How do I train a stratified or partitioned model?¶
You may sometimes be interested in building a prediction model on different subgroups of your dataset, rather than the overall dataset. These models, called stratified models (or partitioned models), can lead to better predictions when relevant predictors for a target variable are different across subgroups of the dataset. For example, customers in different data subgroups may have different purchasing patterns that contribute to how much they spend.
Train a stratified model¶
When you create a visual machine learning (prediction) model on a partitioned dataset, you have the option to create partitioned models.
Navigate to the Design page of the modeling analysis session.
In the Target panel, enable the Partitioning option.
Select which partitions of the dataset to use when training in the Analysis. For example, the following screenshot shows three selected partitions.
Train the models.
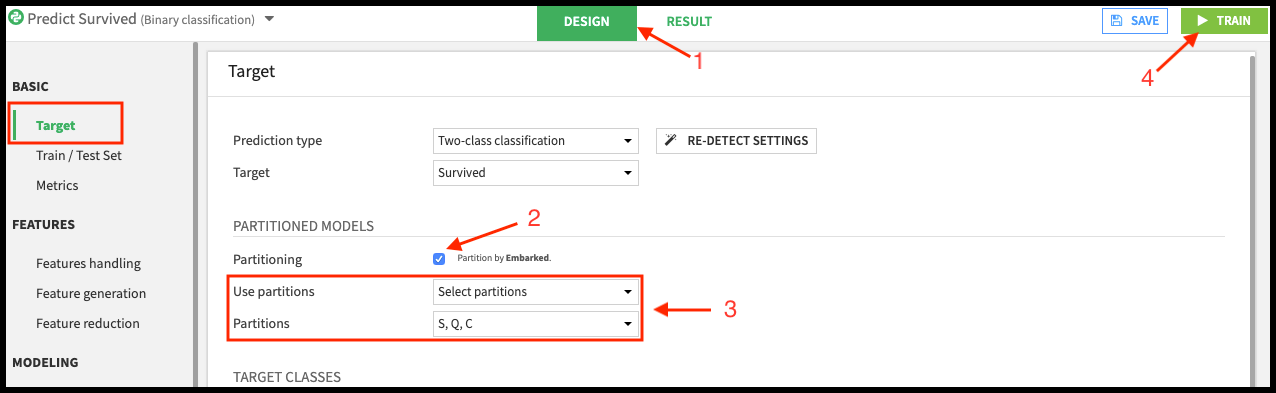
Specifying partitions to use for training¶
The following results show partitioned models.
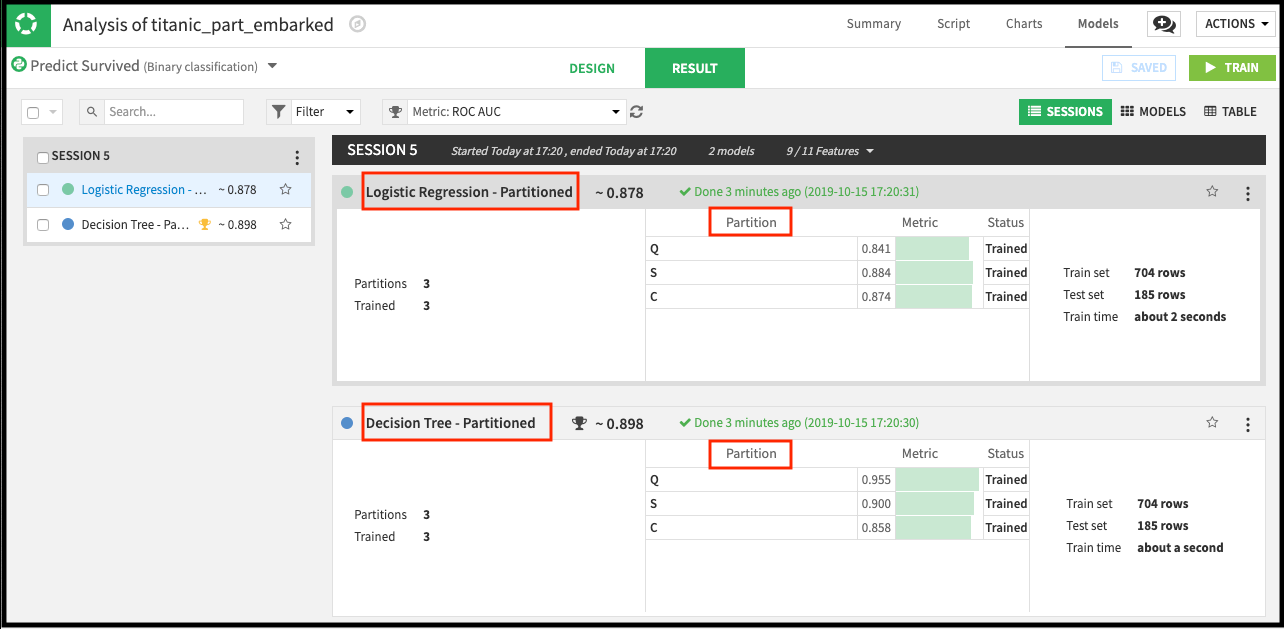
Result page showing partitioned models¶
When you select algorithms to use for training, Dataiku DSS trains a partitioned model for each algorithm. Each partitioned model consists of one sub-model (or model partition) per data partition. For example, the previous screenshot shows two partitioned models (Logistic Regression - Partitioned and Decision Tree - Partitioned). Each of these models has three model partitions, one for each partition that was trained.
What’s next?¶
The reference documentation provides more details about Partitioned models in Dataiku DSS.