The AI Lifecycle: Data Preparation¶
The goal of the Data Preparation phase is to wrangle and enrich data as input for model building.
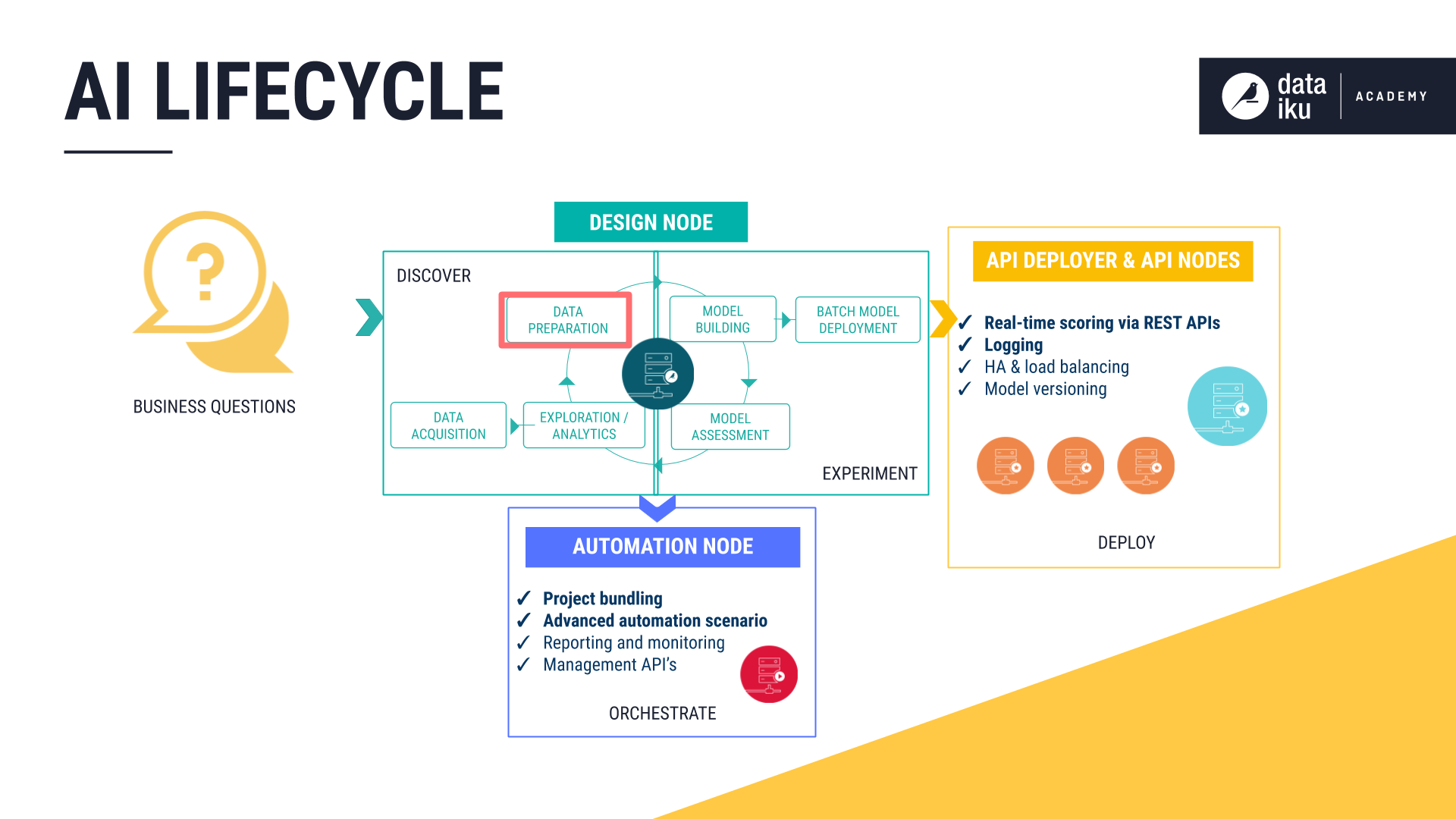
Regardless of the data’s underlying storage system, data preparation in DSS is accomplished in the same manner. It is done through running recipes.
A DSS recipe is a repeatable set of actions to perform on one or more input datasets, resulting in one or more output datasets. As is found throughout DSS, recipes are one function that can be created with a visual UI or code. The name “recipe” is meant to underscore that it is a series of steps designed to be repeated.
The following lessons focus on the different types of recipes (visual, code, and plugin) and how these recipes execute jobs.
Visual Recipes¶
DSS provides a standard set of visual recipes that provide a simple UI for accomplishing the most common data transformations. Filtering, sorting, splitting and joining datasets are just some of the operations that can be performed with a few clicks.
According to the visual grammar of DSS, yellow circles signify a visual recipe, where the center icon represents the particular transformation. For example, the icon of the Prepare recipe is a broom.
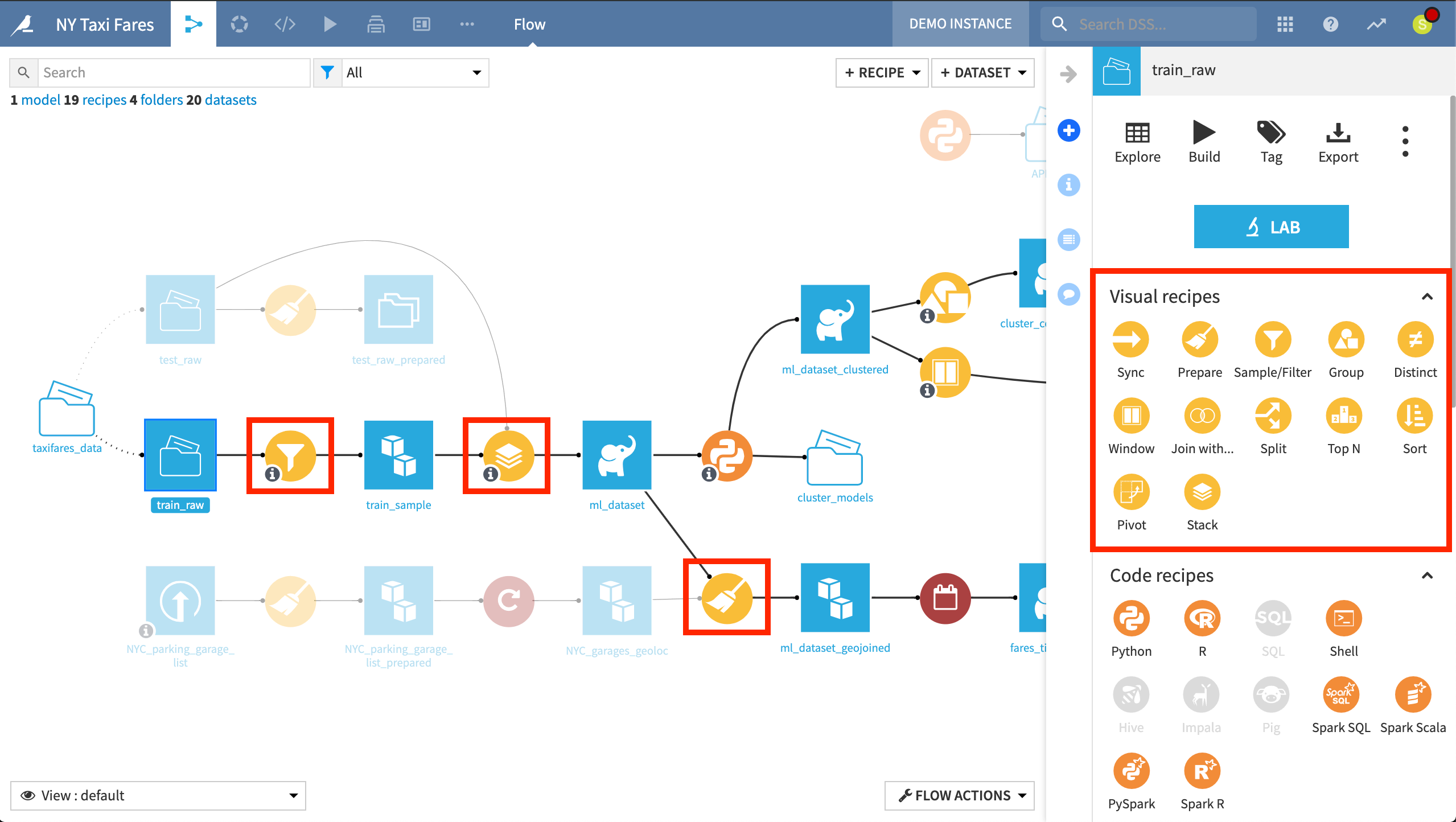
Visual recipes highlighted in this Flow include a Filter recipe to sample the raw training data, a Stack recipe to perform a union of the training sample and testing data, and a Prepare recipe to perform cleaning and enrichment steps.
Moreover, unlike many visual tools such as spreadsheets, visual recipes in DSS provide a recorded history of actions that can be repeated, copied, or edited at any time. The idea is to iteratively construct a workflow that can be run as needed, and avoid a conflict between the original dataset and the output version.
The Prepare recipe handles the bulk of the data cleaning and feature generation with the help of the processors library. Over 90 built-in visual processors make code-free data wrangling possible. These processors can be used to accomplish a huge range of tasks like rounding numbers, extracting regular expressions, concatenating or splitting columns, and much more. Users can also write Formulas in an Excel-like language for more customized operations. An alternative option is to write a custom Python function as a step within the Prepare recipe.
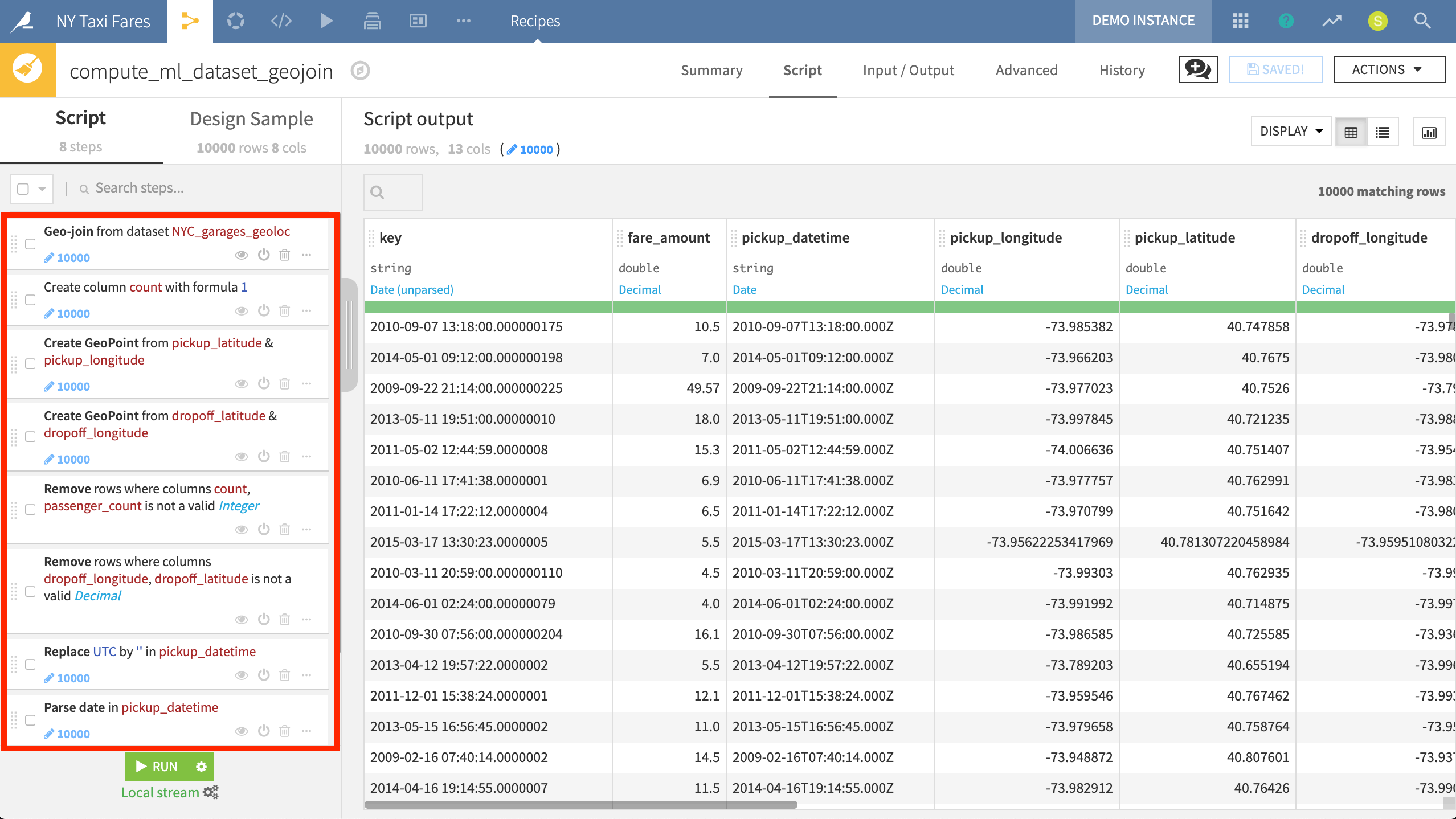
This Prepare recipe consists of 8 steps, including creating geo-points from geographic coordinates, removing rows under certain conditions, and parsing dates.
DSS will even automatically suggest transformations to a column based on its predicted meaning.
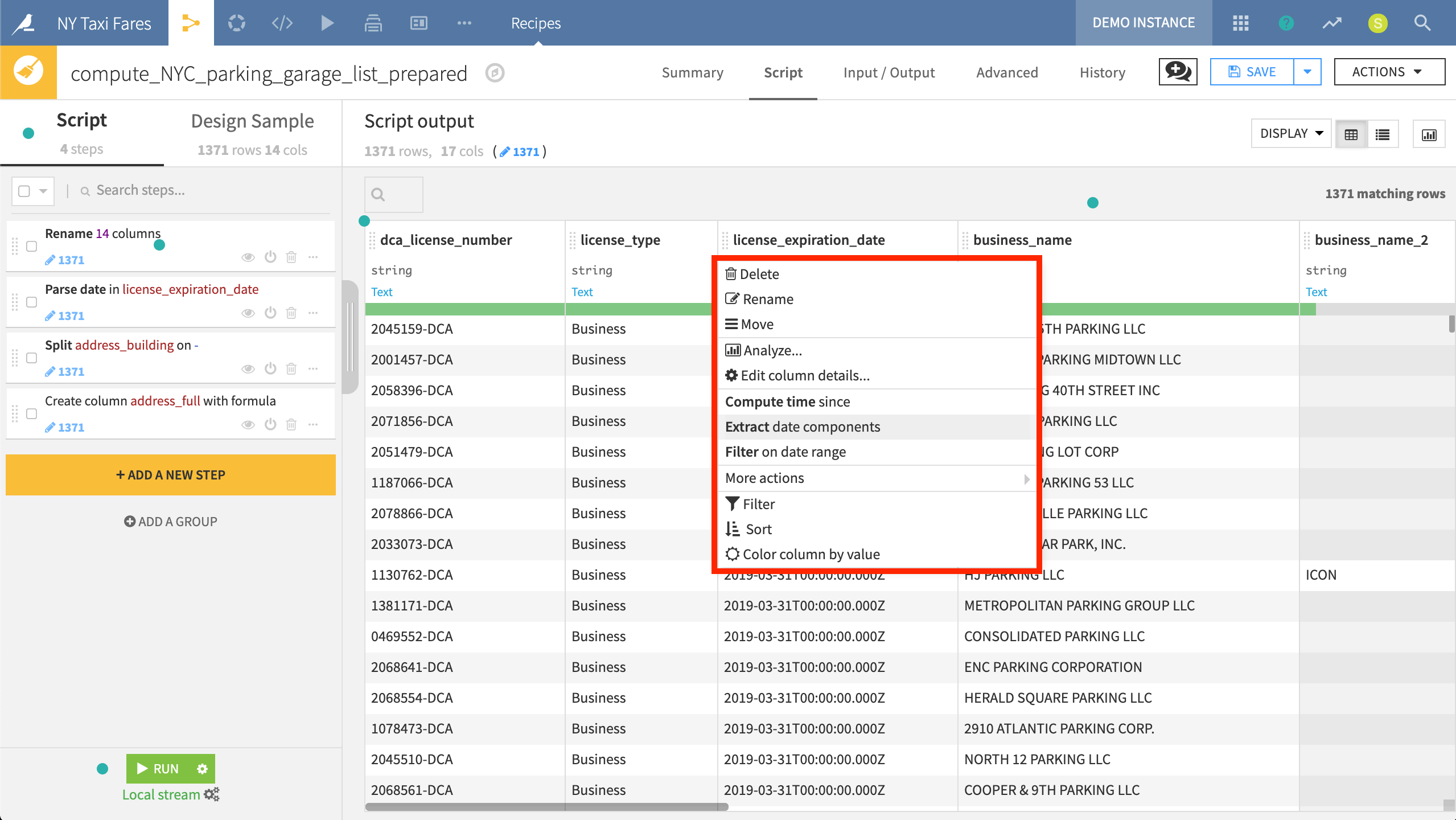
Here DSS suggests using the Extract date components processor because it recognizes the column meaning as a Date.
Code Recipes¶
In cases where the need is more customized than what a visual recipe can provide, or just according to the user’s preference, DSS allows users to code any recipe in a variety of languages. This code can be written in a Jupyter notebook or using any of the IDE integrations.
As shown above, code notebooks can be used for interactive design or debugging, but can be saved and deployed to the Flow as a recipe when ready for production. In the Flow, orange circles with the icon of the programming language represent code recipes.
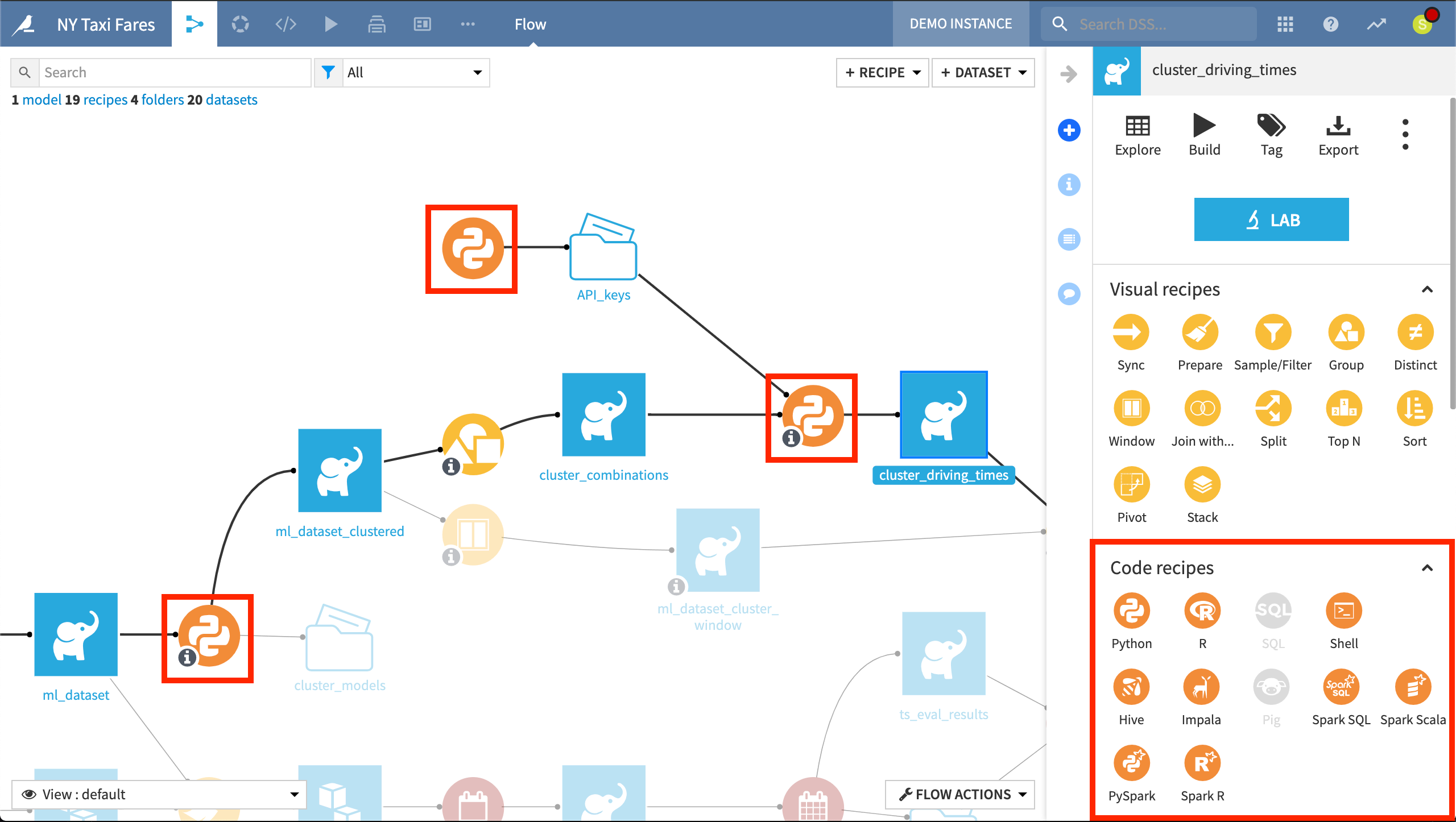
The project uses a Python recipe to compute driving times for every cluster combination. From an input of geographic coordinates of pickup and dropoff locations, this Python recipe produces an output including distance and travel time for every cluster combination.
Plugin Recipes¶
In addition to the standard library of visual recipes, users can also code their own visual recipes by creating a plugin. This option allows users to create reusable components that wrap additional functionality into a visual UI, thereby extending the capabilities of DSS to a wider audience. Users can also search the Plugin store for existing plugins shared by the community. Red circles in the Flow represent plugin recipes.
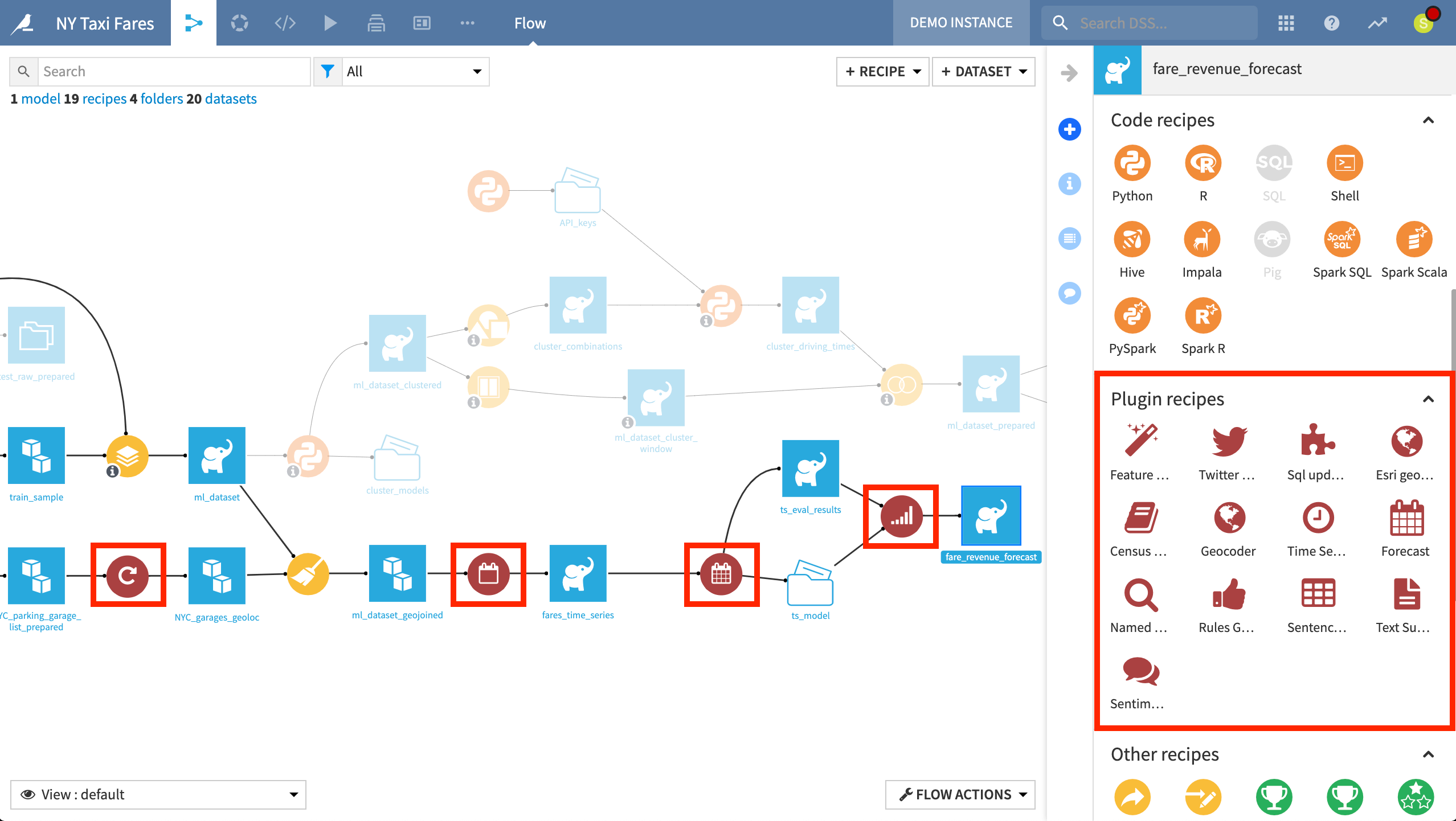
The three red circles to the right belong to the Forecast plugin. In three visual steps, it covers the full forecasting cycle of data cleaning, model training, and evaluation and prediction.
Job Execution¶
Actions in DSS, such as running a recipe (whether it may be visual, code or plugin) or training a model, generate a job. The flexible computation environment of DSS grants users control over how a job is executed.
Wherever possible, DSS pushes down the computation to the underlying location of the data. However, in addition to choosing the execution engine for a particular job, users can also control the composition of tasks within a job. This is especially important when managing long data pipelines, computationally-expensive operations, and/or the continuous arrival of new data.
Accordingly, before executing any job, users can choose between a range of different build strategies. For example, a non-recursive build runs only the current recipe. A “smart” rebuild only rebuilds out-of-date datasets. The most computationally-intensive option rebuilds all dependent datasets. Users can also prevent datasets from being rebuilt by write-protecting them.
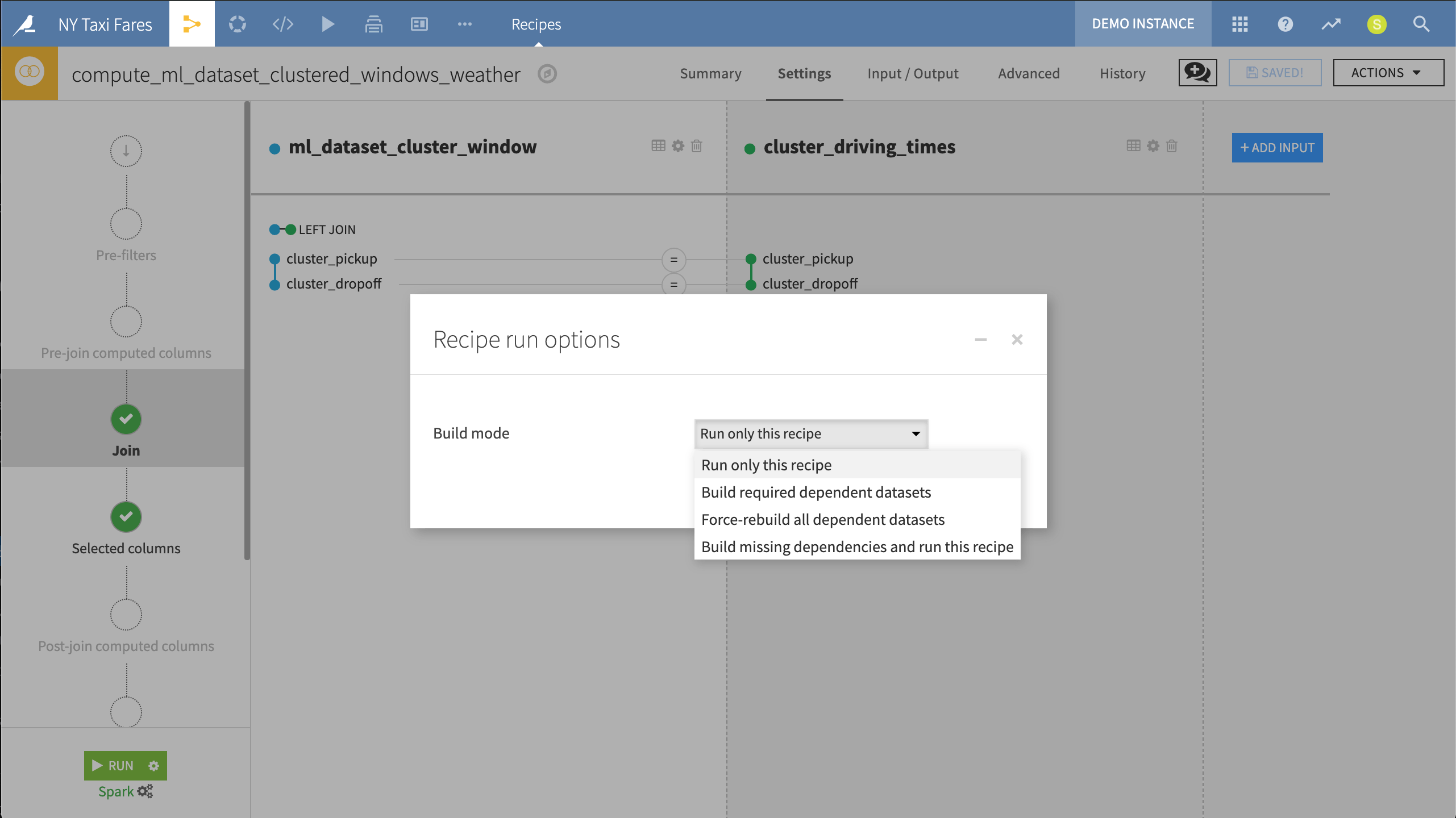
Before running this recipe, we can choose whether to run only this recipe or to recursively build dependent datasets that may be out of date.
The Jobs menu shows the status of all current and past jobs, including log files. Users can observe how long each activity in a job took to complete. When trying to optimize a Flow for production, this may be a useful place to start, as it can help identify bottlenecks and direct attention to parts of the Flow that could be refactored.
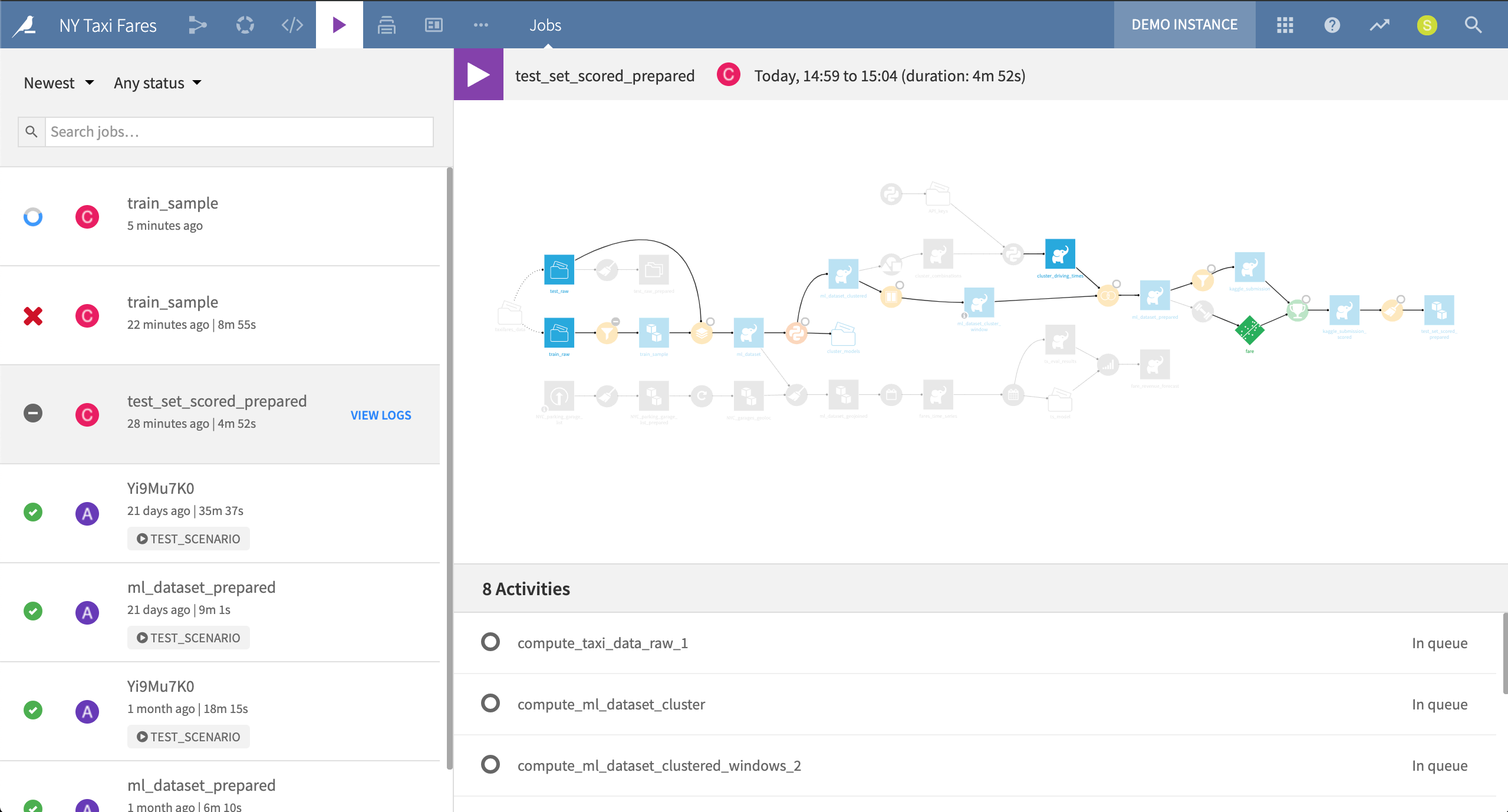
This current job in progress is rebuilding the final output dataset in the project. In this case, it needs to complete eight activities in order to do so.