Where does it all happen?¶
In the Dataiku DSS flow, you take datasets from different sources (SQL, file-system, HDFS) and you seamlessly apply recipes (like SQL queries, preparation scripts or computing predictions from a model). But what happens under the hood, where does the computation actually take place? In this post, we will present you succinctly the architecture behind DSS, and explain why it matters.
Overview¶
Computation in Dataiku DSS can take four main forms:
in-memory
streamed
runs in database (SQL)
runs on-Hadoop.
Which strategy is used depends on the dataset and the operation you are applying to the dataset.
Why does it matter? Well, sometimes if you apply the wrong type of recipe to your dataset, your computation will be painfully long or run out of memory! These issues particularly arise with big data.
Here is a table summarizing where the computation takes place for each operation performed in DSS:
| Locally in DSS | In Hadoop / Spark | In SQL Database | In Kubernetes / Docker | |
|---|---|---|---|---|
| Visual Preparation Design | In-memory Sample |
N/A | N/A | N/A |
| Visual Preparation Execution | YES Streaming |
YES Spark |
YES | N/A |
| Visual Recipes (other than Prepare) | YES Streaming or disk-copy |
YES Hive, Spark, Impala |
YES | N/A |
| Python and R recipes | YES In-memory or streaming |
YES PySpark, SparkR, sparklyr |
Custom code with DSS helper API | YES In-memory or streaming |
| Spark-Scala recipe | N/A | YES | N/A | N/A |
| Charts | YES | YES Hive, Impala (most charts) |
YES (most charts) |
N/A |
| Machine Learning train | YES scikit-learn, XGBoost, Keras/Tensorflow |
YES MLlib, Sparkling Water |
YES Vertica ML |
YES scikit-learn, XGBoost, Keras/Tensorflow |
| Machine Learning execution | YES scikit-learn, XGBoost, MLlib, Keras/Tensorflow |
YES scikit-learn, XGBoost, MLlib, Sparkling Water |
YES scikit-learn (partial), XGBoost, MLlib (some models), Vertica ML |
YES scikit-learn, XGBoost, MLlib, Keras/Tensorflow |
| Python, R, Scala notebooks | YES In-memory or streaming |
YES Spark-Scala, PySpark, SparkR, sparklyr |
Custom code with DSS helper API | YES |
| SQL-like recipe or notebook | N/A | YES Hive, Impala, Pig, SparkSQL |
YES | N/A |
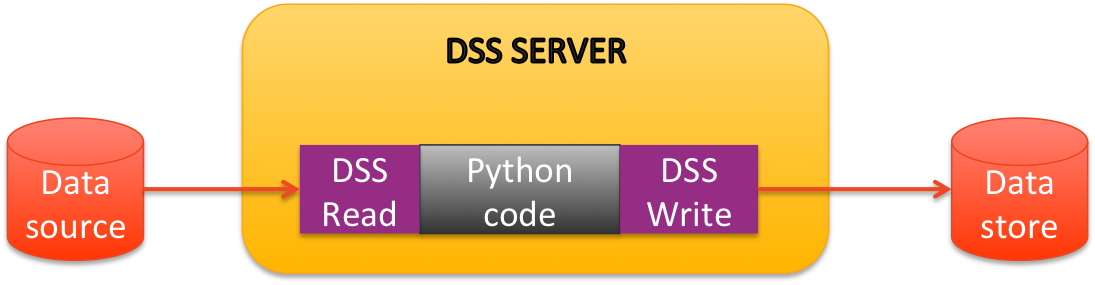
Some rules are clear and easy to understand. Take a SQL recipe. First, remember that the input datasets of your SQL recipe must be in a SQL database. When you hit run in the SQL recipe, DSS will send a query to the SQL database: read the input datasets, perform the SQL query, and finally write the output dataset if it is a SQL dataset, or streams the output otherwise.

So the computation actually runs in-database. Same idea for Pig and Hive recipes, but here applied to HDFS datasets, and everything runs in-cluster.

DSS does not solely act as a server, sending queries to a SQL-database or a Hadoop-cluster. It also performs computation, what we called the DSS engine, which uses two main strategies:
in-memory; the data is stored in RAM
streamed; DSS reads the input dataset as a stream of rows, applies computations to the rows as they arrive, and writes the output datasets row per row.
The DSS engine also uses a third strategy for charts, but this a particular topic that is well-explained in the documentation.
In-memory processing¶
By concept, in-memory computation can lead to out-of-memory situations on large datasets.
When can this annoying situation actually happen in DSS? As you can see in the above table, in-memory computation can happen in the following situations;
Python and R recipes
Editing a preparation recipe (or analysis)
Training a machine learning model
Visual data preparation¶
When you are editing a preparation script, DSS actually samples the dataset to ensure that the design computations will fit in RAM.
In a preparation script, you can add any processor and the editor is always fast and responsive, no matter the size of the original dataset because the computation is done only on a small sample.
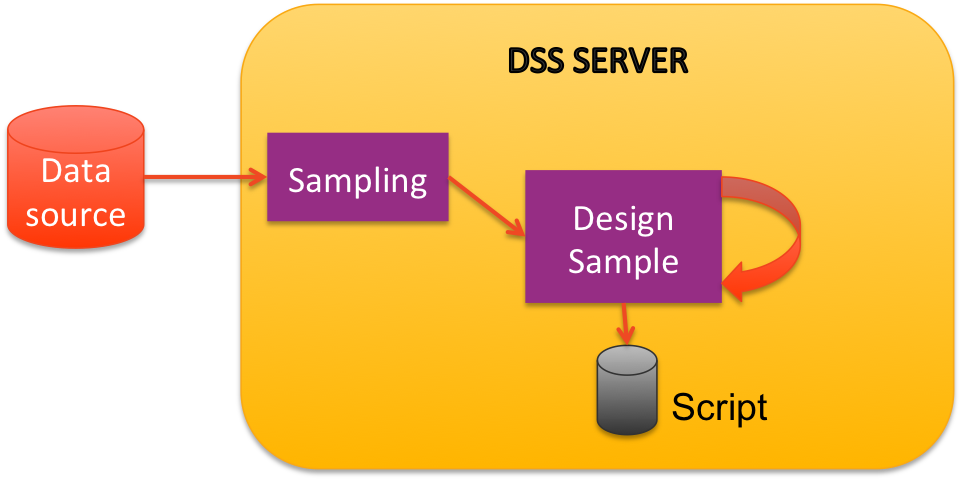
Note that you can change the sampling, and you could even use the whole dataset. But you should really think twice before switching the sampling to the whole dataset when you have a large dataset.
First of all, it misses the point of having a fast and responsive editing mode, and you may even run out of memory!
In a preparation script, do not use a design sample that is too large
Data preparation execution¶
You may have noticed that the strategy used in preparation script execution (when you click run) is completely different from the one used in editing the script.

DSS will choose the best strategy available (streamed or in-cluster) to execute the script, but never in-memory. DSS will of course apply the computation to the whole dataset, which is why it does not use in-memory processing.
Python and R recipes¶
When you are using the pandas Python package, or R, you should keep in mind that both require in-memory data manipulation. As such, R and pandas are not well-suited tools for large data manipulation. If the input or output dataset cannot fit in RAM, you may run out of memory.
You cannot apply R recipes or Python recipes with pandas to datasets that are too big
In Python, several workarounds are available:
Use streamed (per-row) processing instead of Dataframe processing
Use chunked processing (read dataframes by blocks)
The documentation has details on these implementations in Python recipes.
How to deal with big data?¶
Python+Pandas or R remain useful when working with big data.
For example, sometimes, you can limit yourself to a sample of the dataset. It’s a good way to prototype your code. DSS allows you to stream a random sample of the data and import it directly as a Pandas dataframe (by passing the sampling and limit arguments in the get_dataframe() function) or R dataframe (by passing the sampling argument in the read.dataset() function).
But afterwards, if you want to apply the computation to the whole dataset, you will have to switch to another computing strategy.
DSS offers many alternatives:
As mentioned, you could use a streamed implementation of your Python code
A Python UDF processor in a preparation recipe could work
In some cases, using a SQL recipe may be a very good option.
However, when dealing with big data, you want to push the computation to the data as much as possible. Computing engines like Hadoop on HDFS follow this principle, and are specifically designed for big-data computing. Pig or Hive recipes, which run in-cluster, are well-suited for big data computing.
DSS allows you to easily switch between computing engines. For instance, suppose your current dataset is on the filesystem, but is too large for a python recipe. You can simply use a sync recipe to push your dataset to HDFS, and opt for a Pig, Hive or PySpark recipe instead.