Hands-On Tutorial: Building your Feature Store in Dataiku¶
In this article, we will look in detail on how to leverage Dataiku’s capabilities to implement a Feature Store approach.
Prerequisites¶
We strongly recommend that you read our blog post introducing Feature Store concepts.
Additionally, you should be familiar with Dataiku to fully understand the explanation here, especially Designer and MLOps topics. The Dataiku Academy learning paths Advanced Designer and MLOps Practitioner are the most suitable to follow.
With regards to the version, almost all capabilities utilized here exist since version 8 of Dataiku. The only recent addition is the centralized place to publish and search for Feature Groups, which has been released in version 11 (If you have an older version, you will need to use the Catalog for that).
If you want to import the demo projects attached to this article, you will need a Dataiku instance of least version 11. See below for detailed instructions.
Introduction¶
Building a Feature Store is not a standalone project. It is a way to organize your data projects to put in common as much as possible the arid work of building valuable datasets, with proper and useful features in them. Those can then be used to train your model and score the data in production.
A typical schematic of a Feature Store is as such:
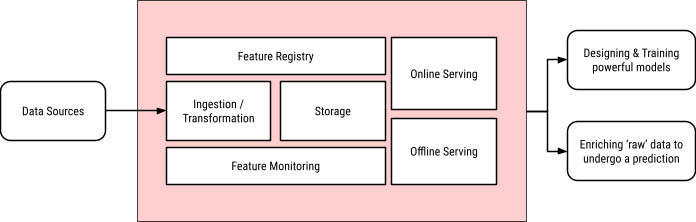
All of these components are available in Dataiku, and so it is a matter of understanding how to put them in motion, which is the goal of this article.
Feature Store Capability |
Dataiku Capability |
Related Documentation |
|---|---|---|
Ingestion / Transformation |
Flow with recipes |
|
Storage |
Datasets based on extensive Connections library |
|
Monitoring |
Metrics & Checks with Scenarios |
|
Registry |
Feature Store |
|
Offline serving |
DSS Automation Server, Join recipes |
|
Online serving |
DSS API Nodes, especially enrichment capabilities |
Let’s Get Started!¶
We will use a set of projects to showcase a typical setup. You can import them on a test instance to look more in detail.
FSUSERPROJECT.zip - Original project, without a Feature Store approach
FSFEATUREGROUP.zip - Dedicated project to build Feature Groups
FSUSERPROJECTWITHFEATURESTORE.zip - Revamped project using Feature Groups
Note
These projects have been built on Dataiku version 11 so you need at least this version to import them properly.
They are using almost all PostgreSQL connections, except for one that uses MongoDB (for import purposes, you can create a fake MongoDB connection).
The Reverse geocoder plugin is required to compute data for the model. (We do not need this plugin for the Feature Store logic; this is purely for this precise project).
Be careful in which order you import the projects: “FSFEATUREGROUP” needs to be imported before “FSUSERPROJECTWITHFEATURESTORE”.
Once imported, the output datasets of the “FSFEATUREGROUP” project will not be published in your instance’s Feature Store; you need to do it manually (see below for more details). Similarly, the API endpoints used for online serving will be there, but not deployed to an API node.
The structure of this article is:
Understand the original standalone project.
Build a specific project to generate the feature groups, including feature monitoring and automated builds
Update the original project to use the new feature groups.
Let’s look at a standard project¶
We are starting this journey with a payment card authorization project. Let’s understand what we have achieved so far.
Note
The relevance of this project or the actual ML model used is not the topic of the article. We use it only as a practical support for the demonstration.
Flow Overview¶
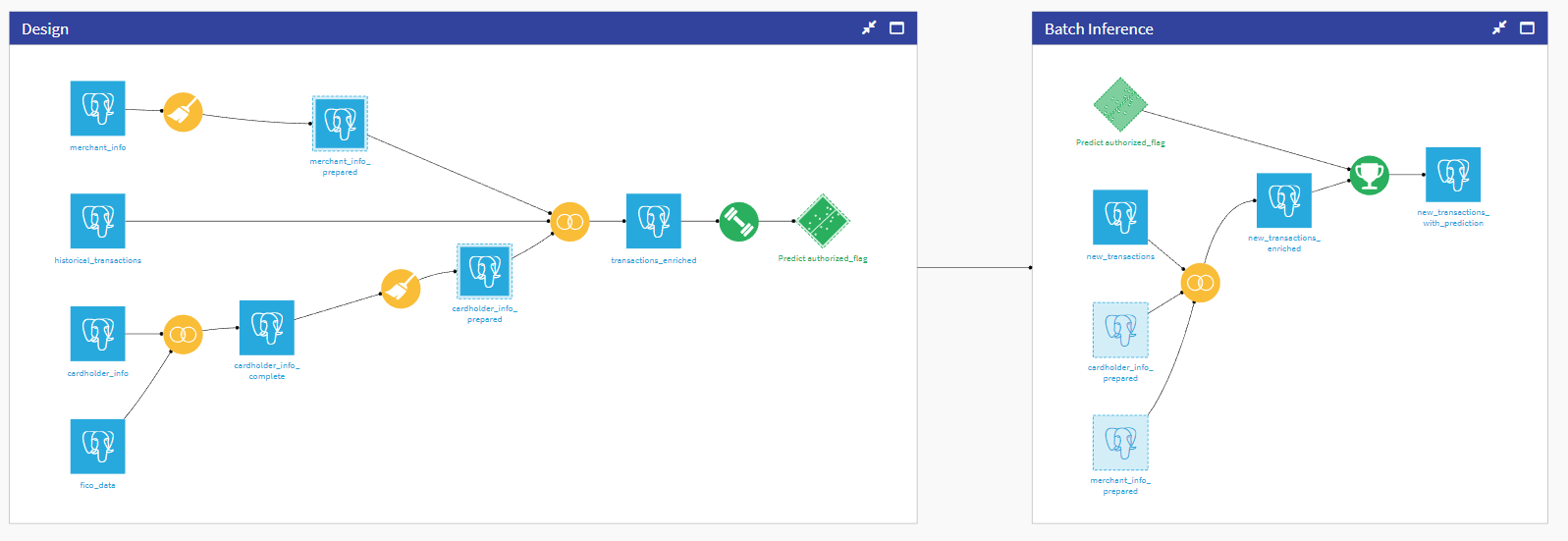
The Flow has been organized into two zones:
Design - This is where we fetch data from various sources, prepare it, and use it to design a model.
Inference - This is the actual batch Flow that takes a dataset with new un-predicted data and adds a prediction (This is the part that you automate with a scenario and run on your Automation node).
Let’s dive into each section a bit further.
Design¶
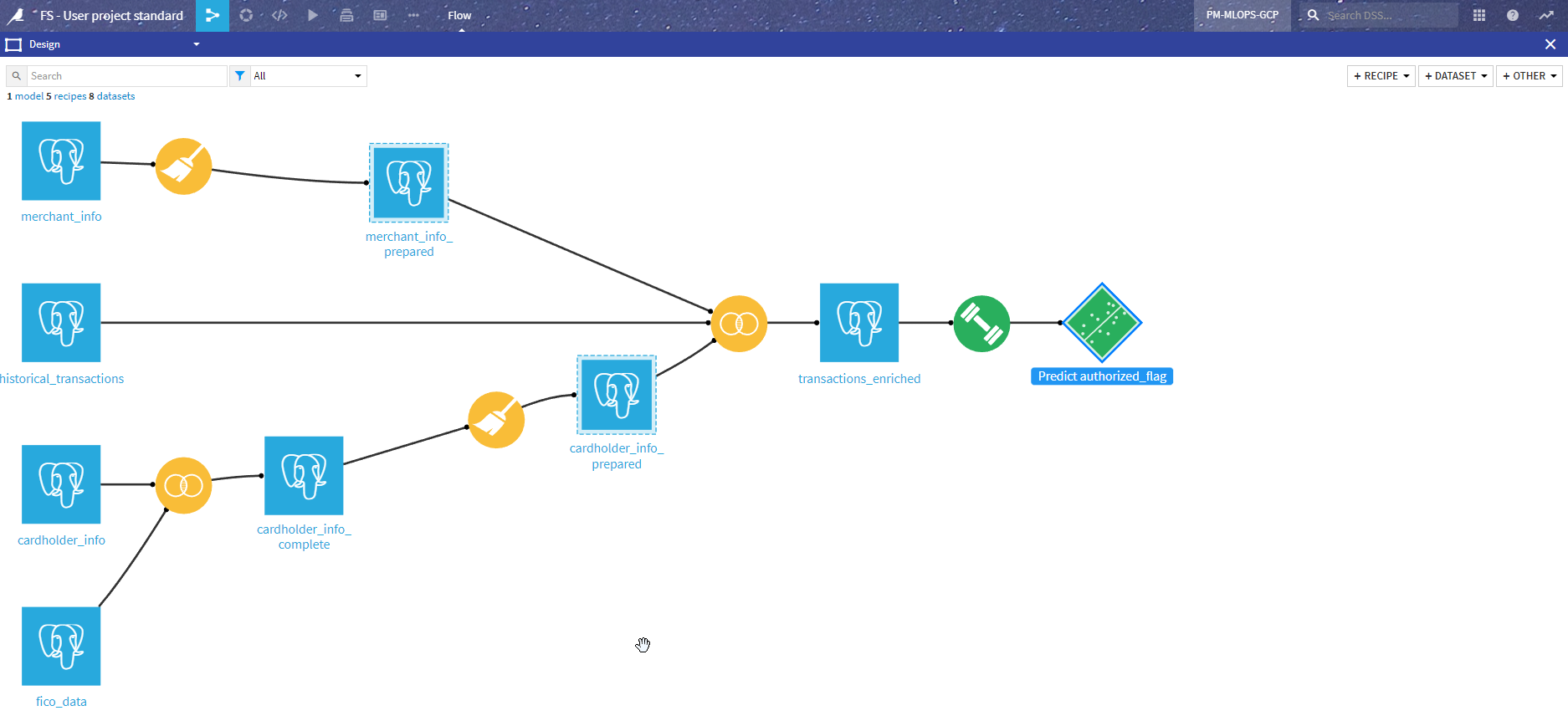
We have four main sources of data:
The merchant data comes from the merchant_info dataset, and transformations are mostly on geo localization (both geopoint and name of state), resulting in merchant_info_prepared.
The cardholder data comes from the cardholder_info dataset. This is enriched by a Join recipe with FICO information (a risk score) from fico_data resulting in carholder_info_compute. Similar to merchant data, data preparation is mostly on geographical data, which produces cardholder_info_prepared.
The main Flow (historical_transactions dataset) is the historical data from past purchases with the resulting authorizations.
Those datasets are joined to produce the model input dataset transactions_enriched.
The model in itself is not very complex. It is worth noting that a last set of data transformations (pictured below) are performed in the model to compute some additional features. Adding these steps in the model will allow those transformations to be automatically integrated in the API package for online serving.
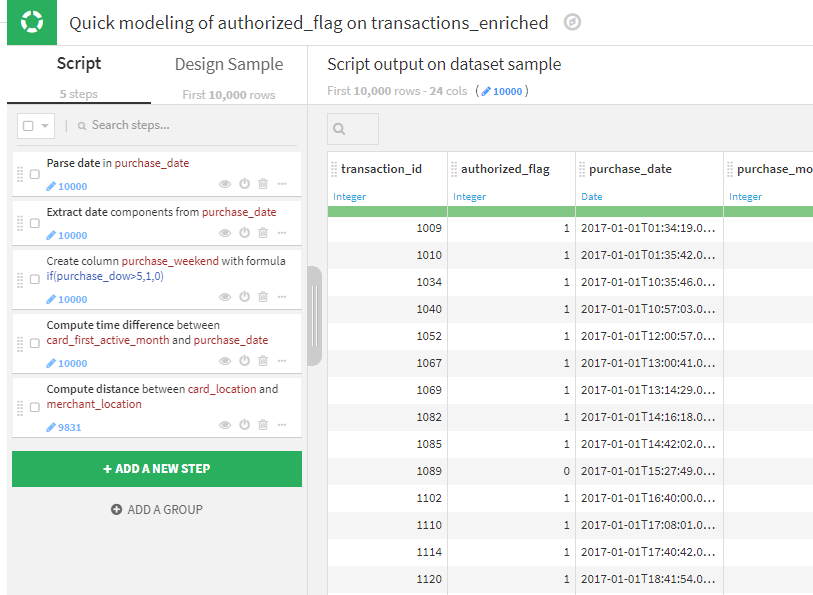
Then the model is trained and deployed.

Batch Inference¶
This section is intended to be deployed as a bundle on an Automation node and automated with a scenario.
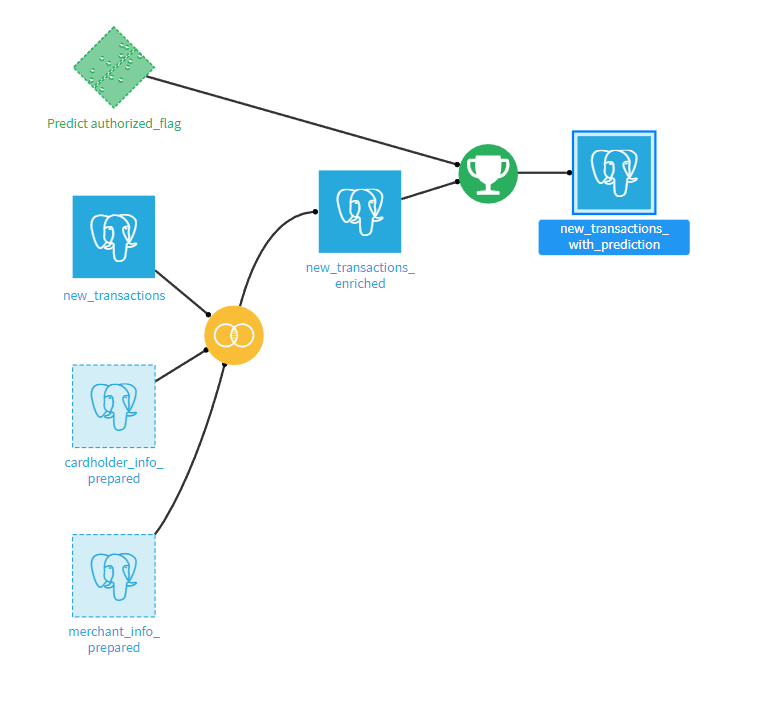
It takes all the new transactions, enriches them with the cardholder and merchant data (using the same dataset as in the Design section), and then scores using the deployed model.
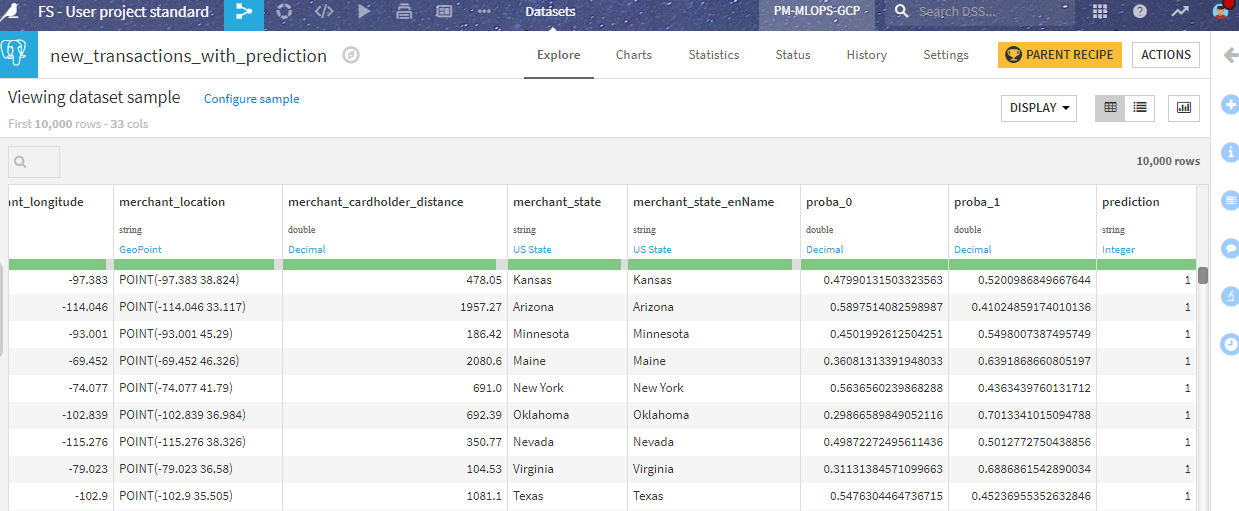
This produces an output dataset with the prediction:
Real-time Inference¶
In order to use this model in various ways, we also deployed it as an API endpoint for real-time scoring. This is done by using the API Designer and defining a simple prediction endpoint with the saved model.
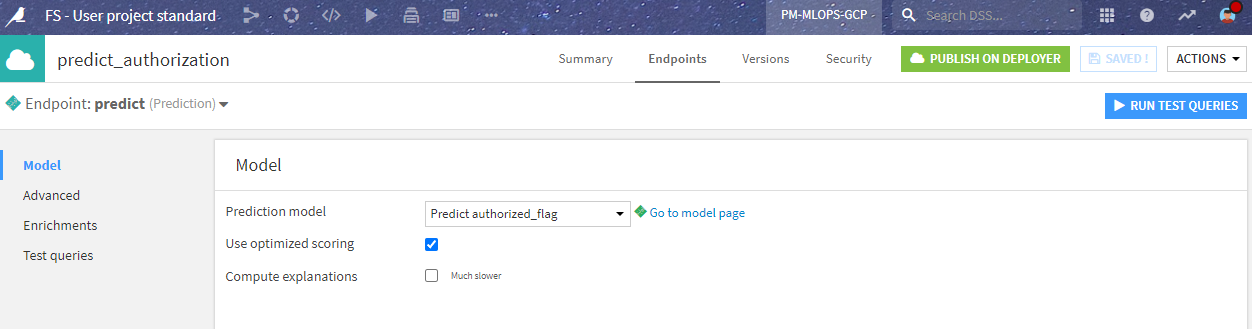
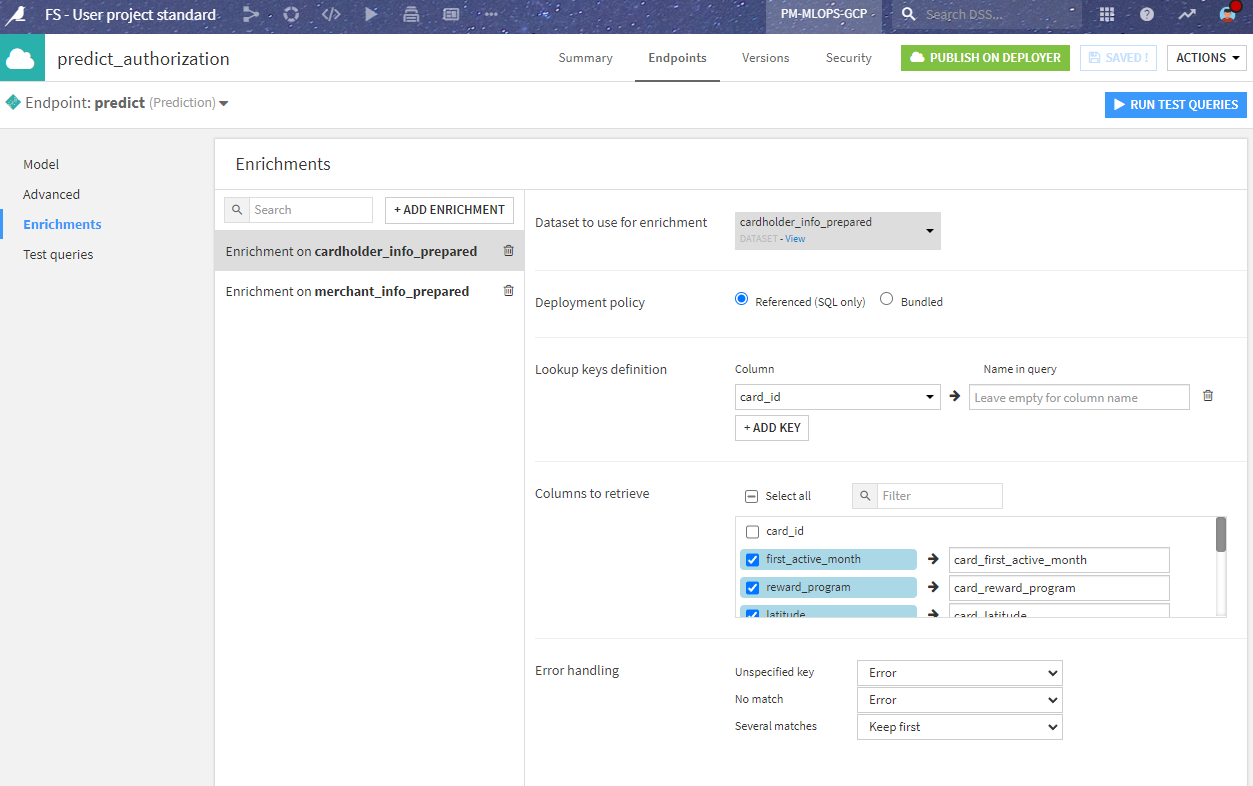
In the API definition, we have to consider that the third party will call the endpoint with only the new transaction data, not including the enrichments coming from the merchant_info and cardholder_info datasets.
This is easily solved in the endpoint definition where we tell the API node to enrich the incoming data directly from the SQL data source. This allows us to reproduce the Join in the batch inference phase in a simple and elegant way.
We then deploy the prediction endpoint to an API node using the API Deployer. Before doing so, we can test that the prediction endpoint is working correctly.
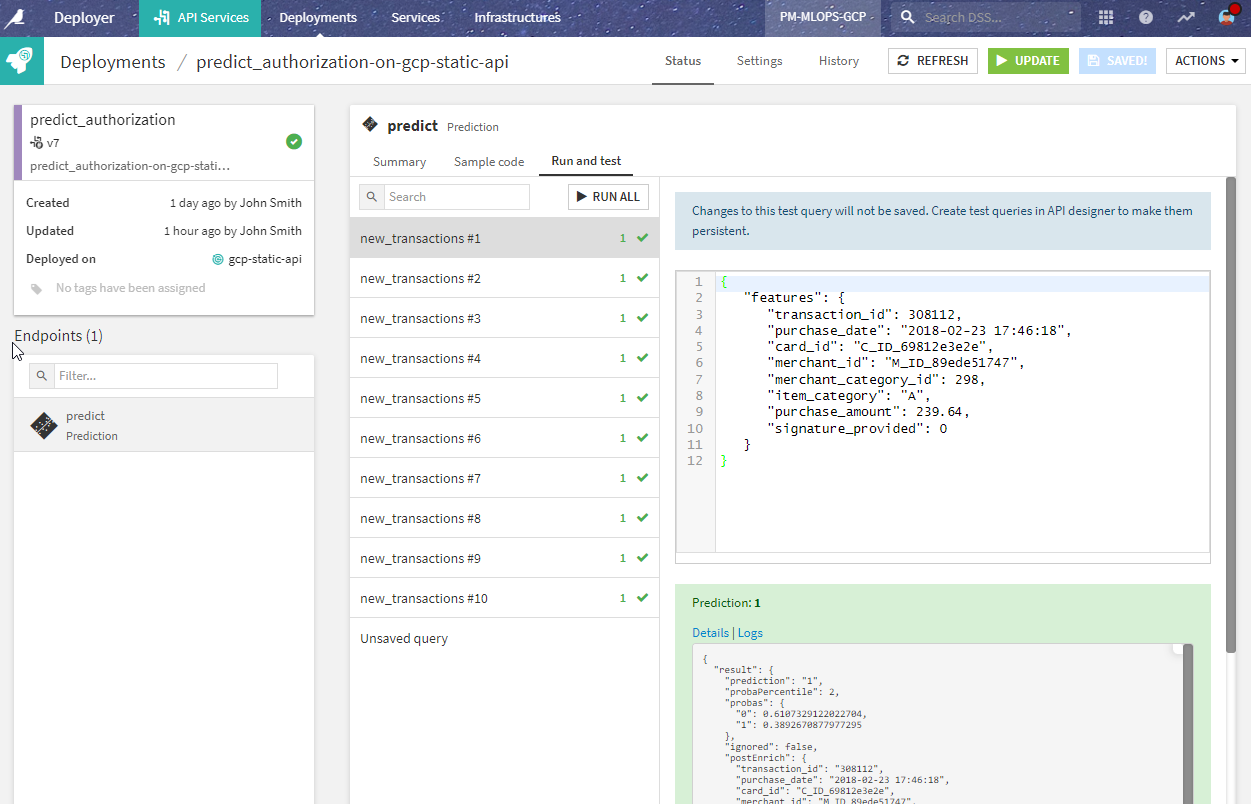
What is wrong with this project?¶
In fact, nothing. This project is well designed and delivers the model to where it generates value. However, issues might arise from several angles:
Another project will (or may already!) use this same cardholder and merchant data. If the team members on this project are not the same, they will probably rework the same data preparation steps, doubling the work, and potentially introducing errors.
If there is a change in those inputs or preparation steps, this change may impact one project, but not the others.
Another team may manage the cardholder and merchant data, and they’d rather not see anyone wrangling it on their own, without knowing the data’s origin, quality, or limitation of use.
In the end, you will face the need for factoring and organizing the management of those datasets containing the features needed for your ML models. This is what a Feature Store is all about.
In the next section, we will see how to evolve this project to solve the problems mentioned above. Buckle up!
Feature Group Generation¶
The first step is to consider that the computation of the enriched datasets, both for design and inference, needs to be done in a specific project, that may have different ownership.
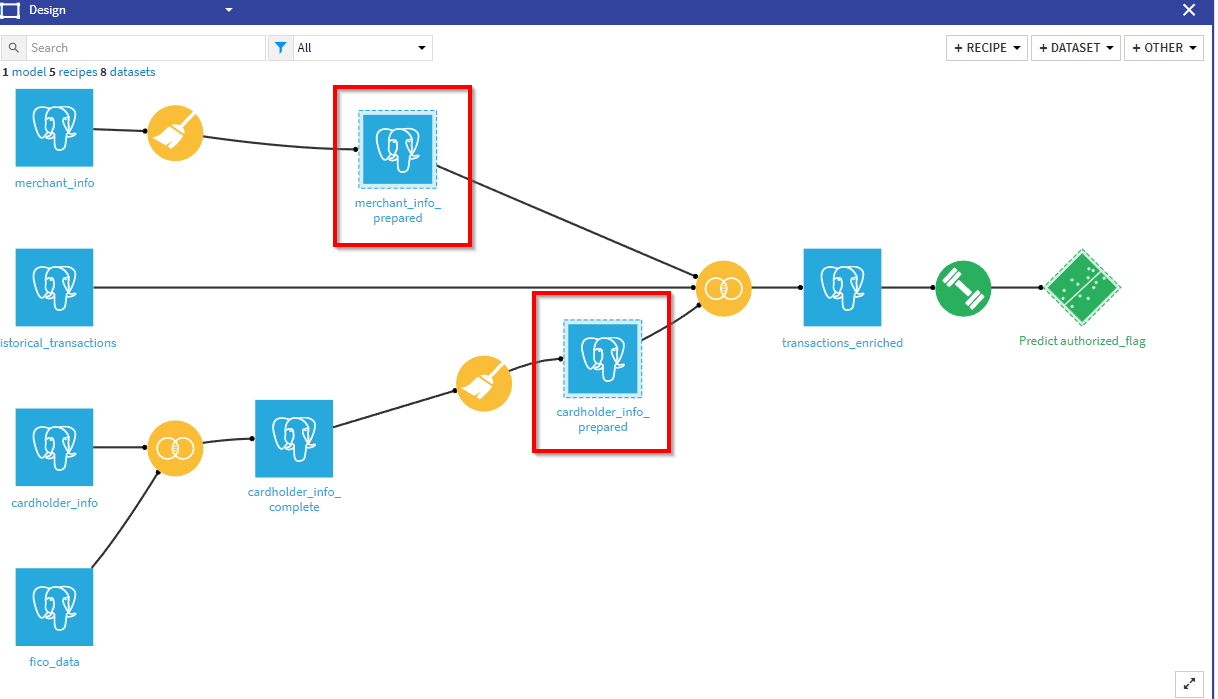
So we created a new project called “Feature Group” and moved the data processing steps to that project.

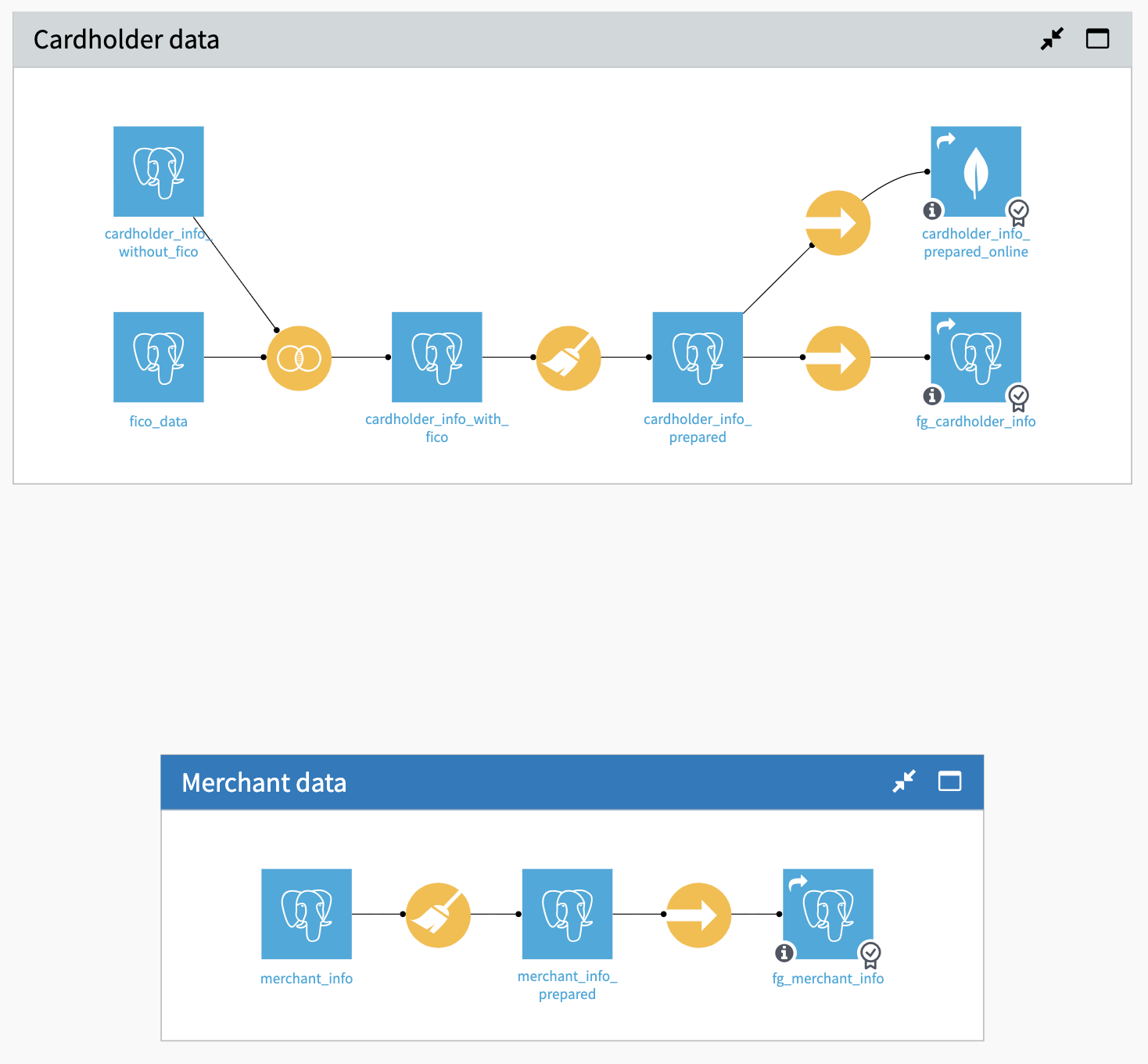
Building a Feature Group ingestion and transformation with the Flow¶
We have not changed the data processing part (That is the whole point). However, we have added some specific steps, let’s look into the details for the cardholder dataset.
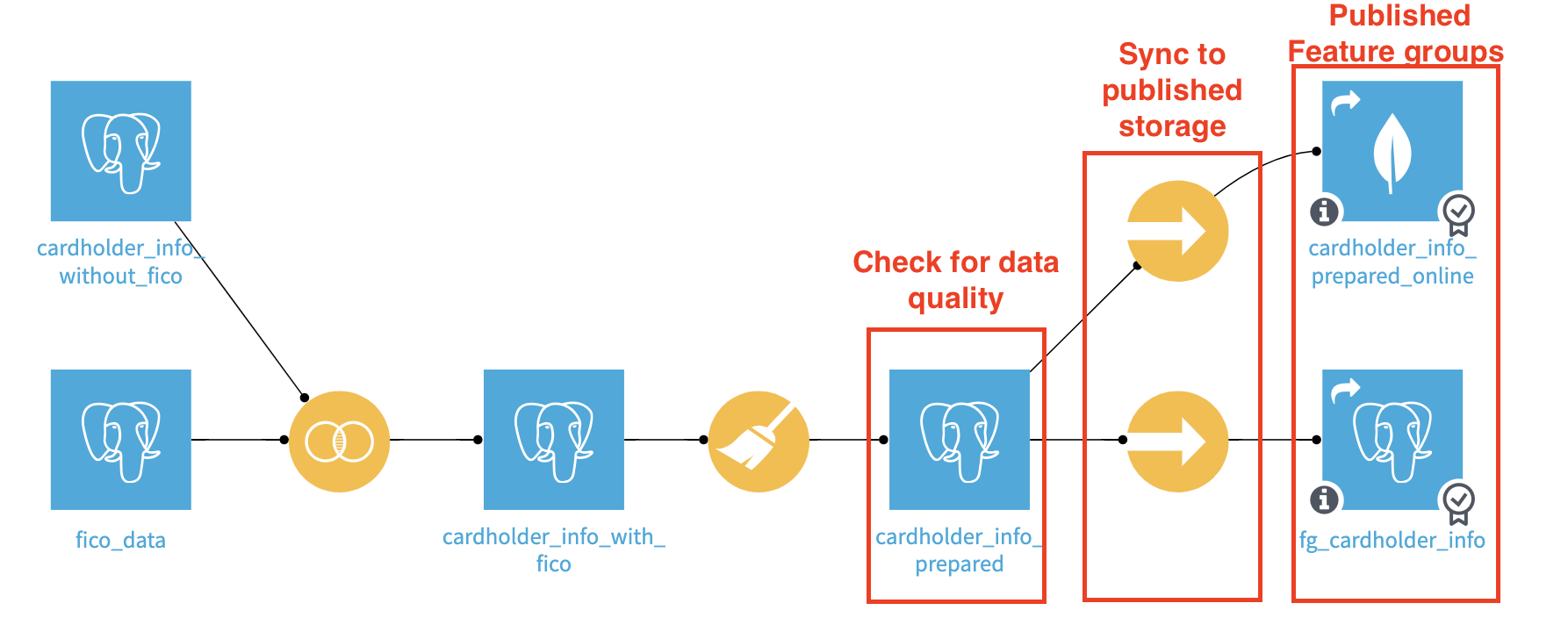
The Sync recipes provide an opportunity to put data checks on the cardholder_info_prepared dataset. When automating the update with a scenario, we can then run the checks at this stage and not update the published Feature Group if its quality metrics are not good enough. After failing a check, updating the published Feature Group will require a fix or a manual run.
The Sync recipe is not mandatory, but allows us to automate the quality control of the carholder_info_prepared dataset and not update the final shared datasets in case of problems.
As an addition to the previous setup, you can configure the Sync to an alternative infrastructure for online serving. Even though Postgres could handle the load in this example, here we are pushing the data in a reading-optimized key-value database (MongoDB). This can be used for online serving typically.
Note
An alternative is to use a “bundled” enrichment on the API endpoint. Using this strategy requires setting up a local database on your API node, and Dataiku takes care of bundling the data from the Design node and inserting it into this local database. This ensures a very fast response time, as explained in the product documentation.
Since we are organizing the data preparation process, we take this as an opportunity to ensure high quality. This is especially important if many projects will use the resulting Feature Group.
Monitoring Feature Groups with Metrics & Checks¶
We want high-standard data quality for our Feature Group. To reach that level, the key capabilities to use are metrics and checks.
The first control we added is to clearly identify the schema and the meanings.
We did this by editing the column schema for each column and locking the meanings.
Then we added metrics, in this case on meaning validity. Of course, you can add more controls depending on your needs and time.
This provides more metrics on the dataset.
Finally, in order to leverage those metrics, we create checks. In this case, we created a custom Python check that will control all meaning metrics in one go and raise a warning if any are invalid.
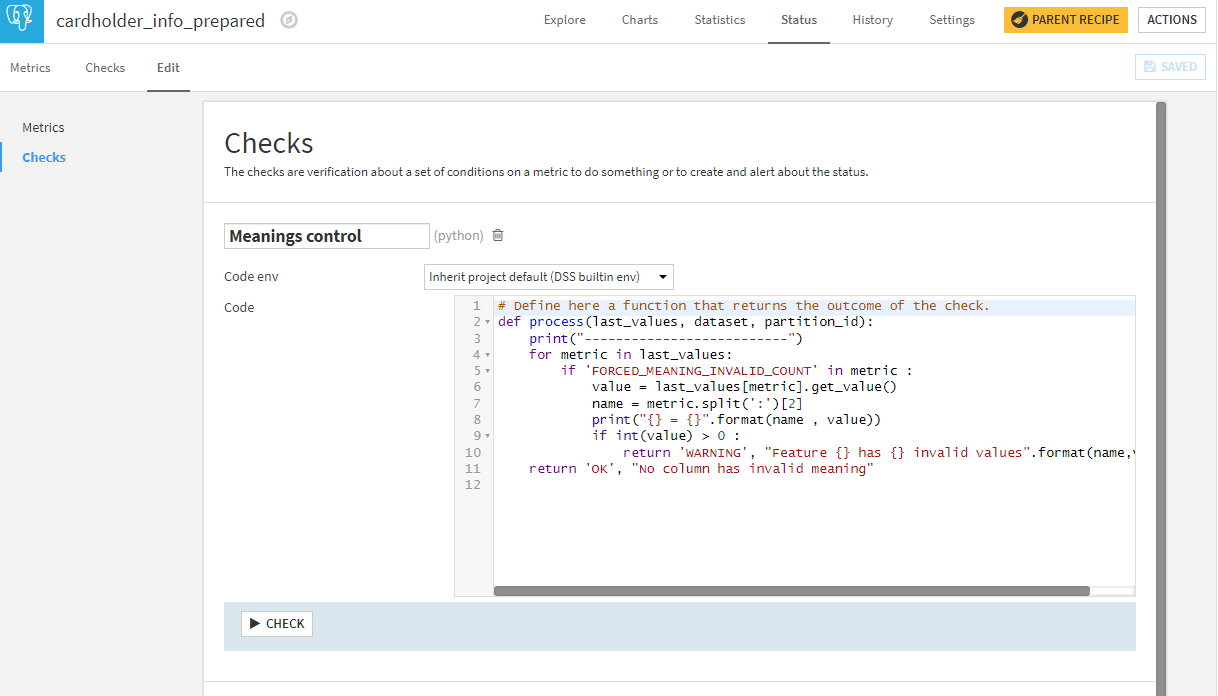
In the end, that gives a simple single check on the dataset as to whether any column has an invalid meaning compared to the one we have locked.
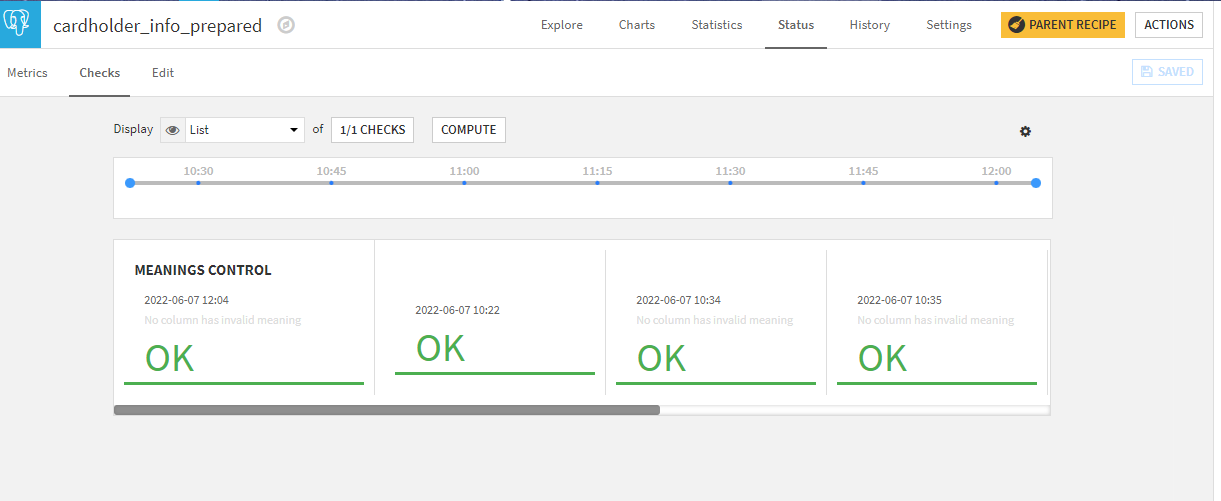
With this check in place, we can easily use a scenario to automate the quality control of the dataset during updates.
Documenting features with descriptions and tags¶
Now that we have checks to ensure data quality, we can generate the final dataset fg_cardholder_info that is our promoted Feature Group.
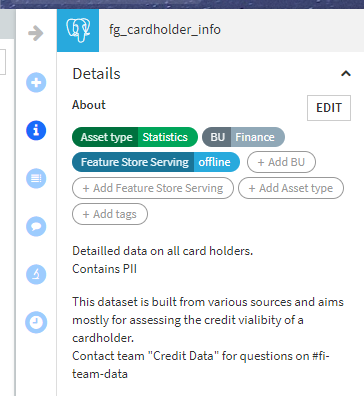
Good quality is critical, but documentation is just as important. For this, we used several capabilities:
Dataset descriptions, both short and long
Tags
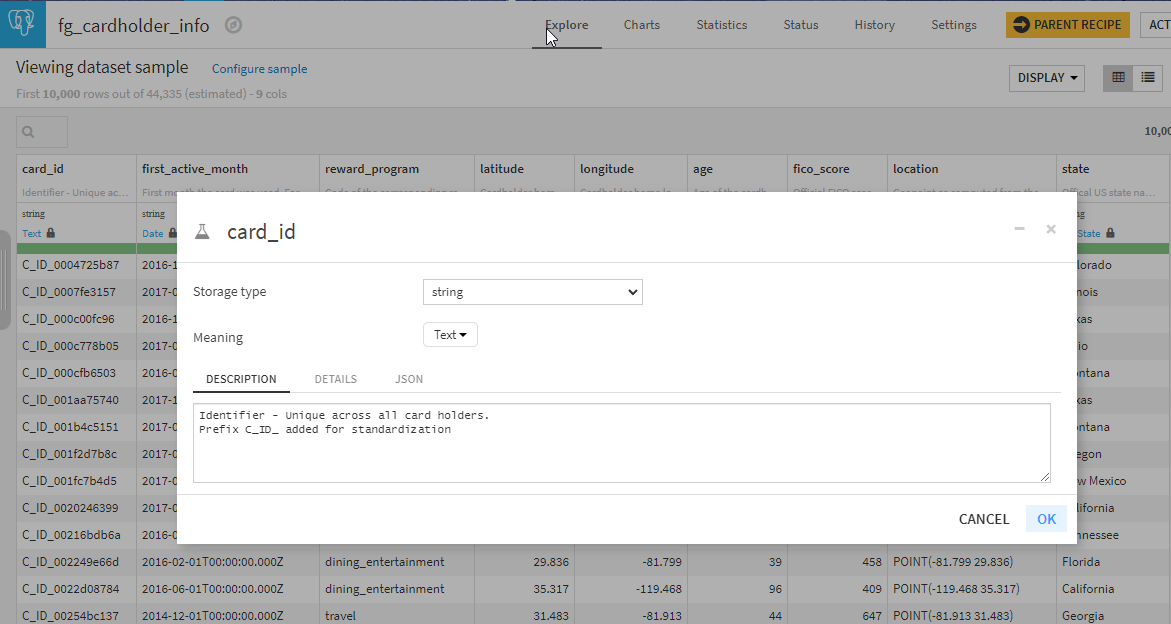
Column descriptions (accessible from the “column name dropdown > Edit column schema” menu)
Here’s what it looks like in the end (in the information panel on the right):
And the dialog for adding column descriptions:
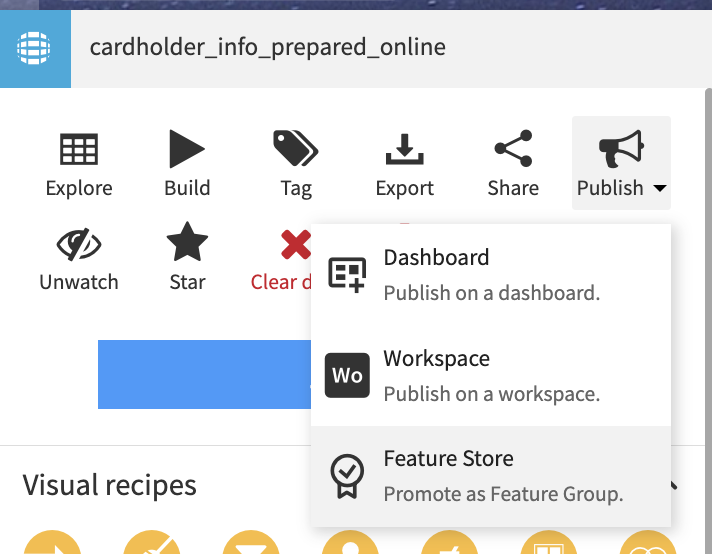
Promoting as a Feature Group¶
Now that we have a well-documented dataset of good quality, we can promote it as a Feature Group.
Note
For a more detailed walkthrough of the mechanics of adding a dataset to the Feature Store, please read this article.
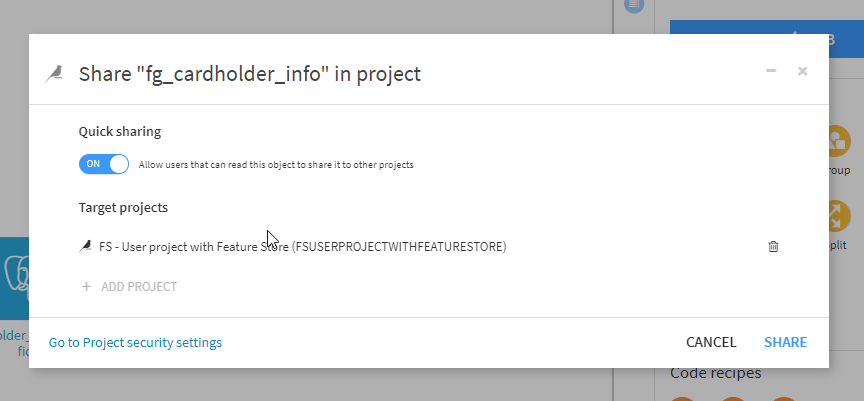
Because Feature groups are intended to be reused in many places, we strongly recommend to facilitate the ability for users to get access to them. Your organization can achieve this goal by either by allowing self-service import using Quick sharing or to activate the request feature, allowing users to request and be granted access directly within Dataiku.
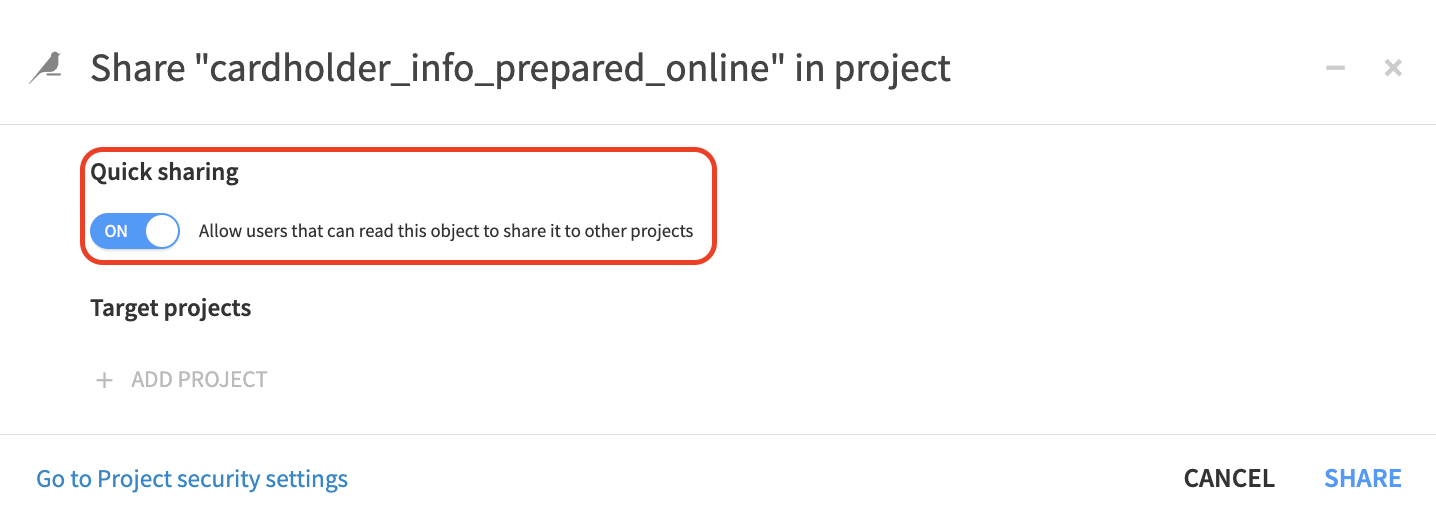
Note
Publishing to Feature Store and Quick Sharing are new capabilities of DSS version 11. Should you have an older version, you can use instead the standard sharing mechanism and do the discovery with the DSS Catalog.
Automate Feature Group Generation with Scenarios¶
Scenarios are a very convenient way to automate the update of a Feature group. Of course, you can keep full control over the building process by leaving it as a manual process, but you can also automate it, leveraging all of the gateways we put in place with the Sync step and check to make sure this automation stops in case of issues.
Here is an example of such a scenario:
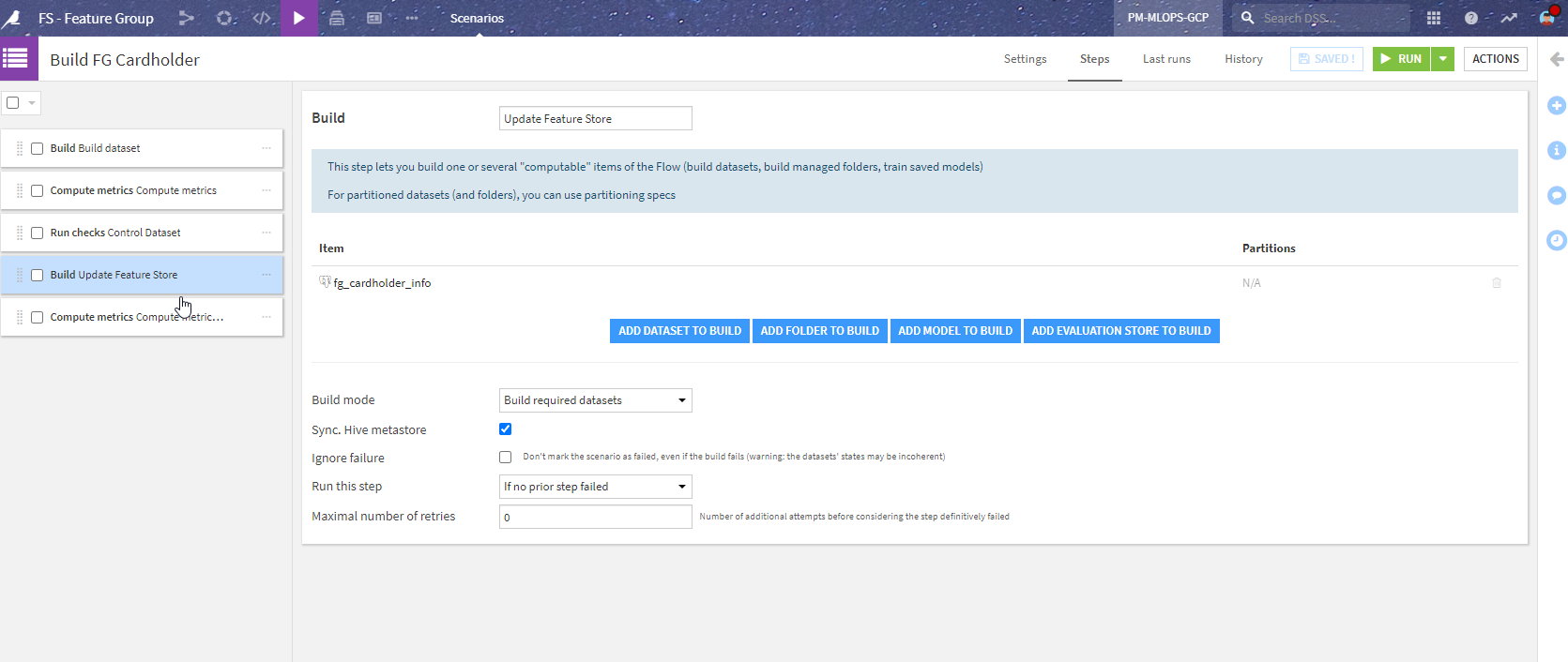
To explain a bit more about the steps shown in the image above:
“Build dataset” - builds cardholder_info_prepared (the dataset before the Sync).
“Compute metrics” - computes the metrics on this dataset.
“Control Dataset” - runs the checks. This stops the scenario if an error in the check is encountered (so that the Feature Groups are not updated).
“Update Feature store” - runs the Sync recipes to the actual published Feature Group.
“Compute metrics” - computes the metrics on the Feature Groups.
With this simple scenario, we ensure that the data in the Feature Group is both up-to-date and of good quality. The last step is to add a trigger to the scenario. It could be, for example, a dataset modified trigger (on the initial datasets) or a time-trigger (every first day of the month for example). With a proper reporter in case of error to look at what is wrong, this can all be automated.
Redesigning the Project with Feature Groups¶
Now that we have a specific project to create ready-to-use powerful Feature Groups, we can either revisit the original project to use them or create a new project with this new approach. Let’s see the different steps.
Adding a Feature Group to a Project¶
Note
The Feature Store section is only available starting with version 11 of Dataiku. Should you have an older version, you can still perform this discovery within the DSS Catalog.
The starting place is to look for Feature Groups. This can be done in the Feature Store section of Dataiku.
In this place, you will be able to see all of the Feature Groups with all their details and usage (hence the importance of properly documenting them). Here we can see the two Feature Groups we created in the project above.
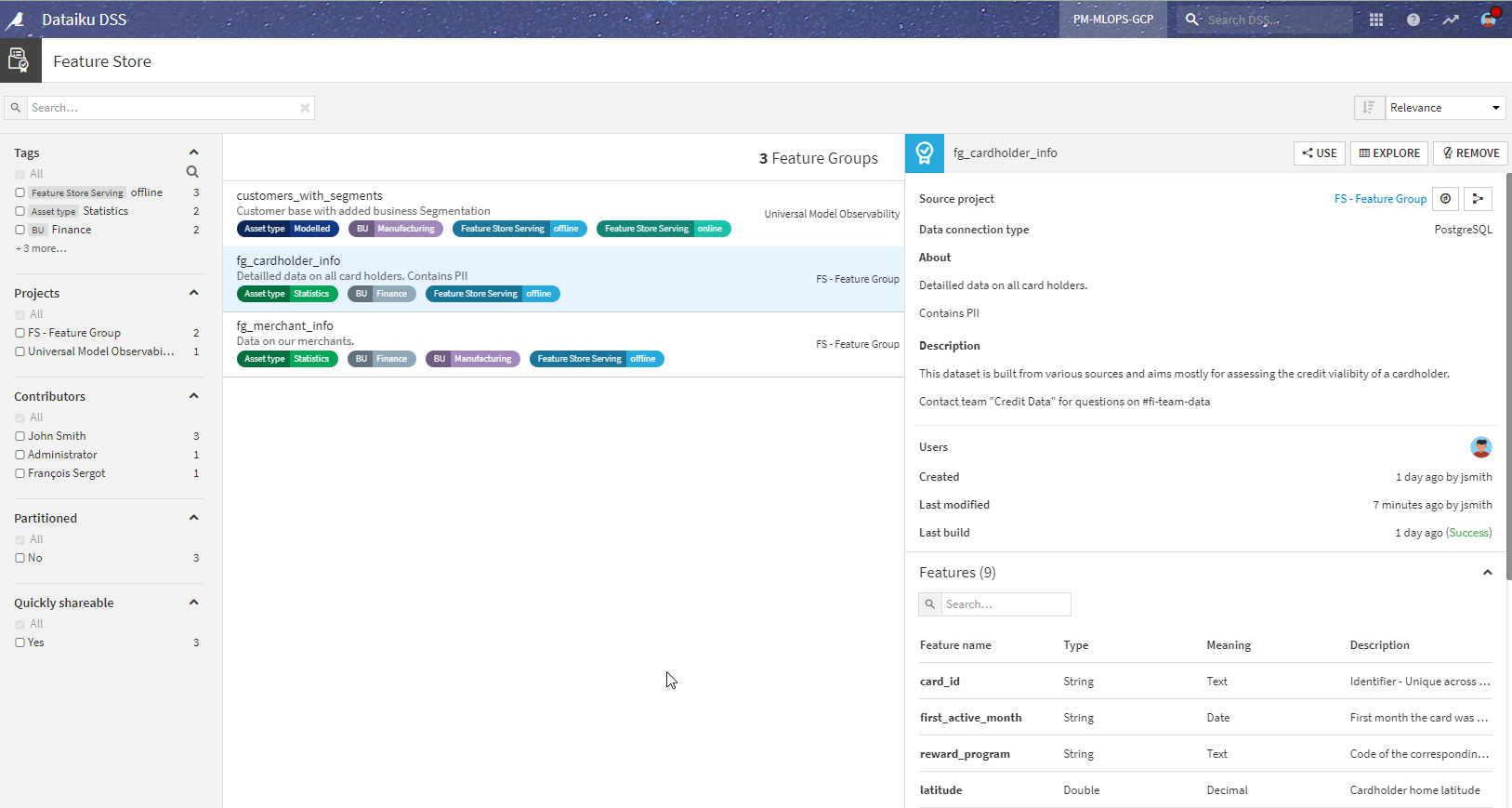
By clicking on the Use button, these Feature groups are made available in your project.
The Redesigned Project¶
After incorporating the Feature Groups into the Flow instead of the original data preparation steps, here is how it looks:
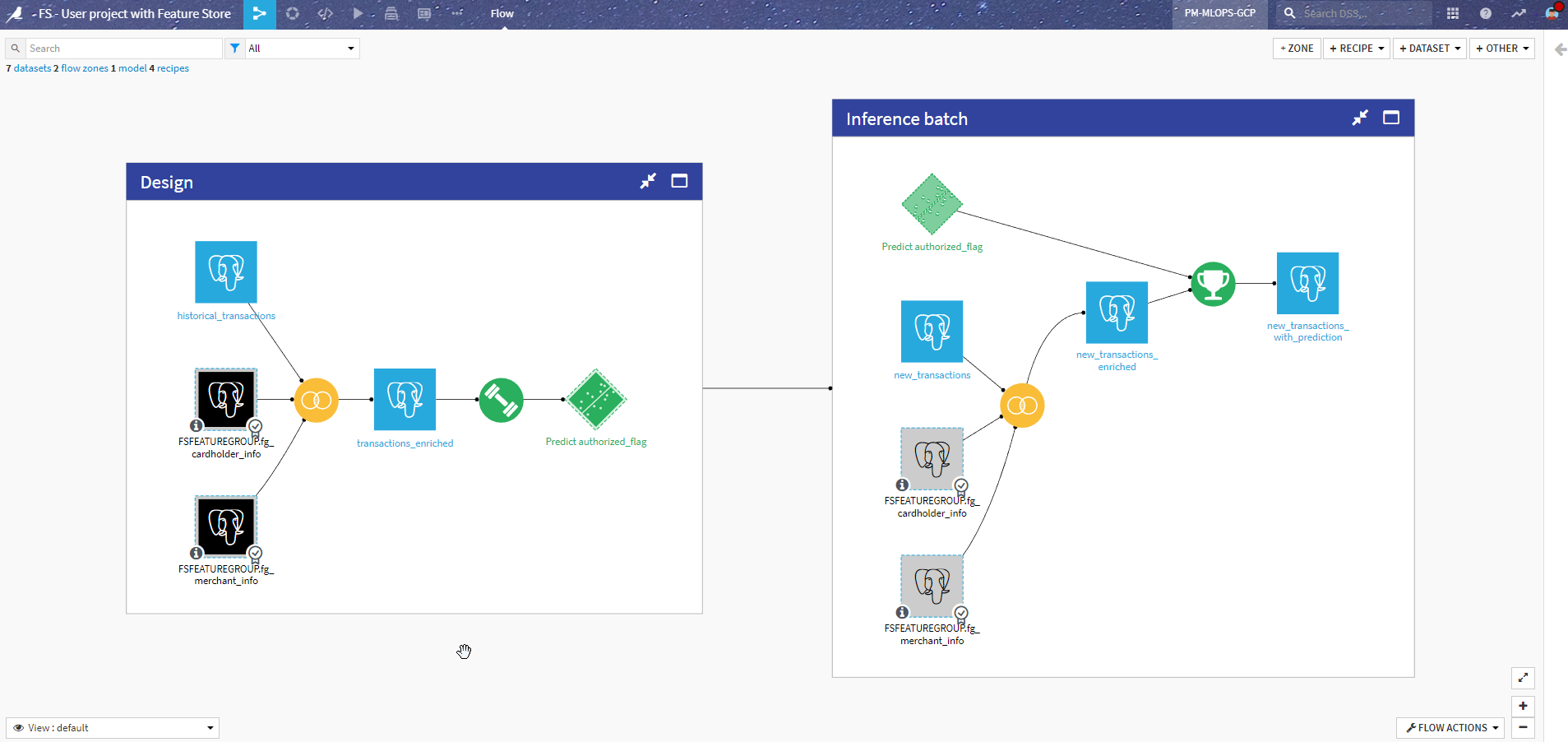
Let’s review the changes compared to the previous version.
Design using Feature Groups¶
The most visible change is that we removed the data processing on the cardholder and merchant datasets. We switched to using the Feature Groups instead, as shared datasets (appearing black in the Flow). Since the schema is the same, this change was pretty straightforward.
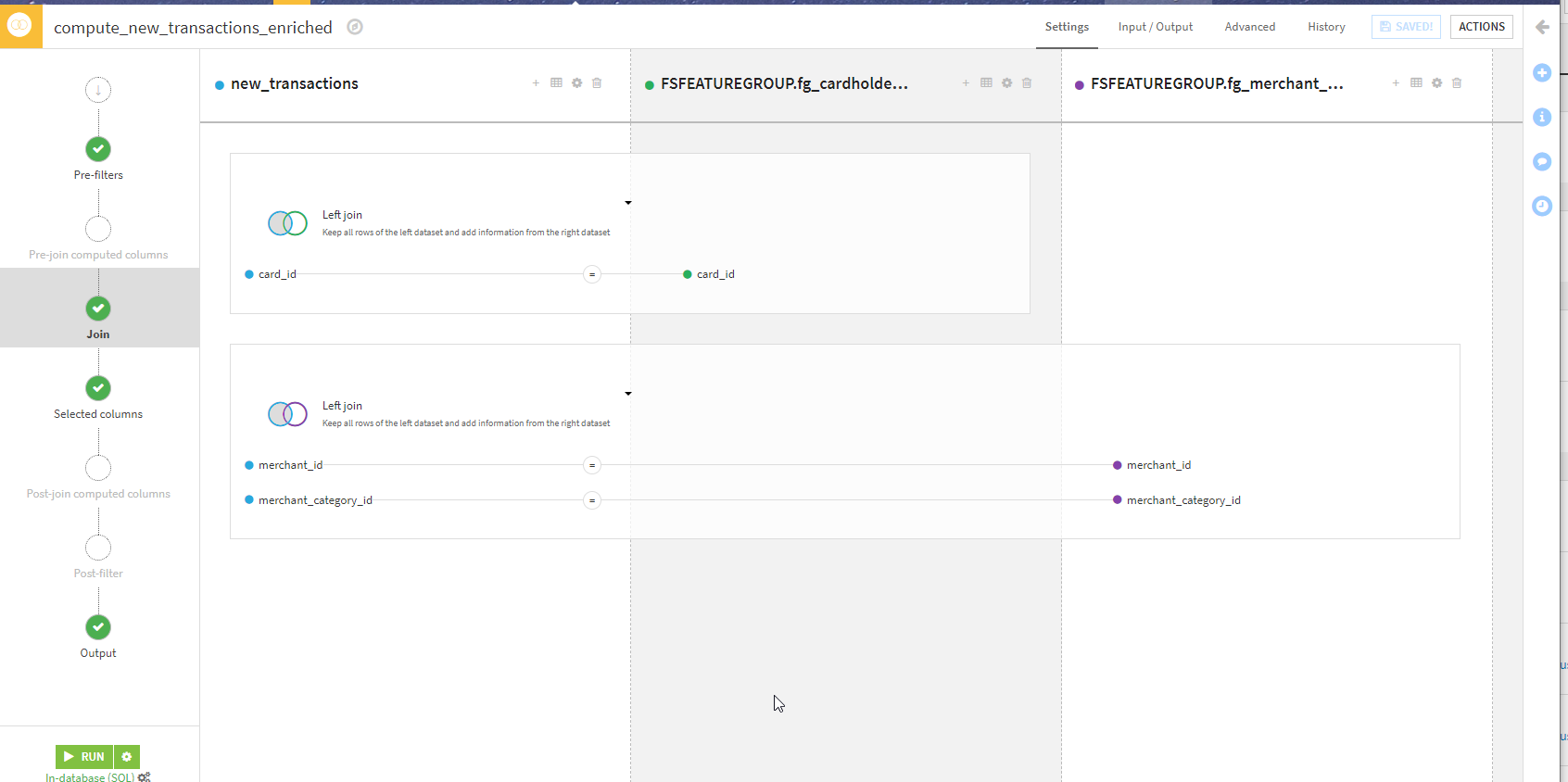
Batch inference using Feature Groups (Offline scoring)¶
This is the part in the “Inference batch” zone where we replace the local datasets with Feature Groups. This is also pretty seamless and with the same Join as above in the design.
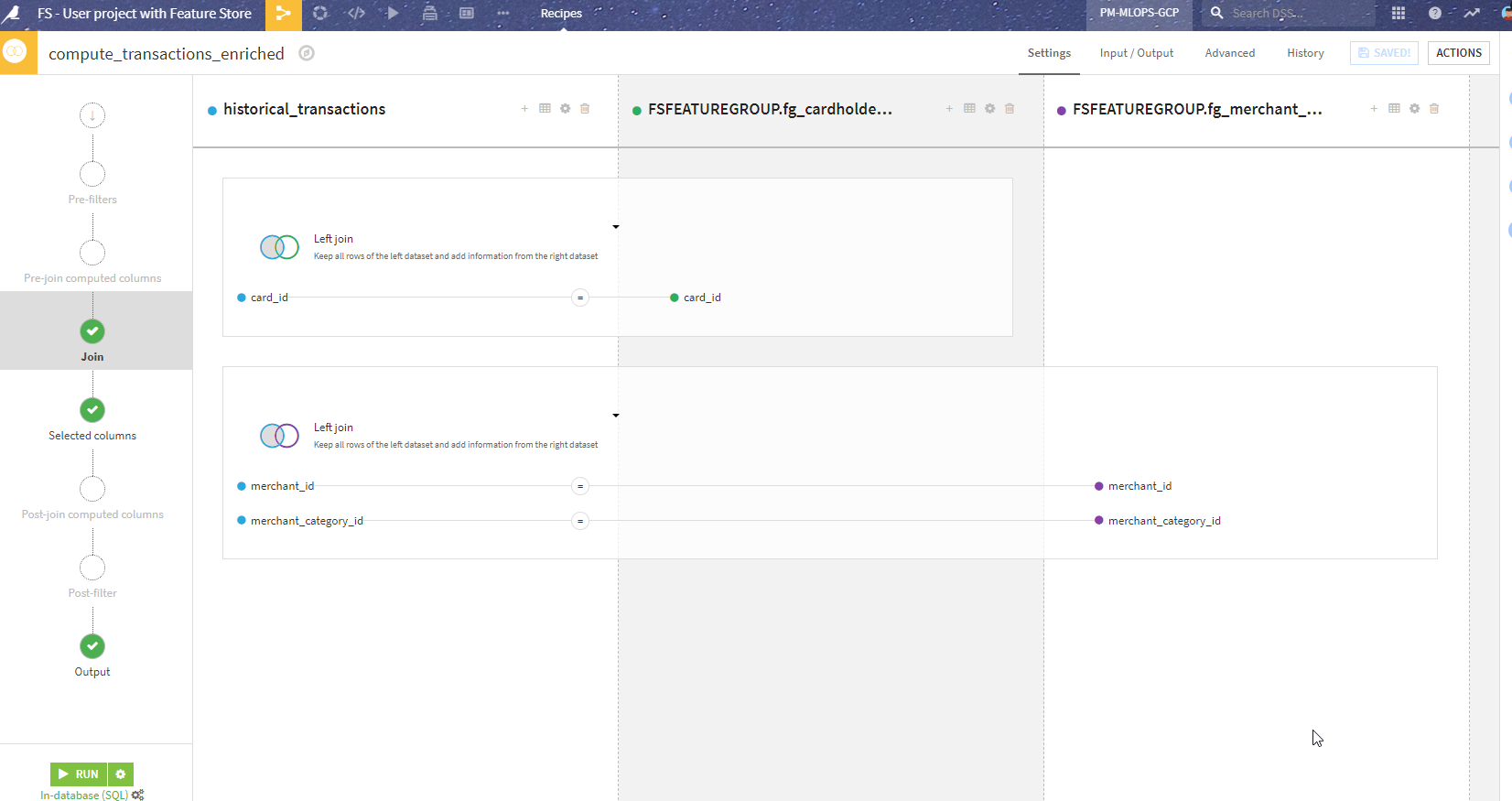
Real-time inference using Feature Groups (Online scoring)¶
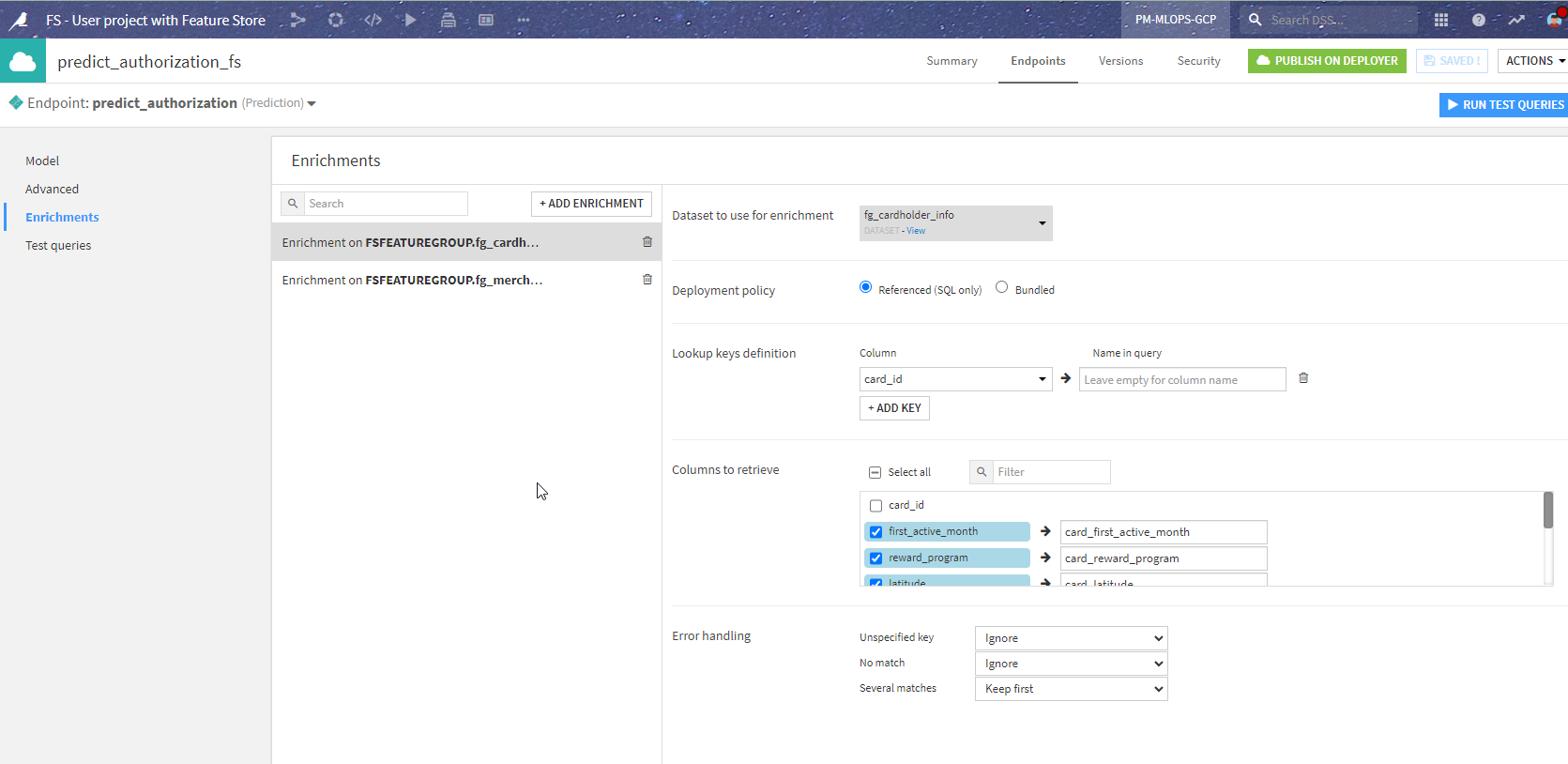
This one requires some changes in the API endpoint definition, similar to the logic above: replace enrichments from local datasets to enrichments from shared datasets. This is how the endpoint in API Designer now looks:
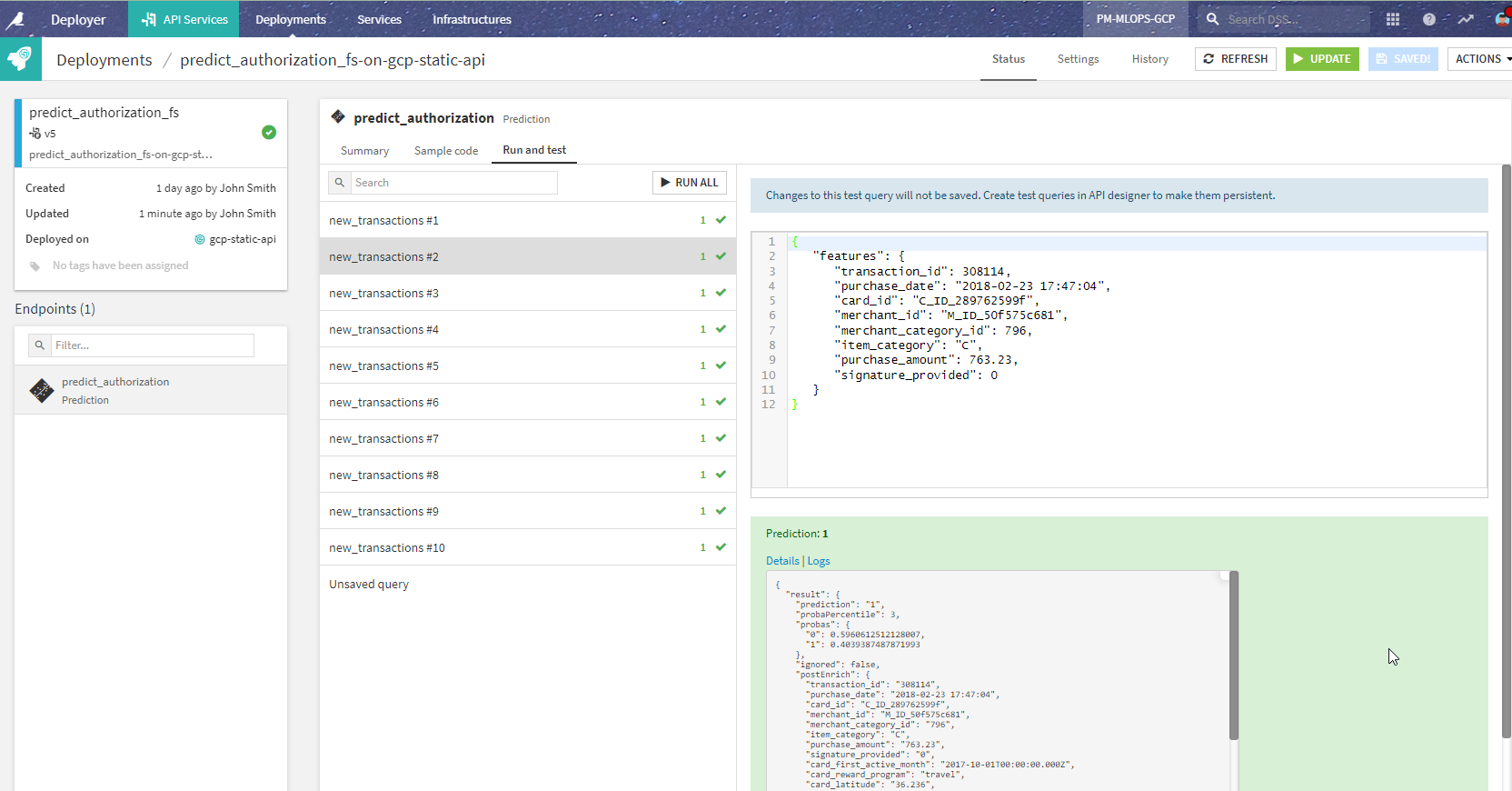
This gives the same results from the API client perspective once repackaged and redeployed (in just a few seconds, thanks to API Deployer).
Conclusion¶
What we have seen is that the biggest work is moving the data preparation to a dedicated project, rather than redesigning the project itself using the Feature Groups.
In the end, we have a simpler project and clearer separation between building the data and using the data for machine learning. Because everything happens in one tool, suitable for both ML engineers and data specialists, there is no complex transition between the two worlds. And you keep the same security, auditing, and governance framework throughout your lifecycle.
Note
For more information, consult the Feature Store product documentation.