Can I control which datasets in my Flow get rebuilt during a scenario?¶
When configuring a Build/Train step in an Dataiku scenario, four different build modes let you control which items in your Flow are rebuilt or retrained when the scenario is triggered.
In the Steps tab of your Scenario, click Add Step and select Build / Train.
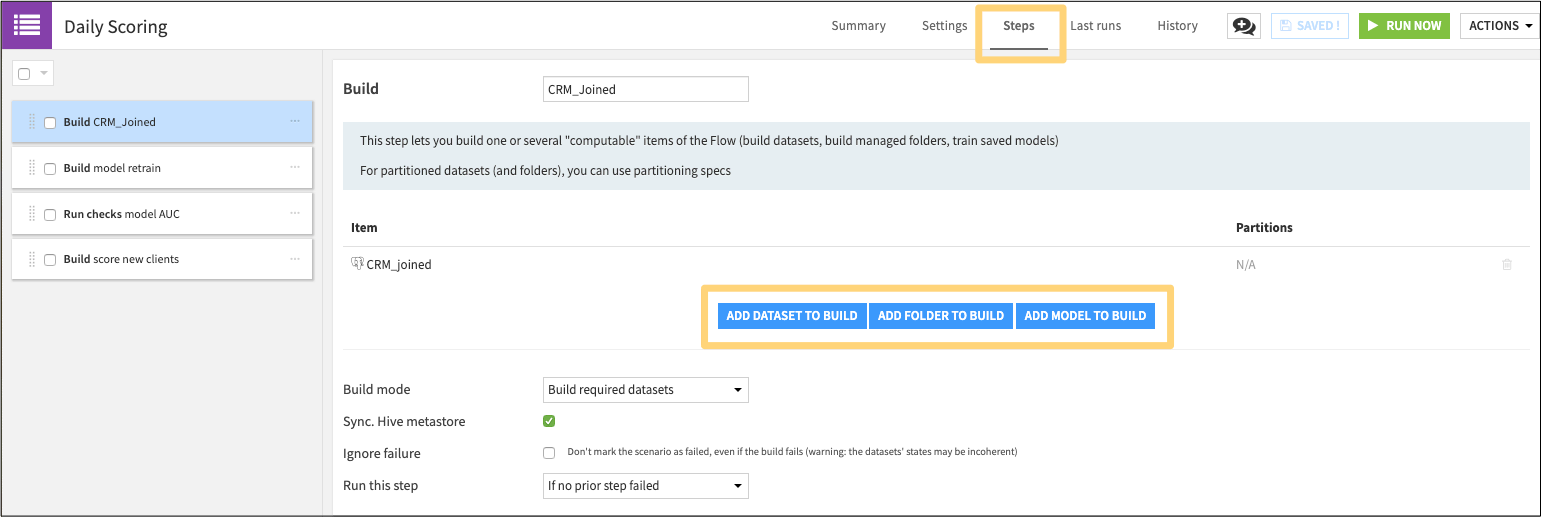
Next, select the item you would like to build (a dataset, folder, or model). In the options below, you have the option of four different build modes to control which datasets and upstream dependencies are executed each time the trigger fires.
Build only this dataset
Select this option to build only the selected dataset using its parent recipe. This option requires the least computation, but does not take into account any upstream changes to datasets or recipes. Therefore, if previous dependencies to this recipe are not built, the job will fail.
Build required datasets
Also known as smart reconstruction, this option checks each dataset and recipe upstream of the selected dataset to see if it has been modified more recently than the selected dataset. Dataiku DSS then rebuilds all impacted datasets down to the selected one. This is the recommended default.
Force-rebuild dataset and dependencies
Also known as forced recursive rebuild, select this option to rebuild all of the dependencies of the selected dataset going back to the start of the Flow. This is the most computationally-intense of the build modes, but can be useful for overnight-build scenarios in order to start the next day with a double-checked and up to date Flow.
Build missing dependent datasets then this one
This option is not recommended for general usage. It works a bit like “Build required datasets”, but a dependent dataset needs to be (re)built only if it’s completely empty, prior to then building the specified dataset.
Note
In all of these cases, if a dataset is built, its siblings (other outputs of the source recipe) will also be built. If you specify multiple datasets in the same build step, they will be built in parallel at run-time. Shared datasets will also not be built, as the flow build stops when it reaches foreign objects.
What’s next?¶
In addition to scheduling automated jobs, monitoring those jobs and the status and quality of the resulting datasets is also important. You can learn more about operationalization with this series of hands-on tutorials.