Sentiment Analysis in Dataiku DSS (Plugin)¶
Binary Sentiment Analysis is the task of automatically analyzing a text data to decide whether it is positive or negative. This is useful when faced with a lot of text data that would be too time-consuming to manually label. Dataiku provides a plugin that allows you to compute binary sentiment scores for English text data.
Objectives¶
We will show you how to:
Install the sentiment analysis plugin
Compute sentiment scores for text data
Prerequisites¶
We will be working with IMDB movie reviews. The original data is from the Large Movie Review Dataset, which is a compressed folder with many text files, each corresponding to a review. In order to simplify this how-to, we have provided a single csv file for download.
Install the Plugin¶
First you need to install the Sentiment Analysis plugin. This requires Administrator privileges on the Dataiku DSS instance.
Create Your Project And Prepare The Data¶
Create a new project and give it a name like IMDB Sentiment Analysis. In the flow, create a files-based dataset and upload the CSV file you downloaded earlier.
The dataset has three columns, one containing the text of the review, one containing the rating given by the customer on a 1-10 scale, and one containing a mapping of that rating to sentiment polarity. When a text is positive we say that it has a polarity of 1, otherwise we say it has a polarity of 0.
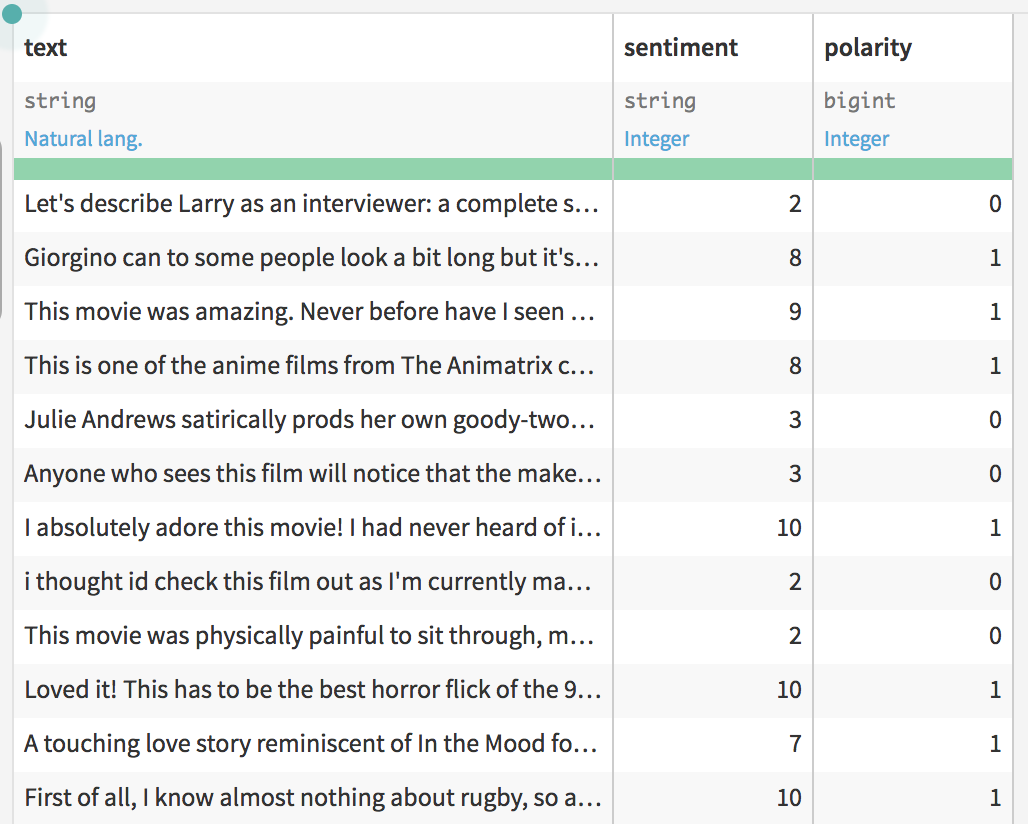
Let’s predict the sentiment of these reviews and then compare the predicted sentiment polarities with the actual values to get a sense of how the plugin works and how well it does.
Compute Sentiment Scores¶
In the project Flow, click on +RECIPE then select the Sentiment Analysis plugin.
Select the recipe “Compute sentiment scores”, specify an input dataset where the reviews can be found, and specify an output dataset.
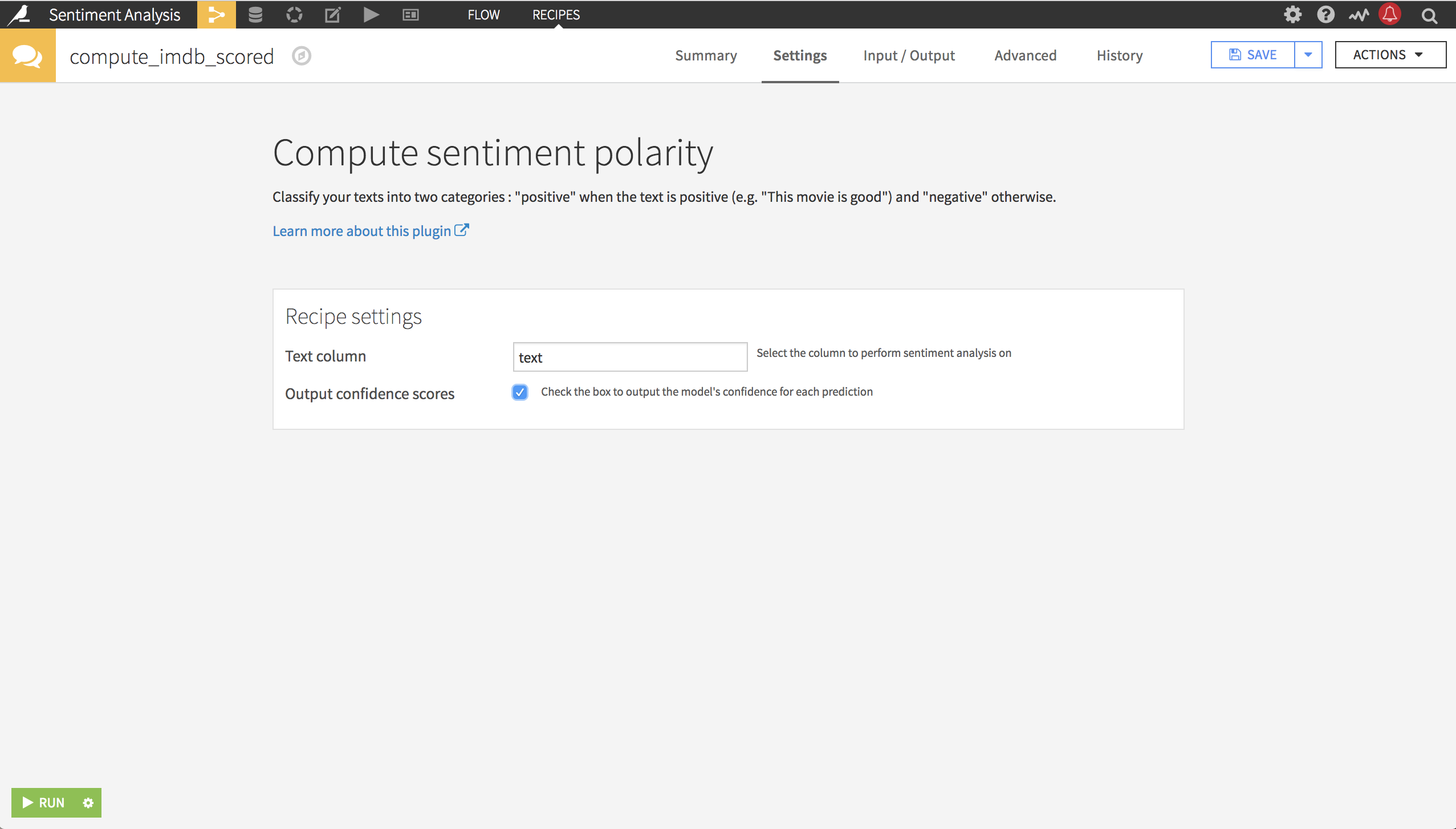
After creating the recipe, you can run it by simply selecting the column containing the texts (here, our movie reviews). Also set the Output confidence scores checkbox, which outputs the model’s confidence on each prediction as a new column. Then click Run.
After a few seconds, the plugin outputs a copy of the original dataset with 2 additional columns:
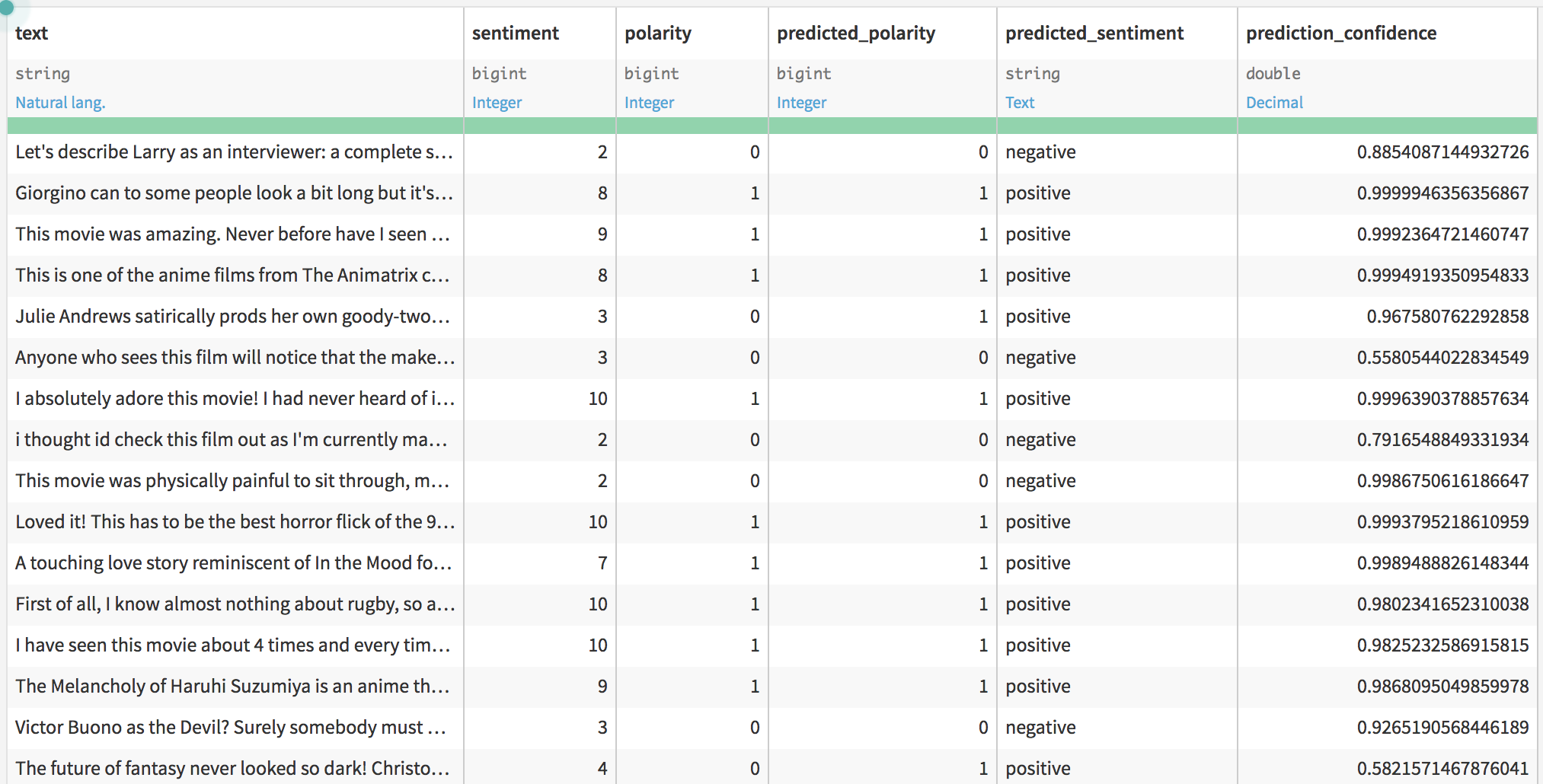
You can see that the plugin is sometimes right in its predictions and sometimes wrong. To get a better idea of how well the plugin did on our task, let’s compute an accuracy score (the number of good predictions over the number of reviews). To do that we go to “Status > Edit” and create a new Python Probe, using the following code as the metric:
def process(dataset, partition_id):
df = dataset.get_dataframe()
prediction = df["predicted_sentiment"].values == "positive"
original = df["polarity"].values
return {"accuracy": (prediction == original).mean()}
Then we run this probe, save it, and get the accuracy in “Status > Metrics”:
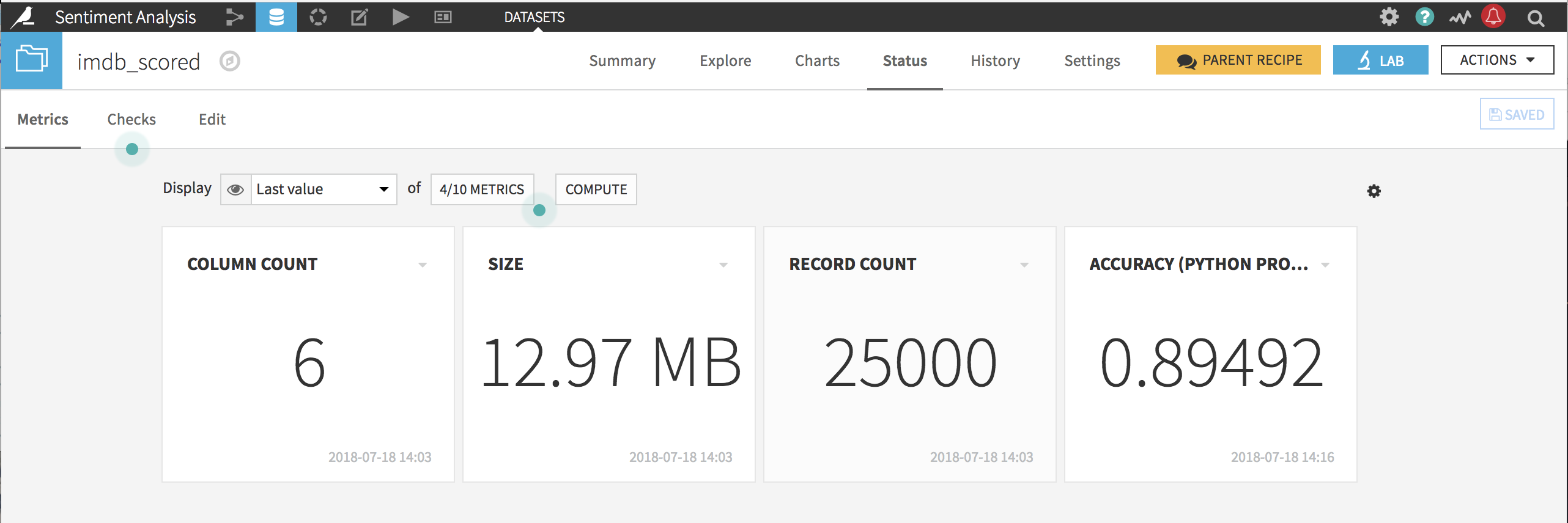
So, we can see that using the Sentiment Analysis plugin, we get ~ 89.5% accuracy over 25,000 movie reviews.
What’s Next¶
There is a Dataiku gallery project that shows a completed project using the plugin.
There is also a page dedicated to the Sentiment Analysis plugin.
You can build your own deep learning models for Sentiment Analysis using Keras and Tensorflow in Dataiku.