Concept: Deploy the Model¶
In the previous course, Machine Learning Basics, we looked at how to train models using the visual interface of Dataiku DSS. In trying to build a model to predict whether a patient would be readmitted to the hospital, we went through an iterative process between adjusting the design and then evaluating the results.
After each training session, we evaluated the results, looking not only at the overall performance metrics, but also the explainability of a model in a number of different ways. Now that we have experimented in the Lab building a range of different models, the next step is to put one to work!
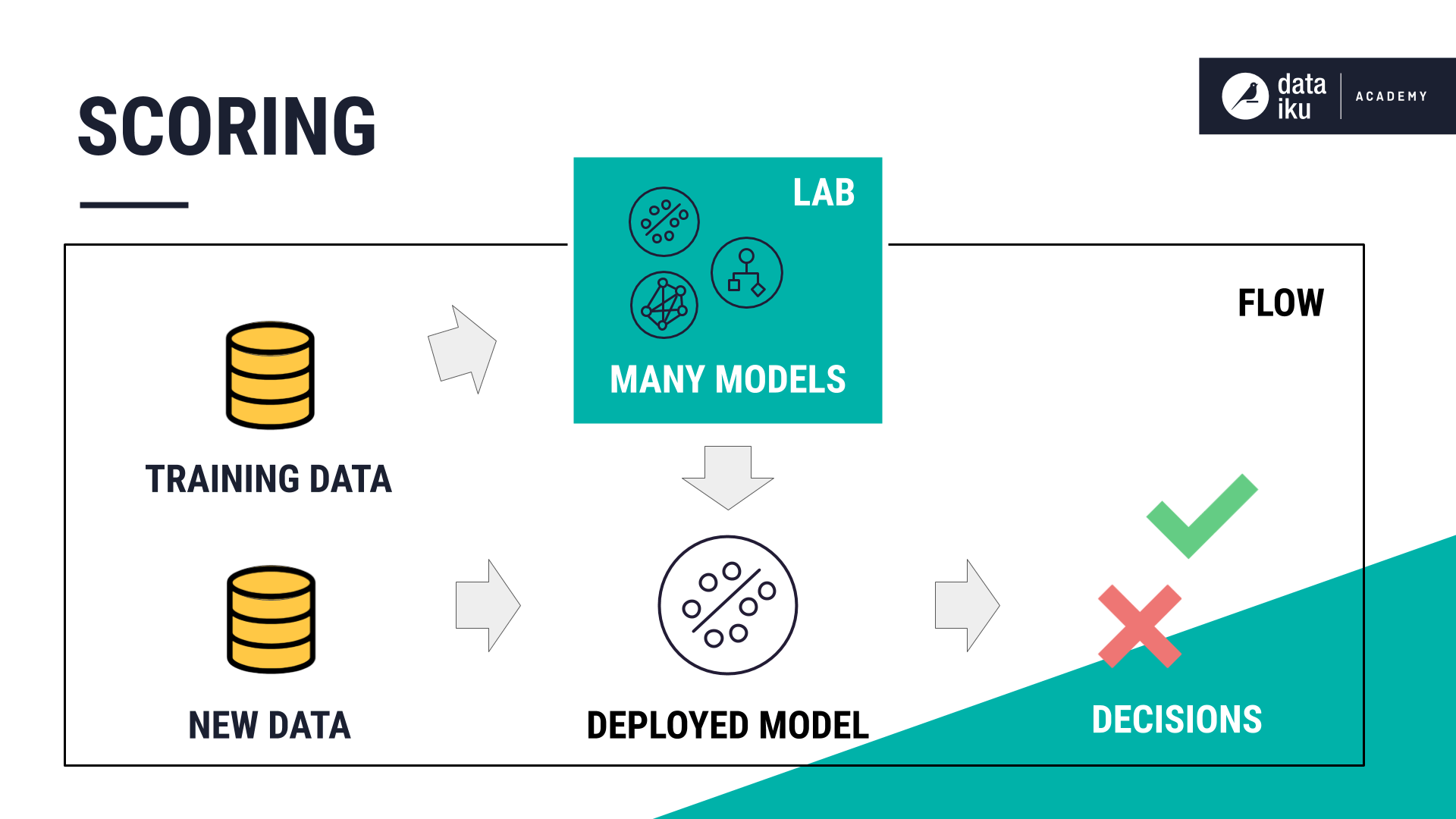
Scoring New Data¶
This step of the model lifecycle is called scoring. We want to feed the chosen model new data so that it can assign predictions for each new, unlabelled record.
In this case, we want to use one model to predict which new patients are most likely to be readmitted to the hospital.
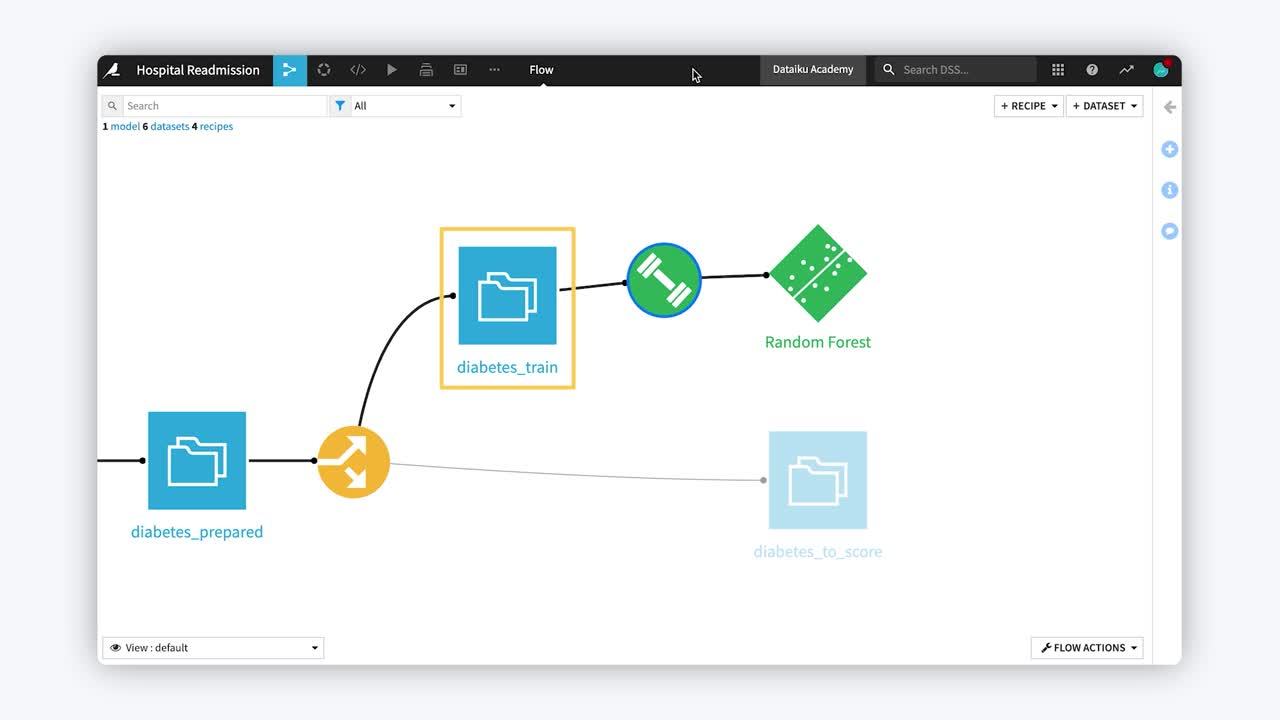
Deploying a Model to the Flow¶
Recall that we did our model training in a visual analysis, which is part of the Lab, a place for experimentation in DSS separate from the Flow. To use one of these models to classify new records, we’ll need to deploy it to the Flow.
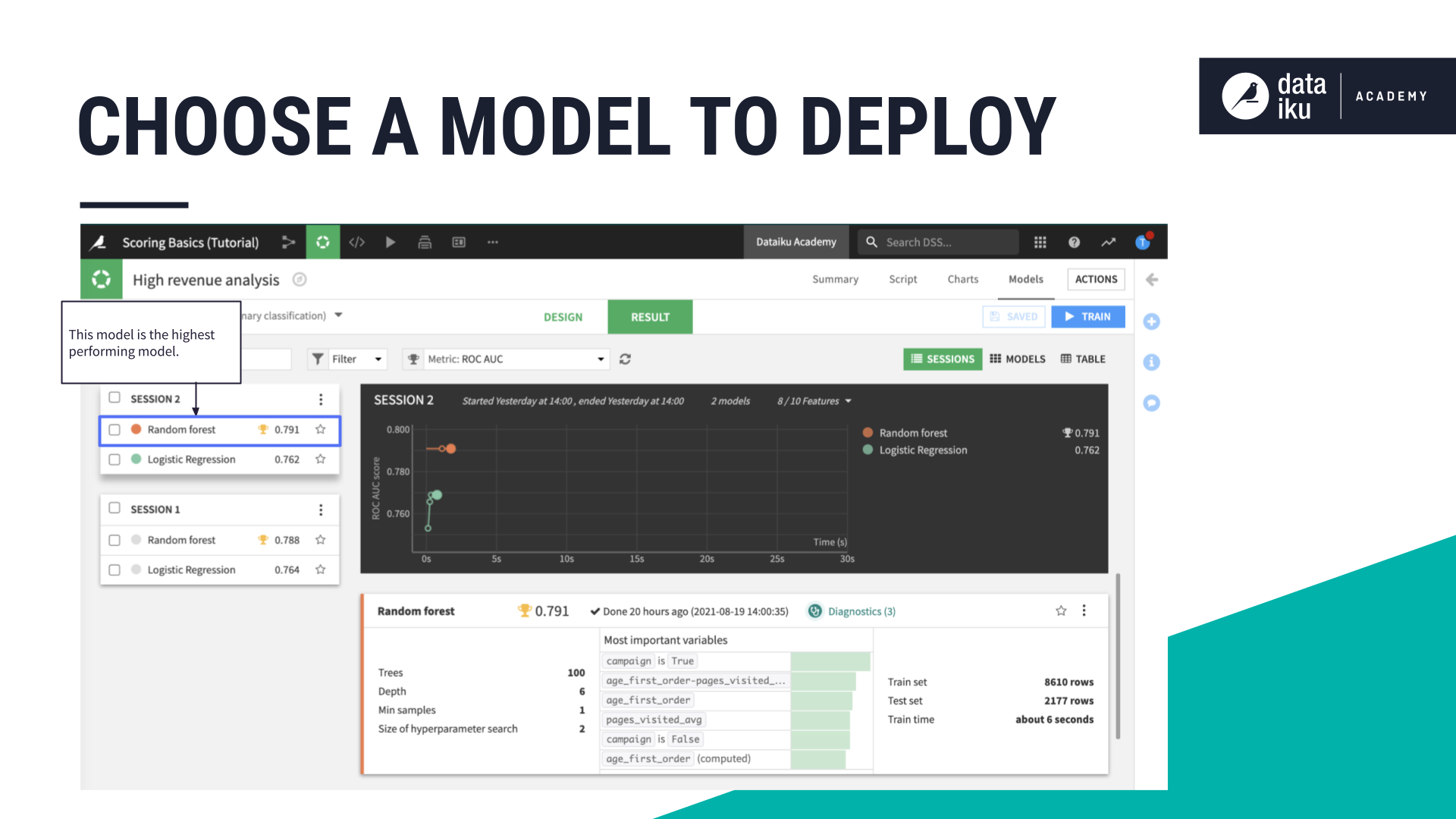
Which model should we choose to deploy? In the real world, this decision may depend on a number of factors and constraints– such as performance, explainability, and scalability. Here let’s just choose the best performing model.
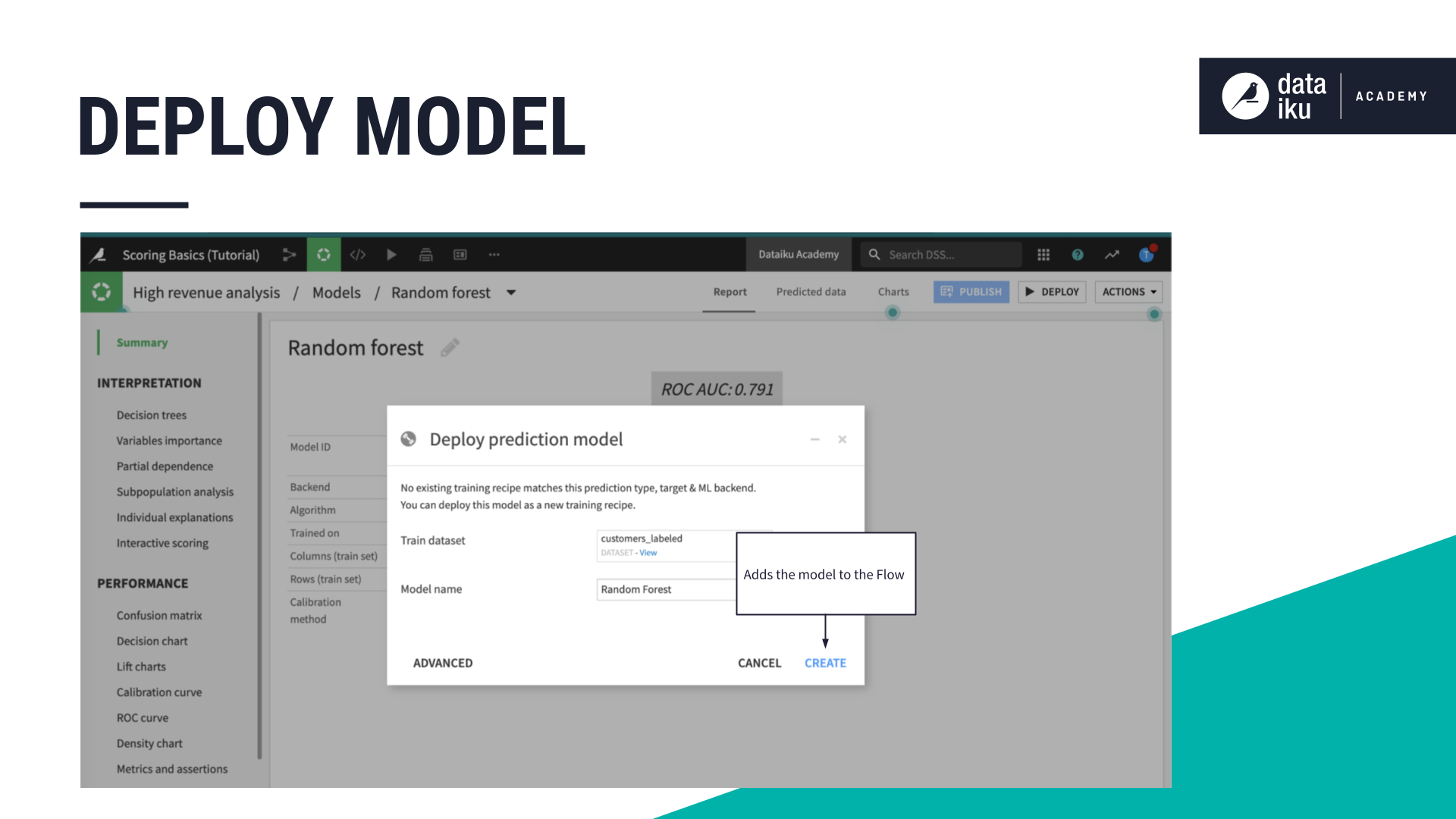
The dialog window for deploying a model is not unlike that of other recipes. Like with most recipes, we have an input dataset. Instead of naming the output dataset, we can rename the model. Clicking “Create” brings the model from the Lab into the Flow where our datasets live.
Deploying a model adds two objects to the Flow.
The first is a special kind of recipe, called the Train recipe. Just like other recipes in DSS, its representation is a circle. Instead of yellow or orange though, the green color lets us know it is for machine learning.
Most often, recipes take a dataset as input and produce another dataset as output. The train recipe takes one dataset as its input but outputs a model in the Flow.
The second object added to the Flow is called a saved model object. Notice we have a new shape in the Flow! A diamond represents a saved model.
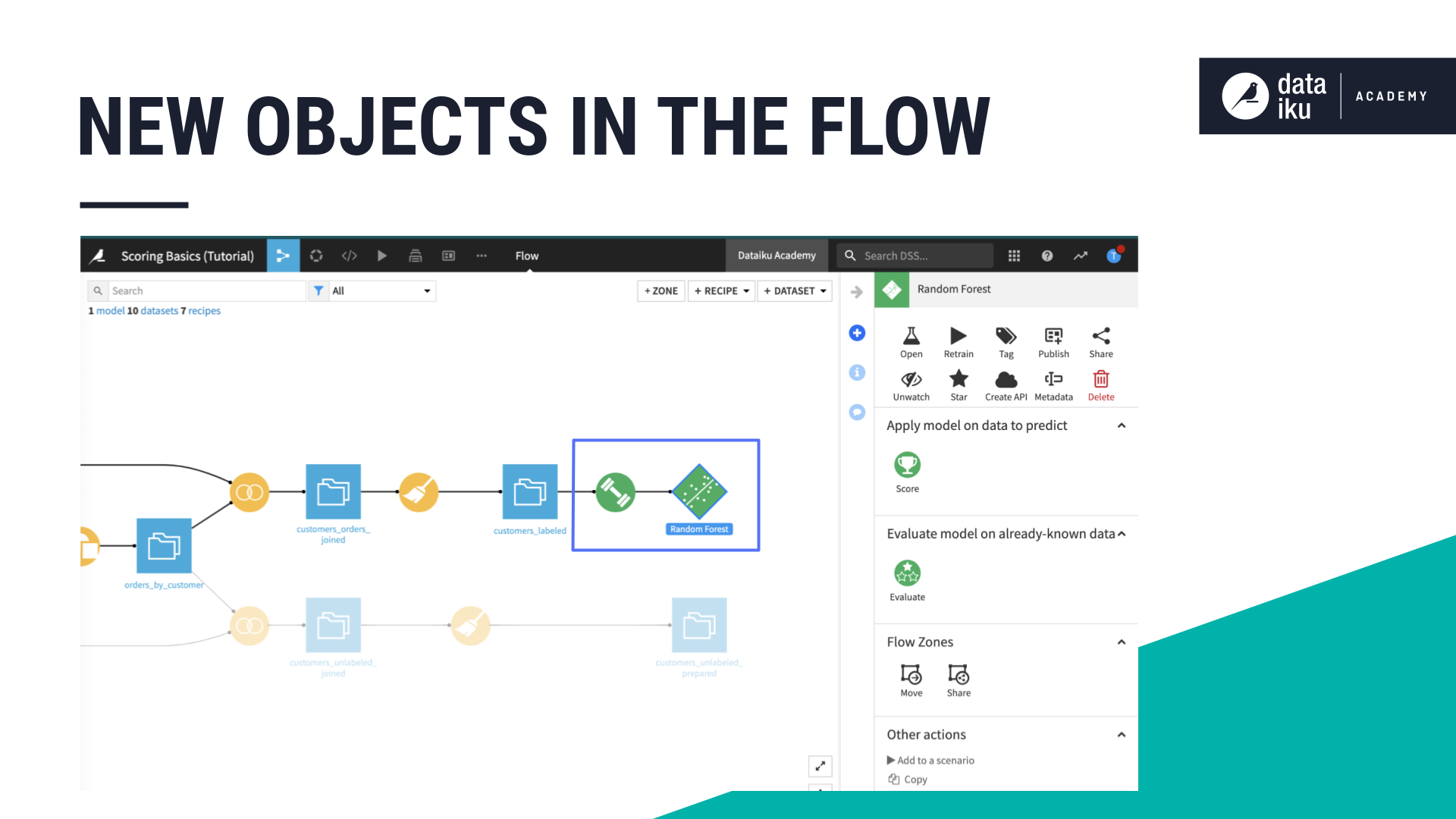
A saved model is a Flow artifact that contains the model that was built within the visual analysis. Along with the model object, it contains all the lineage necessary for auditing, retraining and deploying the model–things like hyperparameters, feature preprocessing, the code environment, etc.
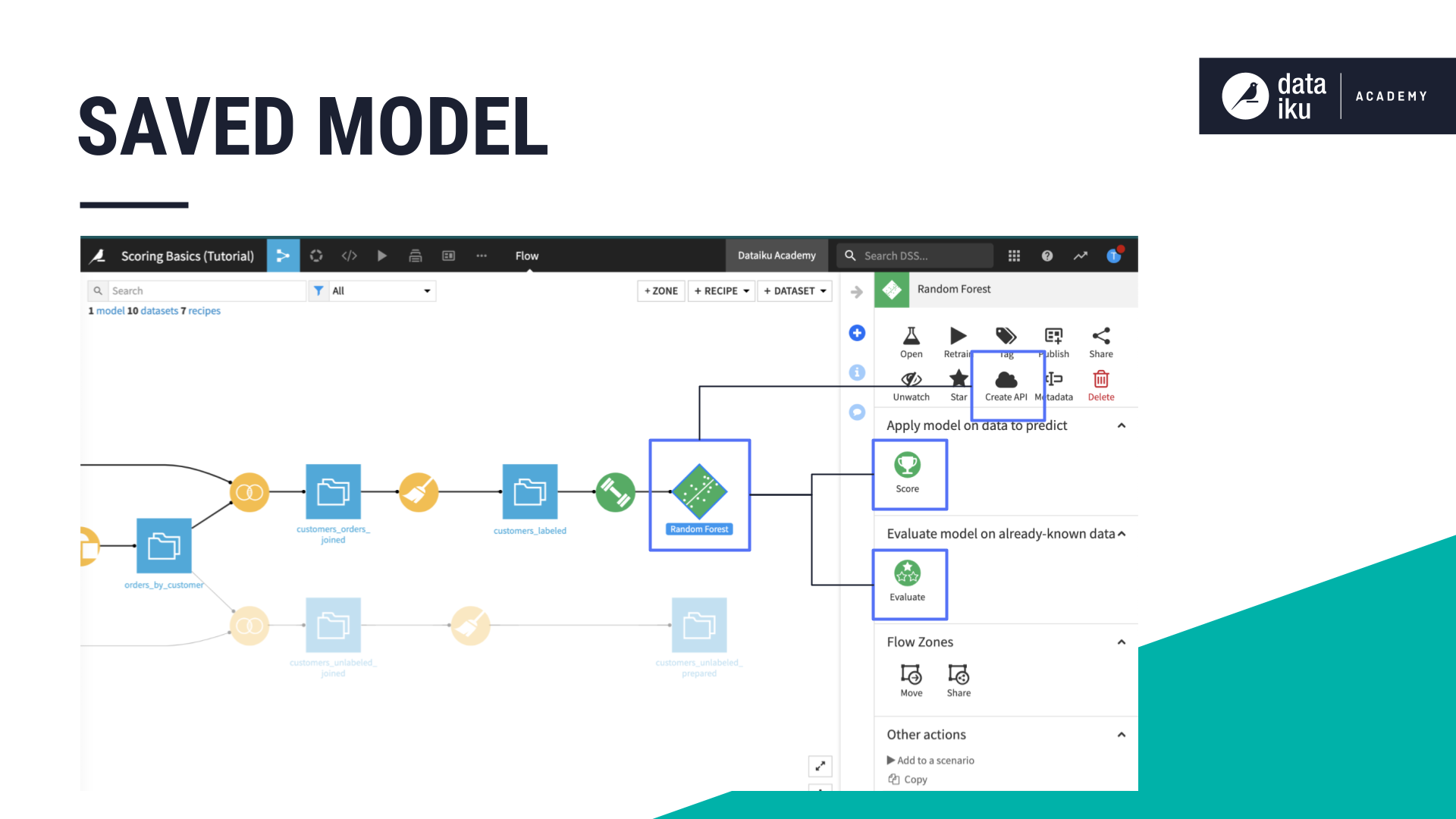
This saved model can be used in several ways:
It can score an unlabelled dataset using the Score recipe.
It can also be evaluated against a labelled test dataset using the Evaluate recipe.
Or it can be packaged and deployed as an API to make real time predictions.
What’s Next?¶
In the video, Concept: Scoring Data, we’ll see how to prepare and score new, unlabelled data with a “saved” model.