Deep Q-Learning¶
In the previous tutorial, Q-Learning (Exploration), we learned about Q-Learning. We also implemented a Q-learning function to create and update a Q-table for a game. An agent could then use the Q-table as a “cheat sheet” to decide the best action to take at each step in the game.
Today we will explore some of the newest techniques in Q-Learning by leveraging Deep Learning. Our task will be to learn how to keep a cartpole at equilibrium. For that we’ll use DSS RL’s plugin to train a Deep Q-Learning (DQL) agent.
This article is a high-level overview of DQL. If you want to learn more about the theory you can see Reinforcement Learning (Sutton & Barto).
Objectives¶
In this tutorial, you’ll learn the following:
The fundamentals of Deep Q-Learning (DQL)
How to implement DQL with the RL Plugin in DSS
Adding Deep to Q-Learning¶
In the Q-Learning tutorial, we saw how an agent learned to use a Q-Table for selecting the best action to take at each step in the game. You can think of this Q-table as a “cheat-sheet” that helps us to find the maximum, expected future reward of an action, given a current state.
Using a Q-Table, as described, is a good strategy; however, this strategy is not always scalable.
Imagine a game like a 3D FPS (first-person shooter), a large environment with a huge state space (millions of different states). Or think about an agent that must define the price of an airline ticket based on millions of information (e.g., weather, date, number of empty seats, competition), hence, a big state size. Creating and updating a Q-table for such environments would be extremely inefficient, as there are millions of possible states.
An alternative strategy is to use a neural network. For a given state, this neural network can approximate the different Q-values for each possible action at that state. Because the neural network will approximate the Q-values, it can also generalize to unexplored states. This type of neural network is called a Deep Q Network (DQN).
Consequently, the neural network requires only a “state” as the input to return a Q value for each possible action at the state. This single input is in contrast to a Q-Table — you need to provide both the state and the action to return the Q value.
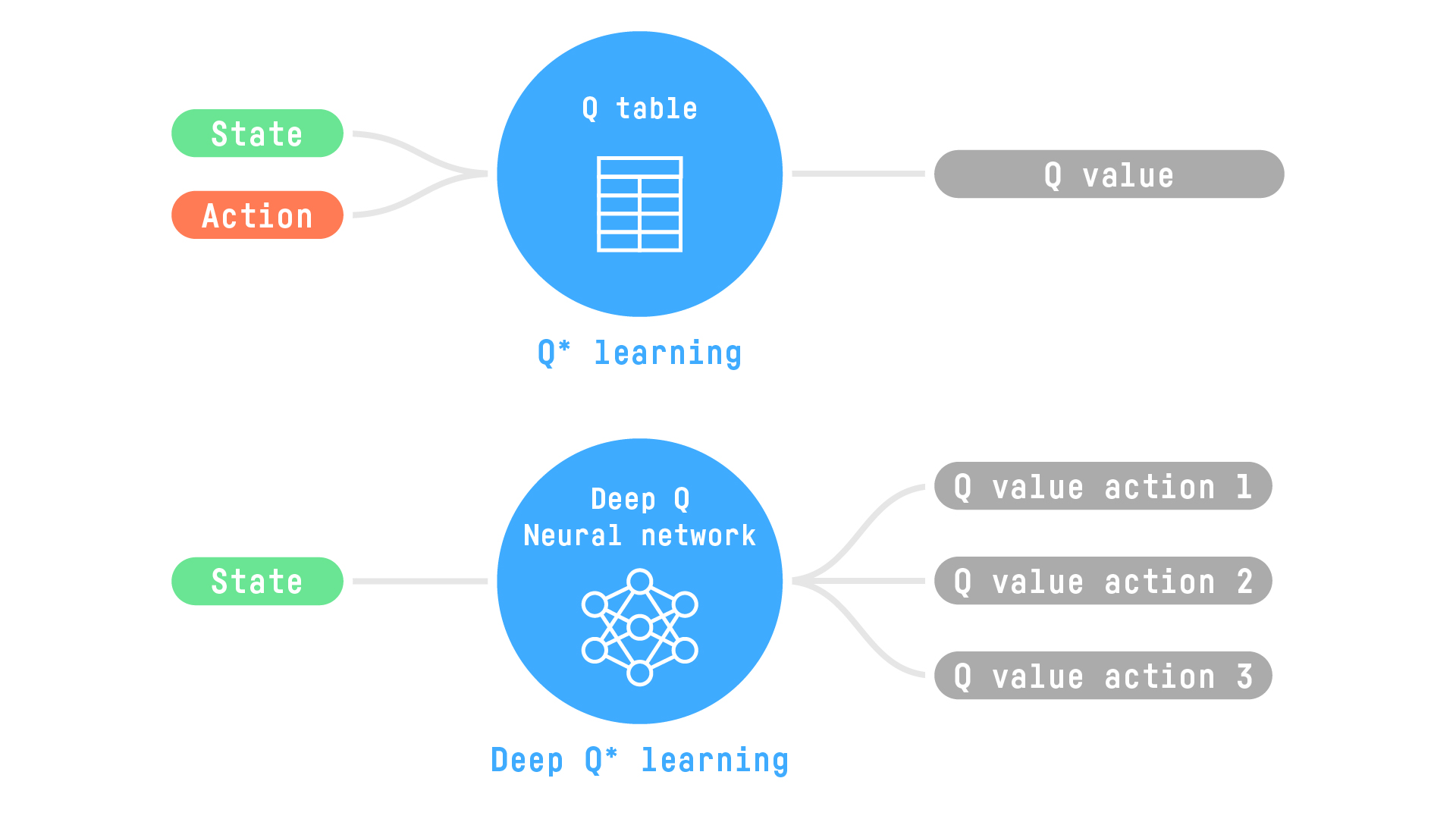
As an example, consider a video. In this case, the input to our DQN is a frame (or stack of frames), and the predicted outputs of the network are the Q-values of the possible actions.
Deep Q Networks With DSS¶
Now that we have an understanding of Deep Q-Learning, let’s use the RL plugin in DSS to train an agent to play Cartpole.
Cartpole is an environment from the OpenAI gym — a library that allows you to use small and simple environments to see if your agents are learning.
In Cartpole, you control the cart (by pushing it left or right), and the goal is for the pole to stay in equilibrium. For any given situation, your agent must be able to know what to do. The agent wins (+1) at every time step that the cartpole stays in equilibrium, and it loses (-100) otherwise.
Create Your Project and Prepare your Folders¶
Create a new project and give it a name like: Deep Q-Learning with DSS.
Create two folders in the Flow. From the + Dataset dropdown, select Folder. Name the folders:
Saved Model to contain the saved model and a JSON containing the training information.
Replay elements to contain a JSON with the testing information.
You’re ready to use the RL plugin.
Train your agent¶
From the + Recipe dropdown, select Reinforcement Learning > Train.
In the recipe dialog, select Saved Model as the saved models folder. Then click Create Recipe.
In the Training dialog, you have access to a lot of hyperparameters. Hyperparameters are variables that we need to set before applying a learning algorithm.
First, select the environment with which your agent will interact.
For “Environment library”, select OpenAI gym.
For “Environment”, select Cartpole v1.
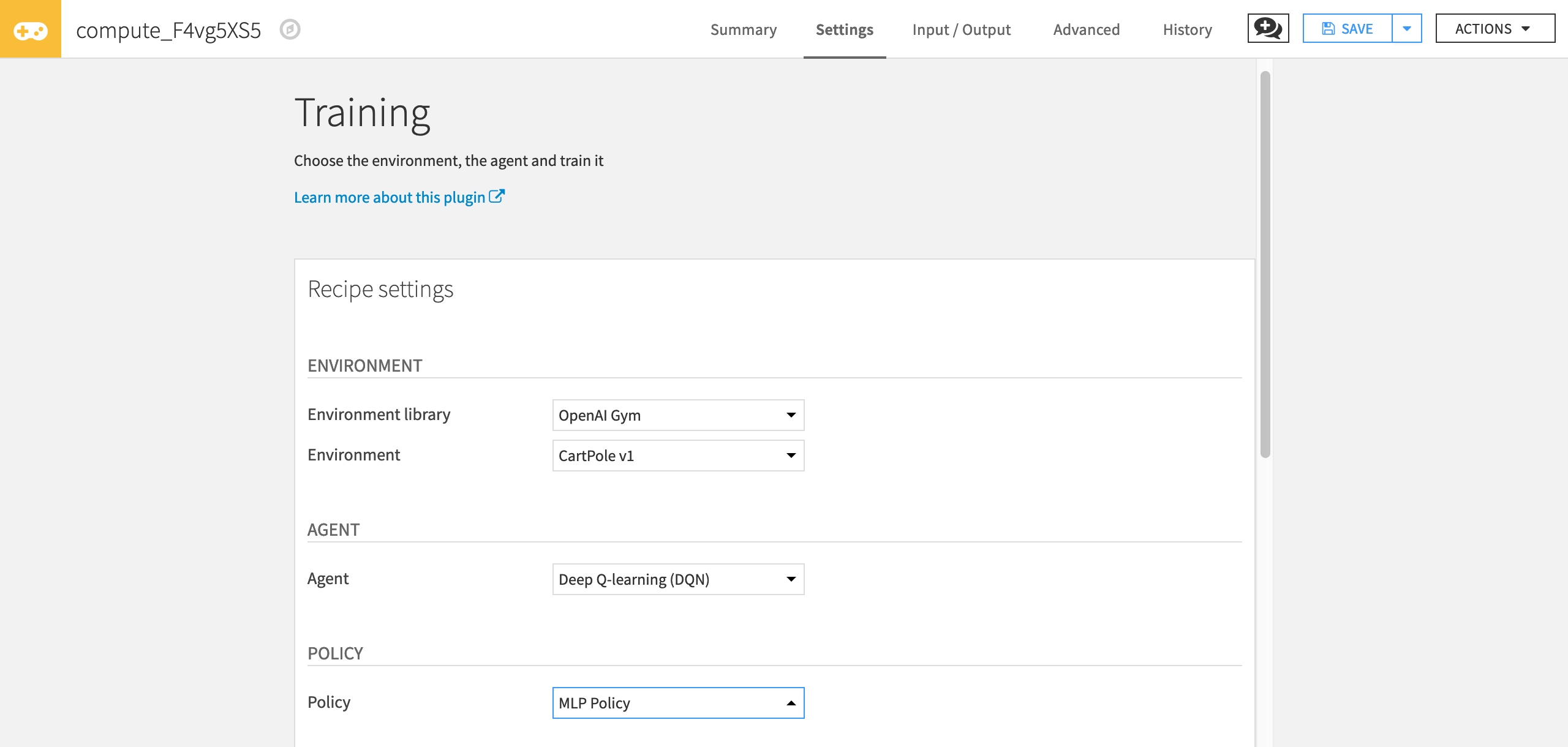
Then, select the agent you want to use (in our case Deep Q-Learning Agent).
For “Agent” select Deep Q-Learning.
Next, select the policy.
For “Policy” select MLP Policy.
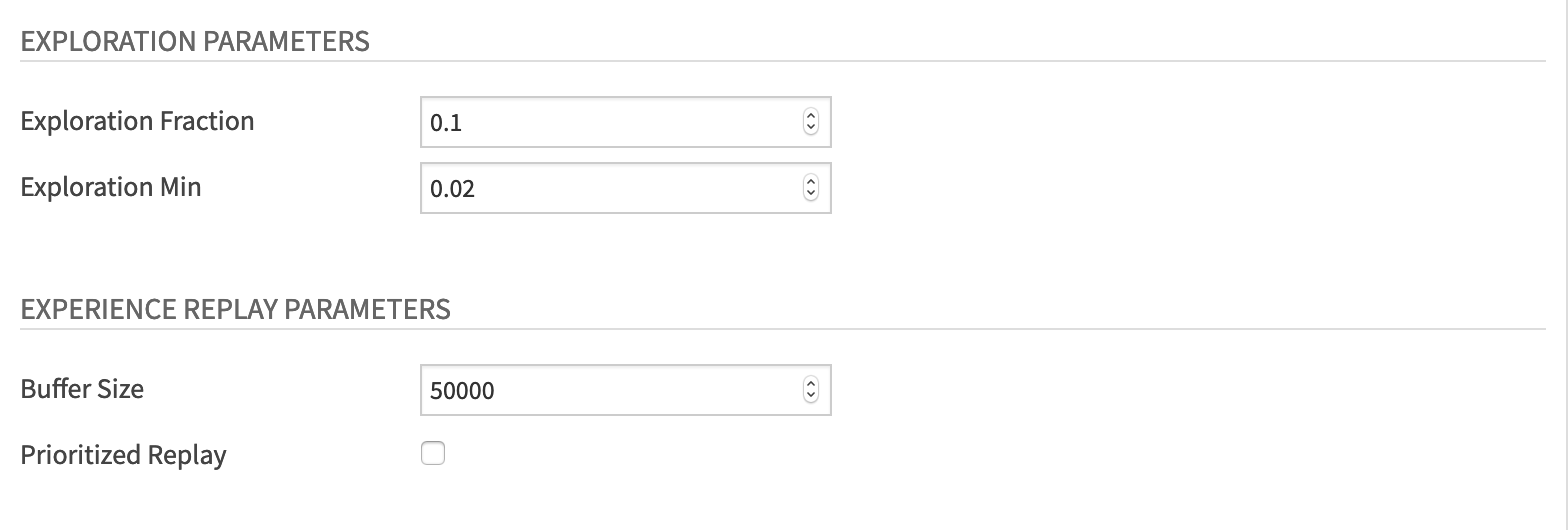
Set the following values for the Exploration Parameters:
In “Exploration Fraction”, the exploration decay rate, set the value to 0.1.
In “Exploration Min”, set the value to 0.02.
And set these values for the Experience Replay parameters:
“Buffer Size” to 50000
Uncheck “Prioritized Replay” checkbox. We will explain and use this notion in the chapter about improvements in Deep Q-Learning.
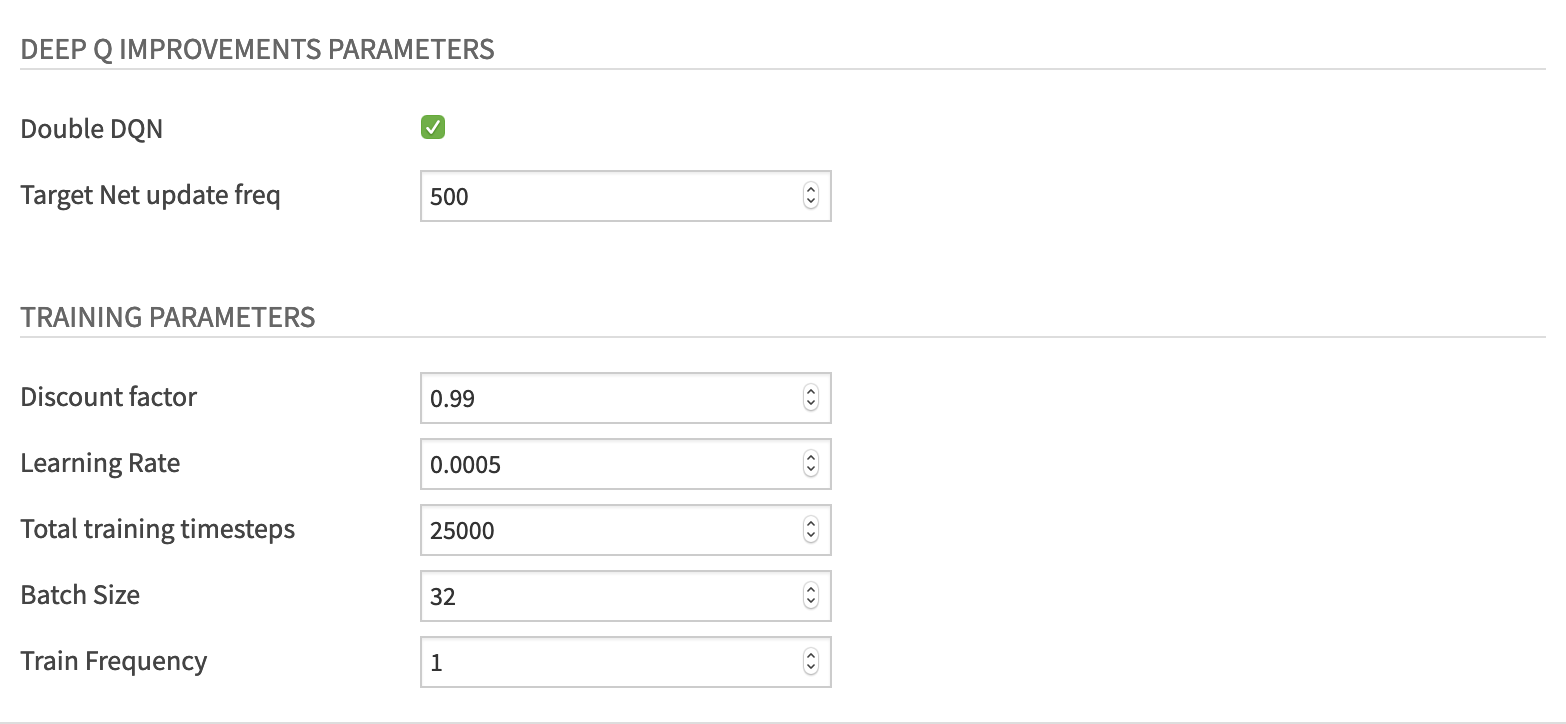
For the Deep Q improvements parameters:
Check the “Double DQN” checkbox
Set “Target Net update freq” to 500
For the Training parameters, set:
“Discount factor” to 0.99. Recall from the previous tutorial, that this hyperparameter allows our agent to focus more or less on long term rewards. The closer this value is to 1, the more our agent focuses on the long term reward.
“Learning Rate” to 0.0005
“Total training timesteps” to 100000
“Batch Size” to 64
“Train Frequency” to 1.
Finally, click Run to train the agent.
Test your agent¶
Now that you’ve trained your agent, let’s test its performance. To do this, begin by clicking the +Recipe dropdown menu and selecting Reinforcement Learning > Test.
In the recipe dialog, select Saved Models as the “Saved Models” folder, and Saved Replays as the “Saved Replays” folder. Then click Create.
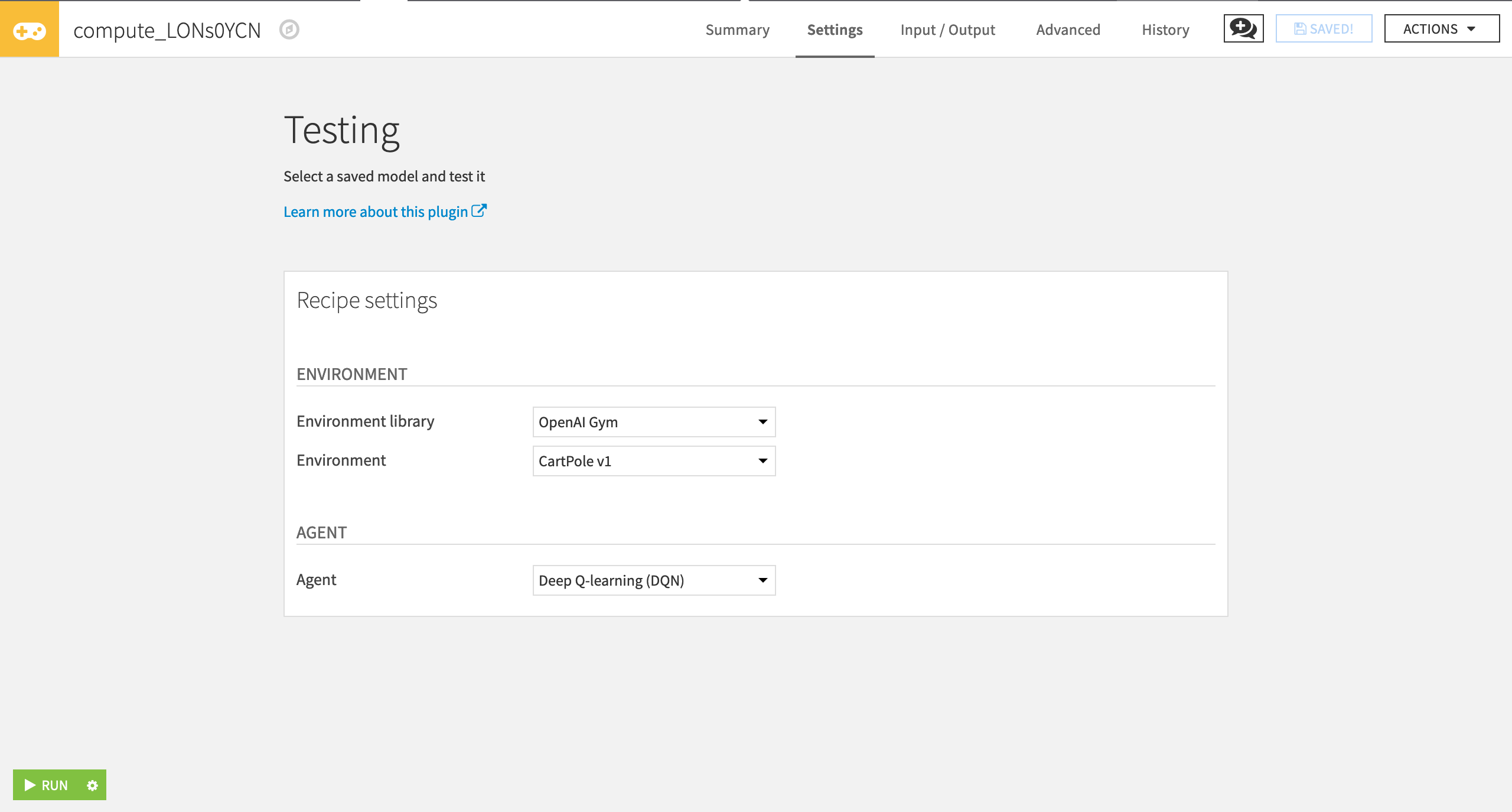
In the Testing window, specify the following values:
“Environment library” as OpenAI Gym
“Environment” as Cartpole v1
“Agent” as Deep Q-learning (DQN)
Click Run.
Display the results of the testing¶
Now you can use the RL web app to visualize the testing results. To do this:
Go to the Code menu > Webapps and then select +New Webapp > Visual Webapp > RL Agent Testing Results.
Name the web app and click Create.
Next, select the Replay Folder that contains your testing JSON file.
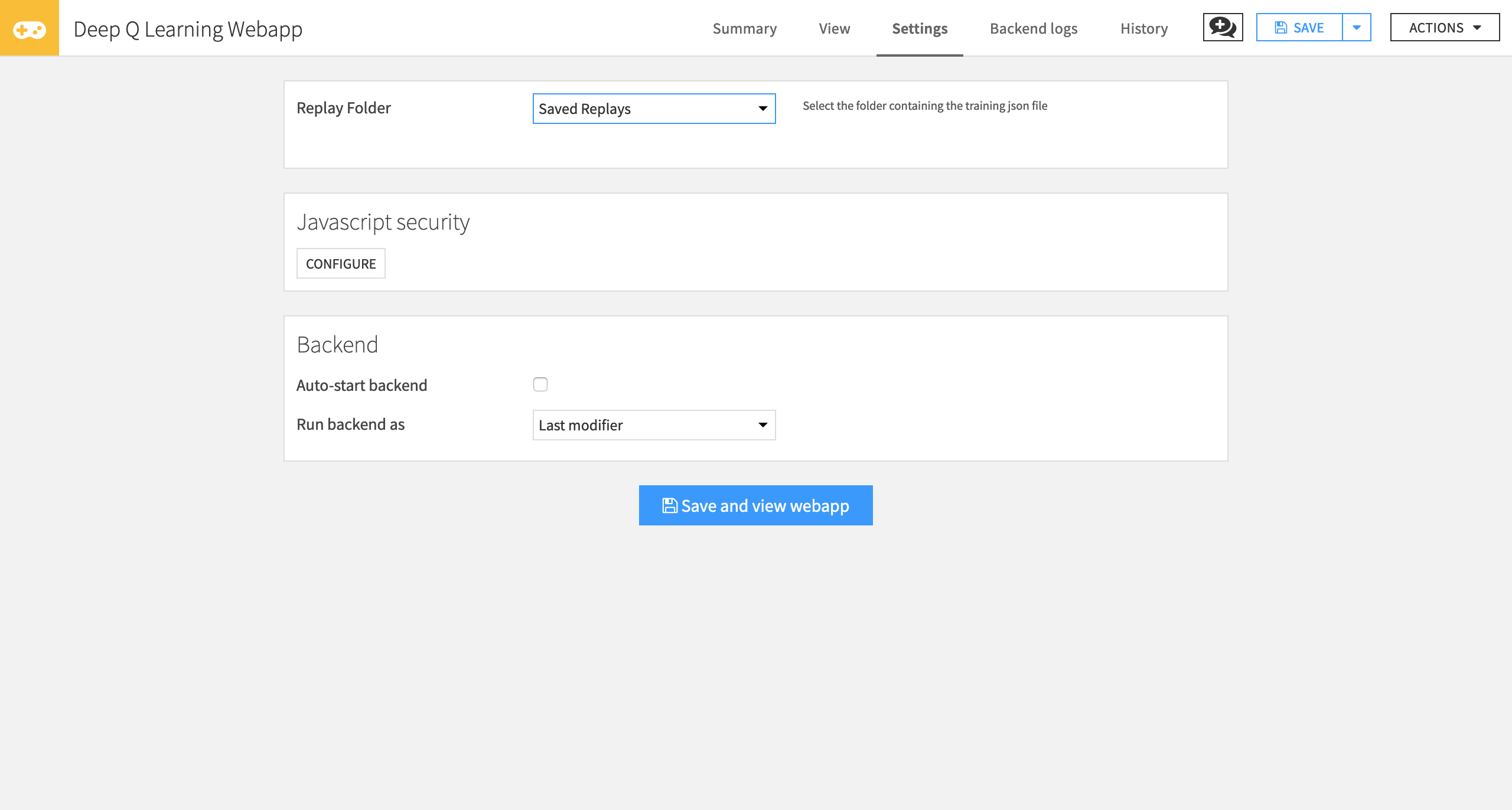
Click Save and view webapp.
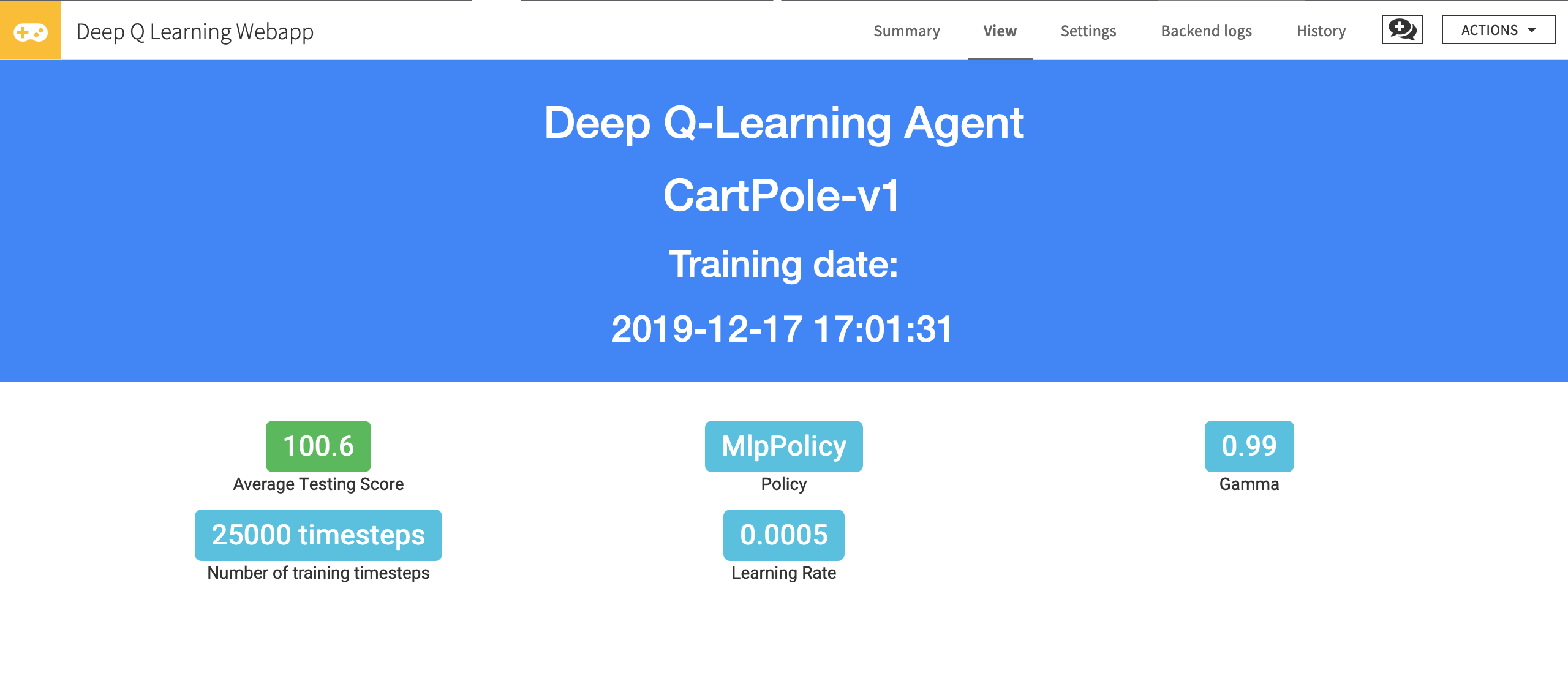
You can now see the average testing score and training hyperparameters.
Conclusion¶
That’s it! You’ve just trained an agent that learns to play Cartpole using Deep Q-Learning.
Now, try to change the hyperparameters to see if you can obtain better results.
Remember that the best way to learn is by doing, so try with other environments (for instance, use MountainCar v0, an environment where your car needs to climb a mountain). Change the hyperparameters, and have fun!
Next time we’ll create a new agent using the Policy Gradients methods.