Concept: Introduction to Natural Language Processing¶
The Goal of NLP¶
Human language has always been around us, but we have only recently developed sophisticated methods to process it. This has given rise to the field of computer science called natural language processing, or NLP.
Note
The goal of NLP is to automatically process, analyze, interpret, and generate speech and text.
As more data that depicts human language has become available, the field of Natural Language Processing within the machine learning ecosystem has grown.

NLP use cases can be reduced to more than one type of machine learning task:
At times, it might be a simple classification task. Is this email spam or not? Is the customer’s review positive or negative?
It might resemble an unsupervised clustering problem. What are the main topics within this corpus of documents?
Or, it could be a complex prediction task. What is the next word the user is going to type?
NLP is one of the most challenging domains of machine learning. Human language is extraordinarily complex. Consider that the same sequence of words can have the exact opposite meaning if spoken sarcastically. How can a computer understand this subtlety? Human language data does not resemble the orderly rows and columns you might find in a time series, for example. Instead, human language is unstructured and messy.
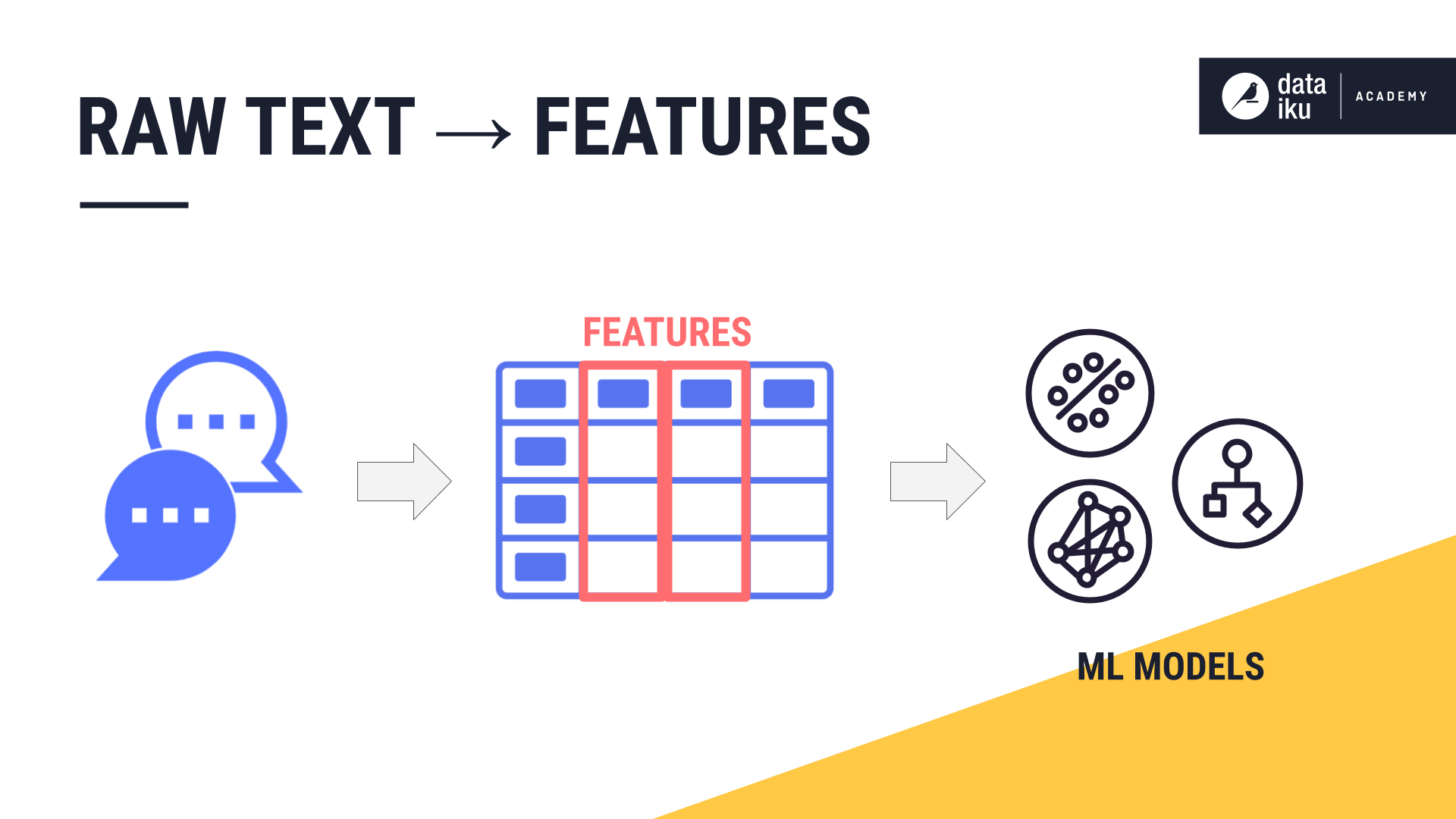
It is the features in the training data that make machine learning possible. The challenge of NLP is turning raw text into features that a machine learning algorithm can process and search for patterns.
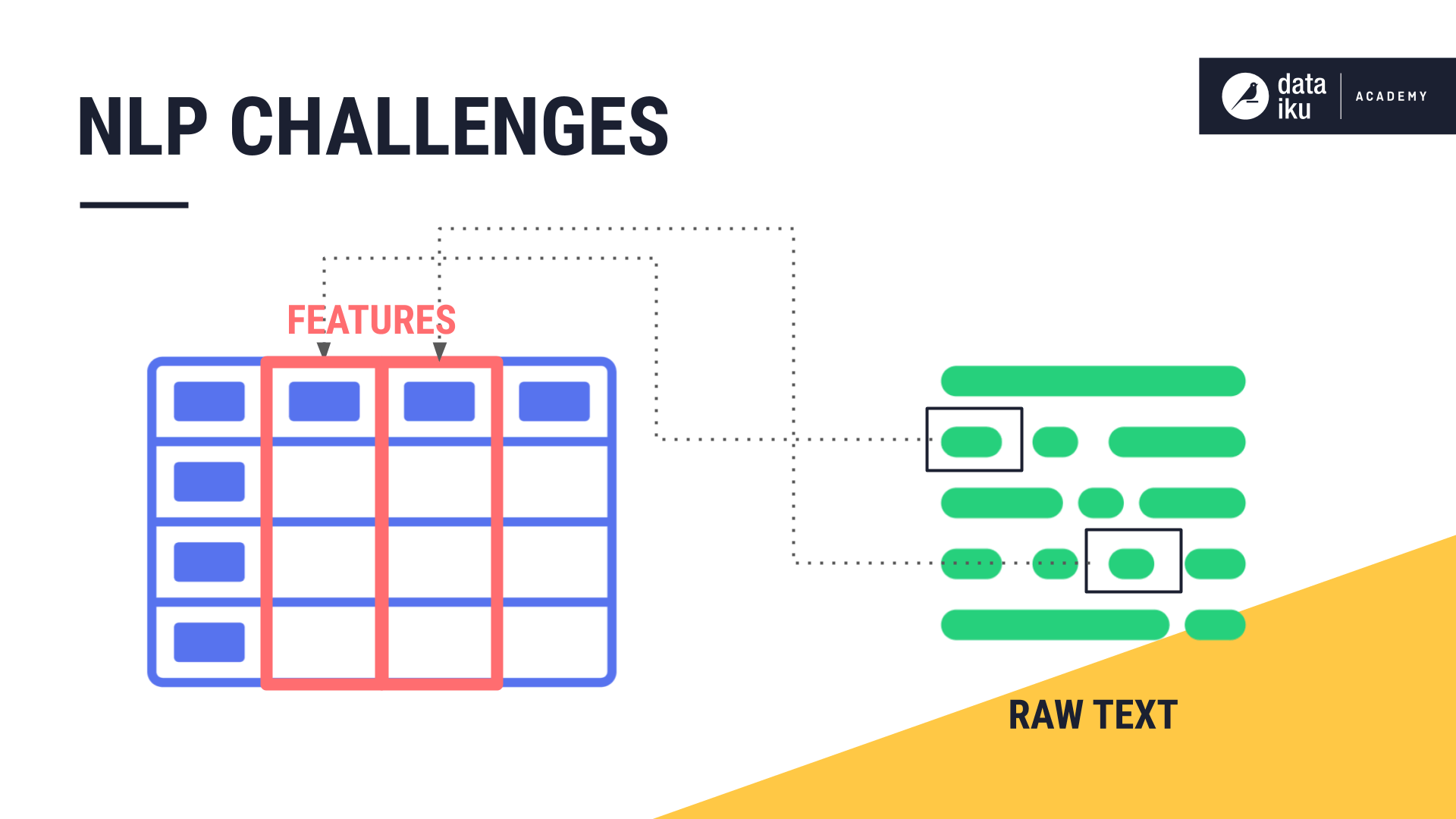
The Bag of Words Approach¶
Recall how Dataiku DSS handles categorical features, such as color. We also faced the problem of turning text into a numeric format an algorithm can understand. Strategies like one-hot encoding allow us to numerically represent categorical classes. With natural language, the approach is similar.
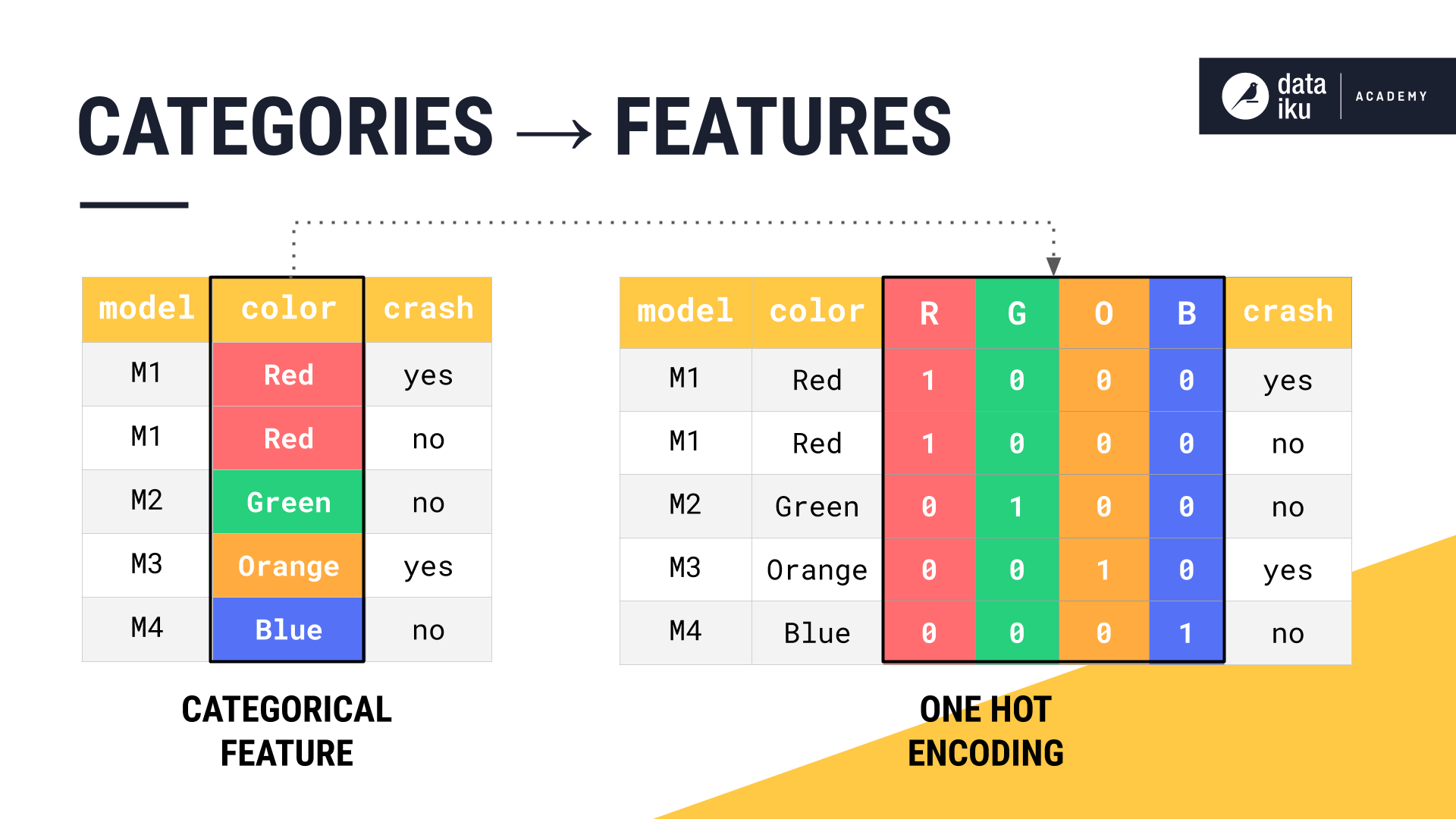
We can consider natural language as a collection of categorical features, where each word is a category of its own. Once that is complete, we can start counting words in clever ways to build our features. For some use cases, treating the text as a bag of words, and just counting the words in the bag, may be all that is needed.
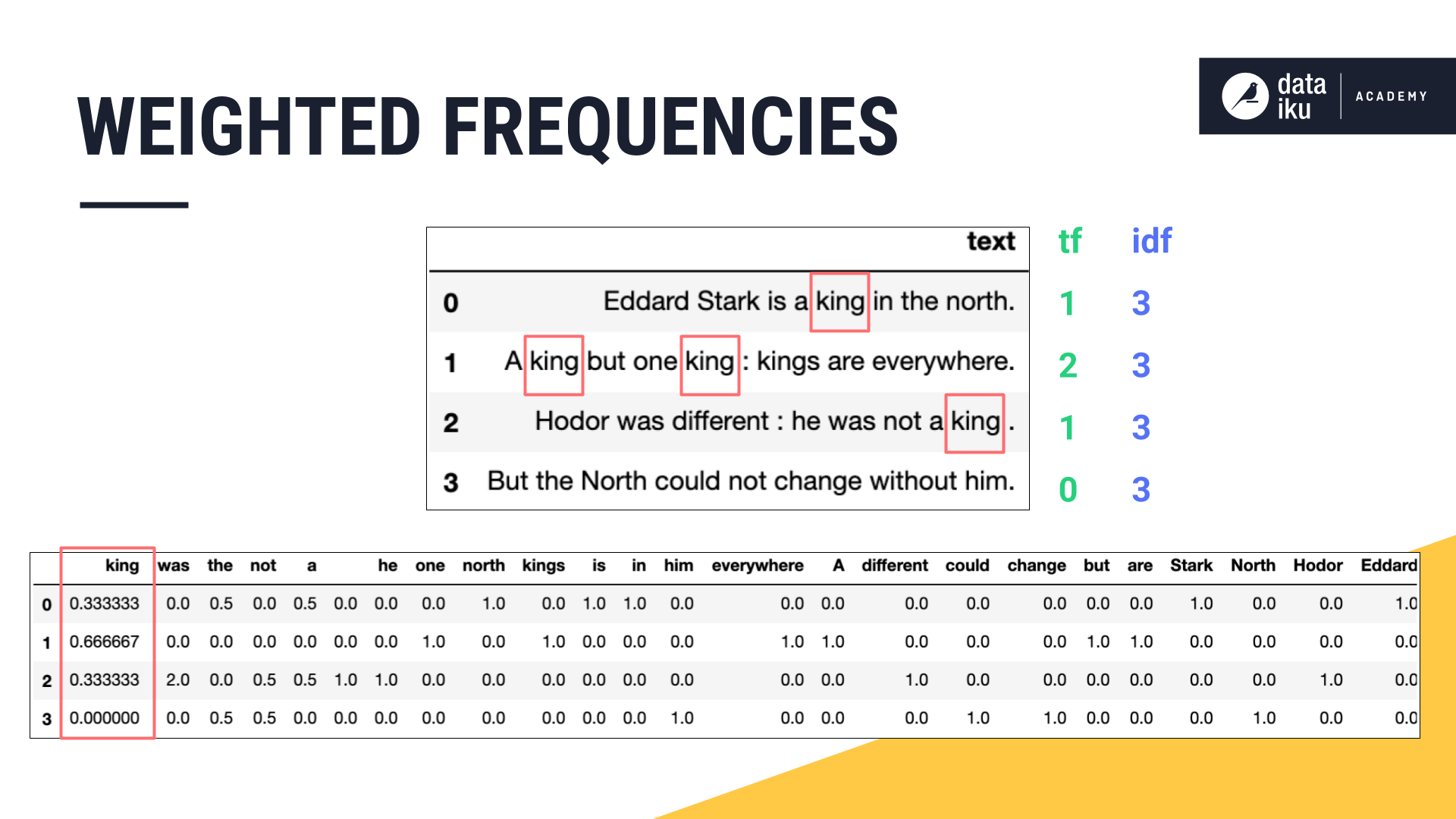
In this example, the word “king”, appears once in the first sentence, twice in the second, once in the third, and none in the fourth.

In other cases, we may see better performance if our features represent not just the frequency of a word, but that frequency weighted by how common it is for that word to appear. This method is known as term frequency - inverse document frequency, or TF-IDF.
In other cases, we may want to not only count individual words, but also group every two, or even three words as a single unit.
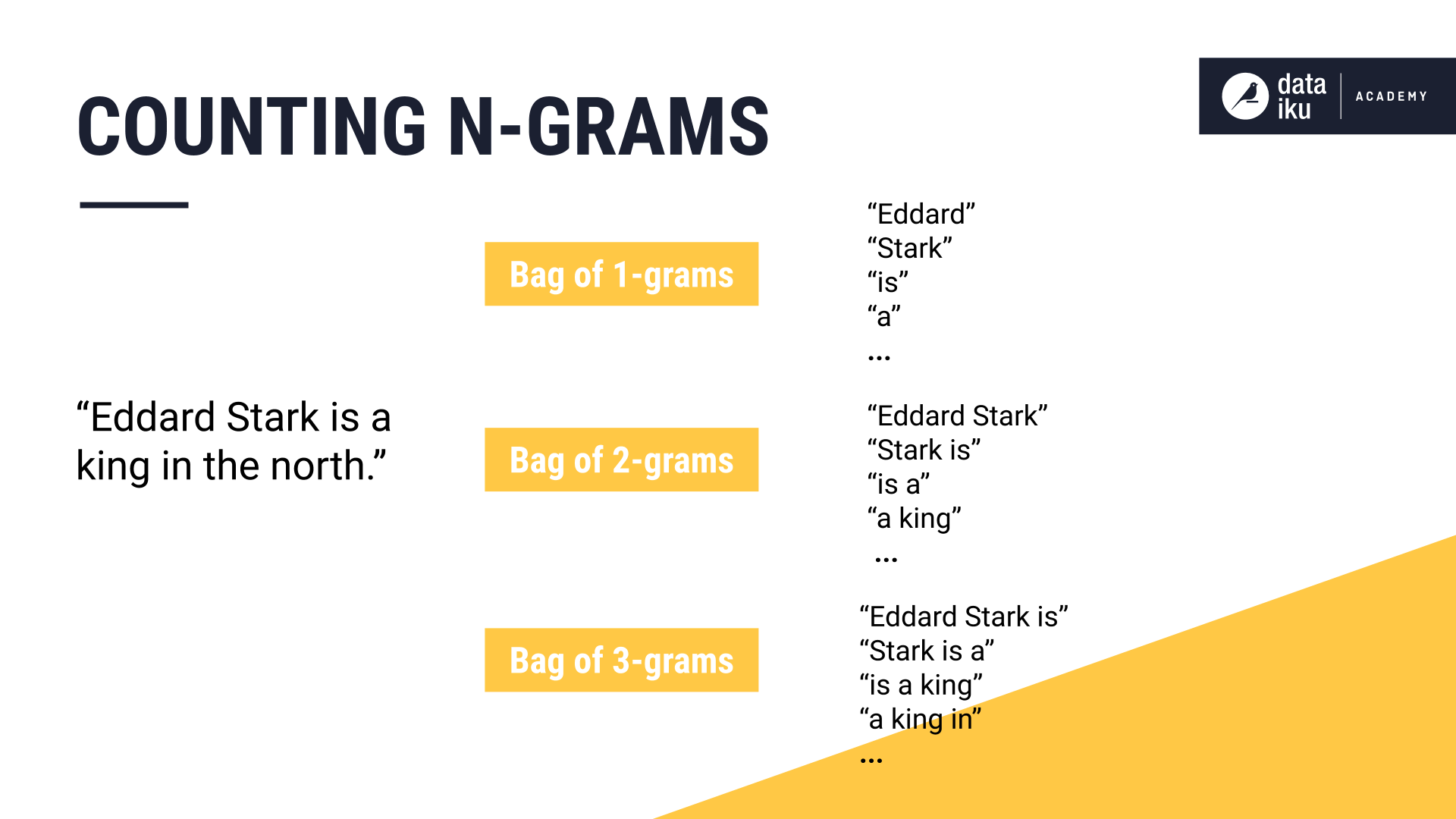
With all of these techniques, the underlying goal is the same: develop ways to transform raw text into numeric features that can be understood by machine learning algorithms.
What’s next?¶
For each of these approaches, you can probably already anticipate problems we will face.
Forge ahead to see how we deal with them in Dataiku DSS!