

Tutorial | Partitioning in a scenario#
Let’s create an automation scenario to rebuild the datasets in our Flow. One benefit of using a scenario to rebuild partitioned datasets in a Flow, is the availability of keywords. For example, instead of having to type the target partition identifier, we can use a keyword, such as PREVIOUS_DAY.
By using keywords in a scenario, no matter what date is triggered by the scenario, Dataiku automatically computes the necessary partitions.
Get started#
In this tutorial, we will create a scenario that contains four steps, one for each dataset we want to build.
Project Flow overview#
In this lesson, we will interact with both discrete and time-based partitioning inside scenarios. The goal of this lesson is to create a scenario that automatically specifies which partitions to build.
Create the project#
From the Dataiku homepage, click +New Project > DSS tutorials > Advanced Designer > Partitioning: Scenarios.
Note
You can also download the starter project from this website and import it as a zip file.
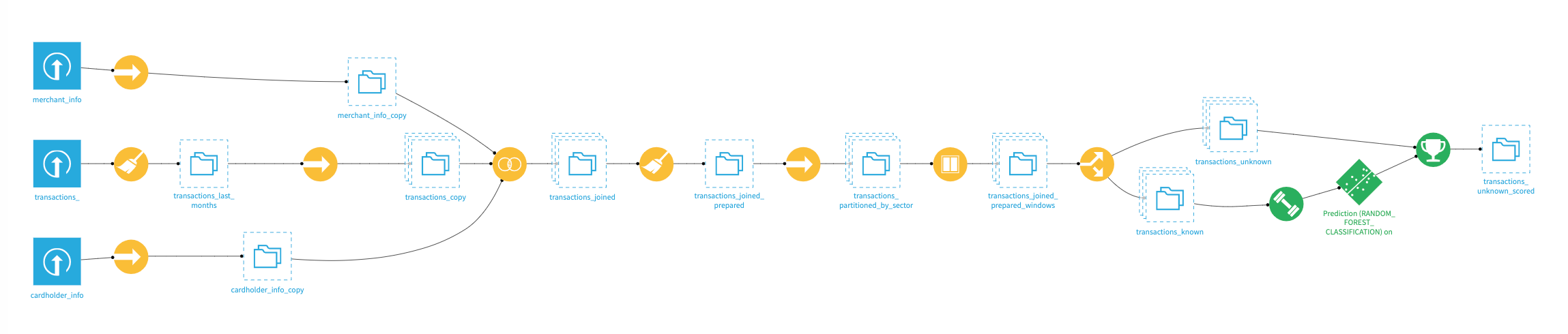
Explore the Flow#
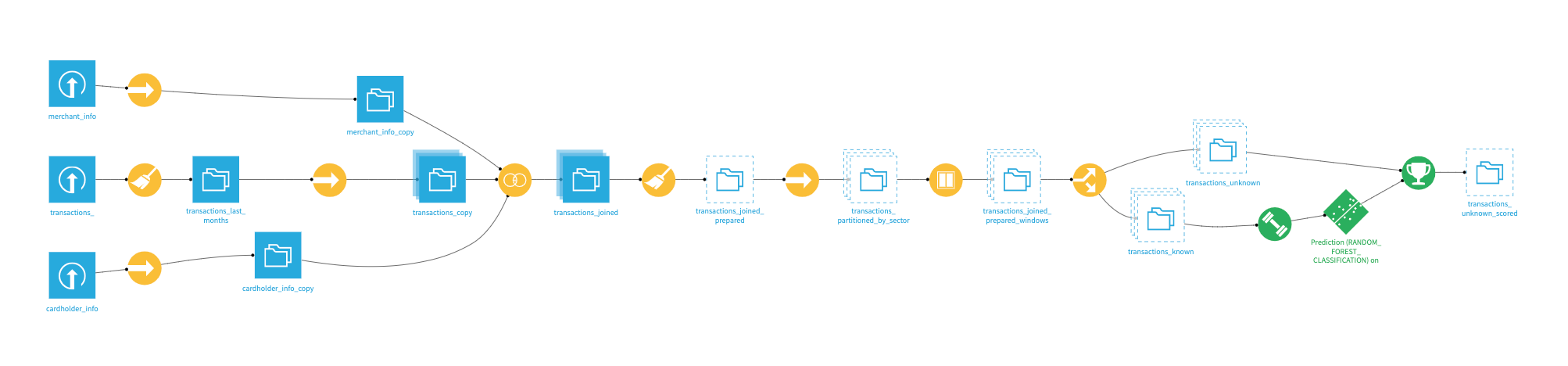
The Flow contains the following datasets:
cardholder_info contains information about the owner of the card used in the transaction process, such as FICO score and age.
merchant_info contains information about the merchant receiving the transaction amount, including the merchant subsector (subsector_description).
transactions_ contains historical information about each transaction, including the purchase_date.
Note
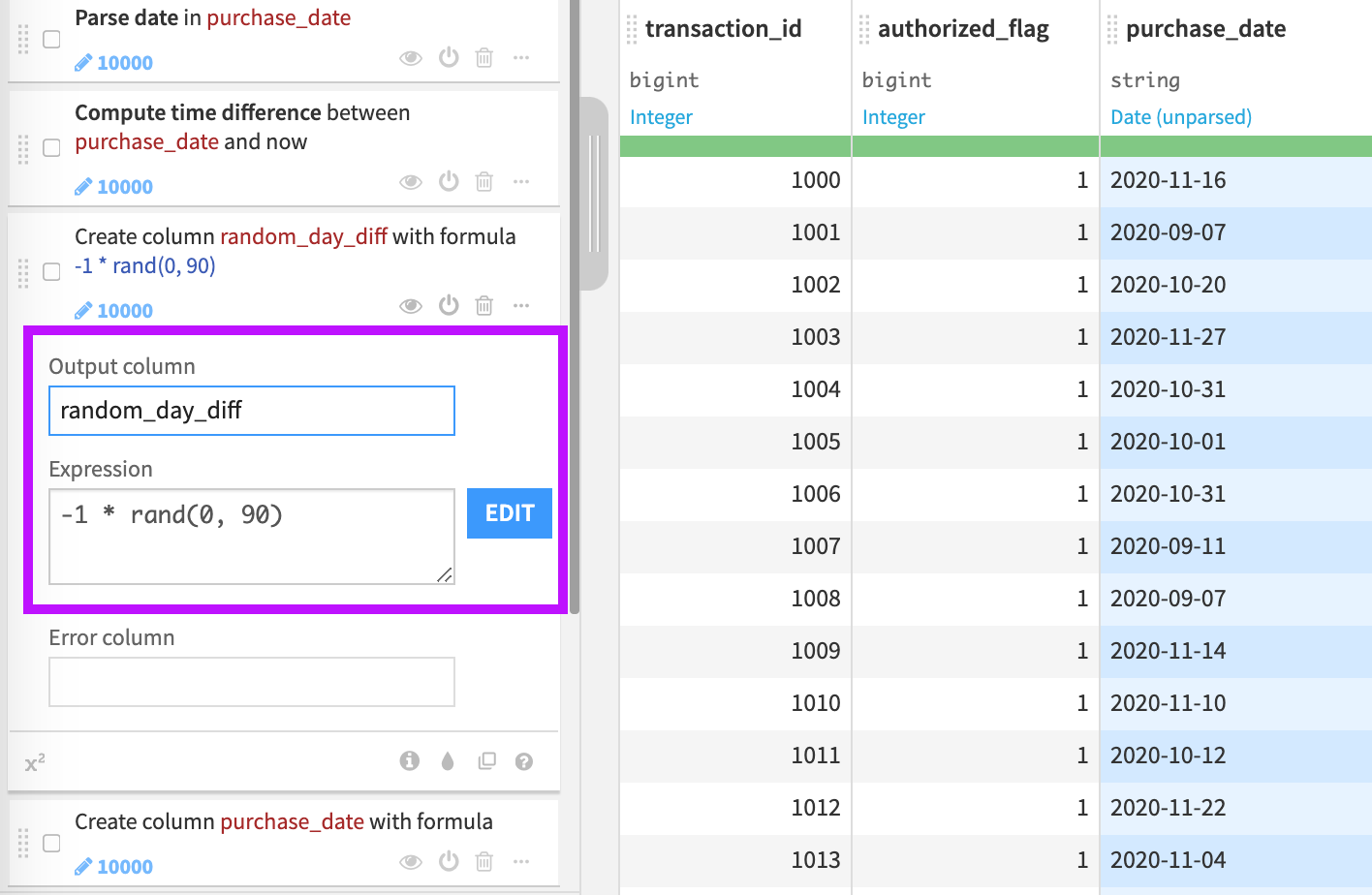
A step in the Prepare recipe uses the “rand” function to simulate having new purchase date information in the transactions dataset. Since the expression, ‘-1 * rand(0, 90)’, returns a random integer every time the computation runs, your results might differ from those shown in this tutorial. Visit the Formula language page in the reference documentation for more information.
Create a scenario#
In this section, we will focus on configuring our scenario to handle a Flow with partitioned datasets.
Note
To make it easier to view the Flow while building the scenario, you could open your project in two separate browser tabs.
Build transactions_copy#
From the Jobs menu, select Scenarios.
Click Create Your First Scenario.
Name your scenario,
flow_rebuildand click Create.
Dataiku displays Settings. We could define a trigger here. However, in this lesson, we will use manual triggers.
Click the Steps tab.
Click Add Step and choose Build / Train.
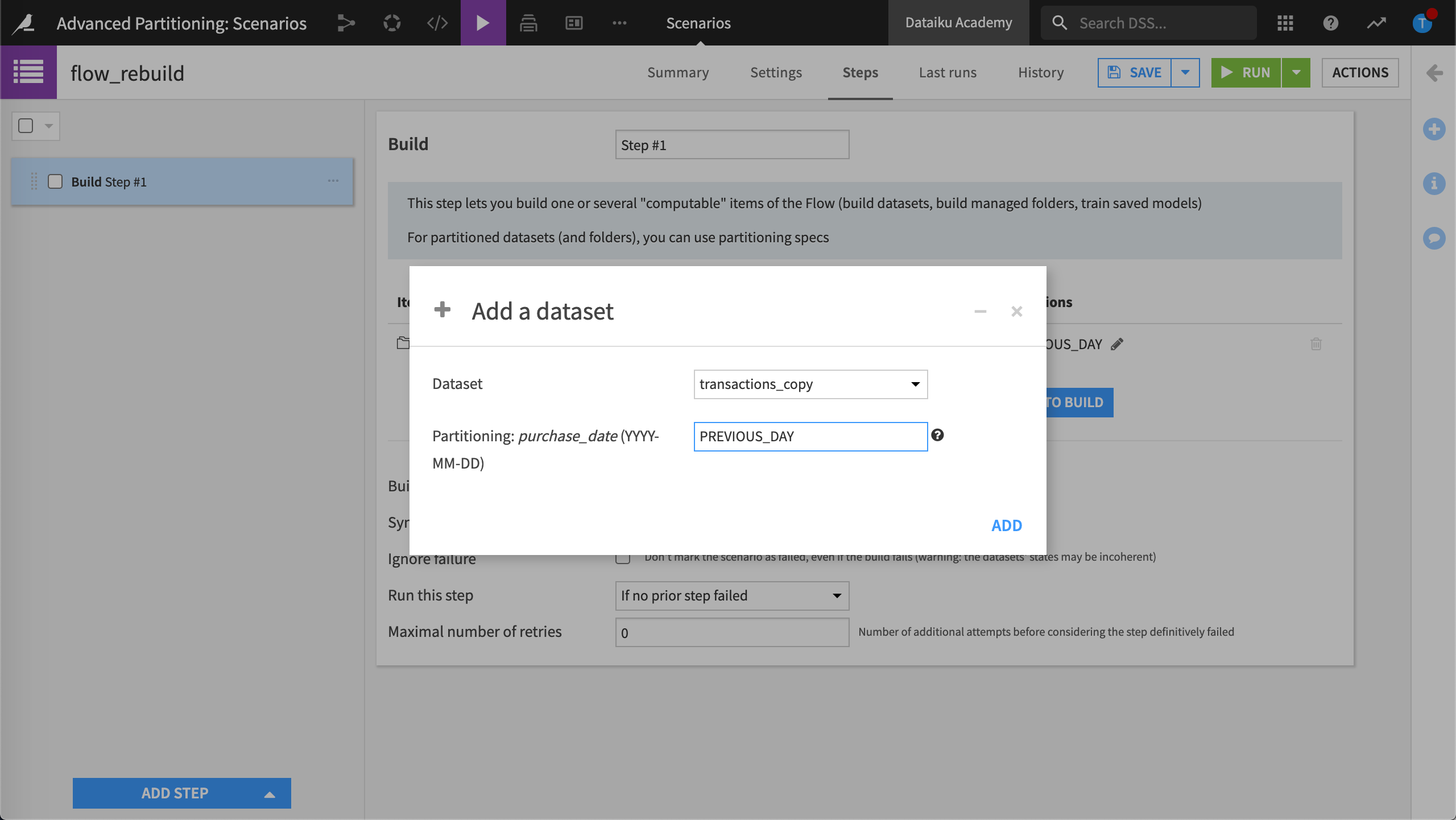
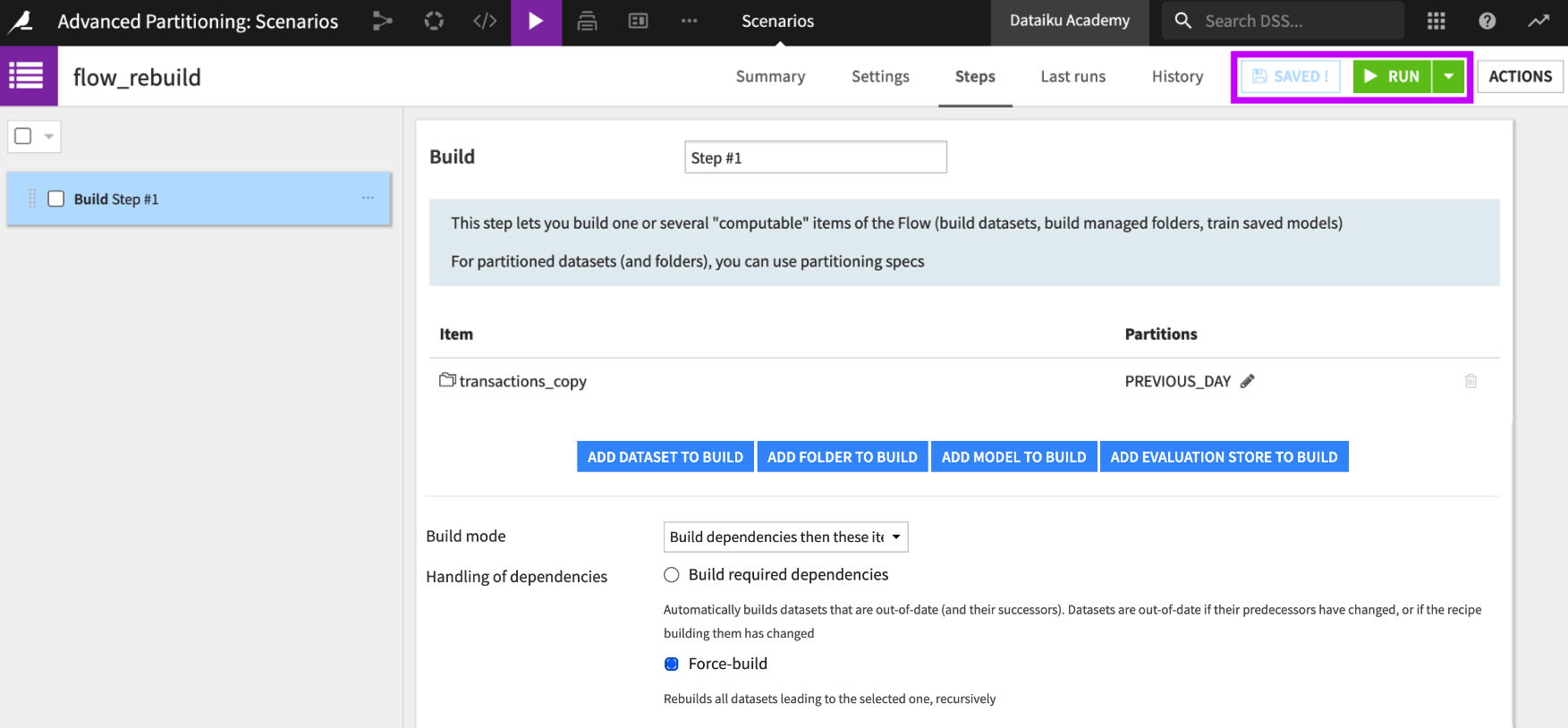
Click Add Dataset to Build and choose transactions_copy.
Dataiku asks which partition we want to build. Since our dataset is partitioned using a time dimension, we can use the keyword,
PREVIOUS_DAY, as the target partition identifier. When the job runs, Dataiku uses the data prior to the current date as the target partition identifier. For more examples, visit Variables in Scenarios.
In Partitioning: purchase_date (YYYY-MM-DD), type the keyword,
PREVIOUS_DAY, then click Add.
To complete the configuration of this step, we need to specify the dataset build mode. We want to be able to test the scenario several times, and we want to be sure we include dependencies that go back to the start of the Flow. Even though it is computationally more expensive, we will select to force rebuild of the dataset and its dependencies for this initial step.
For the build mode, keep Build dependencies then these items.
Choose Force-build for handling of dependencies.
Save and run the step.
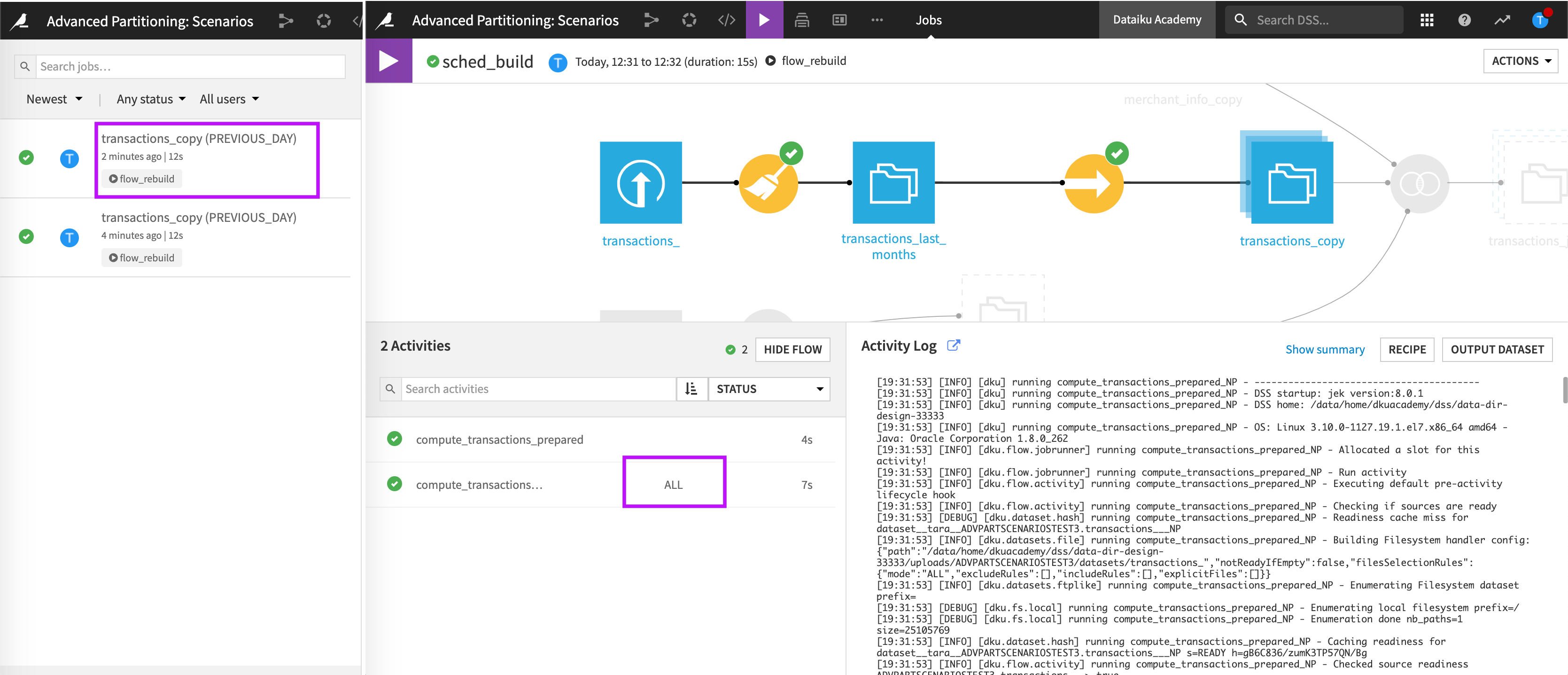
While the job runs, Dataiku displays notifications informing us that the scenario started and that a job started. Let’s look at more details about this job.
We can see that Dataiku triggered a job in order to build the transactions_copy dataset on the partition PREVIOUS_DAY.
However, the second activity built ALL partitions. This is the expected since the Sync recipe that was used to create transactions_copy was configured to use the Partition Redispatch feature. The Partition Redispatch feature writes all the available partitions in the Sync recipe’s output dataset.
Build transactions_joined#
Return to your flow_rebuild scenario and add another Build / Train step.
Click Add Dataset to Build and choose transactions_joined.
Build the same partition as before:
PREVIOUS_DAY.For the build mode, keep Build dependencies then these items.
5. Choose Build required dependencies this time for handling of dependencies. Save and Run the step.
When we view the Job, we can see that the second step of the scenario targets the date of the PREVIOUS_DAY (e.g., “2020-11-07”), as expected. This is more obvious when we view the Last runs of the “flow_rebuild” scenario:
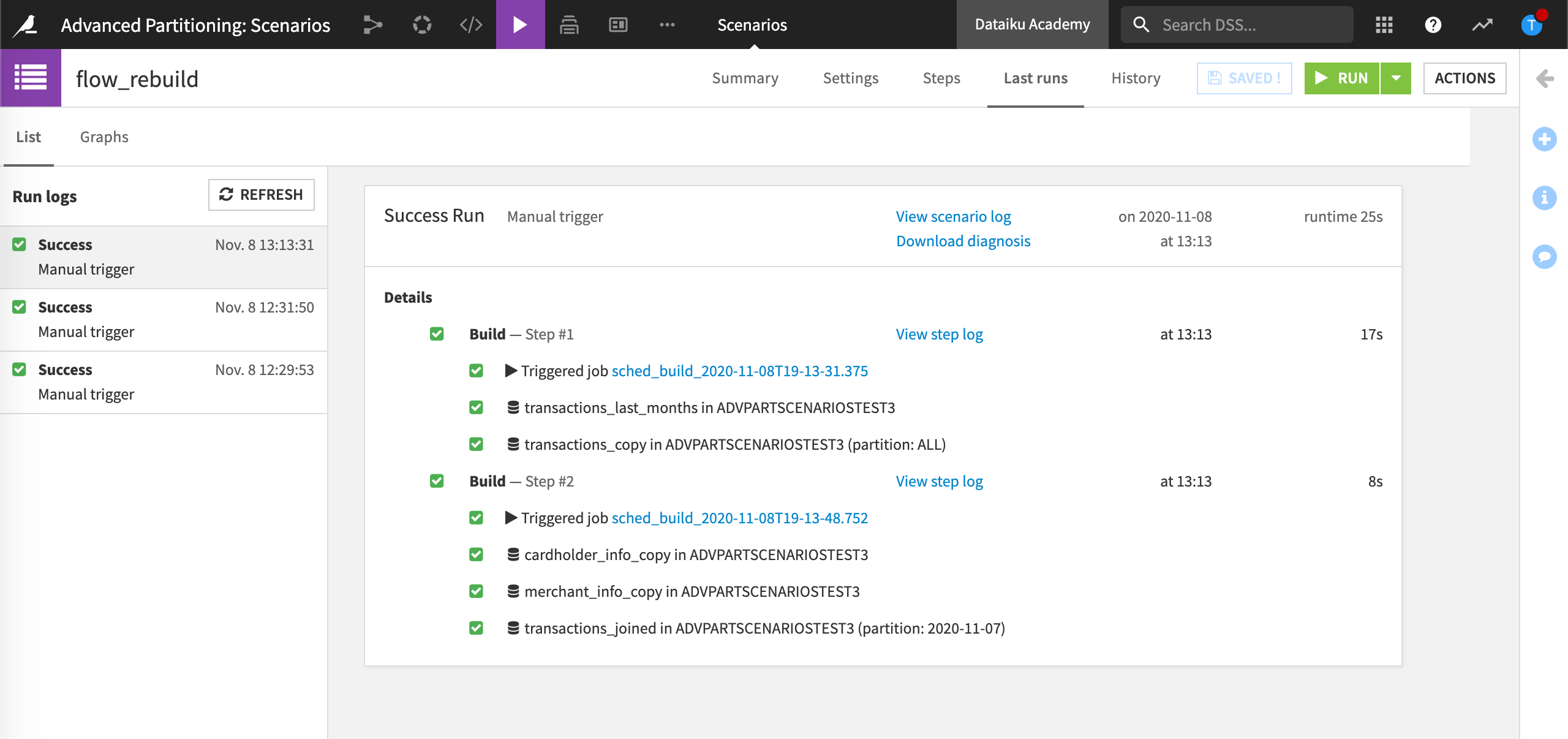
The benefit of using keywords in scenarios is no matter what date is triggered by the scenario, Dataiku automatically computes the necessary partitions.
The Flow is now built up until transactions_joined.
Build transactions_partitioned_by_sector#
Let’s now build transactions_partitioned_by_sector which is partitioned by a discrete dimension, “merchant economic sector”.
Return to your flow_rebuild scenario and add a third Build / Train step.
Click Add Dataset to Build and choose transactions_partitions_by_sector.
Build three partitions,
gas,internet,insurance.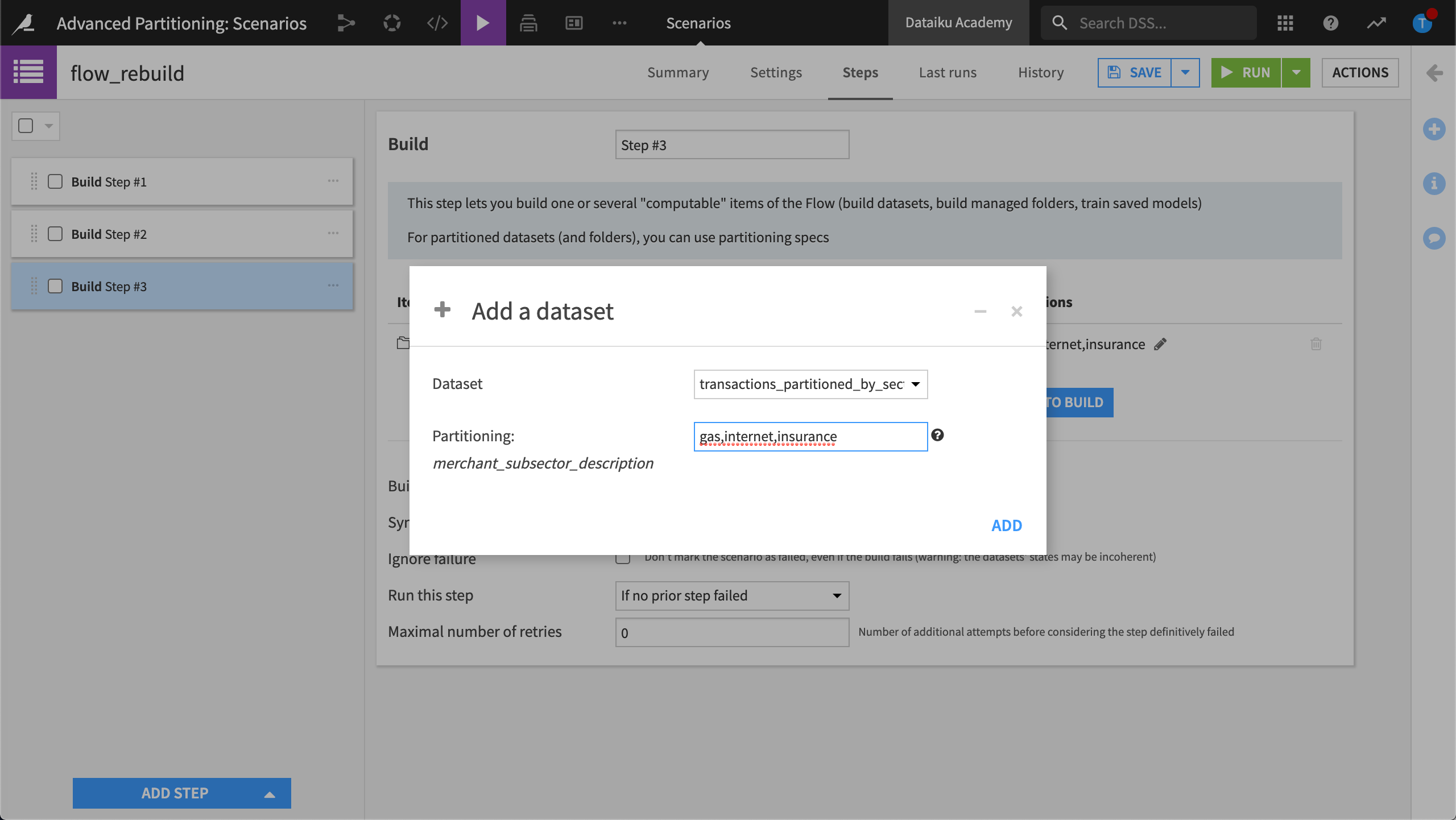
For the build mode, keep Build dependencies then these items.
Choose Build required dependencies for handling of dependencies.
Save and Run the step.
View the job as it runs.
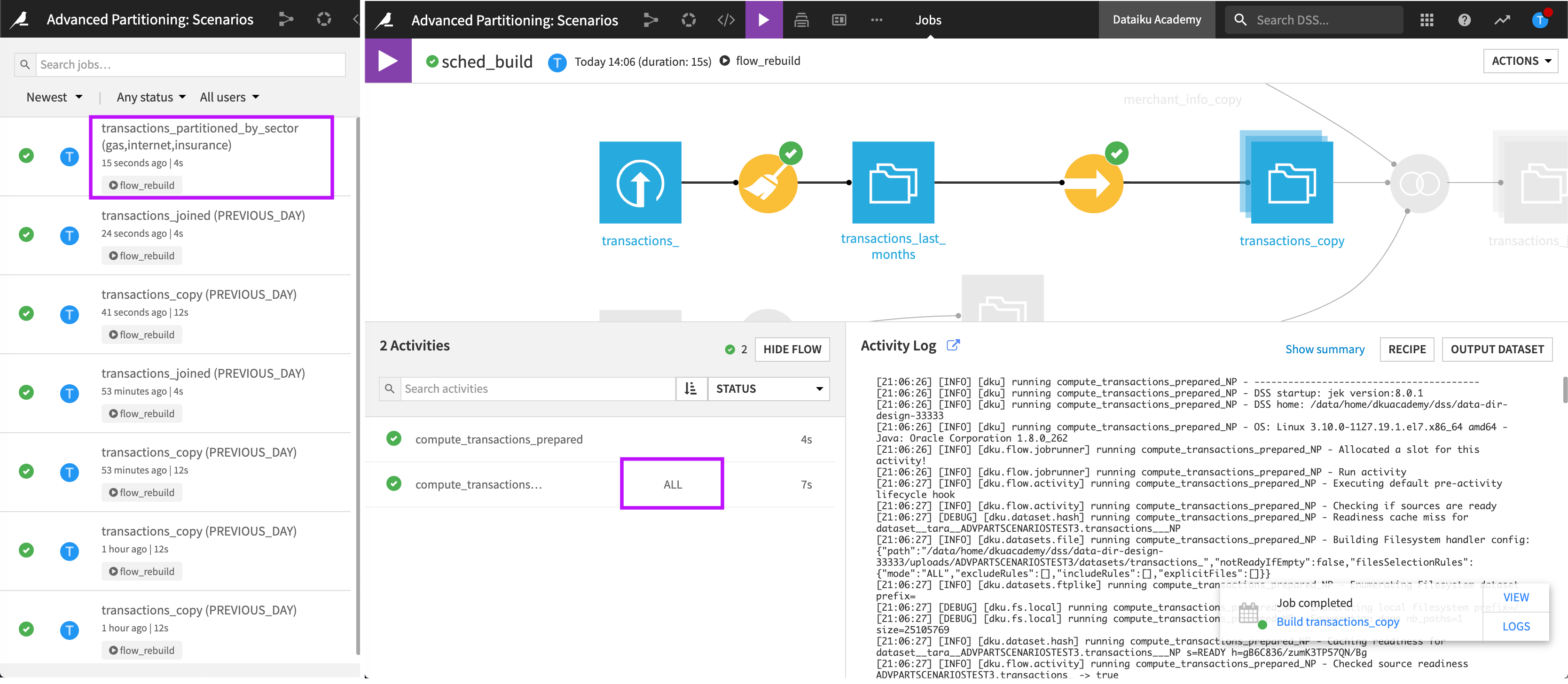
Once again, we can see that no matter which partitions we asked for in the scenario, the redispatching defined in the Sync recipe generates all the partitions in the output dataset. The behavior stays exactly the same as the one we observed with the time dimension.
Our Flow is now built through transactions_partitioned_by_sector.
Build transactions_known and transactions_unknown#
Next, we will build the datasets output by the Split recipe, transactions_known and transactions_unknown.
Return to your flow_rebuild scenario and add a fourth Build / Train step.
Click Add Dataset to Build and choose transactions_known.
Since both transactions_known and transactions_unknown are computed by the Split recipe, we only need to choose one.
Build three partitions,
gas,internet,insurance.Keep the default build mode Build required datasets.
Save and Run the step.
If we view the Last run for this step in the scenario, we can see that Dataiku has built the requested partitions, “gas”, “internet” and “insurance” for both transactions_known and transactions_unknown. Only the specified partitions were built–the Split recipe does not use the Partition Redispatch feature.
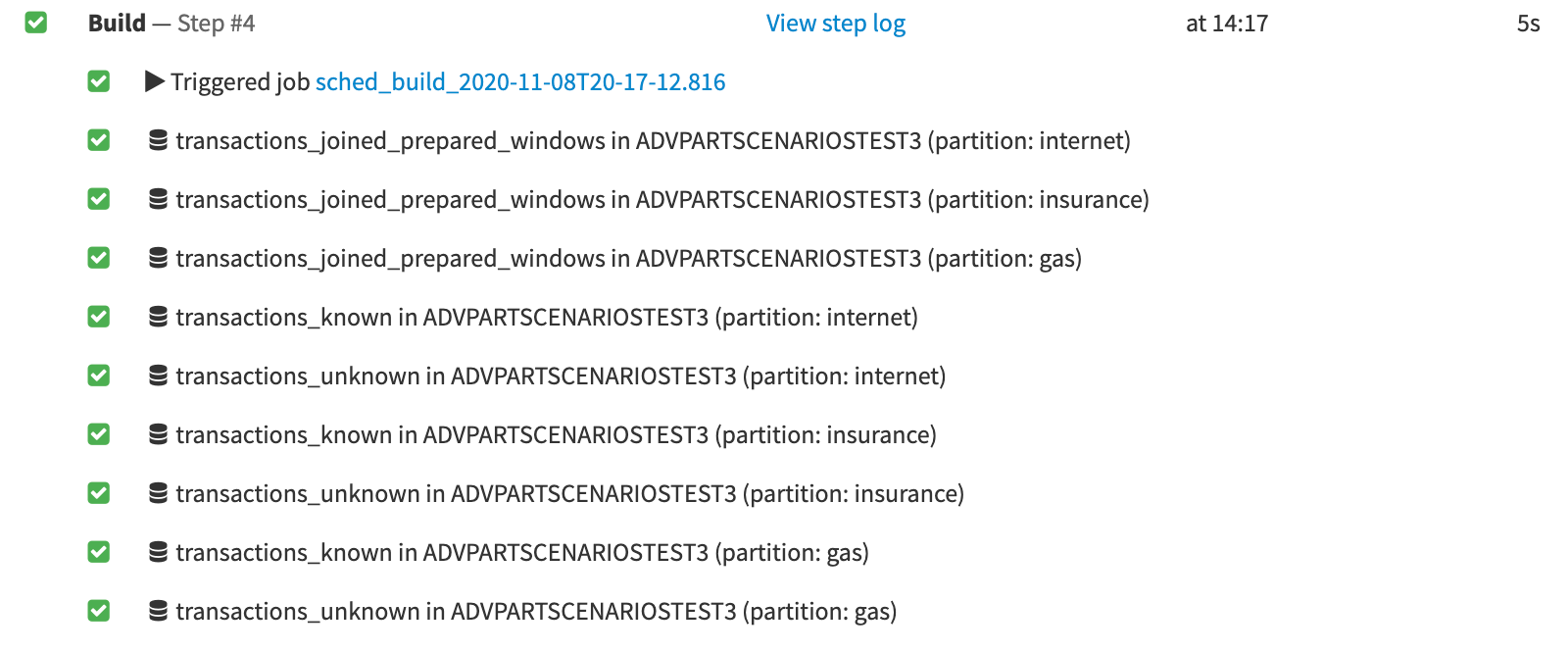
In this tutorial, the Flow is built until the prediction scoring recipe, leaving transactions_unknown_scored unbuilt.
Summary#
Congratulations! You have completed the tutorial. You now know how to manage a partitioned Flow in a scenario. Thanks to the keyword, PREVIOUS_DAY, each day that you execute this scenario will result in new data, based on rows belonging to the partition of the previous day.
What’s next?#
To challenge yourself further, you could try altering the steps in this tutorial to make this scenario work on all the partitions belonging to the 15 days before the current day without including the current day.