
Tutorial | Forecasting time series data with R and Dataiku#
Get started#
R has several great packages built specifically to handle time series data. Using these packages within Dataiku, you can perform time series visualization, modeling, and forecasting.
Objectives#
In this tutorial, you will:
Use R in Dataiku for time series analysis, exploration, and modeling.
Deploy a time series model from the Lab as an R recipe.
Prerequisites#
Dataiku 12.0 or later.
An Advanced Analytics Designer or Full Designer user profile.
The R integration installed.
An R code environment including the forecast and zoo packages.
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Forecasting Time Series With R.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
Use case summary#
This tutorial uses the passenger dataset from the U.S. International Air Passenger and Freight Statistics Report. It contains data on the total number of passengers for each month and year between a pair of airports, as serviced by a particular airline.
Notice that the Flow already performs the following preliminary steps:
A Download recipe imports the data from the URL:
https://data.transportation.gov/api/views/xgub-n9bw/rows.csv?accessType=DOWNLOADand creates the passengers dataset.A Prepare recipe modifies the dataset leaving only those columns relevant to the analysis: Date, carriergroup, and Total.
A Group recipe creates a new dataset group0_passengers that contains the total number of travelers per month for carrier group 0.
Now you can proceed to perform analysis and forecasting on the group0_passengers dataset.
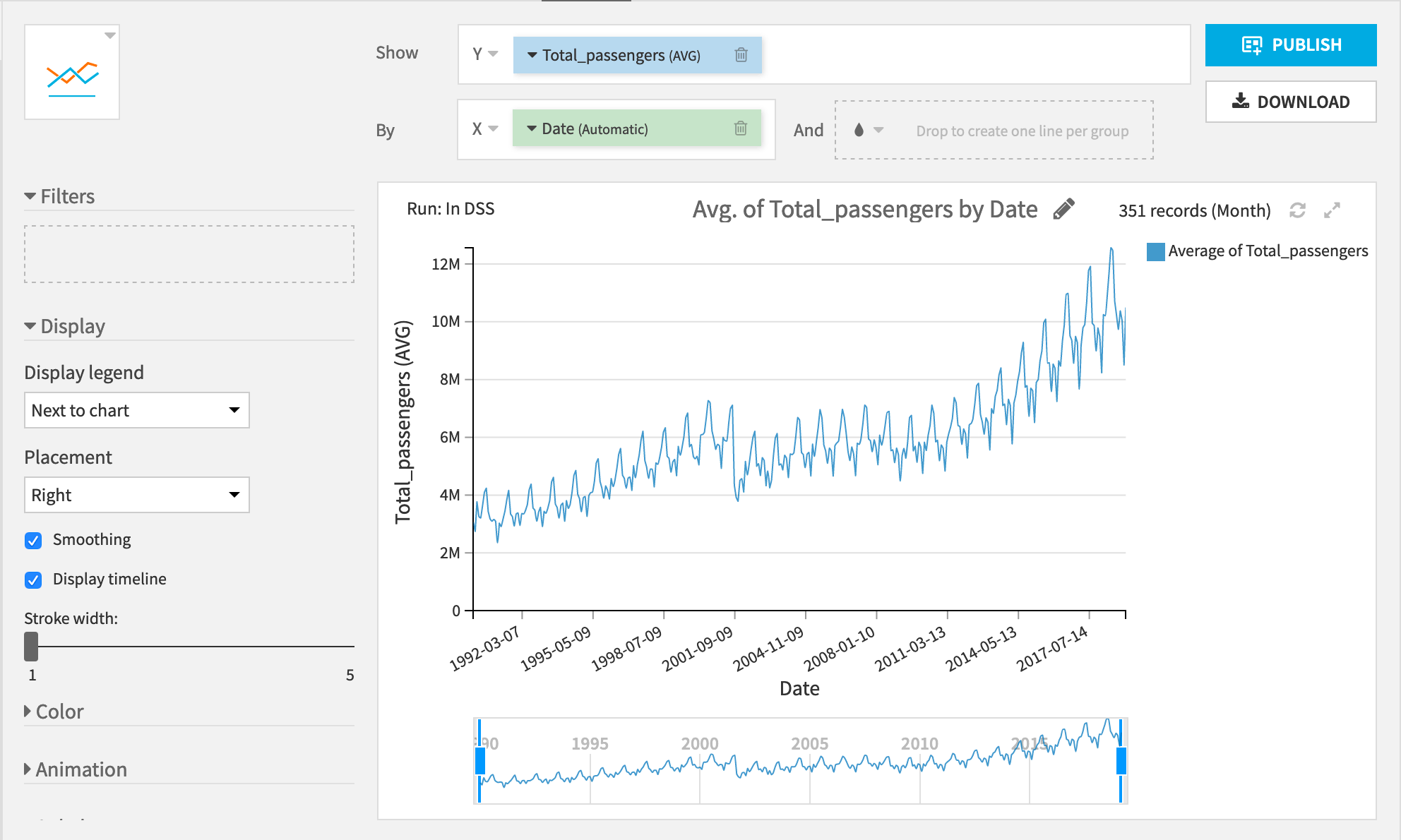
You can see two really interesting patterns:
A general upward trend in the number of passengers.
A yearly cycle with the lowest number of passengers occurring around the new year and the highest number of passengers during the late summer.
Let’s see if you can use these trends to forecast the number of passengers after March 2019.
Create an R notebook#
Start with an R code notebook.
Select the group0_passengers dataset.
Navigate to the Lab (
 ) tab of the right side panel.
) tab of the right side panel.Under Code Notebooks, click New.
From the available types of notebooks, select R.
If not set at the project level, change the code environment to one including the forecast and zoo packages.
Click Create.
Perform interactive analysis with an R notebook#
Let’s first confirm the trends seen in the native chart.
Replace the default library import statement with the one below including the extra packages.
library(dataiku) library(forecast) library(dplyr) library(zoo)
Tip
The dataiku package lets us read and write datasets to Dataiku.
The forecast package has the functions we need for training models to predict time series.
The dplyr package has functions for manipulating DataFrames.
The zoo package has functions for working with regular and irregular time series.
Run the cell to read in the data to an R DataFrame using the R API.
Add a line like
head(df)to explore the data.
Now that you’ve loaded the data, create a time series object using the base ts() function and plot it.
The ts() function takes a numeric vector, the start time, and the frequency of measurement. For the dataset, these values are:
Total_passengers
1990(the year for which the measurements begin)a frequency of
12(months in a year)
Copy-paste and run the following lines in the next cell of the notebook:
ts_passengers <- ts(df$Total_passengers, start = 1990, frequency = 12) plot(ts_passengers)
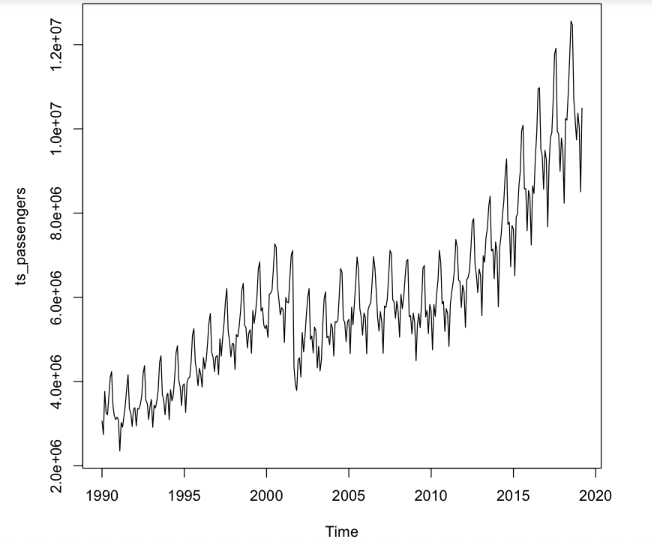
Tip
Not surprisingly, it shows the same trends found in the plot using the native chart builder in Dataiku. Now let’s start modeling!
Choose a forecasting model#
Let’s try three different forecasting methods and deploy the best one as a recipe in the Flow. In general, it’s good practice to test several different modeling methods, and choose the method that provides the best performance.
Model 1: Exponential smoothing state space model#
The ets() function in the forecast package fits exponential state smoothing (ETS) models. This function automatically optimizes the choice of model parameters.
Copy-paste the code below to use the
etsfunction to make a forecast for the next 24 months.
m_ets <- ets(ts_passengers)
f_ets <- forecast(m_ets, h = 24) # forecast 24 months into the future
plot(f_ets)
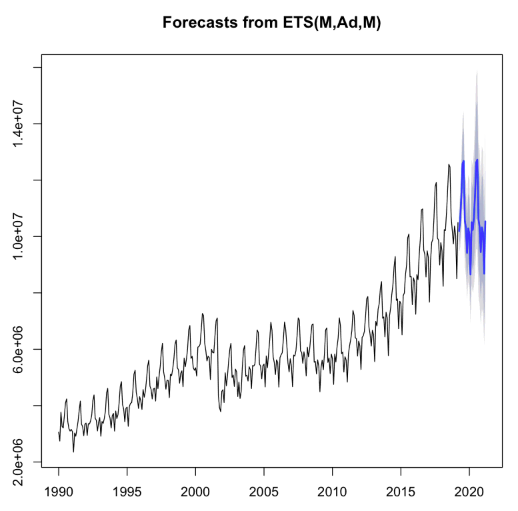
Tip
The forecast is shown in blue, with the gray area representing a 95% confidence interval. You can see that the forecast roughly matches the historical pattern of the data.
Model 2: Autoregressive Integrated Moving Average (ARIMA) model#
The auto.arima() function from the forecast package returns the best ARIMA model based on performance metrics. Using the auto.arima() function is almost always better than calling the arima() function directly.
Note
For more information on the auto.arima() function, see an explanation in the Forecasting textbook.
Once again, copy-paste the code below to make a forecast for the next 24 months.
m_aa <- auto.arima(ts_passengers)
f_aa <- forecast(m_aa, h = 24)
plot(f_aa)
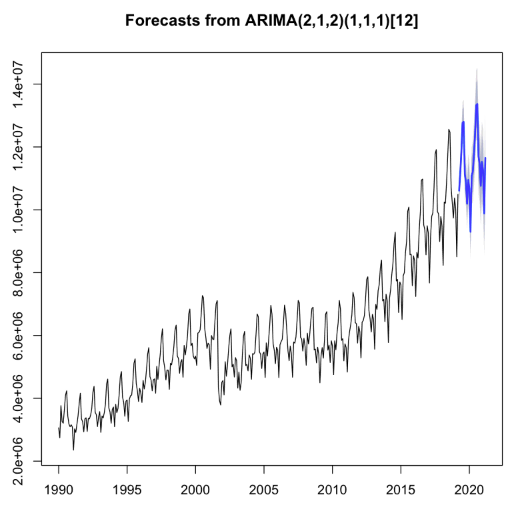
Tip
Observe that these confidence intervals are a bit smaller than those for the ETS model. This could be the result of a better fit to the data. Let’s train a third model, and then do a model comparison!
Model 3: TBATS model#
The last model to train is a TBATS model. This model is designed for use when there are multiple cyclic patterns (for example daily, weekly, and yearly patterns) in a single time series. Let’s see if this model can detect complicated patterns in our time series.
Copy-paste the code below to make a third forecast for the next 24 months.
m_tbats <- tbats(ts_passengers)
f_tbats <- forecast(m_tbats, h = 24)
plot(f_tbats)
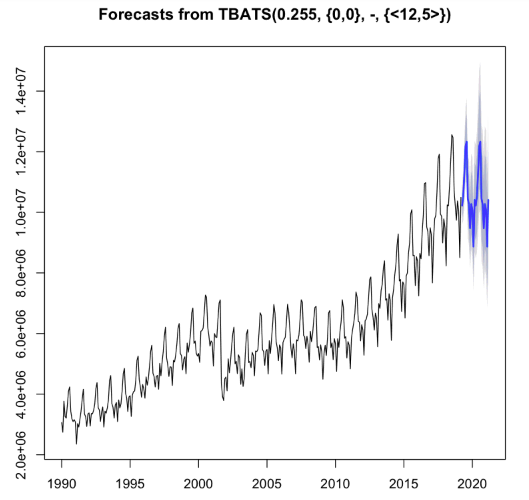
Tip
Now you have three models that all seem to give reasonable predictions. Let’s compare them to see which one performs best.
Compare models#
Let’s use the Akaike Information Criterion (AIC) to compare the different models. AIC is a common method for determining how well a model fits the data, while penalizing more complex models. The model with the smallest AIC value is the best fitting model.
Add the following code to the next cell, and run it.
barplot(c(ETS = m_ets$aic, ARIMA = m_aa$aic, TBATS = m_tbats$AIC),
col = "light blue",
ylab = "AIC")
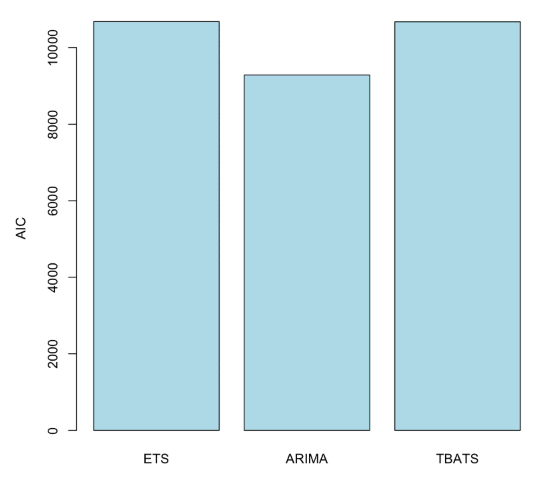
The ARIMA model performs the best according to this criteria. Let’s now convert the interactive notebook into an R code recipe.
Store the forecasted values#
To do this, you first have to store the output of the forecast() function from the chosen model into a DataFrame, so that you can pass it to Dataiku. The following code can be broken down into three steps:
Find the last date for which we have a measurement.
Create a DataFrame with the prediction for each month. We’ll also include the lower and upper bounds of the predictions, and the date. Since we’re representing dates by the year, each month is 1/12 of a year.
Split the date column into separate columns for year and month.
Add the following code to the next cell, and run it.
last_date <- index(ts_passengers)[length(ts_passengers)]
data.frame(passengers_predicted = f_aa$mean,
passengers_lower = f_aa$lower[,2],
passengers_upper = f_aa$upper[,2],
date = last_date + seq(1/12, 2, by = 1/12)) %>%
mutate(year = floor(date)) %>%
mutate(month = round(((date %% 1) * 12) + 1)) ->
forecast
Now you have the code to create the forecast for the next 24 months and the code to convert the result into a DataFrame. You’re all set to deploy the model as a recipe.
Note
Here we speak of deploying a model from a notebook (part of the Lab) to a recipe (part of the Flow). Note however that this isn’t the same as deploying a Dataiku-managed visual or custom model to the Flow. The result will be an R recipe in the Flow and not a saved model (represented by a green diamond).
Deploy the model to the Flow#
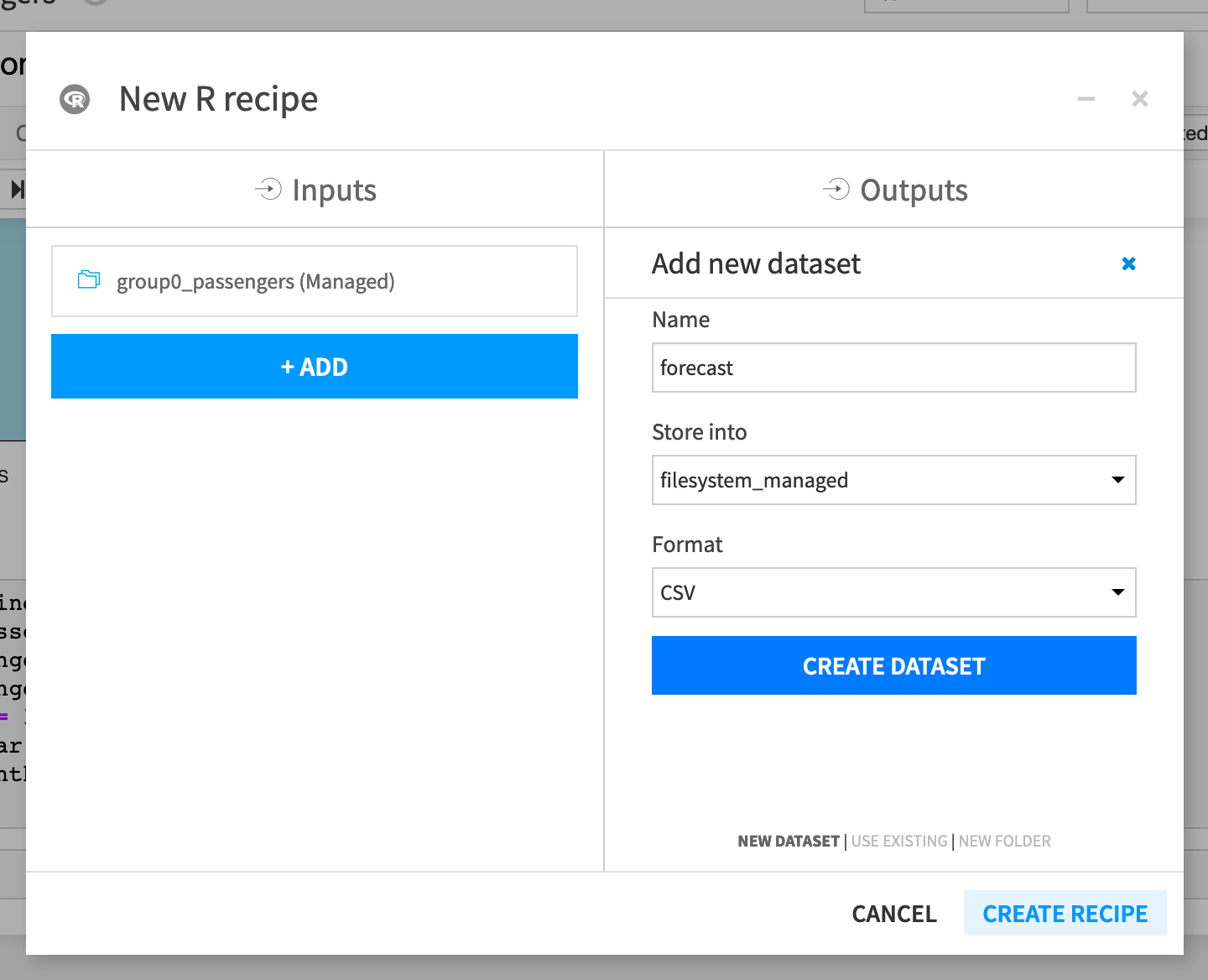
To deploy the model, you must create a new R recipe. In the notebook:
Click + Create Recipe > R recipe > OK.
Ensure that group0_passengers dataset is the input dataset.
Under Outputs, click + Add. Name the output dataset
forecast.Click Create Dataset.
Click Create Recipe.
If not already selected, set the code environment on the recipe’s Advanced tab to the one used in the notebook.
Click Run in the recipe editor to execute the recipe.
Open the forecast dataset to look at the new predictions.
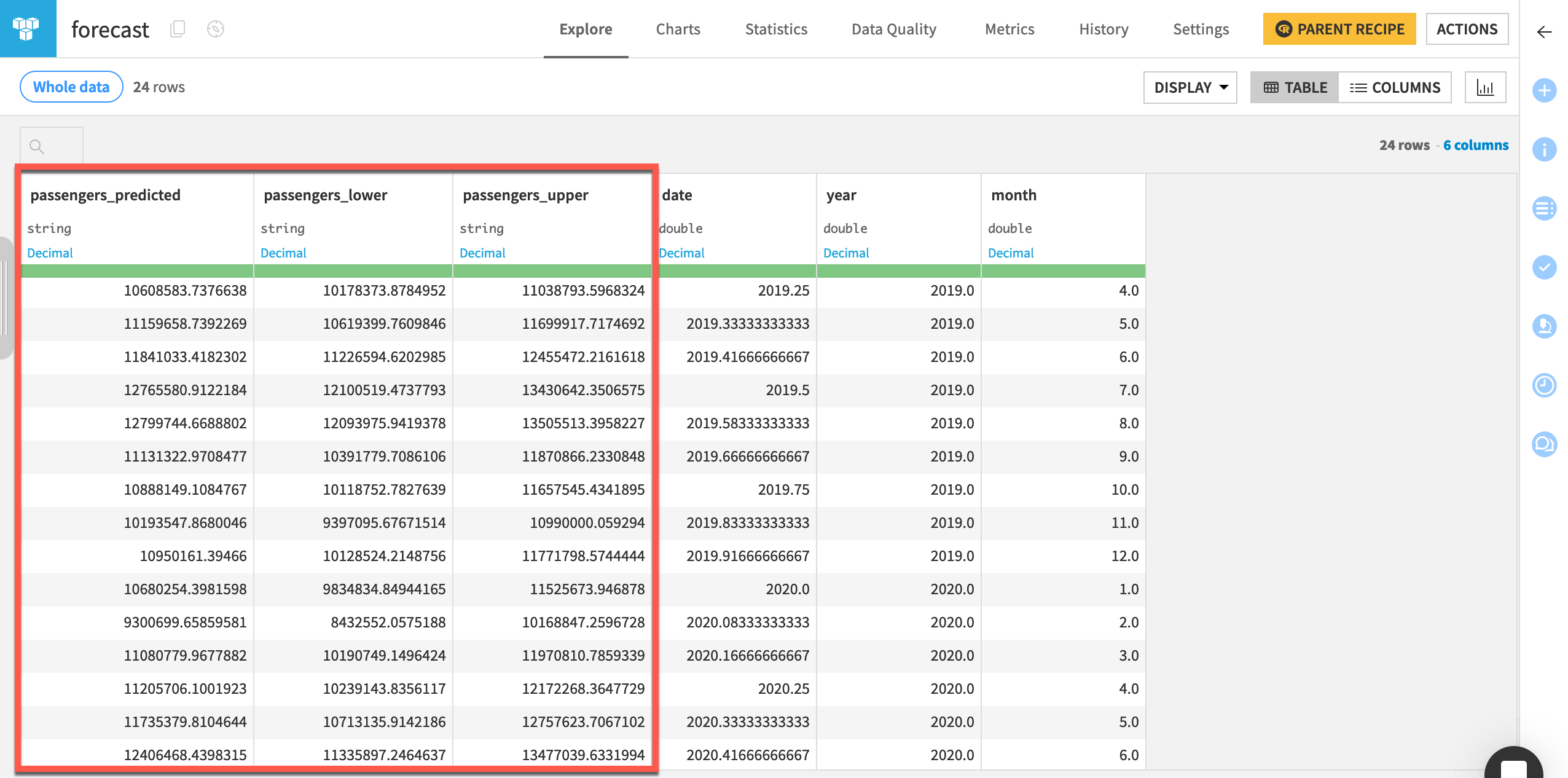
Tip
In a real situation, you’d optimize the code in the recipe to run only the portions that will output the forecast dataset.
Next steps#
Congratulations! Now that you have spent some time forecasting a time series dataset with R in Dataiku, you may also want to see Tutorial | Time series forecasting (visual ML) to perform time series forecasting without code.