
Concept | Partitioning#
Watch the video or read the summary below.
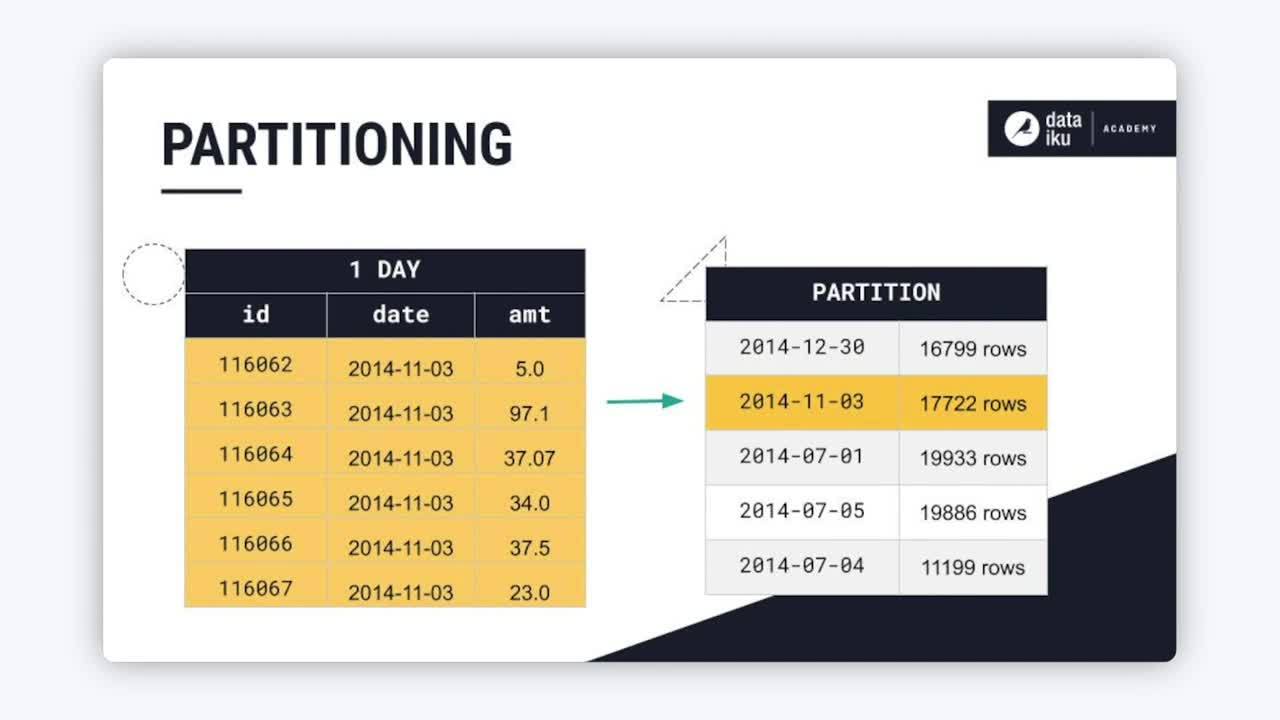
Partitioning a dataset refers to the splitting of a dataset based on one or multiple dimensions. When a dataset is partitioned, each chunk or partition of the dataset contains a subset of the data, and the partitions are built independently of each other.
When new data is added at regular intervals, such as daily, you can tell Dataiku to build only the partition that contains the new data.

In Dataiku, you can partition both file-based datasets and SQL-based (column-based) datasets. For file-based datasets, the partitioning is based on the filesystem hierarchy of the dataset. For SQL-based datasets, one partition is created per unique value of the column and generally doesn’t involve splitting the dataset into multiple tables.
You can recognize a partitioned dataset in the Flow by its distinct stacked representation.

To configure file-based partitioning for a dataset, first activate partitioning by visiting the Partitioning tab under Settings, and then specify the partitioning dimensions (for example time).

To configure SQL-based partitioning, specify which column contains the values you want to use to logically partition the dataset.
When running a recipe that builds a partitioned dataset, use the Input / Output tab of the recipe to configure which partitions from the input dataset will be used to build the desired partitions of the output, and to specify if there are any dependencies, such as a time range.

Once this is configured, select the output dataset in the Flow, then click Build to view the configured partition or partitions. The output to input mapping can be one to one, one to many, or more complex, depending on the use case. Once this is set up, you can build the Flow incrementally.