Concept: Dataset Building Strategies¶
In this lesson, you’ll learn about important concepts for rebuilding datasets, including:
recursive vs. non-recursive builds,
types of recursive builds, and
how or when datasets can be rebuilt.
Tip
This content is also included in a free Dataiku Academy course on Flow Views & Actions, which is part of the Advanced Designer learning path. Register for the course there if you’d like to track and validate your progress alongside concept videos, summaries, hands-on tutorials, and quizzes.
Datasets in a Flow can depend on other datasets that lie upstream, or they can depend on the outputs of upstream recipes. As a result, these dependent (or downstream) datasets can become outdated if changes are made upstream.
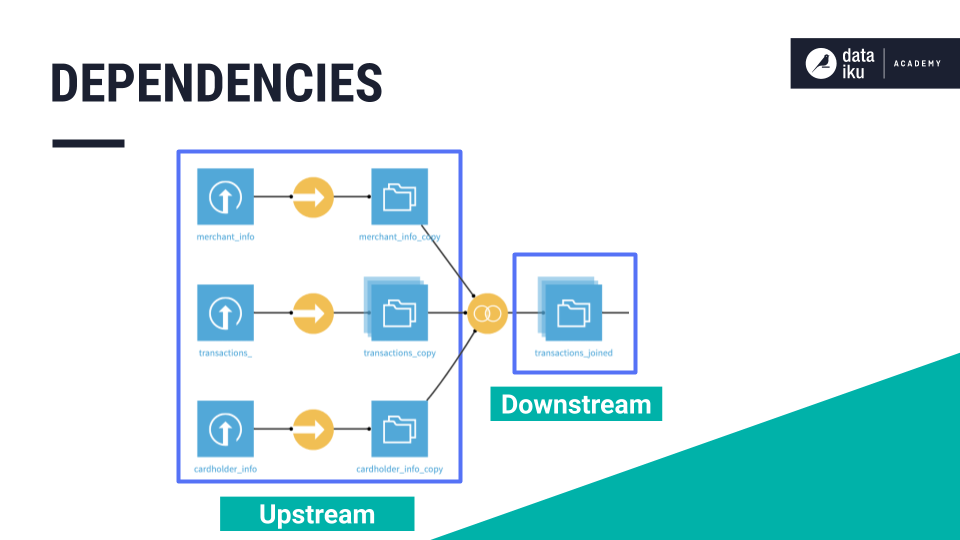
Dataiku DSS is aware of the dependencies for every dataset in our Flow and can efficiently rebuild outdated downstream datasets. When there are changes upstream, we have different strategies to choose from, including performing a non-recursive or a recursive build.
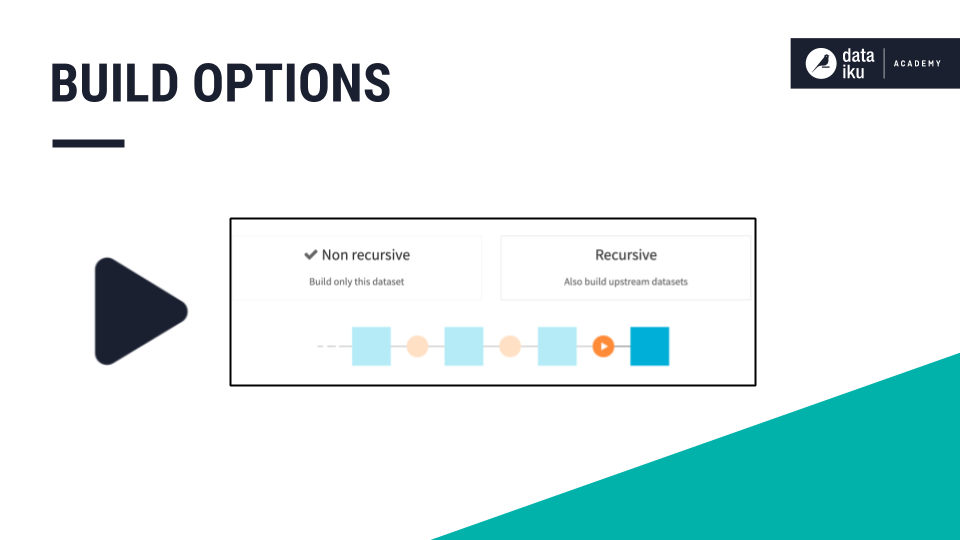
Non-Recursive Build¶
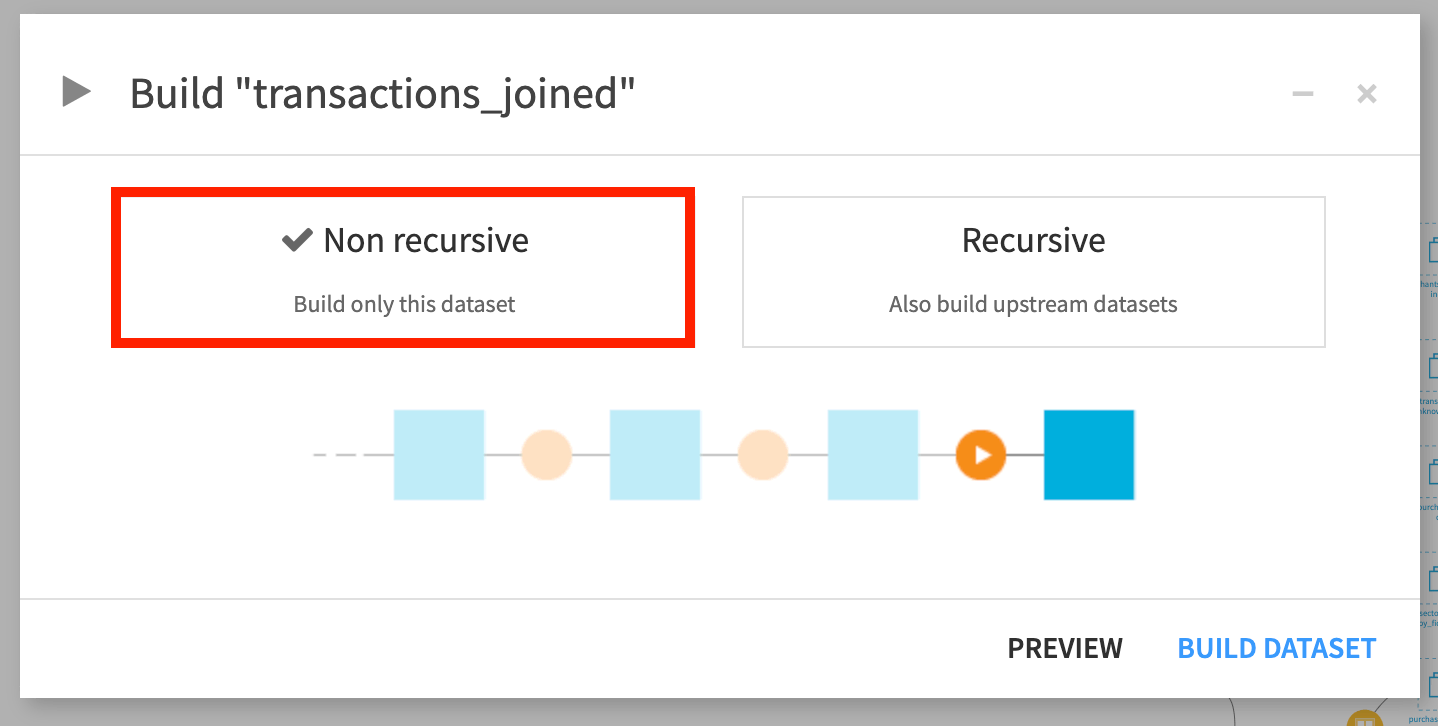
The simplest way to build or rebuild a dataset is by simply building the dataset or running its parent recipe in a non-recursive manner. A non-recursive build is the default build option. It runs only the specific recipe that outputs the dataset.
Recursive Build¶
The Recursive build option builds the dataset along with upstream datasets. The recursive build aims to rebuild dependencies, while avoiding a rebuild of upstream datasets that are already up-to-date.
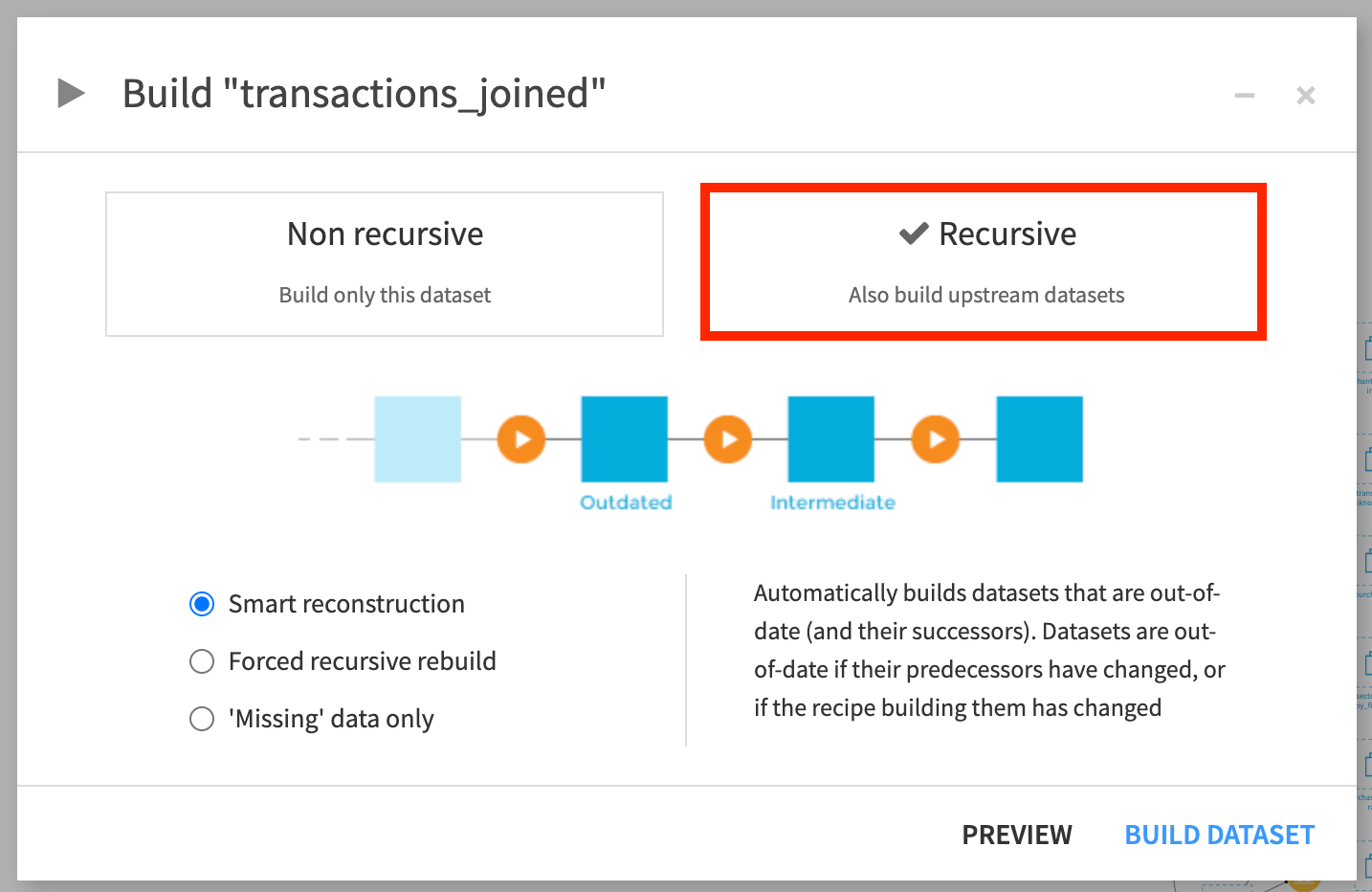
With a recursive build, we have three options:
Smart reconstruction
Forced recursive rebuild, and
‘Missing’ data only.
Smart Reconstruction¶
With Smart reconstruction, Dataiku DSS utilizes its awareness of upstream changes. When selected, Dataiku DSS first rebuilds any required upstream datasets that have become outdated due to changes such as edits to their parent recipes. Only after building the upstream datasets is the dataset selected for re-building built by Dataiku DSS.
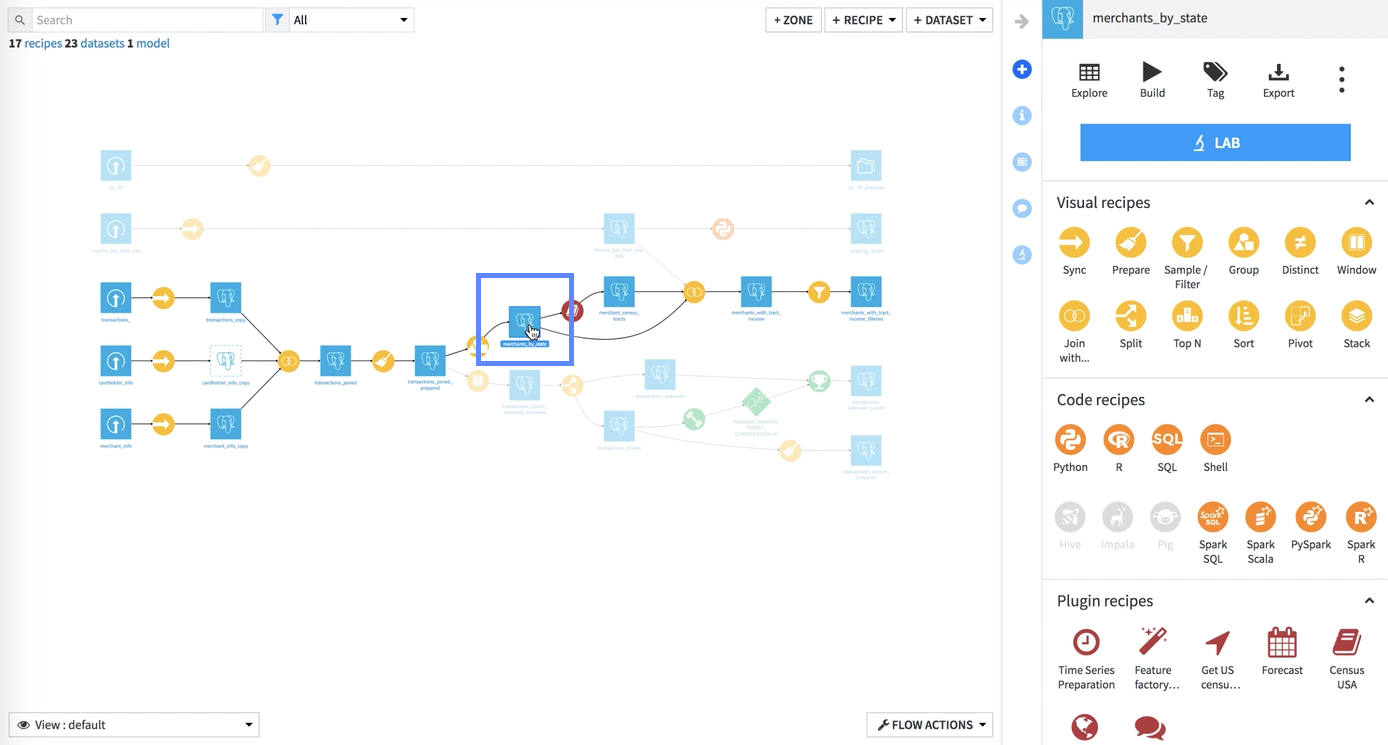
In this example, we’ll build merchants_by_state using Smart reconstruction.
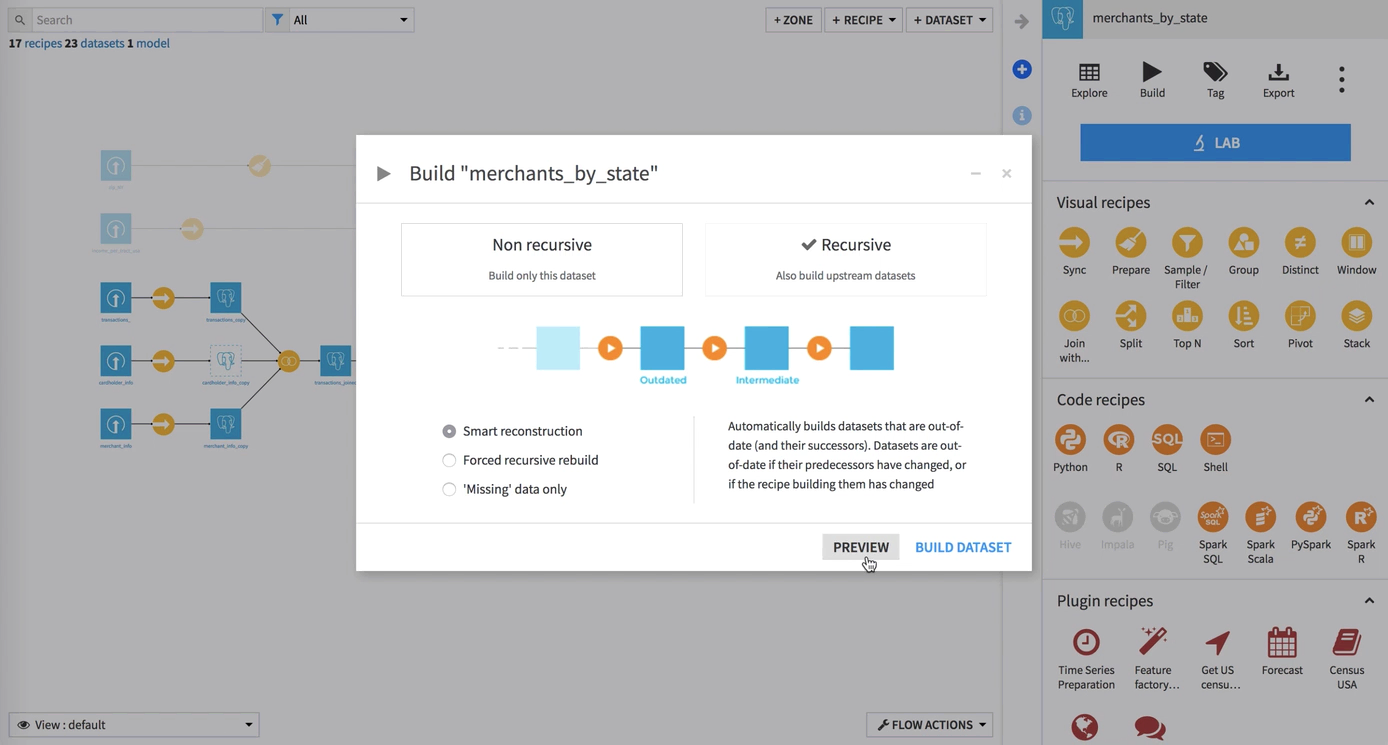
When we select to preview the job, we can see the computed dependencies. For example, building the dataset, cardholder_info_copy, is required because it has not been built, and it lies upstream relative to the merchant_by_state dataset. The upstream datasets that are already up-to-date, are not rebuilt.
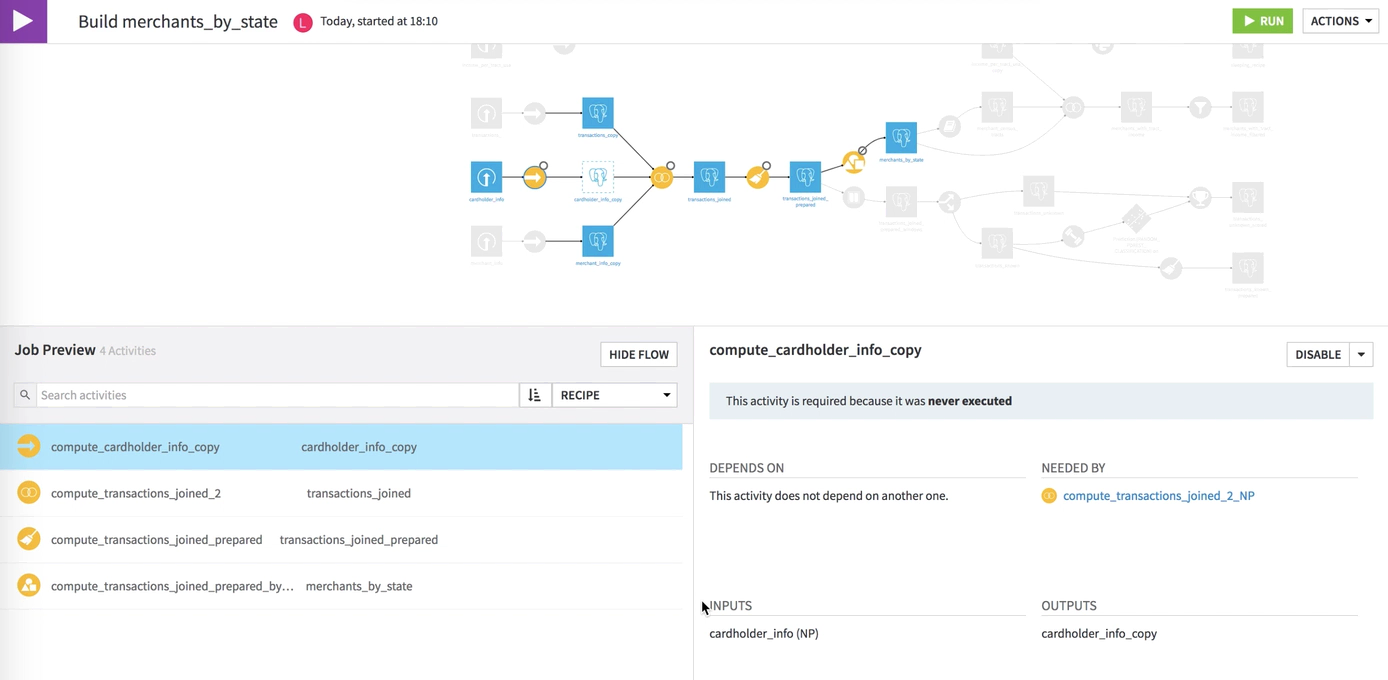
As a result of this recursive build of the merchant_by_state dataset using smart reconstruction, the empty dataset and all the intermediate datasets that depend on it are built.
Forced Recursive Build¶
The second option, Forced recursive rebuild, rebuilds all of the dependencies of the selected dataset, going back to the beginning of the Flow. In this example, we’ll build merchants_by_state using Forced recursive build.
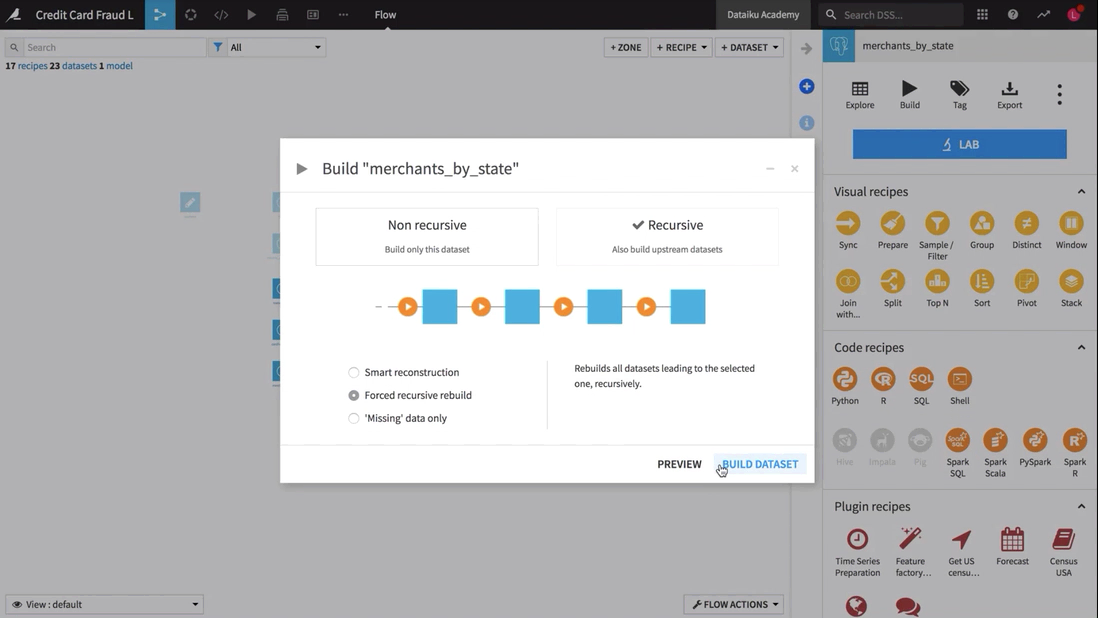
When we select to preview the job, we can see the computed dependencies. The upstream datasets, even those that are already up-to-date, are rebuilt.
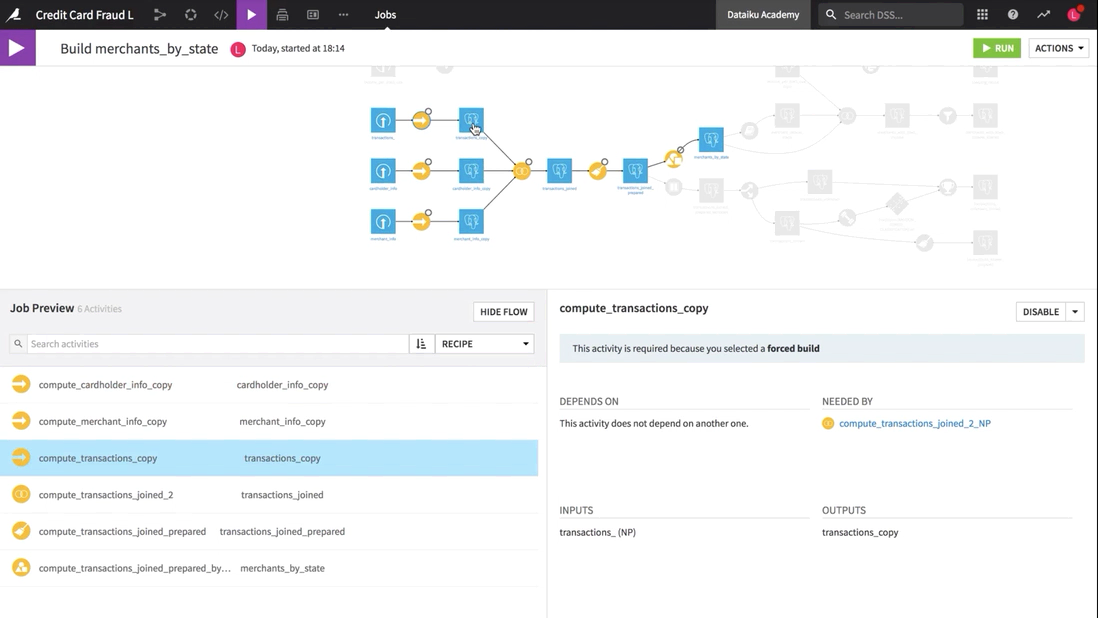
As a result of this recursive build of the merchant_by_state dataset using forced recursive build, the dataset and all required upstream datasets are rebuilt, even if they are already up-to-date.
Missing Data Only¶
The third option ‘Missing data only’ rebuilds only the required upstream datasets that are completely missing. This method is very specific and generally not recommended.
Controlling How and When a Dataset Can Be Built¶
We can change a dataset’s settings to control how it can be built, or if it can be re-built.
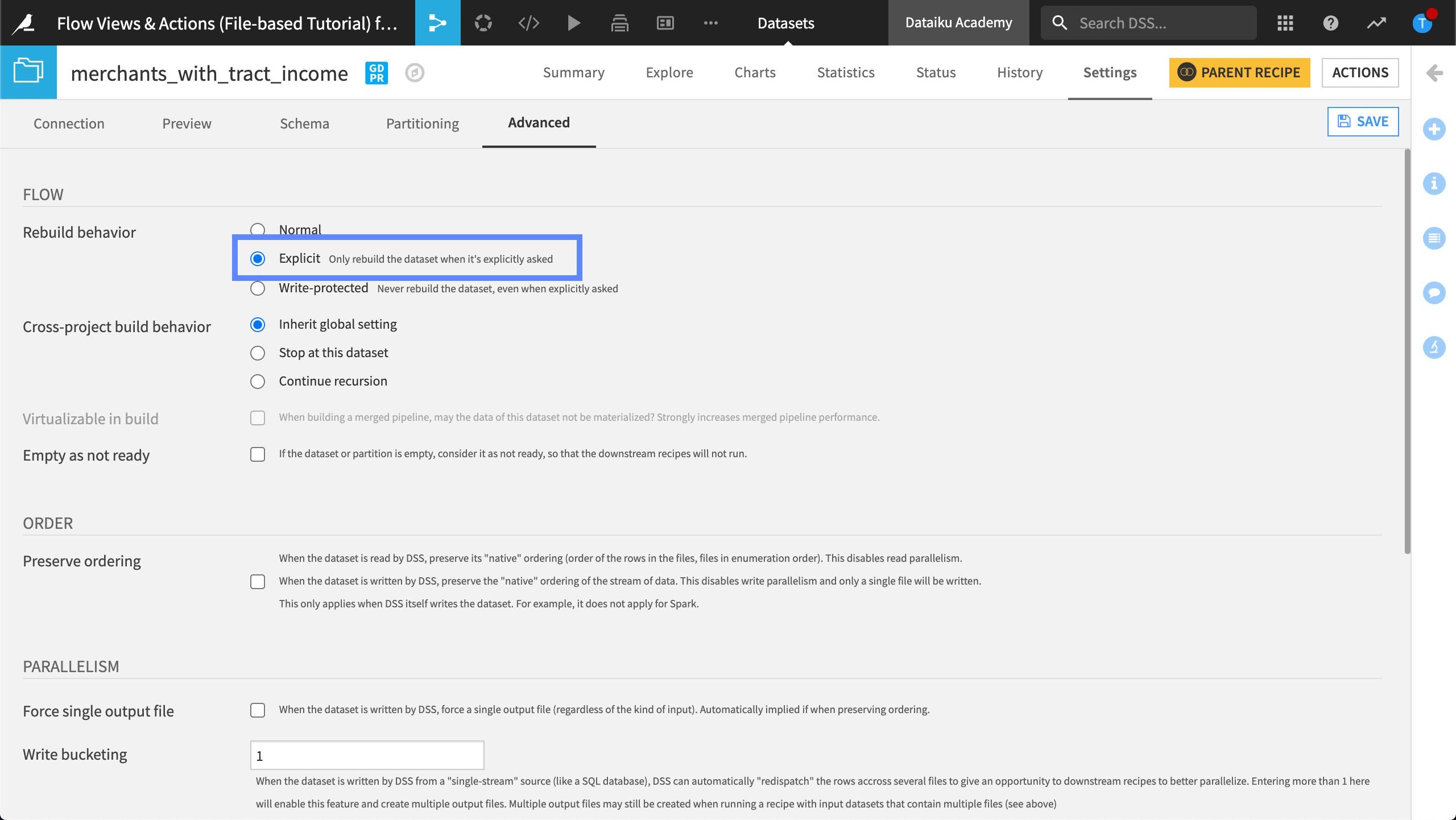
Explicit Rebuild Behavior¶
By specifying the rebuild behavior of a dataset as “Explicit”, the dataset does not get rebuilt, unless we specifically choose to rebuild it.
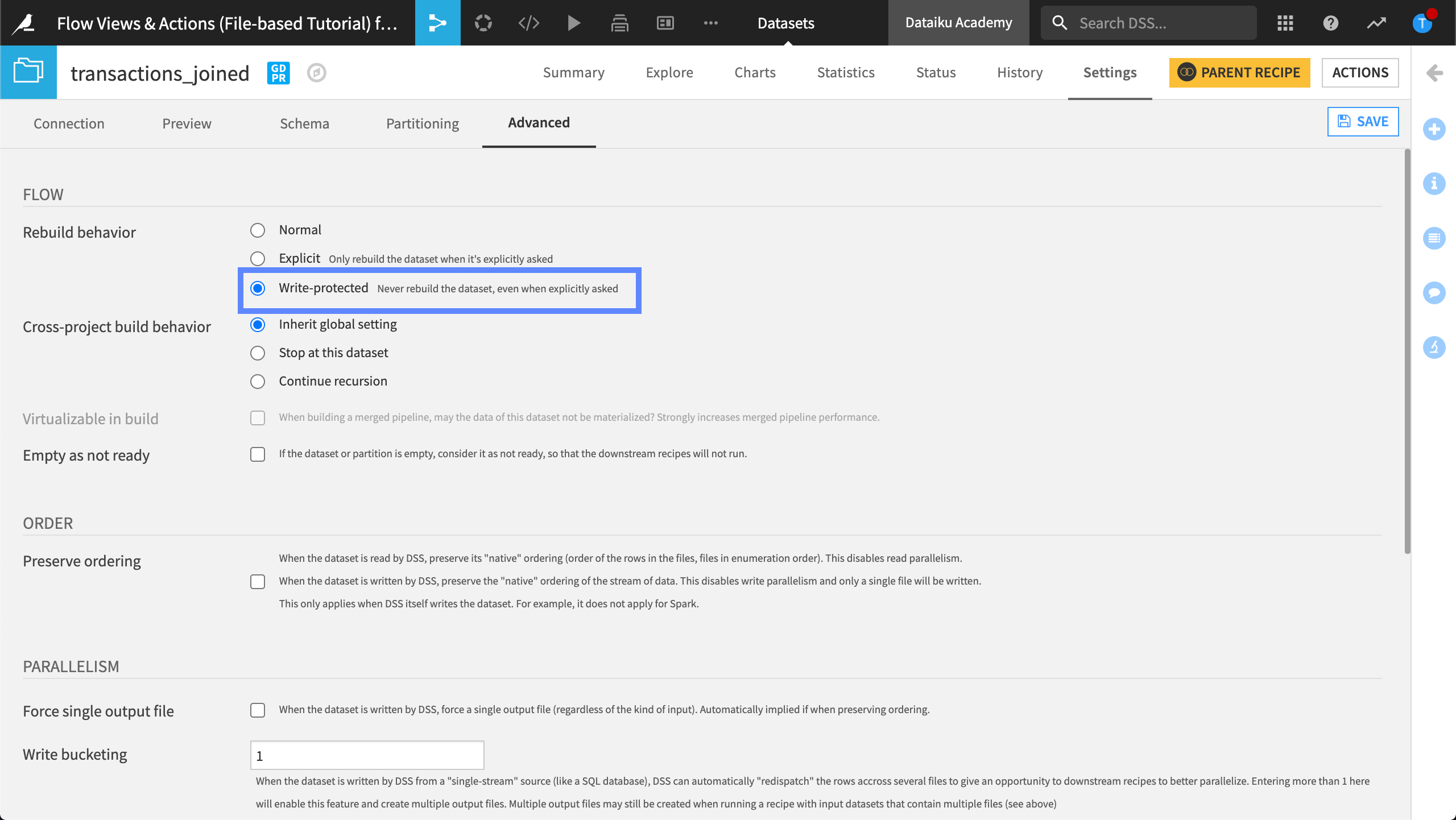
Write-protected Behavior¶
We can also write protect a dataset so that it never gets rebuilt. In this example, the dataset is “read-only”, and the only way to edit it is by writing from a code notebook.
Shared Datasets¶
When we are using a shared dataset in our Flow, the dataset can only be built from the Flow where it was created— that is, from its source project.
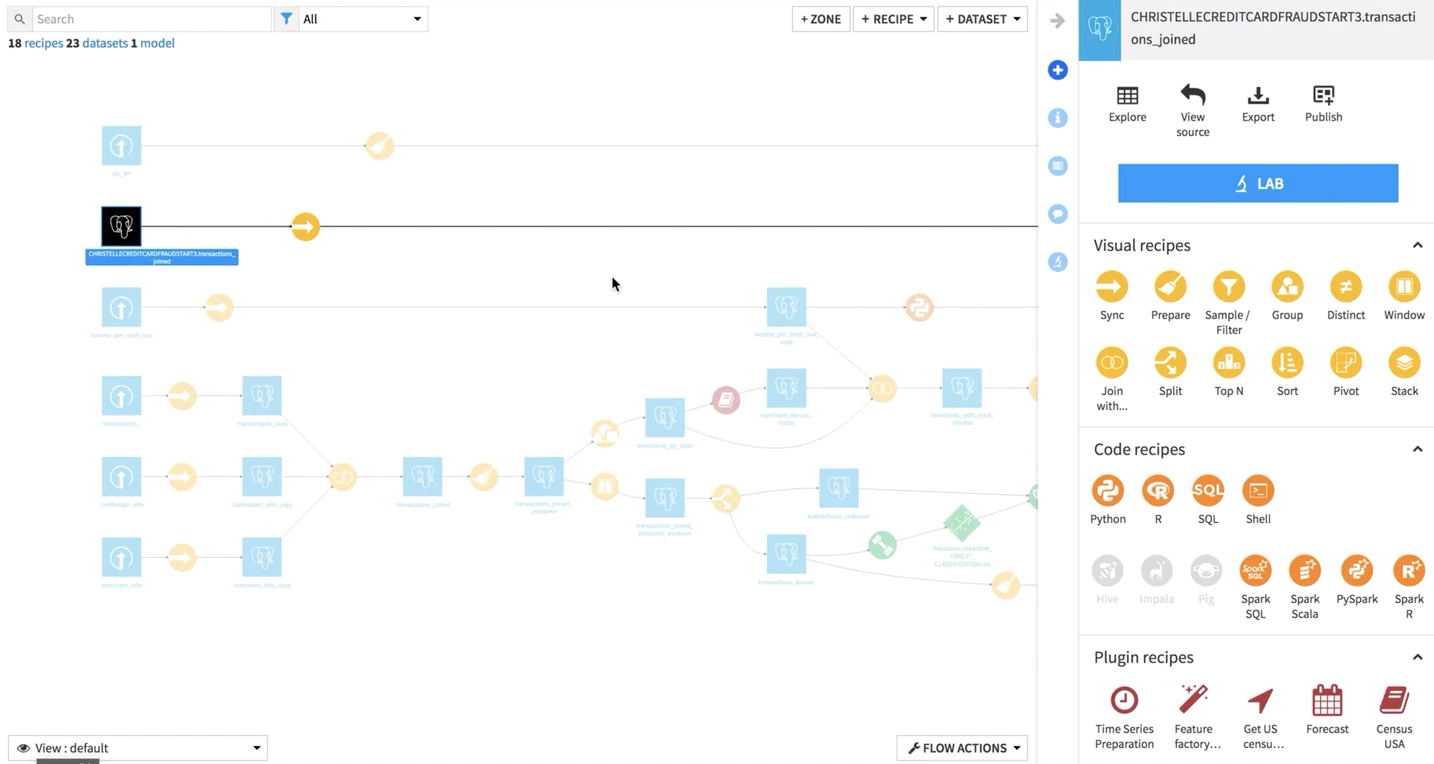
Selecting any of the “recursive build” options from our current project, including Forced recursive build, will not build a shared dataset in a Flow outside of its source project. In other words, the recursive build only builds the datasets that are created in the current project.
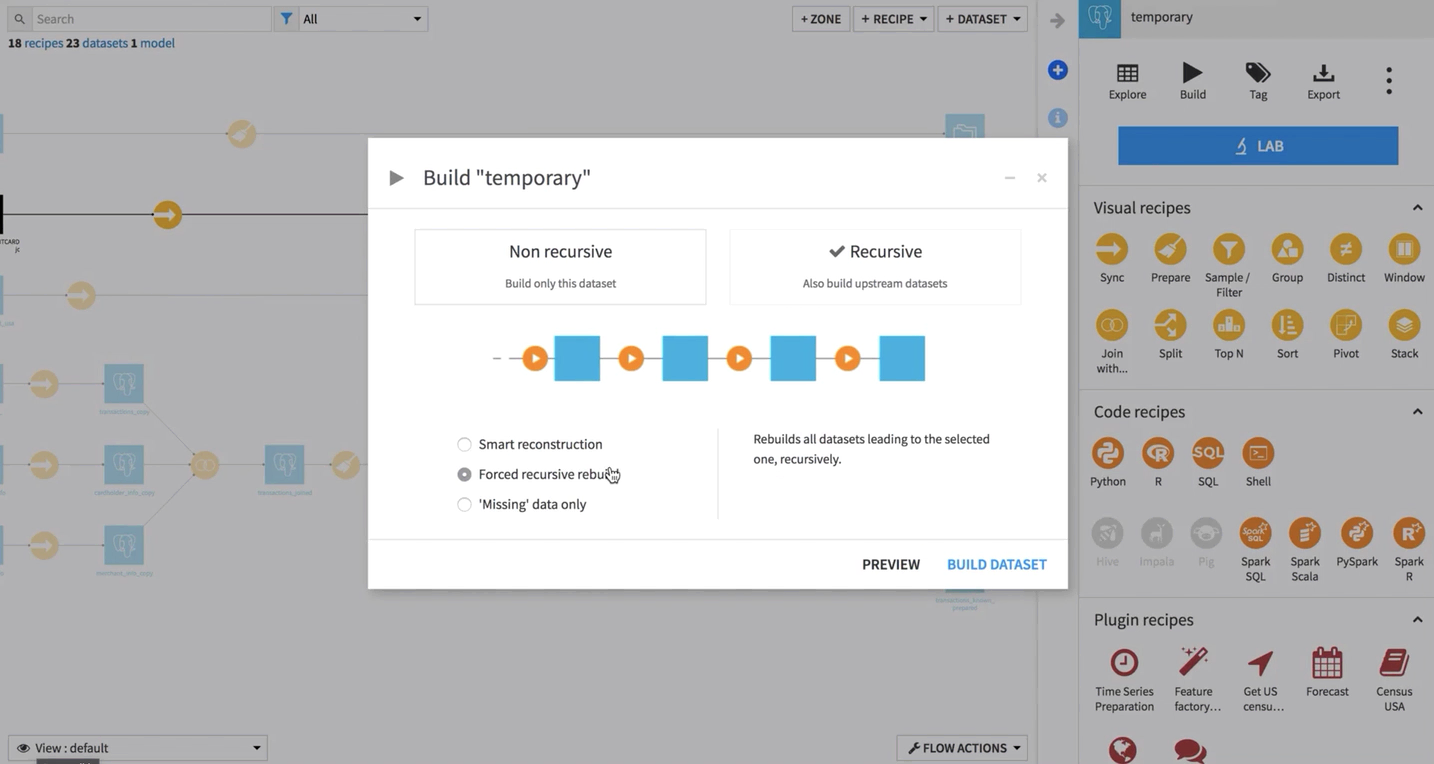
Indeed, the job log shows that only one activity is run, without any impact on the source project of the shared dataset.
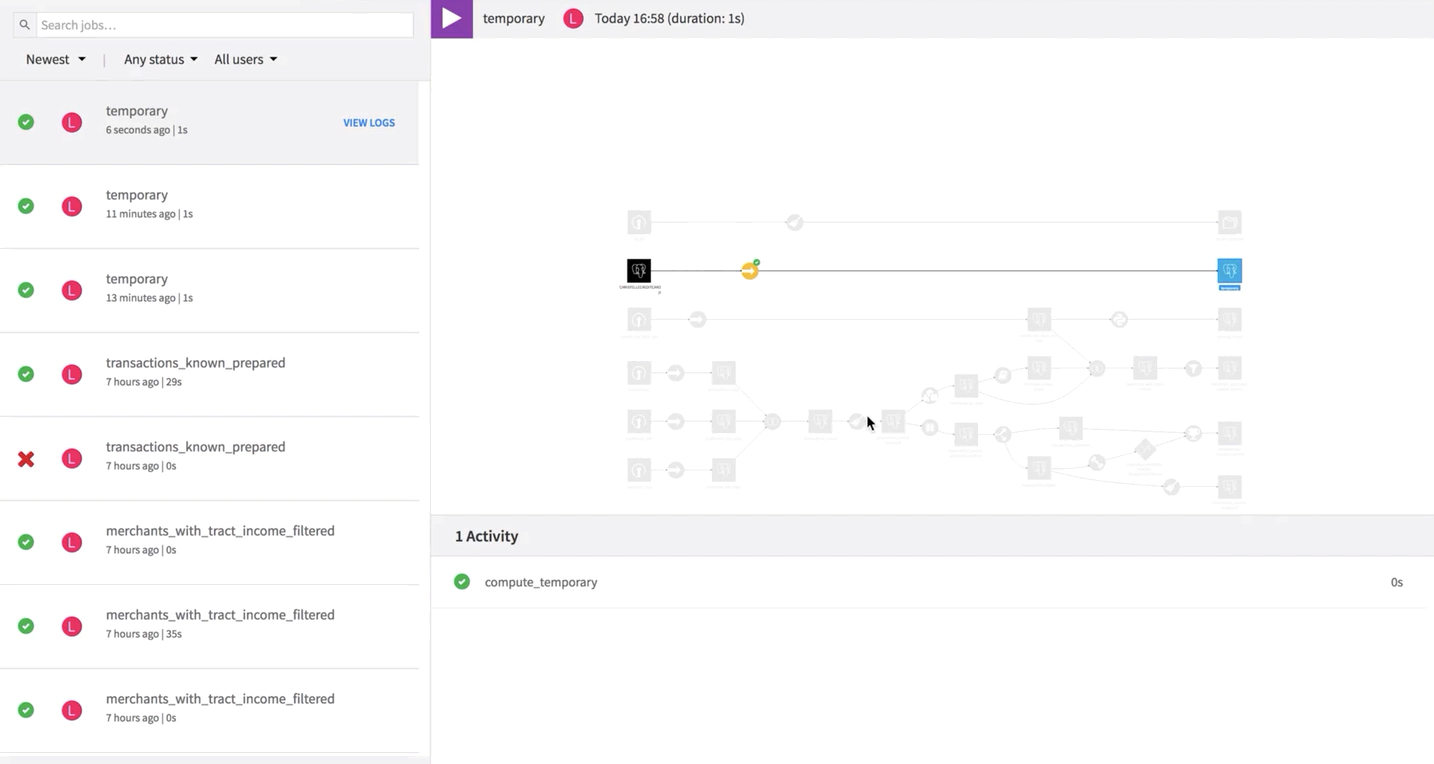
In contrast, if we build this “shared dataset” from the Flow of the source project, any changes to the dataset are reflected in the source project as well as any other projects to which the dataset has been shared.
Building From the Flow¶
We can build all the downstream datasets relative to a particular recipe or dataset, right from the Flow. To do this, we use the Build Flow outputs reachable from here option. Using this option, the selected dataset and downstream datasets along its branches get built according to the specified way for handling dependencies.
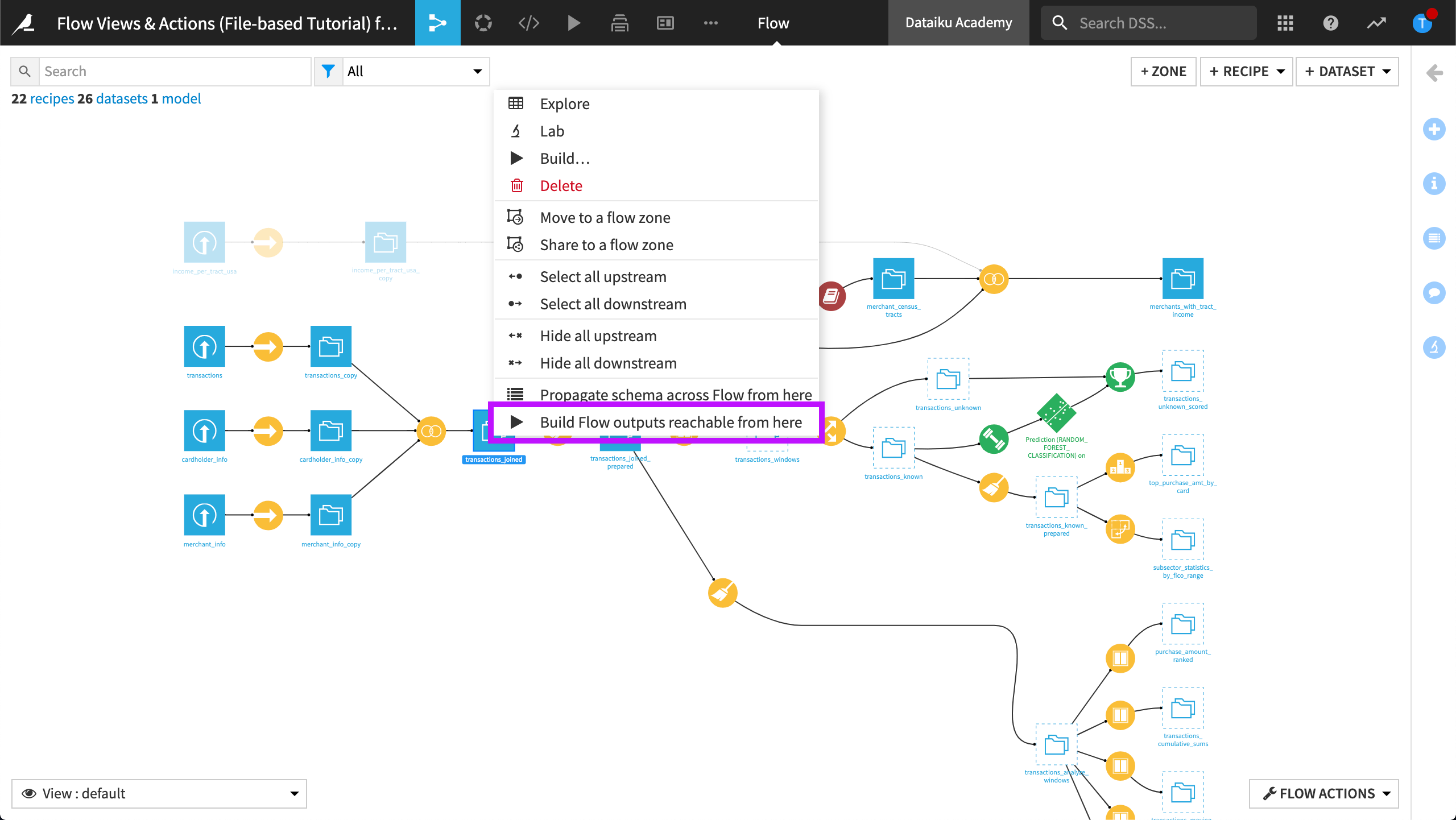
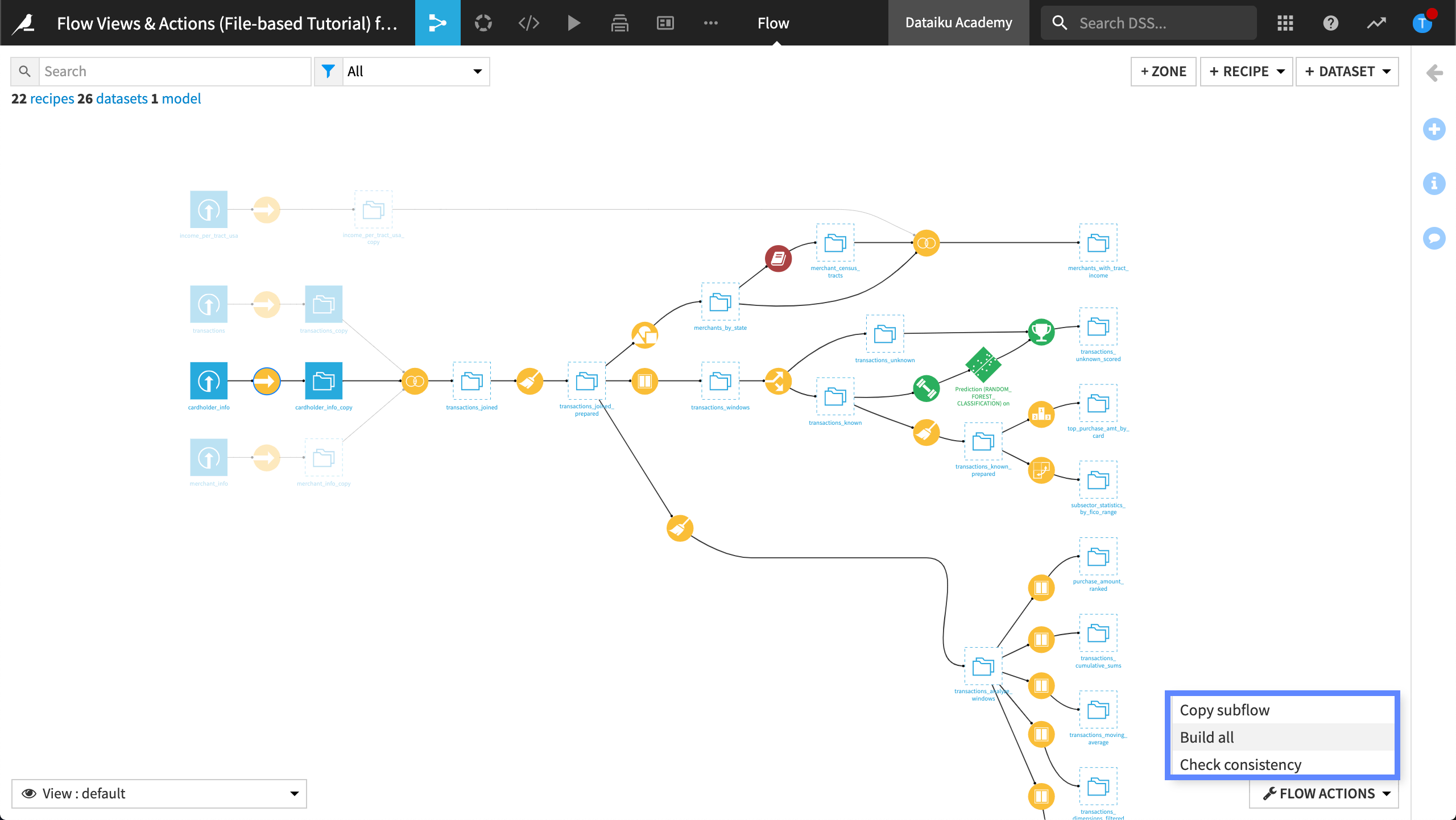
Building from the Flow Actions Menu¶
Finally, we can use the Flow Actions menu, and select Build all to quickly build the entire Flow at once. This option can be particularly useful if we have imported a project and we want to build all its datasets for the first time.
Learn More¶
Congrats on discovering the different ways to rebuild a Flow and how dependencies impact the build!
To learn more about Flow Views & Actions, including through hands-on exercises, please register for the free Academy course on this subject found in the Advanced Designer learning path.
The product documentation also contains more information about dataset rebuilding strategies.