Hands-On: Partitioned Models¶
Let’s build a partitioned model to predict flight delays for two subgroups of a transportation dataset.
Note
A partitioned dataset is a dataset made up of different subgroups of the data that share the same schema. A partitioned model is created from a partitioned dataset. Partitioned models can sometimes lead to better predictions when relevant predictors for a target variable are different across subgroups (or partitions) of the dataset.
Let’s Get Started!¶
In this tutorial, you will create a partitioned machine learning model to predict how much time (minutes) a given flight will be delayed based on flight characteristics. The prediction type is “Regression”.
Objectives for this tutorial:
First, we’ll create a model based on the whole dataset.
Then, we’ll configure Dataiku to create another modeling session based on the partitions of the dataset.
Finally, we’ll compare the two results.
Your partitioned model will be based on two subgroups of the dataset, California, and Florida. Partitioning the model by the state could help improve model performance if the reasons for arrival delay are different for the two geographical locations.
Prerequisites¶
This tutorial assumes that you have completed “Basics 101-103”, and “Machine Learning Basics” prior to beginning this one.
Create Your Project¶
From the Dataiku homepage, click +New Project > DSS Tutorials > ML Practitioner > Partitioned Models (Tutorial).
Click on Go to Flow.
Explore the Datasets¶
In the Flow, you can see the folder, flights_folder. The folder contains two directories, florida and california.
The Flow contains one dataset, flights_data_partitioned. The rows of this dataset have already been partitioned by the flight destination state. Let’s explore this dataset.
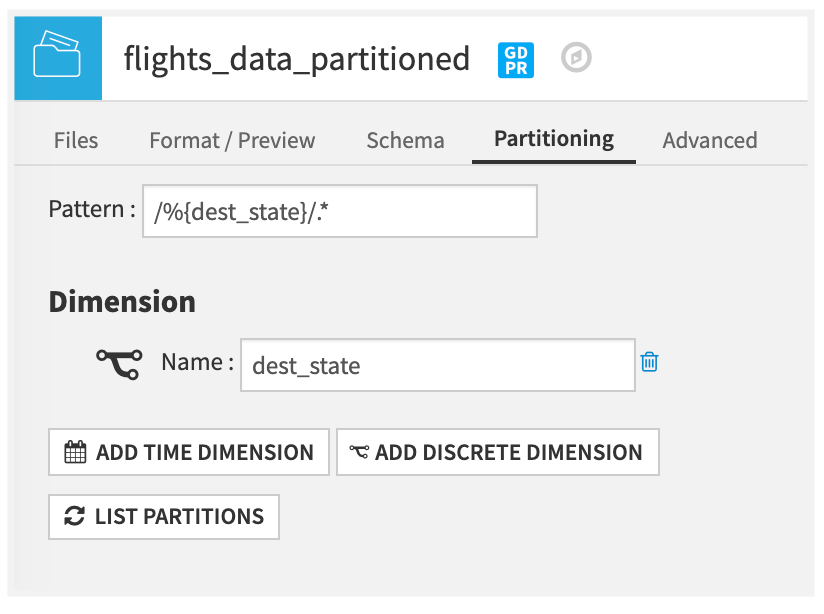
Open the dataset, and then view the Settings to discover how the partitions were created. In the Partitioning tab, note that the partitions were created using the pattern /%{dest_state}/.* and dimension dest_state (destination state). The destination state is the column that contains the values for the US destination state for the flight.
Build the Initial Model¶
Let’s create an initial visual machine learning (prediction) model using the dataset.
In the Flow, select the flights_data_partitioned dataset and click on the Lab button.
Click New Analysis and give the visual analysis a descriptive name like
Analyze flight delays by subgroup.Click Create Analysis.
Follow these steps to build the initial model:
Click on the Models tab and then click Create first model, then Prediction.
Since we want to predict “flight delay”, choose arr_delay as the target variable.
Click Quick Prototypes.
Click Create, then click Train.
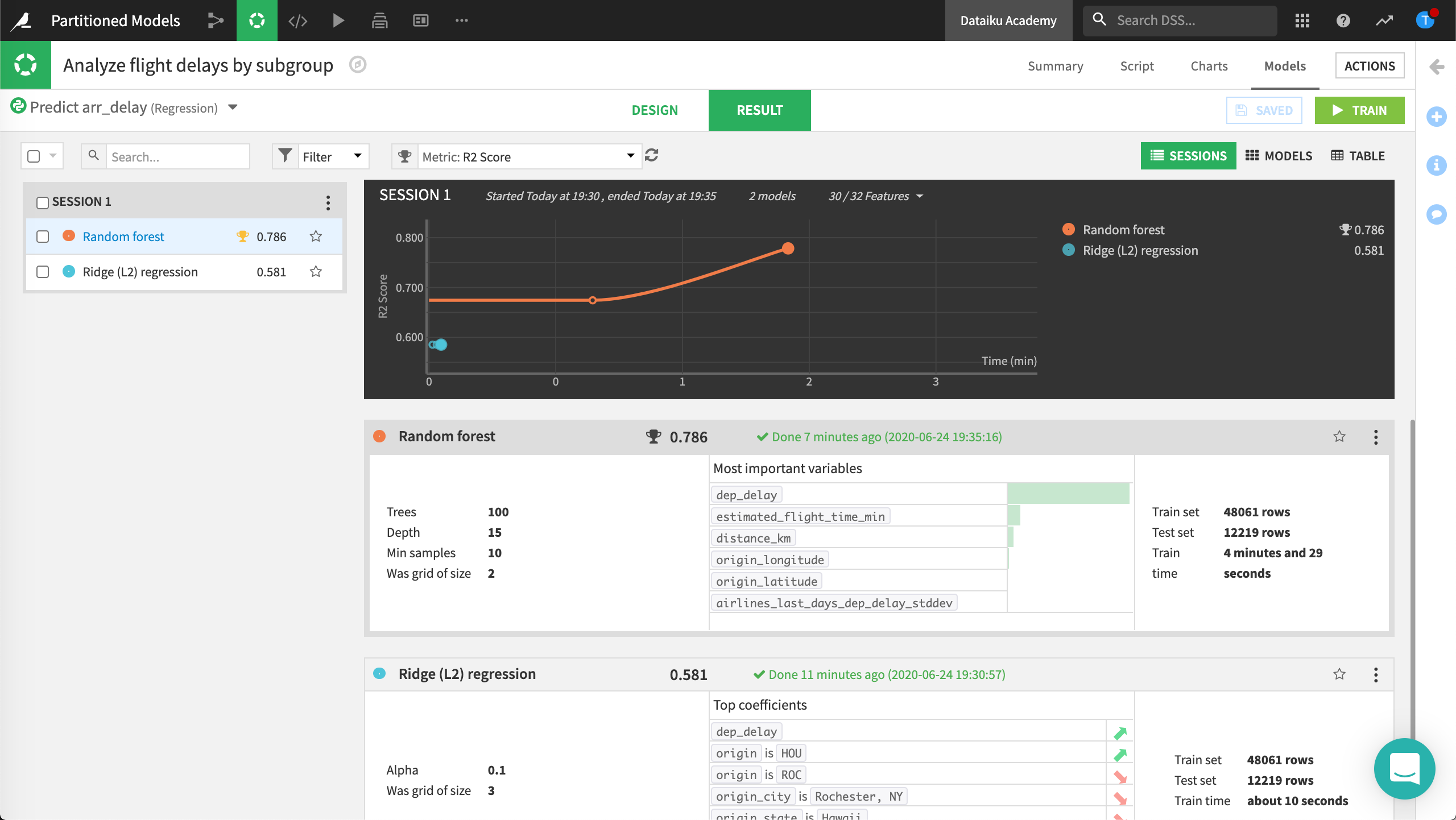
Dataiku presents a summary of the results of this modeling session.
Build the Partitioned Model¶
Because we created our visual machine learning (prediction) model on a partitioned dataset, we have the option to train partitioned models. To train a partitioned model:
Navigate to the Design page of the modeling session.
In the Target panel, enable the Partitioning option.
Select All partitions of the dataset to use when training in the Analysis.
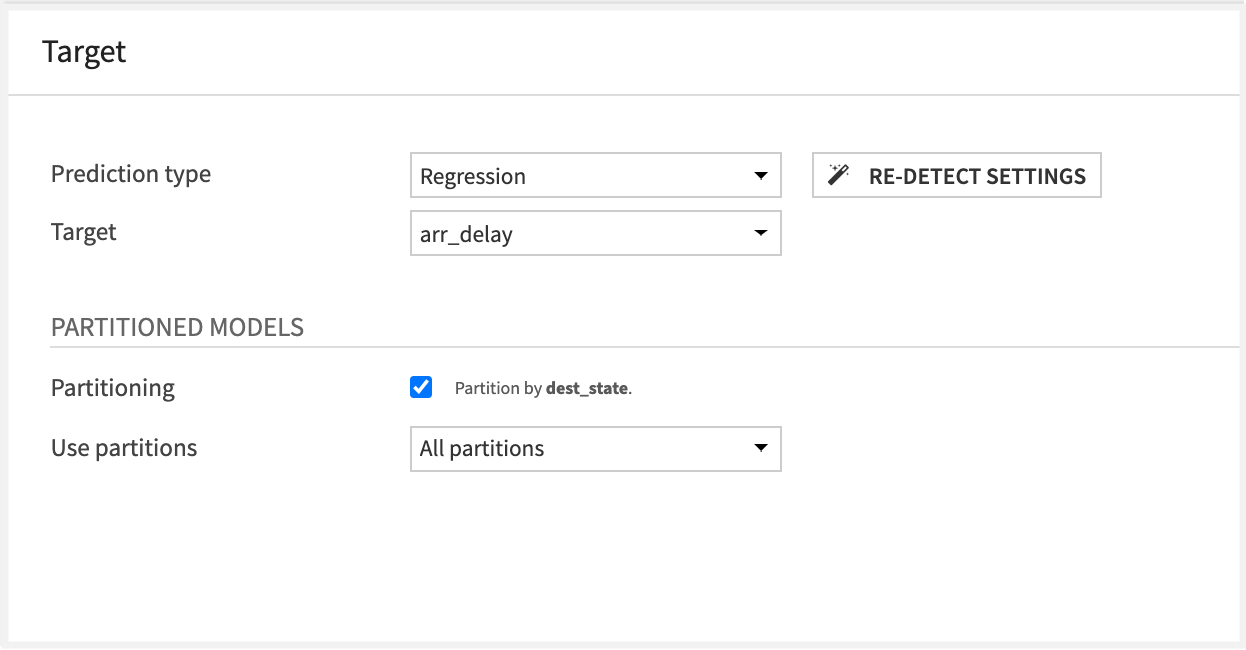
Save your work, then click Train.
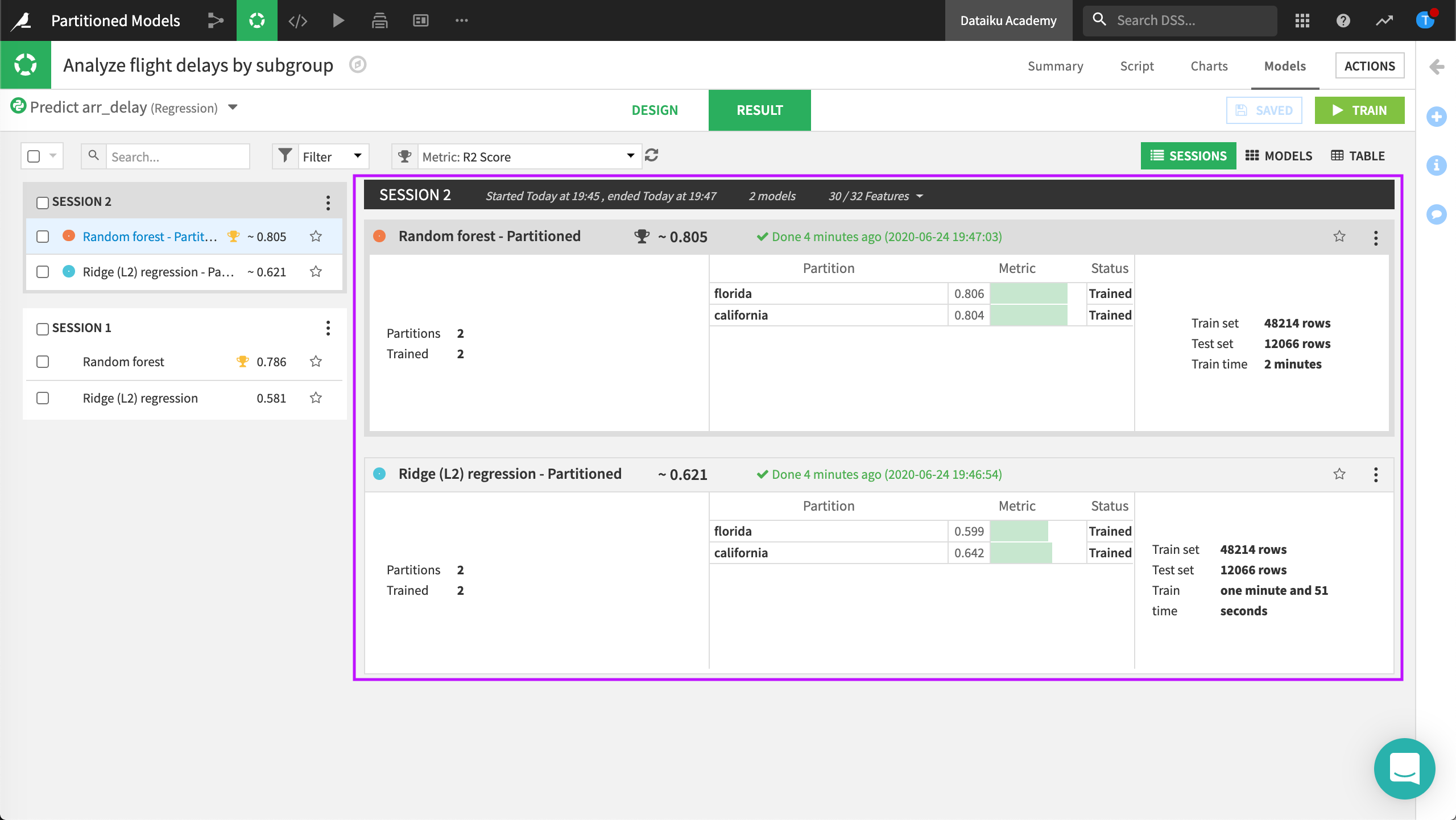
In the Result tab, Dataiku displays two partitioned models. Each of these models has two model partitions, one for each partition that was trained.
Note
When you select algorithms to use for training, Dataiku DSS trains a partitioned model for each algorithm. Each partitioned model consists of one sub-model (or model partition) per data partition. Your results may differ from the results shown. Each time you train the model your results may change slightly.
Evaluate the Results¶
We now have two modeling sessions. The first session is trained over the whole data even though flights_data_partitioned is a partitioned dataset. The second session is trained using the partitions.
Let’s compare these two kinds of models and observe the results.
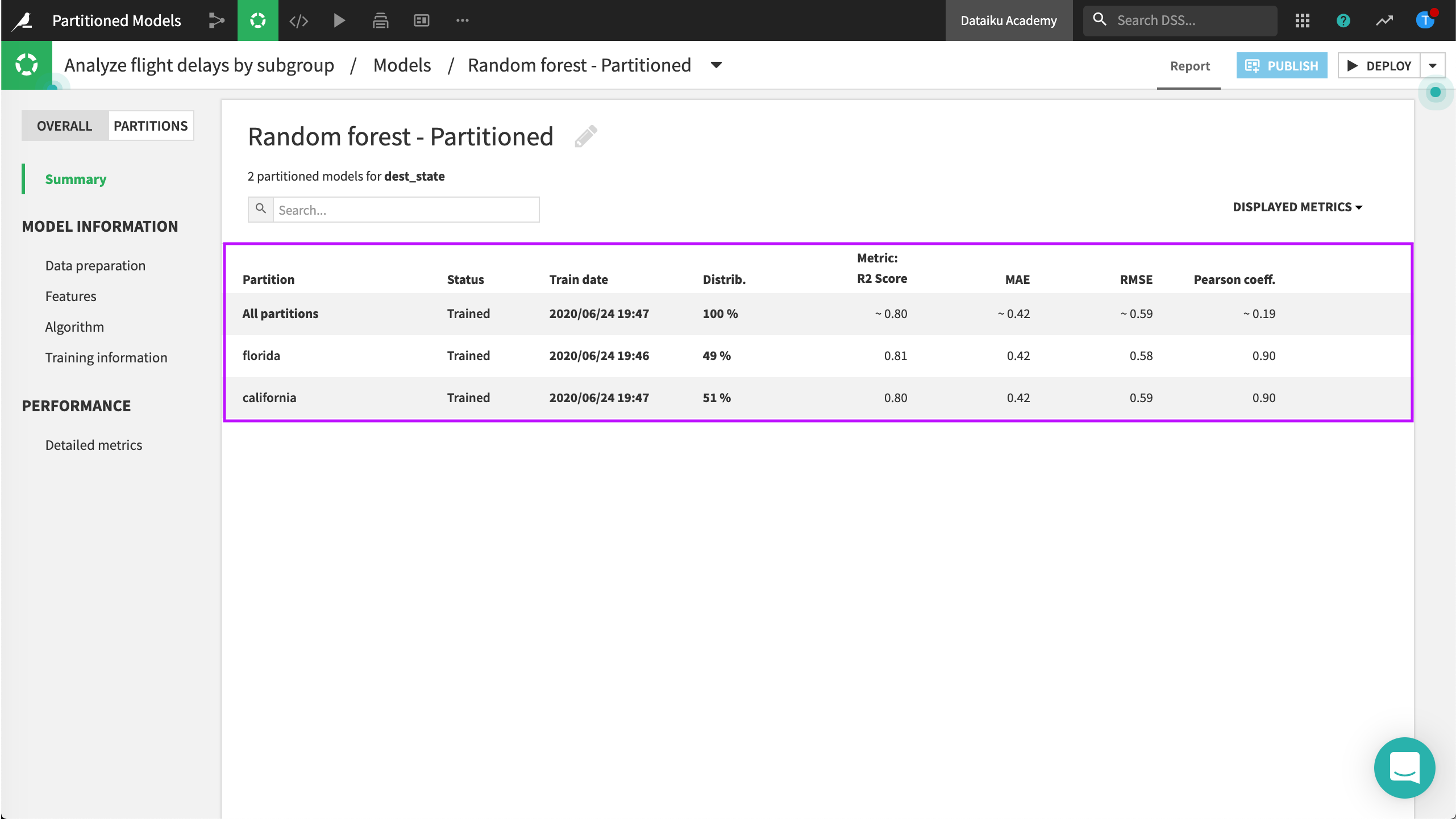
Click on the Random Forest model from the partitioned model training session to view the Summary page.
Dataiku displays a summary where you can compare results for the partitions with the overall results. Some overall details (aggregated or common to all partitions) are also available.
Note
Metrics for the Overall model are aggregated. When an exact computation is not possible, then Dataiku determines the value as a weighted average, where the weights are determined by the size of each partition (using sample weights, if applicable).
Expand the florida row to view details about this partition.
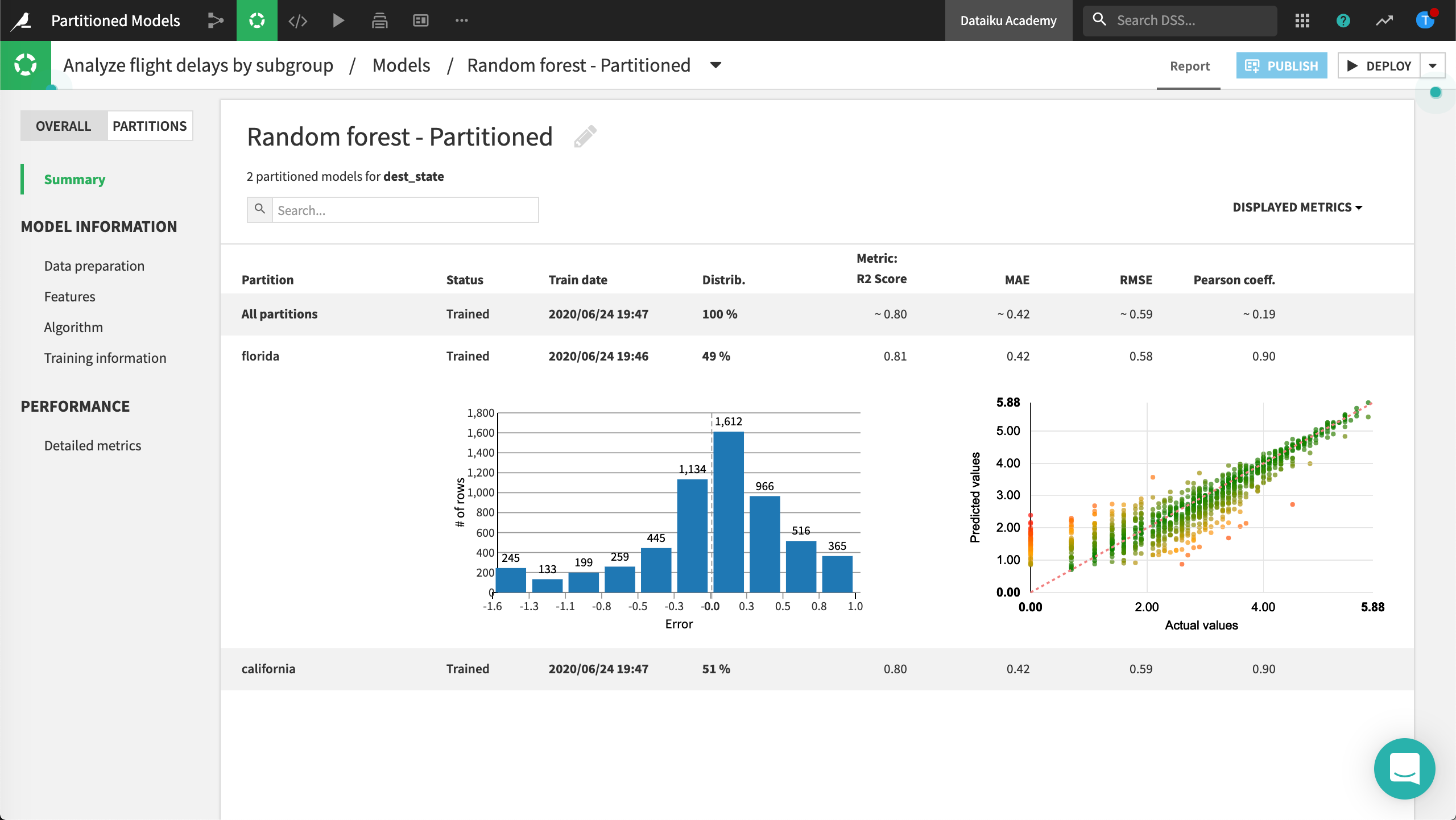
Click florida to open the summary for the partitioned model. Alternatively, you can switch to the Partitions tab and select the partition of interest.
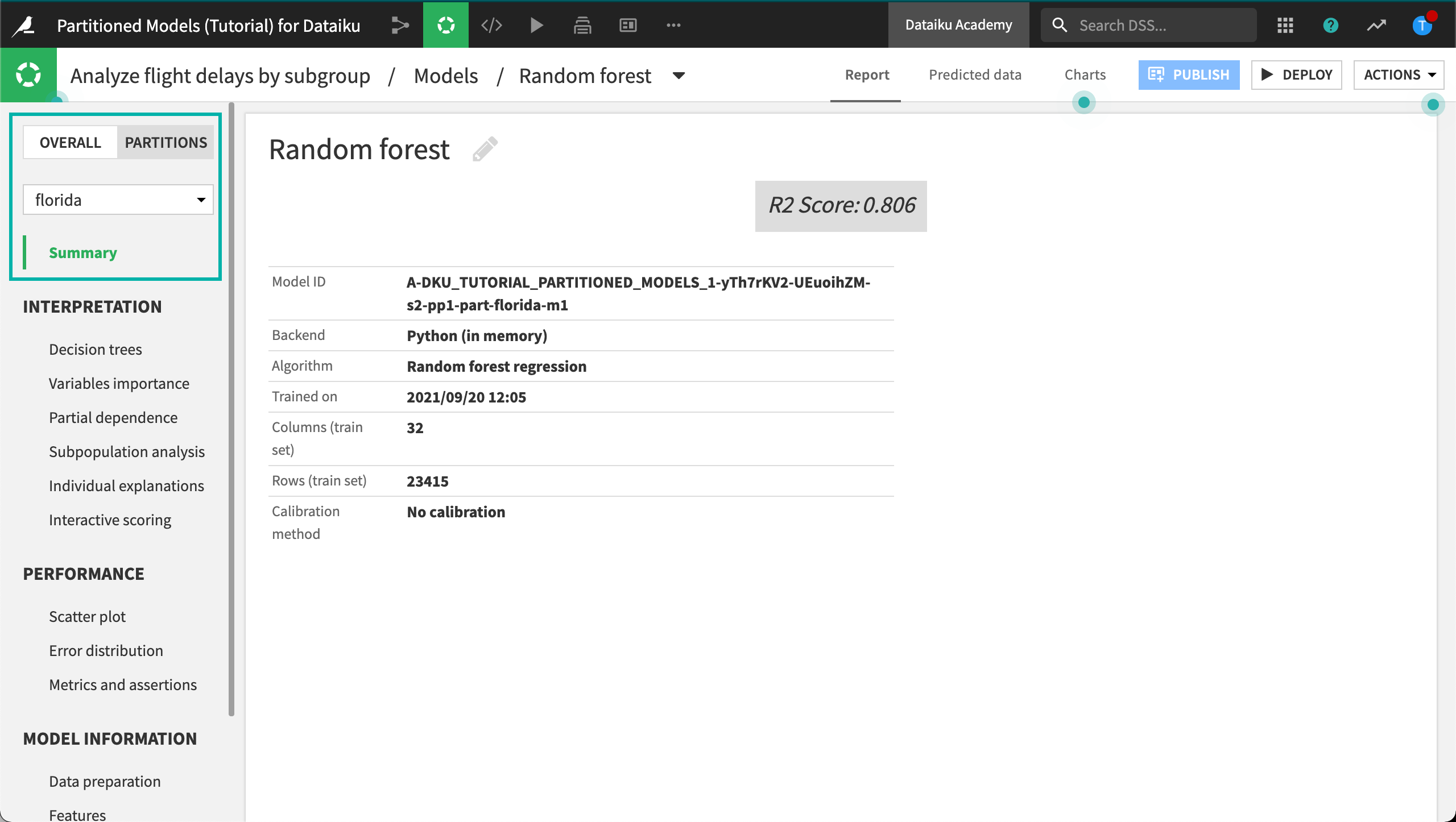
In this example, the partitioned model performed better than the non-partitioned model. This is because subgroups of a data set can have dissimilar characteristics that draw different patterns over the features. You can further explore the summary for each partitioned model to investigate whether or not there are differences between the partitioned model results.
Summary¶
Now that you understand how to build a partitioned model and interact with it, you can compare the results between the overall model results and the partitioned model results. The difference is the partitioned model is specific to a subgroup of the dataset and provides information specific to that subgroup. A partitioned model can provide better performance than a non-partitioned model.
What’s next?¶
In this course, you’ve seen how to train a prediction model on partitions, or subgroups, of a dataset to test whether or not you could improve the prediction performance over a non-partitioned model.
Now you can continue your learning journey by challenging yourself with other machine learning courses or even advanced analytics courses.