
Tutorial | Enrich web logs in the Prepare recipe#
Get started#
Logs can be difficult and time-consuming to parse. Let’s see how a number of processors in the Prepare recipe can make this job easier!
Objectives#
In this tutorial, you will:
Parse and enrich web log data using Prepare recipe processors, such as Resolve GeoIP, Classify User-Agent, and Split URL.
Prerequisites#
Dataiku 12.0 or later.
Basic knowledge of Dataiku (Core Designer level or equivalent).
Create the project#
From the Dataiku Design homepage, click + New Project.
Select Learning projects.
Search for and select Web Log Enrichment.
If needed, change the folder into which the project will be installed, and click Create.
From the project homepage, click Go to Flow (or type
g+f).
Note
You can also download the starter project from this website and import it as a ZIP file.
Explore the data#
The starter project provides a randomly generated toy dataset to work with.
Even for standardized formats, such as Apache log files, one often needs to code several regular expressions to be able to extract all the information needed. Common fields include:
User (not available in this example)
Timestamp
Requested URL
Request status code
Size of the object returned
Referer (from where the user made the request)
User agent (user’s device)
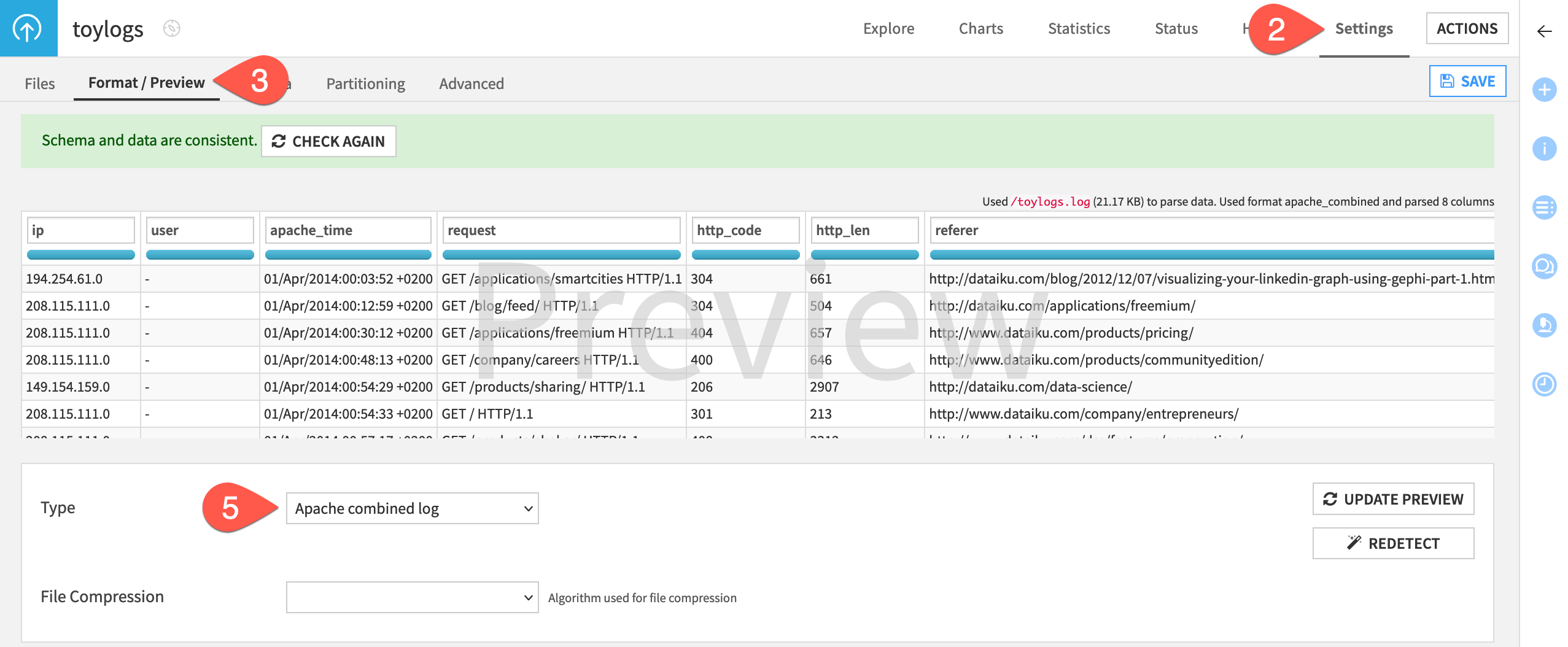
In the starter project, let’s take a look at how Dataiku automatically has detected the format Apache combined log and performed the log parsing on your behalf.
Open the toylogs dataset.
Navigate to the Settings tab near the top right corner.
Click on the Format / Preview subtab.
Click Preview This Dataset.
Note that Dataiku has recognized the file as an Apache combined log.
Create a visual analysis#
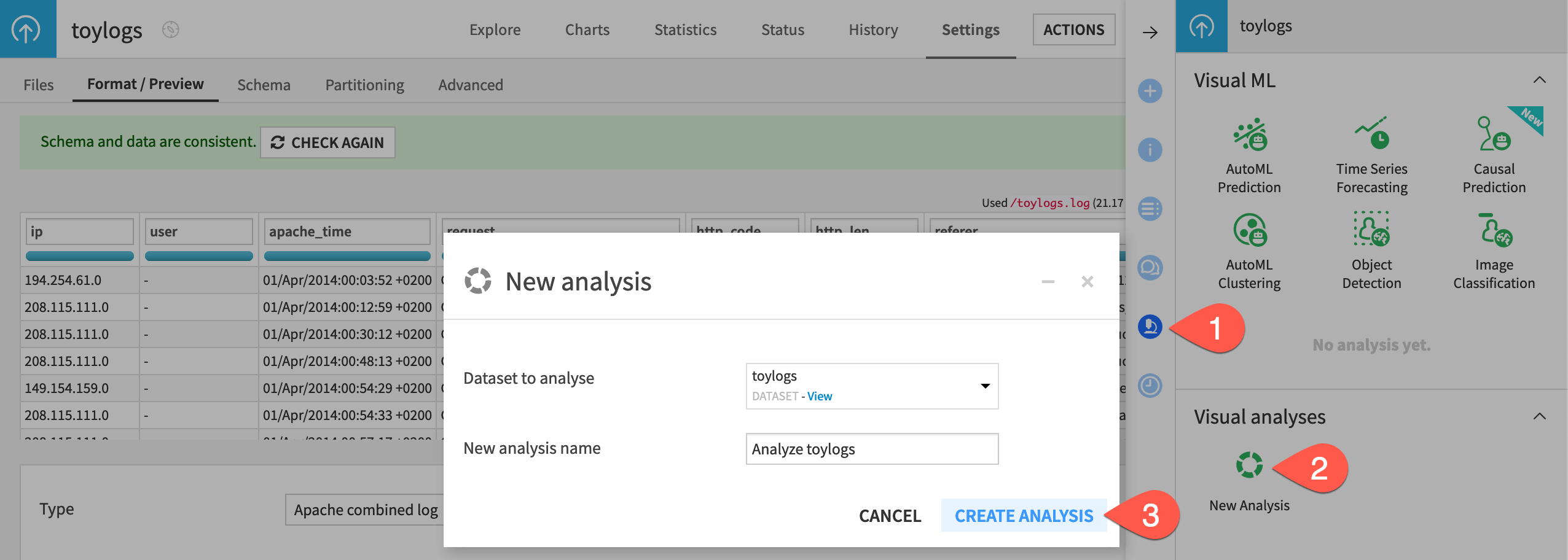
You could prepare this log data in a Prepare recipe or a visual analysis. Let’s choose the latter.
From the toylogs dataset, go to the Lab (
 ) in the right panel.
) in the right panel.Under Visual analyses, click New Analysis.
Click Create Analysis.
Resolve GeoIP addresses#
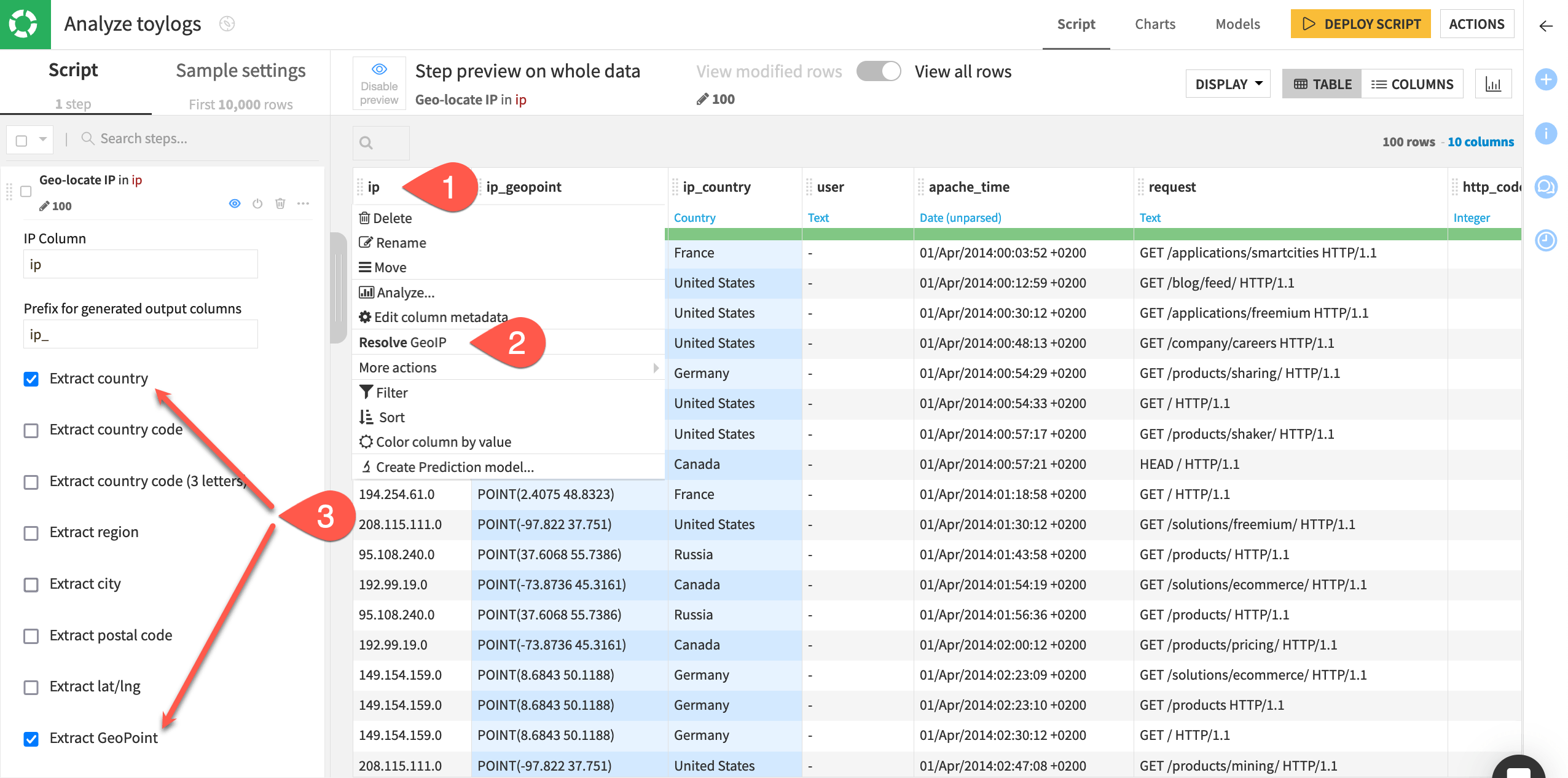
First extract geographic information from the IP address.
Open the column header dropdown for the ip column.
Select Resolve GeoIP.
Extract only the country and GeoPoint columns.
Tip
It’s possible to visualize the extracted geographic data on a map. See Tutorial | No-code maps to learn more.
Parse a user-agent information#
In a web log analysis, the user-agent information can help answer questions like:
Is the user on a computer, a phone, or a tablet?
Which browser is the most used on a website?
Which one generates the most error statuses?
Is there a correlation between the device used and the probability of a sale?
Extract this information now!
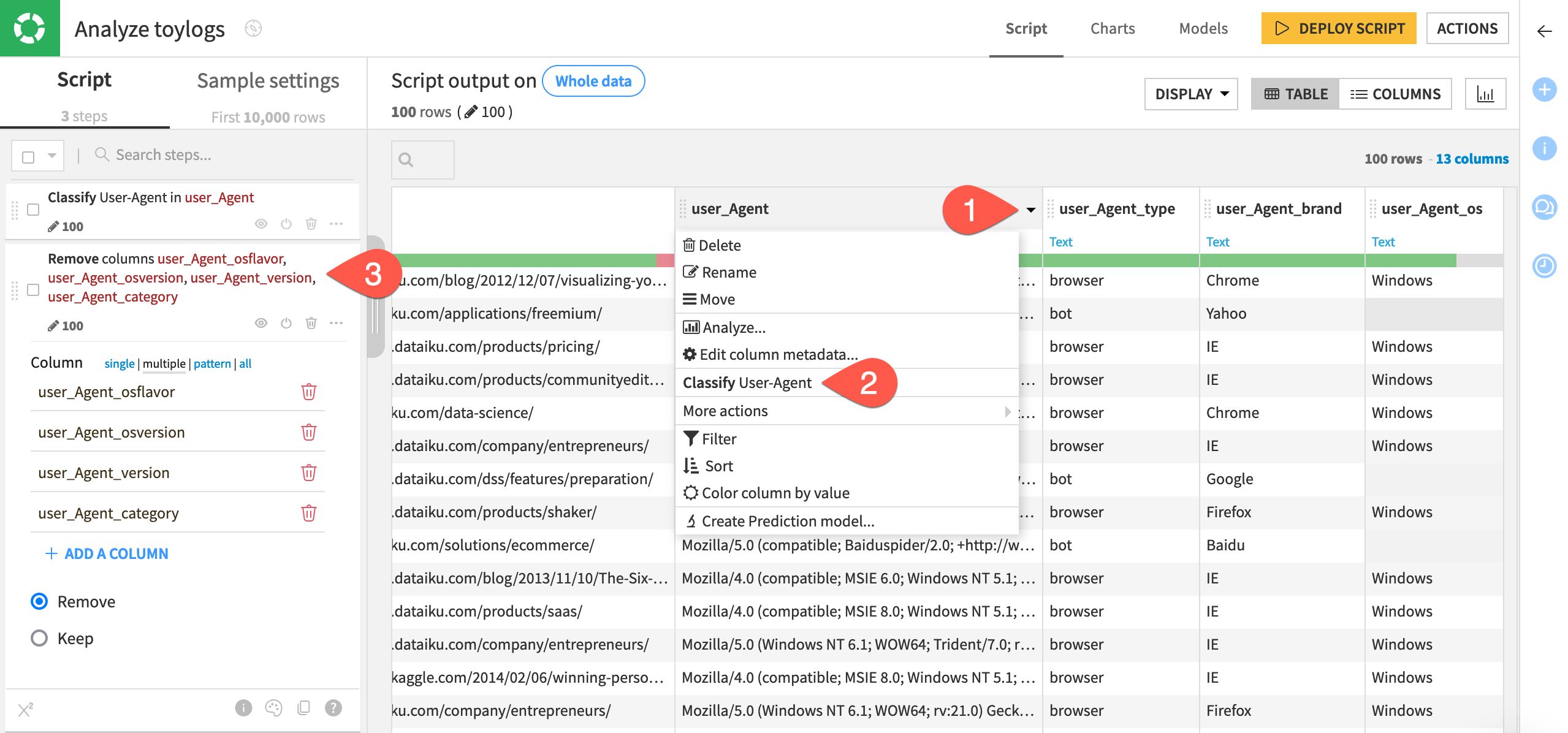
Open the column header dropdown for the user_Agent column.
Select Classify User-Agent.
Using the column header dropdown, delete the columns: user_Agent_category, user_Agent_version, user_Agent_osversion, user_Agent_osflavor — leaving only user_Agent_type, user_Agent_brand, and user_Agent_os.
Note
Dataiku suggests this particular step from the processor library because it has inferred the meaning of the this column to be User-Agent.
Clear invalid values based on column meaning#
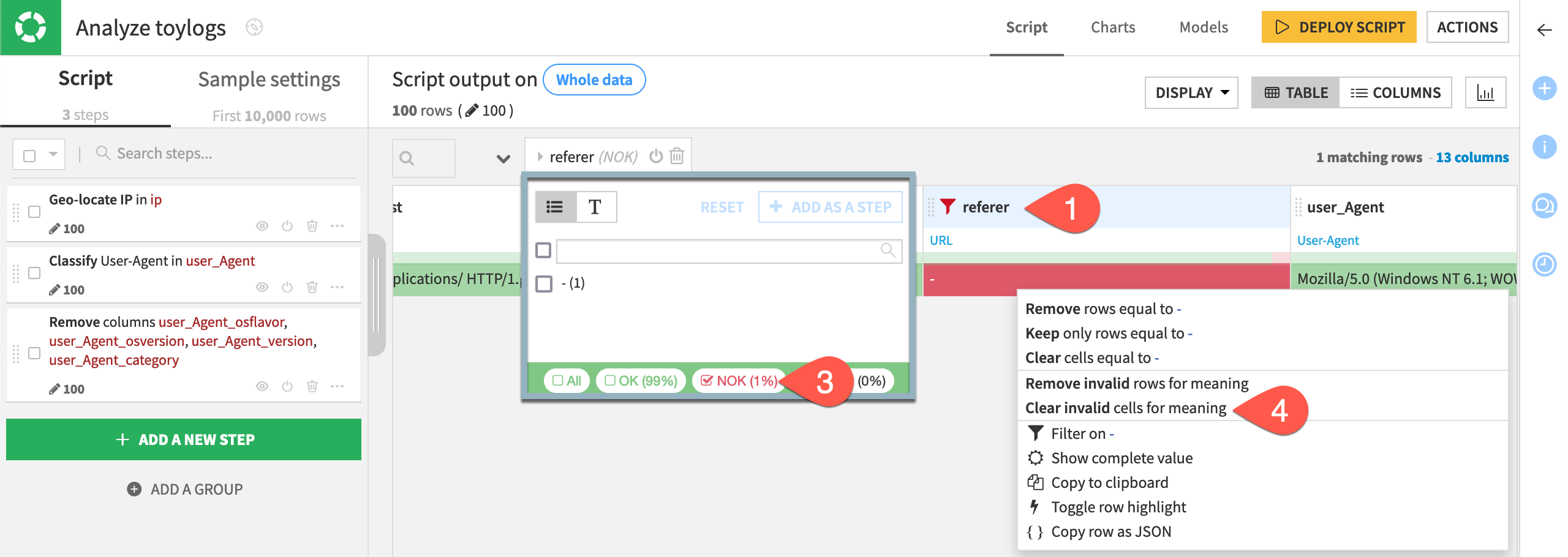
Now let’s turn attention to the referer URL, which details where visitors are coming from. The data quality bar underneath the column header shows that not all values in the column match the autodetected meaning for the referer column.
Find and clear these invalid values.
Open the column header dropdown for the referer column.
Select Filter.
Select NOK to show only the rows not matching the autodetected column meaning of URL.
Click on referer cell value not matching the URL meaning, and select Clear invalid cells for meaning.
Parse a referer URL#
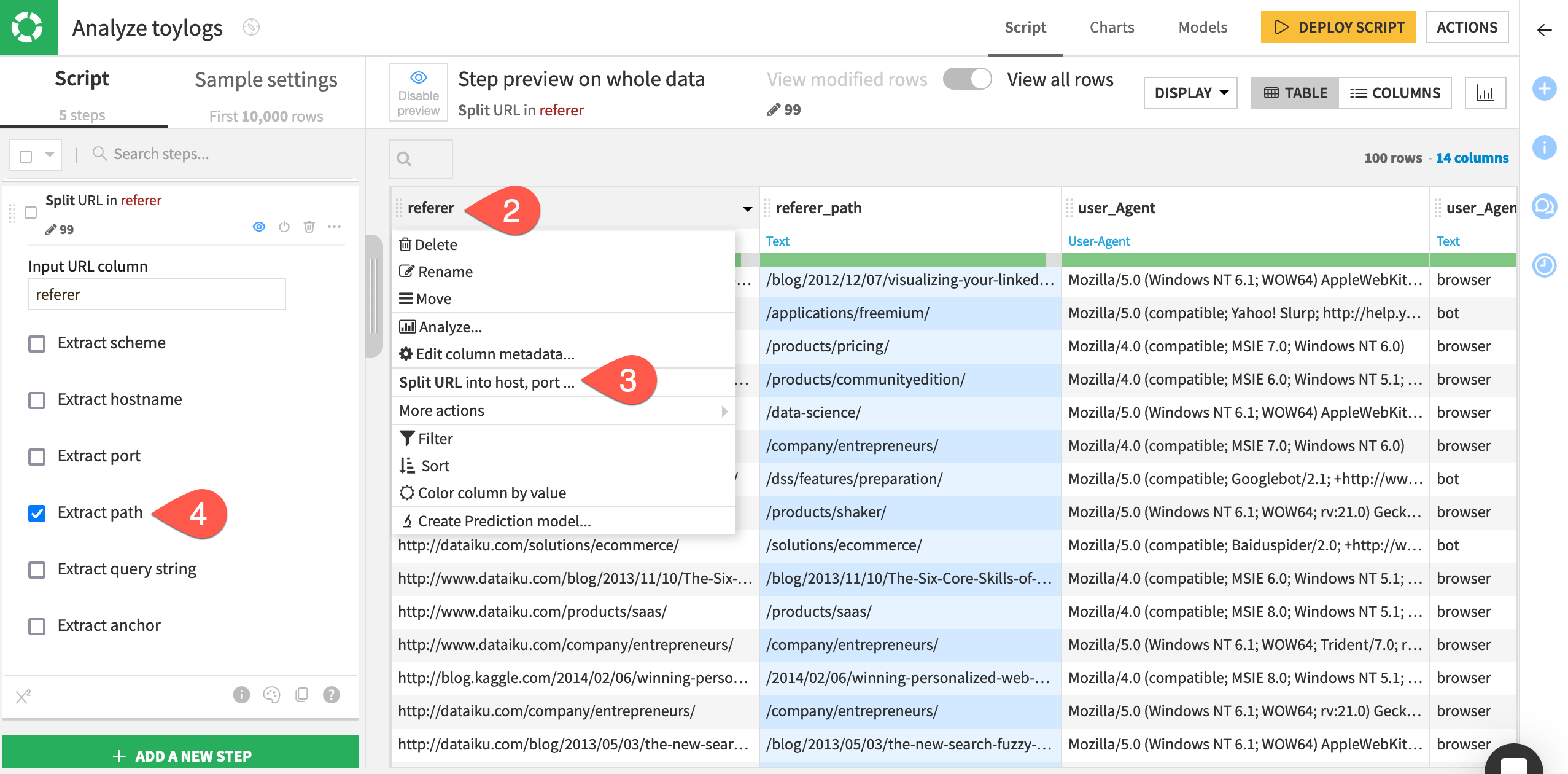
Based on the autodetected meaning of URL, Dataiku suggests a step for splitting the URL into host, port, and many other entities. In particular, let’s analyze the path for these URLs.
Delete the filter on the referer column.
Once again, open the column header dropdown for the referer column.
Select Split URL into host, port.
On the left, leave only Extract path select. Uncheck the other options.
Split a column#
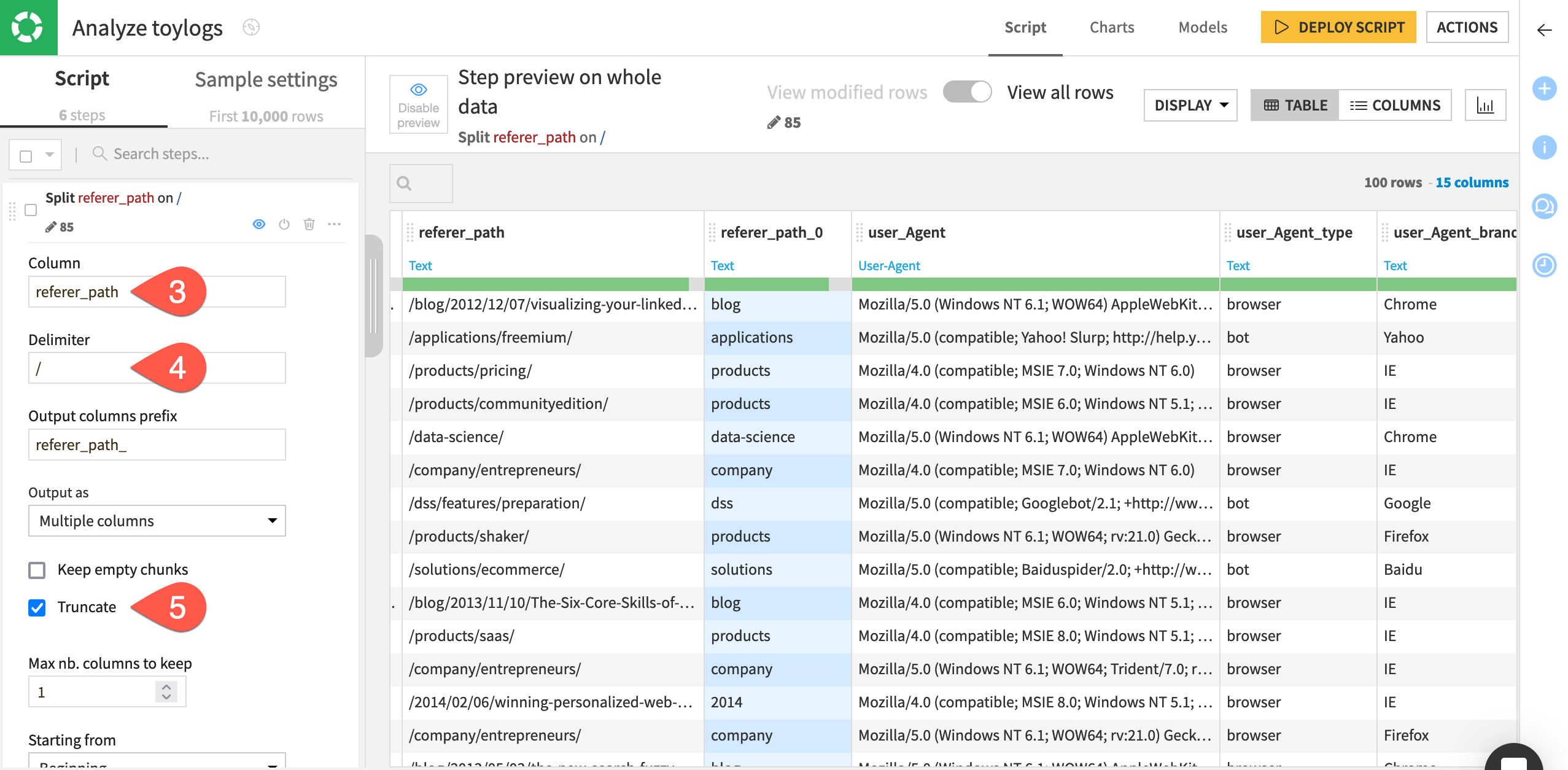
Keep working on the extracted URL paths.
Click + Add a New Step near the bottom left.
Select Split column from the processors library.
Provide referer_path as the column to split.
Provide
/as the delimiter.Check the box Truncate, and keep the default maximum of 1 column.
Next steps#
Congratulations! You’ve gained practice using Prepare recipe processors for extracting information from web log data without the need to code any regular expressions.
Before deploying the script as a Prepare recipe, you could continue this analysis in a variety of ways:
Use the Analyze tool on the referer_path_0 column to study where most requests come from.
Parse and extract date components from the apache_time column.
Split the request column as done for the referer column.
Visualize results with charts.
See also
You can find more information about all available Prepare recipe processors in the Processors reference section of the reference documentation.