Concept: Sample Recipe¶
The Sample/Filter Recipe can be useful when analyzing a large dataset. For example, you might want to get a general sense of a dataset’s records, schema, and value types, without having to process the entire dataset. To do this you could sample the first N number of records. This is the least computationally expensive sampling technique.
On big data projects, you can add a random sample at the beginning of the Flow and continue working on the project. Later, when you are finished experimenting and ready to run the entire dataset through the Flow, you can remove the sample step.
When using the Sample/Filter recipe to sample a dataset, you might want to ensure the random sample includes all records for a particular column value. For example, in working with a dataset of customers’ orders, you might want to retrieve a random sample that contains either all rows belonging to a particular customer ID or none of the rows, so that the output isn’t missing any orders for the customer IDs that DSS has randomly selected for the sample.
To do this, select “Column values subset (approx. nb. rows)” as the Sampling method, then enter the maximum number of records you want to retrieve for each Column value (e.g., customerID).
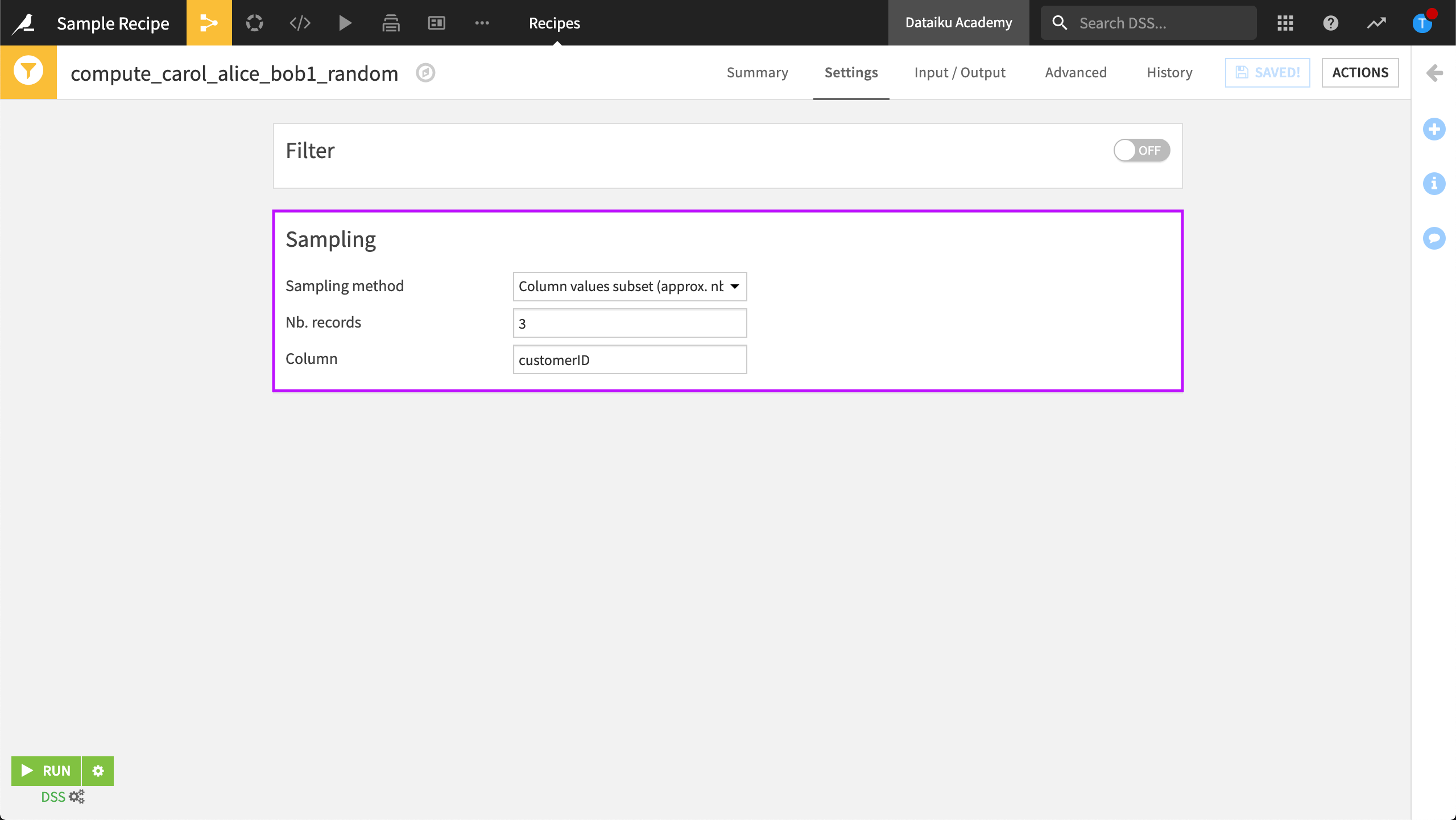
While the sampling function aims to retrieve the specified number of rows across all chosen customer IDs, it is not always exact.

When preparing a dataset for machine learning, you can randomly sample records while rebalancing the classes of a column. This is a common step to take on a heavily skewed dataset.