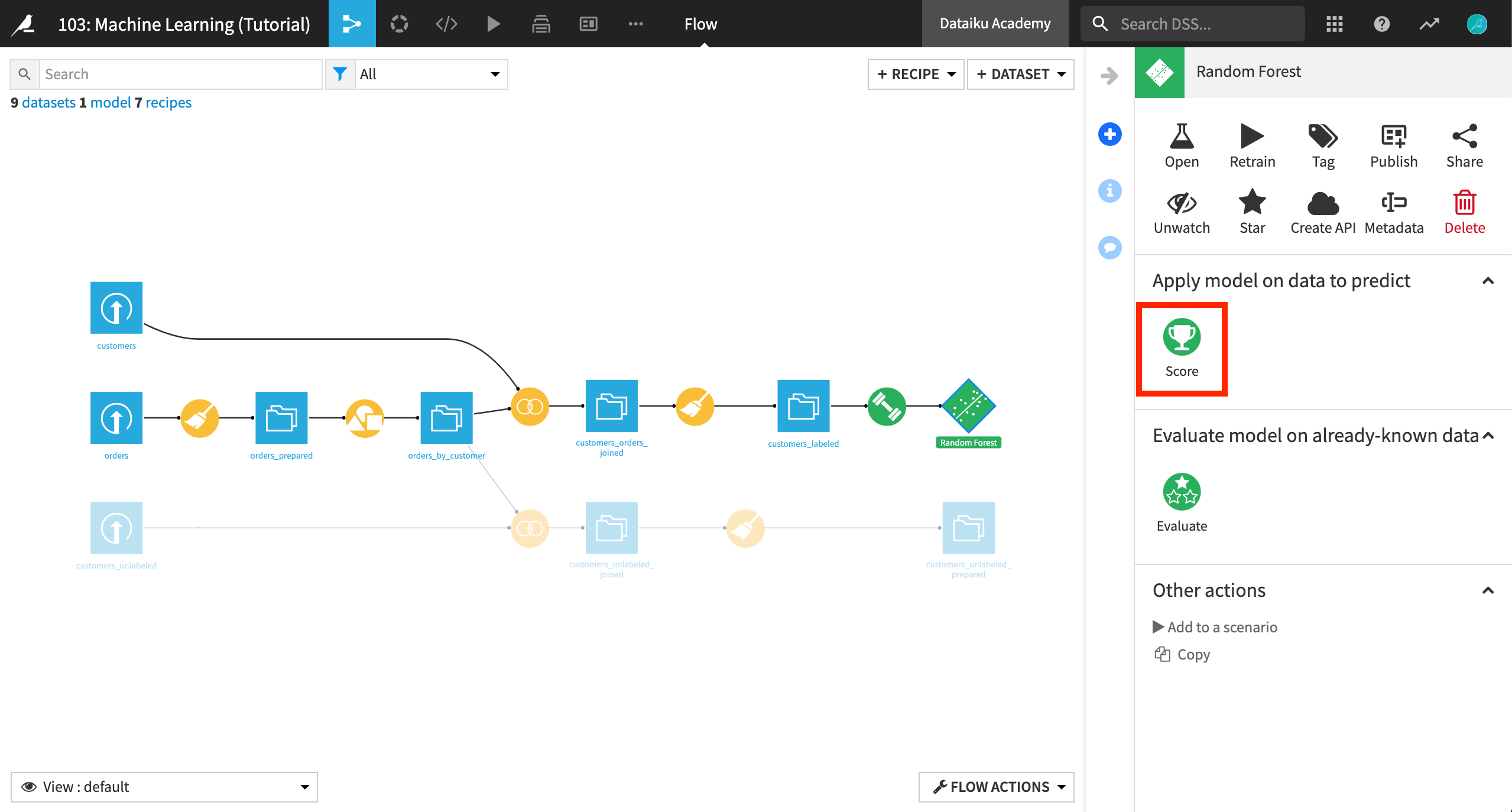
これをクリックすると、ポップアップウィンドウが表示されます。これは、以下のようないくつかの設定を行う画面です。
スコアリング対象のデータセット(customers_unlabeled_prepared)
使用する予測モデル(既に選択済み)
アウトプットデータセットの名前(
customers_unlabeled_scored)結果情報を保管するために使用する接続
これらの値を入力してから、Create recipe ボタンを押してください。
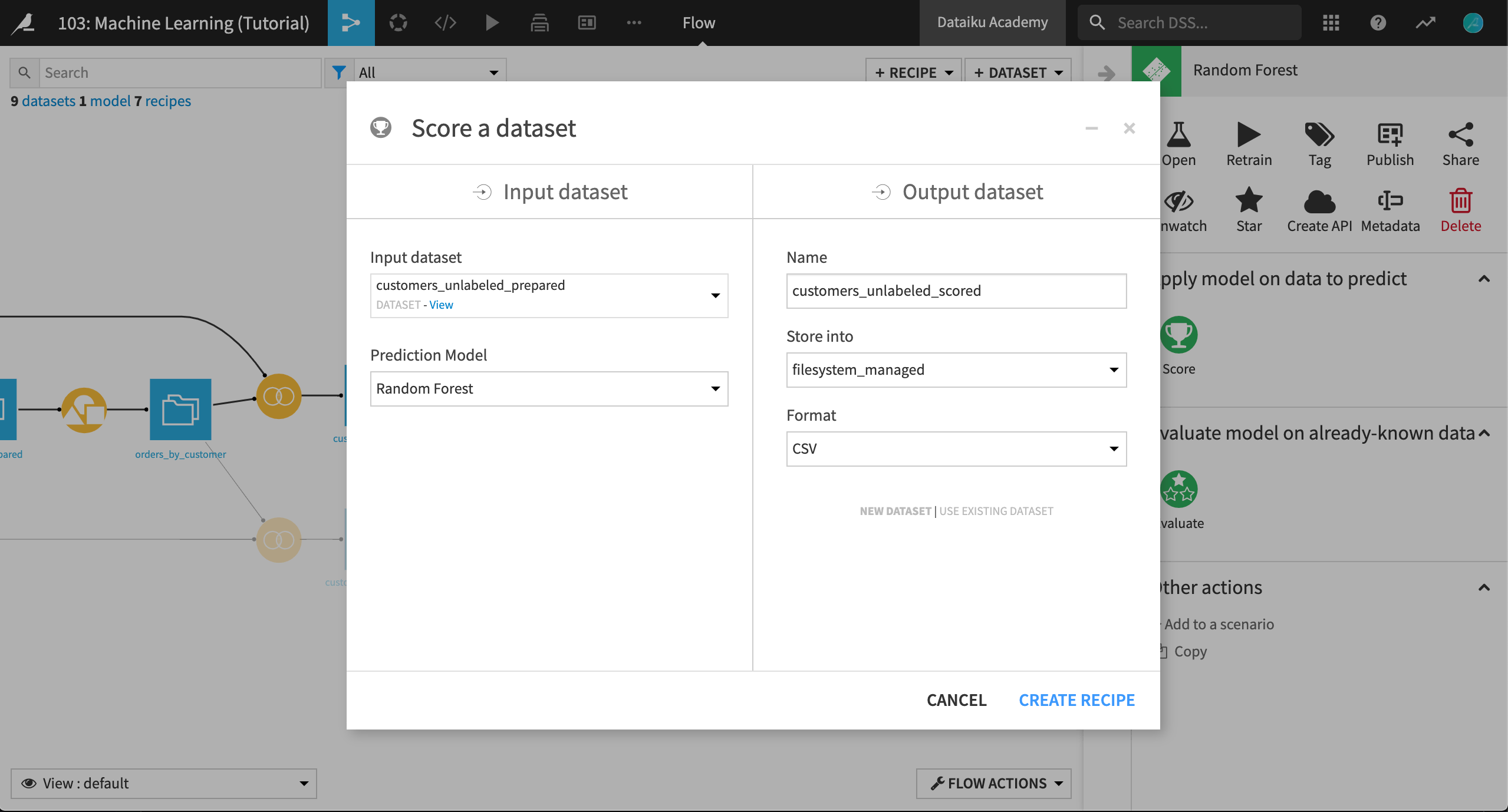
すると、**Scoring recipe に入ります。
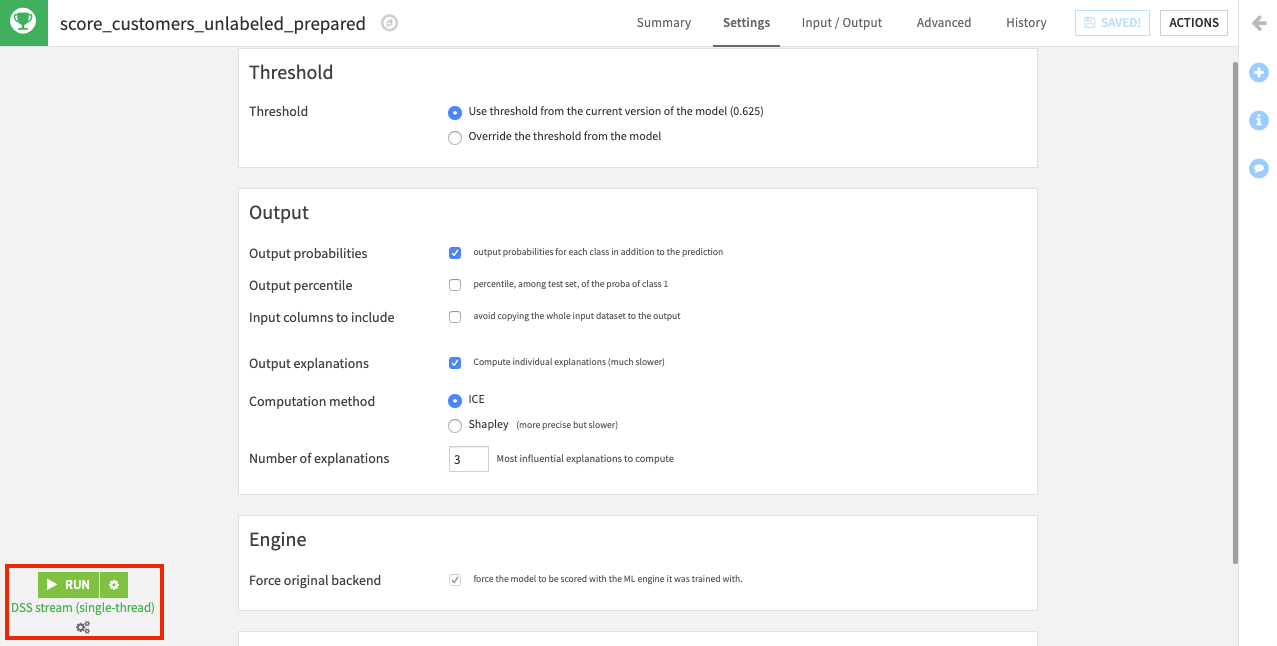
閾値は、所定のメトリックを最大にするために計算された最適値です(:doc:`パート1 <../machine-learning/index>`に記載)。この場合、0.625 に設定されました。閾値を超える確率値を含む行は、高価値として分類され、閾値に満たない行は、低価値として分類されます。
customers_unlabeled_prepared データセットの各行の予測に関する個別の説明に戻りたい場合は:
“Output explanations” のチェックボックスをクリックしてください。このアクションにより、”Force original backend” オプションが有効化されるので、モデルは、そのトレーニング中に使用された機械学習エンジンを使ってスコアリングされることが可能になります。また、”Output explanations” チェックボックスを有効化すると、いくつかの追加のパラメータも表示されます。
“Computation method” には “ICE” を選択してください。
“Number of explanations” には
3を指定してください。これは、各行に関して、最も影響力のある3つの機能の貢献度を返します。
最後に、左下の Run ボタンをクリックして、データセットをスコアリングしてください。
数秒後、Job succeeded と表示されるはずです。
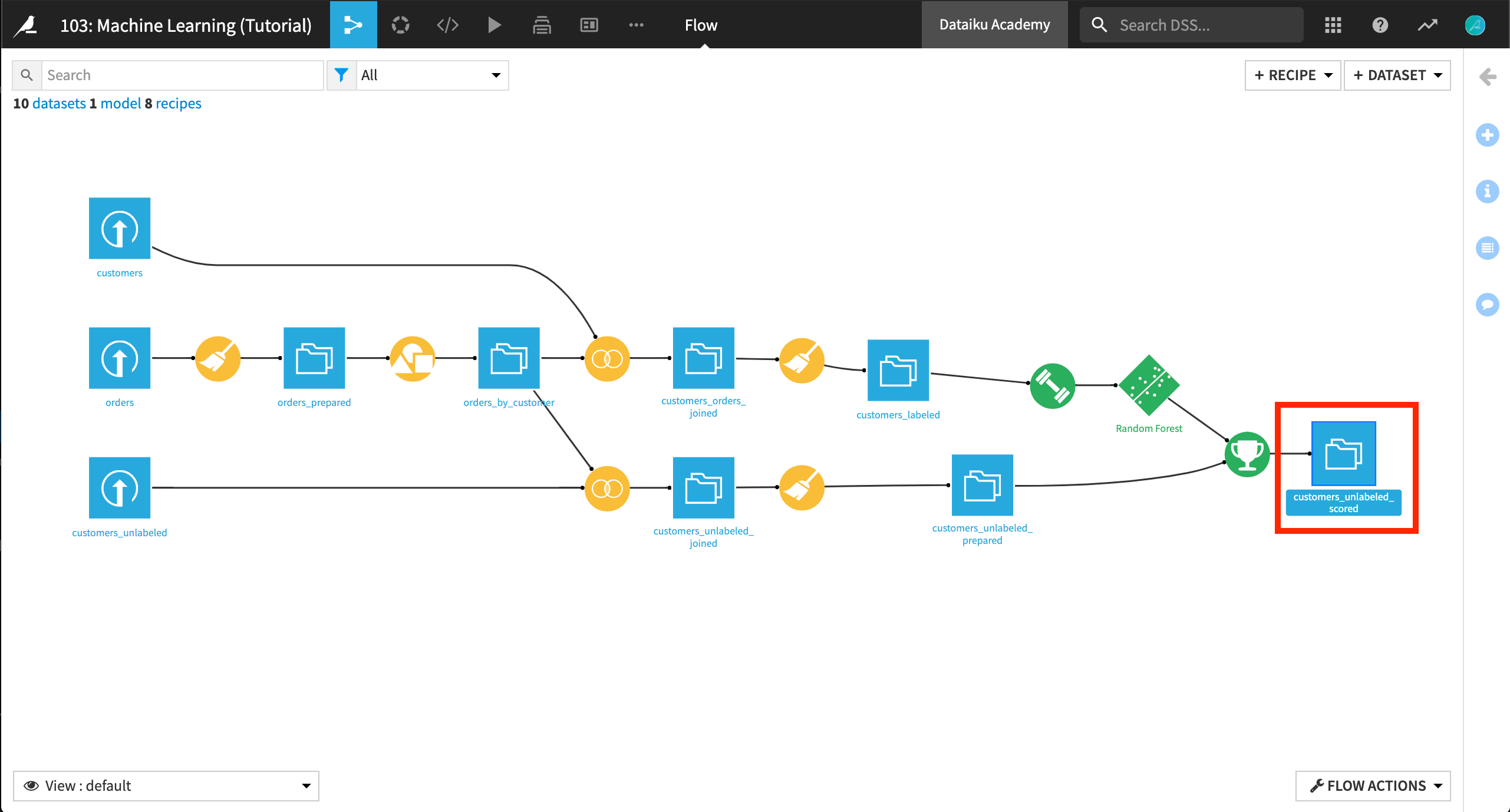
Flow 画面に戻って、自分の最終ワークフローを視覚化できます。まとめると、ユーザーが実施する手順は次のとおりです。
“history data”から開始します。
トレーニングレシピを適用します。
トレーニングされたモデルを取得します。
このモデルを適用して、ラベル付けされていないデータセットに関するスコアを取得します。
スコアリングされた結果の取得¶
あと少しで完了です!customers_unlabeled_scored データセットを開いて、スコアリングされた結果がどのように表示されているか確認してください。
データセットには、次の4つの新しい列が追加されました。
proba_False
proba_True
prediction
explanations (スコアリングレシピの中で要求されたとおり)
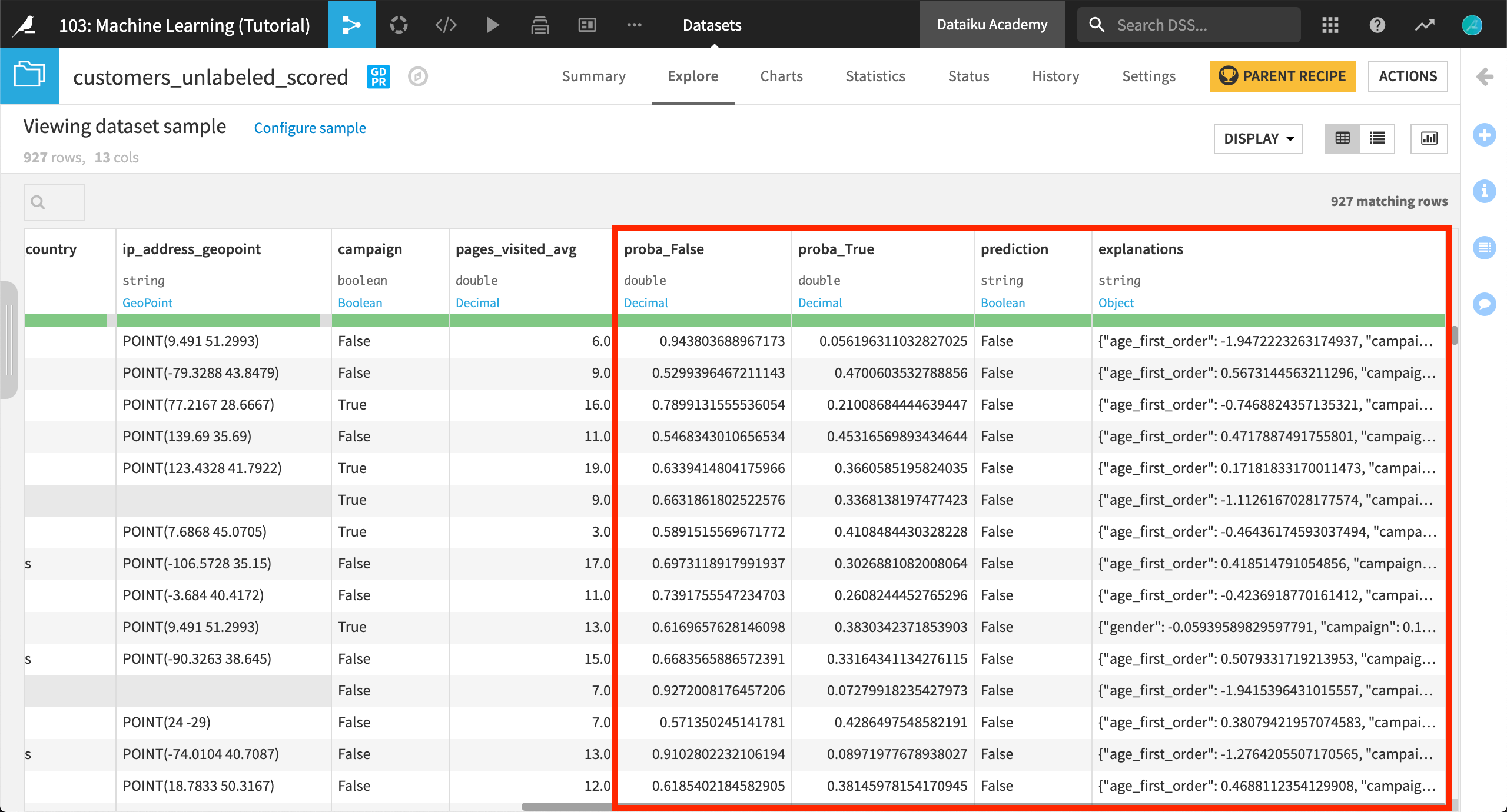
特に興味対象となるのが2つの “proba” 列です。モデルは、2つの確率を提供します。これはすなわち、0 ~ 1 までの値であり、高価値顧客 become*可能性(*proba_True)と、高価値顧客*not become*逆の可能性(proba_False)を測定します。
prediction*の列は、確率およびスコアリングレシピの閾値に基づく決定です。 *proba_True 列が閾値を超えた場合(この場合 0.625)、DSSはこれを prediction “True” とラベル付けします。
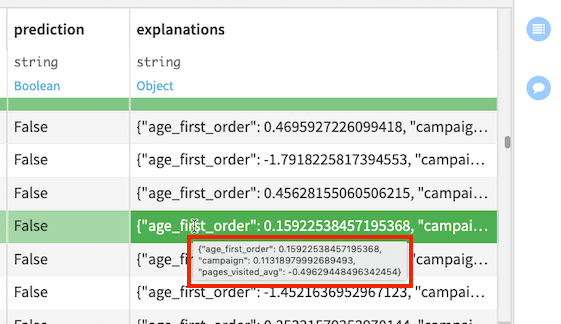
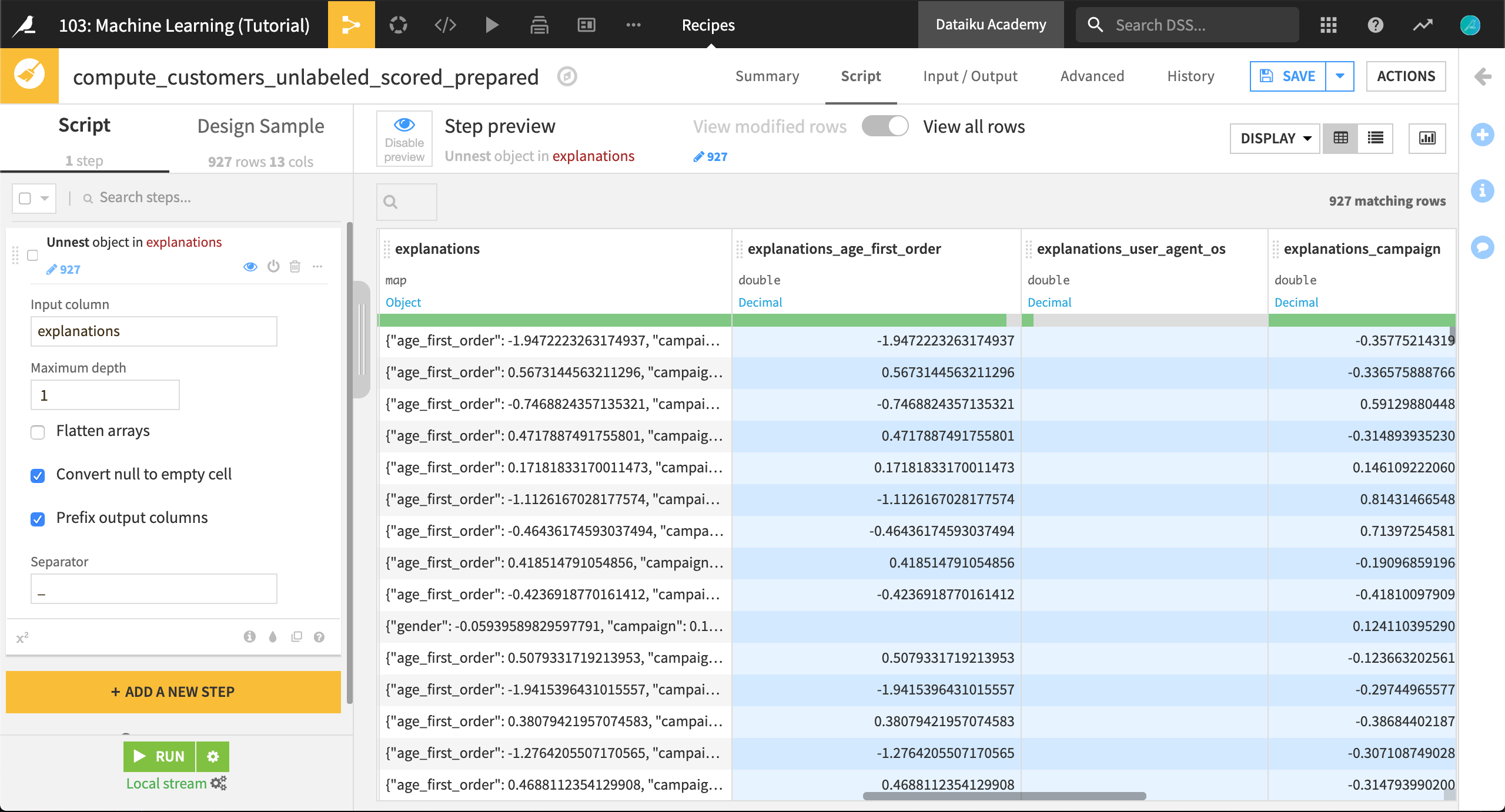
explanations 列には、フィーチャを key、そしてその正または負の影響を value としたJSONオブジェクトが含まれています。例えば、下図でハイライトした行は、この行に最も影響力のある3つのフィーチャ(age_first_order、campaign、pages_visited_avg)と、これらのフィーチャの、それぞれ対応する予測結果への貢献度を示しています。
ユーザーは、この列のJSONデータをもっと容易に処理できるように、customers_unlabeled_scored データセットに関する Prepare(準備)レシピを作成できます。このレシピの中で、explanations 列に Unnest object (flatten JSON) プロセッサを適用してください。
個々の予測の説明の詳細については、`参考ドキュメント <https://doc.dataiku.com/dss/latest/machine-learning/supervised/explanations.html>`_を参照してください。
もっと知る¶
以上です!これで、みなさんの初めての予測モデルをビルドして、その結果を分析し、モデルをデプロイするための十分な知識を習得できました。これらは、もっと複雑なアプリケーションに向けての第一歩です。