Explore the Flow¶
In this section, you will explore a Dataiku project and its Flow.
Explore the Project Homepage¶
Let’s start by navigating to the project homepage to learn about its purpose and contents.
Go back to the Dataiku homepage, and open the AI Consumer Quick Start (Tutorial) project by clicking on its tile in the Projects section.
Click on the project title in the top left corner to navigate to the project homepage.
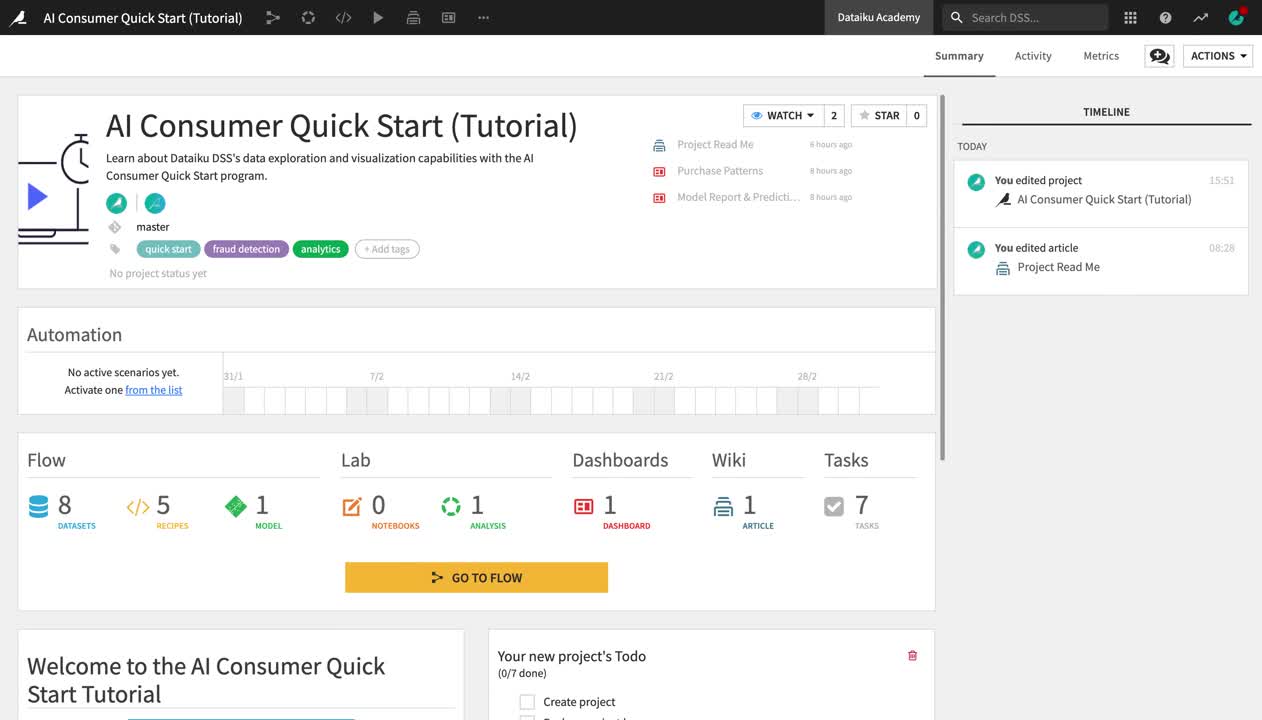
On the project homepage, you can see the project’s tags, description, status, to-do list, contributors, discussions, and recent activity.
Familiarize yourself with the project homepage.
Click the Wiki article to open the project README about the purpose and contents of the project.
Return to the project homepage by clicking the project title at the top left.
Explore Flow Items¶
From the project homepage, click Go to Flow. Alternatively, you can use the shortcut
G + F.
Note
The Flow is the visual representation of how datasets, recipes (steps for data transformation), and models work together to move data through an analytical pipeline.
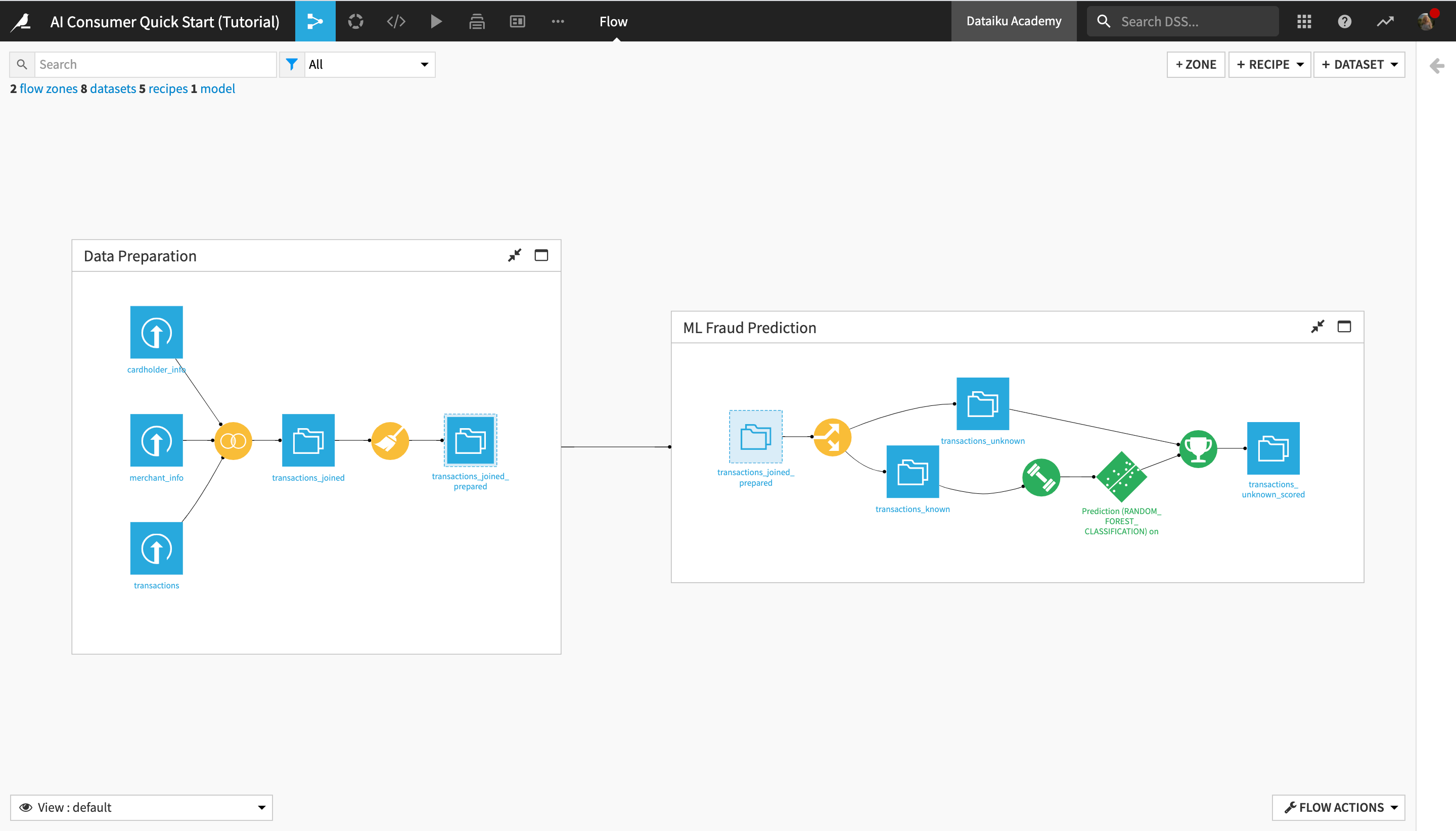
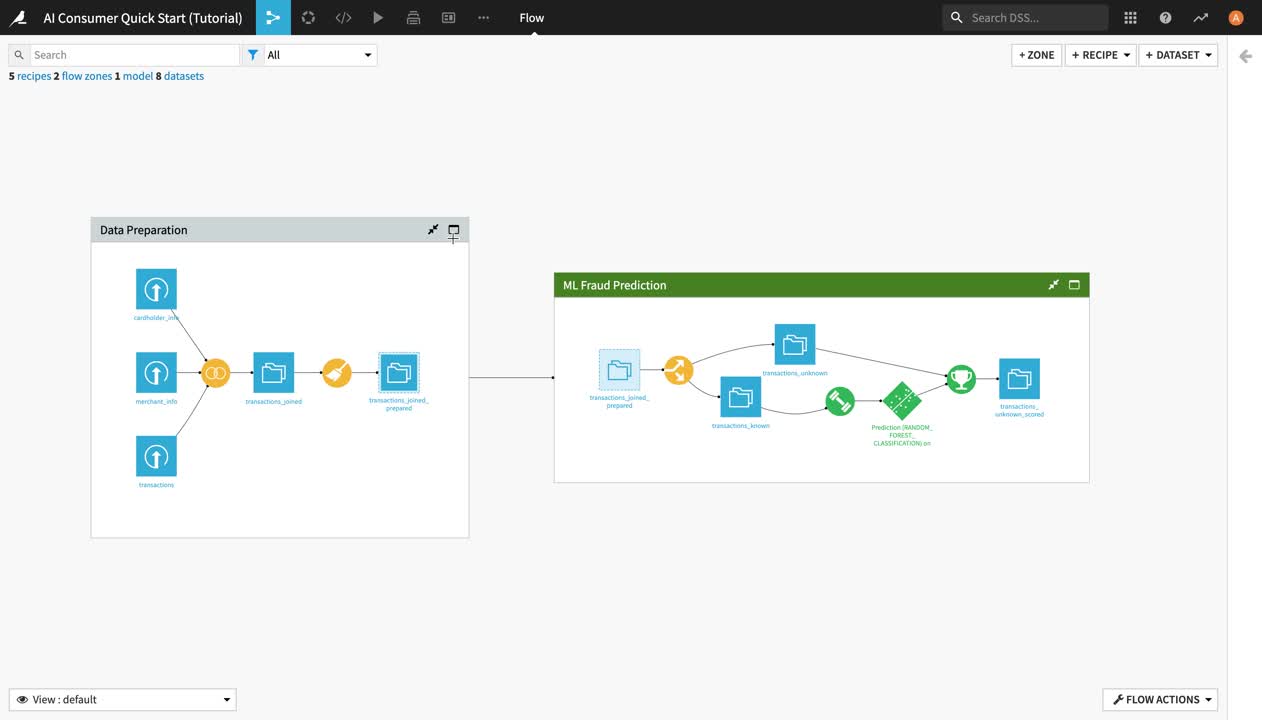
The Flow of this project is divided into two Flow zones, “Data Preparation” and “ML Fraud Prediction”. We will dig deeper into the concept of Flow zones in the next section.
Within a Flow zone, you’ll find several types of objects, or Flow items:
Blue squares represent datasets . The icon on the square represents the type of dataset or its underlying storage connection, such as a filesystem, an SQL database, or cloud storage.
Yellow circles represent visual recipes (or data transformation steps that don’t require coding and can be built with the Dataiku DSS visual UI).
Green elements represent machine learning (ML) elements, such as models.
Explore Flow Zones¶
Now, let’s discover the concept of Flow zones, and find out more about the operations performed in each Flow zone.
Note
Data science projects tend to quickly become complex, with a large number of recipes and datasets in the Flow. This can make the Flow difficult to read and navigate. Large projects can be better managed by dividing them into Flow zones.
Zones can be defined in the Flow, and datasets and recipes can be moved into different zones. You can work within a single zone or the whole Flow, and collapse zones to create a simplified view of the Flow.
First, let’s explore the “Data Preparation” Flow zone.
Click the full screen icon in the upper right corner of the “Data Preparation” Flow zone window, or double-click anywhere in the white space inside the window, in order to open the Flow zone.
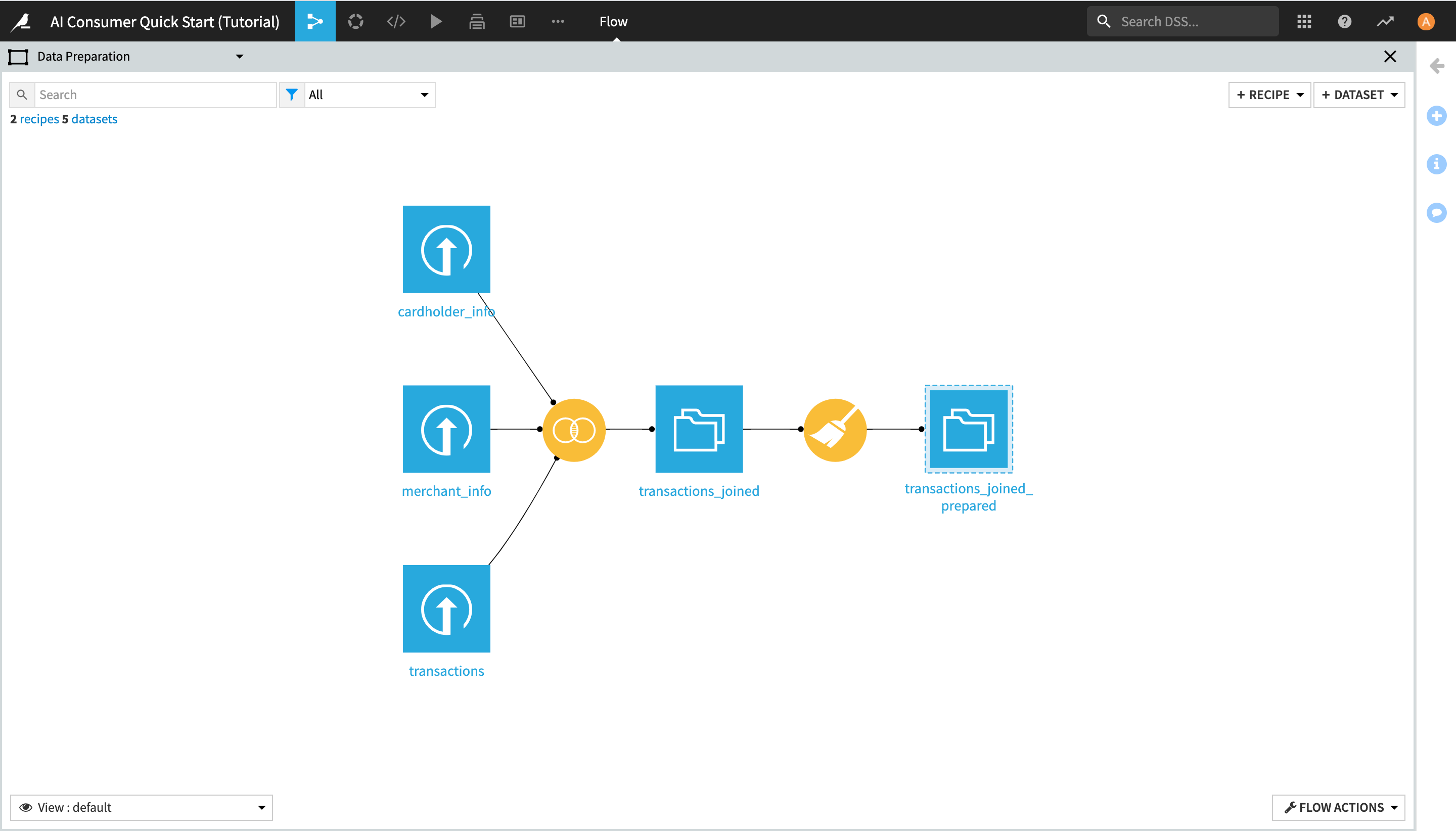
This Flow zone contains three input datasets, which are joined together using a Join recipe, and then prepared using a Prepare recipe, resulting in the transactions_joined_prepared dataset.
Notice the dashed lines around the transactions_joined_prepared dataset. Those lines indicate that this dataset is shared into another Flow zone–in this case, the “ML Fraud Prediction” one.
Before getting started with exploring the data, let’s also briefly look at the “ML Fraud Prediction” Flow zone.
Click the X button in the upper right corner of the screen to exit the “Data Preparation” Flow zone and go back to the entire Flow.
Click the full screen icon in the upper right corner of the ML Fraud Prediction Flow zone window, or double-click anywhere in the white space inside the window, in order to open the Flow zone.

By doing this, you have navigated to another zone of the Flow, which starts from the transactions_joined_prepared dataset and contains all the downstream Flow items. As its name suggests, this Flow zone relates to the machine learning tasks in the project.
Note
As an AI Consumer, you do not interact directly with the machine learning (ML) elements of the Flow, and you do not need to understand their full extent, but you are nevertheless able to draw, consume, and manipulate actionable ML insights (as seen in the dashboards and the Dataiku app of the previous two sections).
In this Flow zone, the transactions_joined_prepared dataset is split into two datasets using a Split recipe:
transactions_known contains the transactions that have been identified as either authorized or unauthorized; and
transactions_unknown contains the transactions for which we don’t know whether they were authorized or not.
The transactions_known dataset is used to train a machine learning model to predict whether a transaction is authorized or not, and the output model is then applied to transactions_unknown, producing the transactions_unknown_scored dataset. This end dataset contains all of the previously “unknown” transactions, flagged by the model as either authorized or unauthorized (a.k.a. potentially fraudulent).
Click the X button in the upper right corner of the screen to exit the “ML Fraud Prediction” Flow zone and go back to the initial view.
View the Flow Using Tags¶
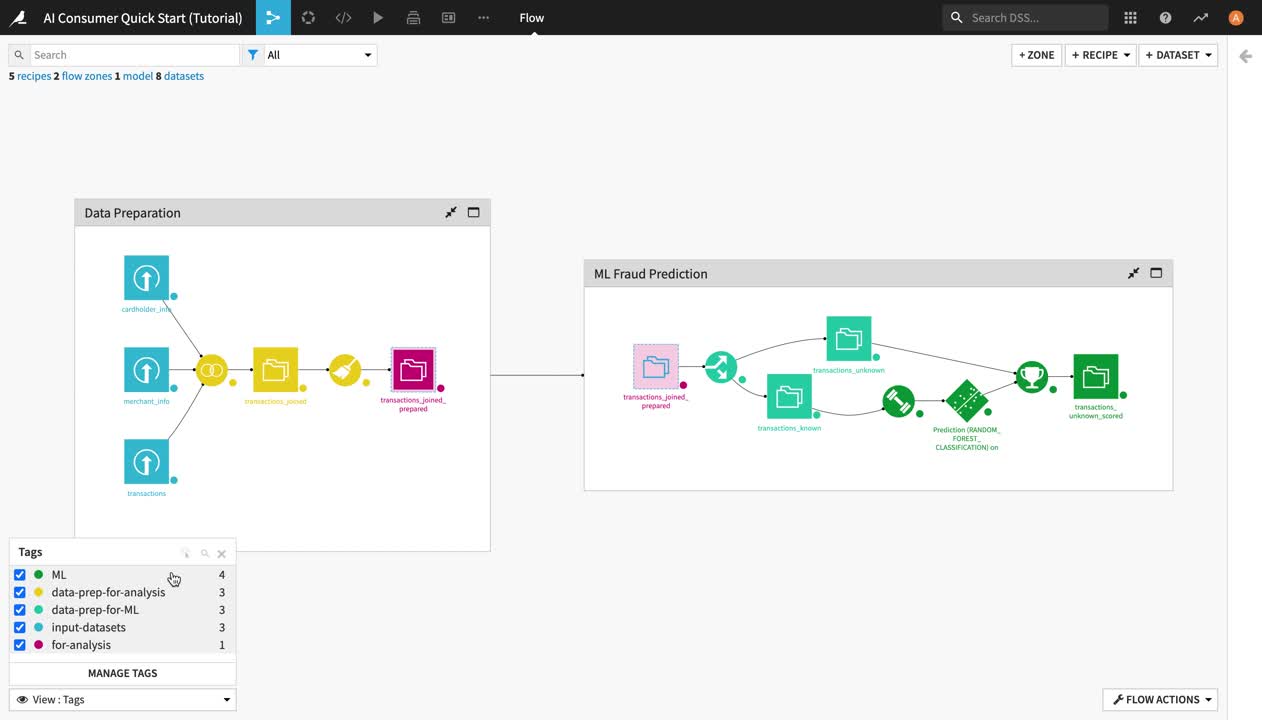
To enhance the interpretability of the Flow, you can use different Flow Views at the bottom left of the screen. For example, you can color your view based on Tags.
In this view, objects with an associated tag are highlighted depending on the selected tags. This view can be particularly helpful for understanding large or complicated Flows or when multiple people are working on the same Flow.
To use the Tags view:
Click View: default in the lower left corner, and select Tags from the dropdown menu.
Activate all tags and observe their effects in the Flow.
Experiment with a few other views, and then click the X to close the tags menu, and return to the default view.