Hands-On Tutorial: Perform Flow Actions¶
Understanding how the datasets and recipes behave and interact in the Flow is key to knowing what kinds of Flow actions to perform, when to perform these actions, and how to perform them efficiently.
Let’s Get Started!¶
In this hands-on lesson, you will learn to:
perform schema consistency checks and propagate schema changes in the Flow;
build datasets, keeping in mind their dependencies; and
change dataset connections in the Flow.
Advanced Designer Prerequisites
This lesson assumes that you have basic knowledge of working with Dataiku DSS datasets and recipes.
Note
If not already on the Advanced Designer learning path, completing the Core Designer Certificate is recommended.
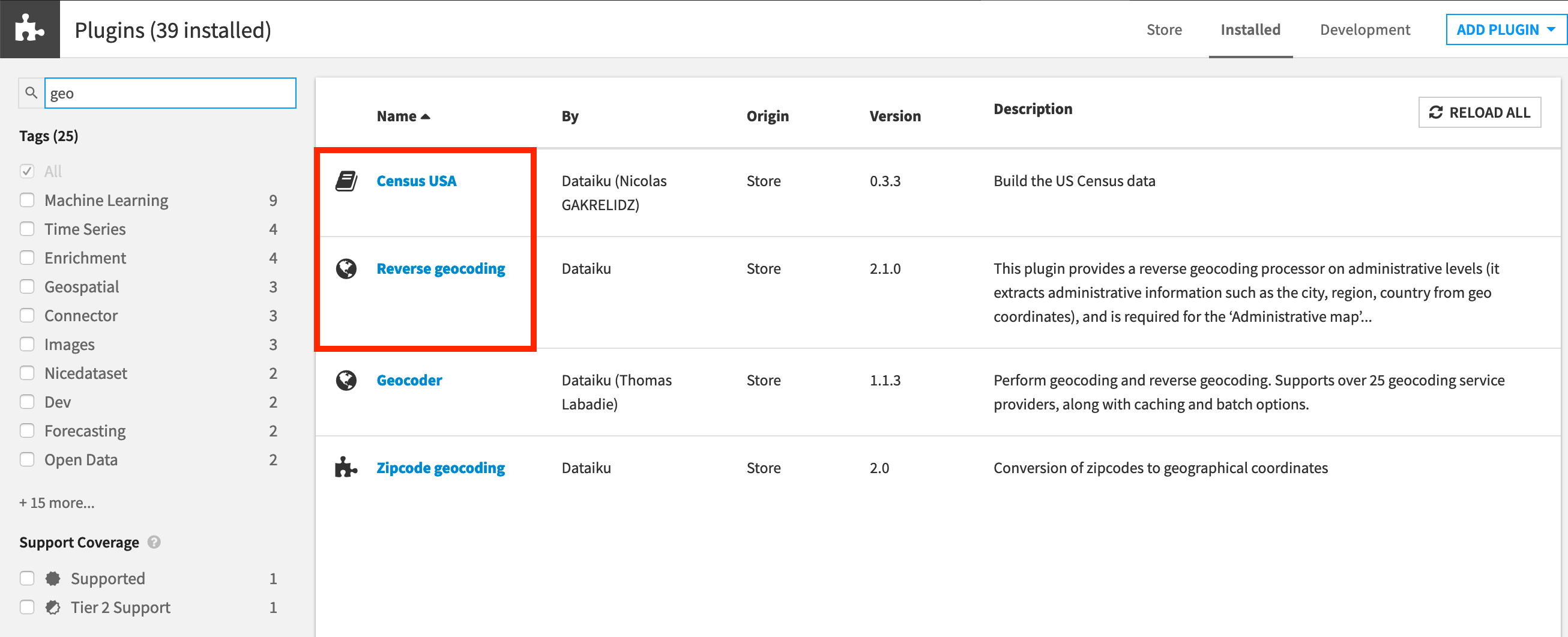
You’ll need access to an instance of Dataiku DSS (version 9.0 or above) with the following plugins installed:
Census USA (minimum version 0.3)
These plugins are available through the Dataiku Plugin store, and you can find the instructions for installing plugins in the reference documentation. To check whether the plugins are already installed on your instance, go to the Installed tab in the Plugin Store to see a list of all installed plugins.
Note
We also recommend that you complete the lessons on Schema Propagation & Consistency Check, Connection Changes & Flow Item Reuse, and Dataset Building Strategies beforehand.
Plugin Installation for Dataiku Online Users
Tip
Users of Dataiku Online should note that while plugin installation is not directly available, you can still explore available plugins from your launchpad:
From your instance launchpad, open the Features panel on the left hand side.
Click Add a Feature and choose “US Census” from the Extensions menu. (“Reverse geocoding” is already available by default).
You can see what plugins are already installed by searching for “installed plugins” in the DSS search bar.
Create the Project¶
Click +New Project > DSS Tutorials > Advanced Designer > Flow Views & Actions (Tutorial).
Note
You can also download the starter project from this website and import it as a zip file.
Change Dataset Connections (Optional)
Aside from the input datasets, all of the others are empty managed filesystem datasets.
You are welcome to leave the storage connection of these datasets in place, but you can also use another storage system depending on the infrastructure available to you.
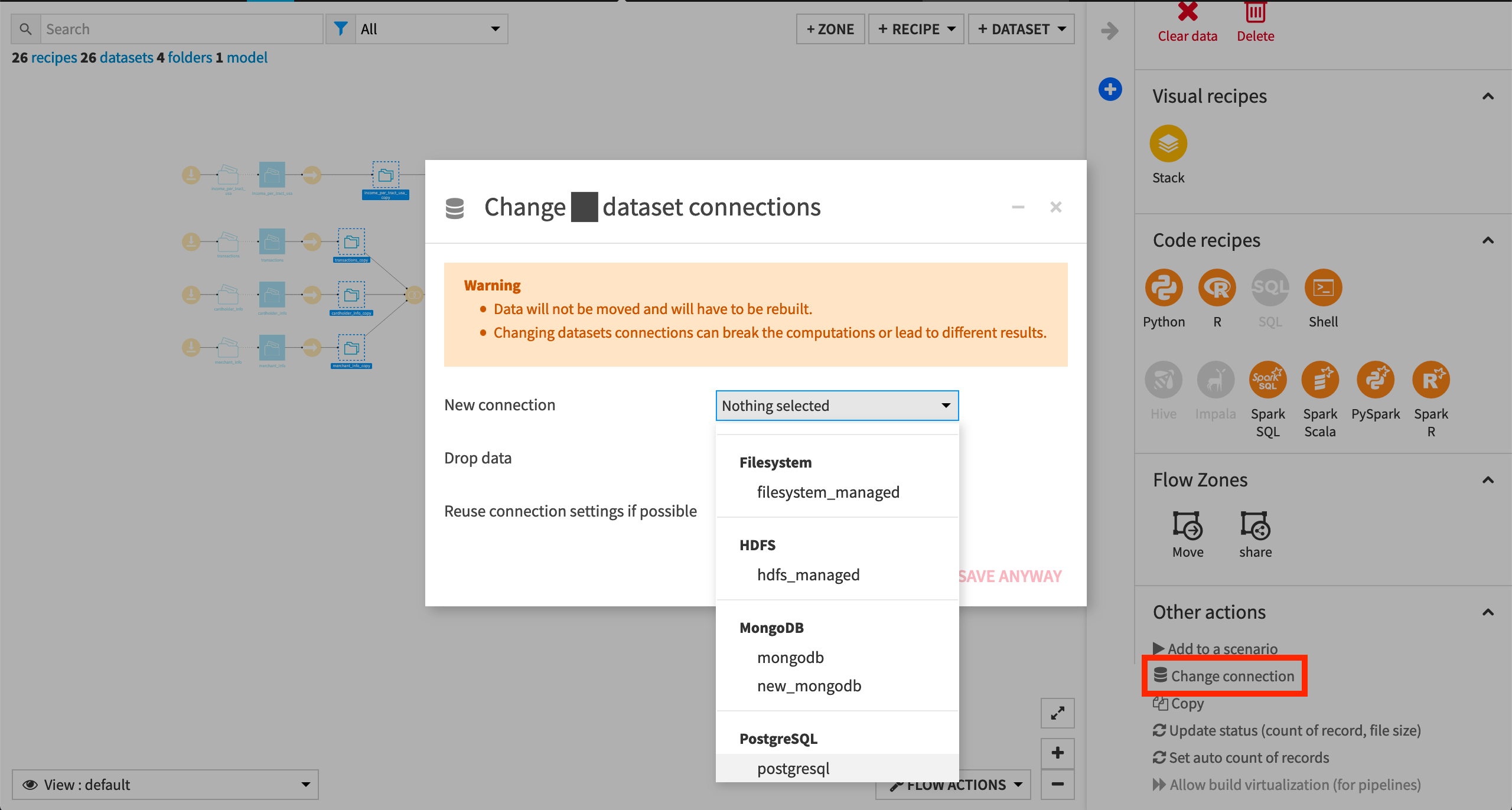
To use another connection, such as a SQL database, follow these steps:
Select the empty datasets from the Flow. (On a Mac, hold Shift to select multiple datasets).
Click Change connection in the “Other actions” section of the Actions sidebar.
Use the dropdown menu to select the new connection.
Click Save.
Note
For a dataset that is already built, changing to a new connection clears the dataset so that it would need to be rebuilt.
Note
Another way to select datasets is from the Datasets page (G+D). There are also programmatic ways of doing operations like this that you’ll learn about in the Developer learning path.
The screenshots below demonstrate using a PostgreSQL database.
Whether starting from an existing or fresh project, ensure that the entire Flow is built.
See Build Details Here if Necessary
To build the entire Flow, click Flow Actions at the bottom right corner of the Flow.
Select Build all.
Build with the default “Build required dependencies” option for handling dependencies.
Note
See the article on Dataset Building Strategies and the product documentation on Rebuilding Datasets to learn more about strategies for building datasets.
Consistency Checks¶
Changes in a recipe or in upstream datasets can lead to dataset schema changes downstream in the Flow. Therefore, it is useful to perform schema consistency checks and keep the Flow up-to-date by propagating schema changes downstream in the Flow. We’ll begin by showing how to perform consistency checks.
Automatic Consistency Checks¶
Dataiku DSS automatically performs a consistency check when you save and run a recipe. Let’s try this out by editing one of the recipes in the Flow.
Open the compute_transactions_joined_prepared recipe (the recipe after the transactions_joined dataset)
Add a Copy column step that duplicates the content of the transaction_id column into a new column
dup_transaction_id.Click Run. The “Schema changes” message appears because Dataiku DSS has detected a change in the number of columns for the recipe’s output dataset.
Accept the schema update to finish running the recipe and building the dataset transactions_joined_prepared.
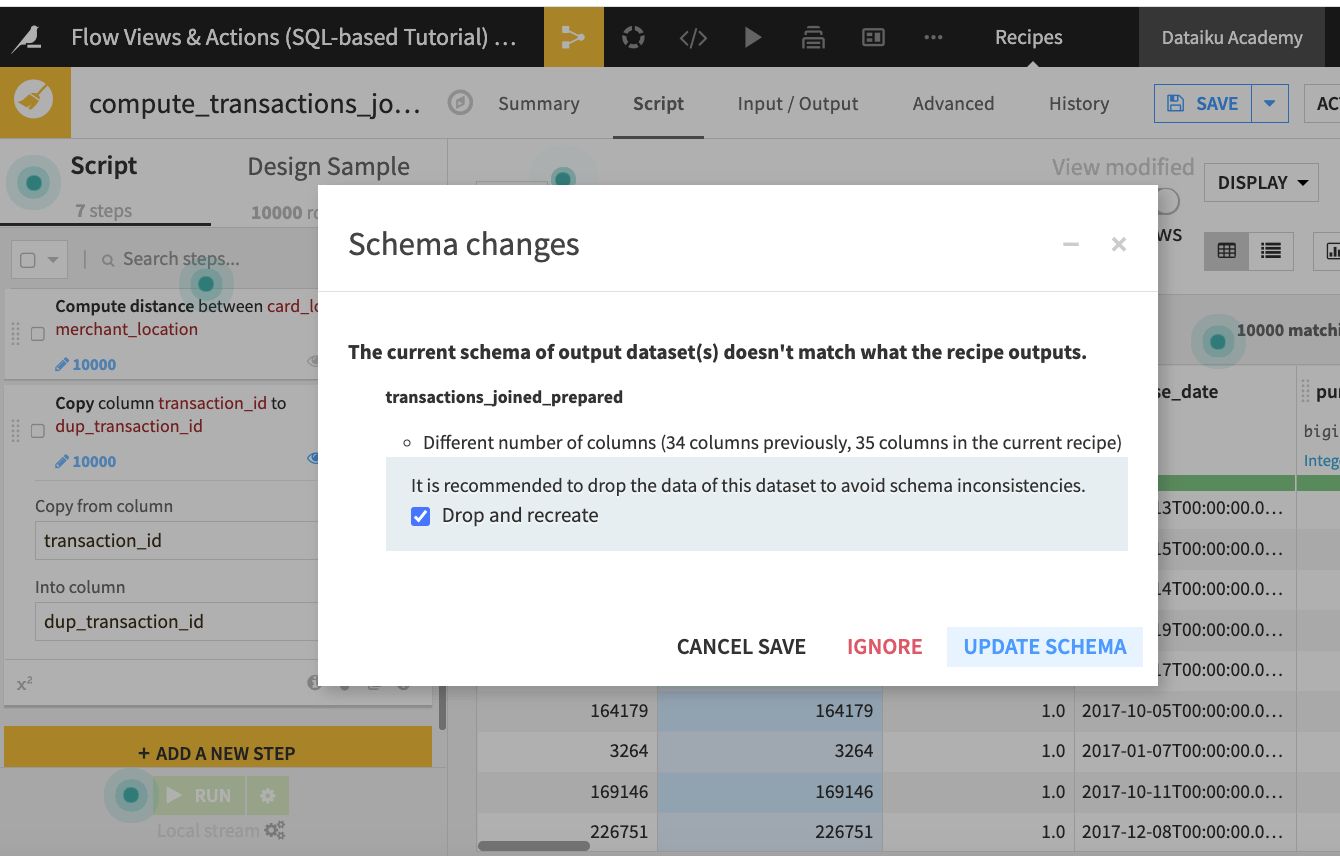
Consistency Check Tool - When It Detects a Schema Change¶
Now, let’s use the Consistency check tool to check the Flow.
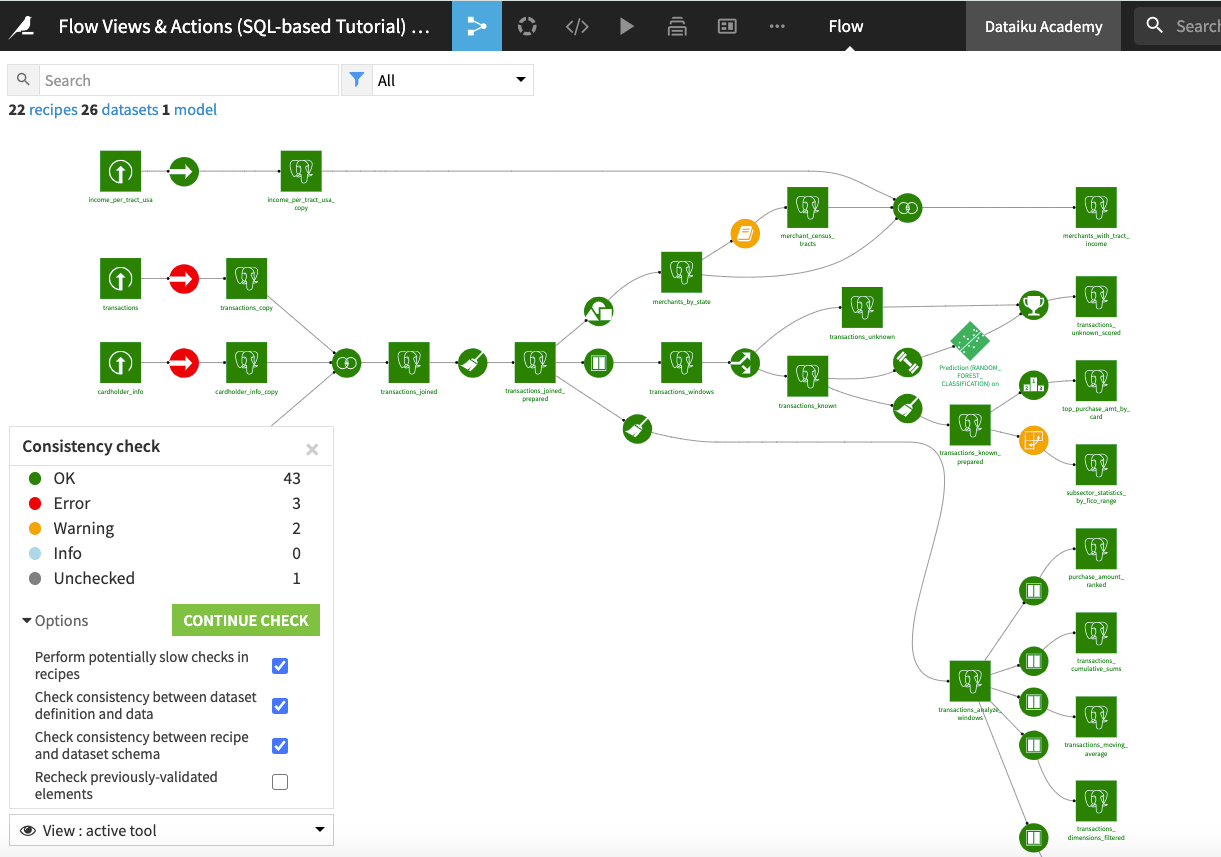
From the Flow Actions menu, click Check consistency.
Keeping the default selections for the “Options”, click Start Check.
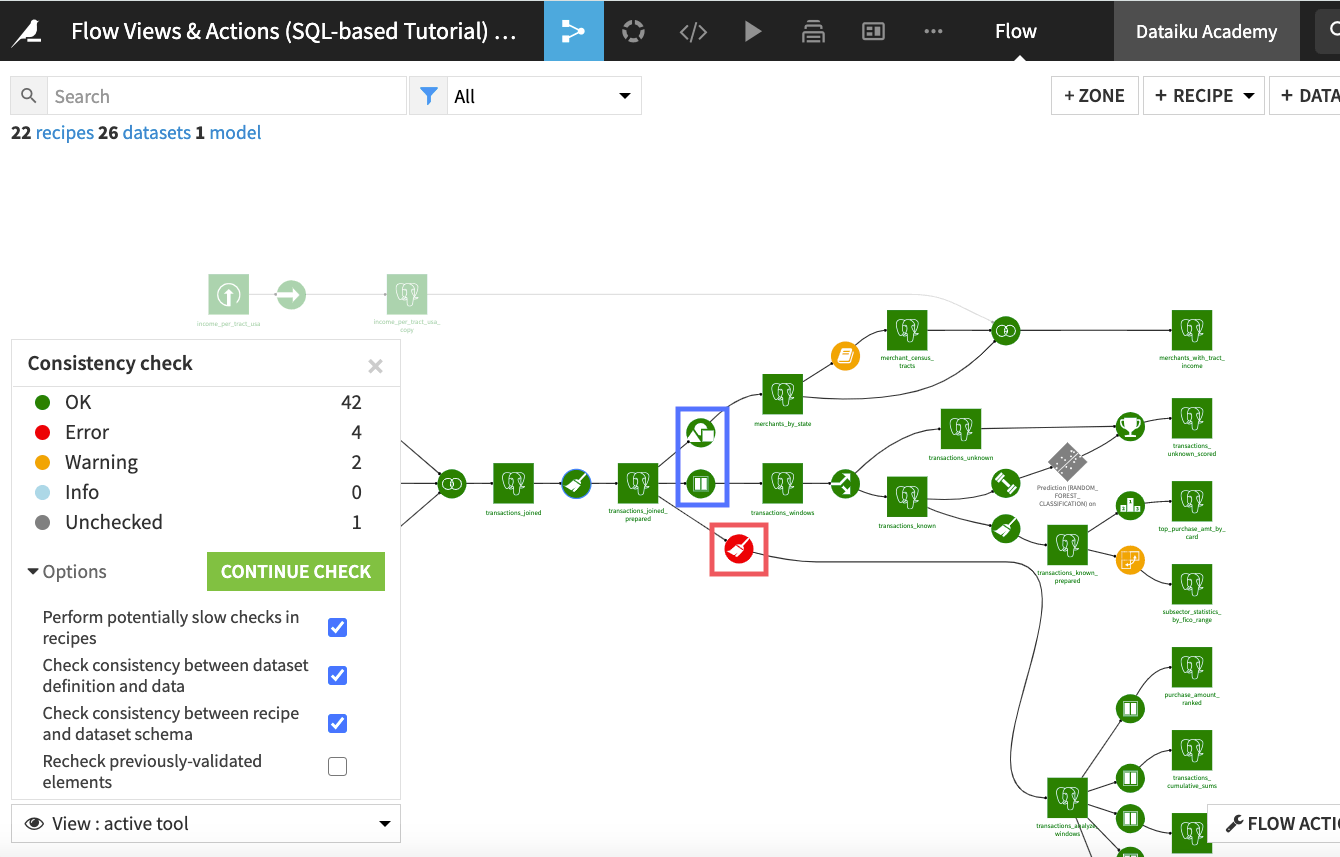
Dataiku DSS detects an error in the immediate downstream Prepare recipe, but not in the immediate downstream Group or Window recipe. Clicking the downstream Prepare recipe (in red) displays that the error is due to a change in the number of columns of the dataset used by the recipe.

For now, click Mark as OK to ignore the error. Later on in the lesson, we will show how to resolve schema inconsistencies. Close the consistency check tool.
Consistency Check Tool - When It Fails to Detect a Schema Change¶
You may be wondering why the consistency check did not detect an error in the immediate downstream Group recipe or Window recipe. Instead, those recipes were marked as “OK”.
To investigate, open the compute_transactions_joined_prepared_windows_1 Window recipe.
Indeed, the “Aggregations” step of the recipe shows that the recipe is aware of the new column dup_transaction_id.
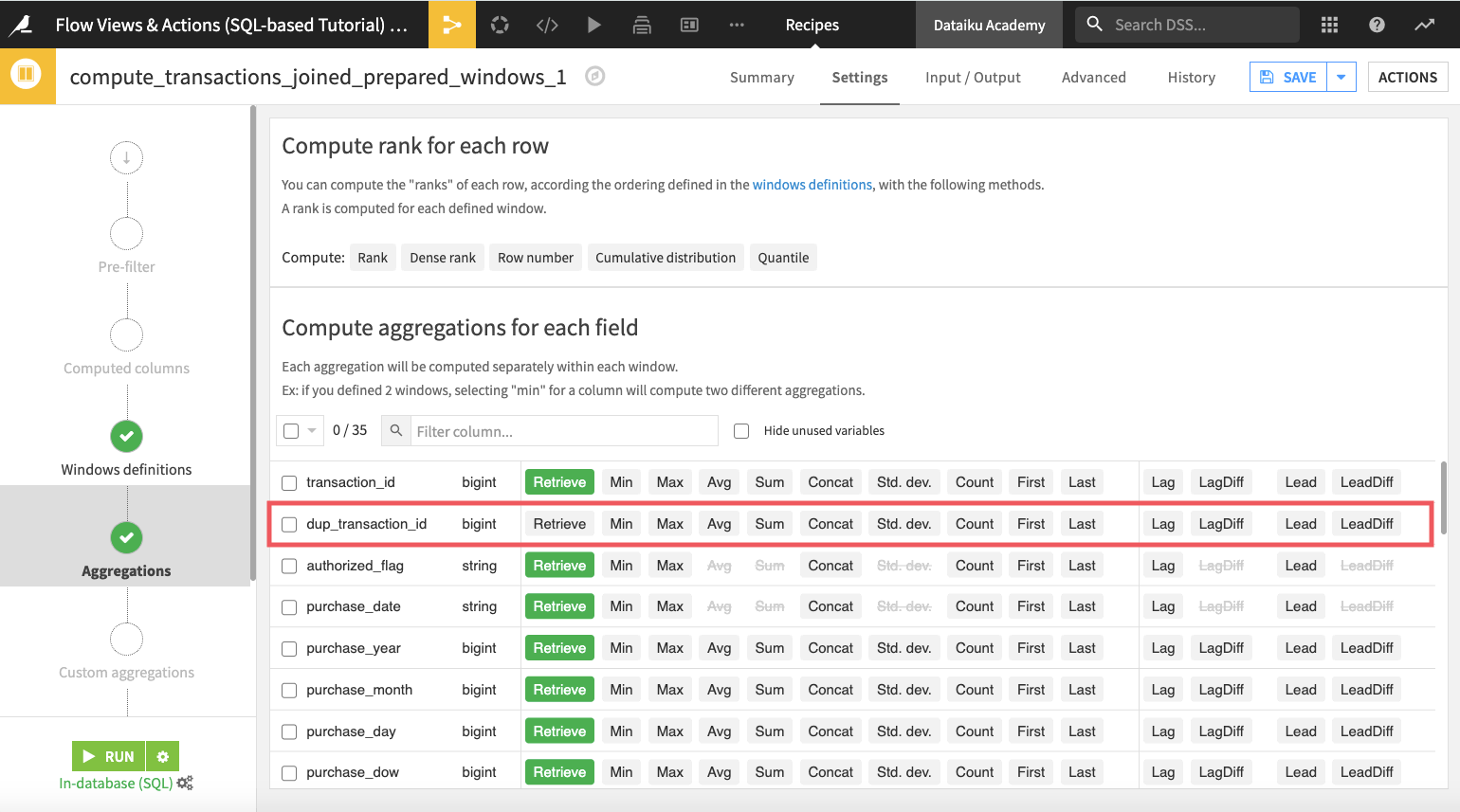
However, because this new column is not used anywhere in the Window recipe (e.g. it is not retrieved in the “Aggregations” step, or used in any other step), the output schema of the Window recipe is unchanged. A similar explanation also applies to the Group recipe.
Return to the Flow, ignoring any warning about unsaved changes in the Window recipe.
Now, let’s see another situation where the consistency check tool fails to detect a schema change. For this, we are going to edit the compute_transactions_joined_prepared Prepare recipe again. This time, though, we will change the storage type for one of its columns.
In the compute_transactions_joined_prepared Prepare recipe, first, delete the step where we added the duplicate transaction ID column.
Then change the storage type of the column purchase_year from “bigint” to “string”.
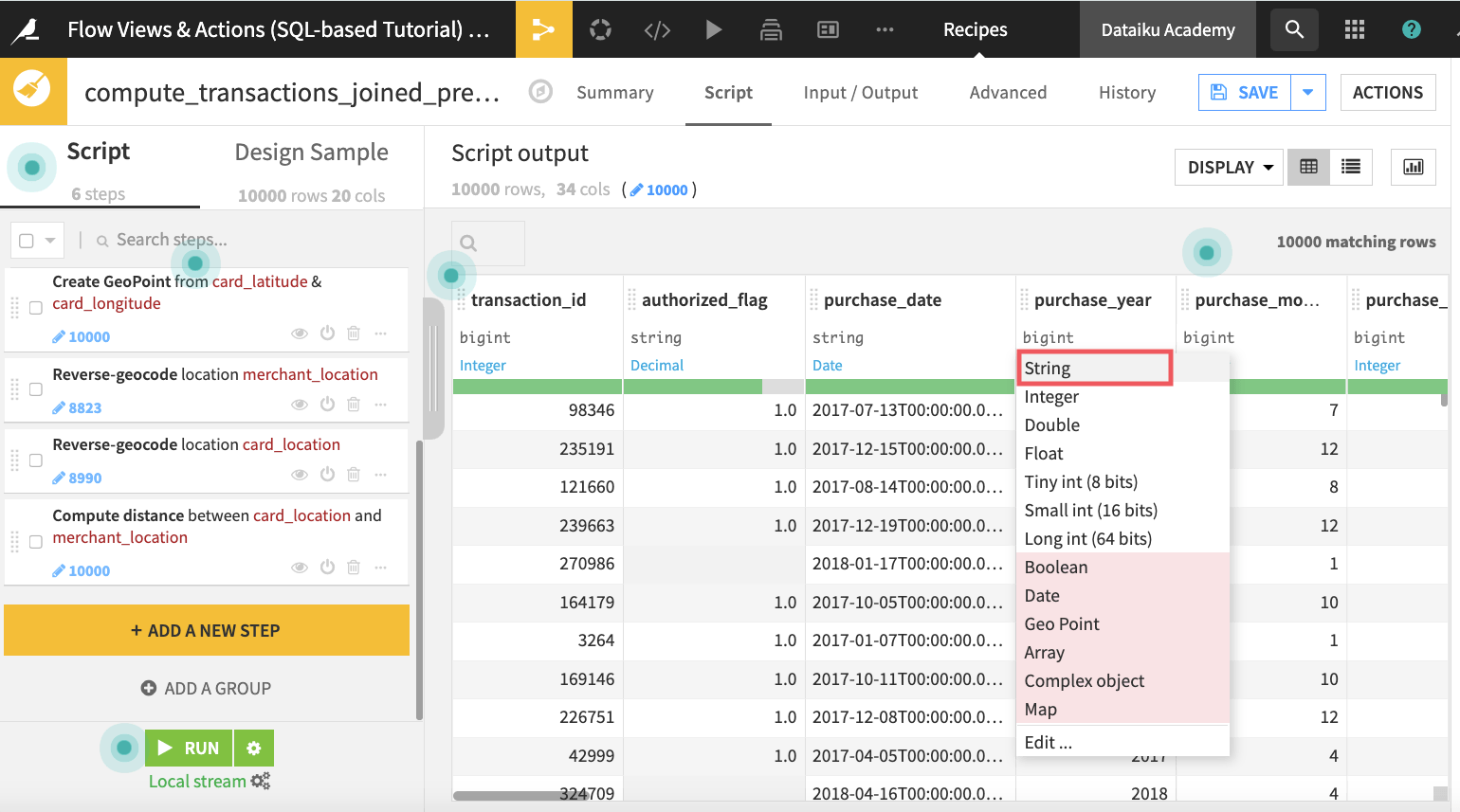
Run the recipe and accept the schema update.
Returning to the Flow, perform the consistency check on the entire Flow again.
This time, Dataiku DSS finds an error with the immediate downstream Window recipe, but not with the downstream Prepare recipe, and still not with the downstream Group recipe.
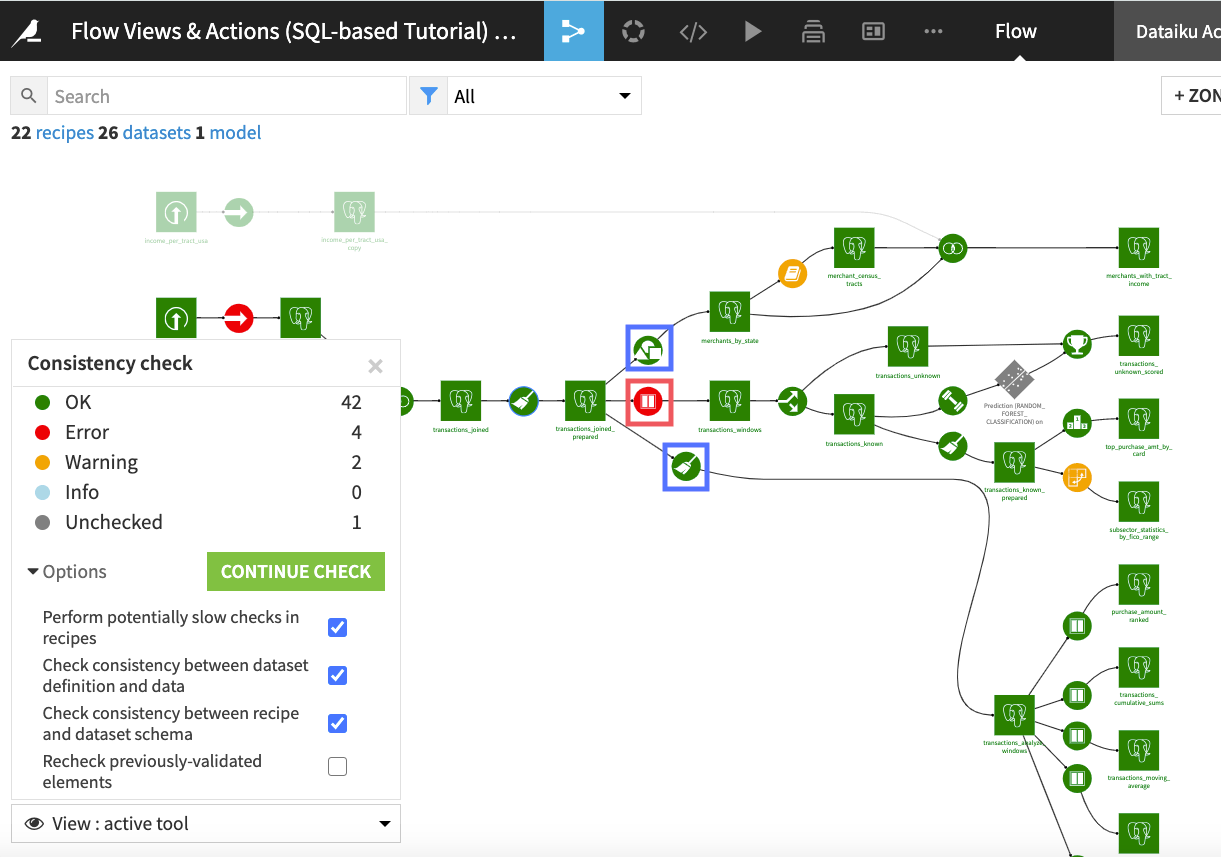
Note that a Prepare recipe always infers the data storage type from the sample of its input dataset, regardless of what is specified in the input dataset’s schema. As a result, the downstream Prepare recipe ignores the change we just made to the column storage type, since the data sample itself did not change in a way for the inferred schema to be different.
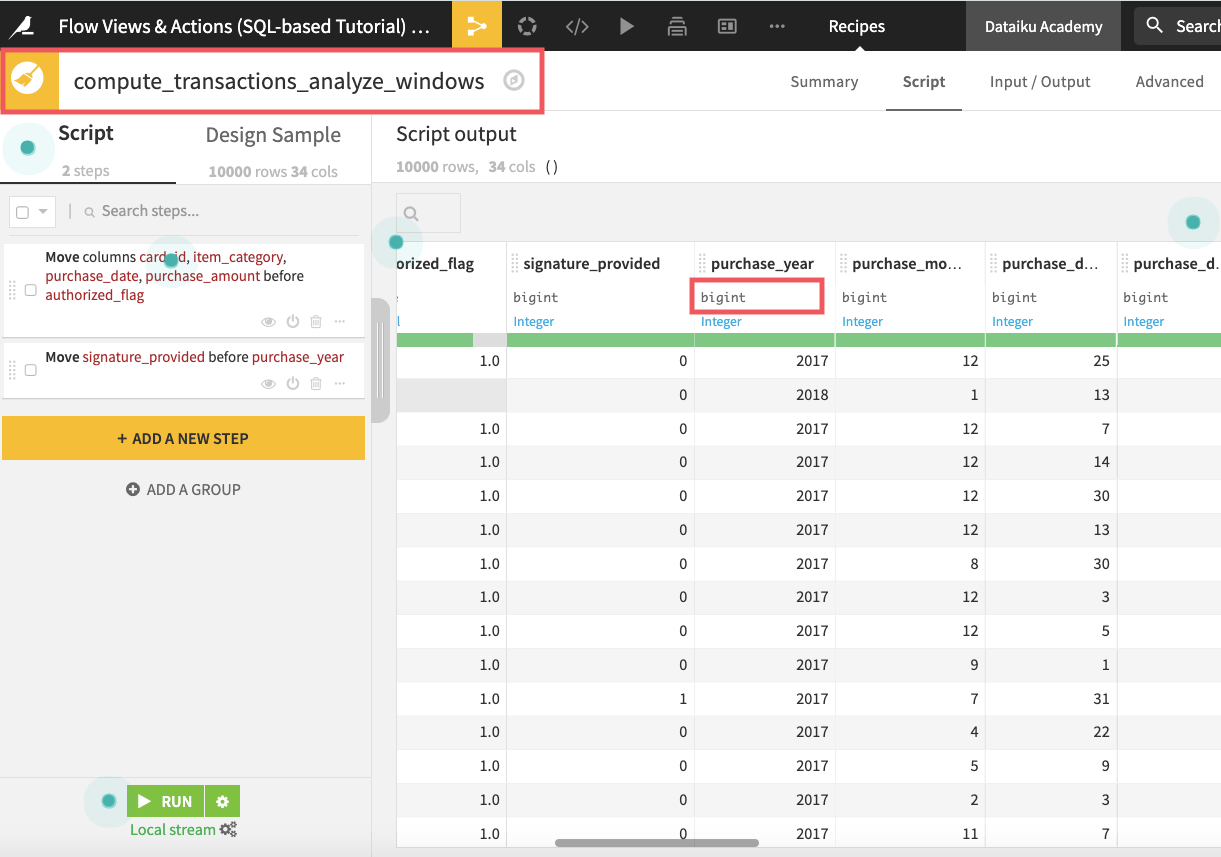
In fact, opening up the downstream Prepare recipe (compute_transactions_analyze_windows), we see that the column type for purchase_year is back to “bigint”.
Schema Propagation¶
We can resolve the error in the Window recipe by opening the recipe and saving (or doing a force save with “ctrl” + “s”) it to propagate the schema changes. We could also run the recipe (and accept the schema update), and it will propagate the schema and rebuild the dataset.
After running the Window recipe, we can perform the consistency check again, ensuring that the “Check consistency between recipe and dataset schema” option is selected. Now, the tool finds no issues with the Window recipe.
Although it was easy to resolve the schema discrepancy in the Window recipe, it would be impractical to have to open every recipe that requires a schema update, especially for large Flows. For this reason, we have the schema propagation tool in the Flow.
Schema Propagation Tool¶
To demonstrate this tool, let’s first create a situation for the schema check to fail in the compute_transactions_joined_prepared Prepare recipe.
Open the compute_transactions_joined Join recipe (the first join recipe in the Flow), and uncheck the product_title column from the “Selected columns” step.
Run the recipe and accept the schema update.
Now, when we run the consistency check tool from the Flow Actions menu, as expected, the compute_transactions_joined_prepared prepare recipe gives an error because the number of columns used in the recipe has changed.
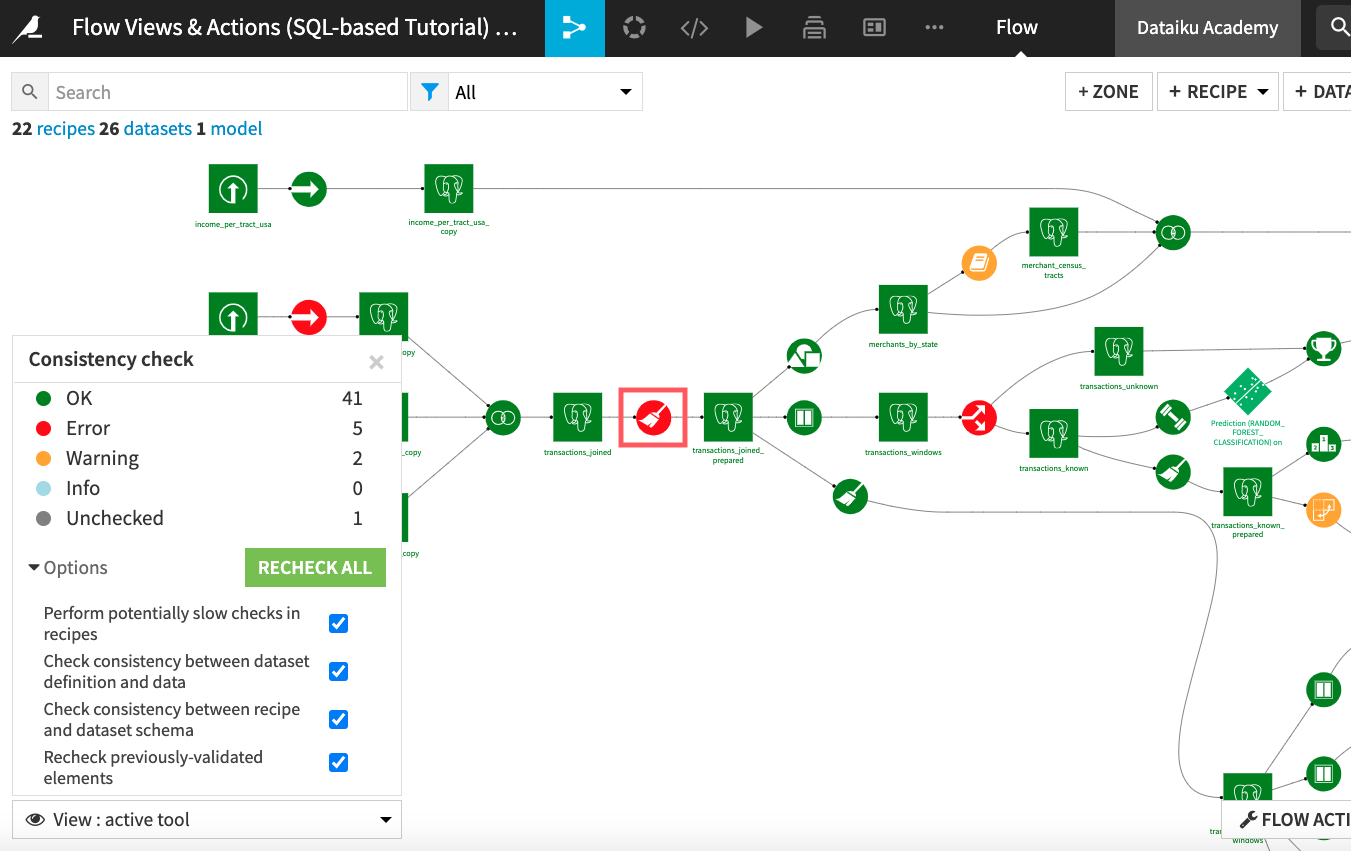
We will resolve this error by using the schema propagation tool.
Manual Schema Propagation¶
To manually use the schema propagation tool to resolve the error in the Prepare recipe:
Right-click the transactions_joined dataset, and click Propagate schema across Flow from here.
Click Start to begin the propagation of schema changes.
Click the Prepare recipe (in red) to see the error message.
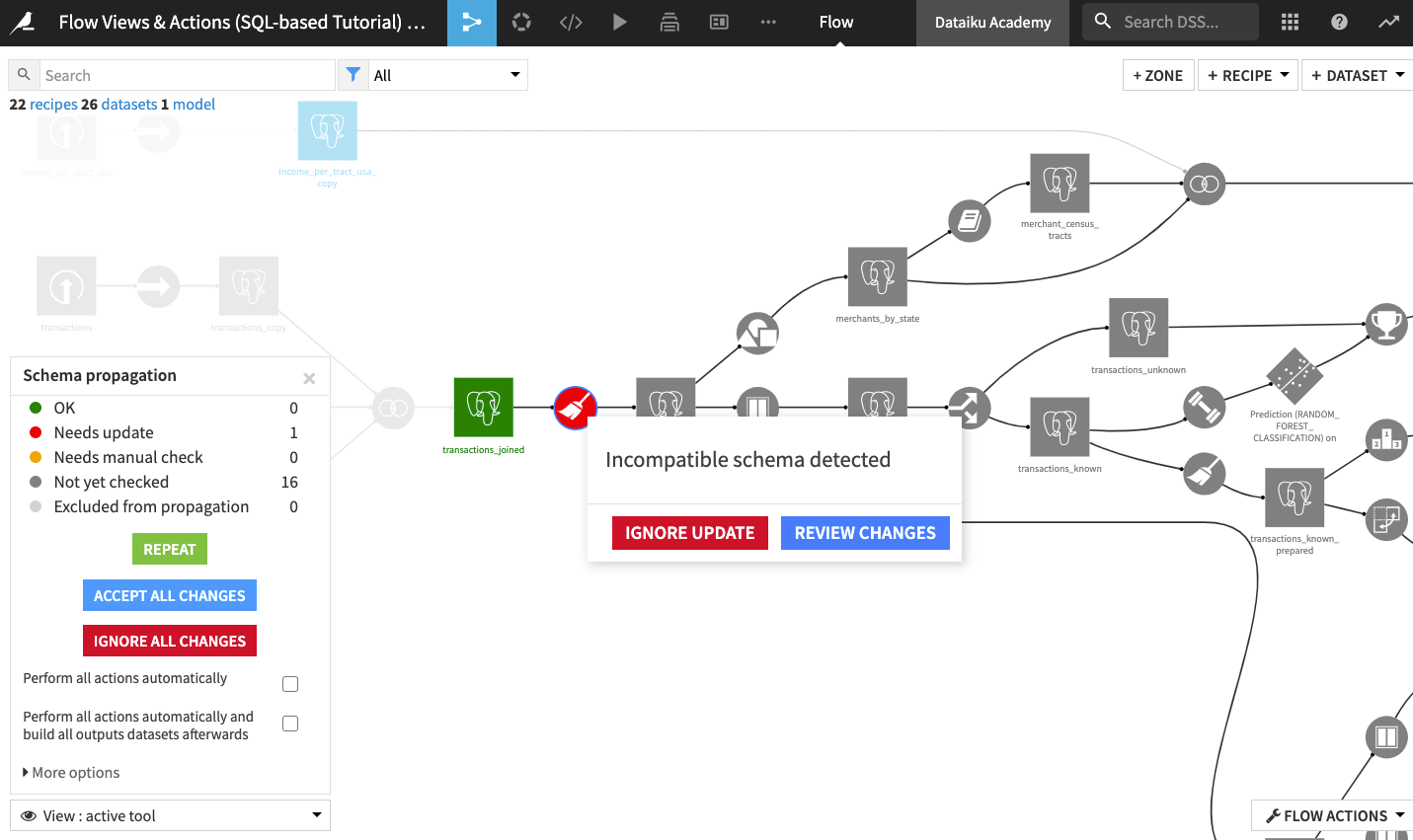
Click Review Changes for more details about the incompatible schema error.

The message informs us that the error is due to a change in the number of columns. Click Update Schema.
After updating the schema, notice that the transactions_joined_prepared dataset (in yellow) needs a manual check. This is because the downstream Window recipe (which uses this dataset as input) needs the actual data from the dataset to compute its output schema. Click the dataset and you will see this explanation.
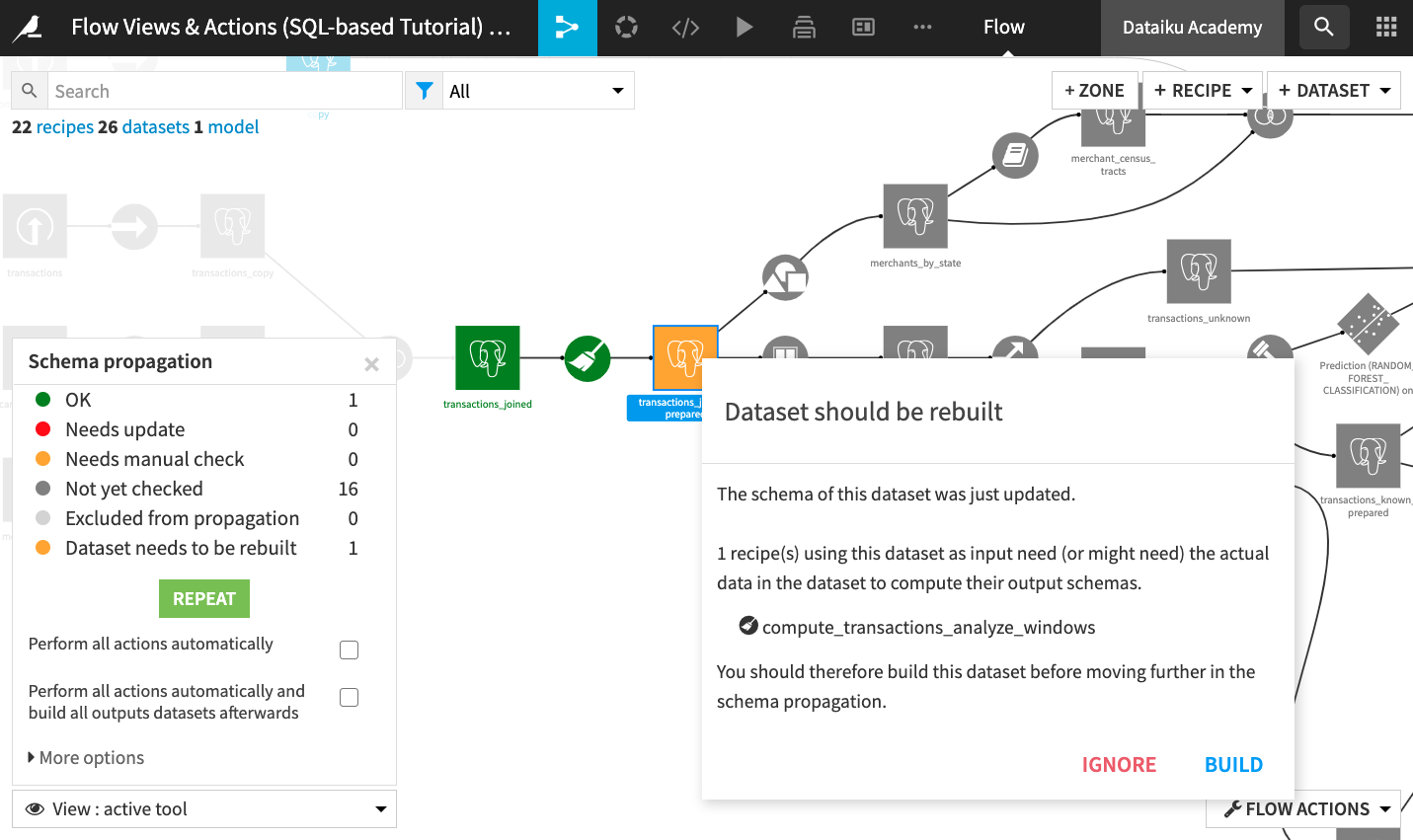
Click Build and choose the default non-recursive build to build only this dataset. Once the build is complete, you’ll see that the transactions_joined_prepared dataset is now green and marked as “OK”.
Automatic Schema Propagation¶
Schema propagation involves a repetition of these steps (updating a dataset’s schema and building the dataset).
To automate this process, enable the option “Perform all actions automatically and build all output datasets afterwards”.
Then click Repeat to launch automatic schema propagation.
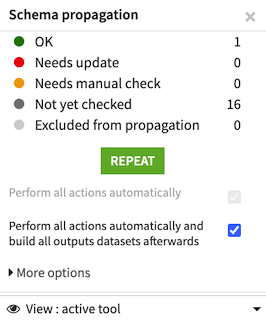
The schema propagation tool now attempts to update schemas and rebuild downstream datasets. For some recipes, the automatic schema propagation is successful, but it fails for others.
Looking at the Flow, the schema propagation worked just fine until it reached some downstream Window recipes (in purple to indicate that the checks failed).
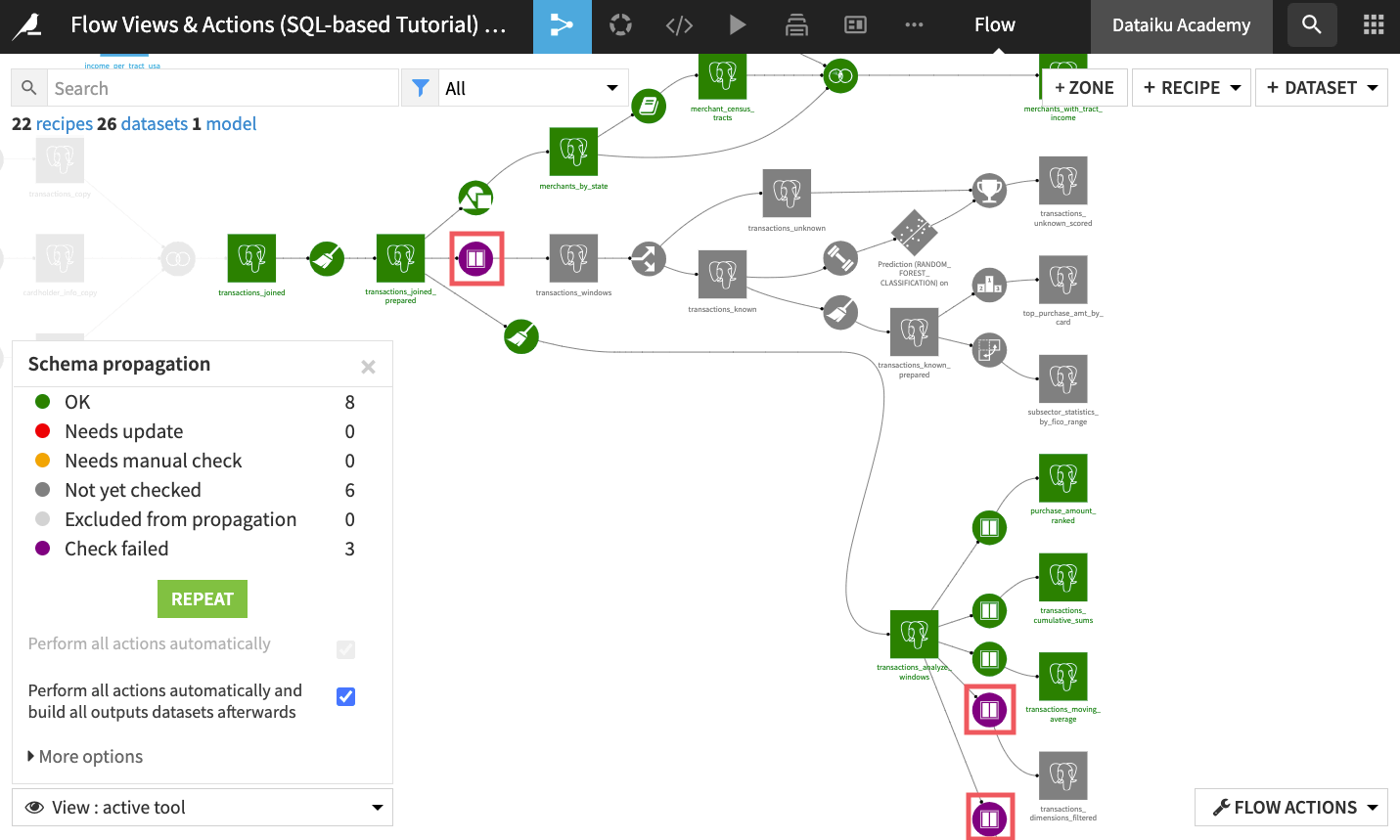
Clicking the first of those recipes, we see that the error stems from a missing column, the product_title column that we unselected in the settings of an earlier Join recipe (compute_transactions_joined). This column is used for aggregations in the downstream Window recipes, hence the failed checks.
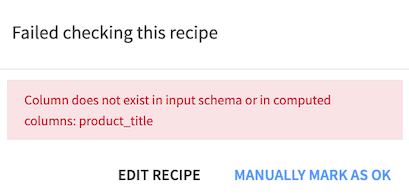
If we clicked Manually Mark as OK, Dataiku DSS would ignore the schema inconsistency in this Window recipe.
Since we want to fix it, click Edit Recipe.
When the recipe opens up, the product_title column which had previously been used for computing aggregations is no longer listed in the Aggregations step of the recipe.
Click Save and accept the schema update.
Returning to the Flow, enable the “Perform all actions automatically and build all output datasets afterwards” option again and click Start. This will update the schema of the Split recipe and rebuild the transactions_known and transactions_unknown datasets.
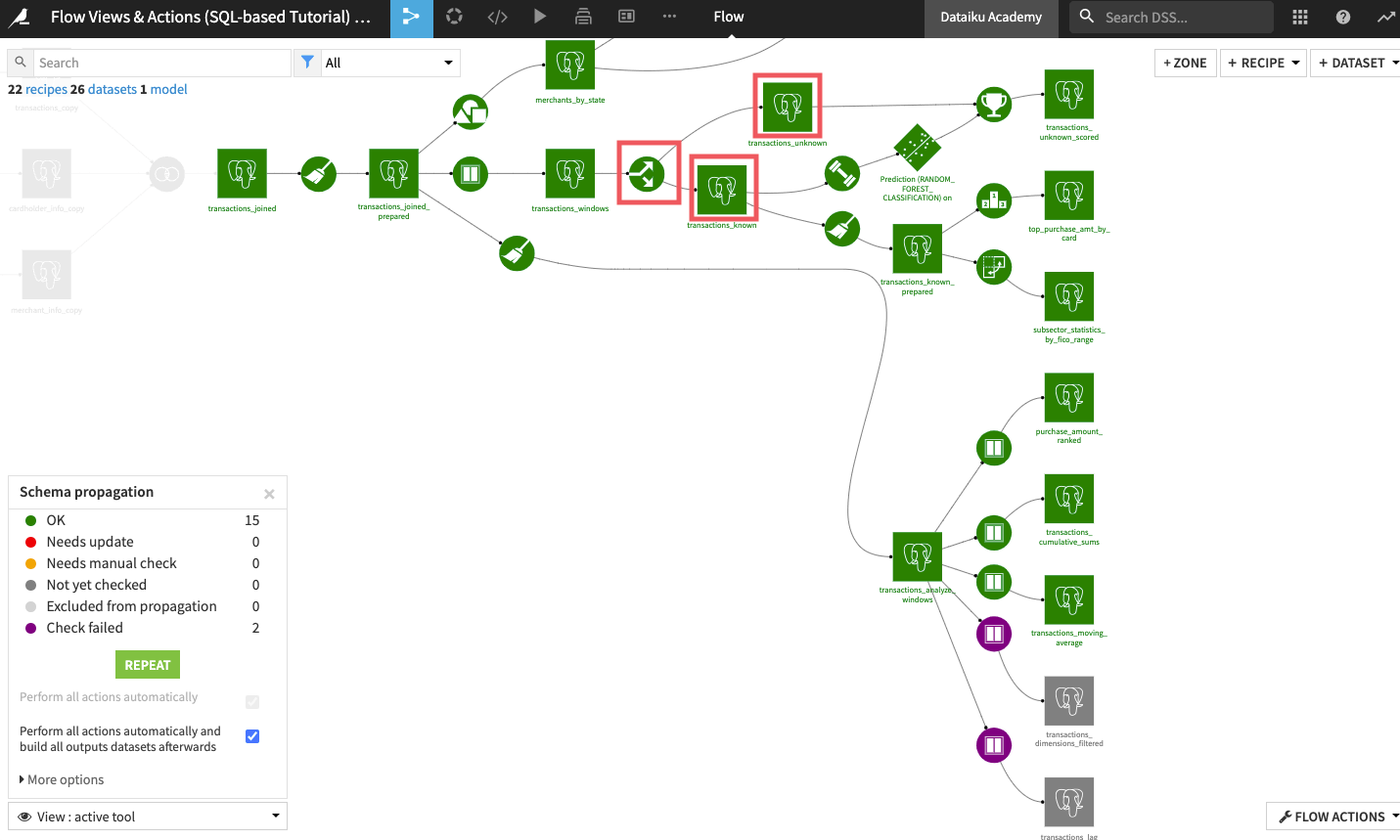
The same applies to the two remaining downstream Window recipes (that build the transactions_lag and transactions_dimensions_filtered datasets). These recipes also use the product_title column to compute aggregations. You can fix their errors by manually opening and saving the recipes to update the schemas of their output datasets.
Rebuild Your Flow¶
Dataiku DSS allows you to control the rebuilding of a Flow (or parts of it).
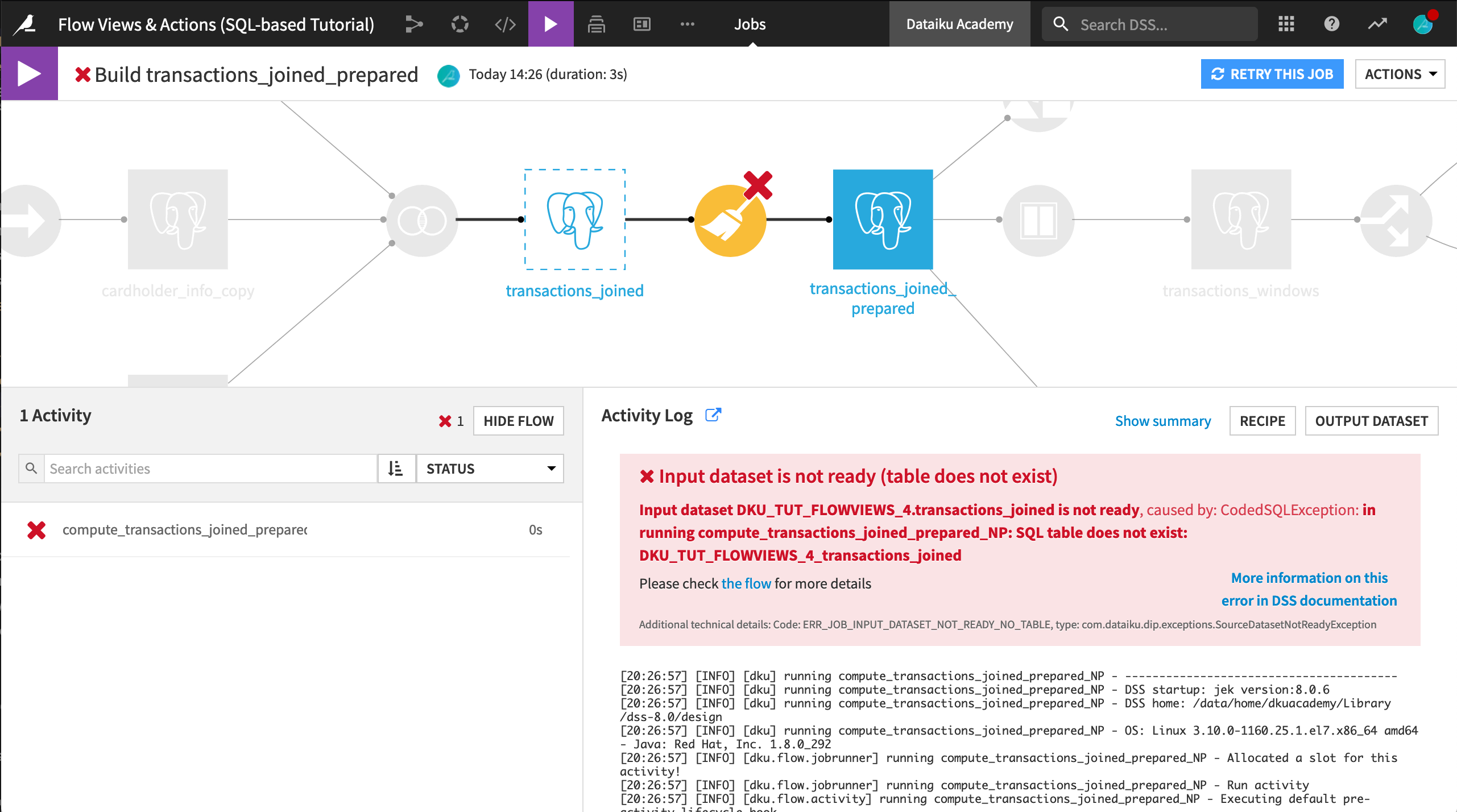
To demonstrate this, select transactions_joined from the Flow, and click Clear data from the Actions sidebar.
Attempt the default non-recursive build of transactions_joined_prepared. This means that Dataiku DSS will try to execute the compute_transactions_joined_prepared recipe.
This job fails because the input dataset no longer exists.
In this case, a recursive build can fix this problem.
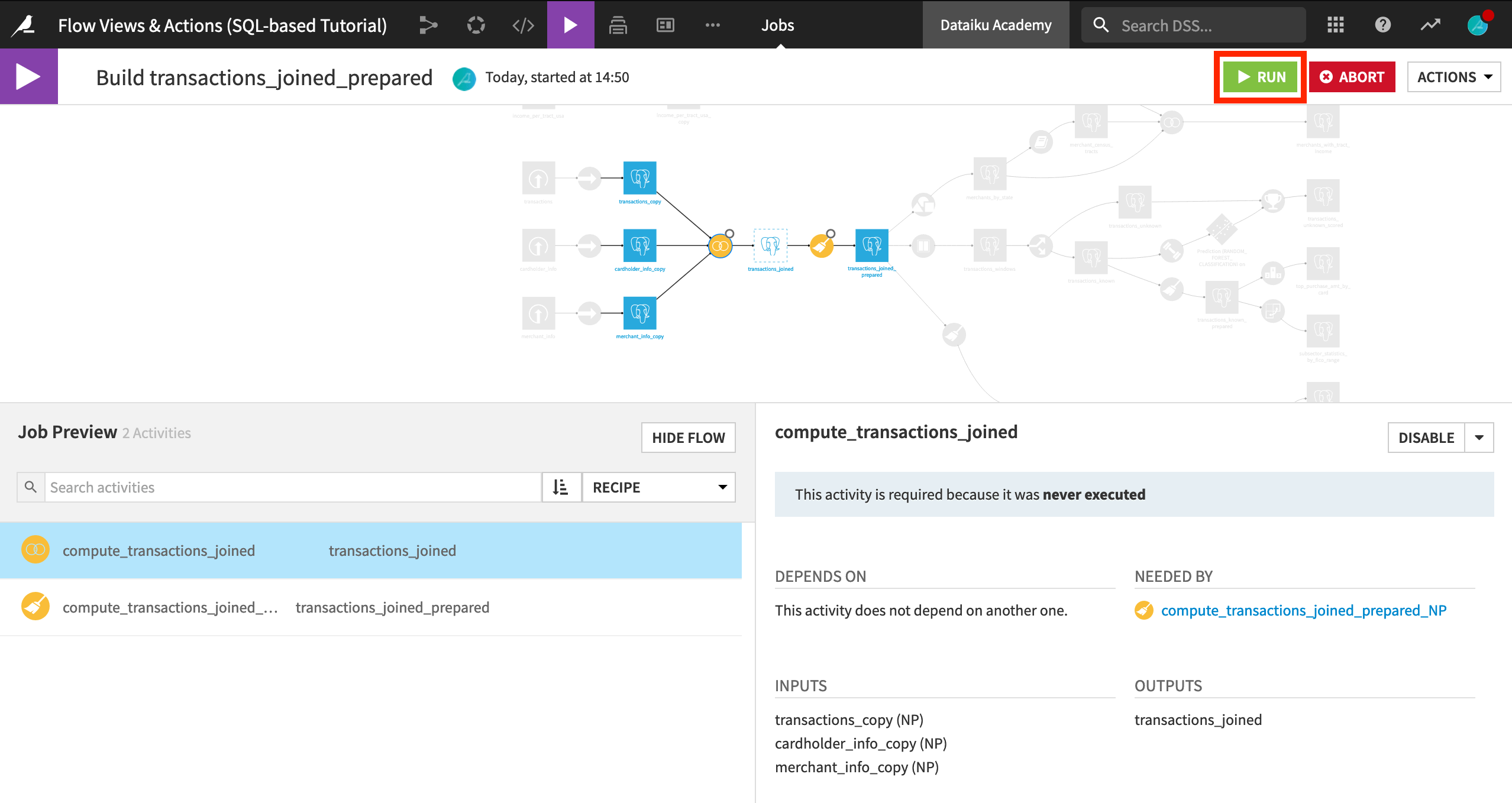
Return to the Flow, and open the Build options for transactions_joined_prepared.
This time, choose Recursive > Smart reconstruction > Preview.
After computing the job dependencies, we can see two activities planned: first the Join recipe and then the Prepare recipe.
Click Run to initiate the job.
We could have also rebuild the dataset starting from the beginning of the pipeline without regard for what dependent datasets may or may not need to be rebuilt.
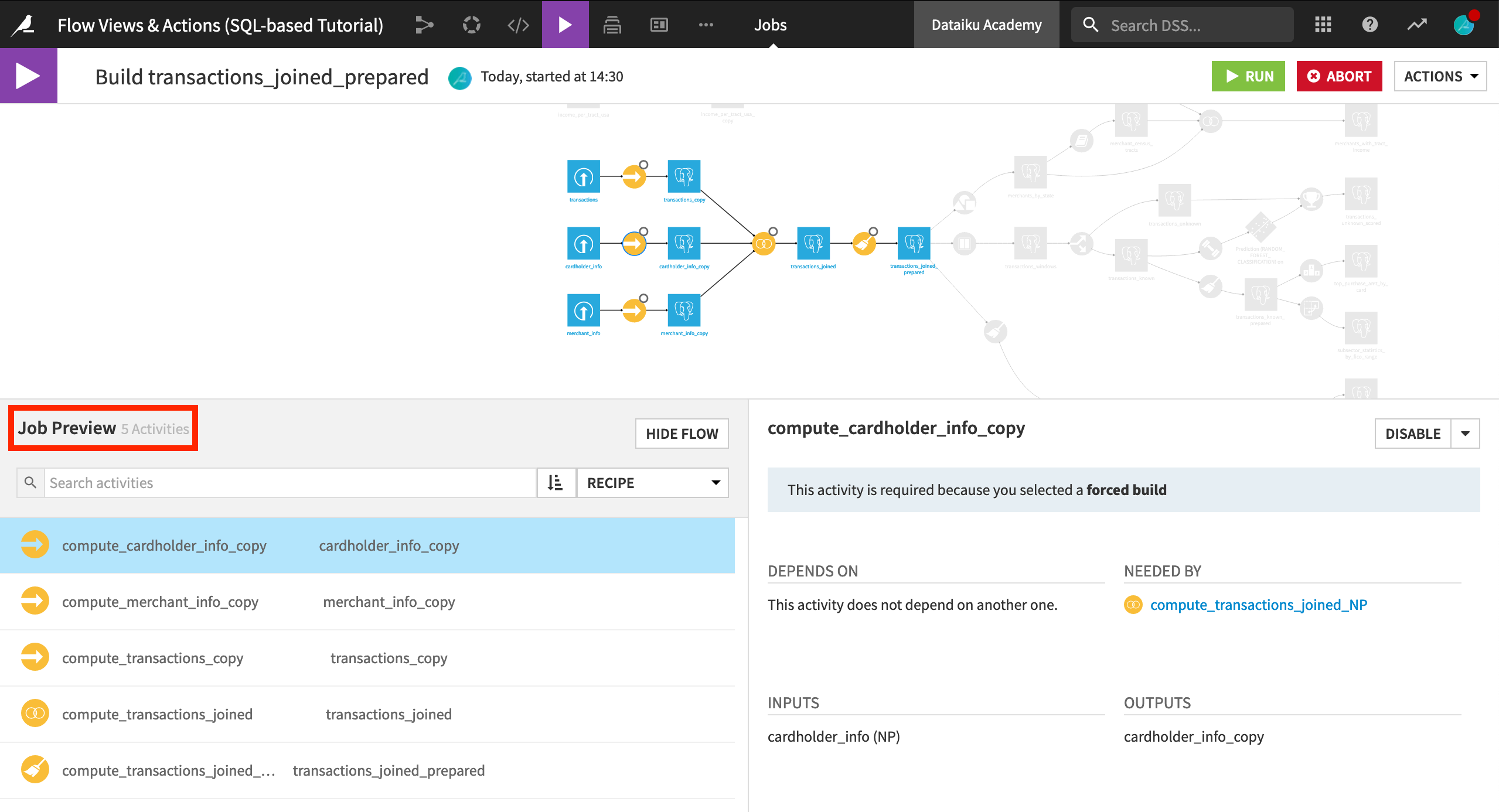
Return to the Flow, and open the Build options for transactions_joined_prepared once more.
This time, choose Recursive > Forced recursive build > Preview.
After computing the job dependencies, we can see five activities planned. In addition to the Join and Prepare recipes, the three upstream Sync recipes will also run.
Learn More¶
Great job! Now you have some hands-on experience performing advanced actions in the Flow.
If you have not already done so, register for the Academy course on Flow Views & Actions to validate your knowledge of this material.
You can also explore additional articles in the Knowledge Base about this topic.