Data Governance with the GDPR Plugin¶
In order to help data teams comply with internal policies and external regulations (such as GDPR) around data privacy and protection, Dataiku provides a plugin that allows you to:
Document data sources with personal information and enforce good practices
Restrict access to projects and data sources with personal information
Audit the personal information in a Dataiku DSS instance
Prerequisites¶
Familiarity with plugins in Dataiku
Familiarity with how Dataiku uses a groups-based model to manage permissions
Technical Requirements¶
An account with administrative privileges, to install and configure the plugin and related security measures
An account with privileges as described in the plugin configuration below, to work with personal data
Install and Configure the Plugin¶
Logged in on an account with administrative privileges, install the GDPR plugin from the plugin store.
The video below provides a walkthrough of the instructions described in this section below.
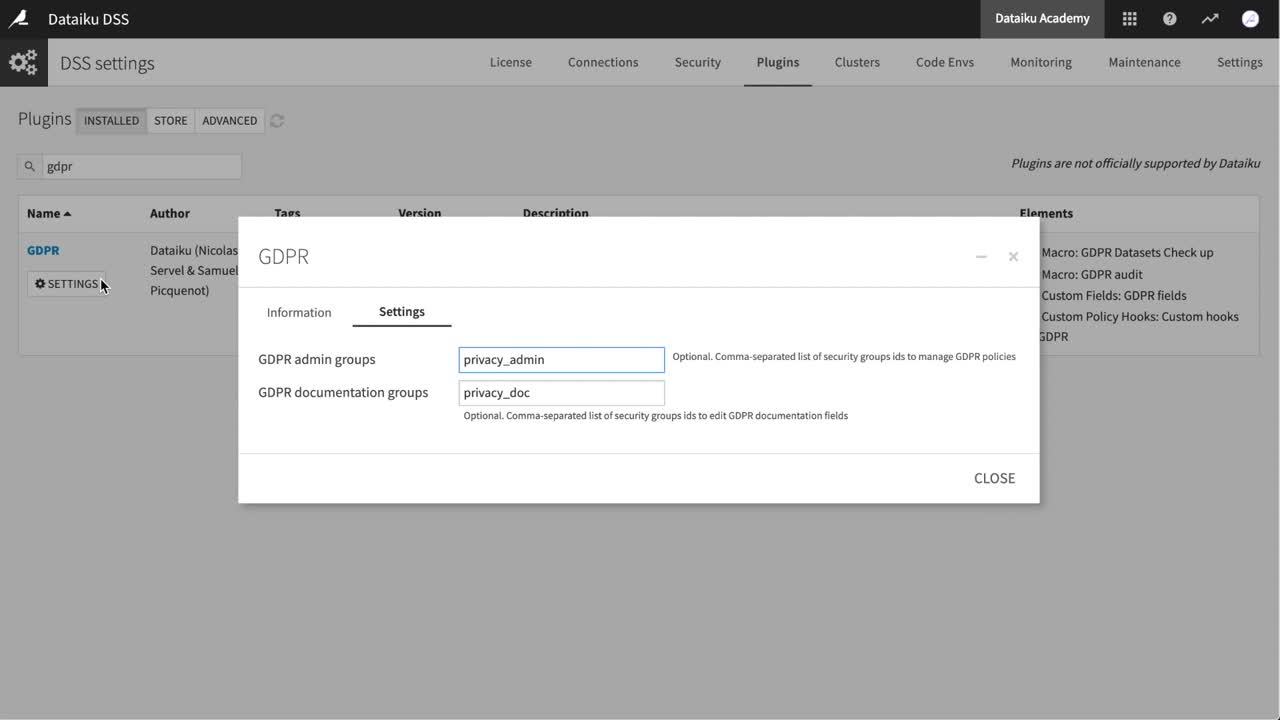
Within the Installed tab of the Plugins page, navigate to the GDPR plugin and click Settings. Configuring the plugin requires defining two types of groups responsible for enforcing data governance policies:
Group
Responsibility
GDPR admin groups
Configure projects that contain personal data
GDPR documentation groups
Document whether datasets contain personal data
We could assign these privileges to pre-existing groups. However, depending on your team’s particular circumstances, it is often good practice to separate groups of privileges to specific users that require those privileges.
Accordingly, in this example, define privacy_admin as a GDPR admin group and privacy_doc as a GDPR documentation group.
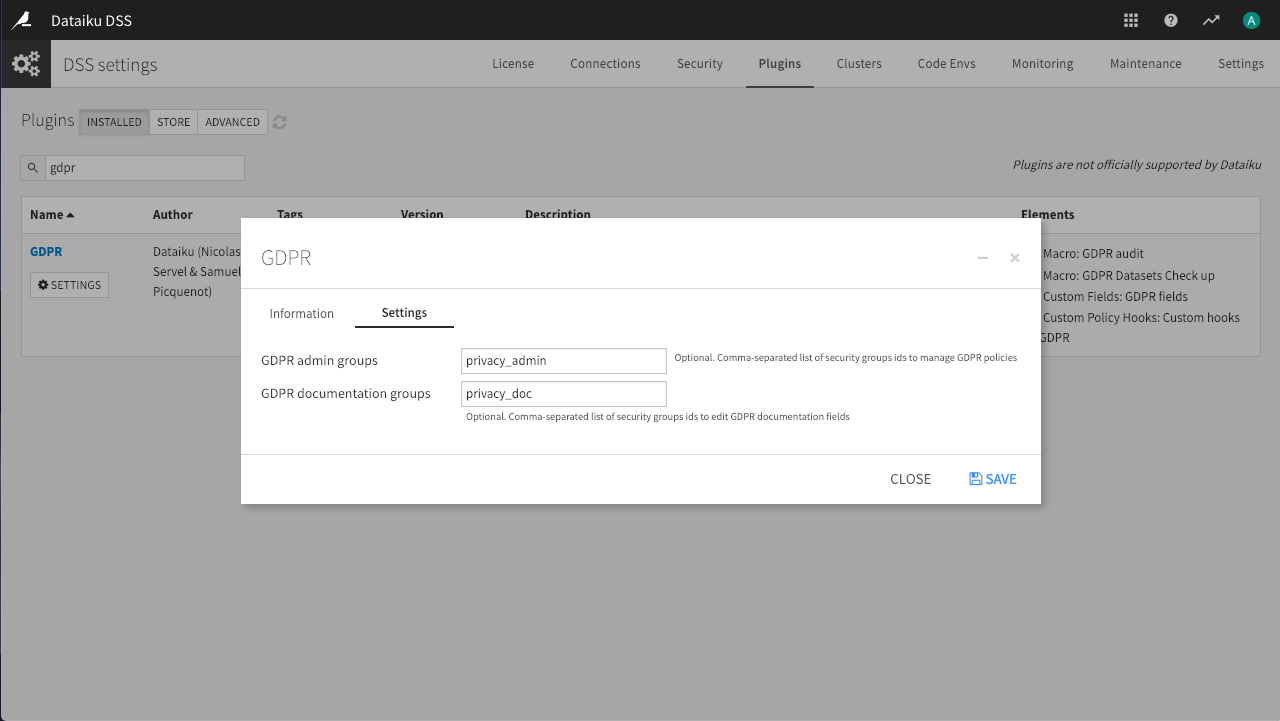
As demonstrated in the video, it is possible to assign these GDPR privileges to multiple groups by separating the group names with a comma. For the purposes of this demonstration however, one group in each category is sufficient.
Configure Security for Work with Personal Data¶
Although we have defined privacy_admin and privacy_doc to be our respective GDPR admin and documentation groups, we have not yet actually created those groups on the instance. Nor have we assigned any users to those groups.
Create those groups now.
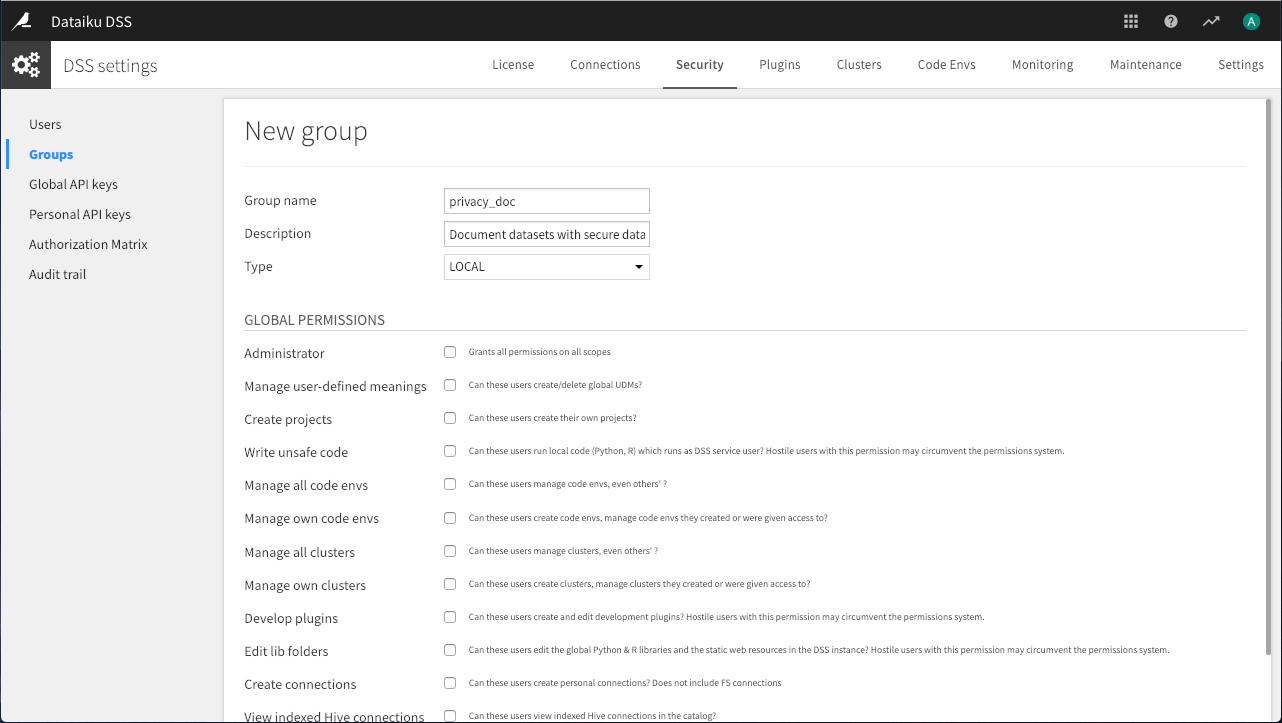
Continuing on an admin account, navigate to the Security tab of the administration tool, and then to the Groups panel.
Click +New Group.
Name the new group
privacy_adminand provide a description such as “Configure projects for work with personal data”.Then click Save.
There is no need to set any global permissions for this group, since its existence is simply to confer project administrator permissions related to privacy. A user’s other global permissions come from membership in other appropriate groups.
Note that it may be good practice to give privacy_admin the “Create projects” permission, and only allow users with privacy_admin to create projects on the instance.
Create another group called
privacy_docand provide a description such as “Document datasets with personal data”.
Now that we have created these two groups, we need to assign users to them. On the Users panel, assign at least one user to each of these newly-created privacy groups.
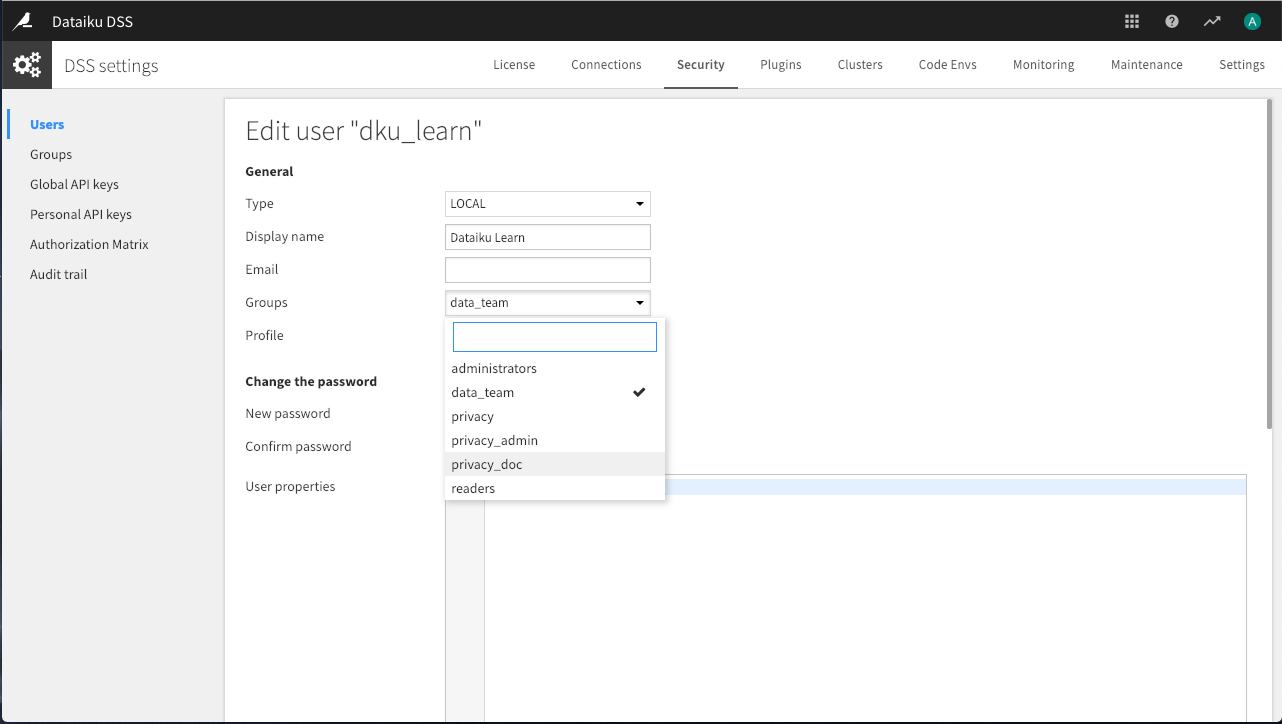
Note that the user assigned to the privacy_doc group should have write access to the DSS project created below.
Note
Depending on your organization’s data governance strategy, it may be useful to create other “privacy_*” groups for users who will be given access to individual projects containing personal data, but not the authority to configure the project or dataset privacy settings.
Configure Projects for Work with Personal Data¶
Once a Dataiku DSS instance is configured to work with personal data, you can configure data governance settings at the project level.
While logged in as a user with the privacy_admin group privilege, from the instance homepage, select +New Project > DSS tutorials > General Topics > Data Governance.
The video below provides an overview of the features described in the next two sections.
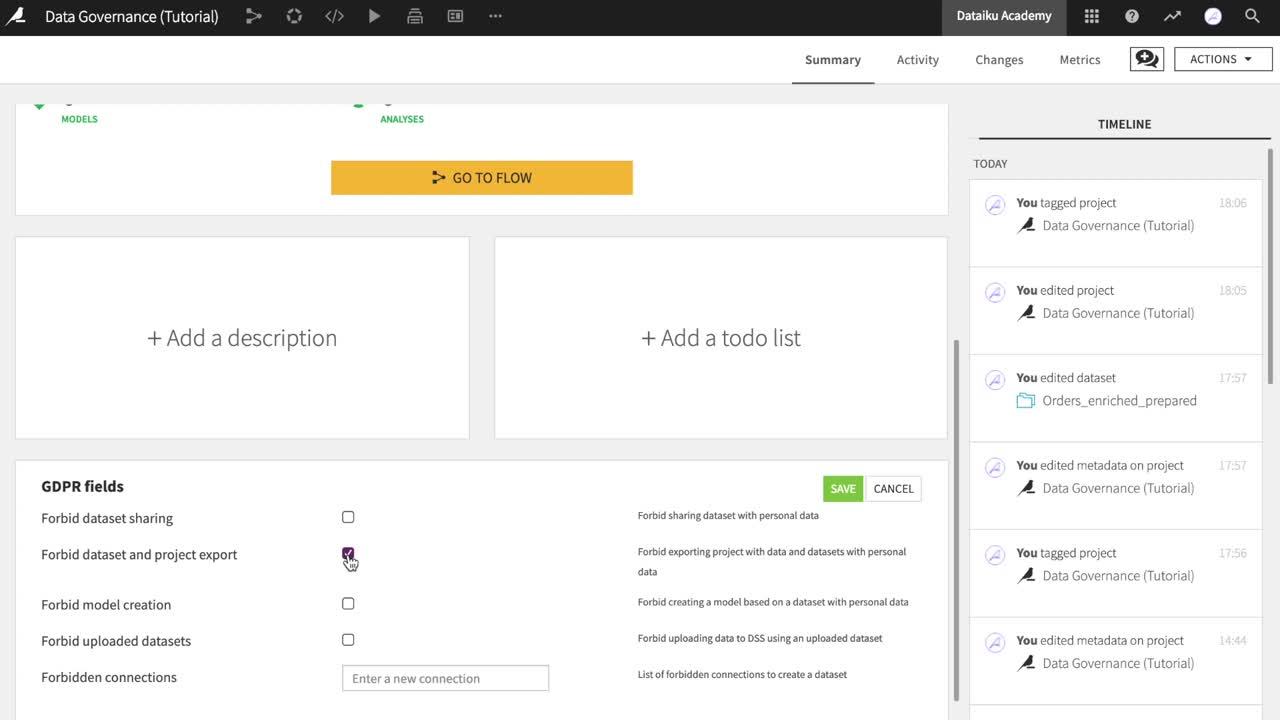
With the GDPR plugin installed, the bottom of any project homepage contains a section of data governance settings. These options include a variety of restrictions a GDPR admin can place on the project.
GDPR Field |
Prevent any user from: |
|---|---|
Forbid dataset sharing |
Sharing a dataset with personal data outside of the project |
Forbid dataset and project export |
Exporting a dataset with personal data, or exporting the project if it contains any dataset with personal data |
Forbid model creation |
Creating a model with the Dataiku Visual ML tool on any dataset with personal data |
Forbid uploaded datasets |
Creating an “Uploaded files” dataset and potentially introducing personal data to the project in an insecure way. Note that this restriction only affects new datasets, and not existing ones. |
Forbidden connections |
Creating a dataset in this project from any of the connections. The idea is that you may want to explicitly restrict the usage of some connections because they contain personal data (CRM source for example). |
For example, here a GDPR admin has forbidden users from sharing or exporting any specific datasets, or the project itself, if they contain personal data. Similarly, users cannot create models based on datasets with personal information.
In practice, if a user who does not belong to the privacy_admin group attempts to edit any of these fields, they will encounter an error like the one below and be unable to save the project.

Warning
The restrictions put in place here encourage best practices, but do not guarantee they will be followed. A user can circumvent the restrictions using code or the API. For a larger context, you may find this white paper available on executing Data Privacy-Compliant Data Projects to help useful.
Document Datasets with Personal Data¶
Now that a user in a GDPR admin group has configured the project-level data privacy settings, let’s see how a user in a GDPR documentation group can identify datasets containing personal data.
While logged in as a user with the privacy_doc group privilege, from the project Flow, open the Customers dataset.
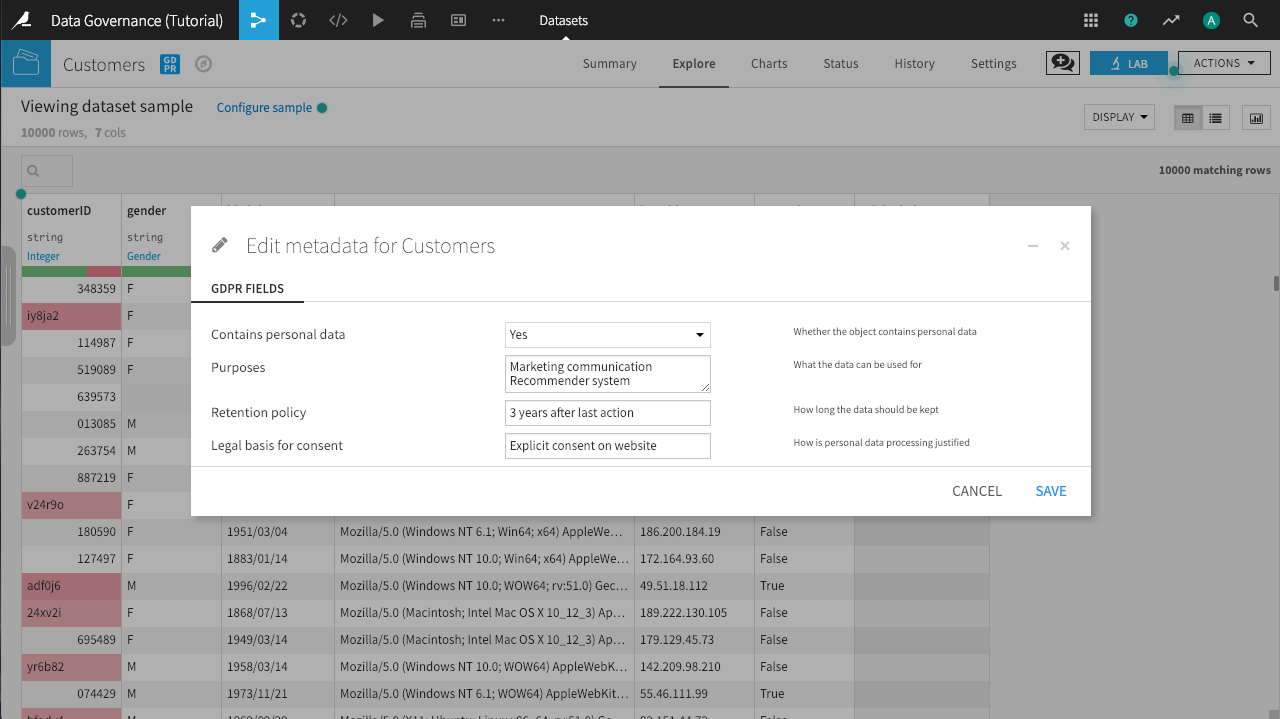
Click on the blue GDPR icon next to the dataset’s name to view the four GDPR fields for the dataset.
GDPR Field |
Documenting: |
|---|---|
Contains personal data |
Whether or not the dataset contains personally-identifying information |
Purposes |
For auditing purposes, the reason why this data was collected |
Retention policy |
For auditing purposes and to take appropriate filtering actions, how long the personal data can be used |
Legal basis for consent |
For auditing purposes, how the personal data came into our possession |
In this case, provide the following sample answers and click Save:
Contains personal data: Yes
Purposes:
Marketing communication Recommender systemRetention policy:
3 years after last actionLegal basis for consent:
Explicit consent on website
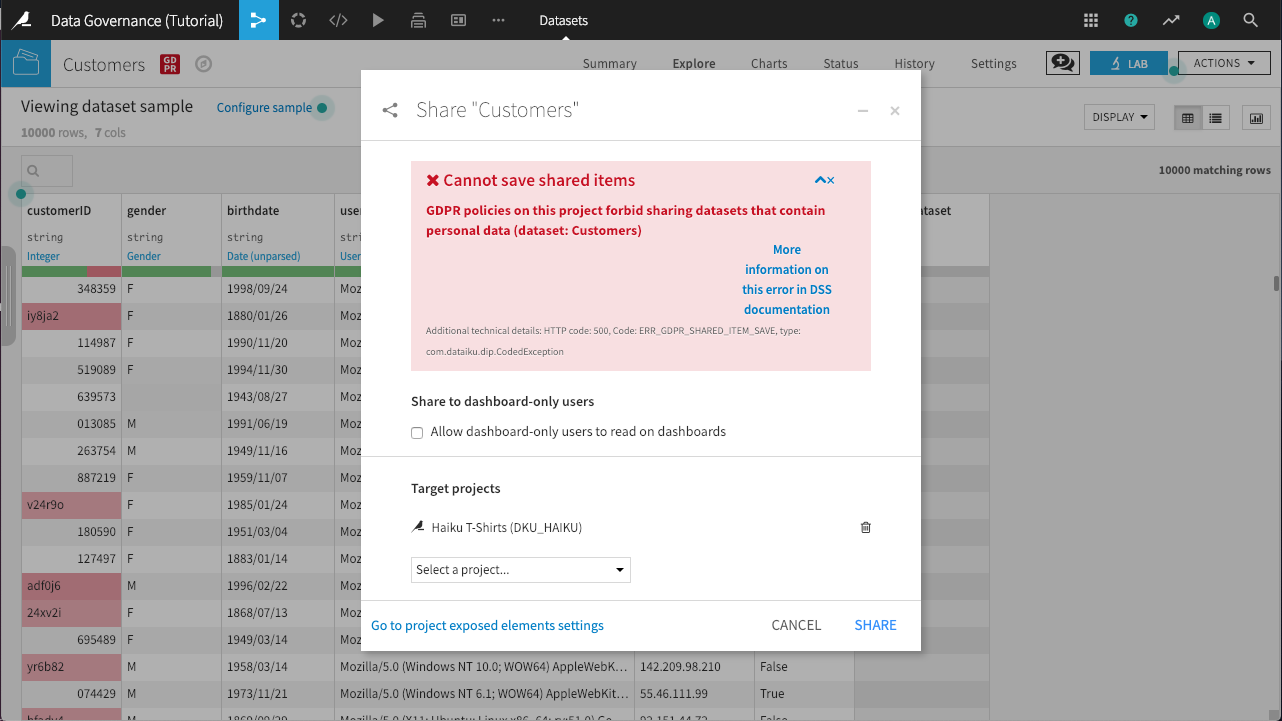
Notice that the formerly blue GDPR icon has now turned red after indicating that the dataset contains personal data. Now select Actions > Share and choose any project to share this dataset with.
Because the privacy_doc user has documented this dataset as containing personal data, and because of the project-level privacy settings configured by the privacy_admin user, Dataiku DSS prevents the share from happening.
Now open the Orders_enriched_prepared dataset. The Prepare recipe that produced it has removed the personally-identifying information, and so we can mark this dataset as not containing personal data. The GDPR icon is now colored green to signal the lack of personal data.
In the Flow, you can view the GDPR status of each dataset by choosing Metadata fields from the View menu at the bottom left of the screen. Ensure that GDPR fields - Contains personal data is the selected field.
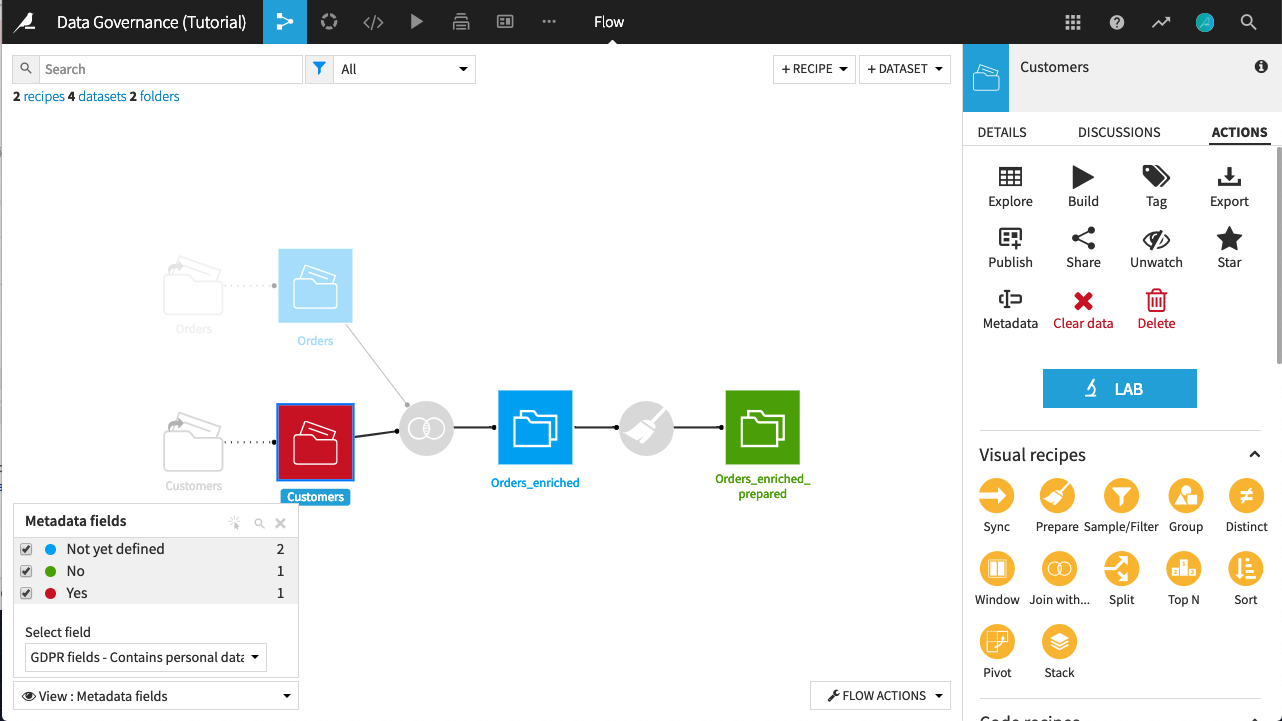
Personal Data Status in Recipe Output¶
It is important to understand how recipes impact a dataset’s GDPR status with respect to the presence of personal data. The principle to keep in mind is that the documentation of personal data is, by design, a human task. Accordingly, documenting the output of a recipe with respect to personal data is also a human task.
Note
Key Concept
When building a Flow, the initial output dataset to any recipe, regardless of whether its input dataset was marked as blue, green or red, will not be defined with respect to the presence of personal data.
It remains a human task to document the presence of personal data in an output dataset because it is not obvious whether the recipe in question has introduced or removed personal data.
After a user has documented the status of personal data in an output dataset, attention must also be given to the effect of editing and saving the recipe that produced it.
If all inputs to a recipe have been documented as being free of personal data (green), and a user has also marked the output dataset as green, then editing and saving the recipe will not affect the status of personal data in the output dataset. The output dataset remains green.
On the other hand, if the inputs to a recipe are not entirely clear of personal data (at least one blue or one red input), regardless of the previous documentation of the output dataset, editing and saving the recipe will revert the status of the output dataset to not yet defined (blue). Once again, the plugin ensures a human is in the loop to document the presence of personal data.
Safely Sharing Data Downstream¶
This tutorial has demonstrated how the GDPR plugin assists in documenting personal data at the project level (through a GDPR admin group) and the dataset level (through a GDPR documentation group).
We may next wish to consider structuring a workflow that allows datasets to be safely shared with users not permitted to access personal data.
In the above example, the green icon of Orders_enriched_prepared signifies that it no longer contains personal data, following the Prepare recipe. Accordingly, it is free to be shared downstream with groups of users that should not have access to personal data.
To share the Orders_enriched_prepared dataset with another project, first select it from the Flow. From the Actions section of the right panel, find the Share icon. In the following dialog, under Target Projects, select one or more projects with which to share the dataset.
That dataset now appears in the selected project’s Flow. Its name will have the name of the origin project prefixed to it. Moreover, after having been shared, the GDPR status with respect to personal data for that dataset remains present in the new project.
In addition to sharing a dataset from the Flow, we can also navigate to the Exposed elements section of the … > Security menu found in the top Navigation bar. This menu lists not only datasets, but all objects (which may include models, notebooks, web apps, etc.) currently exposed, and the projects with which they have been shared. Add or delete new exposed objects from this menu at any time.
Note
For more information on exposed objects, please see the reference documentation.
Produce an Audit Report¶
Being able to quickly generate audit reports is an important aspect of compliance with data privacy regulations. The GDPR plugin enables the creation of two different types of audit reports for personal data. From the top Navigation bar, choose … > Macros.
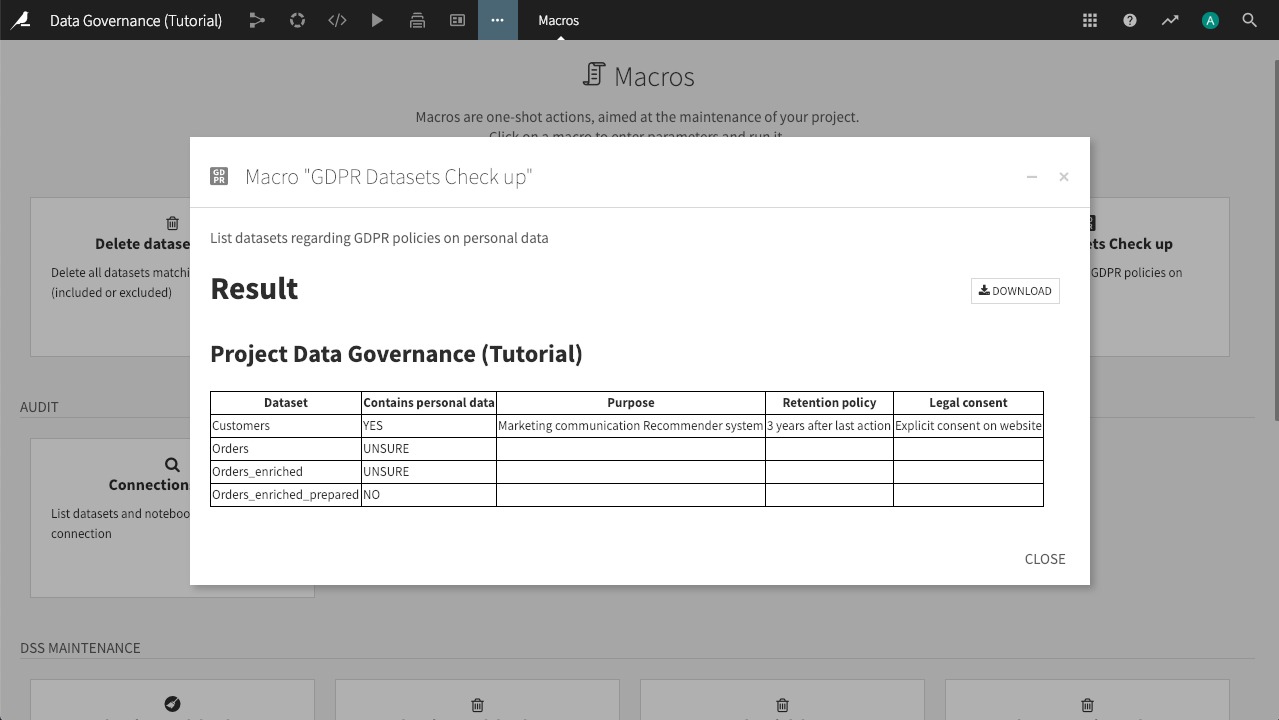
GDPR Datasets Check-up¶
Open the GDPR Datasets Check-up macro.
Deselect Only UNSURE
Click Run Macro.
This action builds a list of all the datasets in the project (or all projects, if we select that in the macro dialog), and allows you to quickly scan the list to see if there is missing information; for example, datasets that are in an UNSURE state, or datasets that contain personal data, but do not have a listed purpose, retention policy, or basis for legal consent.
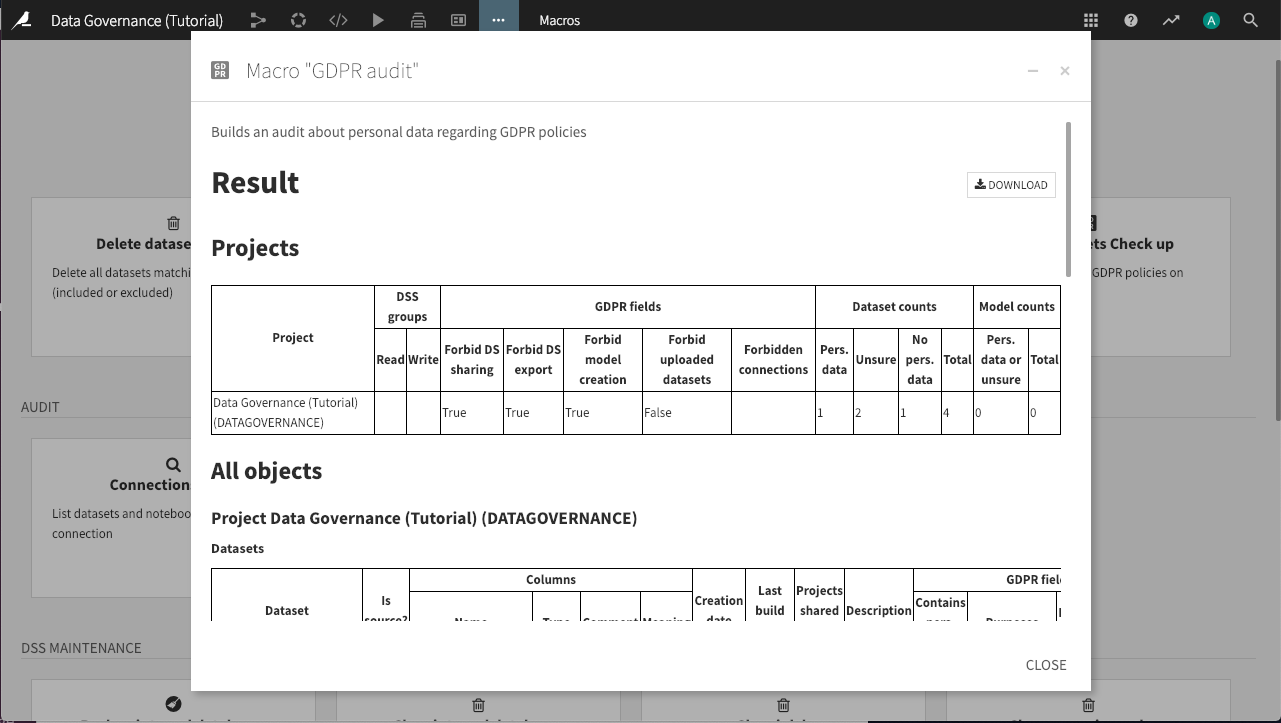
GDPR audit¶
Open the GDPR audit macro.
Click Run Macro.
This action builds an audit trail of the personal data policies applying to each object within the project (or all projects, if we select that in the macro dialog). It has greater detail than the datasets check-up report, and helps you to identify potential problem areas in your projects and across the Dataiku DSS instance.
What’s Next¶
Congratulations! You’ve taken your first steps towards understanding proper data governance and can begin to apply it in your own organization.