

Tutorial | SparkR in Dataiku#
Introduction#
This short article shows you how to use Dataiku with SparkR, a Spark module built to interact with DataFrames through R syntax.
Prerequisites#
You have access to an instance of Dataiku with Spark enabled, and a working installation of Spark, version 1.4+.
We’ll be using the Titanic dataset (here from a Kaggle contest), so make sure to first create a new Dataiku dataset and parse it into a suitable format for analysis.
Using SparkR interactively in Jupyter notebooks#
The best way to discover both your dataset and the SparkR API interactively is to use a Jupyter Notebook. From the top navigation bar of Dataiku, click on Notebook, and select R, pre-filled with “Template:Starter code for processing with SparkR”:
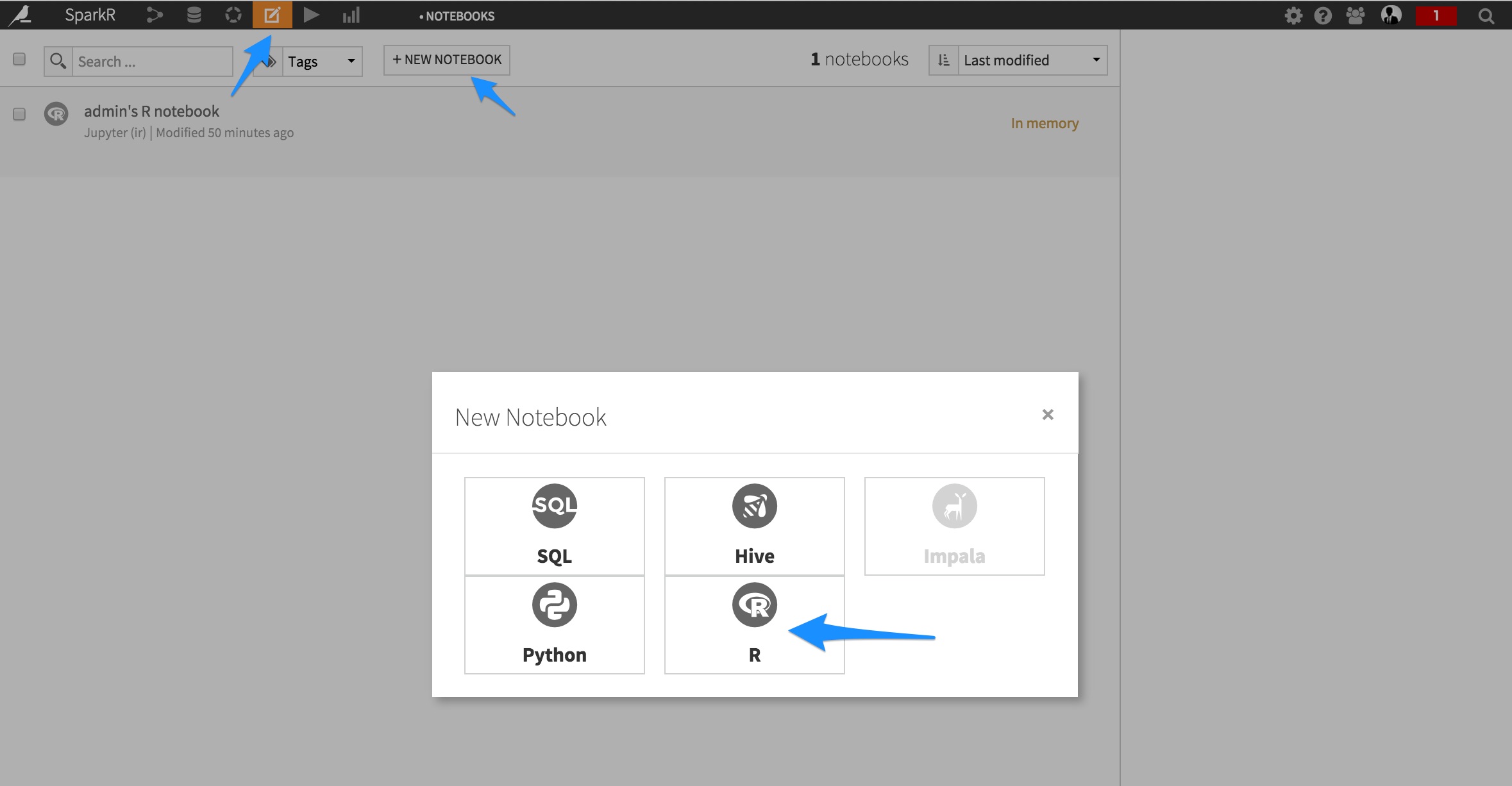
A Notebook shows up. Leveraging the template code, you can quickly get your Dataiku dataset in a SparkR DataFrame:
library(SparkR)
library(dataiku)
library(dataiku.spark)
# Initialize SparkR
sc <- sparkR.init()
sqlContext <- sparkRSQL.init(sc)
# Load DSS dataset into in a Spark dataframe
titanic <- dkuSparkReadDataset(sqlContext, "titanic")
Now that your DataFrame is loaded, you can start using the SparkR API to explore it. Similarly to the PySpark API, SparkR provides us with some useful functions:
# How many records in the dataframe?
nrow(titanic)
# What's the exact schema of the dataframe?
schema(titanic)
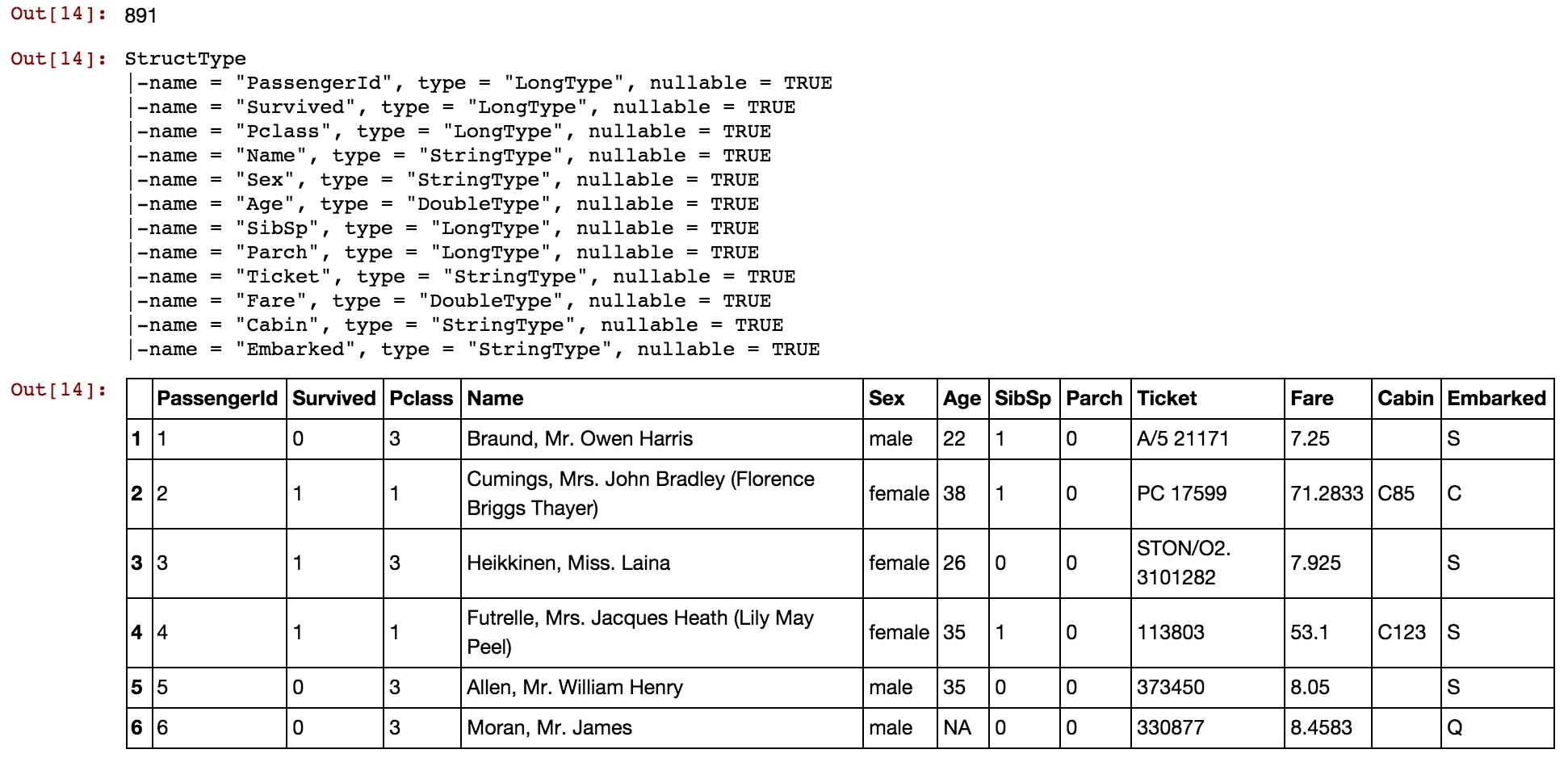
# What's the content of the dataframe?
head(titanic)
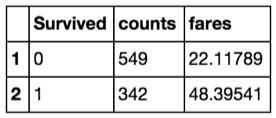
Also, SparkR has functions to create aggregates:
head(
summarize(
groupBy(titanic, titanic$Survived),
counts = n(titanic$PassengerId),
fares = avg(titanic$Fare)
)
)
Make sure of course to regularly check the official documentation to stay current with the latest improvements of the SparkR API.
Integrating SparkR recipes in your workflow#
Assuming you are ready to deploy your SparkR script, let’s switch to the Flow screen and create a new SparkR recipe:
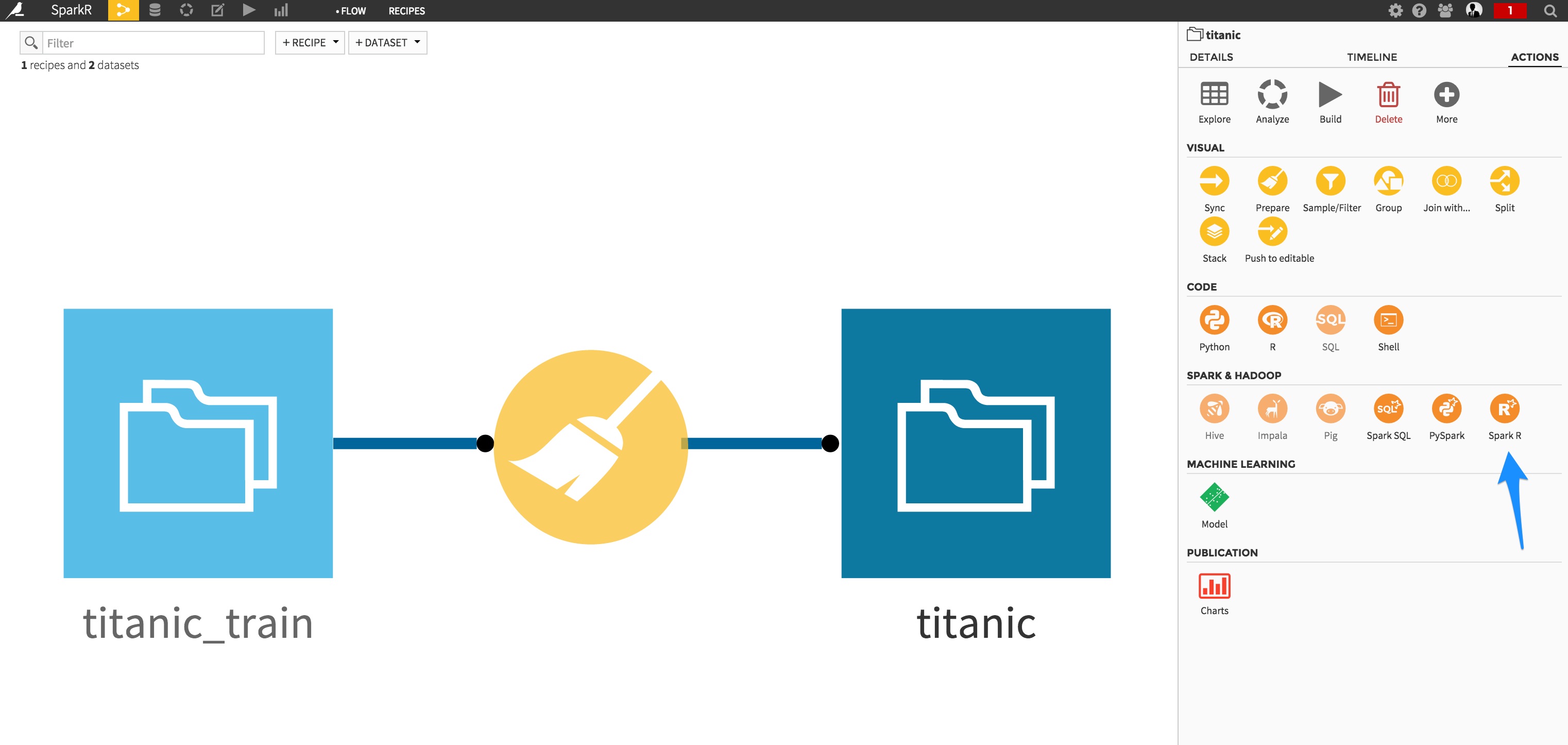
Specify the recipe inputs/outputs, and when in the code editor, copy/paste your R code:
library(SparkR)
library(dataiku)
library(dataiku.spark)
# Initialize SparkR
sc <- sparkR.init()
sqlContext <- sparkRSQL.init(sc)
# Read input datasets
titanic <- dkuSparkReadDataset(sqlContext, "titanic")
# Aggregation
agg <- summarize(
groupBy(titanic, titanic$Survived),
counts = n(titanic$PassengerId),
fares = avg(titanic$Fare)
)
# Output datasets
dkuSparkWriteDataset(agg, "titanicr")
Your recipe is now ready. Just click the Run button and wait for your job to complete:
We’re done for this short intro! SparkR being part of Dataiku, it is now possible to develop and manage completely Spark-based workflows using the language of your choice.