
Concept | Features handling#
Watch the video or read the summary below.
In the Features handling panel, we can allow Dataiku to automatically choose the features included in our model, or we can manually select which features we want to include when our model is trained. In our example, Dataiku automatically excluded a column containing unique identifiers.

We can also perform feature processing including the processing of different types of variables, handling of missing values, and applying additional processing.
Variable types#
In Dataiku, we can process numerical, categorical, text, and vector features. Numerical features include columns made up of numbers. Categorical features are generally made up of “categories” or “class” labels. In machine learning, a Text feature refers to natural language. Vectors refer to a collection of numbers, delimited by commas and enclosed in square brackets.
Handle missing values#
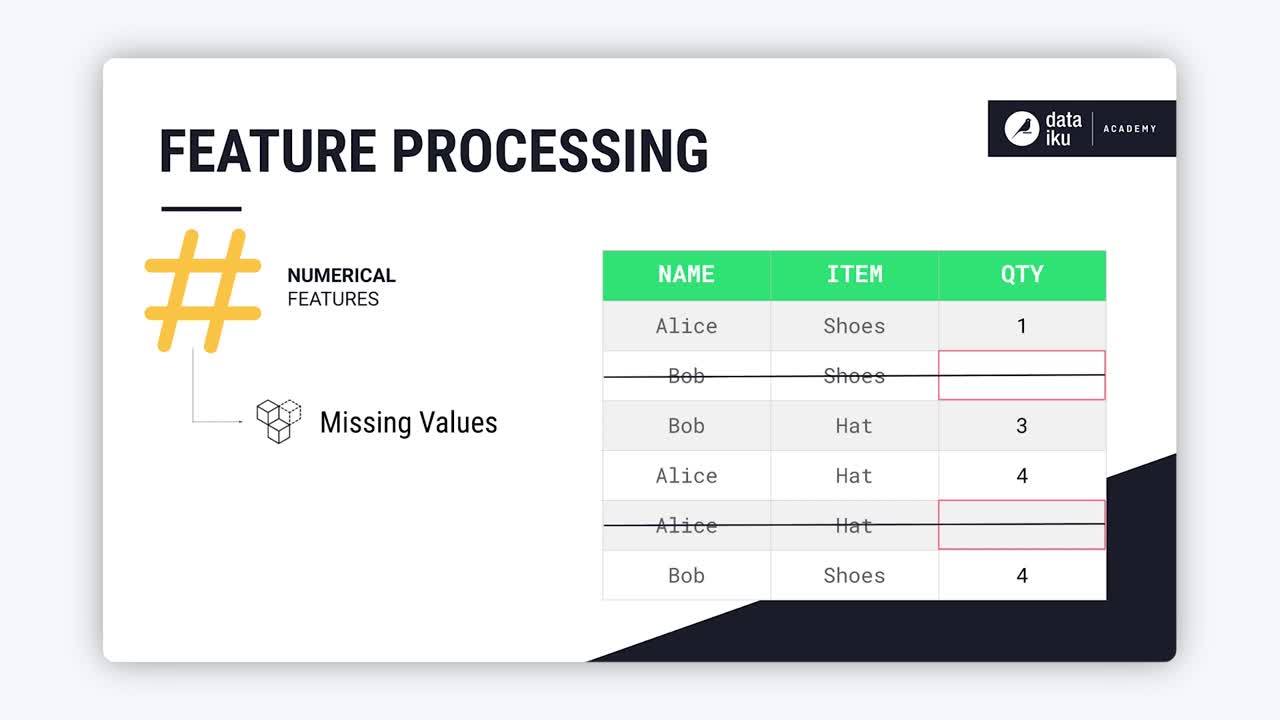
Many machine learning algorithms aren’t able to handle rows with missing values. Therefore, the first feature processing step is to handle any missing values.
For Numerical features, depending on the use case, we could impute the missing values with a constant, like zero, or with the median or mean of the column. In other cases, we might choose to drop rows with missing values as shown in this example:

For Categorical features, we could treat the missing values as an additional “missing” category, or we could impute the most common category. Another option would be to entirely drop rows with missing values.
Apply additional processing including encoding#
The next step is to apply any additional processing. For example, for Numerical features, if there are large absolute differences between the values, we might want to apply a rescaling technique such as “Standard” or “Min-max” rescaling.
For Categorical features, we want to encode the values as numbers so the machine learning algorithm can understand them. In this before and after example, we could apply dummy encoding so that hats and shoes are encoded as numbers:


Note
Dataiku offers many different types of feature encoding, including frequency encoding, ordinal encoding, datetime encoding, and more. See our reference documentation on categorical variables for more information.
Dataiku can process Text features through tokenizing, hashing and applying SVD, count vectorization, TF/IDF vectorization, or custom preprocessing. Count vectorization is similar to dummy encoding for categorical features. The output is a matrix, with each cell containing the count for a particular word:


Vectors can be handled by a process called flattening, whereby each element in the vector is assigned its own column:
