Mining Association Rules and Frequent Item Sets with R and Dataiku DSS¶
Overview¶
Business Case¶
Looking for associations between items is a very common method to mine transaction data. A famous example is the so-called “market basket analysis”, where one looks for products frequently bought together at a grocery store or e-commerce site for instance. These kinds of associations, whether between purchases, TV shows or music, can serve as the basis of recommender systems.
In this tutorial, we demonstrate how to mine frequent item sets using an R package, from within DSS.
Supporting Data¶
We’ll be using the 1 million ratings version of the MovieLens dataset. It consists of a series of movie ratings made by users, and we are going to look for pairs of movies frequently reviewed, hence seen, by users.
This zip archive includes three files:
File name
Data on…
ratings.dat
UserID, MovieID, Rating, timestamp
movies.dat
MovieID, Title, Year, Genre
users.dat
UserID, Gender, Age, Occupation, Zip Code
Workflow Overview¶
The final Dataiku DSS pipeline appears below.
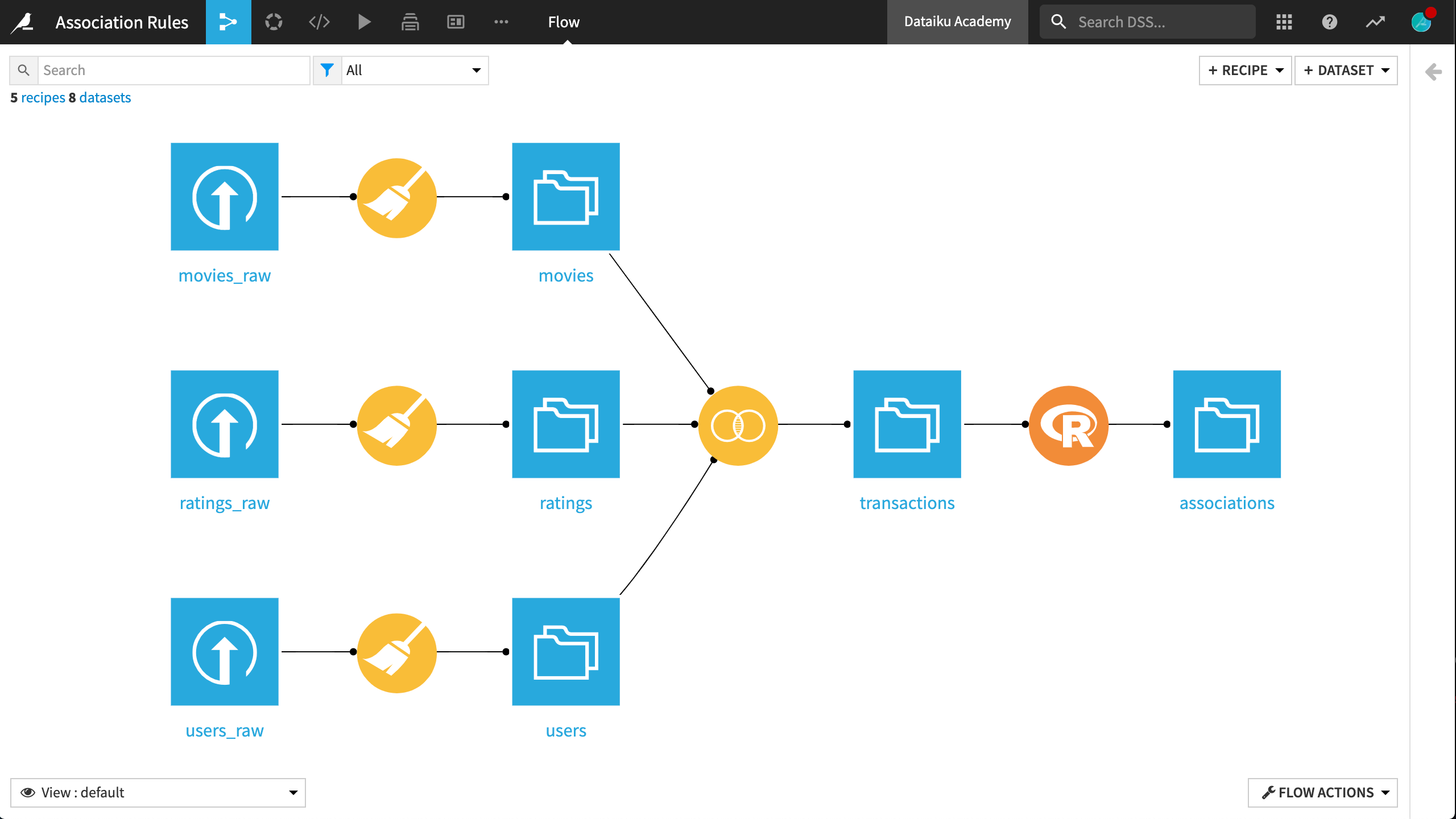
This Flow includes the following high-level steps:
Import raw data from the MovieLens dataset
Wrangle data ready for mining association rules
Use an R script to generate rules
Prerequisites¶
This tutorial assumes that you are familiar with:
the Basics courses
the Basics of R in Dataiku tutorial
Technical Requirements¶
A proper installation of R on the server running DSS.
See the reference documentation if you do not have the R integration installed.
An existing R code environment including the
arulespackage or the permission to create a new code environment.Instructions for creating an R code environment can be found in the reference documentation.
Detailed Walkthrough¶
Create a new blank Dataiku DSS project and name it Association Rules.
Data Acquisition¶
The data acquisition stage in this case requires uploading three flat files to DSS.
Download the MovieLens 1M file and uncompress the zip archive.
One at a time, upload the three files to DSS. For each file, before creating the new dataset, navigate to the Format/Preview tab and change the type to One record per line.
Append “_raw” to the end of each file name. For example, movies_raw.
Data Preparation¶
Before we can use this data for mining association rules, a few simple preparation steps in DSS are needed.
Clean Data¶
All three datasets require a similar Prepare recipe. In the Lab, create a new visual analysis on the movies_raw dataset.
Use the Split column processor on the column line, using “::” as the delimiter.
Remove the original line column.
Rename the freshly-generated columns:
MovieID,Title, andGenre.Use the Extract with regular expression processor on the Title column using the pattern
^.*(?<year>\d{4}).*$in order to create a year column.Deploy this script to the Flow, simplifying the output dataset name to just movies.
Nearly the same process can be repeated on the remaining two datasets, ratings_raw and users_raw. Only the column names differ.
For ratings_raw, rename columns line_0 to line_3 with the names
UserID,MovieID,Rating, andtimestamp, respectively.For users_raw, rename columns line_0 to line_4 with the names
UserID,Gender,Age,Occupation, andZip_code, respectively.
Moreover, the step extracting year with a regular expression can be omitted.
Join Data¶
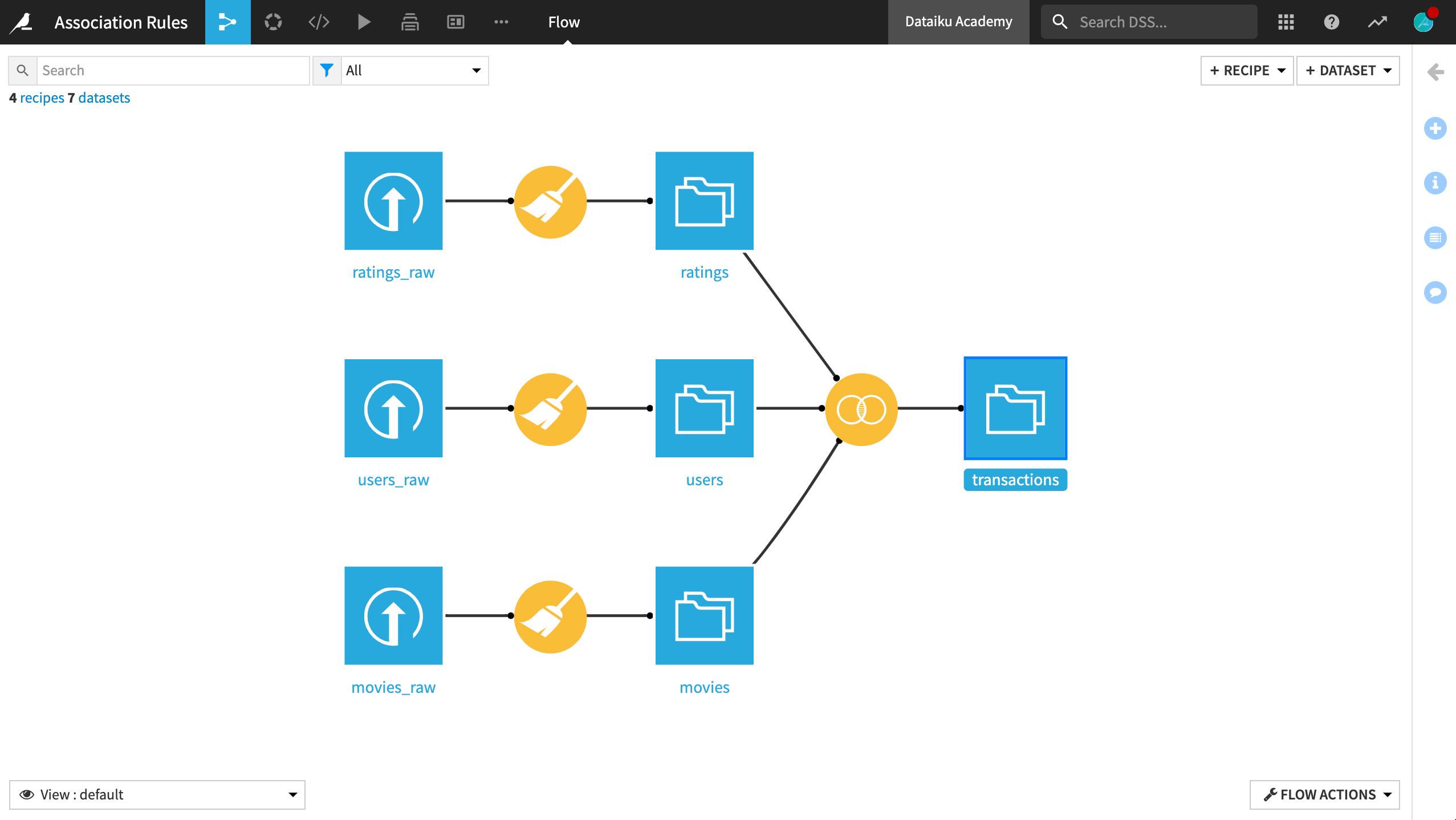
After building the prepared datasets, join all three together with the Join recipe.
Initiate a Join recipe between ratings and users. Name the output dataset
transactions.Use a left join with UserID as the key.
Add movies as a third input dataset by inner joining ratings and movies on the key MovieID.
On the Selected Columns step, add the prefixes
UserandMovieto their respective columns for greater clarity on the origin of these columns.Run the recipe, updating the schema to 11 columns.
This will create a completely denormalized dataset, ready for the association rules analysis. At this point, the Flow should appear as below:
Mining Frequent Associations With R¶
Creating associations rules, or mining frequent item sets, is a set of techniques that can be used, in this case, to look for movies frequently reviewed together by users.
The arules R package contains the apriori algorithm, which we will rely on here.
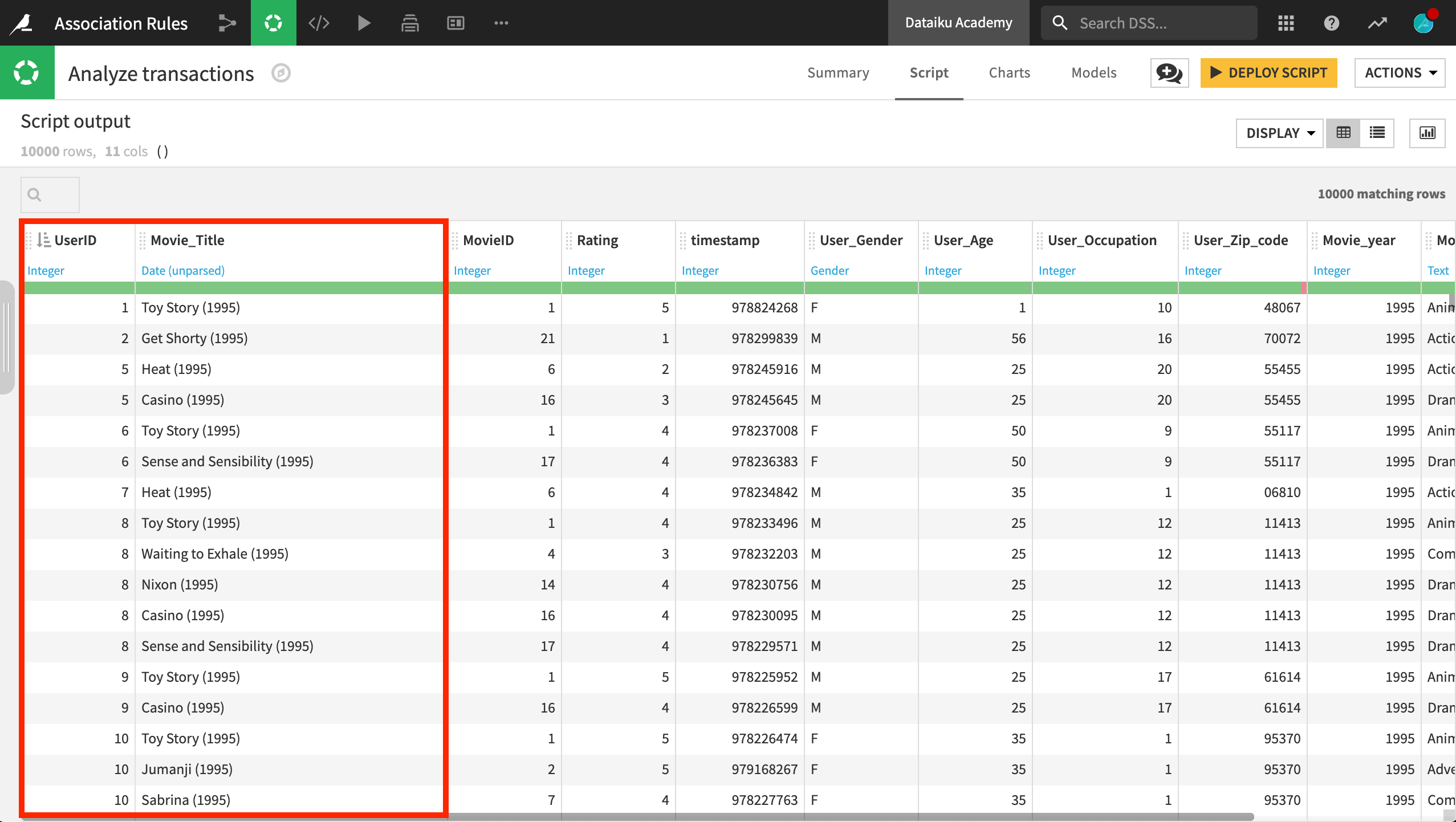
From the transactions dataset, we need just some pretty simple data: a “grouping” key, which is here the UserID, and an “item” column, which is here the movies seen:
Create a Code Environment¶
The default built-in R code environment includes popular packages like dplyr and ggplot2, but it does not include arules. Accordingly, create a new R code environment including this package, if one does not already exist.
Note
Users require specific permissions to create, modify and use code environments. If you do not have these permissions, contact your DSS administrator.
For detailed instructions on creating a new R environment, please consult the reference documentation.
Create a Code Recipe¶
From the transactions dataset, create a new R code recipe, naming the output dataset associations.
Paste the script below into the code recipe. Run it to produce the output dataset associations.
library(dataiku)
library(arules)
# Recipe inputs
transactions <- dkuReadDataset("transactions", samplingMethod="head", nbRows=100000)
# Transform data to make it suitable
transactions <- as(
split(as.vector(transactions$Movie_Title), as.vector(transactions$UserID)),
"transactions"
)
# Analyze
rules <- apriori(
transactions,
parameter=list(supp=0.02, conf=0.8, target="rules", minlen=2, maxlen=2)
)
rules <- sort(rules, by ="lift")
# Recipe outputs
dkuWriteDataset(as(rules, "data.frame"), "associations")
This script does the following:
Imports the required packages, including the Dataiku API
Reads the dataset
Transforms the dataset into a suitable “transaction” format for the
arulesfunctionsApplies the apriori algorithm using a few parameters:
Minimum level of support and confidence (more on this later)
Extract only the rules made of 2 elements
Sort the results by descending lift
Writes the resulting dataframe into a DSS dataset
Note
Instead of directly running this R recipe, you could have interactively written this script in an R (Jupyter) notebook within DSS. Alternatively, you could create a blank R recipe. Develop it in RStudio through its integration with Dataiku, and save it back into DSS.
Interpreting Results¶
The associations rules are stored here in the final associations dataset, which is shown below.
The first column, rules, is structured as {Movie A} => {Movie B}. It can be interpreted as people who saw Movie A also saw Movie B.
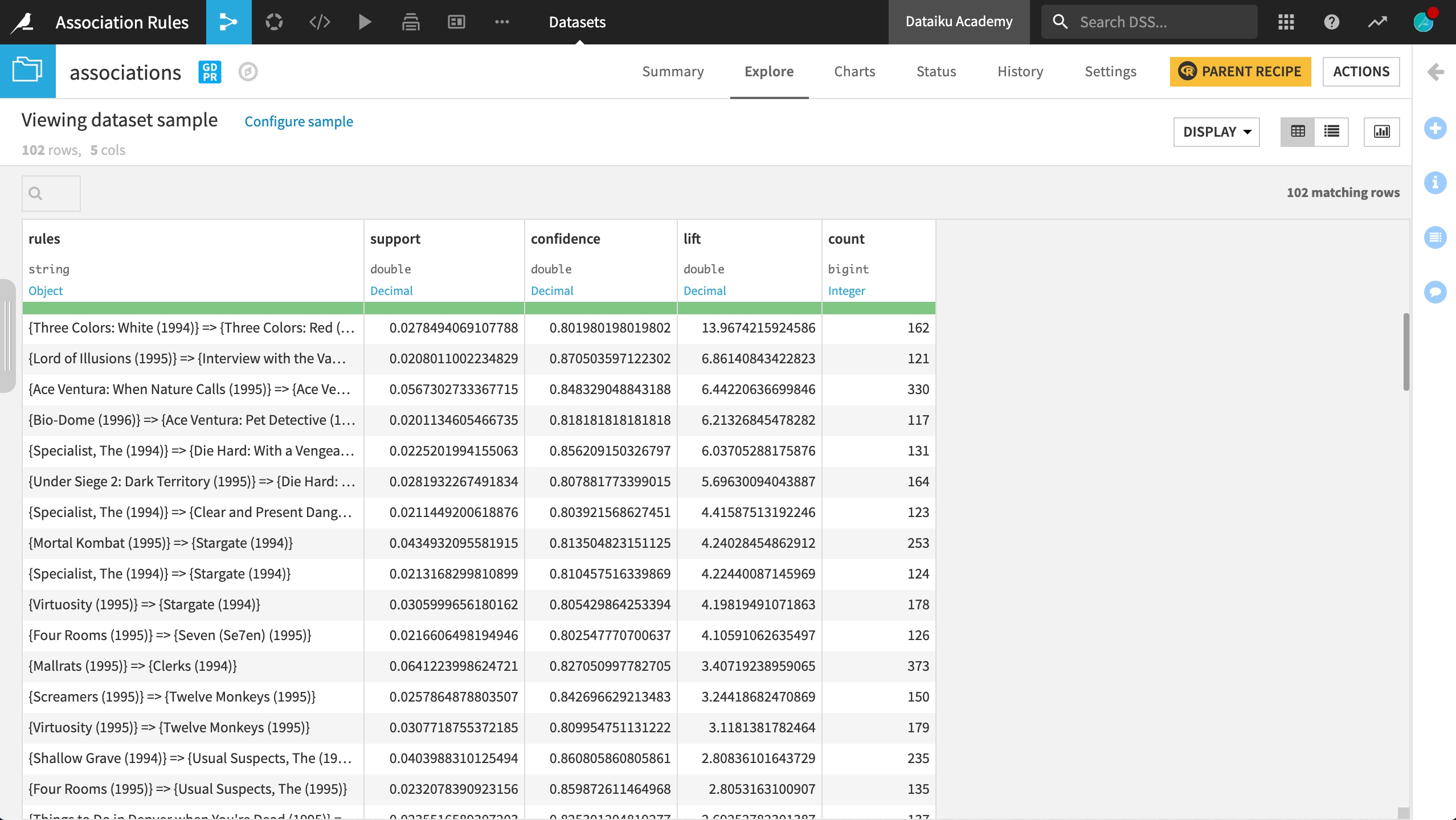
It then includes three important statistics:
The support is the fraction of people who saw both movies among the entire dataset.
The confidence tells us the percentage of people who saw Movie A, also saw Movie B.
Finally, the lift is an interesting measure that will allow us to remove trivial rules, those that could appear only because both movies in the rule are popular. It is a correlation measure based on the fact that the actual joint probability of seeing both movies is higher than the one if they were independent.
Rules with a lift higher than 1 are the rules of greatest interest. The higher value, the higher the correlation. Going further, you may want to experiment adjusting the parameters of the algorithm, being more or less restrictive in terms of different settings.
In this sample, some of the rules with the highest lift score make sense. Some rules includes two films from the same trilogy (Three Colors), a film and its sequel (Ace Ventura), or two films from the same director (Mallrats and Clerks).
Wrap-up¶
Congratulations! You have created a workflow that takes advantage of the visual interface of DSS for data wrangling, while also harnessing a statistical technique from an R package.