The AI Lifecycle: Deploy¶
After experimenting with a range of models built on historic training data, the next stage of the AI lifecycle is to deploy a chosen model to score new, unseen records. The same flexibility DSS brings to model building extends to model deployment. Whether batch or real-time scoring is the right option for a particular use case, DSS has robust tools in place.
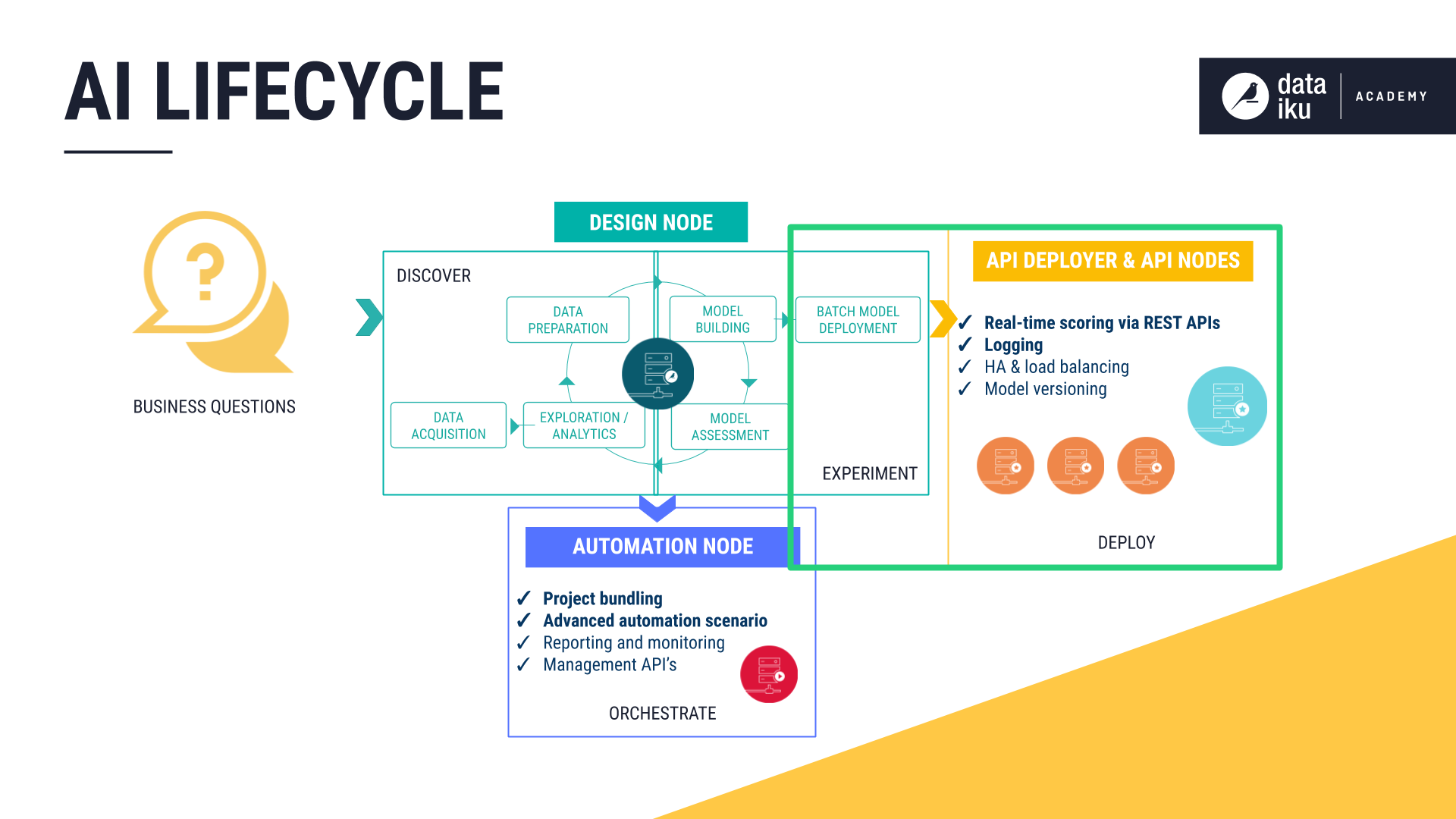
Batch Scoring¶
For many AI applications, batch scoring, where new data is collected over some period of time before being passed to the model, is the most effective scoring pattern. To score a dataset full of records in batch, a user deploys a model to the Flow, attaches a Score recipe to the dataset to be scored, and selects which model to use.
Deploying a model creates a “saved” model in the Flow, together with its lineage. A saved model is the output of a Training recipe which takes as input the original training data used while designing the model.
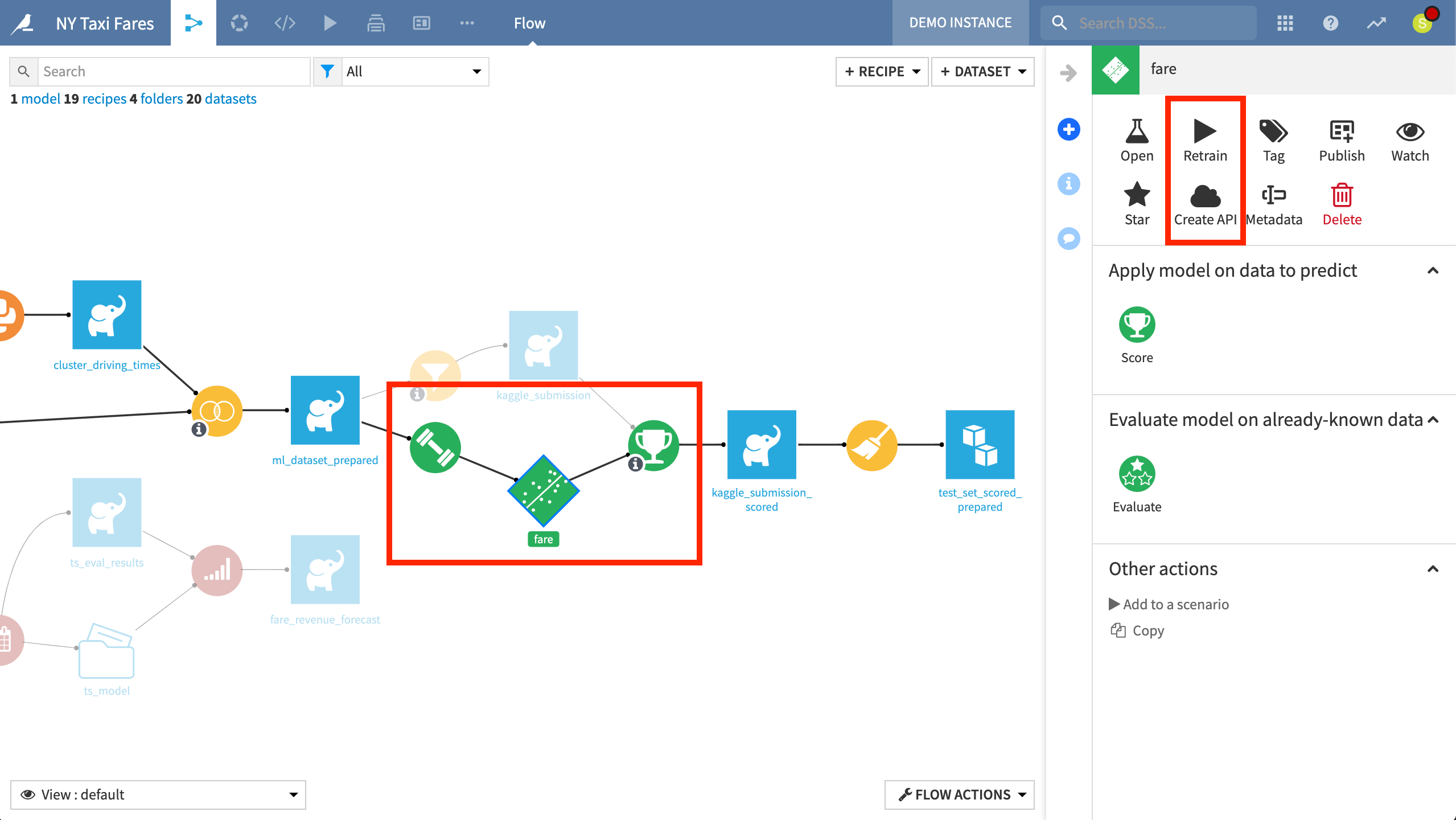
The color green in the Flow represents machine learning processes. The first green circle is the Training recipe. The diamond is the model, which is the output of the Training recipe. The green circle to the right is the Score recipe, which is used to generate predictions for the unseen “kaggle_submission” dataset.
Models aim to capture patterns in a moving and complex world. Accordingly, they must be monitored and re-trained over time in order to prevent model drift. A saved model can be retrained directly from the Flow as new data becomes available.
Despite frequent model re-training sessions over the course of a project’s lifetime, DSS makes it clear what version of the model is active at any given time and makes it easy to fall back to a previously-deployed version when necessary.
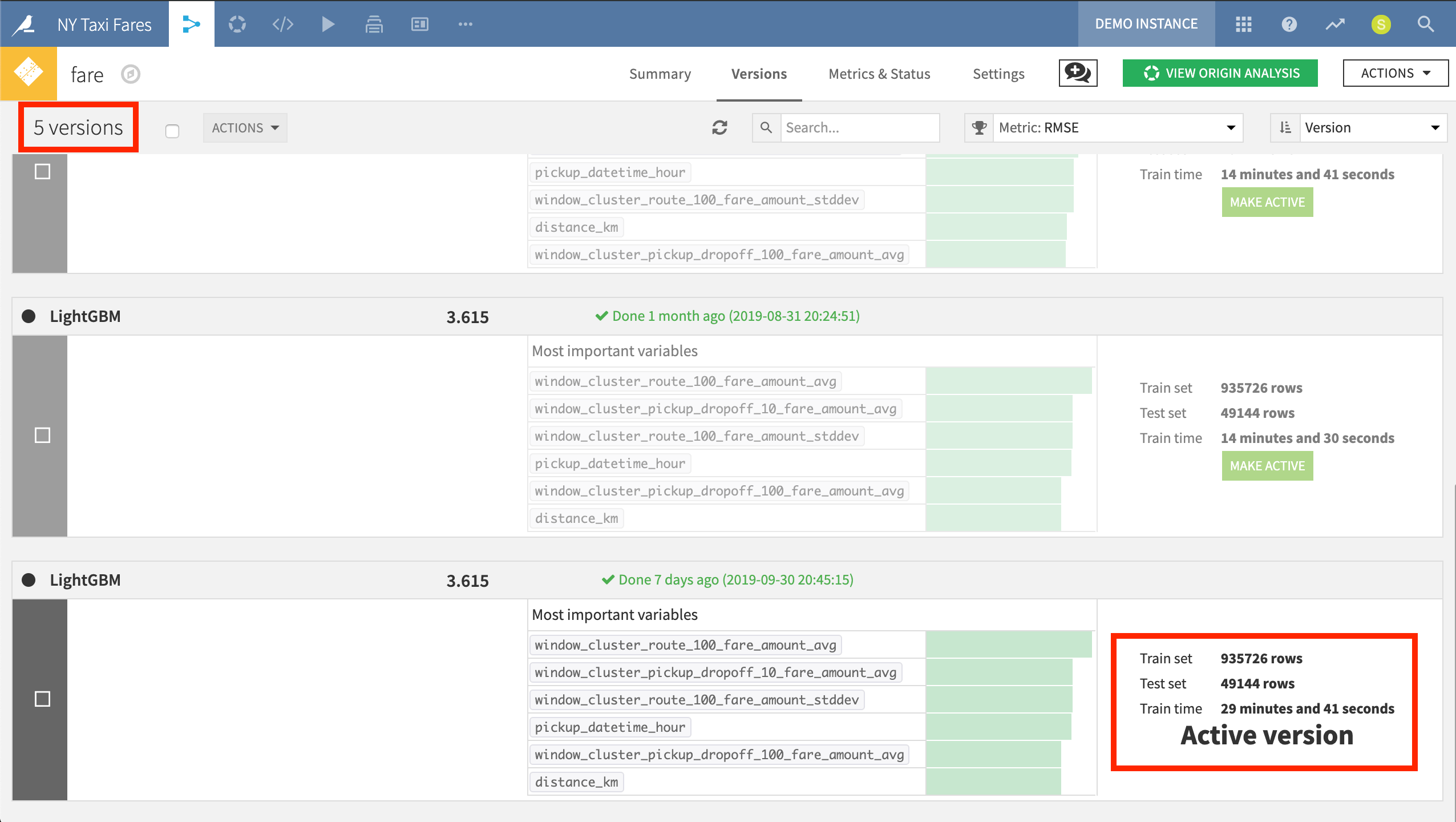
In the NY Taxi Fares project, we have deployed five versions of the LightGBM model, but it’s clear which is the active version.
Real-Time Scoring¶
For use cases with a real-time need, batch scoring may be an insufficient answer. To score records as they arrive in real-time, an infrastructure dedicated to handling the scoring requests is required. Dataiku API nodes can be installed on static servers or on a scalable Kubernetes cluster.
In the Design node, users can create an API service with a chosen model as its endpoint. Once this service is pushed to the API deployer, it can be deployed to (possibly many) API nodes. Using the API Deployer, one can monitor the performance of the model for a given stage of deployment.
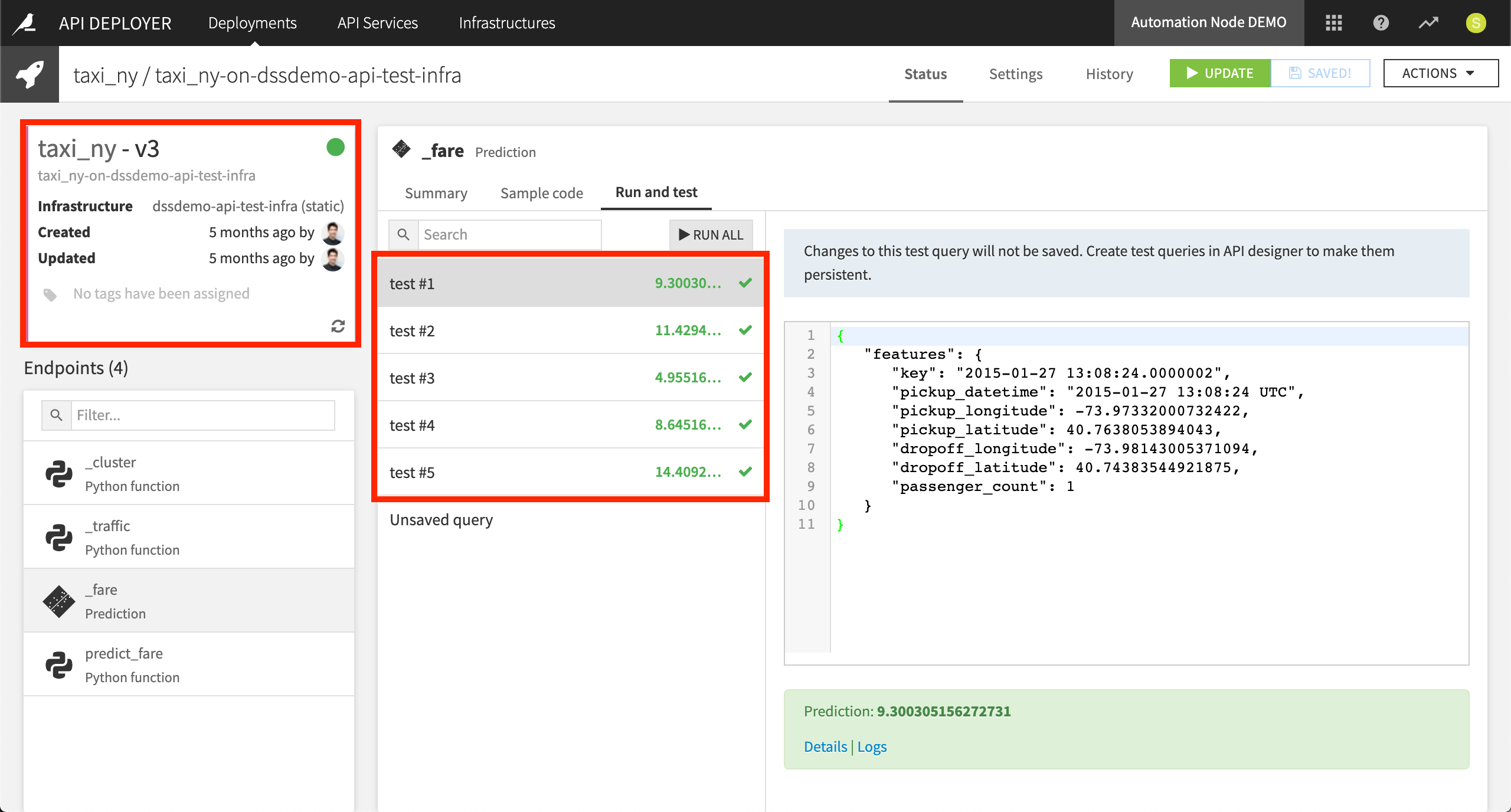
From the API Deployer, we can examine different versions of the API and the endpoints we have created. In our example, we are using a static infrastructure defined over the Dataiku static API node. We also have the ability to run test queries against endpoints. For each of these five test queries, we receive different fare predictions.