Concept: The Challenges of Natural Language Processing (NLP)¶
In this lesson, we’ll look at some of the problems we might run into when using the bag of N-grams approach and ways to solve those problems. For each case, we’ll demonstrate the concept with a simple example.
For the following conceptual examples, we’ll draw on the four simple sentences in the image below.
Redundant Features¶
After dividing these four short sentences into N-grams, we find that some features are redundant. Should “North” with a capital “N” be treated as a different feature than “north” with a lowercase “n”? What about the singular “king” and the plural “kings”?

Without any pre-processing, our N-gram approach will consider them as separate features, but are they really conveying different information? Ideally, we want all of the information conveyed by a word encapsulated into one feature.
Sparse Features¶
You may also notice that this table of features is quite sparse. Most words, and so most features, are only present in one sentence. Only a few words like “king” are found in more than one sentence. This sparsity will make it difficult for an algorithm to find similarities between sentences as it searches for patterns.

High Dimensionality¶
Finally, the number of features of a dataset is called its dimensionality. A bag of N-grams approach generates a huge number of features. In this case, four short sentences generated 23 columns. Imagine how many columns a book would generate!

The more features you have, the more storage and memory you need to process them, but it also creates another challenge. The more features you have, the more possible combinations between features you will have, and the more data you’ll need to train a model that has an efficient learning process. That is why we often look to apply techniques that will reduce the dimensionality of the training data.
Text Cleaning Tools¶
To lessen the three problems of redundant features, sparsity in features, and high dimensionality, let’s look at three of the most basic and most valuable data cleaning techniques for NLP:
normalizing text,
removing stopwords,
and stemming.
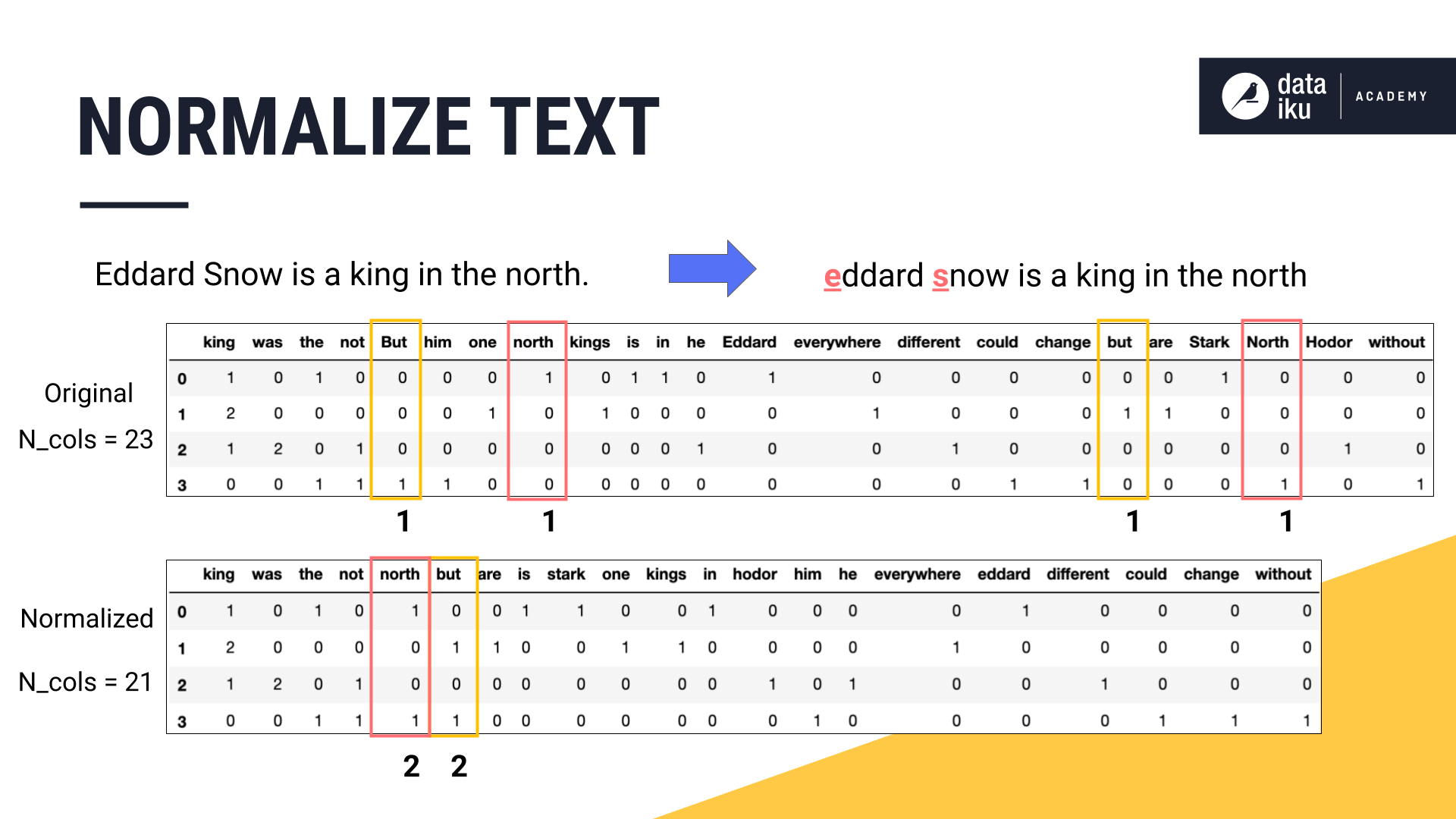
Normalizing Text¶
Text normalization is about transforming text into a standard format. This involves a number of steps, such as:
converting all characters to the same case,
removing punctuation and special characters,
and removing diacritical accent marks.

Applying normalization to our example allowed us to eliminate two columns–the duplicate versions of “north” and “but”–without losing any valuable information. Combining the title case and lowercase variants also has the effect of reducing sparsity, since these features are now found across more sentences.
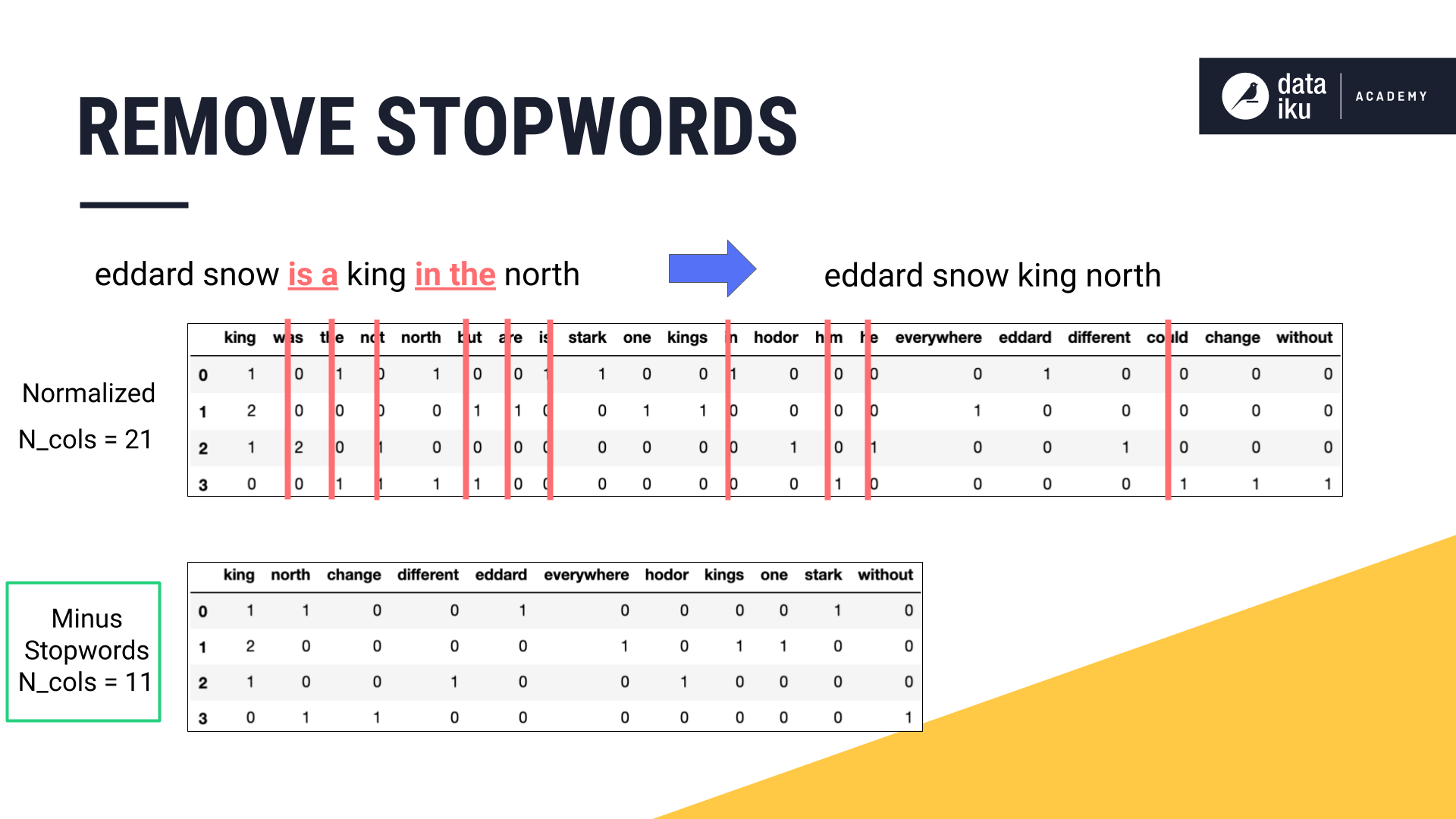
Removing Stopwords¶
Next, you might notice that many of the features are very common words–like “the”, “is”, and “in”. In NLP, the collection of these very common words is called stopwords.
Removing words like these, that do not contain much information by themselves, from the training data is a good idea.
In this example, we’ve reduced the dataset from 21 columns to 11 columns just by normalizing the text.
Stemming¶
We’ve made good progress in reducing the dimensionality of the training data, but there is more we can do. Note that the singular “king” and the plural “kings” remain as separate features in the image above despite containing nearly the same information.
We can apply another pre-processing technique called stemming to reduce words to their “word stem”. For example, words like “assignee”, “assignment”, and “assigning” all share the same word stem– “assign”. By reducing words to their word stem, we can collect more information in a single feature.
Applying stemming to our four sentences reduces the plural “kings” to its singular form “king”. We have reduced another feature in the dataset.
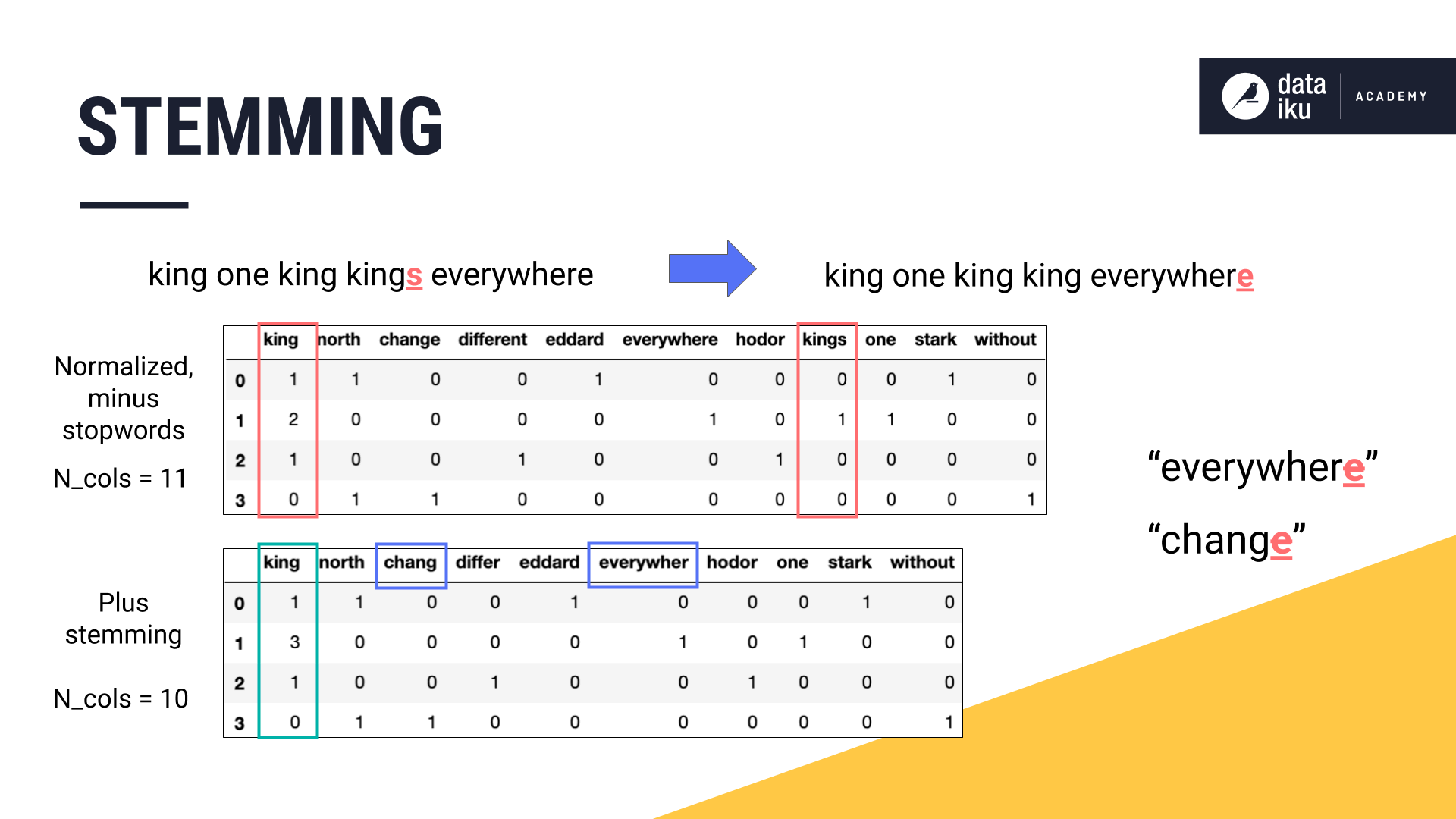
However, this operation was not without consequence. We cannot expect stemming to be perfect. Some features were damaged. In this case, the words “everywhere” and “change” both lost their last “e”. In another course, we’ll discuss how another technique called lemmatization can correct this problem by returning a word to its dictionary form.
What’s Next?¶
Thus far, we have seen three problems linked to the bag of words approach and introduced three techniques for improving the quality of features. Next, we’ll walk through how to implement these techniques in Dataiku DSS.
Then, we’ll start building models!