Product Recommendation¶
Overview¶
Business Case¶
Recommending the right product to the consumer is a win-win situation for both companies and their customers. A relevant way to do it is to implement a recommendation engine based on a collaborative filtering approach. It aims at answering the following question: what are the items that users with interests similar to yours like? By doing so, brands can recommend products that have not yet been purchased by a user and that a group similar to this user has purchased. They’re critical for certain types of businesses because they can expose a user to the content they may not have otherwise found or keep a user engaged for longer than they otherwise would have been.
The solution consists of a data pipeline that applies collaborative filtering to “Established” customers in order to train a product recommendation model which is deployed and used to predict product recommendations for “Growth” customers. Analysts can use the project flow, its accompanying visualizations, and the pre-built webapps as inspiration for their own implementations of a Product Recommendation Engine. Roll-out and customization services can be offered on demand.
Technical Requirements¶
To leverage this solution, you must meet the following requirements:
Have access to a DSS 10.0+ instance
PostgreSQL database named
postgresqlcontaining transactions data. If using a database with a different name or a Snowflake SQL database the project should be installed by importing the .zip project fileA Python 3.6 code environment named
solution_product-recommendationswith the following required packages:
dash==2.3.1
Note
When creating a new code environment, please be sure to use the name solution_product-recommendations
Installation¶
Once your instance has been prepared, you can install this solution in one of two ways:
On your Dataiku instance click + New Project > Industry solutions > Retail > Product Recommendation.
Download the .zip project file and upload it directly to your Dataiku instance as a new project.
Data Requirements¶
The Dataiku flow was initially built using publicly available data from the UCI Machine Learning Repository . There are two input datasets to the flow:
Item_Lookup contains the information of individual products with the following columns:
A product (StockCode)
Product type (Category)
Product Description (Description)
At a given unit price (UnitPrice)
sales_history contains the history of transactions for all customers with the following columns:
A transaction (InvoiceNo)
A product (StockCode)
Product Quantity Purchased (Quantity)
Transaction Date (InvoiceDate)
Purchasing Customer (CustomerID)
Transaction Location (Country)
Workflow Overview¶
You can follow along with the sample project in the Dataiku gallery.
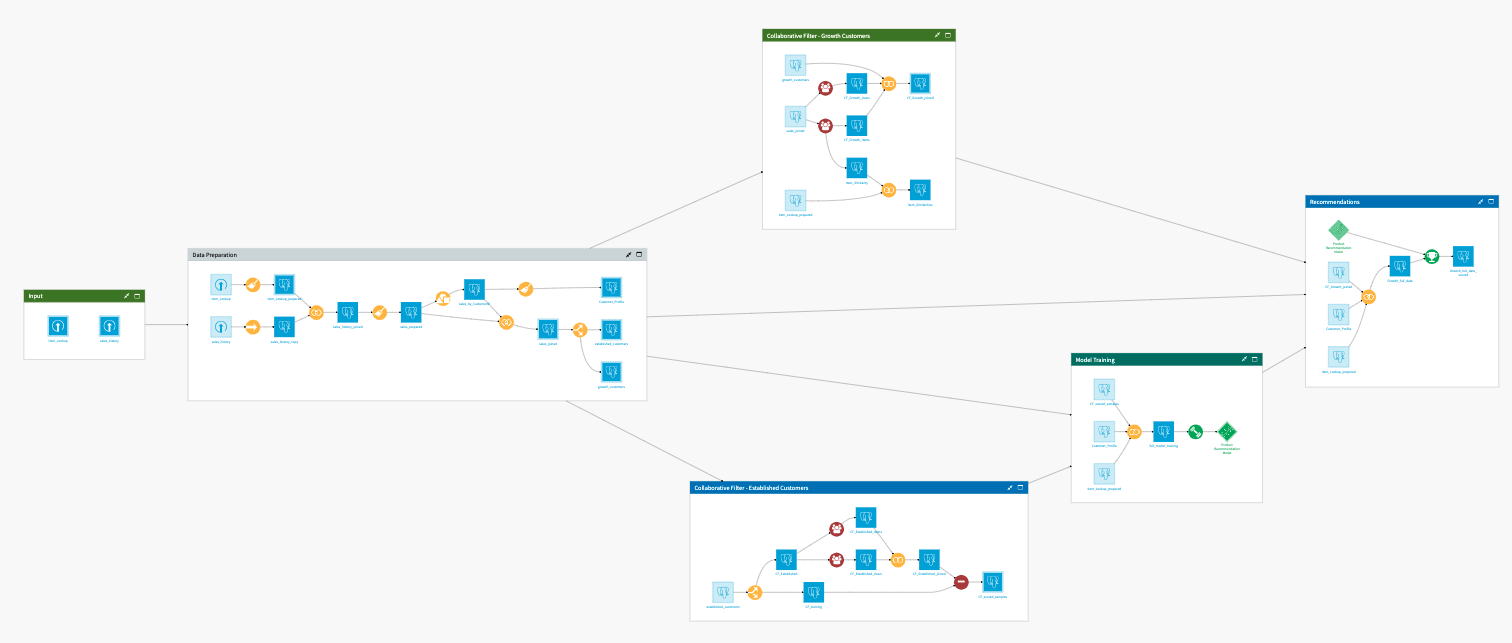
The project has the following high-level steps:
Join and prepare our input data.
Apply collaborative filtering on established customers to create negative samples for downstream modeling.
Train a recommendation model with VisualML.
Calculate affinity scores and apply collaborative filtering on growth customers.
Predict product recommendations for growth customers.
Interactively explore the outputs of our analytics flow and automate reports.
Walkthrough¶
Note
In addition to reading this document, it is recommended to read the wiki of the project before beginning in order to get a deeper technical understanding of how this solution was created, the different types of data enrichment available, longer explanations of solution-specific vocabulary, and suggested future direction for the solution.
Prepare our Data and Identify Customer Types¶
The first two flow zones of our project are fairly straightforward. We begin in the Input flow zone by bringing in our initial 2 datasets. The datasets’ schemas are detailed in the Data Requirements section above. The initial datasets are passed along to the Data Preparation flow zone where they are written into a PostgreSQL database. It is not necessary for the data to be SQL database this early in the flow, it is only required for the input/output datasets of the collaborative filtering recipes, but for ease, we have chosen to create the entire flow using SQL datasets. It is possible to alternatively use a Snowflake database by switching the connection type.
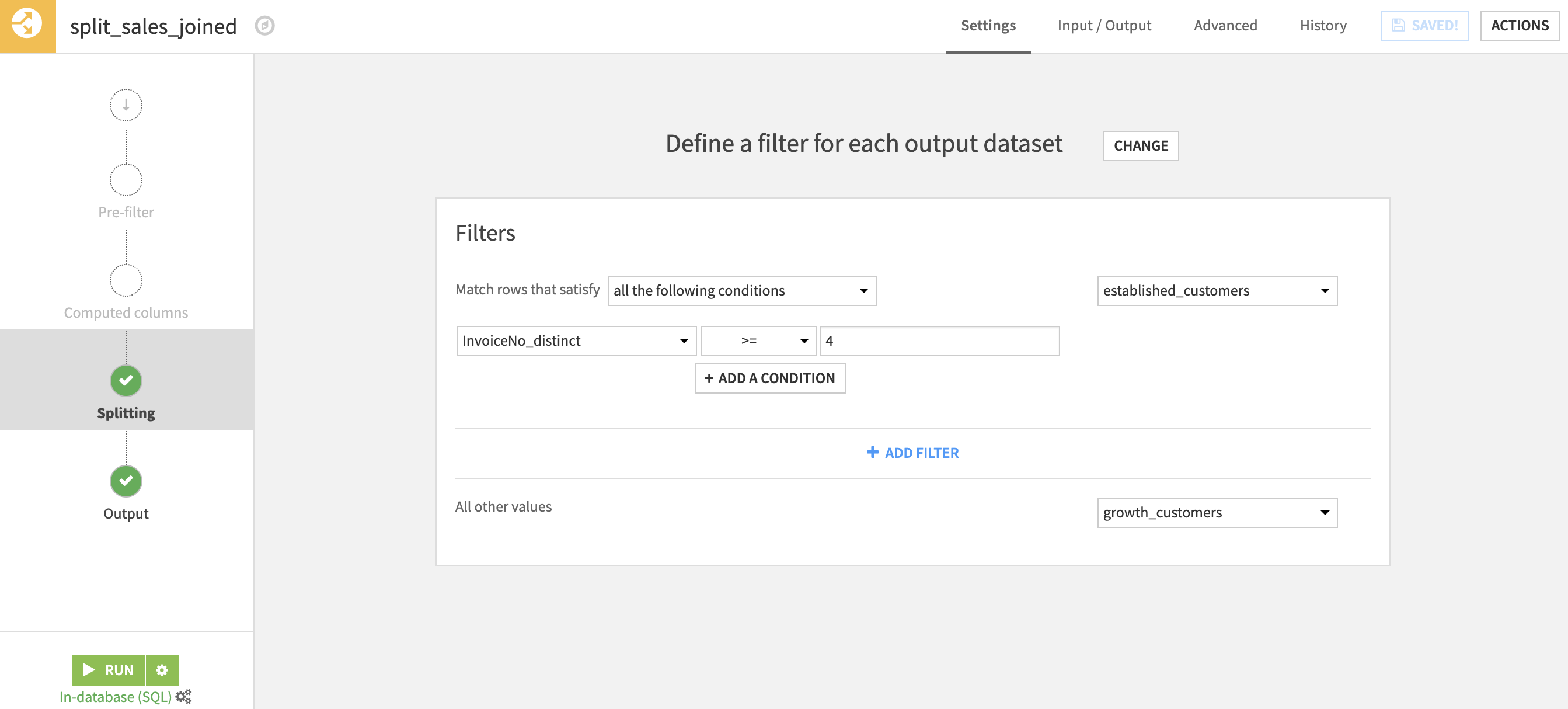
The initial preparation steps clean up our data and create binary values for each item category. We then move on to aggregating our transactions history by the customer to identify the total number of transactions/visits per customer. We then identify 4 transactions per customer as the average for our data and set this value as our threshold for splitting our customer types. Customers with 4 or more transactions/visits are considered “Established” customers whereas customers with less than 4 transactions/visits are classified as “Growth” customers. We will train our recommendation model using the “Established” customers in order to predict product recommendations for our “Growth” customers in order to increase their repeat business.
Feature Engineering using Collaborative Filtering of Established Customers¶
Collaborative filtering is an approach to feature engineering that makes use of information about the number of interactions and user ratings for products to generate affinity scores between users and products. These scores are based on correlations between pairs of items and pairs of users. Using matrix factorization, these affinity scores for a given user/item pair are calculated from the pairwise correlations. In this project, product recommendations are built on the basis of implicit feedback only. Even without rating information, collaborative filtering can generate affinity scores that provide meaningful information for downstream recommendations.
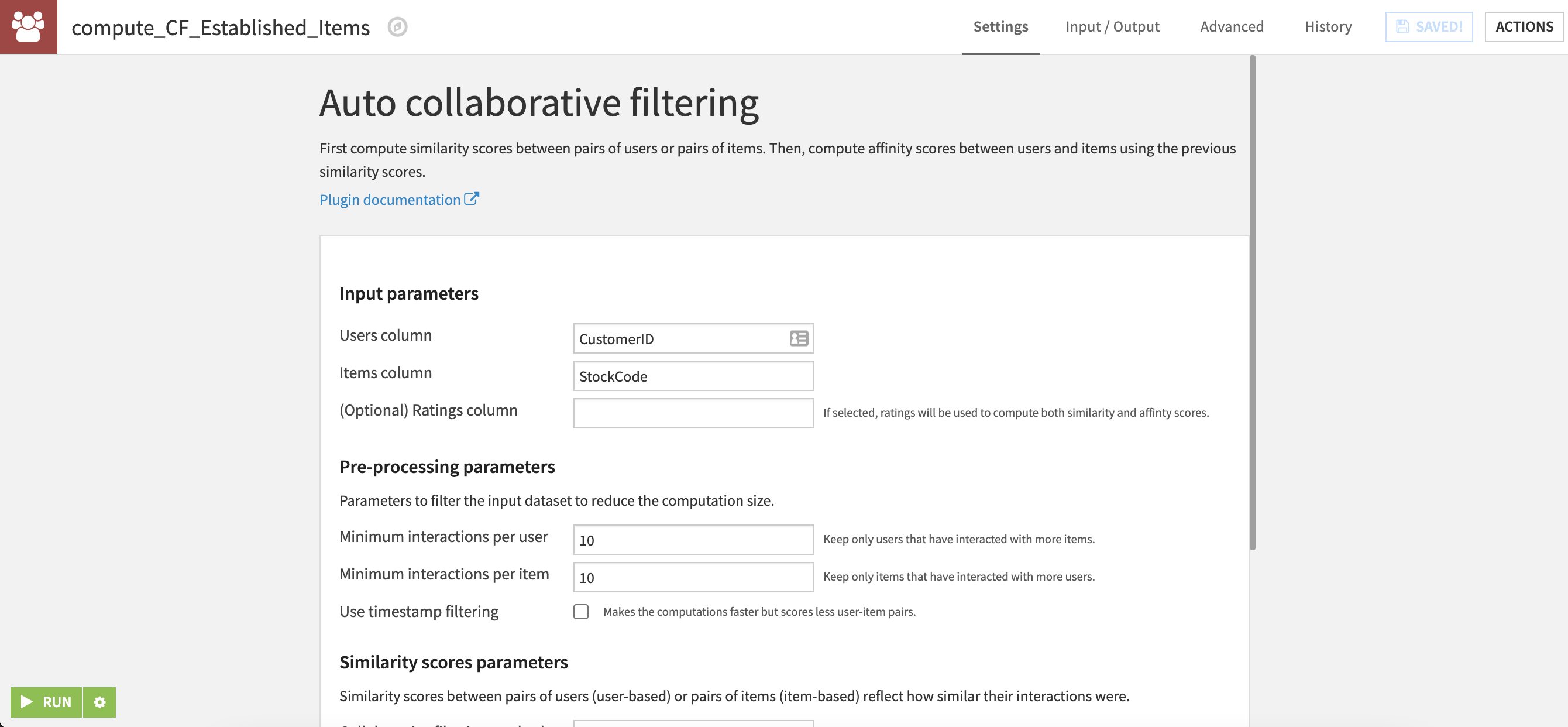
The Collaborative Filter - Established Customers flow zone takes our dataset of Established customers and splits it into a training set and a hold-out set to be used for collaborative filtering. Affinity scores are computed using two instances of the Collaborative Filtering recipe of the Recommendation System plugin - one that makes use of user similarity and the other that uses item similarity. We then join the resulting datasets at the customer and item level which results in each user/item having two affinity scores. Finally, we use this dataset, along with the training dataset previously split out, with the Sampling Recipe of the Recommendation System plugin to generate a random set of samples. The recipe generates a fixed number of samples that indicate whether or not a user interacted with a given item, effectively creating a target variable with both positive and negative outcomes.
Recommending Products to Grow Customer Engagement¶
With affinity scores built and target values defined, we can move to create a recommendation model in the Model Training flow zone. This flow zone joins the Customer_Profile, Item_Lookup_prepared, and CF_scored_samples datasets into a single training dataset for our model. The datasets are joined by item and customer. With a complete training set, we use Dataiku’s visual ML feature to train a classification model that predicts whether or not a user will buy a given item. For our particular set of data and features, a Random Forest model provided the best results compared to Logistic Regression and K Nearest Neighbors algorithms. Model metrics will be dependent on your own set of data.
Before we can use our newly trained model to start recommending products to our customer base, we need to first do some additional preparation of our Growth Customer data within the Collaborative Filter - Growth Customers flow zone. Just like with our Established customers, we need to calculate the Affinity scores of our Growth Customers based on their similarity with all past customer sales. Additionally, we create a dataset called Item_Similarity from the Collaborative Filtering recipe that uses item affinity. This dataset represents the raw similarity score between each pair of items that we sell.
We have a trained model and prepared data for scoring so it is time to move onto the main event - generating Product Recommendations. The Recommendations flow zone joins Item_Lookup_prepared, CF_scored_samples and CF_Growth_joined into a single dataset for scoring against our deployed Recommendations model. The output dataset contains user/item probabilities. We will show how to use this data as actionable insights within the Analytics Dashboard delivered with the solution.
Automate Recommendations, Deep Dive on Customers, and Analyze Individual Products¶
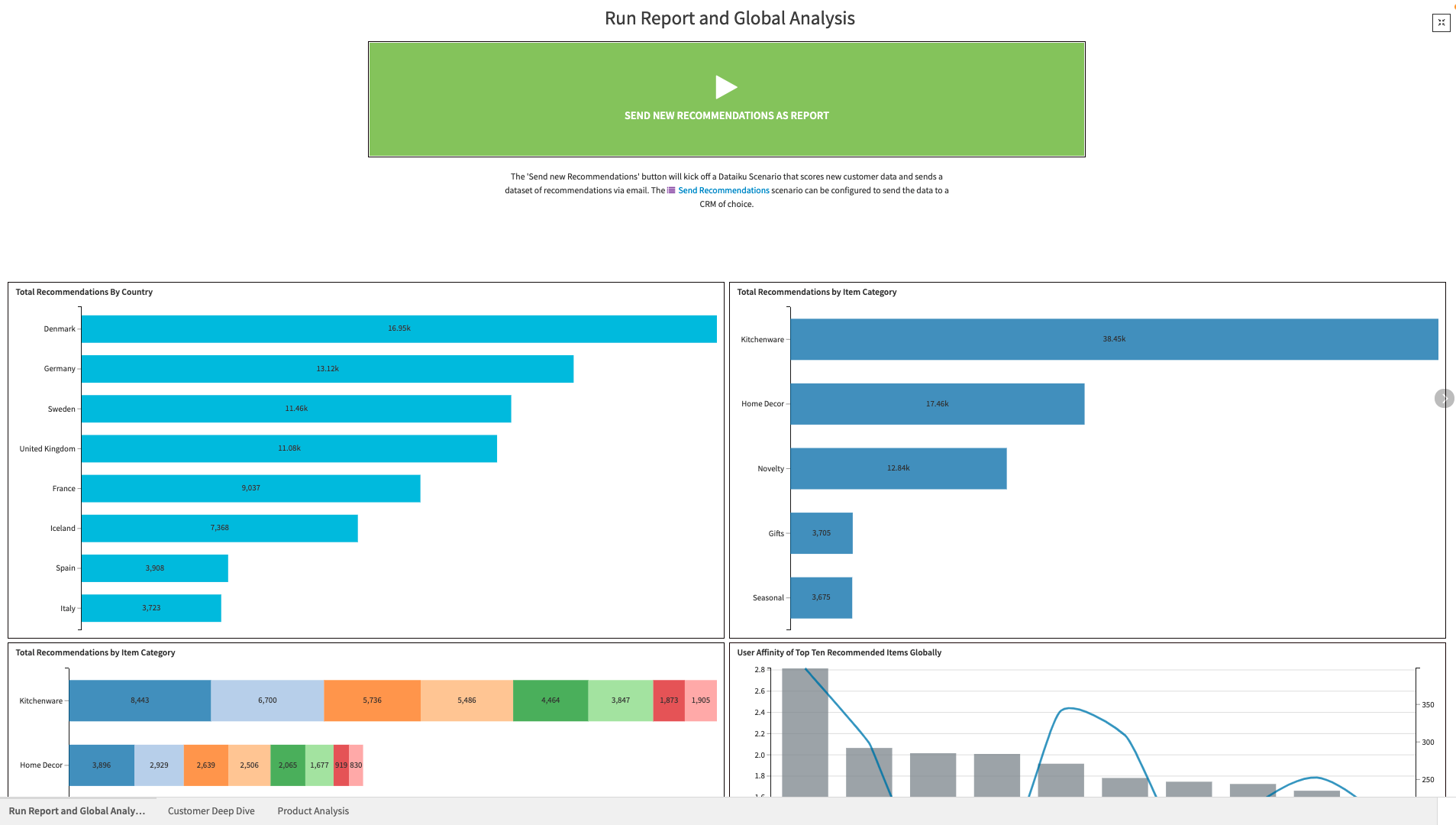
This solution comes with a 3-tab Dashboard that includes ready-to-use visualizations and interactive tools.
The Run Report and Global Analysis tab of the dashboard allow users to easily predict and make new recommendations to a pre-configured email or CRM tool. Users only have to configure the Send Recommendations scenario with their CRM of choice and click the green Run Report button in the dashboard to do so. This scenario can be further automated by setting up auto triggers. This tab additionally aggregates information on the latest recommendations and users to provide a snapshot of trends among growth customers.
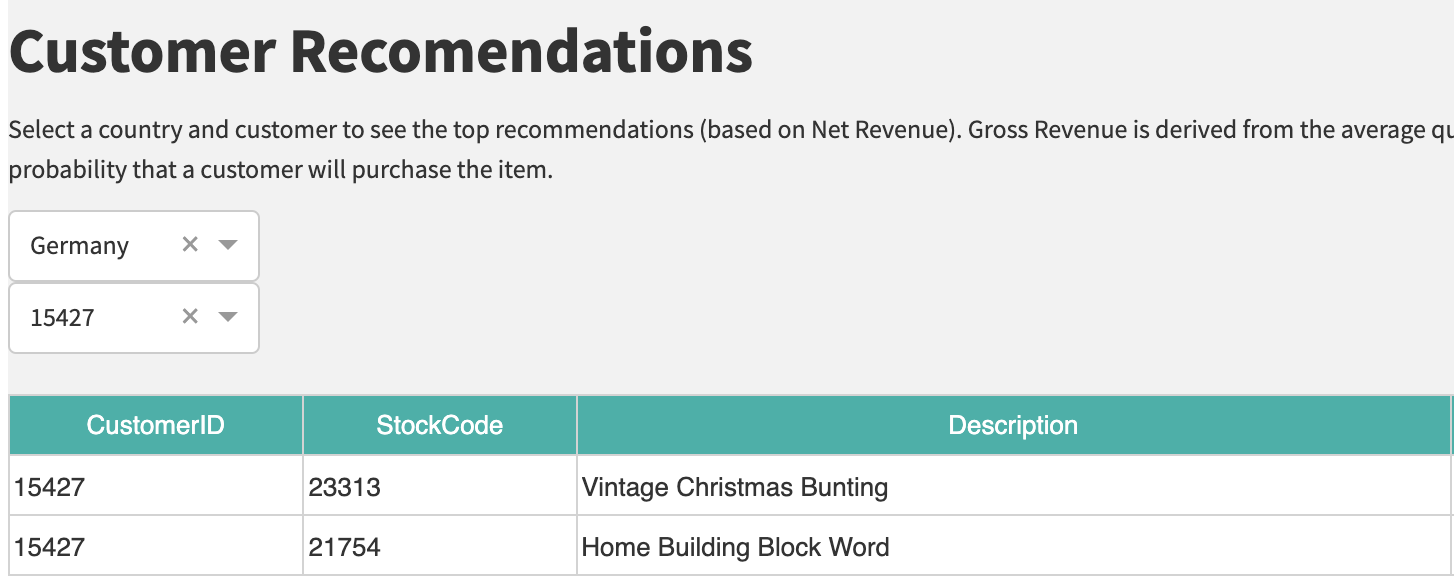
A dash webapp is embedded in the Customer Deep Dive tab with which users can explore the predicted product recommendations for any customer in the Growth Customers dataset. The webapp allows filtering by Country and CustomerID.
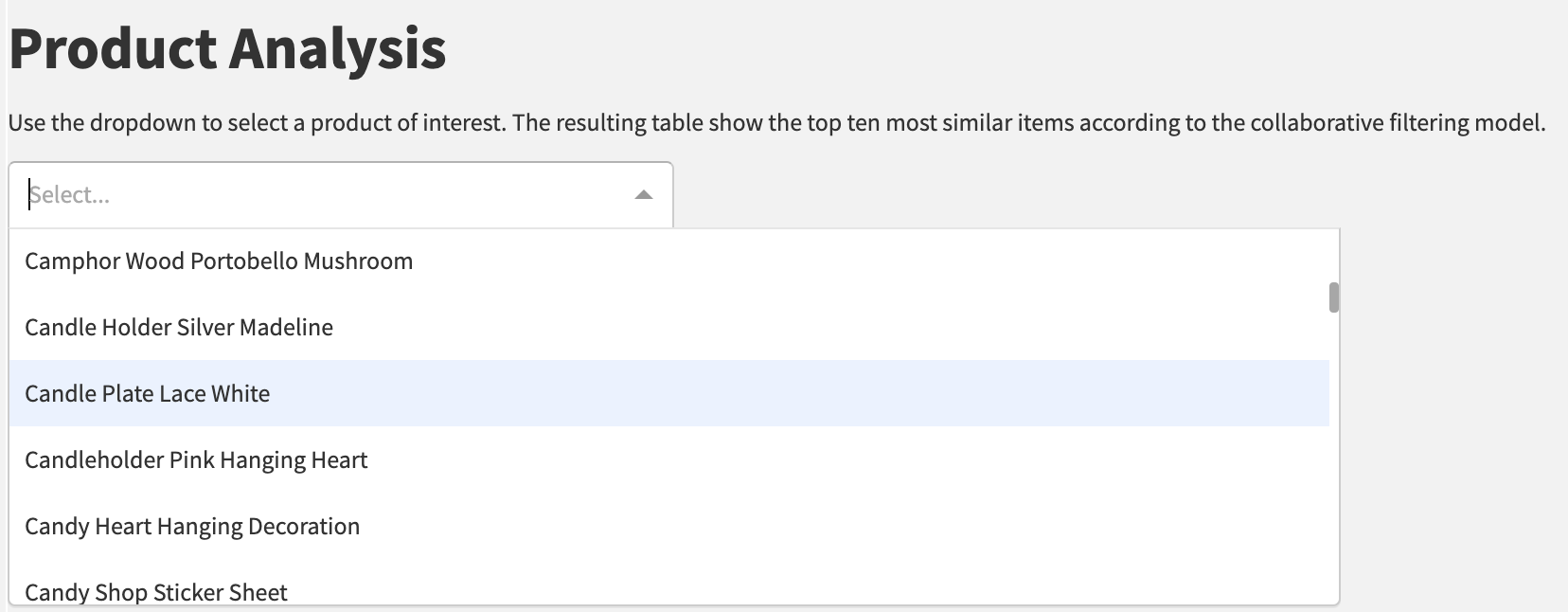
Lastly, the Product Analysis tab provides users with another dash webapp where they can select or search for a specific inventory item. The resulting output shows the items with the highest similarity scores calculated in the Collaborative Filter - Growth Customers flow zone. This analysis can provide us with an understanding of which products tend to be bought together. However, if we want to do a more thorough analysis of which products are most often bought together, we can use the Market Basket Analysis Solution.
Reproducing these Processes With Minimal Effort For Your Own Data¶
The intent of this project is to enable compliance teams to understand how Dataiku, and in particular the newly released Recommendation System plugin, can be used to generate product recommendations for customers. By creating a singular solution that can benefit and influence the decisions of a variety of teams in a single organization, smarter and more holistic strategies can be designed in order to engage with customers, design marketing strategies, and serve as the basis for better product pricing.
We’ve provided several suggestions on how to use transaction data to recommend products but ultimately the “best” approach will depend on your specific needs and your data. If you’re interested in adopting this project to the specific goals and needs of your organization, roll-out and customization services can be offered on demand.