The AI Lifecycle: Data Acquisition¶
The Discovery stage includes three important phases, the first of which is Data Acquisition. The goal of the Data Acquisition phase is to establish connections to data sources, managing the size and speed at which the raw data changes.
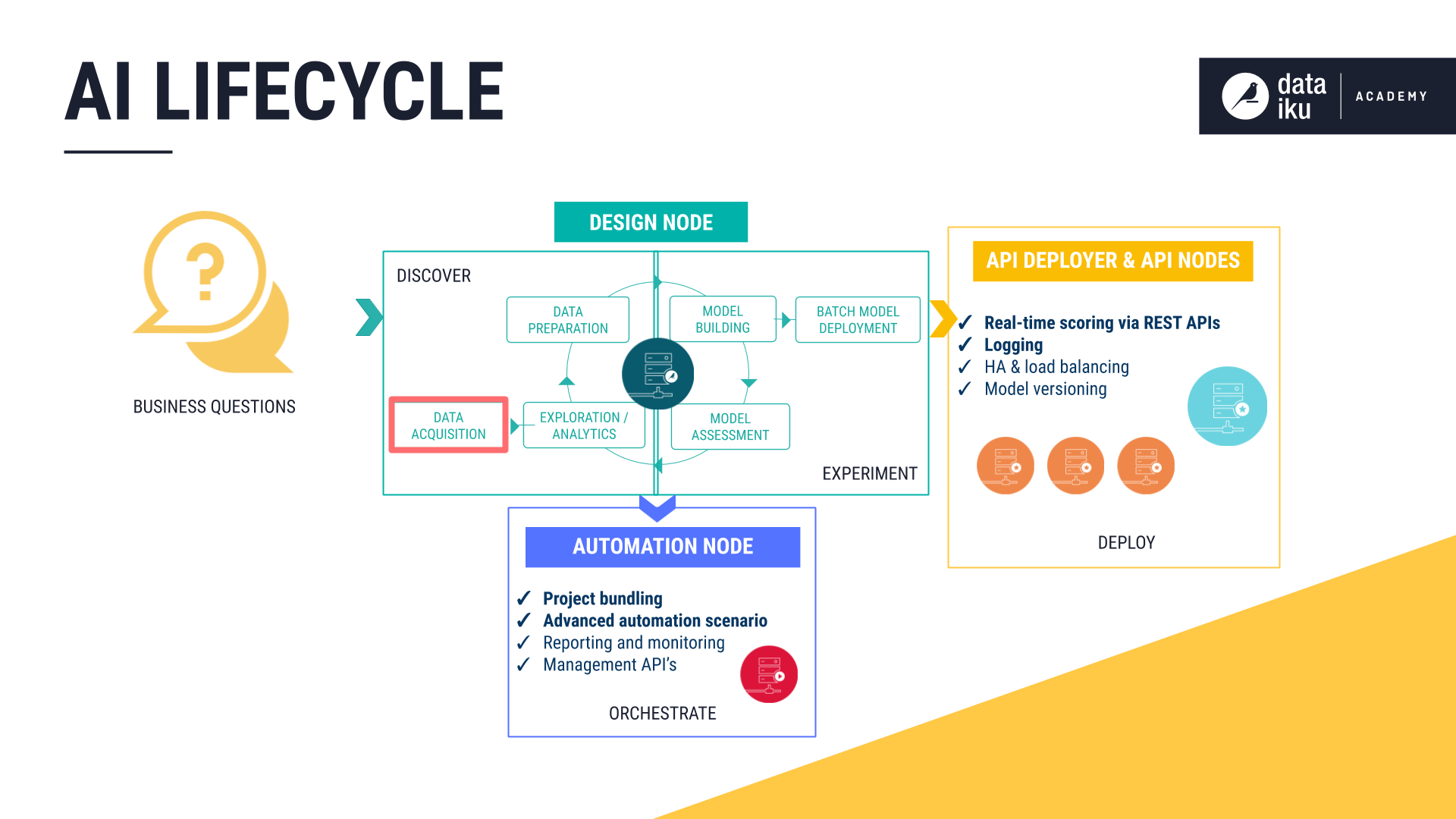
This section addresses:
The nature of datasets in DSS
How everyone can connect to existing infrastructure through the visual interface of DSS
How coders can develop custom connectors through a plugin system for the use and benefit of everyone in an organization
How DSS detects the format and schema of a dataset
Datasets in DSS¶
Before connecting to any data in DSS, it is first important to understand how DSS defines a dataset. In DSS, a dataset is any piece of data in a tabular format. A CSV file, an Excel sheet, or an SQL table are just a few examples of possible datasets in DSS.
Generally, creating a dataset in DSS means that the user merely informs DSS of how it can access the data. DSS remembers the location of the original external or source datasets. The data is not copied into DSS. Rather, the dataset in DSS is a view of the data in the original system. Only a sample of the data, as configured by the user, is transferred via the browser.
Furthermore, DSS can partition datasets. Users can instruct DSS to split a dataset along a meaningful dimension, such as date or a discrete value, so that each partition contains a subset of the complete dataset. This feature can be useful when working with large datasets or analyzing distinct subgroups.
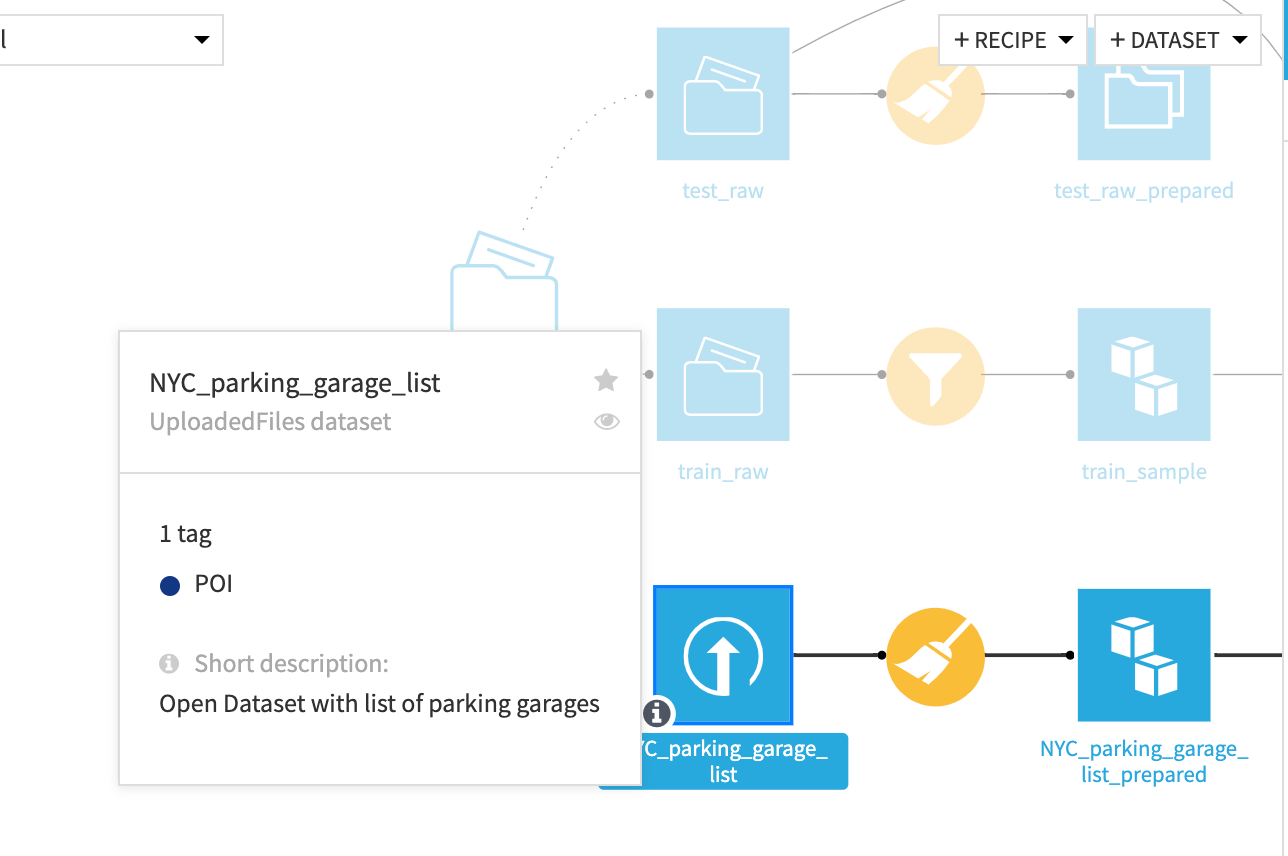
Hovering over a dataset in the Flow shows its storage system, tags, description, and more.
Connecting to Existing Infrastructure¶
Dataiku DSS allows users to natively connect to more than 25 data storage systems, through a visual interface or code. Possibilities include traditional relational databases, Hadoop and Spark supported distributions, NoSQL sources, and cloud object storage.
This means that, when taking advantage of the push-down computation strategy, DSS itself imposes no limits on datasets, based on system or server memory. A dataset in DSS can be as large as its underlying storage system allows.
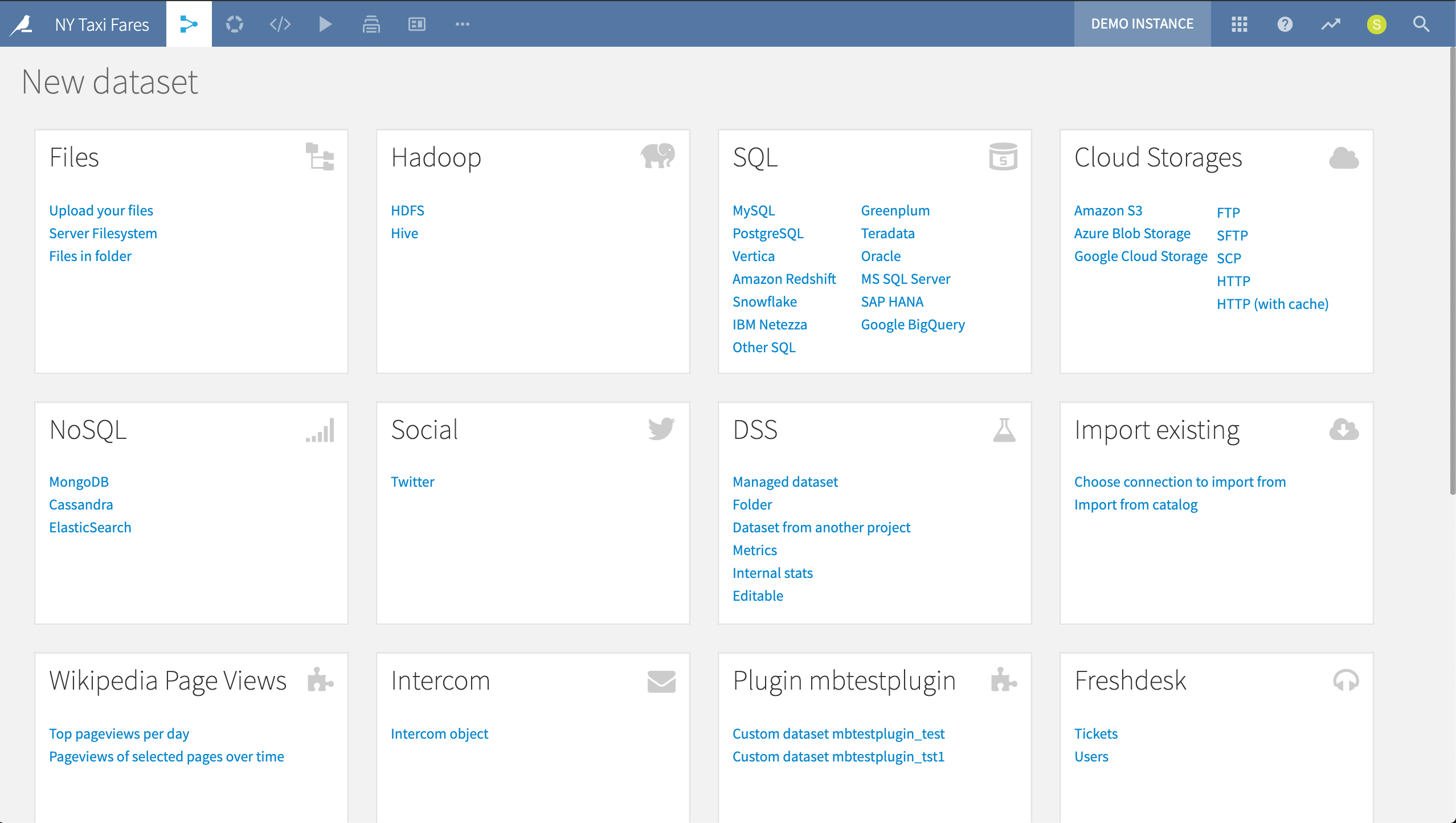
The page for introducing a new dataset to a project depends upon what storage systems have been connected to the instance. In our example, it includes data sources connected to plugins, like Freshdesk and Twitter.
According to the visual grammar of DSS, blue squares represent datasets, and the icon represents the storage system. A single visual grammar also makes it easy to remap connections to new sources when the underlying infrastructure changes.
In the Flow of the NY Taxi Fares project, we see an up arrow for an UploadedFiles dataset, two cubes for a dataset in Amazon S3, and an elephant for HDFS.
Extending Existing Connectivity¶
The list of available out-of-the-box data storage connections is always expanding. However, a core principle of Dataiku DSS is its extensibility. DSS Plugins or an enterprise’s own Python or R scripts can be used to create custom visual connectors for any APIs, databases, or file-based formats. These can easily be shared within a team or the wider community.
The Dataiku Plugin Store includes connections for sources such as Tableau, Salesforce, Microsoft Power BI, Freshdesk, and Airtable.
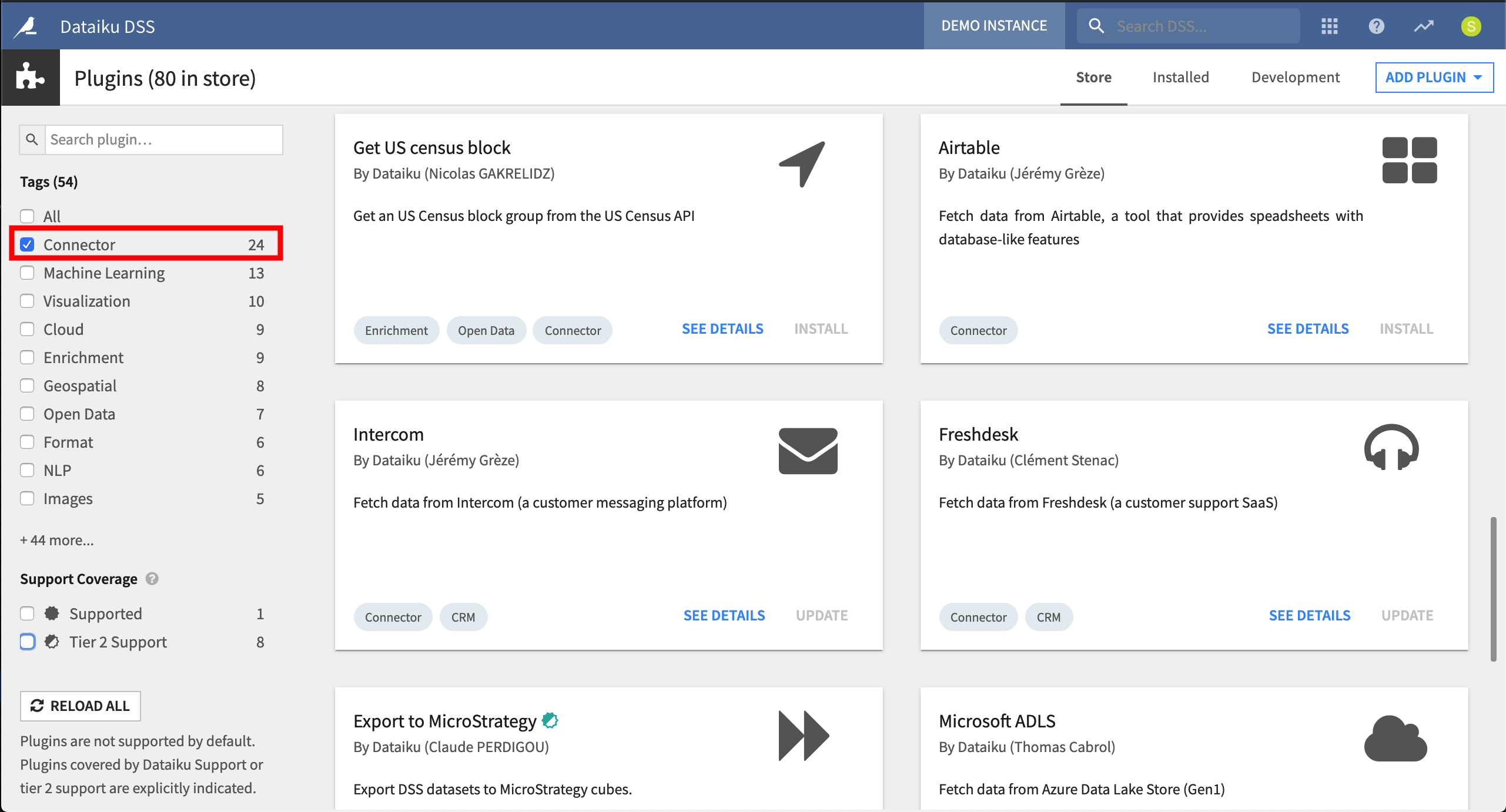
You can find a wide range of additional functionality, including custom connectors, in the Plugin Store.
Format & Schema Detection¶
When connecting to a data source, DSS automatically infers both the file format and the schema (the list of column names and types). Detailed settings for reading the data source and important properties, such as the dataset’s lineage, can be previewed and adjusted in a simple interface.
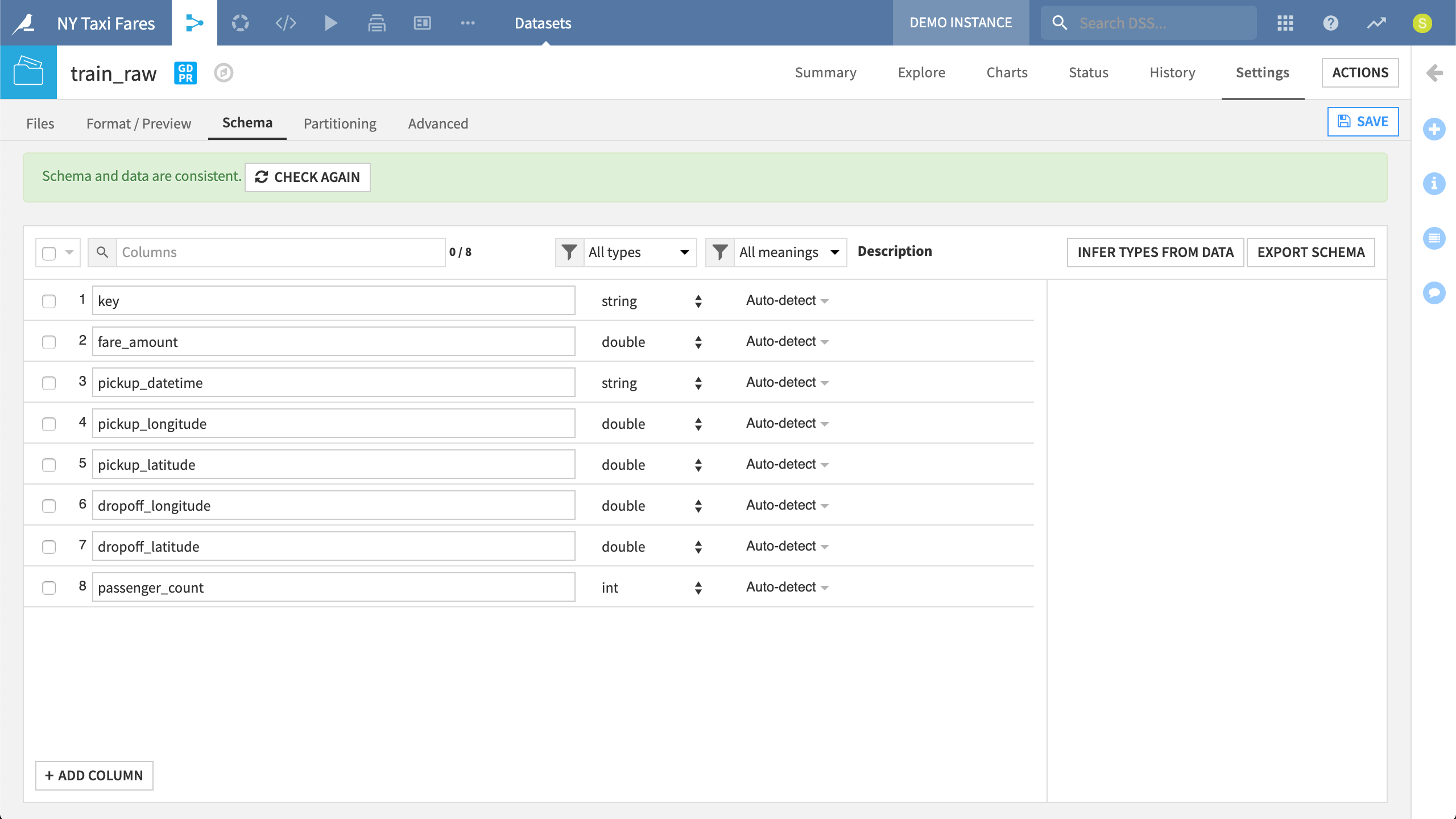
DSS automatically detects the storage type and meaning of all columns in a dataset. These settings can be adjusted from the Schema tab.
Each column in DSS has both a storage type and a high-level meaning:
The storage type indicates how the dataset backend should store the column data. Examples include categories like string, integer, float, boolean, and date.
The meaning, on the other hand, is a rich, semantic type. Meanings have a high-level definition such as IP address, country code, or URL. They are particularly useful for suggesting relevant transformations and validating rows that may not match a given meaning. Users can also define their own meanings for items like internal department codes or likert scales.
The difference between type and meaning can be seen in a dataset’s Explore tab, which is introduced just below. Under the column’s name in bold is first the storage type and then, in blue, the meaning predicted by DSS. There is also a validation gauge representing the number of rows that satisfy the predicted meaning in green.
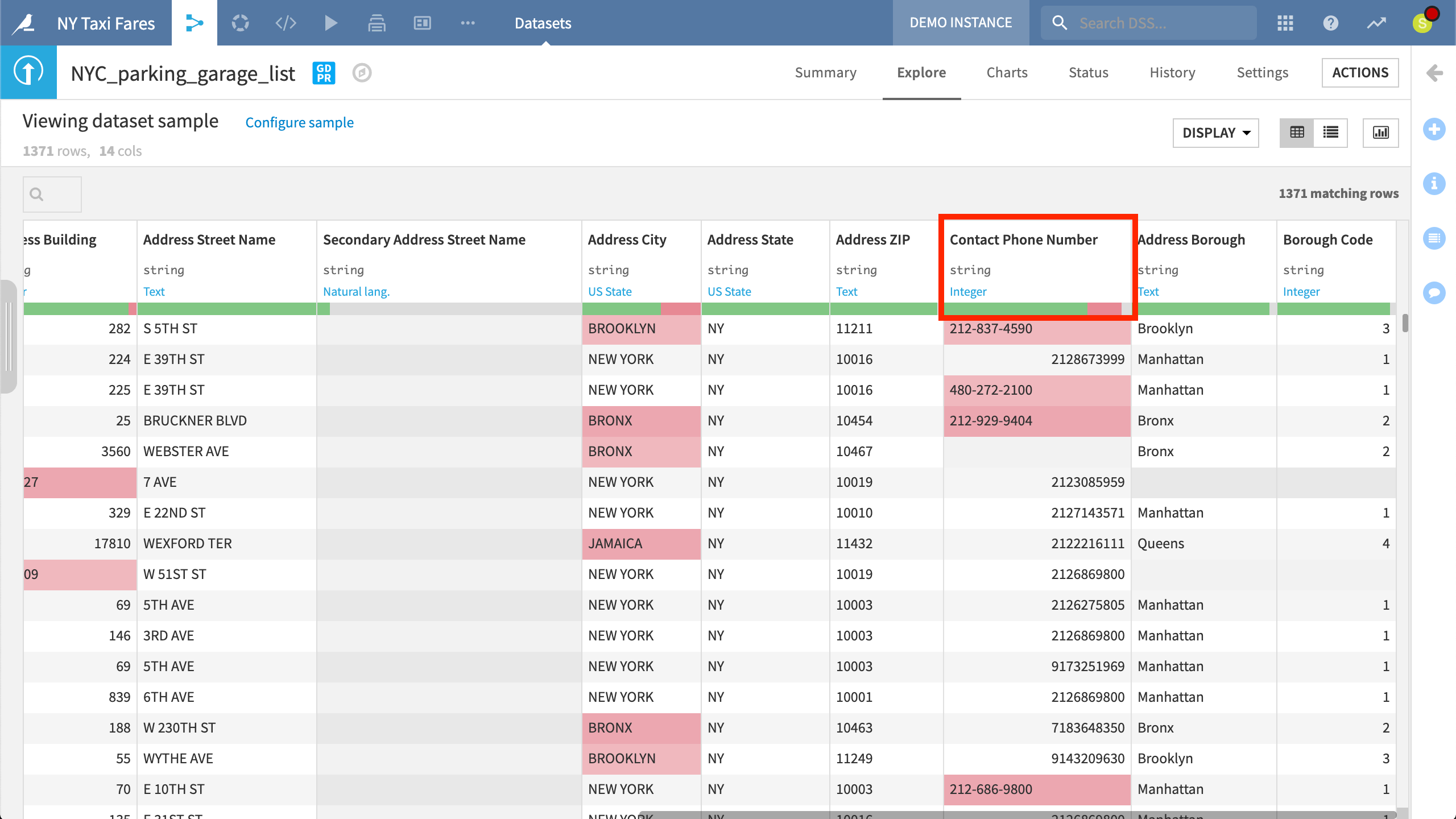
In our example, DSS has assigned a meaning of Integer to “Contact Phone Number”, but has stored it as a string because some rows do not match this expectation. Those that do not are highlighted in red.