Hands-On Tutorial: Managed Folders¶
Sometimes datasets aren’t enough! Although Dataiku supports a large number of data formats, these are not always enough for every data science project. Managed folders, often in conjunction with code recipes, are often a handy tool for working with non-supported file types, such as images, PDFs, and much more.
In fact, folders can be a useful tool whenever you want to manipulate files (even supported file types) programmatically.
In this case, we have data tables printed in a UN report on urban population growth that we want to extract into Dataiku to conduct our own analysis.
Let’s Get Started¶
In this hands-on lesson, you will learn how to:
download and/or upload files that Dataiku cannot natively read into a managed folder;
create a DSS dataset from a folder of files;
work with a folder as both input and output to a Python recipe; and
publish the contents of a managed folder on a dashboard.
Prerequisites¶
To complete this tutorial, you will need:
A locally downloaded copy of this 2016 UN report on world cities.
Dataiku - version 9.0 or above. Dataiku Online is not compatible.
A Python environment with the packages tabula-py and matplotlib.
This tutorial was tested using a Python 3.6 code environment, but other Python versions may also be compatible.
Note
You can find instructions for creating a code environment compatible with all courses in the Developer learning path in this article.
If you are unable to configure this code environment, you can also download the resulting dataset, and continue with the tutorial, practicing how to output images to a managed folder.
Workflow Overview¶
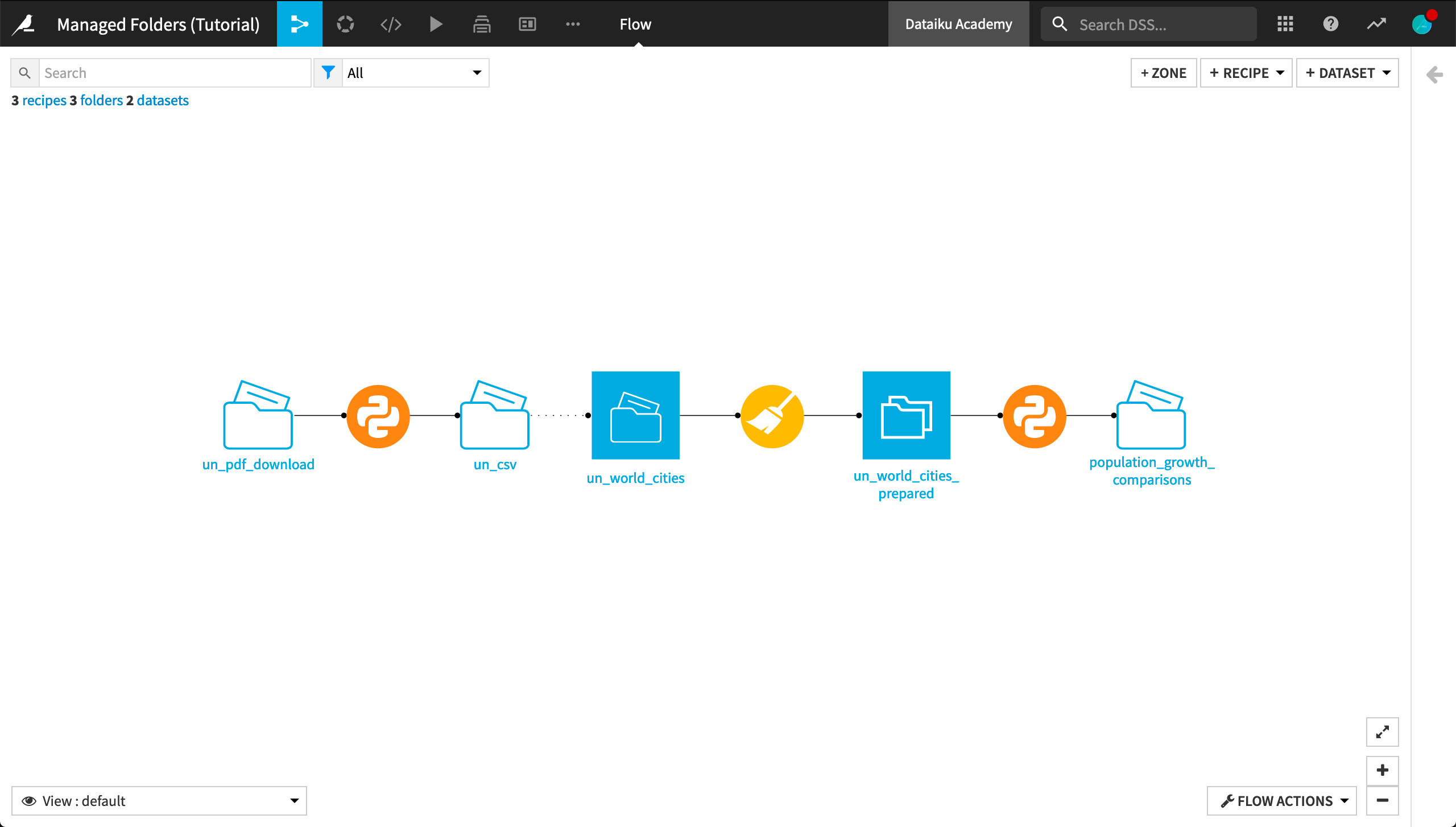
When you have completed the tutorial, you will have built the Flow pictured below:
Create a Project¶
We’ll be creating this project from start to finish so you just need a new empty project.
From the Dataiku homepage, click on +New Project > Blank project.
Give it a name, such as
Managed Folders.Click Create.
Upload the PDF¶
The data for this project is found in the UN’s 2016 report on World Cities. As a PDF though, we cannot directly import it as a DSS dataset. Instead, let’s import the report into a managed folder.
From the Flow, choose +Dataset > Folder.
Name the output folder
un_pdf_download.Click Create Recipe after choosing a storage location.
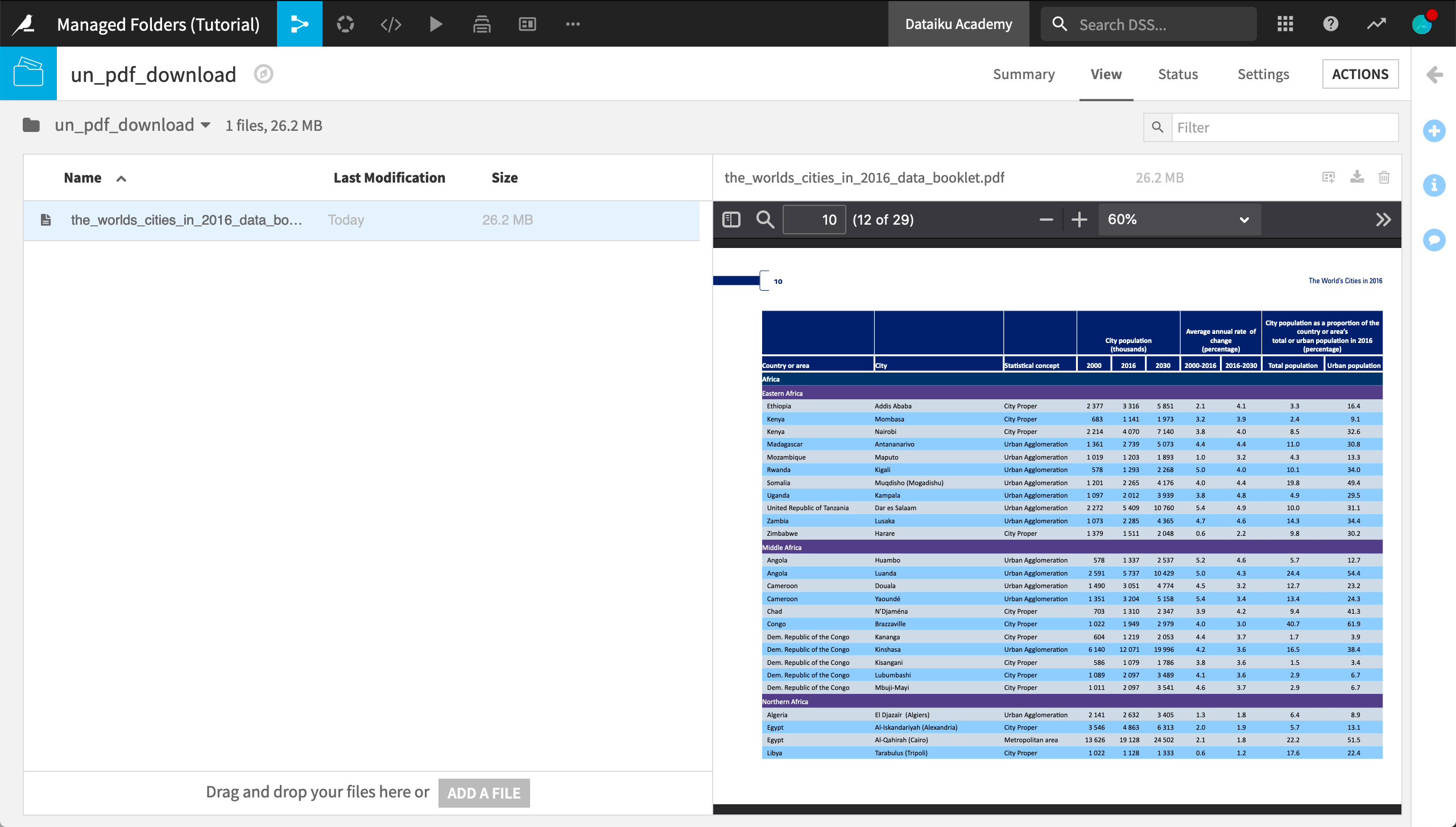
Click Add a File or drag and drop the PDF into the folder.
When it has finished uploading, click on the file name to preview it.
Scroll through the PDF to find the published data tables starting from page 12.
Note
We also could have used a Download recipe to directly download the data into the folder. For use cases where the data sources regularly update, this would be a more sensible approach.
Parse the PDF with a Code Recipe¶
Dataiku doesn’t have its own way of extracting data tables from a PDF, but the tabula Python library does. A small amount of Python code can get these tables into a Dataiku dataset.
The Code Environment¶
Let’s first designate this project’s code environment, one that has the packages tabula-py and matplotlib (which will be needed later).
From the “More options” menu in the top navigation bar, select Settings > Code env selection.
Change the default Python code env by changing the Mode to “Select an environment” and the Environment to a compatible code env.
Recall that you can find instructions for creating a compatible code environment in this article.
Click Save.
The Python Recipe¶
Now we can return to the Flow.
With the un_pdf_download folder selected, add a Python recipe.
Under Outputs, click +Add, but instead of adding a new dataset, add a New Folder.
Name the folder
un_csv.Create the folder, and then create the recipe.
Delete the sample code.
Normally we’d prototype a recipe in a notebook, but in this case, we already have working code ready. The full code is below, but take a moment to understand these key steps.
We use the Dataiku API to stream the PDF from the folder.
The tabula-py library does the actual PDF parsing.
The last step is to write the output to another folder.
After pasting the code below into the recipe editor, Run the recipe, and view the output folder.
Warning
If you gave the downloaded file or managed folders different names than those described here, be sure to update them.
# -*- coding: utf-8 -*-
import dataiku
import pandas as pd
from tabula.io import read_pdf
# Read recipe inputs
un_pdf_download = dataiku.Folder("un_pdf_download")
# read in the pdf and use tabula-py to extract tabular data
with un_pdf_download.get_download_stream("the_worlds_cities_in_2016_data_booklet.pdf") as stream:
tables = read_pdf(stream, pages = "12-26", multiple_tables = True)
# parse the pdf tables
for table in tables:
table.columns = table.iloc[0].values
table.dropna(inplace=True)
table.drop(table.index[0], inplace=True)
# remove corrupted data
tables.pop(2)
# Write recipe outputs
csvs = dataiku.Folder("un_csv")
# write dataframes to csvs
path = '/dataset_{}'
for index, table in enumerate(tables):
csvs.upload_stream(path.format(index), table.to_csv().encode("utf-8"))
Note
Whenever possible, it is advisable to use the get_download_stream() method to read a file from a folder, rather than get_path(). While get_path() will only work for a local folder, get_download_stream() works regardless of where the contents are stored. This is addressed in the product documentation.
Create a “Files in Folder” Dataset¶
Note
If you fail to create the un_csv folder, you can also directly download the un_world_cities dataset.
The un_csv folder now holds 14 files, one for each page of the PDF containing a table. From this folder of CSV files, let’s create one DSS dataset.
From the un_csv folder, click Create Dataset in the Actions sidebar.
Click List Files to confirm the files in the folder (dataset_0 to dataset_13).
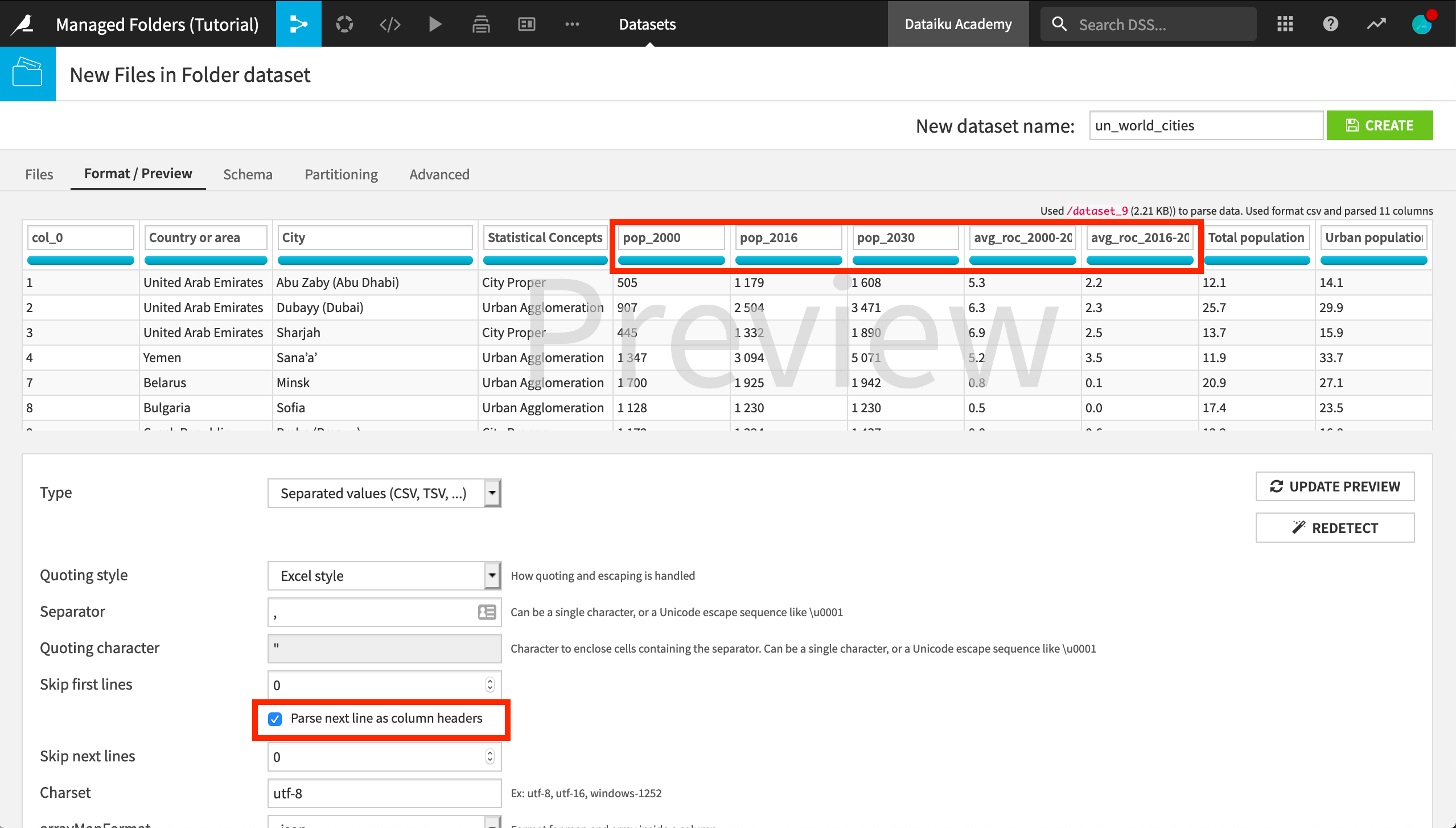
Click Test and then Preview to observe the format of the dataset being created.
On the Format/Preview tab, click “Parse next line as column headers”.
Let’s fix some of the column names here:
Add the prefix
pop_to the three population columns 2000, 2016, and 2030.Add the prefix
avg_roc_to the columns 2000-2016 and 2016-2030 for the average annual rate of change in population.
Name the output
un_world_citiesand click Create.
We now have a Dataiku dataset that we can manipulate further with visual and/or code recipes.
Visual Data Preparation¶
Although we could have handled this in the previous Python recipe, let’s take advantage of the Prepare recipe for some quick data cleaning.
From the un_world_cities dataset, create a Prepare recipe with the default output name.
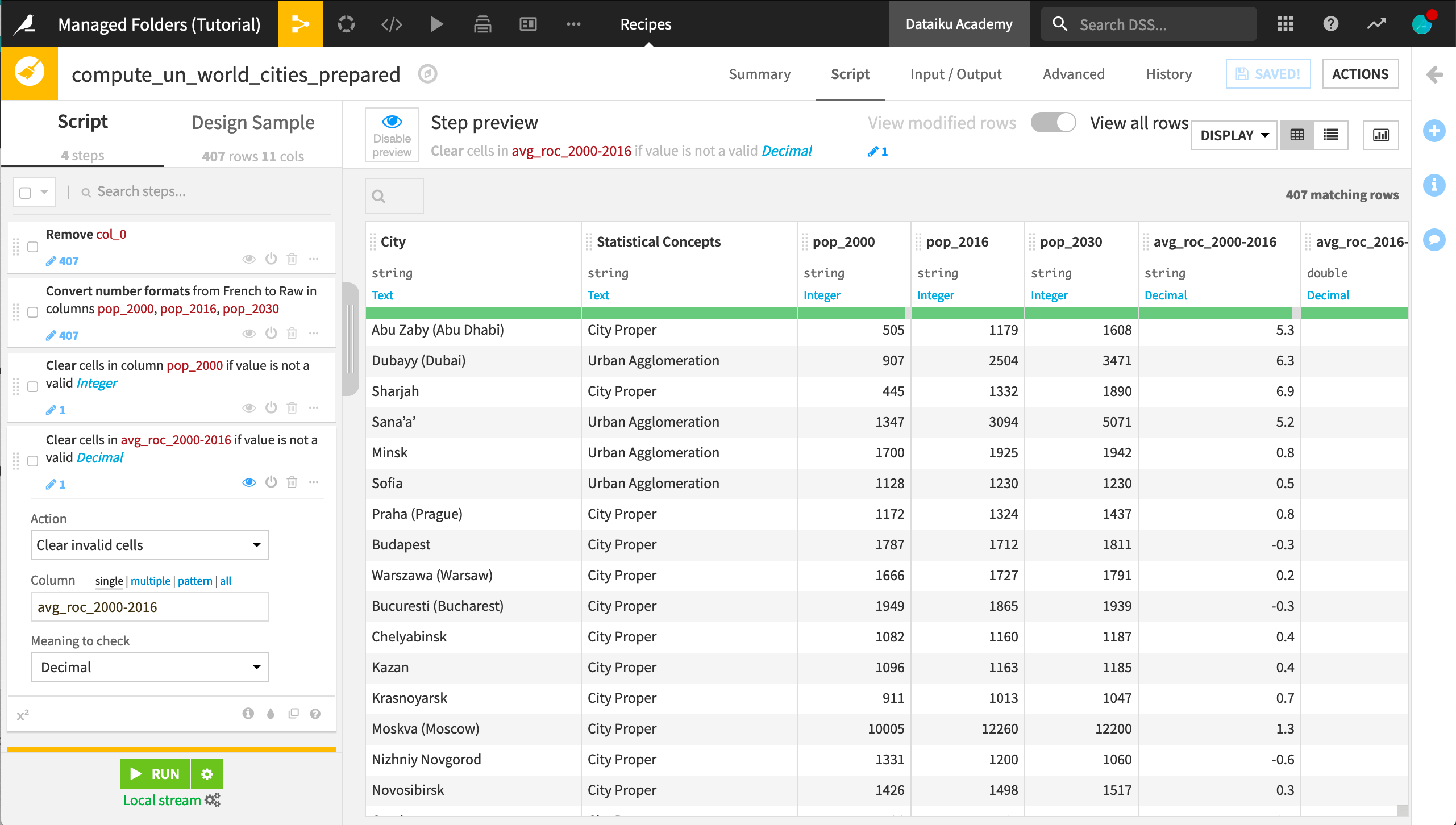
Remove the unnecessary col_0.
Add another step to convert number formats in the three population columns.
The name of the step is “Convert number formats”. The input format should be “French”, and the output format should be “Raw”.
As flagged by the red portion of the data quality bar, there is one city with non-standard representations of missing data.
For columns pop_2000 and avg_roc_2000-2016, clear invalid cells for the meanings integer and decimal, respectively.
Run the recipe, updating the schema if necessary.
Output Custom Plots to a Folder¶
There may be times when the native chart builder cannot create the visualization we need. Instead, we might want to create a more customized plot in a library like matplotlib or ggplot2. We can use a code notebook to create a custom plot, which can then be saved as a static insight and published to a dashboard.
However, for situations where we want to generate a large number of files as output (such as one chart per country), it may be preferable to use a managed folder as output.
For the ten largest countries, let’s compare growth rates from 2000-2016 and the projected growth rate from 2016 to 2030 with a pyramid plot, created in matplotlib.
From the un_world_cities_prepared dataset, create a Python recipe.
Add a New Folder (not a dataset) as an output named
population_growth_comparisons.Create the recipe and delete the sample code.
The full code recipe is below, but take note of the following key points.
We use the Dataiku API to interact with the input dataset as a Pandas dataframe.
We use matplotlib to create the charts.
For each plot, we use the
upload_stream()method to write the image to the output folder because it works for both local and non-local folders.
Once you have pasted this code into your recipe editor, Run the recipe, and view the output folder.
import dataiku
import pandas as pd
import matplotlib.pyplot as plt
import os
import io
# Read recipe inputs
un_data_prepared = dataiku.Dataset("un_world_cities_prepared")
df = un_data_prepared.get_dataframe()
# top 10 most populous countries
TOP_10 = ['India', 'China', 'Brazil', 'Japan', 'Pakistan', 'Mexico', 'Nigeria',
'United States of America', 'Indonesia', 'Turkey']
# generate plot for each country and save to folder
for country in TOP_10:
df_filtered = df[df['Country or area'] == country]
y = range(0, len(df_filtered))
x_1 = df_filtered["avg_roc_2000-2016"]
x_2 = df_filtered["avg_roc_2016-2030"]
fig, axes = plt.subplots(ncols=2, sharey=True, figsize=(12, 9))
fig.patch.set_facecolor('xkcd:light grey')
plt.figtext(.5,.9, "Pop. ROC Comparison ", fontsize=15, ha='center')
axes[0].barh(y, x_1, align='center', color='royalblue')
axes[0].set(title='2000-2016')
axes[1].barh(y, x_2, align='center', color='red')
axes[1].set(title='2016-2030')
axes[1].grid()
axes[0].set(yticks=y, yticklabels=df_filtered['City'])
axes[0].invert_xaxis()
axes[0].grid()
# Write recipe outputs
pyramid_plot = dataiku.Folder("population_growth_comparisons")
bs = io.BytesIO()
plt.savefig(bs, format="png")
pyramid_plot.upload_stream(country + "_fig.png", bs.getvalue())
Publish a Managed Folder Insight¶
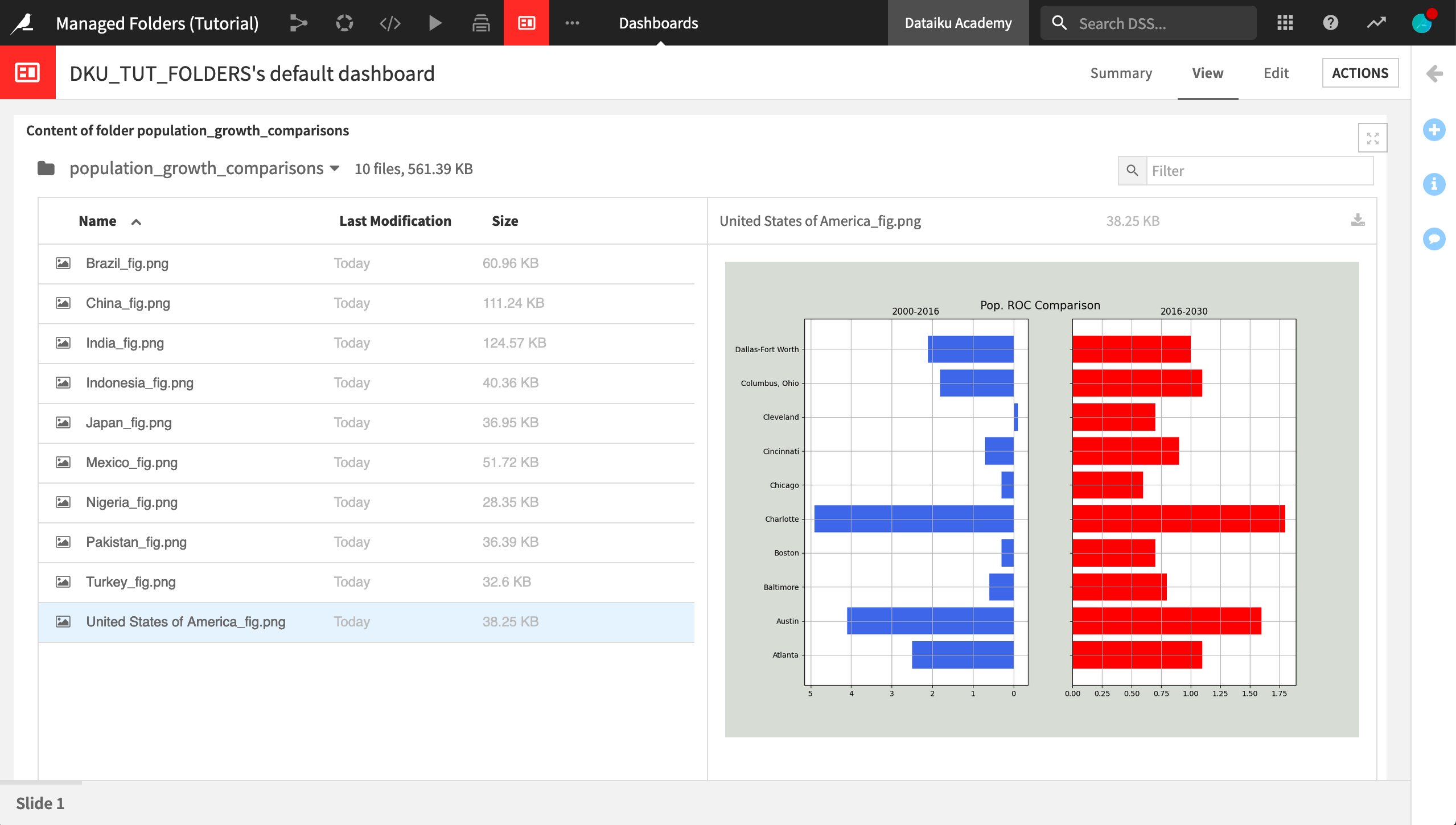
In the population_growth_comparisons folder, we can browse the files to view the chart for each country.
In some cases, we might automate the export of the contents of a managed folder to some other location. For this use case though, let’s publish the whole folder as an insight on a dashboard.
From the population_growth_comparisons folder, click Publish in the Actions sidebar.
Then click Create to add it to a dashboard. It may take a minute or two.
Adjust the size of the folder preview on the Edit tab as needed. Click Save.
Navigate to the View tab to interact with the images in the folder.
Learn More¶
That’s it! You have successfully demonstrated how to use managed folders as the input and output to code recipes to assist you in handling types of data that Dataiku cannot natively read and/or write.
For more information on managed folders, please visit the managed folders product documentation.