Concept: Endpoints and Query Enrichments¶
In this lesson, we’ll go into more detail about API endpoints and what kinds are available in Dataiku DSS. Then we’ll see how to create a particular kind of endpoint, test it, and query it. We’ll also see how to enrich queries that are sent to an endpoint.

Tip
This content is also included in a free Dataiku Academy course on Real-Time APIs, which is part of the MLOps Practitioner learning path. Register for the course there if you’d like to track and validate your progress alongside concept videos, summaries, hands-on tutorials, and quizzes.
API Endpoint¶
An API service exposes one or more endpoints. An endpoint is a single path on the API (that is, a URL to which HTTP requests are posted, and from which a response is expected).
Each endpoint fulfills a single function; therefore, An API service that provides several different functions necessarily contains several endpoints. For example, a banking API service that returns predictions for credit card fraud detection and also returns the probability of loan default would expose two different prediction endpoints.
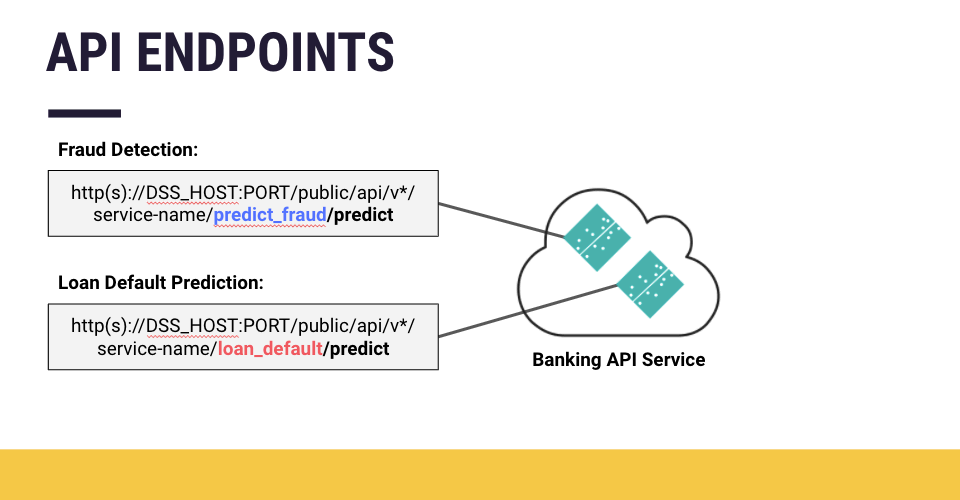
Types of Endpoints¶
You can have many different kinds of endpoints in an API service. In Dataiku DSS, the API node supports creating endpoints such as:
Prediction endpoint, to perform predictions using models created with the visual ML tool. This endpoint can include optional data preparation steps that have been performed in the preparation script of the visual ML tool.
Custom prediction (Python or R) endpoint to perform predictions using a custom model developed in Python or R.
Python/R function endpoint to call specific functions developed in Python or R.
SQL query endpoint to perform parameterized SQL queries.
Dataset lookup endpoint to perform data lookups in one or more Dataiku datasets.
Create an Endpoint¶
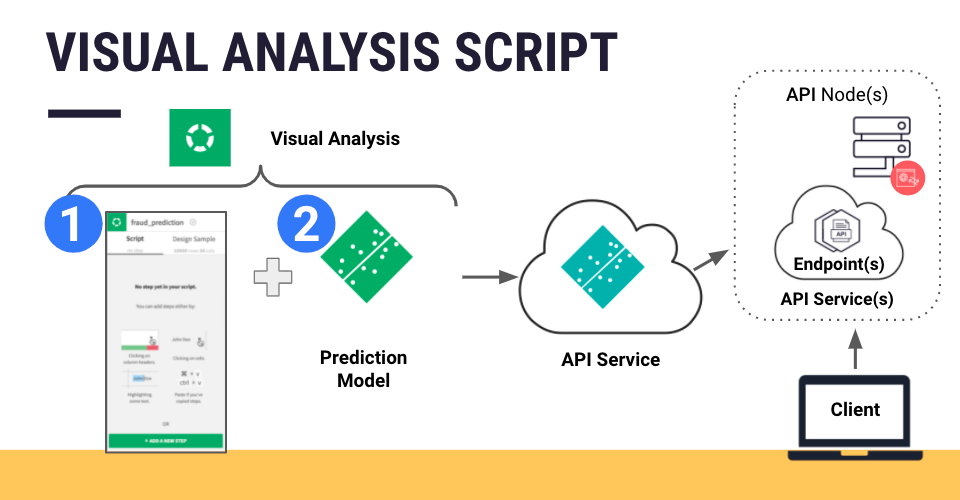
To demonstrate endpoint creation, we’ll create a prediction endpoint. Given a Dataiku project that contains a visual ML prediction model in the Flow, we’ll expose the model as a prediction endpoint.
To create API services and their endpoints, we use the API designer tool. Here, we can specify the kind of endpoint to create; in this example, a prediction endpoint.

Alternatively, a quick way to create a prediction endpoint is to select the deployed model directly from the Flow, and select the Create API option from the right-hand panel. This will open the API designer tool where the kind of endpoint will automatically be specified as a prediction endpoint
Note that if the visual analysis used to create the prediction model includes data preparation steps (in the “Script” tab), these steps will be included in the endpoint that is part of the API service deployed to the API node. As a result, records sent as API calls will first be preprocessed according to the steps in the prepare script of the visual analysis, before being passed to the model for scoring.
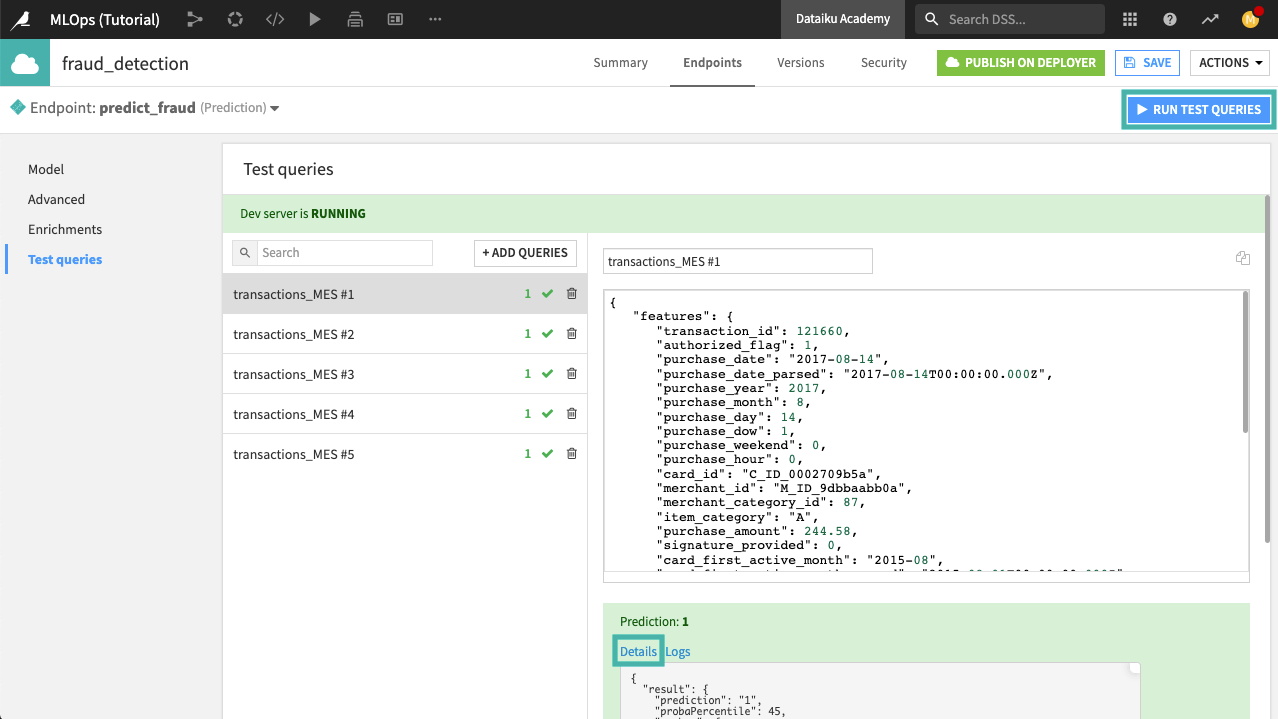
Test the Endpoint¶
In the “Test queries” section of the API designer tool, you can write your own test query in JSON format, or you can specify to run a few random queries selected from a dataset.
When you run the test queries, the endpoint will output predictions for each test query, and you can view the details of the run to get the complete endpoint response.
Query Enrichment¶
Enrichments can enhance features by using a lookup on another table. An enrichment can be useful when the endpoint uses certain features to perform its function, but some of these features are not available to the client making the API request.
For example, in our example on credit card fraud detection, at the time of the transaction, the client making the API request could know the transaction amount, but might not have any information on the cardholder’s FICO score.
Since the features that are missing from the API request, such as the FICO score, are stored in our company’s internal database, we can use an enrichment to retrieve these features and pass them to the prediction endpoint. This way, the endpoint will have all the features needed for processing the request and returning a valid response.
Configure an Enrichment¶
You can configure query enrichments in the Enrichment tab of the API designer. In our credit card fraud example, we’ll enrich each query with a few additional features about our cardholders.
Enrichment data can either be bundled or referenced.
A bundled data deployment policy means that the contents of the lookup table are copied and deployed as part of the API service on the API node. This mode is generally preferred when the lookup table is fairly small.
A referenced data deployment policy means that the data for the lookup table is not managed by the API node. When you export an API service from DSS, the service does not contain the data. It only contains a reference to the original dataset, such as a connection name and a table name.
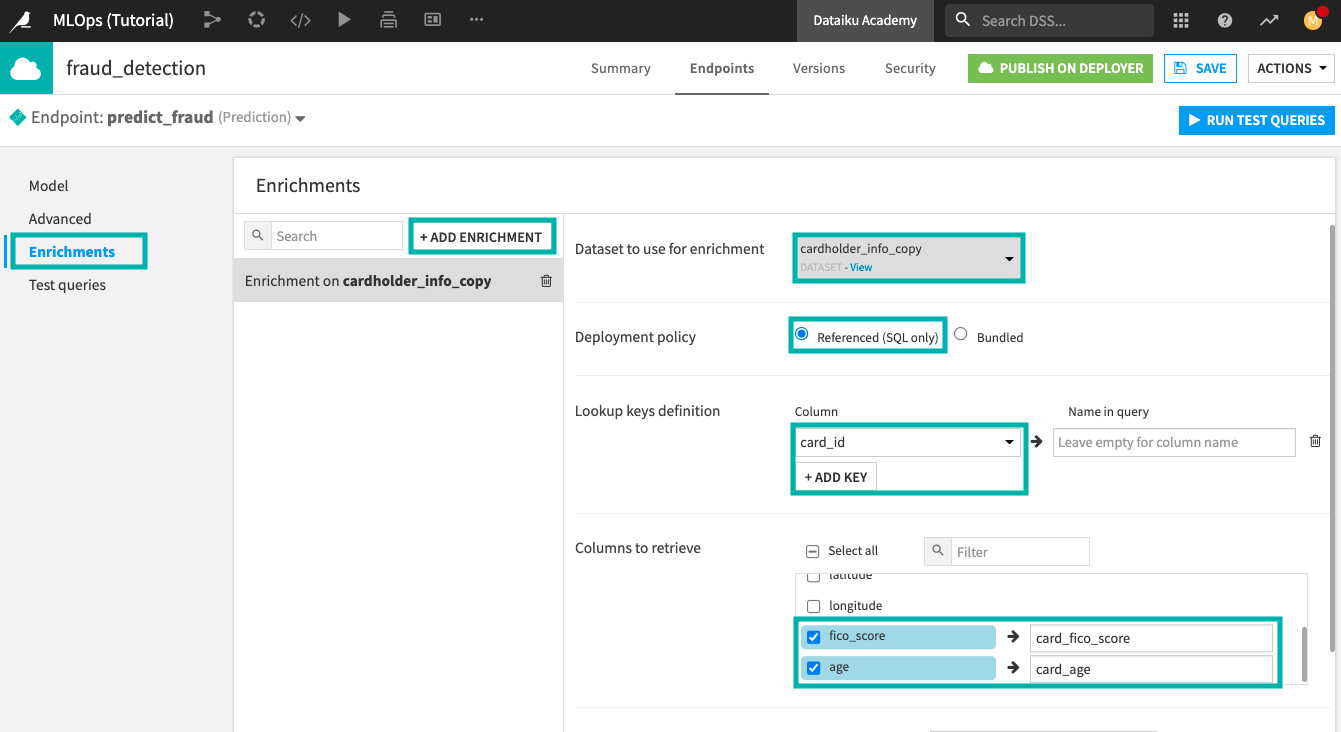
Once the enrichment is configured, you can try running a few test queries that have missing features, so that these missing features can be retrieved through enrichment. If you’ve selected the option to “return post-query enrichment” in the “Advanced” tab, you will see the results of the enrichment in the “Details” section of each query.
What’s Next?¶
To get hands-on practice on using endpoints and enrichments, follow the Hands-On Tutorial: Create Endpoint and Test Queries.