Using AWS AssumeRole with an S3 Connection to Persist Datasets¶
You can use an Amazon Simple Storage Service (S3) connection to persist datasets in Dataiku DSS (DSS). When working with S3 connections, one of the credential mechanisms available is the native AWS AssumeRole.
About the AWS AssumeRole Mechanism¶
Assuming a role means obtaining a set of temporary credentials associated with the role and not with the principal that assumed the role.
How does the AWS AssumeRole mechanism work to allow DSS to interact with the S3 bucket? The following interactions will be carried out with the role assumed, therefore with the rights associated with it:
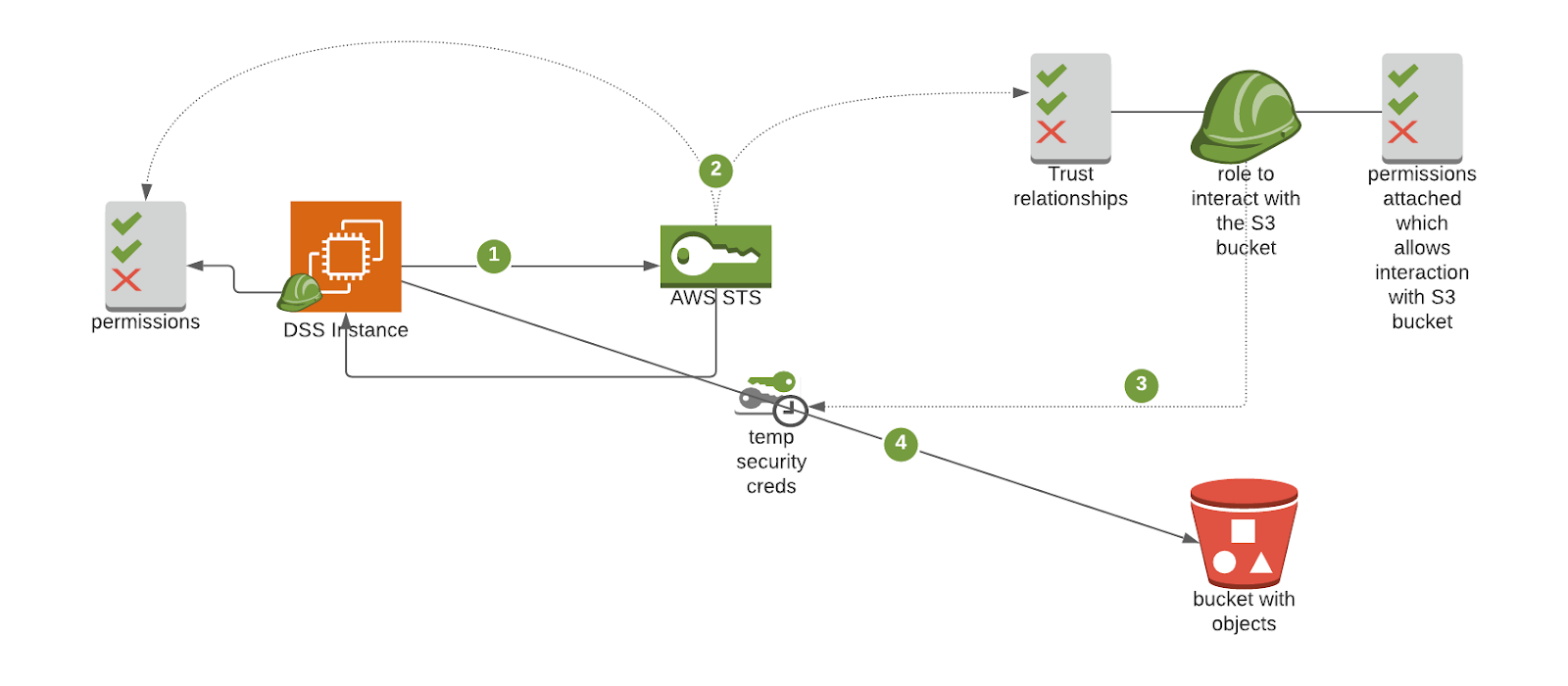
An Amazon EC2 instance running DSS is associated with an instance profile. This is basically an AWS role with associated permissions. To interact with an AWS resource–an Amazon S3 bucket, for example–the instance profile is used to request temporary credentials of the relevant role to the AWS Security Token Service (STS).
STS is an AWS web service that allows you to request temporary security credentials for your AWS resources. STS performs the following checks before allowing the assume request:
Is the instance profile allowed to perform this AssumeRole action by checking its own permissions in IAM?
Is the instance profile trusted by the distant role to assume it?
If both checks pass, STS provides temporary security credentials consisting of an Access Key Id, a Secret Access Key, a Security Token, and an Expiration timestamp.
DSS (including Jobs run by DSS) may now interact with the S3 bucket using these credentials and associated permissions.
AWS CloudTrail tracks every interaction with a dataset stored on an S3 bucket.
Note
You can use AWS CloudTrail to create a trail for auditing details of S3 interactions. Every interaction concerning the role assumed and the role session is auditable and traceable including the role session name.
An interaction tracked and stored by AWS CloudTrail uses the following pattern:
"arn": "arn:aws:sts::<AccountID>:assumed-role/<IAM role defined in the S3 connection>/dss-conn-<DSS connection name>-assumed-for-<DSS frontend User>"
Configure an S3 Connection using STS with AssumeRole¶
Prerequisites¶
To configure an S3 connection using AWS STS with AWS AssumeRole, the following requirements must be met:
The DSS instance profile must be able to use AWS STS. This is needed in order to receive temporary credentials.
The role to be assumed has been properly configured, including policies and a trust relationship, to interact with the bucket.
Configure the S3 Connection¶
To configure a new S3 connection in DSS:
In Credentials, select STS with AssumeRole as the credentials type.
In STS role to assume, enter the Amazon Resource Name (ARN) of the role that will interact with S3 buckets.
Configure optional parameters according to the guidelines.
Select Create.
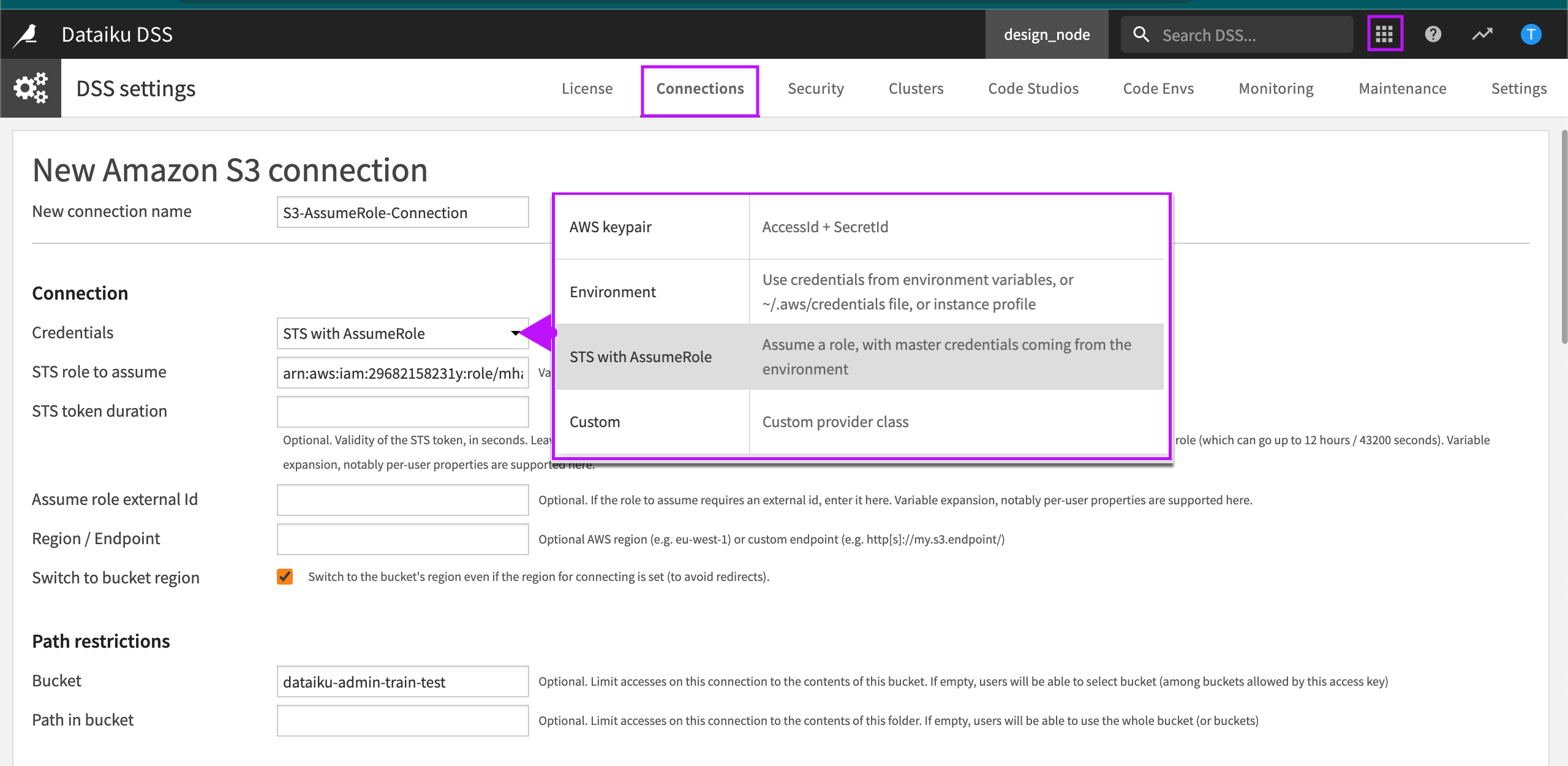
Optional Parameters
STS token duration. You can override the default setting. For example, to account for long running, enter the number of seconds you want the STS token to remain valid.
Assume role external Id. If the role to assume has been created on another account and requires an external ID then enter it here.
Region / Endpoint. If the S3 API must be reached through a specific VPC endpoint or region then enter it here.
Switch to bucket region. Select this option if the connection is restricted to a specific bucket. If this option is not selected then all buckets reachable with the role may be browsed.
Bucket. Enter a bucket if you want to limit accesses on the connection to the contents of a specific bucket.
Path in bucket. You can specify a specific path in the bucket. This provides more granular restriction inside the bucket on a specific prefix.
Modifying “Details readable by” Security Settings to Improve Performance¶
Jobs triggered through DSS can be executed locally.
However, if you want to leverage full parallelization and elasticity for workloads, you can execute Spark jobs over EKS. “Details readable by” is a security parameter can have a huge impact on the capability for jobs to parallelize data requests on S3. Jobs include recipes and notebooks executed using Spark over Kubernetes. If these jobs are able to parallelize (as configured by the parameter), they can reach the data source on their own, improving performance.
To configure this, scroll down to the Security Settings section. Propagate temporary credentials for distributed compute (Spark jobs over EKS) by changing the Details readable by parameter from Nobody to Every analyst or Selected groups (relevant groups).
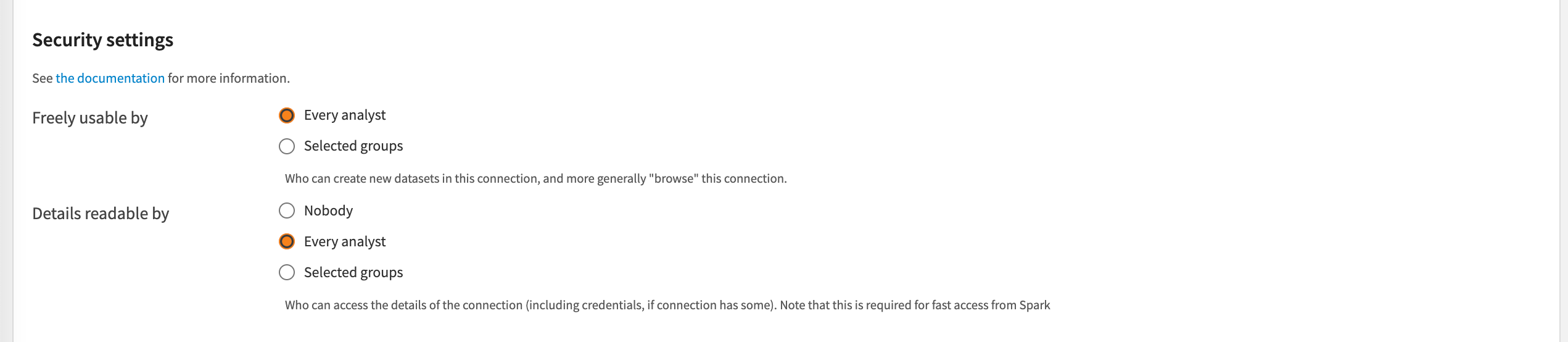
How does this parameter work?
The Details readable by parameter defines if a specific group is allowed to retrieve the credentials information from the connection in order to forward the credentials directly to the Spark executors running on EKS. Every step of this mechanism is handled by DSS.
When this parameter is allowed for a user, jobs can access the data stored on S3 directly by transmitting to the Spark jobs the temporary set of credentials (including the Access Key, Secret Key, and Token) to be used directly in a Spark context. This will create a fast path between executors and partitioned data on S3 increasing drastically the speed of execution.
If this action is not allowed for a job, DSS falls back on a streaming mechanism, also called a slow path. This means that DSS instance will be in charge of retrieving the data from S3 and serving it to one of the Spark jobs through an API endpoint. This results in a bottleneck and does not take advantage of available parallelization.
Interacting with AWS Glue¶
AWS Glue Catalog is a Metastore service that provides references to data. References can include DSS managed datasets or external references filled by external components such as crawlers and EMR. DSS can interact with AWS Glue to either store its own datasets’ metadata or expose a data catalog. When the data catalog is exposed is it reachable through the DSS Catalog > Connections Explorer.
Configure AWS Glue as the Metastore¶
An AWS Glue configuration is coupled with S3 connections because its main authentication mechanism relies on an already defined S3 connection.
To configure AWS Glue as the Metastore catalog:
Select the Administration menu and navigate to the Settings tab.
Select Metastore catalogs in the left panel.
DSS can leverage three kinds of metastores.
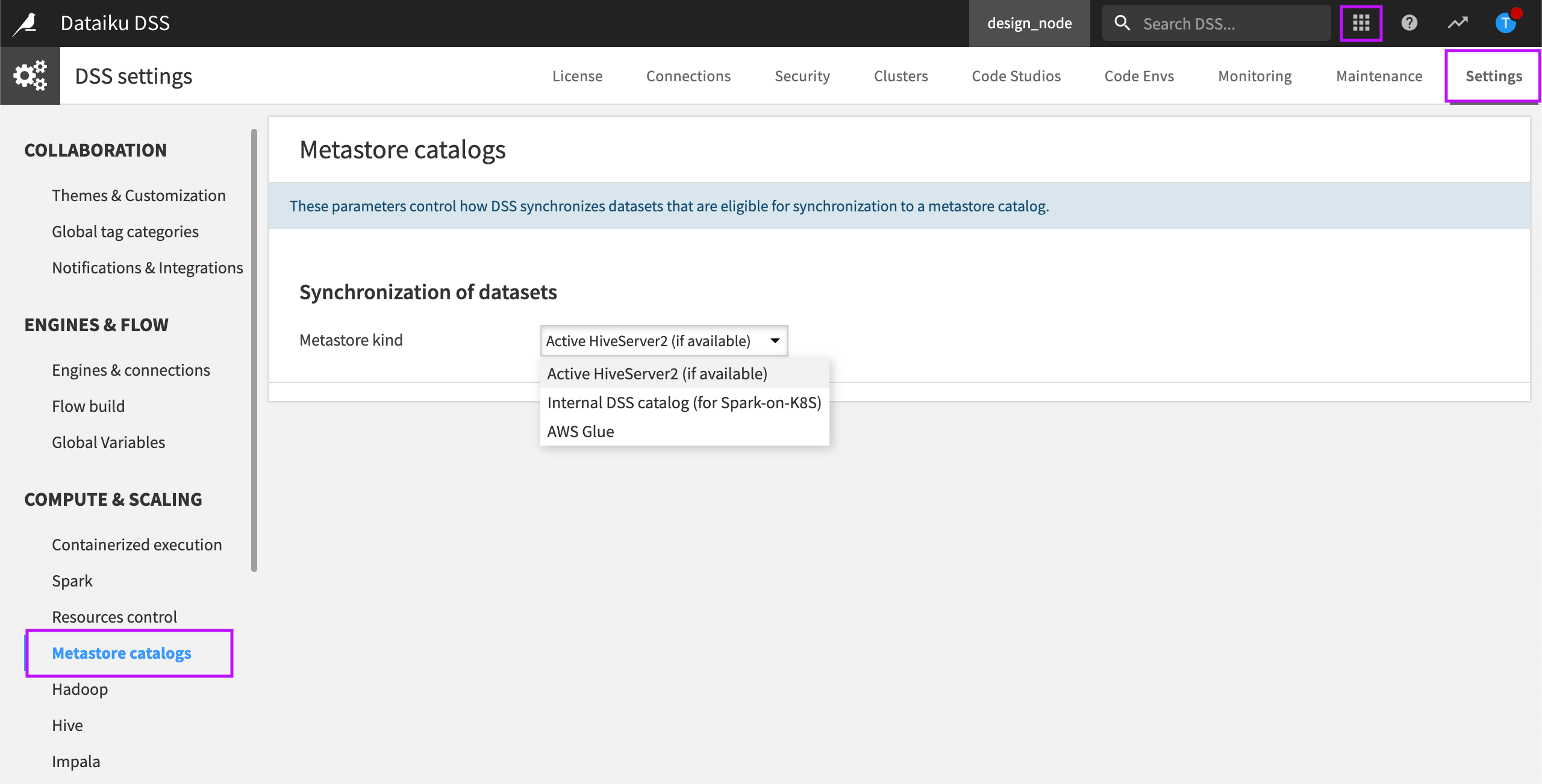
To configure AWS Glue as the Metastore, you must choose an authentication option: Use AWS credentials from Environment (credentials file, environment variables, instance metadata), or Use AWS credentials from an already existing S3 connection
Using AWS Credentials from an S3 Connection¶
When using the credentials from an S3 connection, you must first ensure that the IAM role defined to be assumed is properly configured to interact with AWS Glue. This is because all the AWS Glue interactions will be performed through this role.
The following policy example allows the role to interact with AWS Glue:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:CreateTable",
"glue:GetTables",
"glue:CreateDatabase",
"glue:DeleteTable",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetCatalogImportStatus"
],
"Resource": [
"arn:aws:glue:*:<AWS ACCOUNT ID>:table/*/*",
"arn:aws:glue:*:<AWS ACCOUNT ID>:database/*",
"arn:aws:glue:*:<AWS ACCOUNT ID>:catalog"
]
}
]
}
Once the AWS Glue Metastore is configured, DSS users may browse the DSS Catalog to find AWS Glue databases. This depends on the policies you set for the IAM role that interacts with the Metastore configuration.
In addition, you can configure the S3 connection to persist its managed datasets’ metadata in a specific AWS Glue database.
Note
Every interaction with a dataset stored on an S3 bucket can be audited inside AWS Cloudtrail. For traceability, AWS Cloudtrail contains the information concerning the role assumed and the role session name.