
Concept | The Design tab within the visual ML tool#
Watch the video or read the summary below.
After creating quick models (quick prototypes), you’ll want to modify your model’s design to ensure your model generates the best results possible. Some things to consider are the basic model design, feature engineering and reduction, algorithms and hyperparameters, and additional advanced design options.
Basic model design#
In the Design tab, you can modify your target variable and choose between three prediction types:
Regression for numeric targets.
Two-class classification when the target can be one of two categories.
Multi-class classification when targets can be one of many categories.

You can also opt to partition a model on datasets that have been partitioned, or split across some meaningful dimension. When training a model, it’s important to test the performance of a model on a hold out, or test dataset. You have the option to order by a specific time variable to ensure that the splits adhere to a certain timeline, if necessary.
If you are working with a large dataset that doesn’t fit in RAM, or you would like to subsample to re-balance classes, you can select a relevant sampling strategy. By default, Dataiku performs a random split, in which 80% of records are fed into the train set, and 20% are fed into the test. You can override this if you prefer k-fold cross testing, or more advanced explicit dataset extracts.
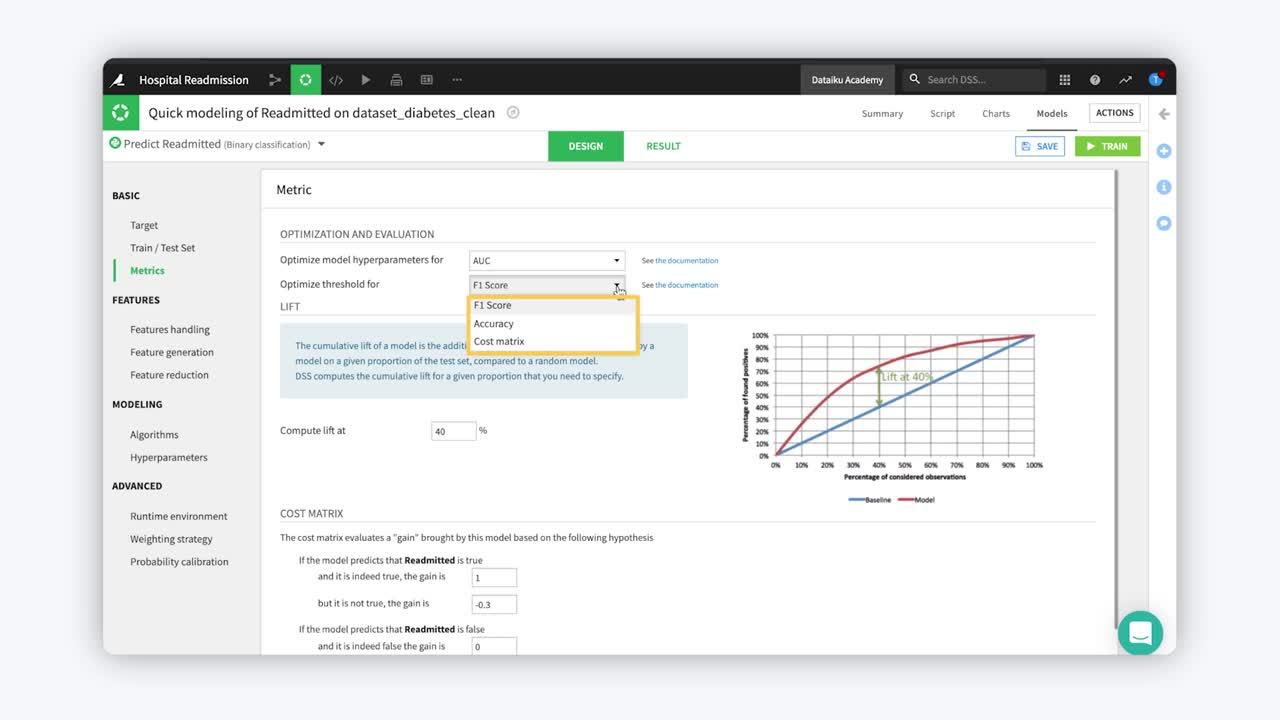
Once you have selected your train-test splitting methodology, you can decide what metric you’ll use to score your test set and decide which hyperparameters are best. You could also provide a custom sci-kit learn compatible Python function. When doing binary classification, you may also select the metric for which you would like to optimize your threshold. The threshold is directly related to the likelihood of a positive prediction.
You can also use the cost matrix to quantify the gains from various outcomes, to better understand your model from a monetary perspective.
Feature engineering & reduction#
Now that you have your basic model design configured, you can begin feature engineering and reduction. In the Features Handling panel, you can decide which features you would like to include in your model, and how you would like to pre-process them, either through the visual user interface or through Python code. Dataiku has different default configurations based on the variable type you’re using–numerical, categorical, text, or vector.

You can also generate new features using linear or polynomial combinations, as well as pairwise interaction terms. If you have many features, you could select a dimensionality reduction technique, such as Principal Component Analysis or tree-based reduction.
Algorithms & hyperparameters#
In the Modeling section, you can select and deselect algorithms. Dataiku supports several algorithms that can be used to train machine learning models. You can decide which algorithms and corresponding hyperparameters you want to test, and can even add custom Python models.

In the Modeling section, you can also define how you want Dataiku to test different hyperparameter values through a process called grid search. Through this process, Dataiku will test all possible combinations of hyperparameters and automatically select the best performing one, based on the metric you selected earlier.

Advanced options#
After configuring the model’s design, consider the advanced options.
If you are using a custom Python model with any libraries that don’t exist in the Dataiku built-in code environment, you can use the Advanced Options to use a different code environment for your model.

If you want to offload model training to a Kubernetes container, you can do so by selecting the relevant container configuration, provided that your instance of Dataiku has Kubernetes enabled.
You can use weighting strategies to specify the relative importance of each row of the dataset, both for the training algorithm and for the different evaluation metrics. This can be particularly helpful in dealing with imbalanced datasets. By default, Dataiku uses class weights for all classification tasks to ensure that each class is taken into account equally.
When training a classification model, you can also opt to use probability calibration to adjust the class probabilities to more closely resemble the class frequencies.
Once you have developed your model design, train your model again. Don’t forget to give this training session a different name so that you can clearly differentiate it from your initial training session.