Hands On: Fuzzy Join Recipe¶
In this hands-on tutorial, you will discover the Fuzzy Join recipe in Dataiku DSS.
The Fuzzy Join recipe is used to perform joins between two datasets when the join keys don’t match exactly. It can take text, numerical, or geopoint columns as join keys.
You will perform two fuzzy joins, one using text columns, and one using geopoints.
Let’s Get Started!¶
The project uses flight reviews data. The goal is to use the Fuzzy Join recipe for the purpose of:
joining the reviews data with a dataset containing city geopoints based on the city names (some of which have alternative spellings); and
mapping reviews to destination airports based on the destination cities’ geopoint.
Prerequisites¶
Some familiarity with basic data preparation in Dataiku DSS (we recommend having completed the Core Concepts course series beforehand).
Technical Requirements¶
An instance of Dataiku DSS - version 9.0 and above.
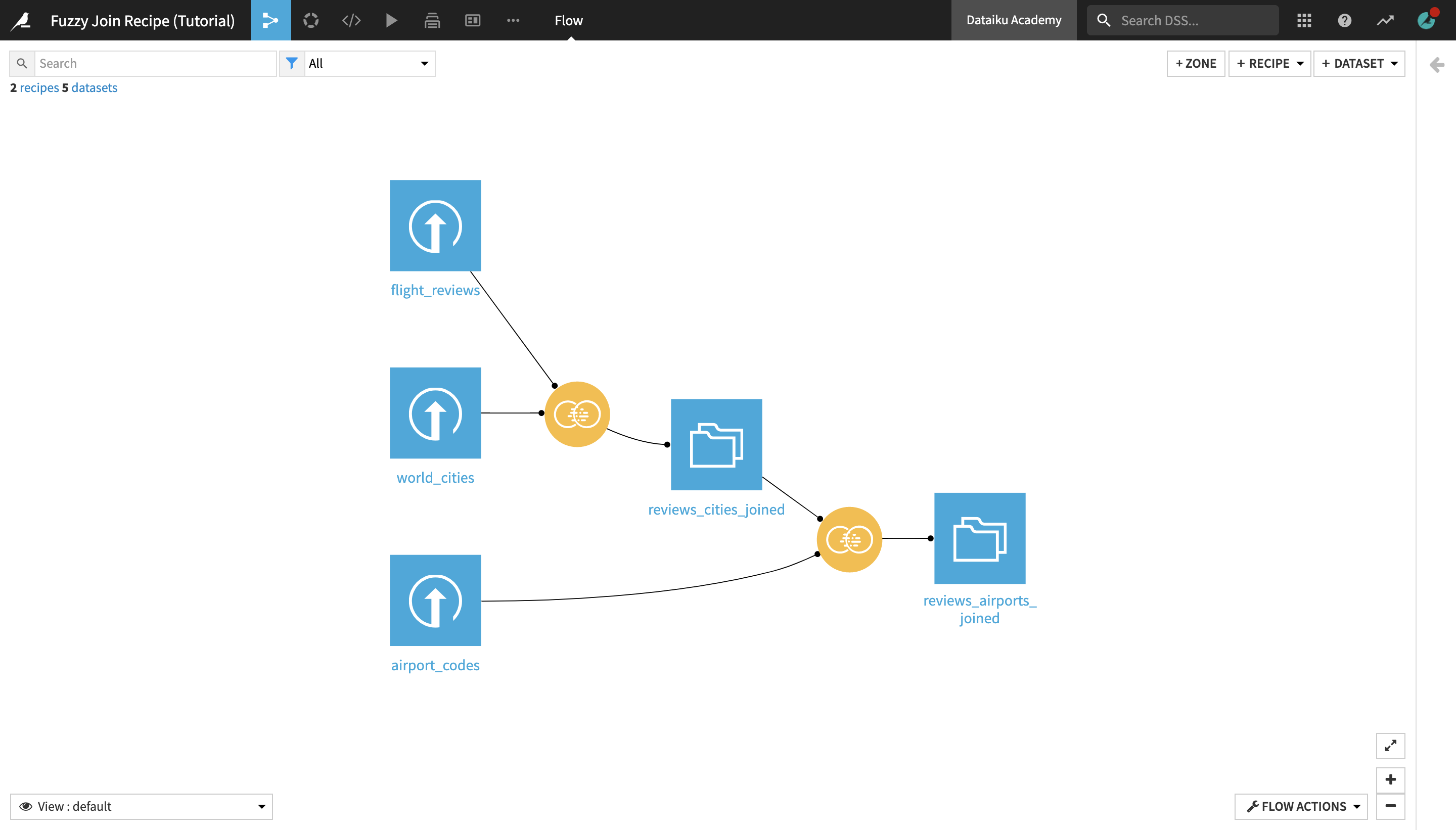
Workflow Overview¶
At the end of this hands-on tutorial, you will have built the Flow below and have an understanding of its components:
Create Your Project¶
From the Dataiku DSS homepage, click +New Project > DSS Tutorials > General Topics > Fuzzy Join Recipe (Tutorial).
Fuzzy Join Datasets on Text Values¶
We’ll start by joining two datasets, flight_reviews and world_cities, which both contain columns with the names of cities (with sometimes slightly varying spellings).
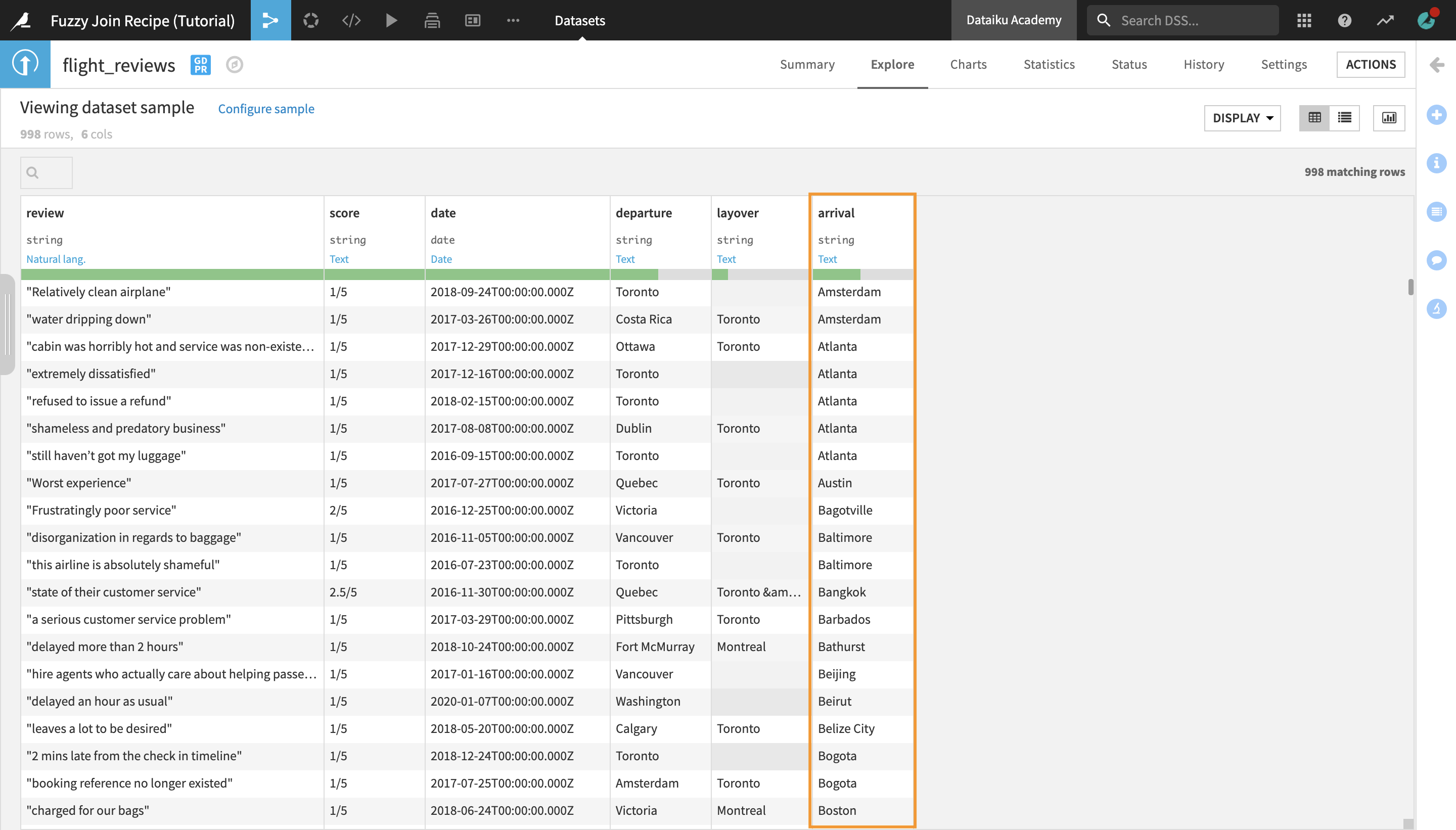
Navigate to the Flow and open the flight_reviews dataset to preview it.
Upon exploring the flight_reviews dataset, notice the arrival column, which contains the names of destination cities. We will use this column as a join key to obtain additional information on the cities from another dataset.
Return to the Flow and open the world_cities dataset to preview it.
The world_cities dataset contains three columns: city, country, and geopoint. We want to join the flight_reviews dataset with this one in order to add the arrival city geopoint information to the flight reviews data.
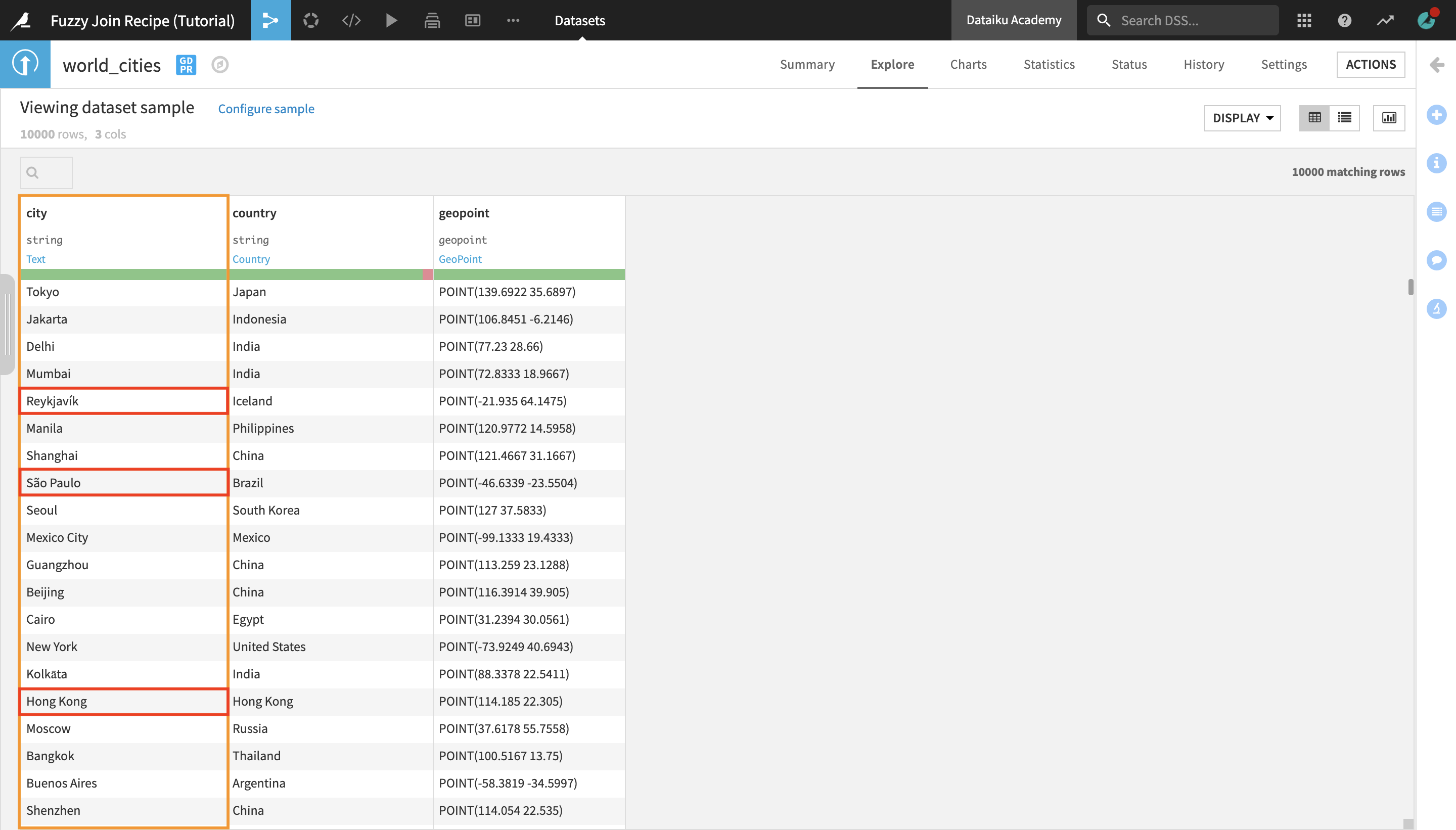
If the city names were identical in both datasets, we could use the regular Join recipe for this purpose. However, notice that the spelling of some of the cities’ names is a bit different here than in the other dataset (e.g. “Reykjavík” in world_cities vs. “Reykjavik” in flight_reviews, “Hong Kong” vs. “Hongkong”, etc.).
If we used a Join recipe, none of the cities with alternative spellings would be matched to a value from the other dataset, and we wouldn’t be able to get the geopoint information for them. Instead, we are going to use the Fuzzy Join recipe to map the cities to their very-similar-but-not-identical alternative spelling.
Return to the Flow. Select the world_cities and the flight_reviews datasets.
With both datasets selected, open the Actions menu and select the Fuzzy Join recipe.
Name the output dataset
reviews_cities_joinedand create the recipe.
The recipe UI looks similar to that of the regular Join recipe.
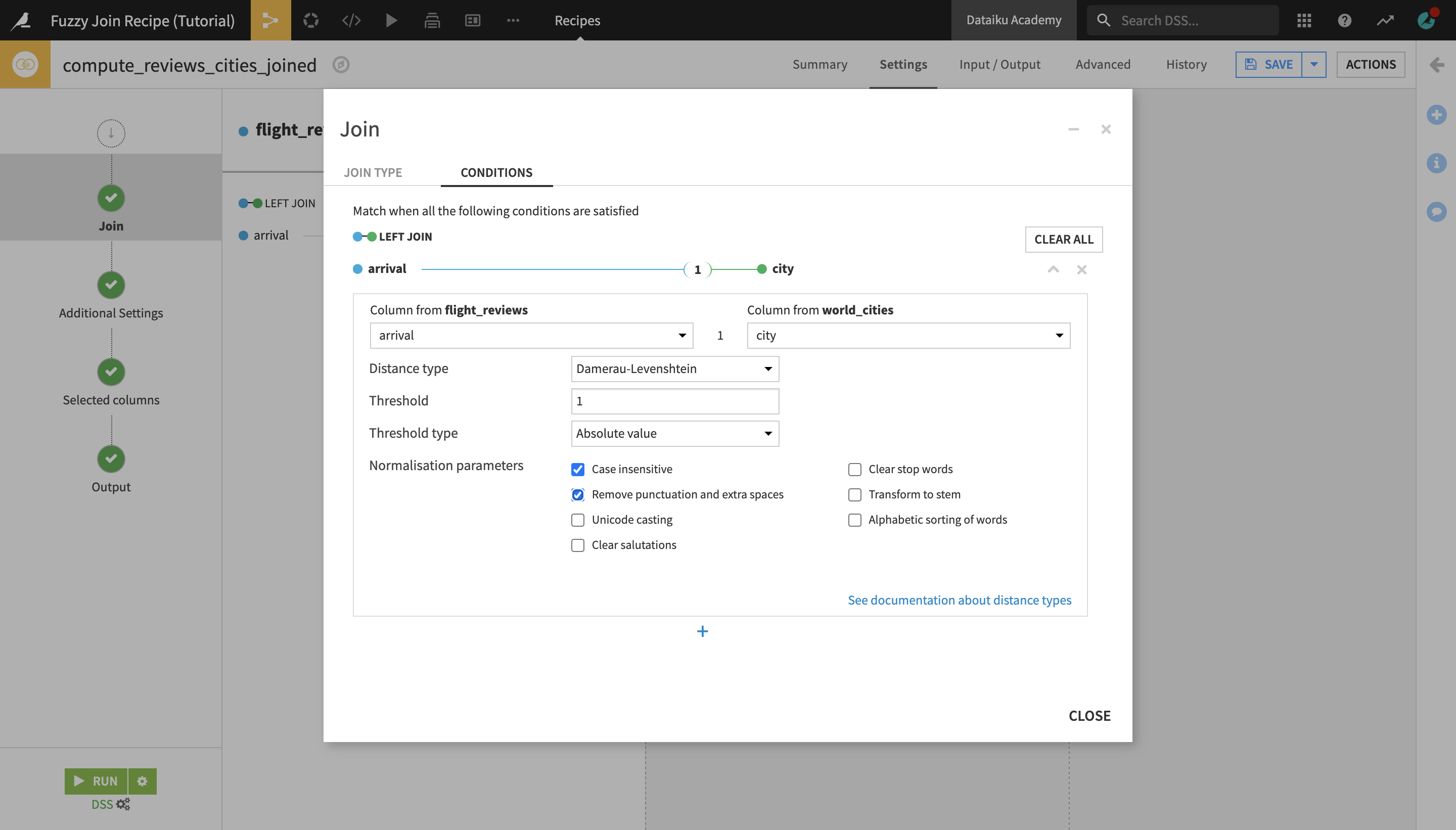
In the Join step, click on one of the autodetected join keys to open the Join edit window, and then click on them again to edit the selection.
Select arrival as the join column from the fligth_reviews_prepared dataset, and city as the join column from the world_cities dataset.
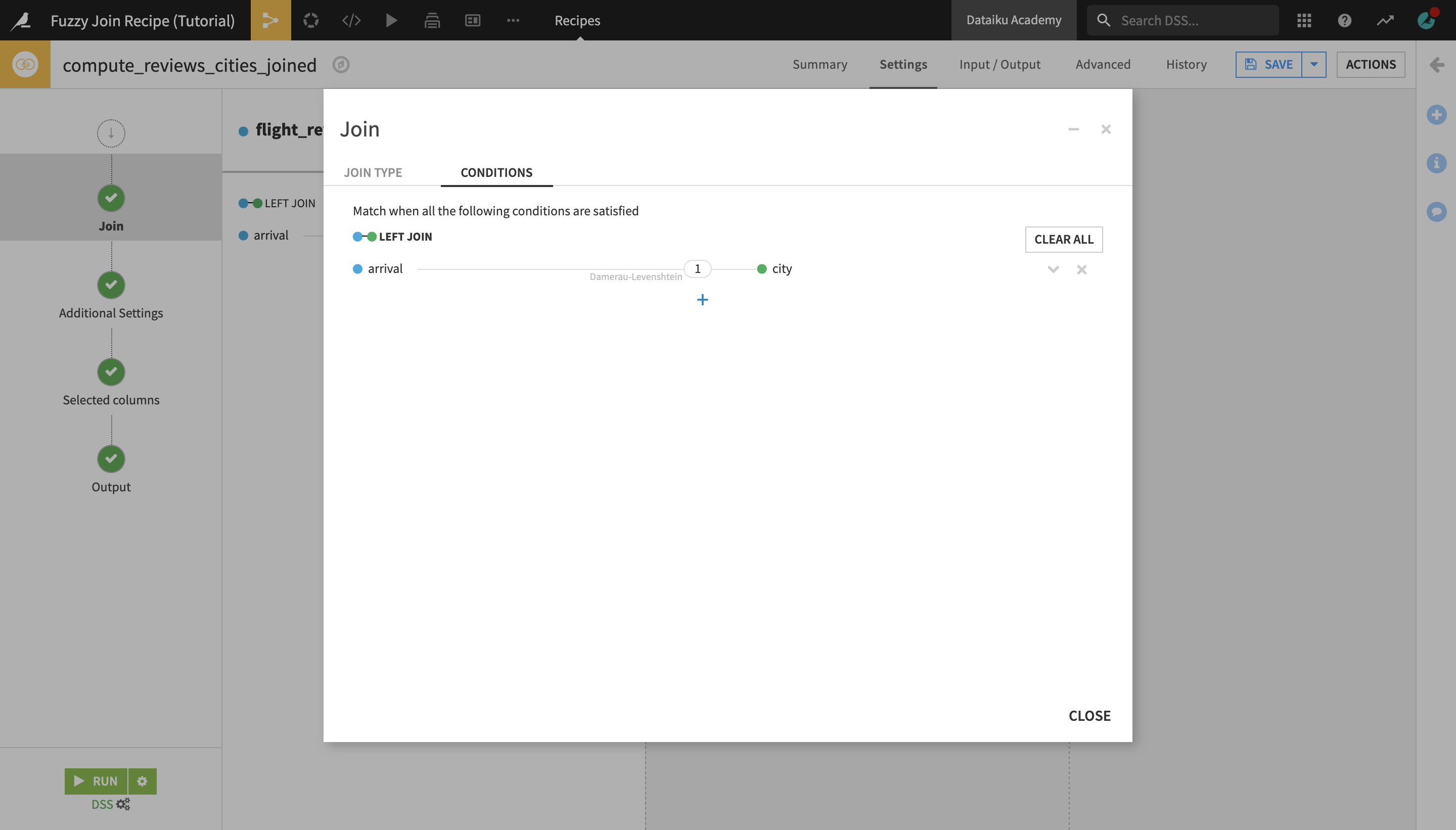
In addition to the join keys, the Fuzzy Join recipe allows you to select the Distance type , the distance Threshold, the Threshold type, and the Normalization parameters.
The distance type selected by default is Damerau-Levenshtein, which measures the minimum number of operations (consisting of insertions, deletions or substitutions of a single character, or transposition of two adjacent characters) required to change one word into the other.
Note
The Fuzzy Join recipe works by calculating the distance between the values of the join columns and then using a user-defined “maximum distance” threshold to map and join the columns based on similar values whose distance fits within the chosen threshold.
For example, the Damerau-Levenshtein distance between “Lisbon” and “Lisboa” is 1 because there is only one substitution of the letter “n” with the letter “a” required to transform one word into the other.
You can refer to the documentation to learn more about Damerau-Levenshtein as well as other methods for measuring distance between strings.
We will stick with the Damerau-Levenshtein distance type and, since we want to minimize the error margin, we will leave the maximum distance threshold to 1. Finally, we will set the normalization parameters so that minor differences between case spellings and punctuation are ignored.
Under Normalization parameters, select Case insensitive and Remove punctuation and extra spaces.
Next, we’ll verify the selected columns to retrieve from the two joined datasets in the output dataset.
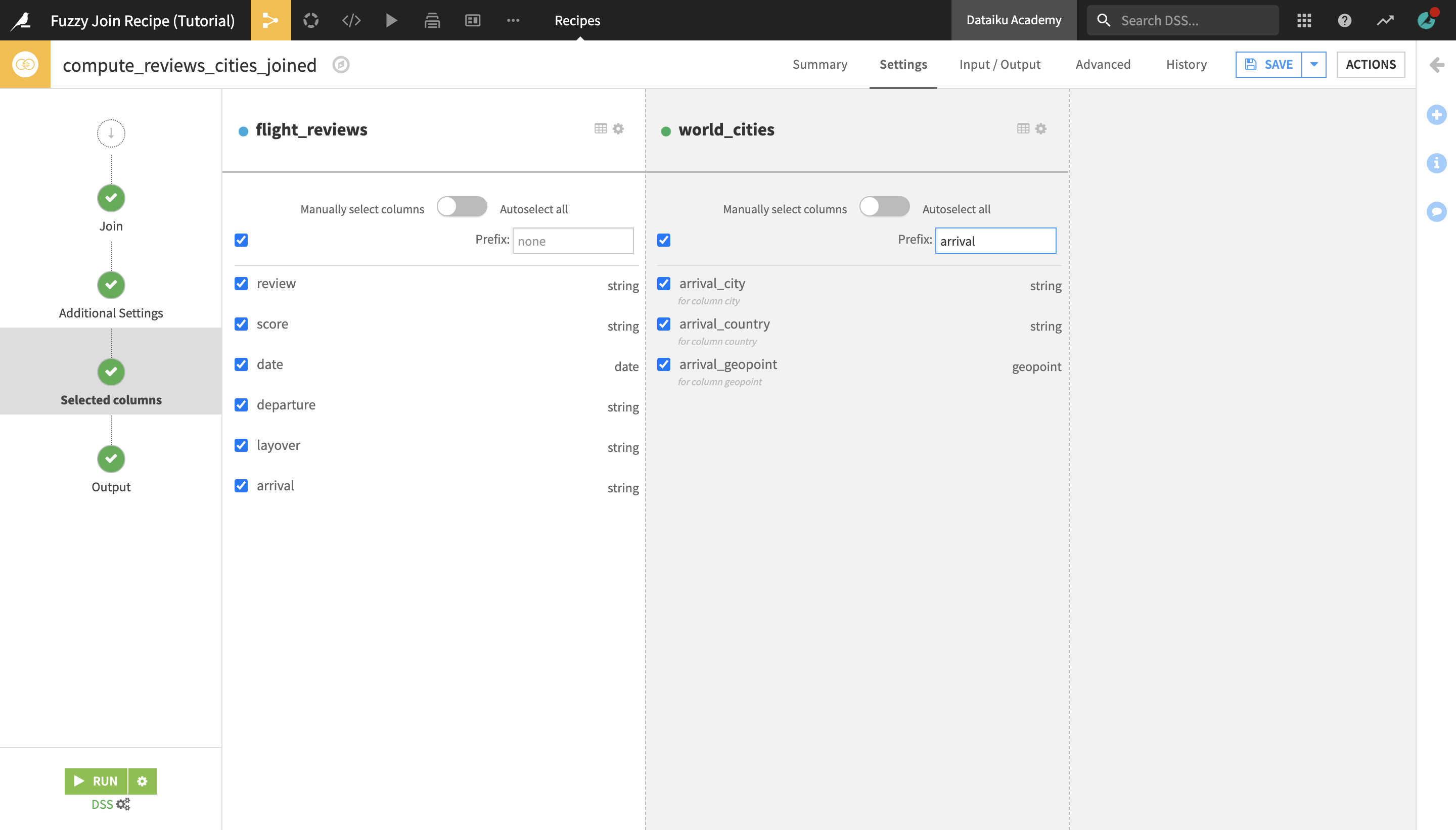
Navigate to the Selected columns step.
We want to retrieve all columns from both datasets, which is already selected by default, but let’s add a prefix to the retrieved columns from the world_cities dataset so that it’s clear that they refer to the city of arrival.
In the world_cities dataset column pane on the right, type
arrivalin the Prefix field.
Preview the output in the Output step, and then run the recipe, accepting the schema change in the process.
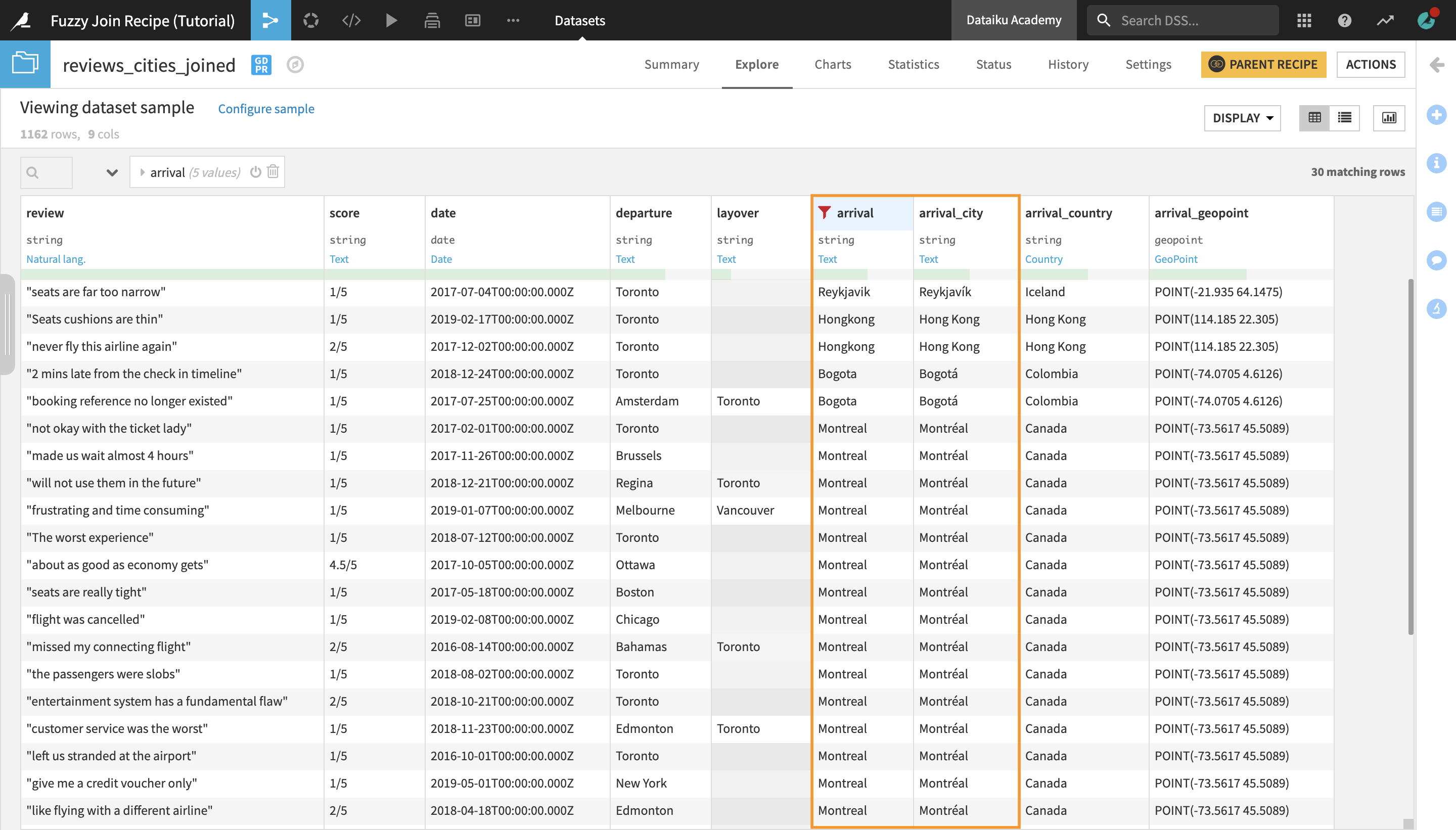
Open the reviews_cities_joined dataset to preview it.
Observe the arrival and arrival_city columns. Notice that the Fuzzy Join recipe has been successful at matching values from the two columns which refer to the same city but are using slightly different spellings, such as “Montreal” and “Montréal”, “Hongkong” and “Hong Kong”, as well as at ignoring minor typos (e.g. matching “Vancover” to “Vancouver”).
Note
You may notice that the output dataset contains 1162 rows, while the original flight_reviews dataset contained 998 rows. This is because some city names correspond to more than one city (e.g. Portland, Oregon and Portland, Maine; San Jose, California and San José, Costa Rica; etc.)
Fuzzy Join Datasets on Geographic Criteria¶
Now that we have enriched our reviews data with the arrival cities’ geopoints, we can use the Fuzzy Join recipe again, this time to perform a fuzzy join based on geographic criteria. Our goal is to map the arrival cities to their corresponding airports by joining the reviews_cities_joined dataset with another dataset, airport_codes, that contains the names, IATA codes, and geopoints of airports.
From the Flow, open the airport_codes dataset to preview it.
Return to the Flow and select the reviews_cities_joined and airport_codes datasets.
With both datasets selected, open the Actions menu and select the Fuzzy Join recipe.
Name the output dataset reviews_airports_joined and create the recipe.
The Fuzzy Join recipe functions in a very similar way when working with geographical data.
In the Join step, the arrival_geopoint column from reviews_cities_joined and the geopoint column from airport_cities are already autoselected as the join keys.
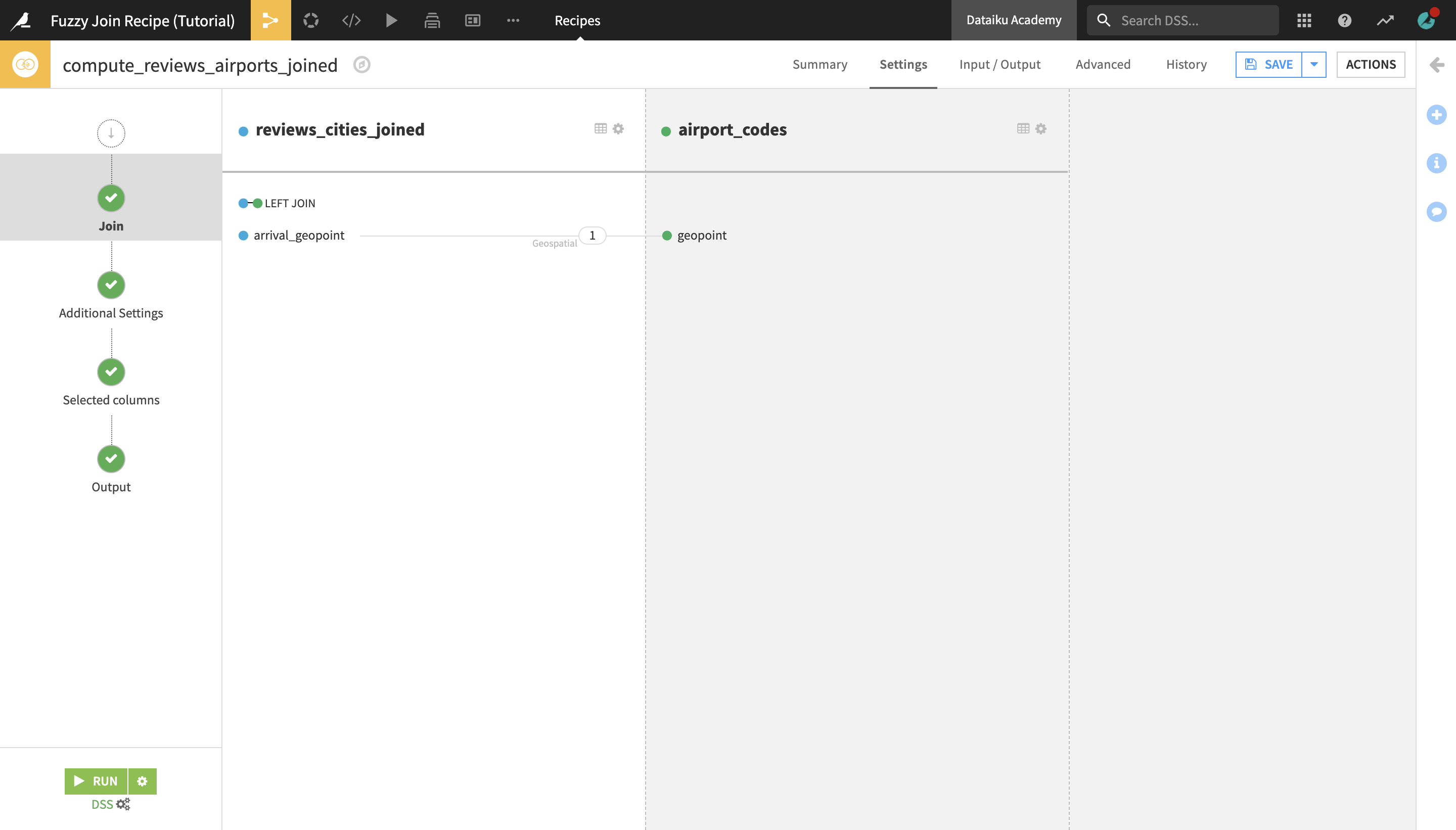
Notice that the Distance type is automatically set to Geospatial, because both of the columns correspond to the “geopoint” type.
Set the Threshold to
50kilometers.
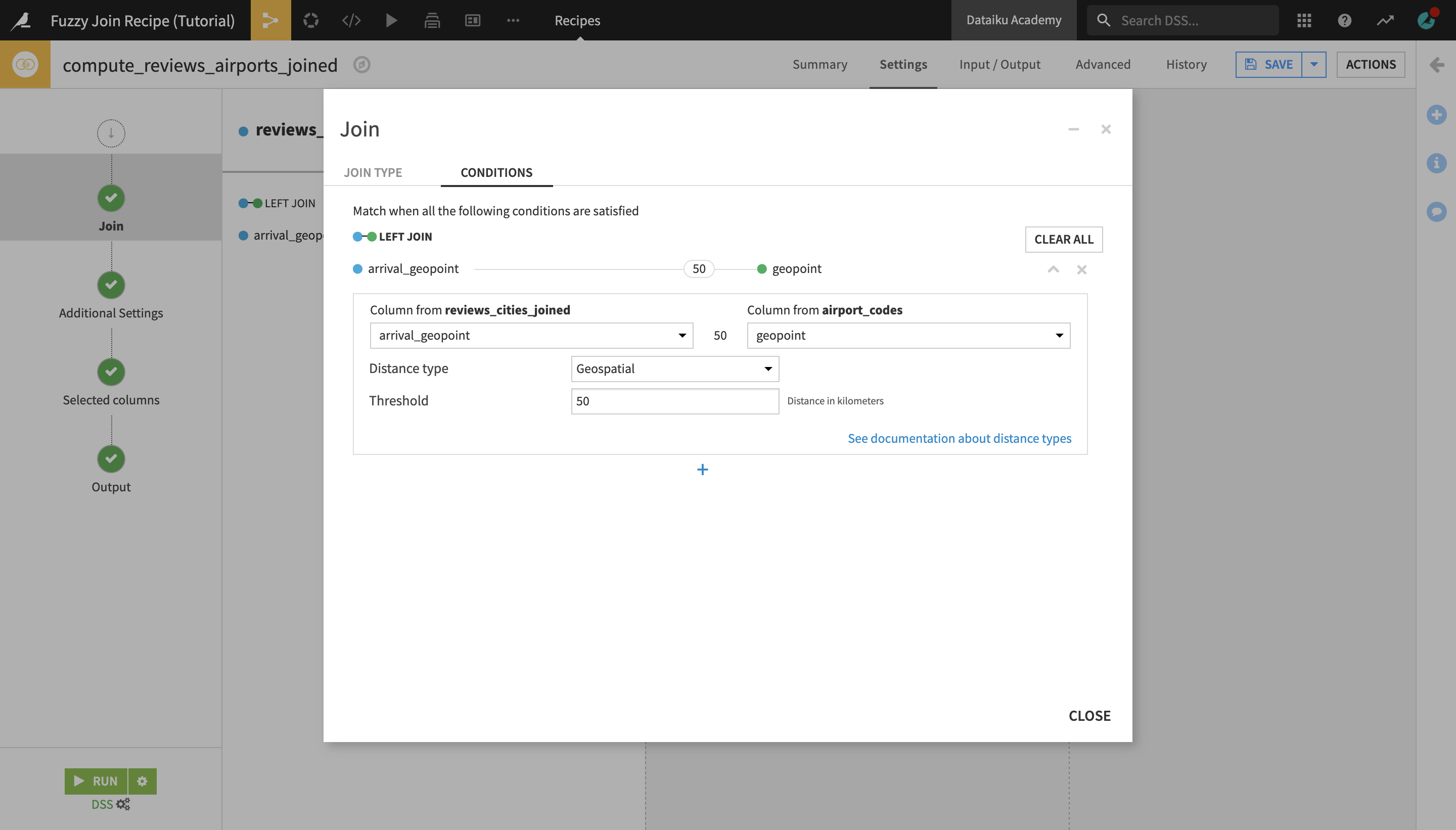
This way, the Fuzzy Join recipe will match cities to airports that are within 50 kilometers away from the city.
Navigate to the Selected columns step.
In the airport_codes dataset column pane on the right, type
airportin the Prefix field.Preview the output, and then run the recipe, accepting the schema change in the process.
Open the reviews_cities_joined dataset to preview it.
Notice that a lot of cities have been mapped to multiple airports, which is expected since there is often more than one airport within a 50 km distance of a city.
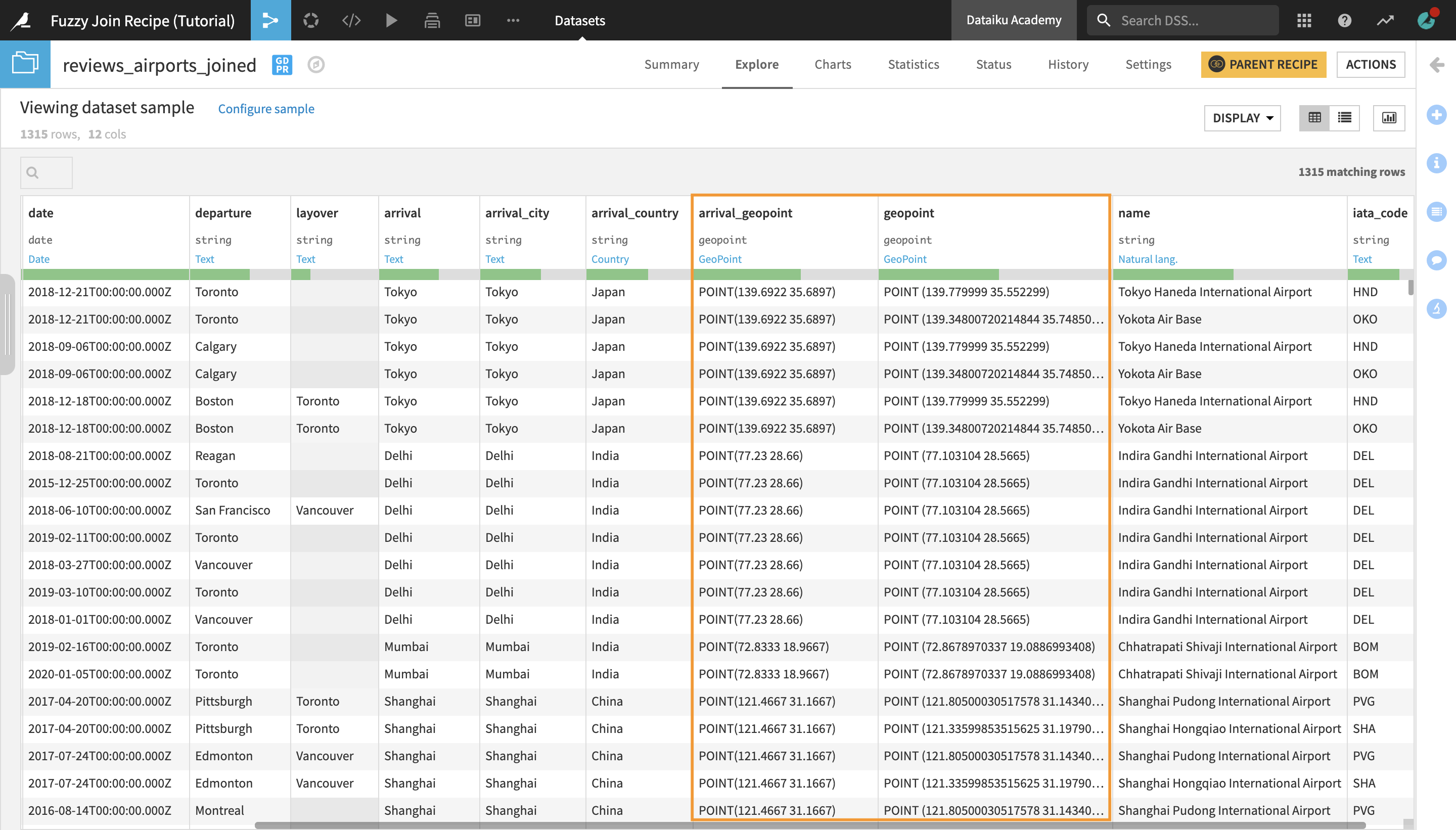
Tip
You could use a Group recipe in order to group by arrival_city and concatenate all the different airports mapped to a single city in one column.
What’s Next¶
In a short amount of time, you were able to discover the Fuzzy Join recipe and apply it in practice.
To go further, you can:
read the Fuzzy Join documentation and the Dataiku DSS 9 release notes for more information on how to leverage the Fuzzy Join recipe, as well as other Dataiku DSS 9 features;
take the Visual Recipes 102 course on the Academy to learn about other advanced visual recipes.