Train and Evaluate a Machine Learning Model¶
In this section, we’ll build machine learning models on the data, using the features as-is. We’ll then deploy the best-performing model to the Flow and evaluate the model’s performance. In a later section, we will generate features to use in the Machine learning model.
Split Data¶
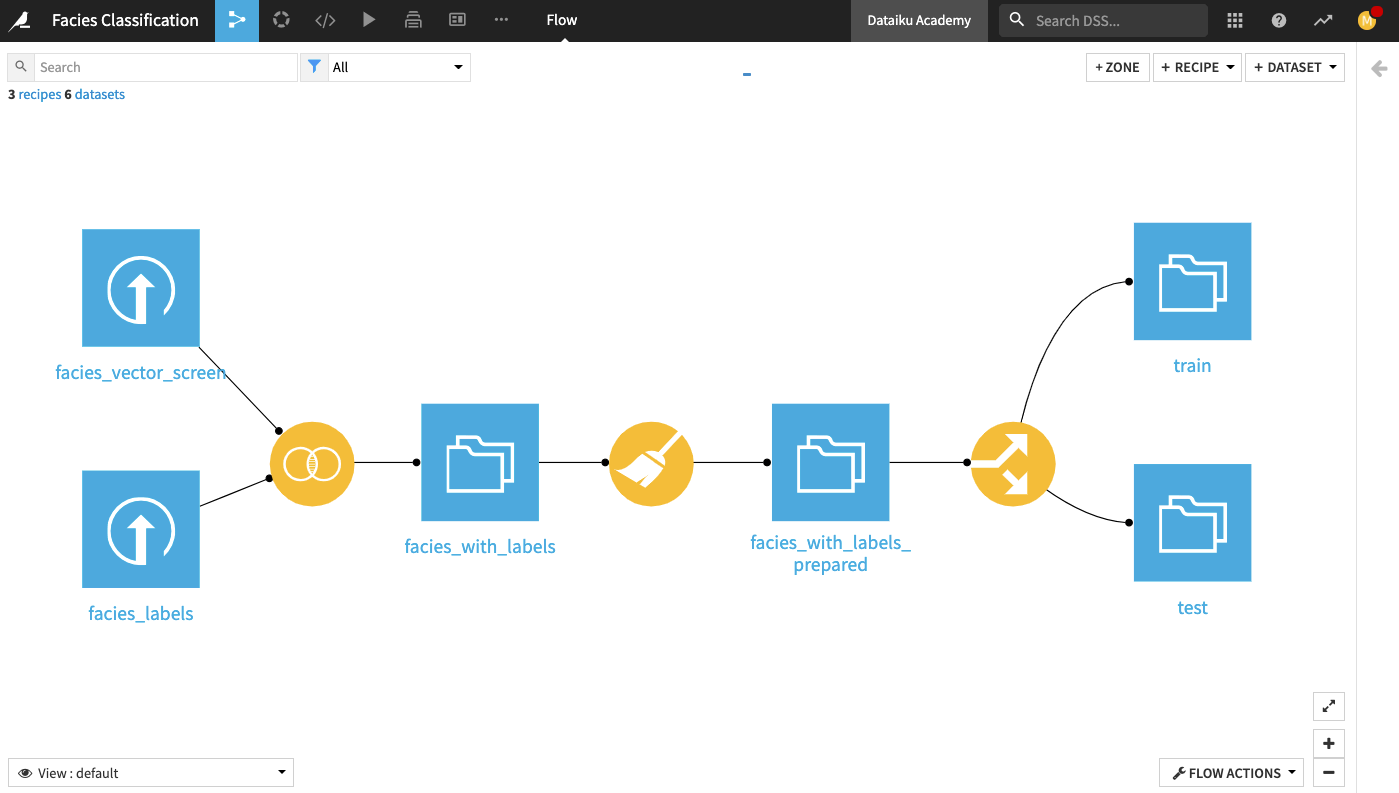
Before implementing the machine learning part, we first need to split the data in facies_with_labels_prepared into training and testing datasets. For this, we’ll apply the Split Recipe to the dataset and create two output datasets train and test.
From the Flow, click the facies_with_labels_prepared dataset.
Select the Split recipe from the right panel.
Add two output datasets
trainandtest.Create the recipe.
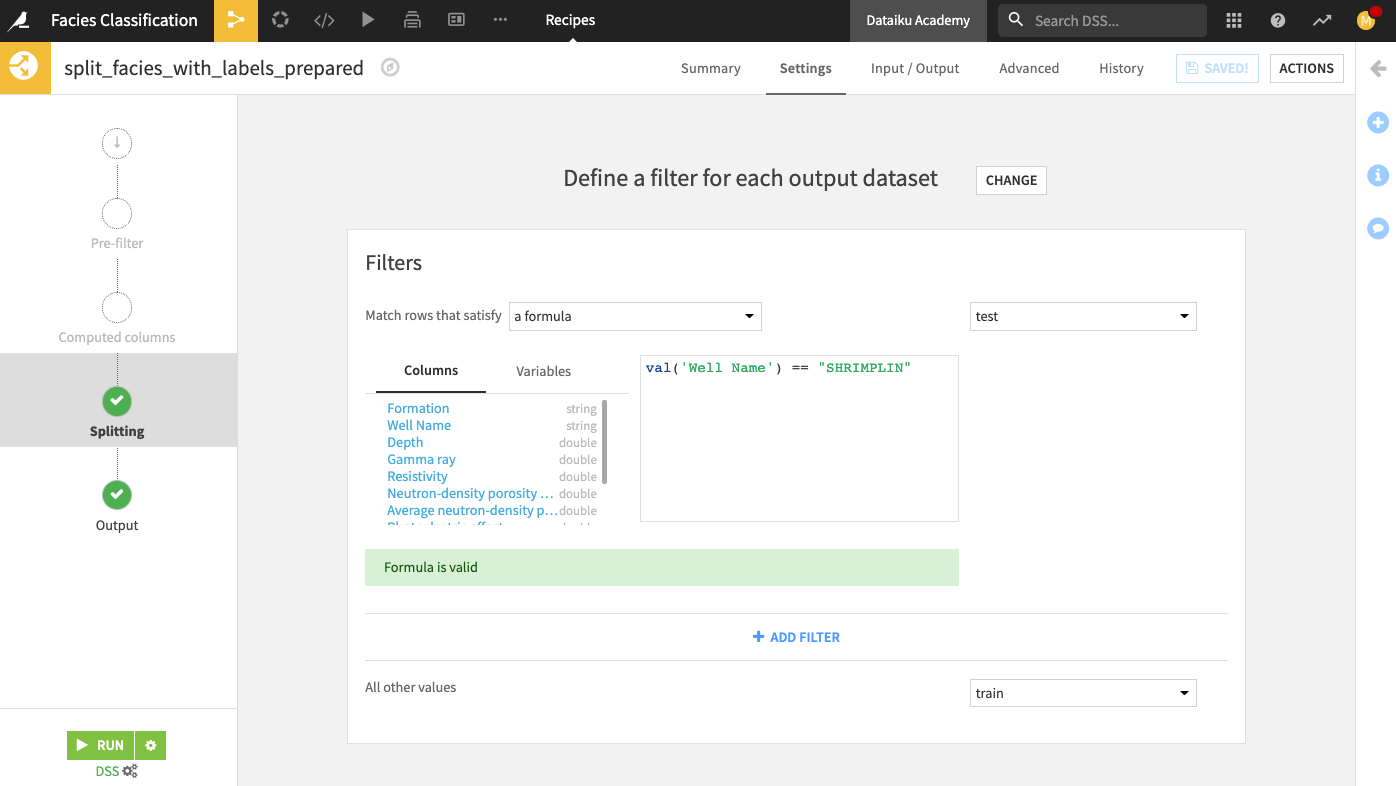
Select the Define filters splitting method.
We will use this method to move all rows that correspond to a specific well (Shrimplin) into the test dataset and move other rows into the train dataset.
At the “Splitting” step of the recipe, define the filter: “Match rows that satisfy a formula:
val('Well Name') == "SHRIMPLIN" for the test dataset.
Specify “All other values” go into the train dataset.
Run the recipe. Your output test dataset should contain 471 rows.
Train Models and Deploy a Model to the Flow¶
Now that we’ve split the dataset into a train and a test dataset let’s train a machine learning model. For this, we’ll use the visual machine learning interface.
From the Flow, click the train dataset to select it
Open the right panel and click Lab.
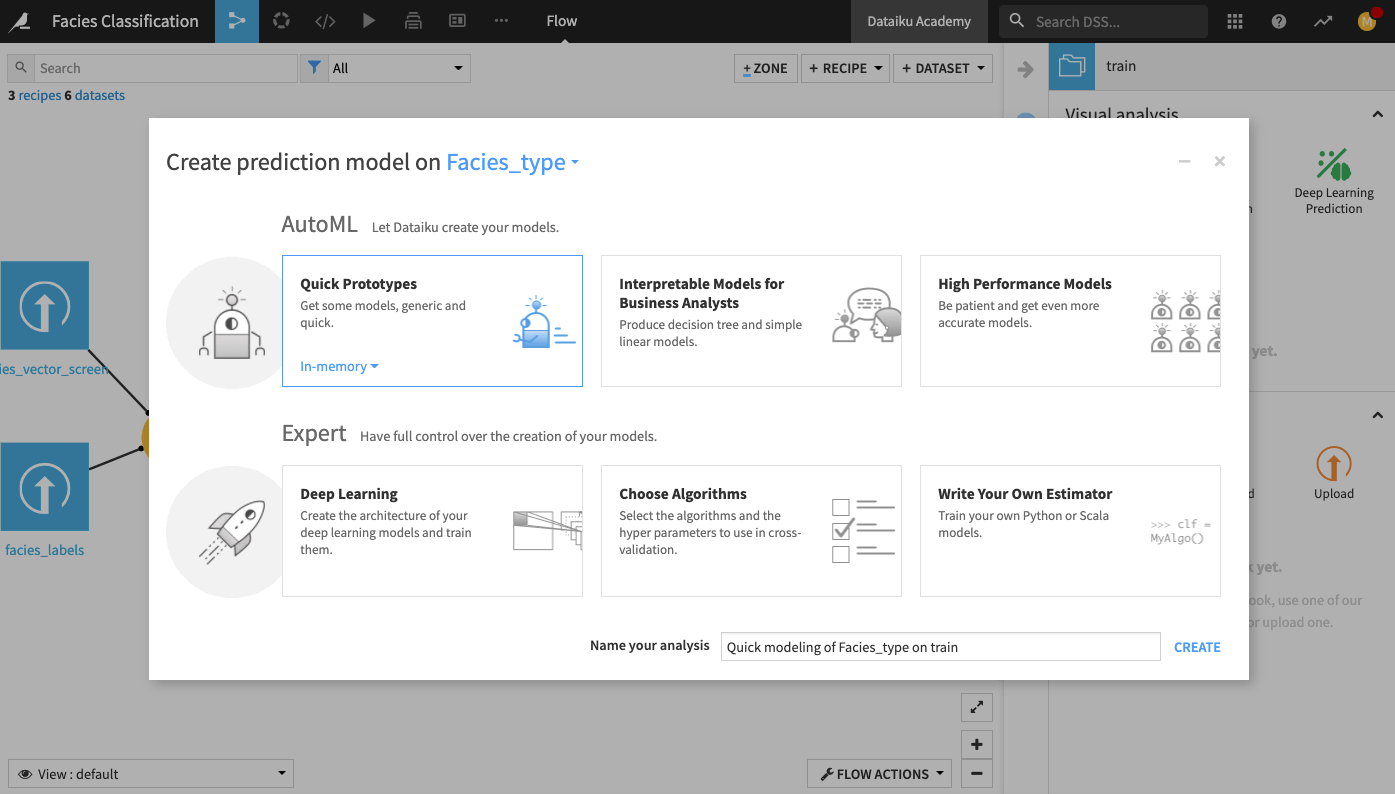
Select AutoML Prediction from the “Visual analysis” options.
In the window that pops up, select Facies_type as the target feature on which to create the model.
Click the box for Quick Prototypes.
Keep the default analysis name and click Create.
In the Lab, go to the Design tab.
Go to the Metrics panel and change the optimization metric to Accuracy.
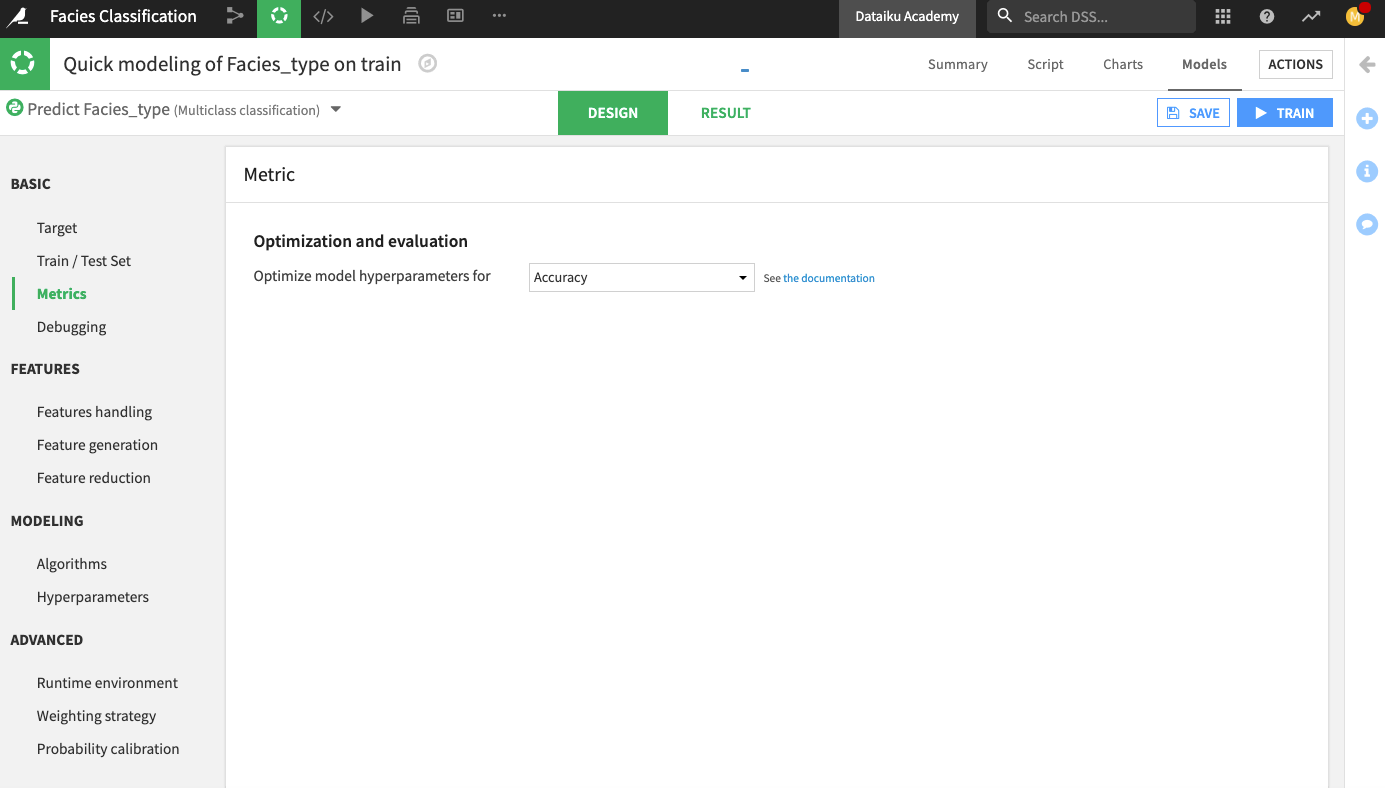
Click Train to train the model.
The Result page for the sessions opens up. Here, you can monitor the optimization results of the models.
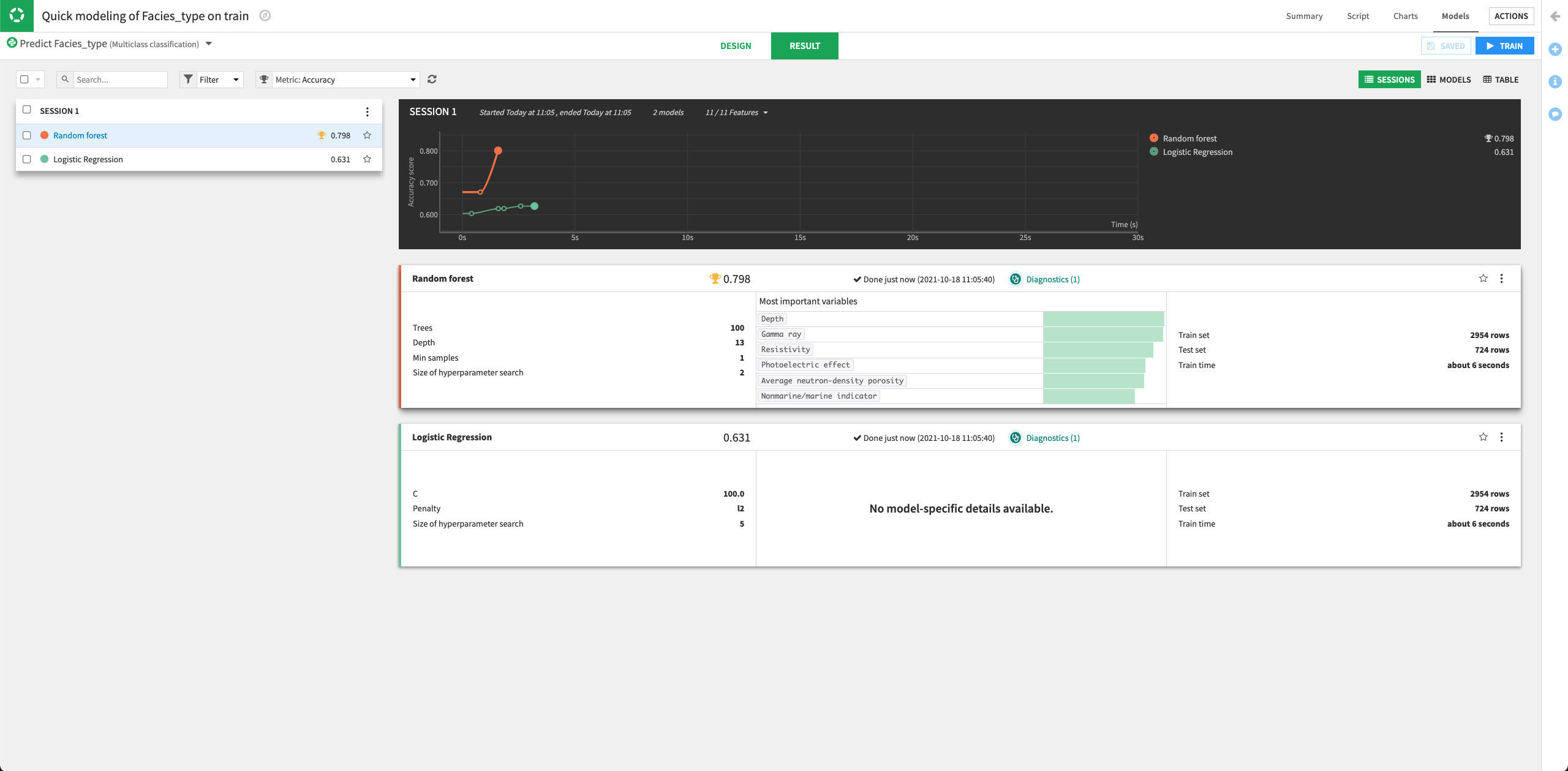
The Result page shows the Accuracy score for each trained model in this training session, allowing you to compare performance side-by-side.
Let’s try to improve the performance of the machine learning models by tuning some parameters. We’ll also add some other algorithms to the design.
Return to the Design tab, and go to the Algorithms panel.
For the Random Forest model, specify three different values for the “Number of trees” parameter:
100,200,400.Keep the default values for the other parameters.
Click the slider next to the “XGBoost” model to turn it on.
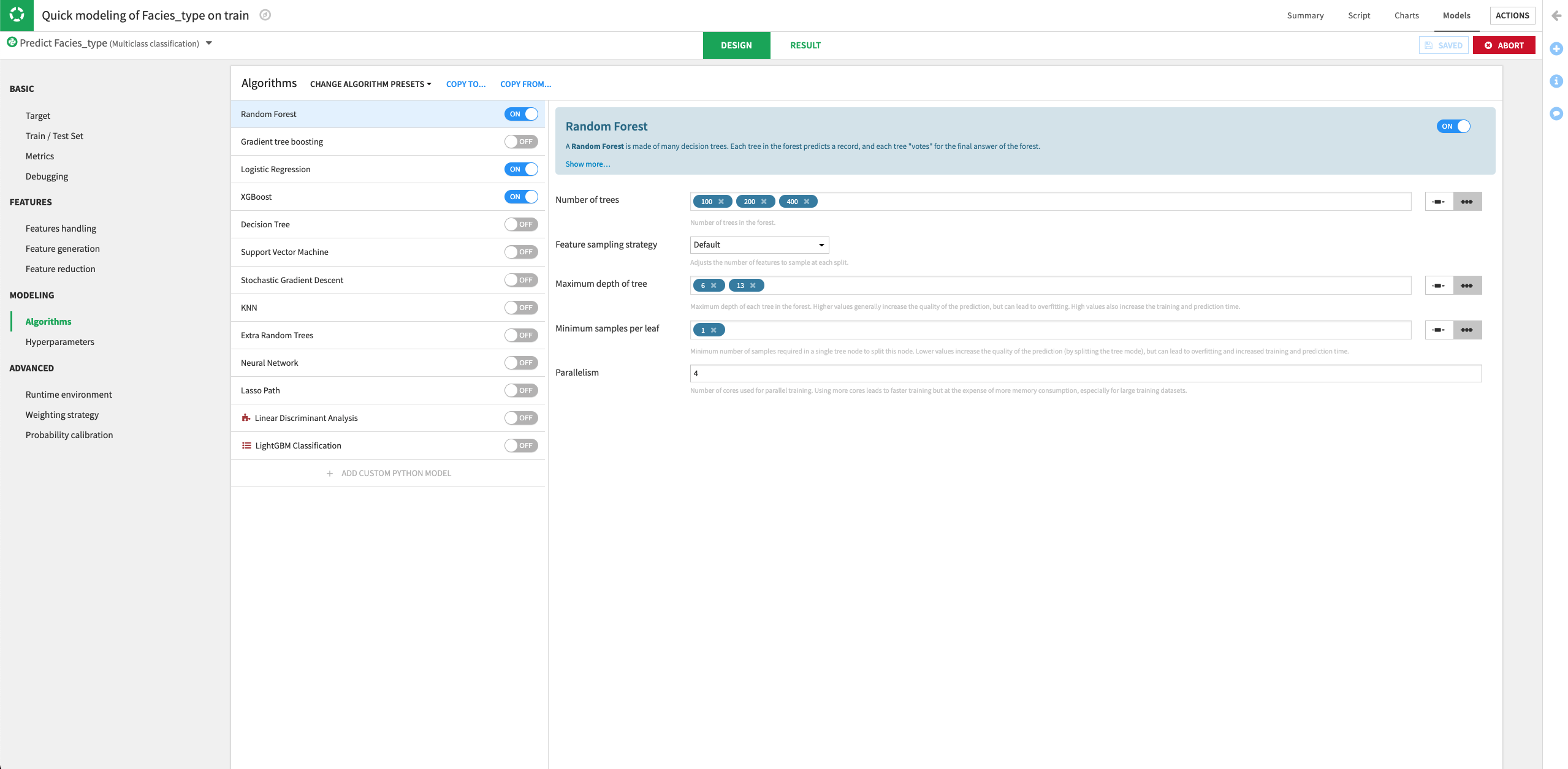
Train the models.
Dataiku will try all the parameter combinations and return the model with the parameter combination that gives the best performance.
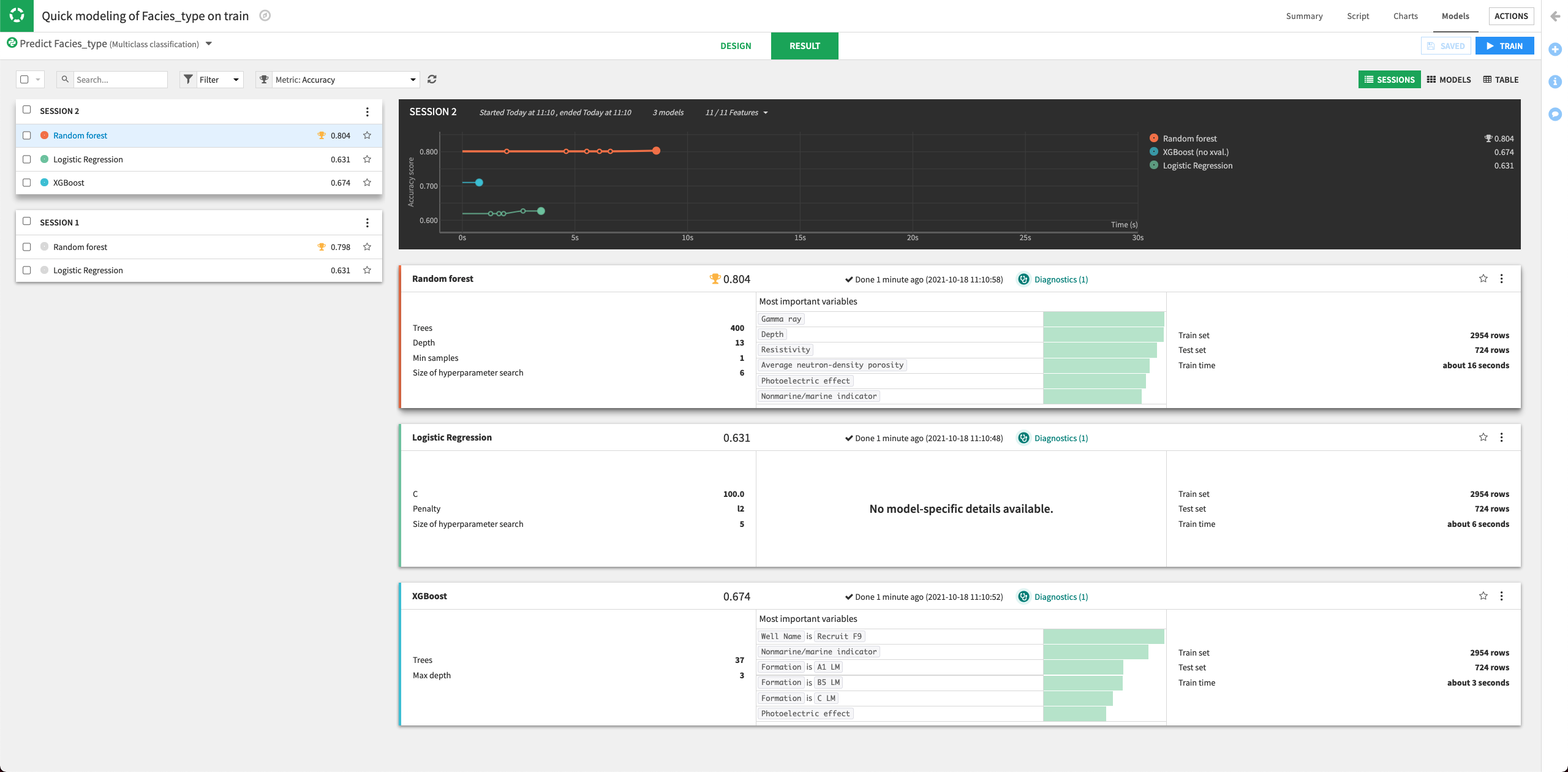
The performance of the Random Forest model improved in the second training session.
Click the Random Forest model to open its Report page.
Click the Deploy button to deploy the model to the Flow.
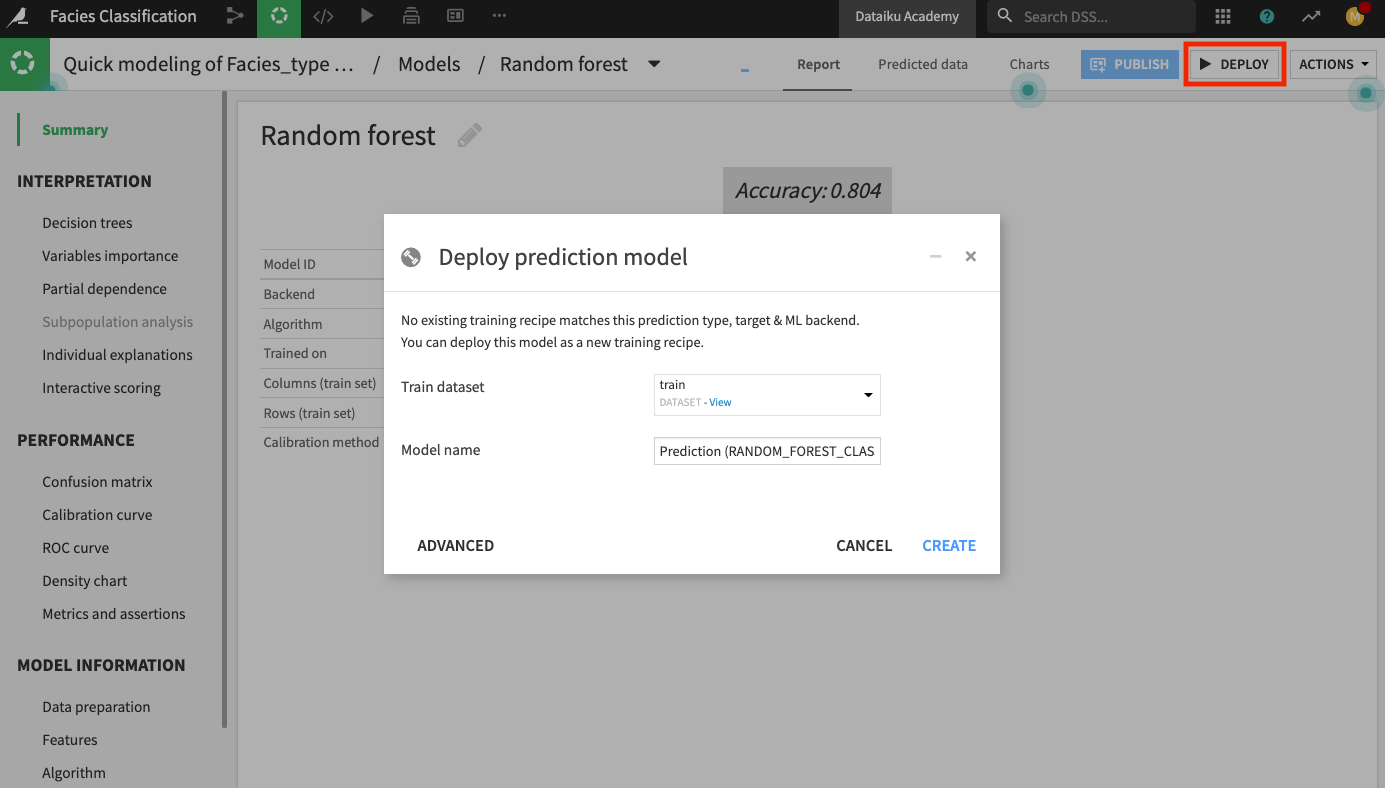
Keep the default model name and click Create.
The Flow now contains the deployed model.
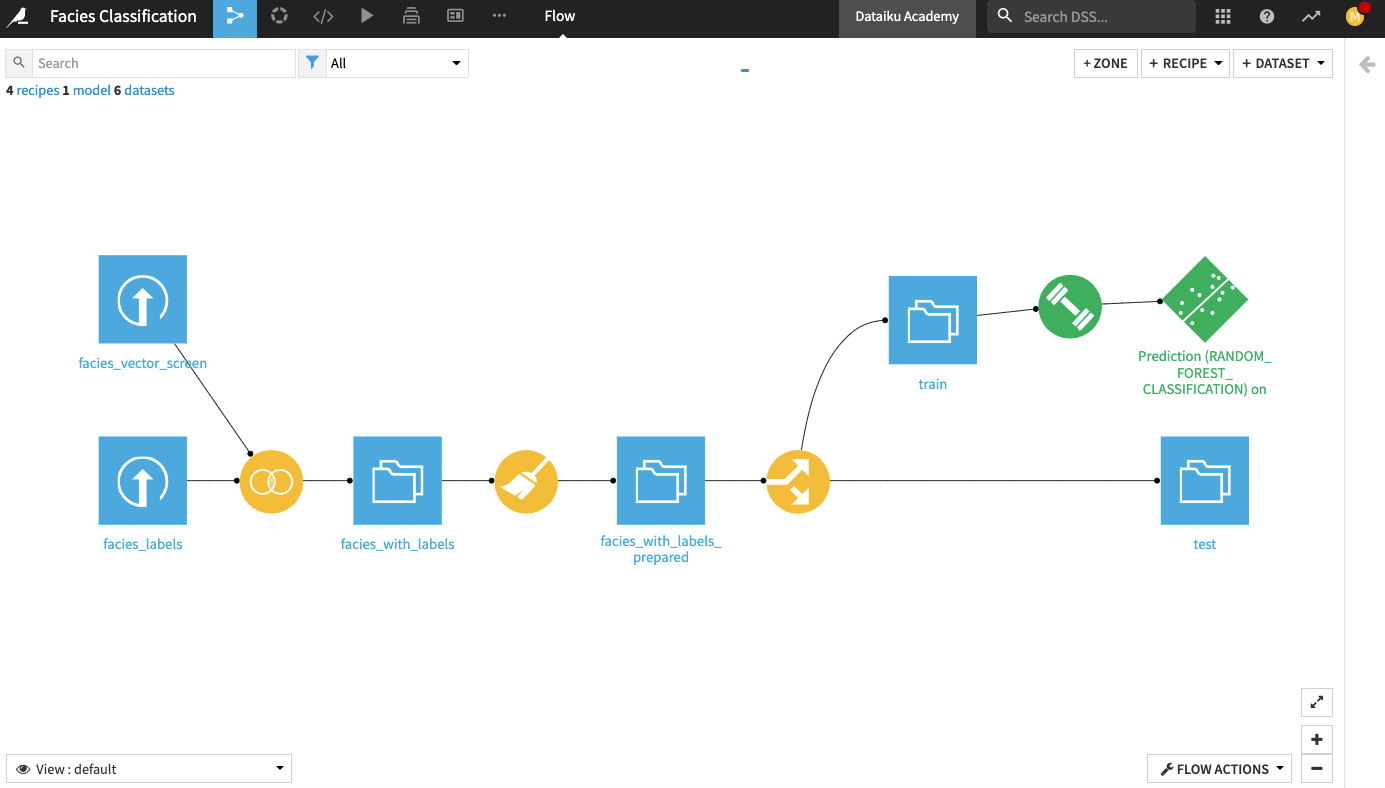
Evaluate Model Performance¶
Our test dataset contains information about the classes of the facies in the Facies_type column. Since we know the classes, we will use the test dataset to evaluate the true performance of the deployed model.
We’ll perform the model evaluation by using the Evaluate recipe. This recipe will take the deployed model and the test dataset as input and generate a predictions and a metrics dataset as outputs.
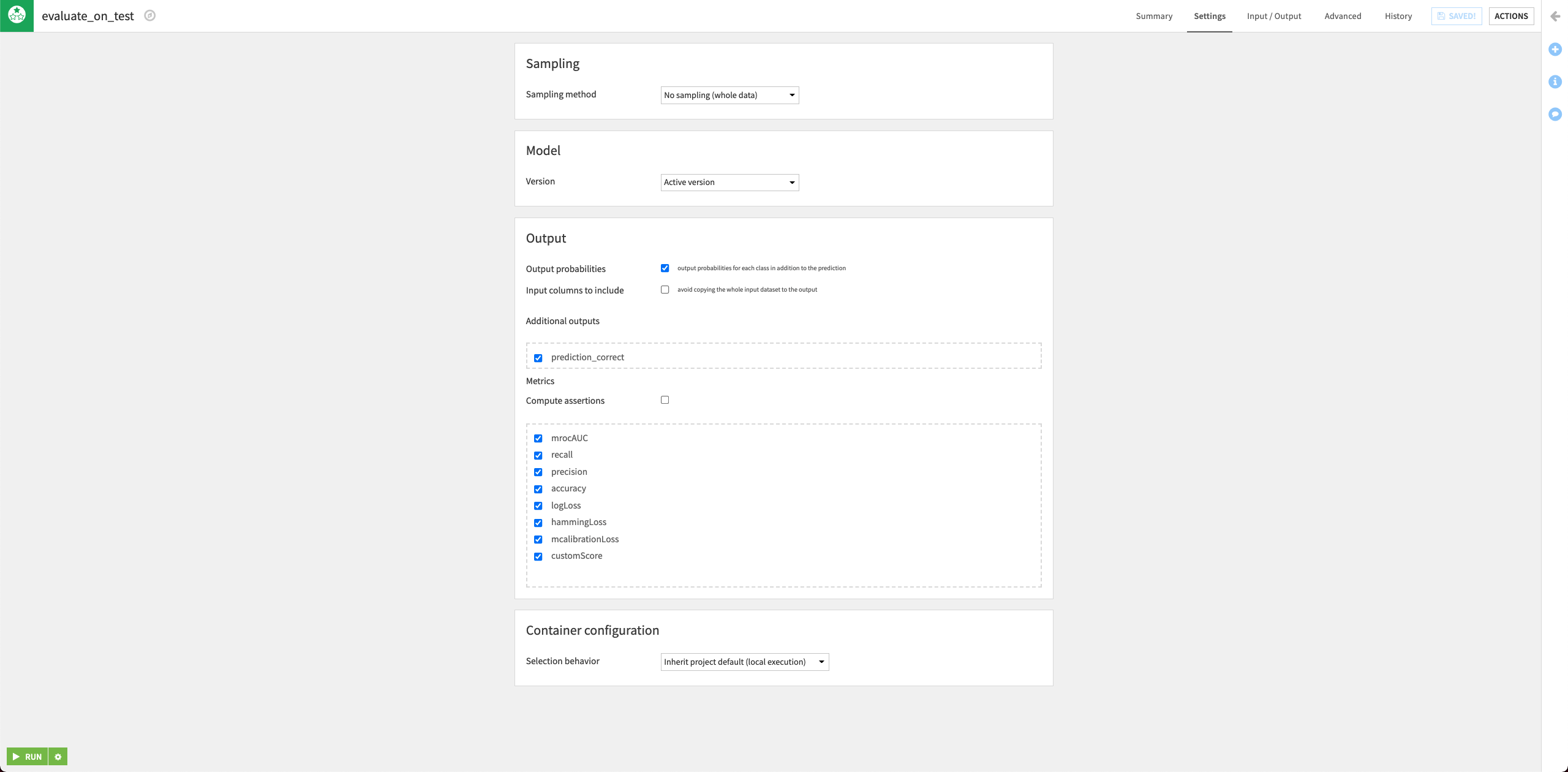
Click the test dataset and open the right panel to select the Evaluate Recipe from the “Other recipes” section.
Select the model we just deployed as the “Prediction model”.
Click Set in the “Outputs” column to create the first output dataset of the recipe.
Name the dataset
predictionsand store it in CSV format.Click Create Dataset.
Click Set to create the metrics dataset in a similar manner.
Click Create Recipe.
Keep the default settings of the Evaluate recipe.
Run the recipe and then return to the Flow.
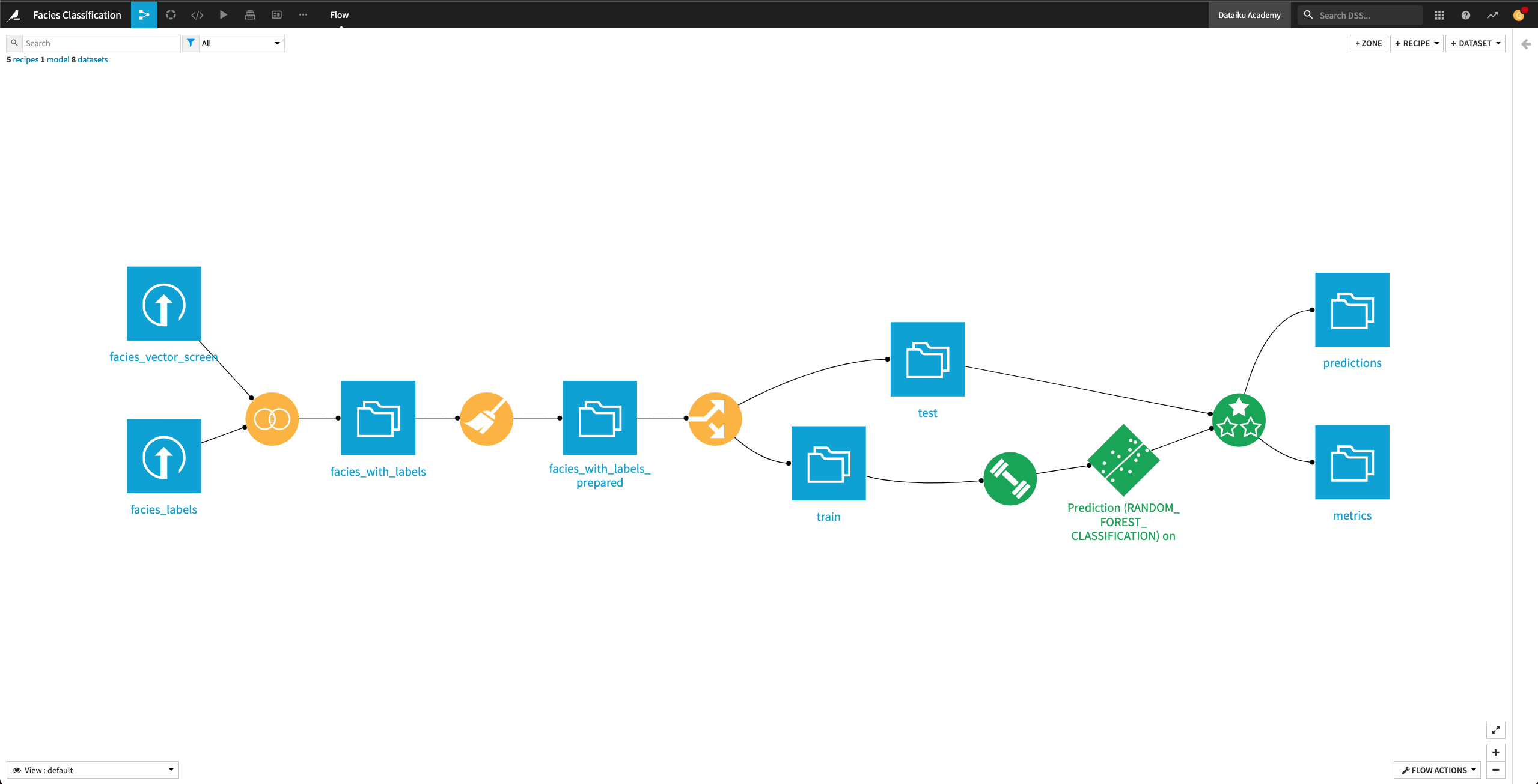
The Flow now contains the Evaluate recipe and its outputs predictions and metrics.
Open up the metrics dataset to see a row of computed metrics that include Accuracy. The model’s accuracy is now 0.66 (the training accuracy was 0.804).
Tip
Each time you run the Evaluate recipe, Dataiku appends a new row of metrics to the metrics dataset.
You can also return to the Flow and open the predictions dataset to see the last 11 columns, which contain the model’s prediction on the test dataset.
Return to the Flow.