Update Recipe Input and Propagate Schema¶
In the previous lesson, we generated new features to use for retraining our machine learning model. In this section, we’ll prepare to retrain the model by updating its input (that is, the train dataset) to include the newly generated features from the facies_with_previous_label dataset.
Remap Input of the Split recipe¶
To update the data in the train and test datasets so that they include the newly generated features, we’ll remap the input of the Split recipe to the facies_with_previous_label dataset.
Double-click the Split recipe to open it.
Click the Input/Output tab of the recipe.
Change the input dataset to facies_with_previous_label.
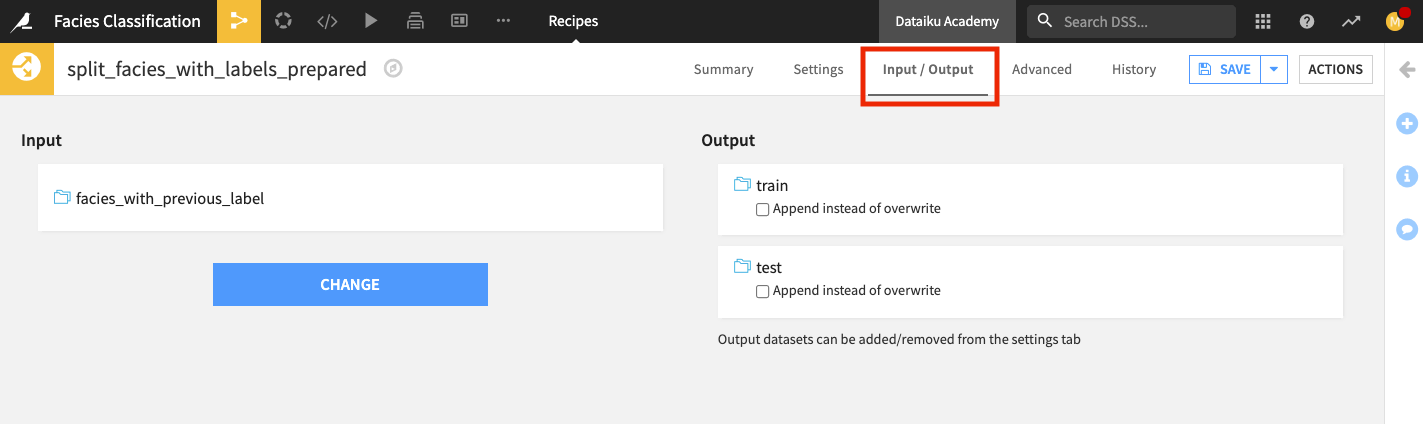
Return to the Settings tab, and run the recipe.
Update the schema when prompted. Wait for DSS to finish building the train and test datasets.
Return to the Flow.
Check Schema Consistency¶
A dataset in Dataiku DSS has a schema that describes its structure. The schema of a dataset includes the list of columns with their names and storage types. Often, the schemas of our datasets will change when designing the Flow. This is exactly what happened when we remapped the input of the Split recipe — we changed the schema of the dataset used as input to the Split recipe.
Furthermore, when we ran the Split recipe to update the data in the output datasets (train and test), we also chose to update the schema of these datasets. However, we must not forget the downstream dataset (predictions). We still need to propagate the schema changes (from train and test) to this dataset.
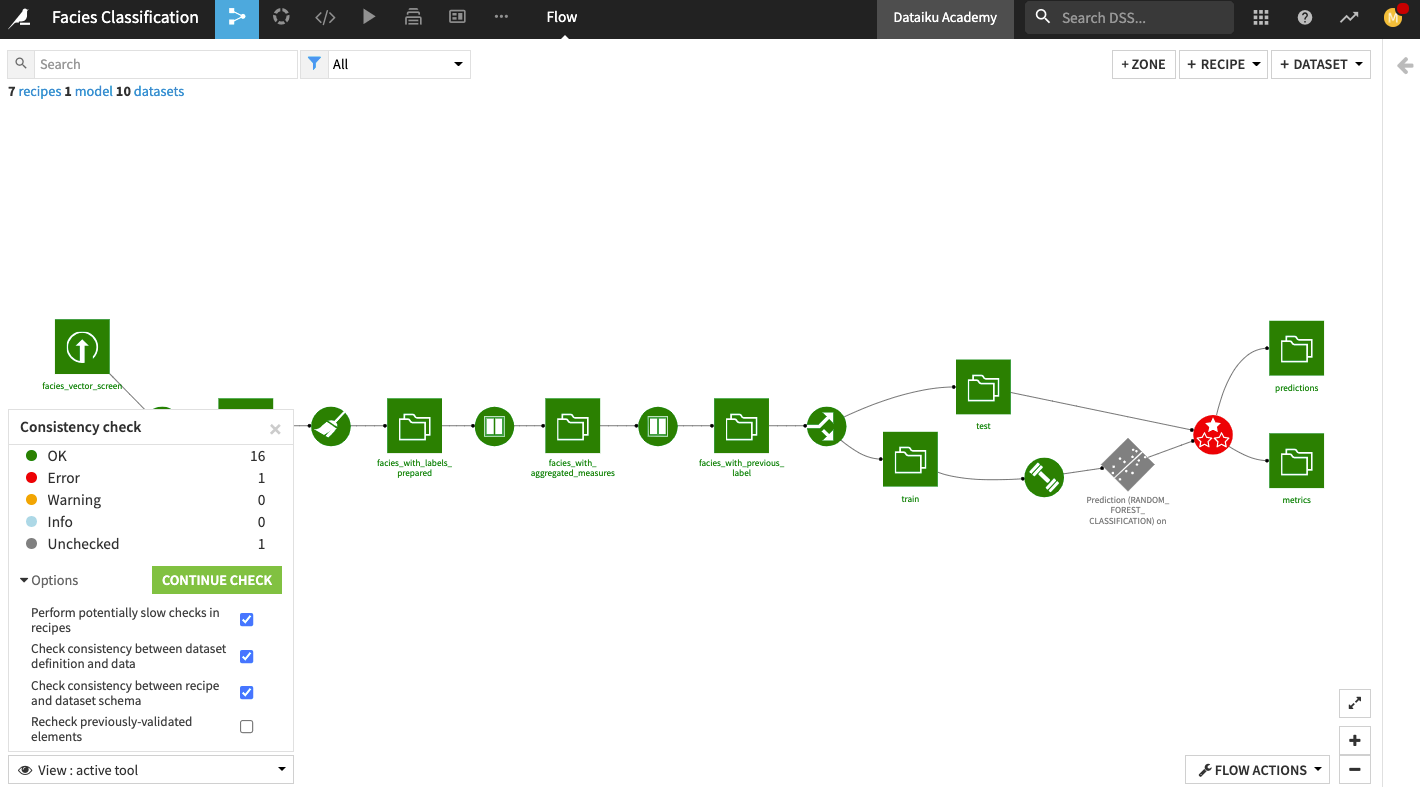
Dataiku DSS has a tool to check the consistency of all schemas in your project. To access this tool:
Click the Flow Actions button in the bottom right corner of the Flow.
Select Check consistency.

In the “Consistency check” options, click Start Check
The tool detects an error on the Evaluate recipe because the schema is incompatible between the input and the output of the recipe.
Propagate Schema¶
To fix the error detected by the Consistency Check tool, we’ll propagate the schema from the facies_with_previous_label dataset downstream across the Flow.
Right click the facies_with_previous_label dataset, and select Propagate schema across Flow from here.
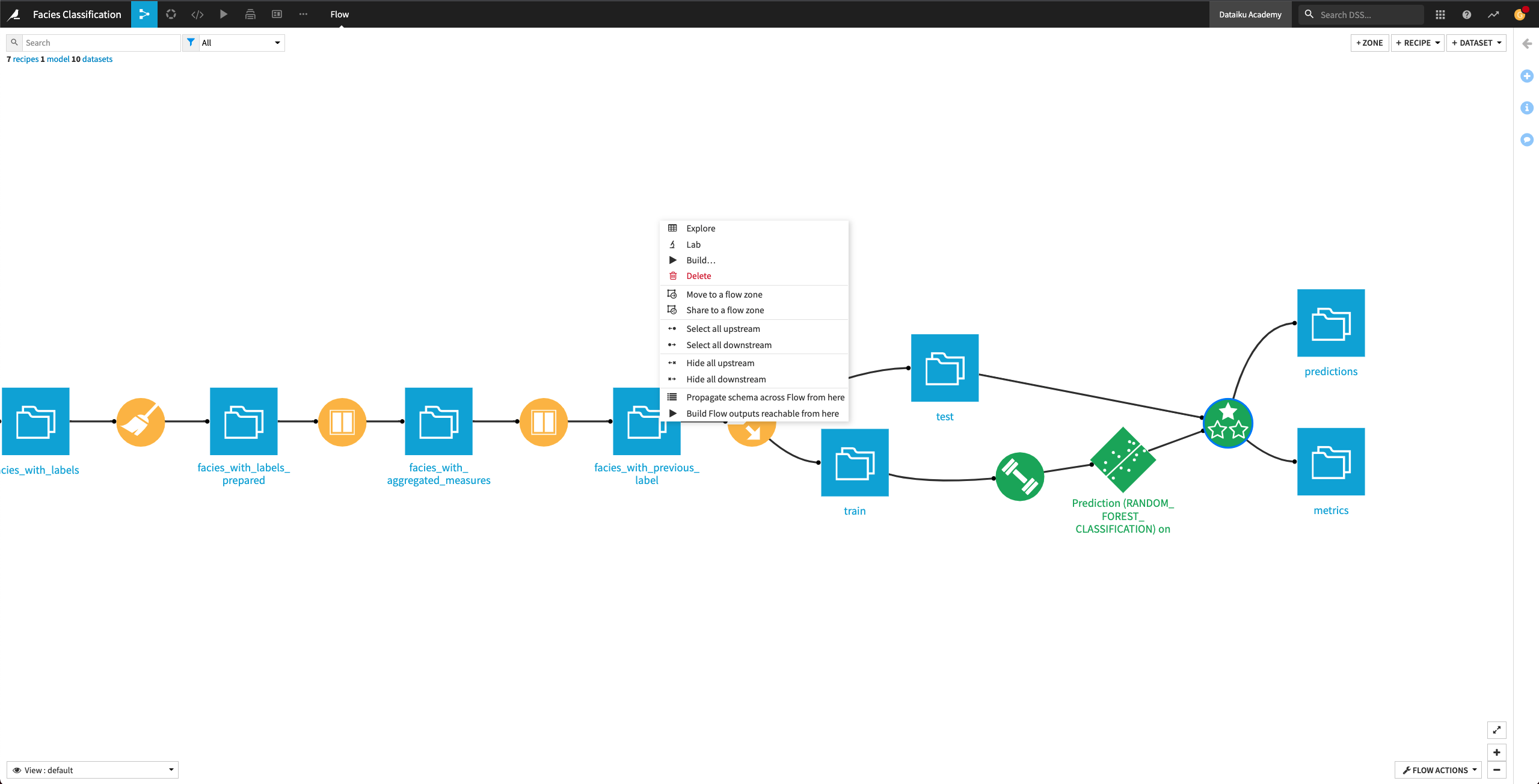
In the “Schema propagation” box, click Start.
The schema propagation tool informs us that the Train recipe needs a manual check.
Right-click the Train recipe and click Mark as OK.
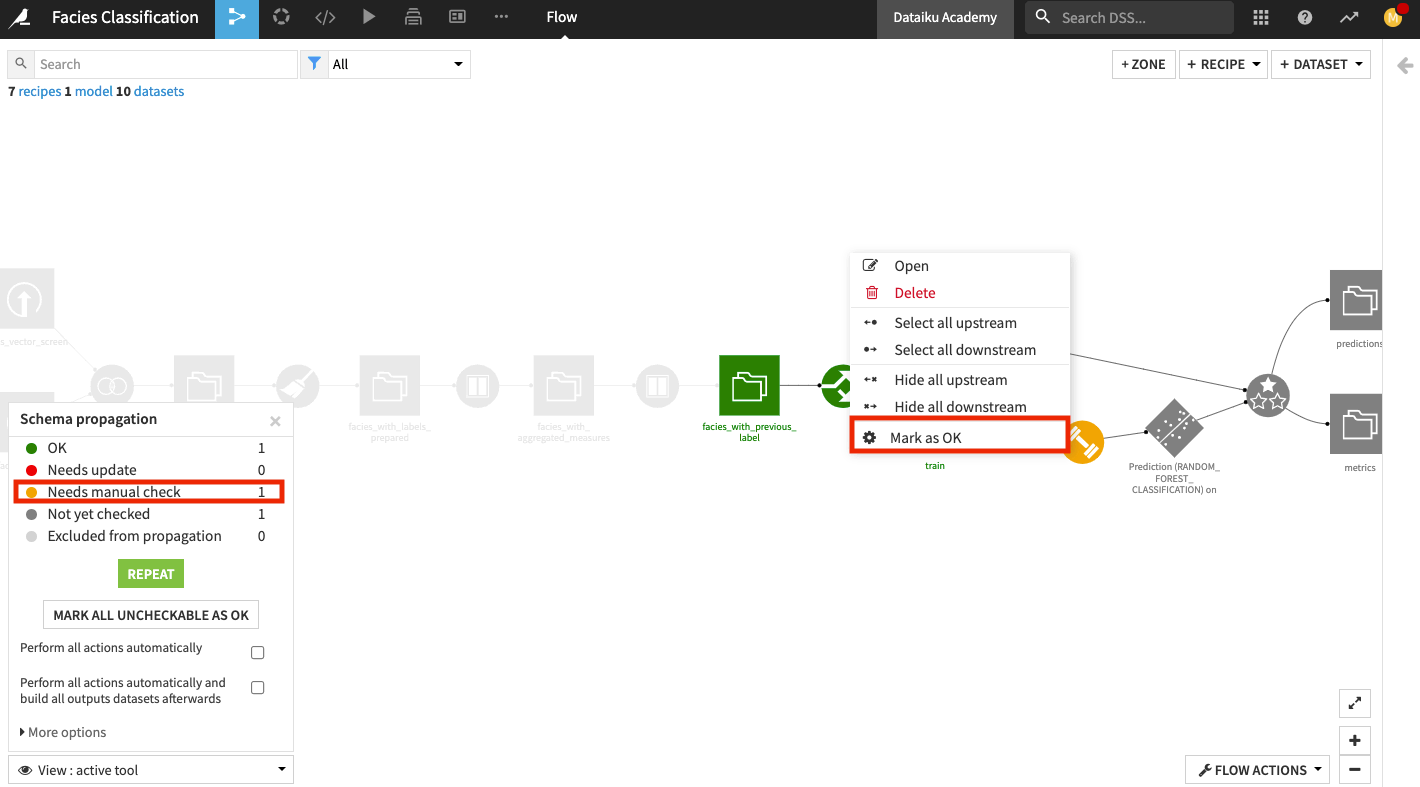
Click Repeat in the schema propagation tool.
Click the Evaluate recipe to review the schema changes.
Accept the schema changes by clicking Update Schema.
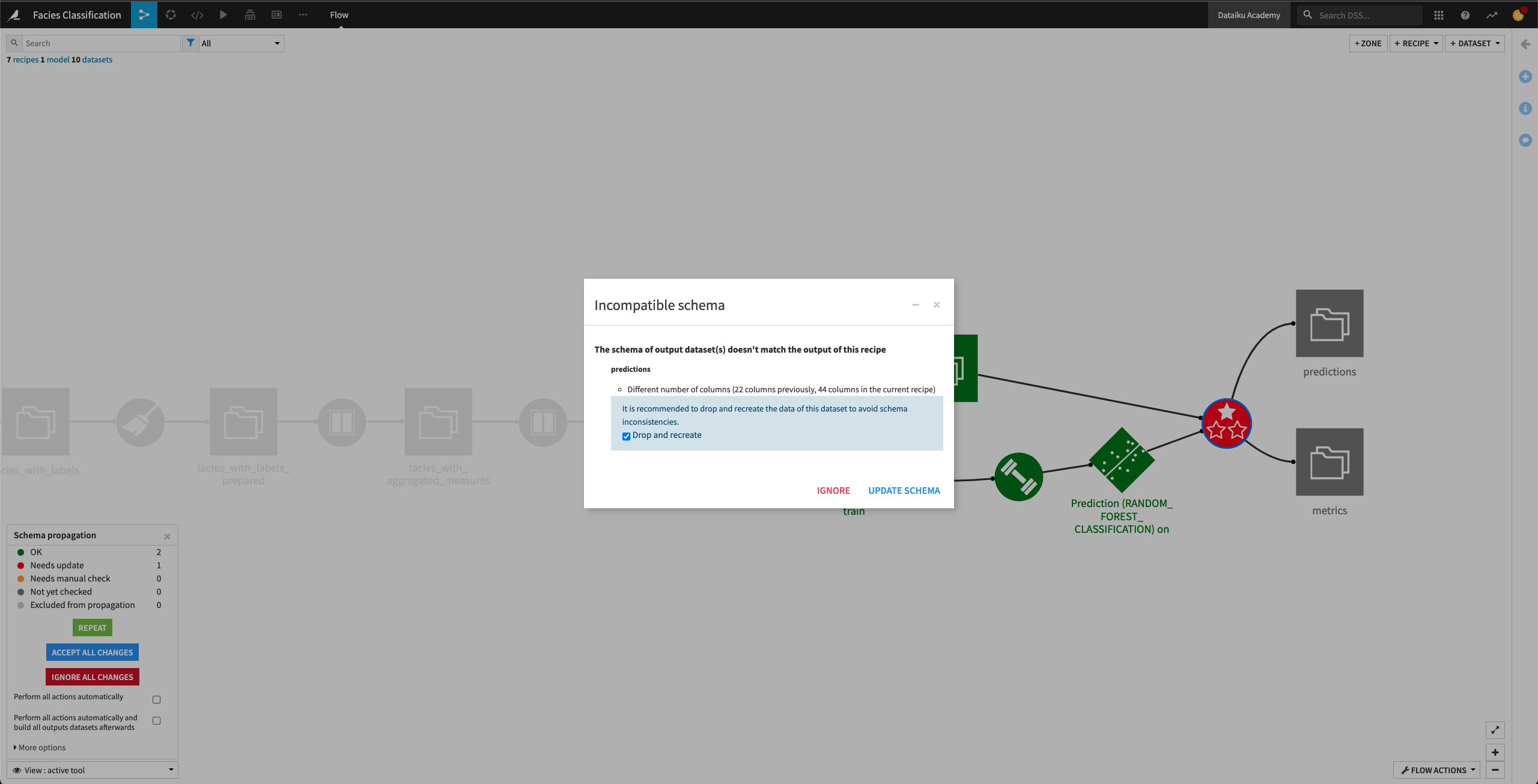
Now, all the downstream Flow items from the facies_with_previous_label dataset are colored green, indicating that we’ve resolved all the schema incompatibilities. We can now move on to retrain the machine learning algorithm.