
Tutorial | Smart pattern builder for string pattern extraction#
Regular expressions, or regex, are character sequences arranged in a pattern. They can be useful for finding, extracting, and managing sets of strings in a dataset that correspond to a specific pattern.
To use them, however, one needs to craft the exact expression that will extract all the matches (and only those matches) that correspond to a pattern.
Dataiku’s smart pattern builder makes it easier to formulate regular expressions by dynamically generating suggested regular expressions based on text selections you provide in the interactive tool. Let’s see how it works in practice.
Prerequisites#
Some familiarity with basic data preparation in Dataiku.
Dataiku 9.0 or later.
Download this CSV file of airline reviews and upload it to any Dataiku project.
Detect regex patterns automatically#
The goal is to identify rows that mention Boeing plane models. A neat categorical column of plane models doesn’t exist. Therefore, let’s use a regular expression to find any mentions of Boeing models. Once you’ve extracted this pattern, you can filter for these rows.
Upload the airline_reviews CSV file into a Dataiku project.
From this dataset, create a Prepare recipe.
Drag to expand the width of the content column, which contains the natural language data, so that Boeing 787 is visible in the first row.
Assuming you don’t know exactly what regular expression to write to capture all possible variations of Boeing models, let’s use the smart pattern builder.
In the first row of the content column, find
Boeing 787, and highlight it.From the displayed options, select Extract text like Boeing 787.
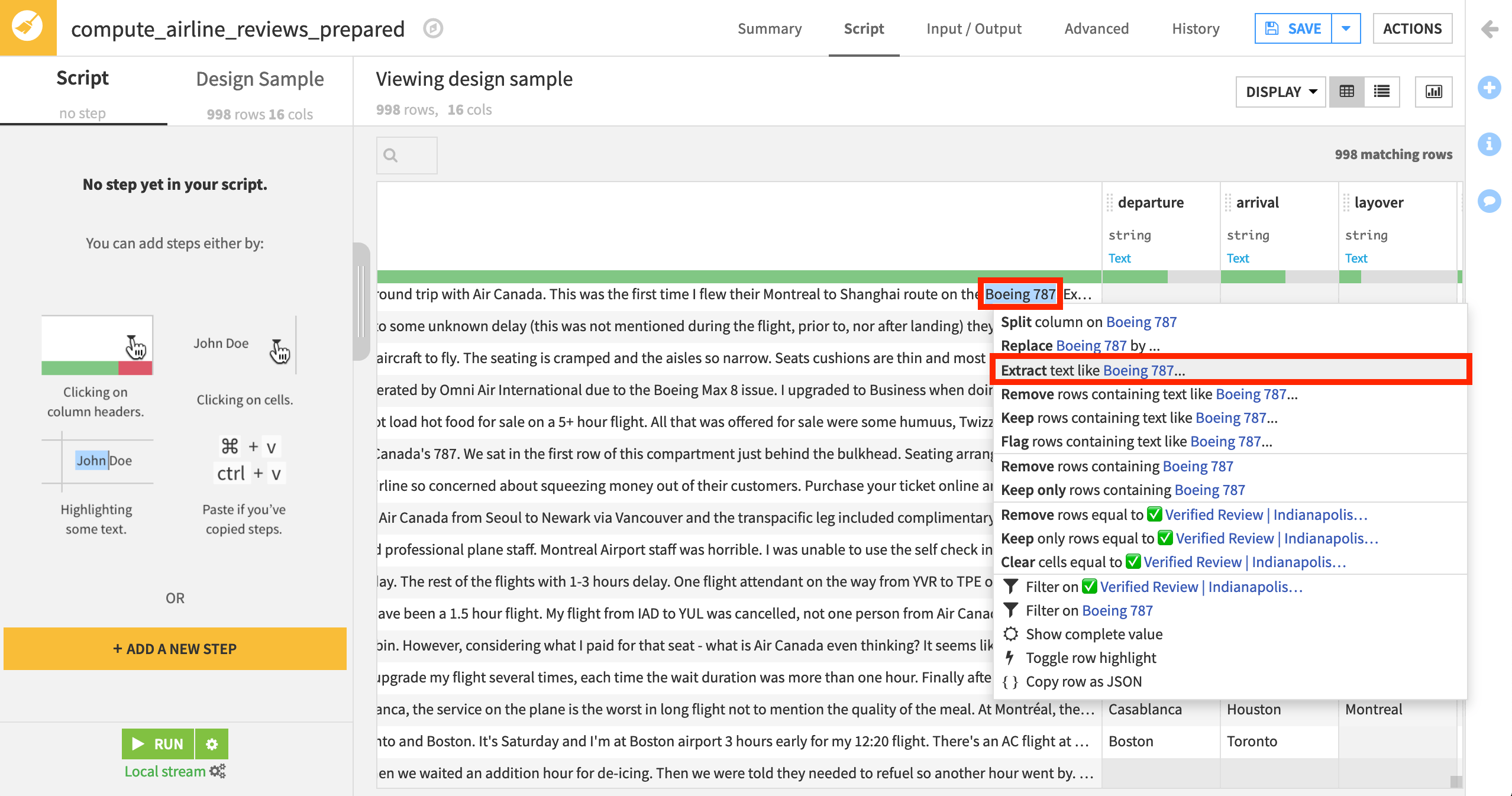
Note
Another way to create the same step would be to add an Extract with regular expression step from the processor library. Choose a column, and then select Generate with Smart Pattern.
The smart pattern window pops open. Under Detected patterns, it displays a list of suggested regular expressions based on the current selections. From just this one selection, however, the first suggestion is too broad. It only matches some amount of characters before the number ‘787’.
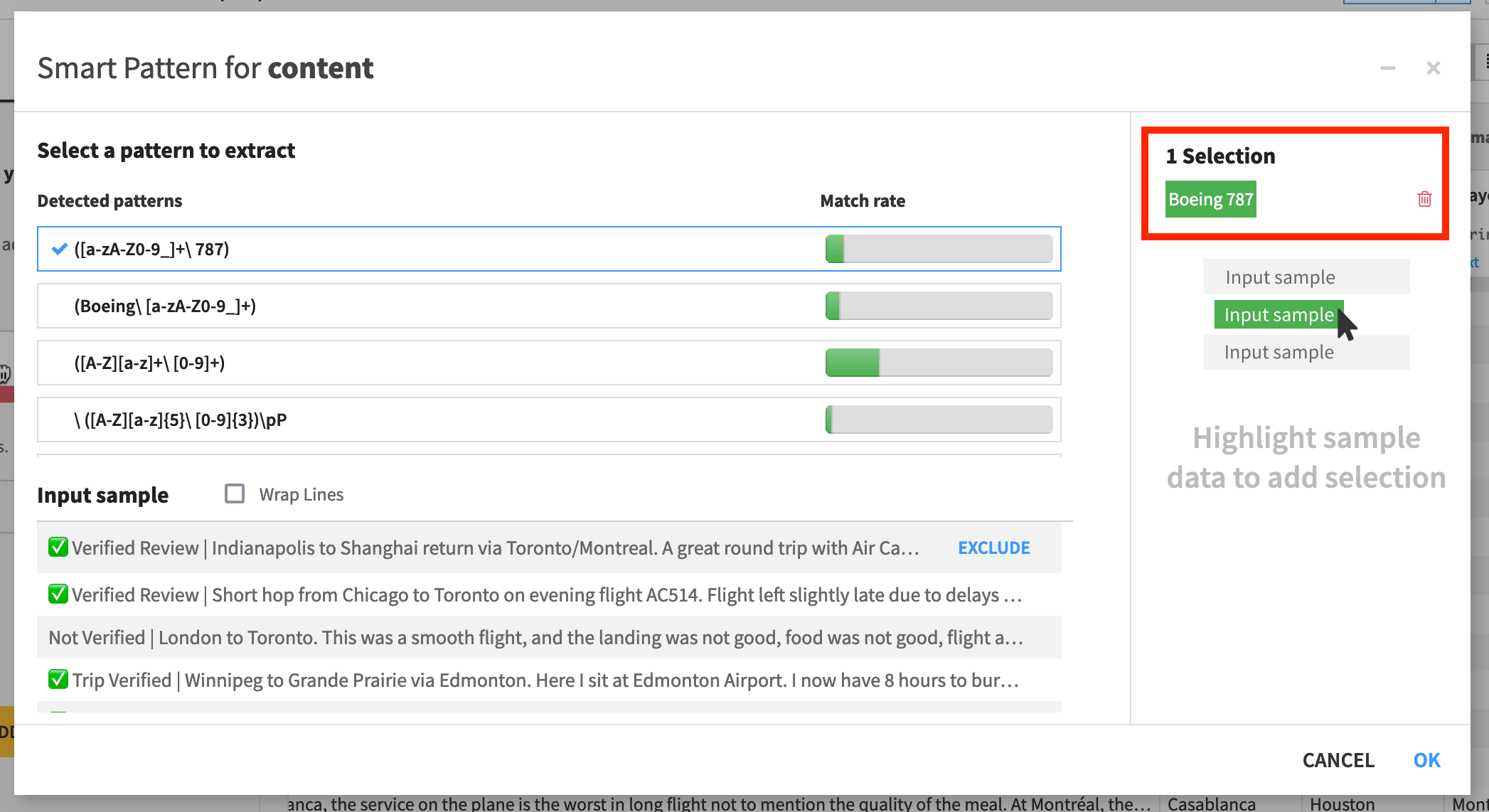
The Match rate bar shows you what percentage of the rows in the current sample contain substrings that correspond to the suggested regex pattern.
Let’s add more examples, and see how the suggested patterns change.
Click Wrap lines to more read each entry in the Input sample.
Use
Cmd/Ctrl+Fon your browser to findBoeing 777. Highlight it to add a second selection.Do the same for
Boeing Max.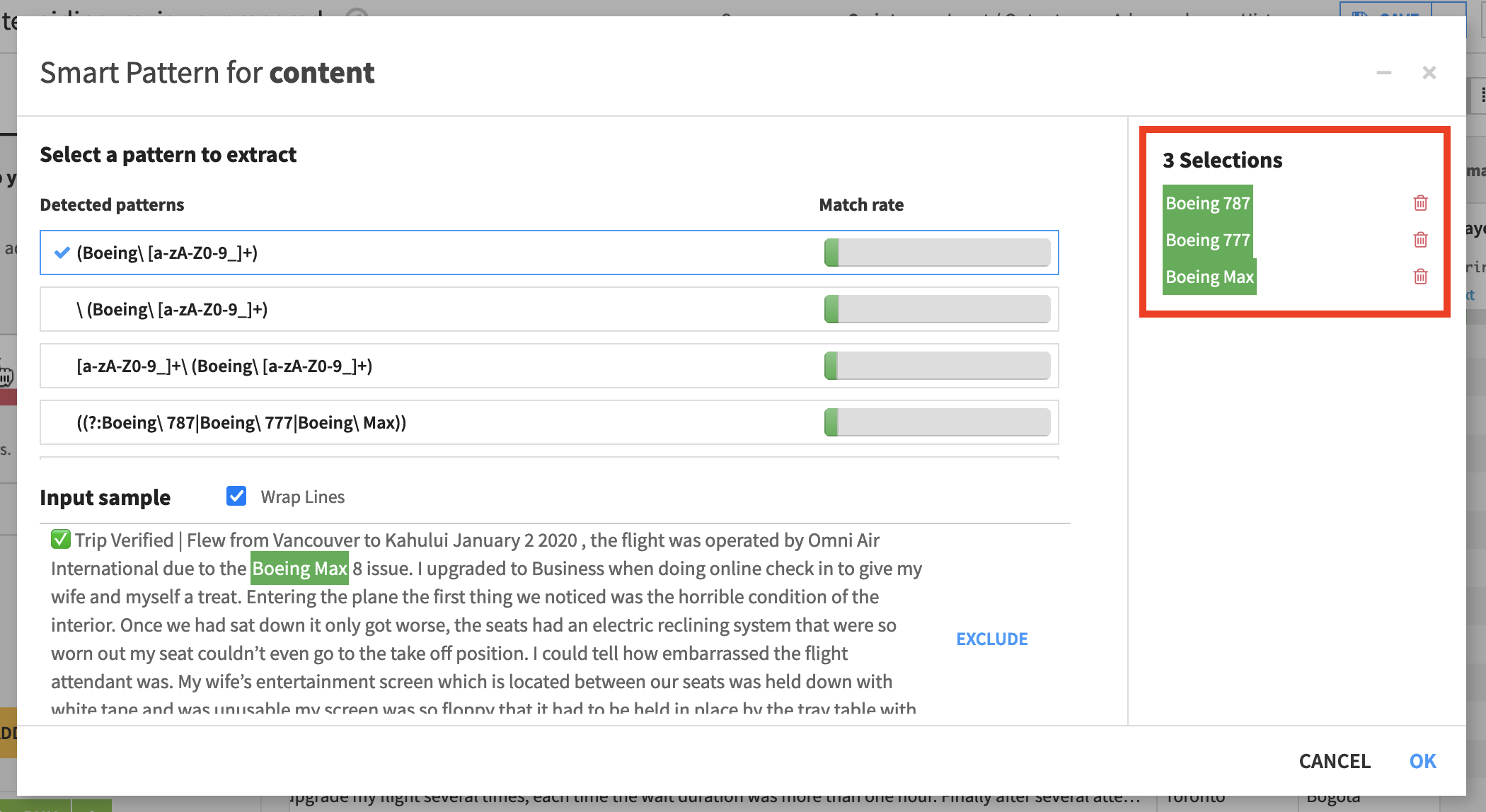
The (Boeing[a-zA-Z0-9_]+) regex now appears at the top and has been ranked as the most likely matching pattern.
Scroll through the Input sample to see what the currently suggested regular expression selects and doesn’t select.
When satisfied that this pattern matches the strings you’re after, click OK.
Note
Why is (Boeing[a-zA-Z0-9_]+) good fit for the use case in this example and ([A-Z][a-z]+[0-9]+) isn’t? The latter extracts any combination of letters followed by any combination of numbers, while the former extracts any occurrence of “Boeing” followed by any combination of letters and/or numbers.
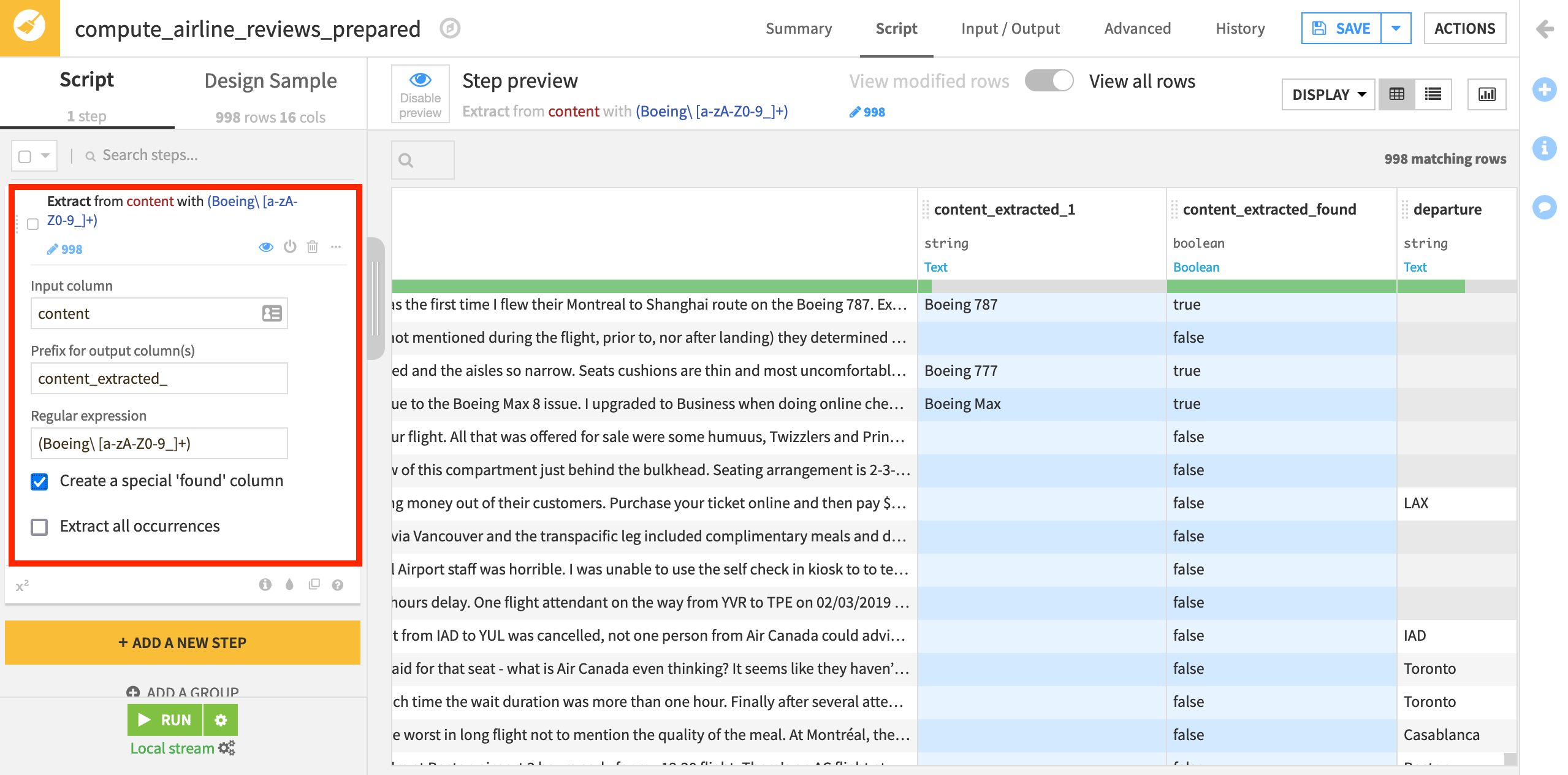
Clicking OK creates a new step in the script. It takes input from the content column and uses the selected regex to extract occurrences of the word “Boeing” followed by a string of letters and/or numbers. It stores the occurrences in a column named by default content_extracted_1.
Once you have chosen a regular expression using the smart pattern builder, there are a few other settings you can configure. These include extracting all occurrences within each row, and not just the first one, by activating the Extract all occurrences checkbox.
Select the option to Create a special ‘found’ column. This will make the goal of filtering based on matches easy!
Next steps#
Learn more about visual recipes in the Visual Recipes Academy course.