Distribution Spatial Footprint¶
Overview¶
Business Case¶
Distribution spatial footprint analysis is a powerful way to optimize retail networks depending on customers, competition, and distribution centers locations: this optimization is particularly critical for retailers.
Fueled with the right data, it can generate up to 20% in sales increase. Achieving these results relies on both global and local network optimizations, for which several use cases can be implemented such as opening/closing/relocating stores, finding the best places for new distribution centers, optimizing marketing campaigns based on local networks specificity etc.
A fundamental aspect of this solution is the computation of isochrone areas in order to enrich the input data for geospatial analysis. Isochrone areas are a type of catchment area which represents the area from which a location is reachable by someone within a given amount of time, using a particular mode of transportation.
The solution consists of a data pipeline that computes isochrones areas, further enriches the input data using these computed areas, and in doing so opens up a wide range of geospatial analyses. Analysts can input their own data and surface the outputs in a dashboard or interactive WebApp in order to analyze their organization’s own distribution networks. Data Scientists should use this solution as an initial building block to develop advanced analytics / support decision making. Roll-out and customization services can be offered on demand.
Technical Requirements¶
Warning
It is strongly recommended to read the project wiki before using this solution as it further explains many of the parameters, requirements, and deliverables throughout the solution.
To leverage this solution, you must meet the following requirements:
Have access to a DSS 9.0 instance
An API key for either Openrouteservice or Here
Additional APIs can be added upon request of customization services.
The following plugins needs to be installed:
Distribution Footprint Webapp (Download
here)To install this plugin, select Add Plugin > Upload and select the zip file. You will be asked to create a python 3.6 environment for the plugin.
Note: This plugin is required for the WebApp but is not necessary for the project, Dataiku App, and Dashboards to run.
An Instance Admin will also need to create the python code env
solution_distribution-spatial-footprintThe code environment can be imported directly as a zip file (Download
here) and installed by selecting Update in the code env settings.Alternatively, a python code environment can be created from scratch with the following required packages:
openrouteservice==2.3.3
folium==0.12.1
geopy==2.1.0
geopandas==0.8.2
Shapely==1.7.1
Flask==1.1.2
flexpolyline==0.1.0
scikit-learn==0.24.2
Note
If creating a new code environment, please be sure to use the name solution_distribution-spatial-footprint.
Installation¶
Once your instance has been prepared, you can install this solution in one of two ways:
On your Dataiku instance click + New Project > Sample Projects > Solutions > Distribution Spatial Footprint.
Download the .zip project file and upload it directly to your Dataiku instance as a new project.
Data Requirements¶
The Dataiku flow was initially built using publicly available data consisting of various French grocery store locations in the Burgundy region of France and fictional customer data. However, this project is meant to be used with your own data which can be uploaded using the Dataiku Application. Your input data should meet the general data requirements and will be renamed to the following datasets:
locations_dataset:
Dataset Granularity: 1 row = 1 single location.
Requirements:
The dataset should have at least 1 key (1 column or a column combination) allowing for the identification of each single location.
Two columns, exactly named latitude and longitude OR
A single address column, exactly named address
(Optional) customers_dataset:
Dataset Granularity: 1 row = 1 customer
Requirements:
The dataset should have a single column allowing to identify each customer named customer_id.
Two columns, exactly named latitude and longitude OR
A single address column, exactly named address
Workflow Overview¶
You can follow along with the sample project in the Dataiku gallery.
The project has the following high level steps:
Input your data and select your analysis parameters via the Dataiku Application
Ingest and pre-process the data to be compatible with geospatial analysis
Compute requested isochrones per location using the selected API service
(If customer data is provided) Identify and count the customers located within your distribution network isochrones
Visualize the overlapping isochrones in your distribution network as well as the locations of customers (if applicable) using pre-built dashboards
Interactively analyze your distribution spatial footprint using a pre-built WebApp
Walkthrough¶
Note
In addition to reading this document, it is recommended to read the wiki of the project before beginning in order to get a deeper technical understanding of how this solution was created, the different types of data enrichment available, longer explanations of solution specific vocabulary, and suggested future direction for the solution.
Plug and play with your own data and parameter choices¶
To begin, you will need to create a new instance of the Distribution Spatial Footprint Dataiku Application. This can be done by selecting the Dataiku Application from your instance home, and click Create App Instance.
Once the new instance has been created you can walk through the steps of the Application to add your data and select the analysis parameters to be run.
In the Inputs section of the Application, upload your distribution network dataset and, optionally, customer dataset. Refer to the Data Requirements section above for the specific formatting requirements for your data. In this section, you will also need to specify the identifier column(s) (i.e. the name of the column(s) containing location data) and how your locations are defined (i.e. latitude/longitude or addresses). It is important that you select the location definition as this will impact which preprocessing steps are run in the flow.
Once your data has been uploaded and parameters input, the data can be preprocessed by clicking the PREPROCESS button(s) in the Preprocessing section of the App.
After the data is done being preprocessed we can move on to the Isochrones section where you will be asked to select an API service. At this time you should copy your API key and paste it into the correct field of the App. Here you will also be able to select the mode of transportation to base your isochrones off of, the isochrones to be computed based on travel time from a central location, and any other isochrone attributes of interest. Please note that isochrone attributes may vary between API providers. Once everything looks good, click Build.
Optionally, if you uploaded a customer dataset, the final Customers section of the App is where you can select which specific isochrones you want to search for customers within.
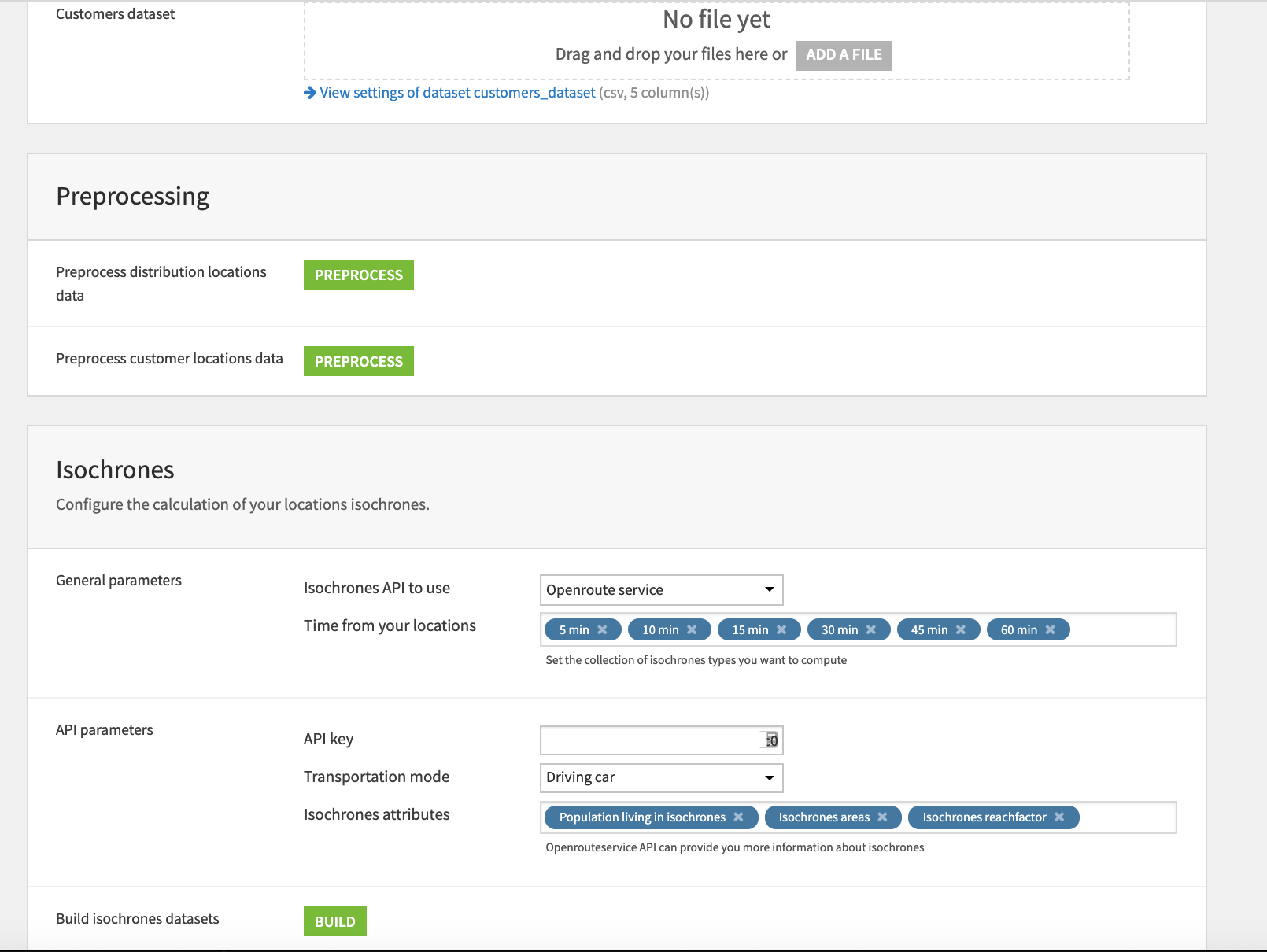
Once we’ve built all elements of our Dataiku Application you can either continue to the Project View to explore the generated datasets or go straight to the Dashboards and WebApp to visualize the data. If you’re mainly interested in the visual components of this pre-packaged solution, feel free to skip over the next section.
Under the Hood: What happens in the Dataiku Application’s underlying Flow?¶
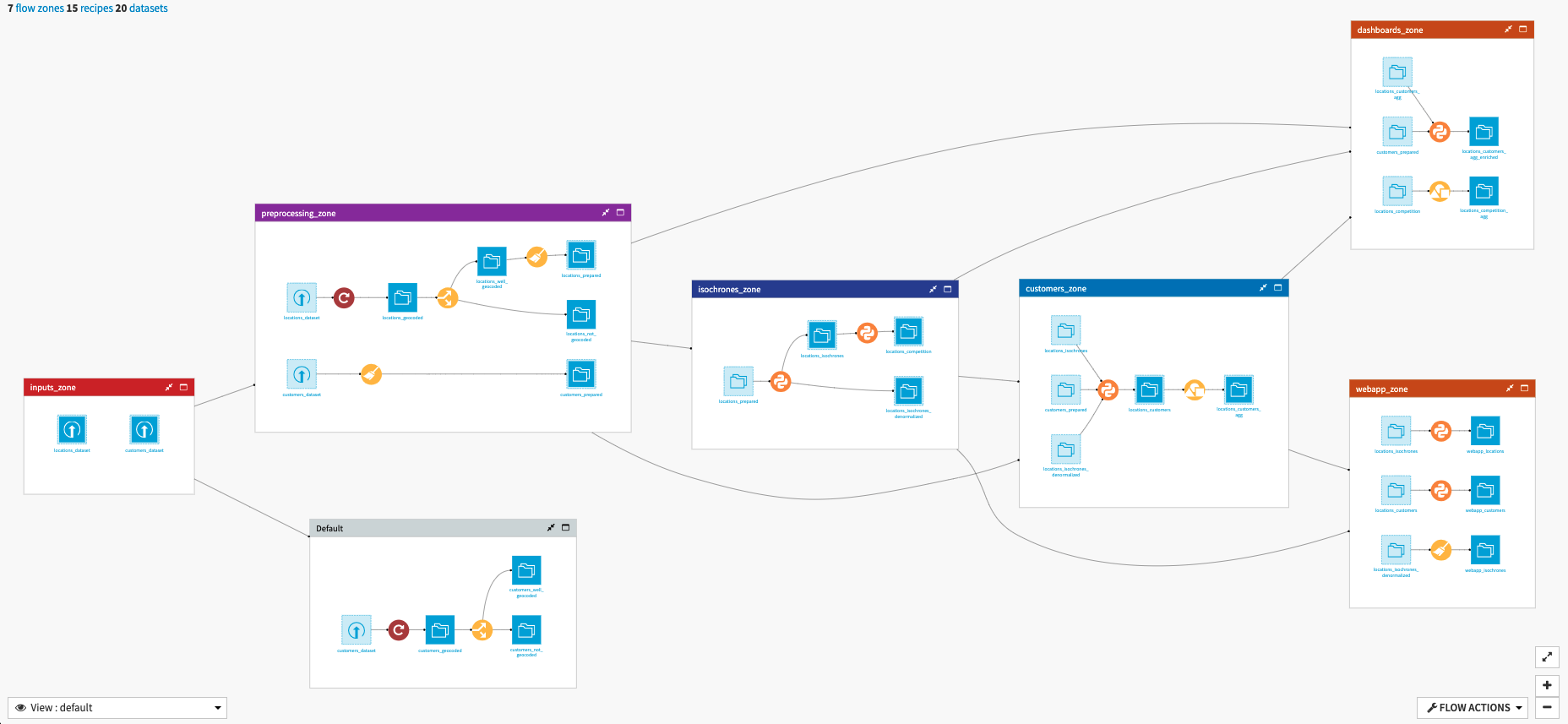
The Dataiku Application is built on top of a Dataiku Flow that has been optimized to accept input datasets and respond to your select parameters. Let’s quickly walk through the different flow zones to get an idea of how this was done.
The inputs_zone contains the uploaded dataset(s) for your distribution network (locations_dataset) and customer data (customers_dataset)
Elements of your data that are not needed in the preprocessing zone (i.e data that is already geocoded) are passed along to the Default flow zone.
The preprocessing_zone is dependent on the parameters you input to the Dataiku Application to define the type of your location identifiers.
If input locations were defined as latitude/logitude combinations, the data is directly passed to the final prepared datasets (locations_prepared and customers_prepared).
If input locations were defined as addresses, the Geocoder plugin is used to geocode the addresses. The resulting dataset(s) is split to separate out successfully geocoded locations (locations_well_geocoded and customers_well_geocoded). These datasets are passed to the final prepared datasets. Those that could not be geocoded are stored in datasets that will not be used in the remainder of the flow but can be investigated to understand why they could not be successfully geocoded.
Moving along to the isochrones_zone, we will find 3 datasets of interest that are created by sending each row of the locations_prepared to the selected isochrone API service to compute the requested isochrones.
locations_isochrones contains, for each location, the computed isochrone areas (in geojson format), and additional information about isochrones depending on the isochrone API service used.
locations_competition gives, for each location and each computed isochrone, all other locations from locations_prepared that are contained in the computed isochrone.
locations_isochrones_denormalized is created to support the visualization capabilities of the solution’s WebApp by materializing and identifying the relationship between locations and their isochrones.
If you provided customer data to the Dataiku Application, the customers_zone of the flow will:
Take customers_prepared, locations_isochrones and locations_isochrones_denormalized from the previous zones in order to locate all customers that exist within the previously computed isochrones, as well as the distance between the location and each customer in the isochrone. Additionally, all customer information is copied over to the resulting locations_customers dataset.
Finally, locations_customers_agg aggregates all customers across all isochrones for a location.
The dashboards_zone is dedicated to the isolation of all the datasets needed to build visualizations for the two project dashboards (see below for more details)
The webapp_zone isolates the datasets used by the solution WebApp and can largely be ignored unless you wish to make changes to the WebApp. Editing these datasets will break the WebApp.
Further explore your geospatial data with shareable visualizations¶
The data generated by the Distribution Spatial Footprint Application can be either viewed directly in the flow in raw format, or explored through a variety of rich visualizations pre-built into dashboards.
Beginning with the Locations competitors dashboard, 3 charts are provided that can be particularly useful in identifying cannibilization that is occuring between your own points of sale, or between your points of sale and your competitors’.
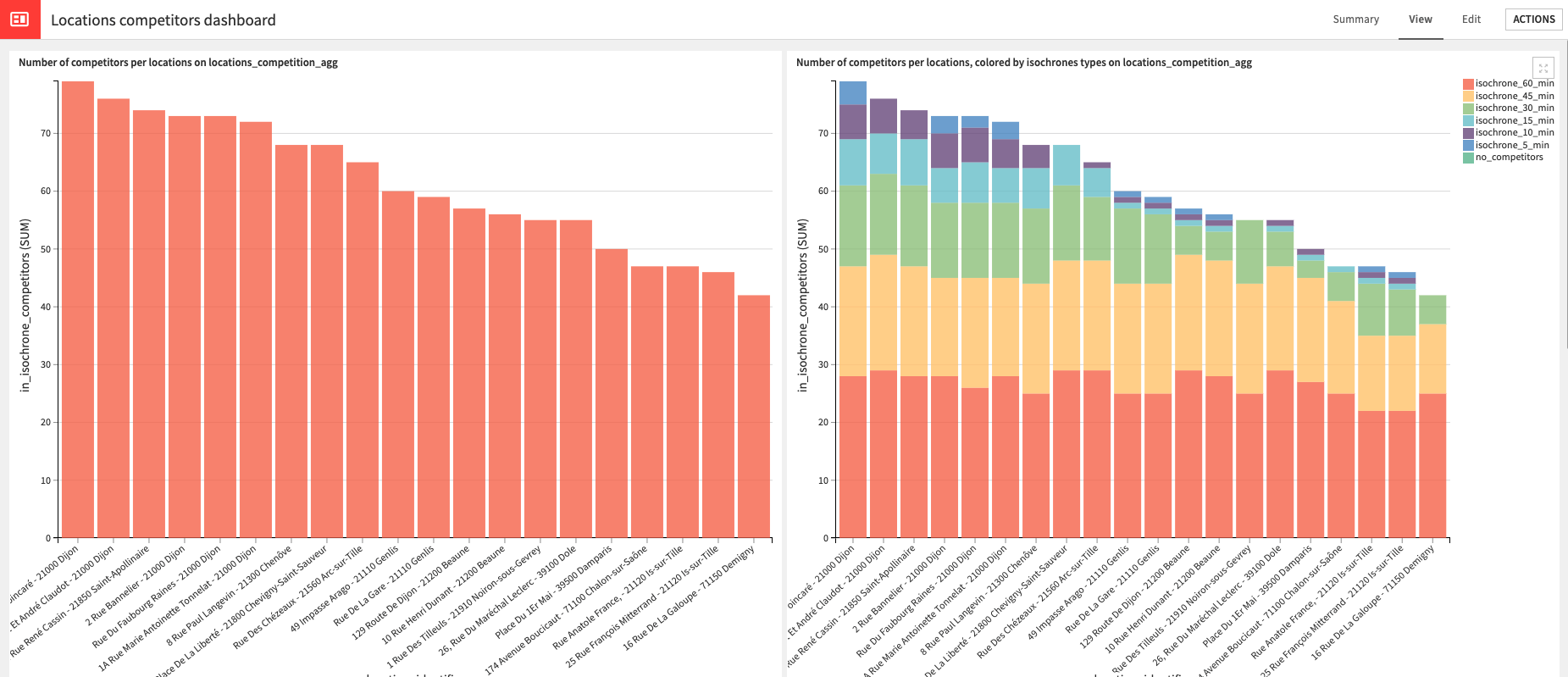
Within the Locations customers dashboard (if you provided customer data), you will find several pre-built charts which visualizes the spread of customers across all computed isochrones for all locations, a map representation of where your customers are located, and the number of your customers that are not contained in a computed isochrone. With this information, you can optimize marketing campaigns based on customer spread, optimize your distribution network for high potential areas, and identify new store locations to draw in new customers.
Expanding analysis with an interactive WebApp¶
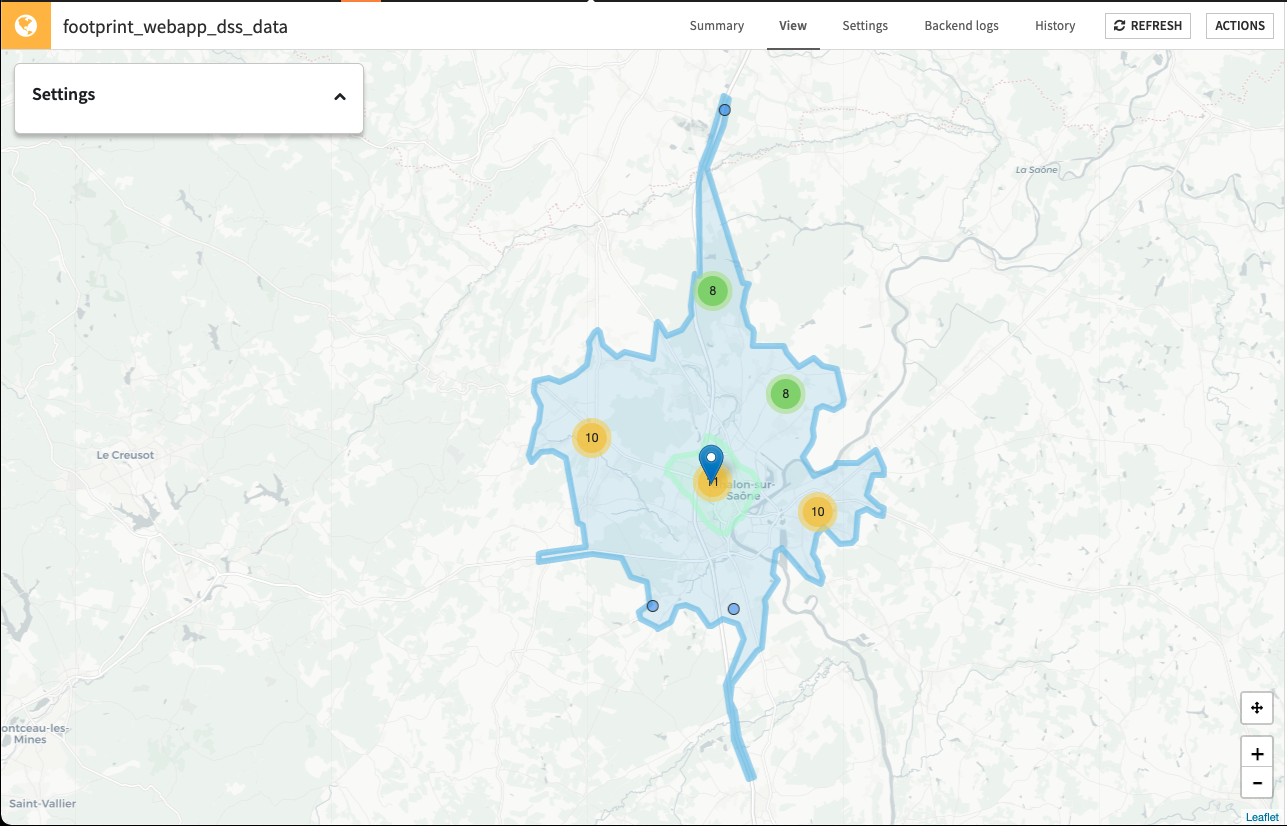
Although this solution already contains high value visualizations in the pre-built dashboards, the geospatial analytic capabilities are taken further by enabling you to conduct your own visual analysis using a pre-built WebApp for spatial analysis. The webapp has several fields that can be used to impact the real-time map visualization. Please note, at this time the WebApp does not save your previous searches and will restore to its default empty state each time you re-load it.
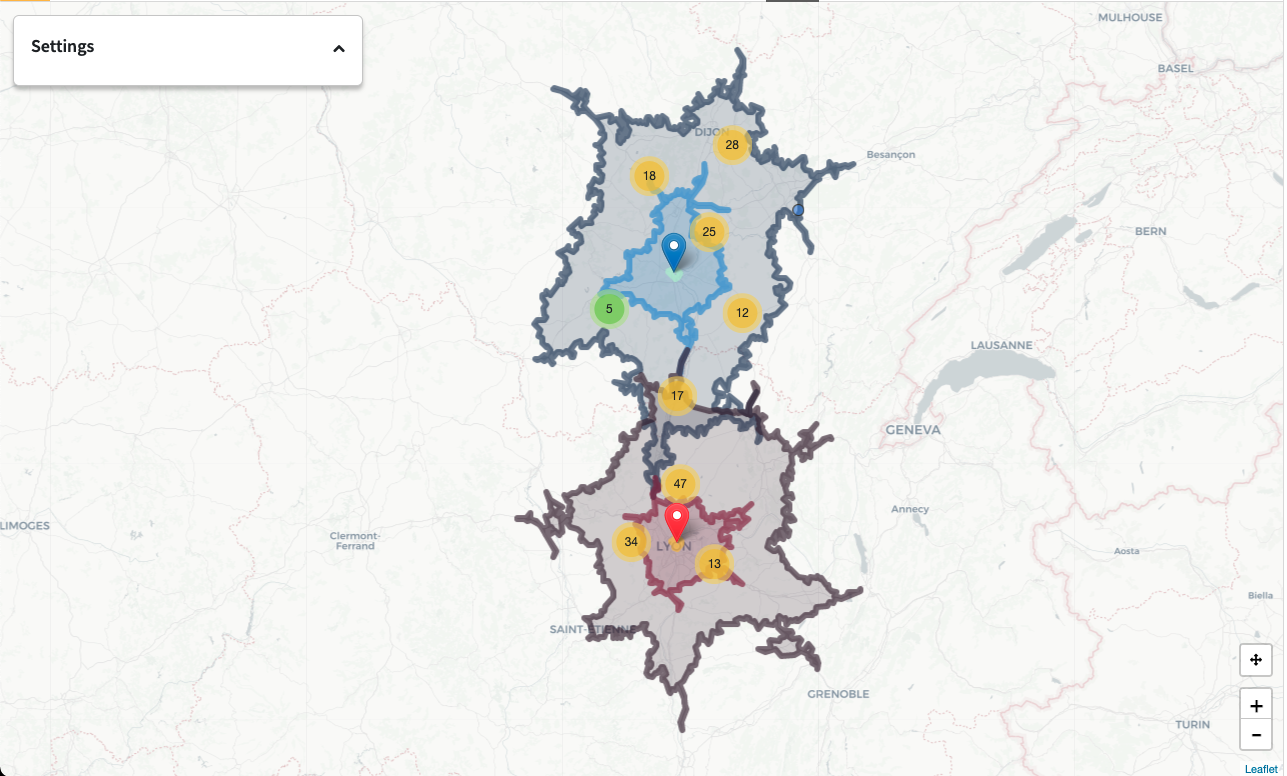
To begin, select the isochrones you would like to focus on from the full list of computed isochrones. The icon will change to reflect the trasnportation mode you previously selected in the Dataiku Application.
Within the Network Analysis section you can either individually add locations from your full list OR apply filters based on your location data (e.g. city, shop type, etc.).
The number of visualized points of sale out of the total sample of Points of Sale will update with the map. You can also increase or decrease the random sample size but please be wary that larger samples might cause the WebApp to slow down.
More information about a location can be displayed by clicking on the location pin
When displaying locations based on filter, clicking on the location pin will also allow you to unselect a specific location (i.e. remove it from displaying on the map) or focus on a specific location (i.e. remove all other locations from the map). This will push you into the From Location selection option. Switching back to From Filters will add all unselected locations back to the map
Similarly, clicking on an area within an isochrone will display a card with the isochrone information
The Comparitive Network Analysis section is turned on/off by clicking the slider button. Here you can add locations for comparison using the same fields as in the network analysis section.
Doing so has many benefits including identifying isochrone canibilization between points of sale or identifying strategic distribution points to support all your points of sale.
Sample size can also be independently increased/decreased here
Lastly, if customer data was provided, Customer Analysis can be turned on with the slider button. Customers cannot be added individually but can populate the map using filters based off of customer information in your customer dataset.
Only customers contained in the isochrones of a location will display on the map so a location must be selected.
Customer detail will increase by zooming and individual customer points can be clicked on to display the full card of customer information.
The sample size can be independently increased/decreased and the value you select will be a random sample of customers per location (e.g. sample size of 100 when 2 locations are displayed will result in 200 customers being displayed on the map)