Concept: Model Lifecycle Management¶
In the previous lessons, we trained models to predict readmission for hospital patients based on historic patient data. We then deployed a model to the Flow and used the Scoring recipe to apply the model predictions to new, unseen patient records.
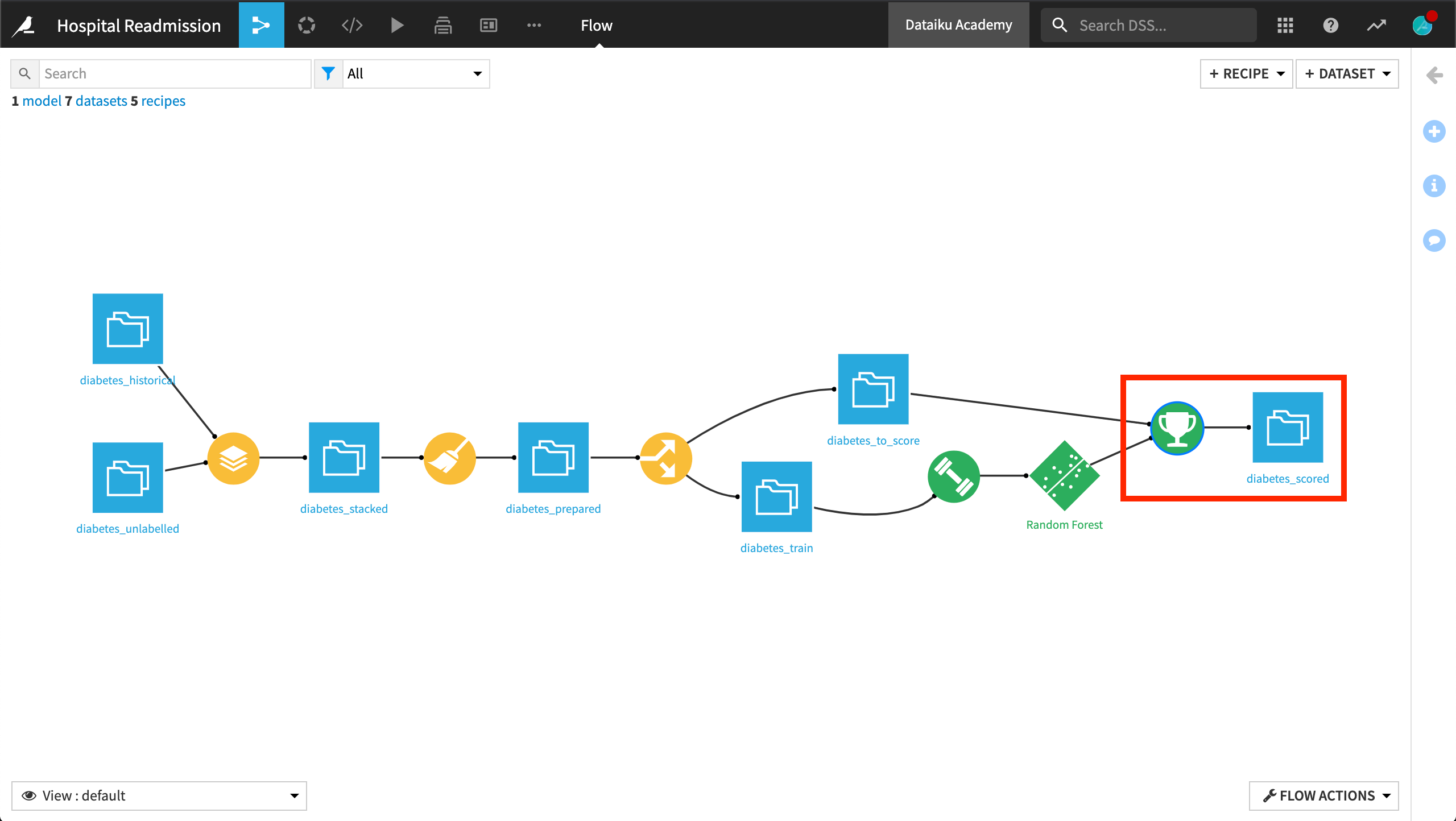
Active Version of the Model¶
Currently, the model deployed in the Flow is our first and active version of the model, which means that it is the version used when running the Retrain, Score, or Evaluate recipes.
The idea of which model is the “active version” is important because data science projects are highly iterative. Over time, your projects and models will evolve as new labelled data becomes available, or as you come up with new feature engineering strategies for your training data.
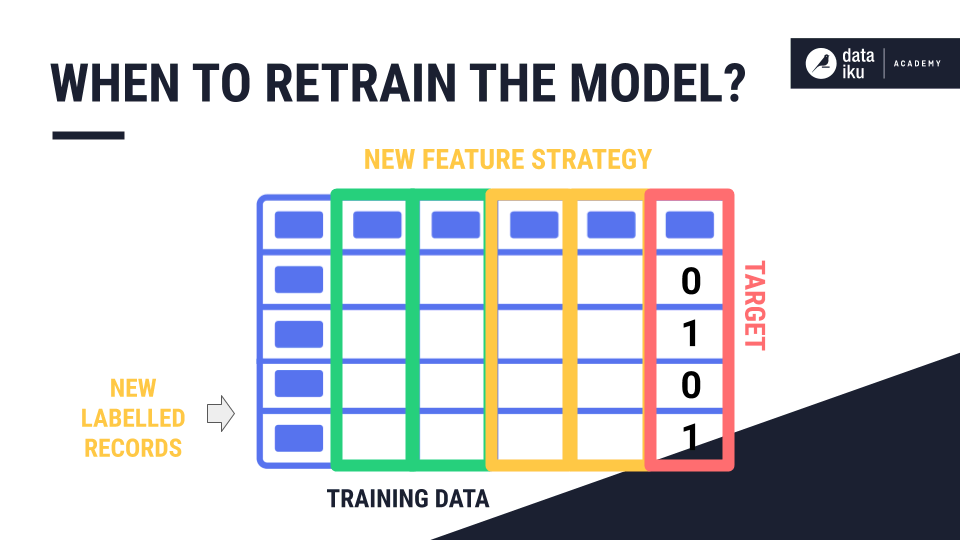
Whether you have a batch of new labelled records or are ready to try a new feature strategy, you will need to replace the deployed model with a new, updated version.
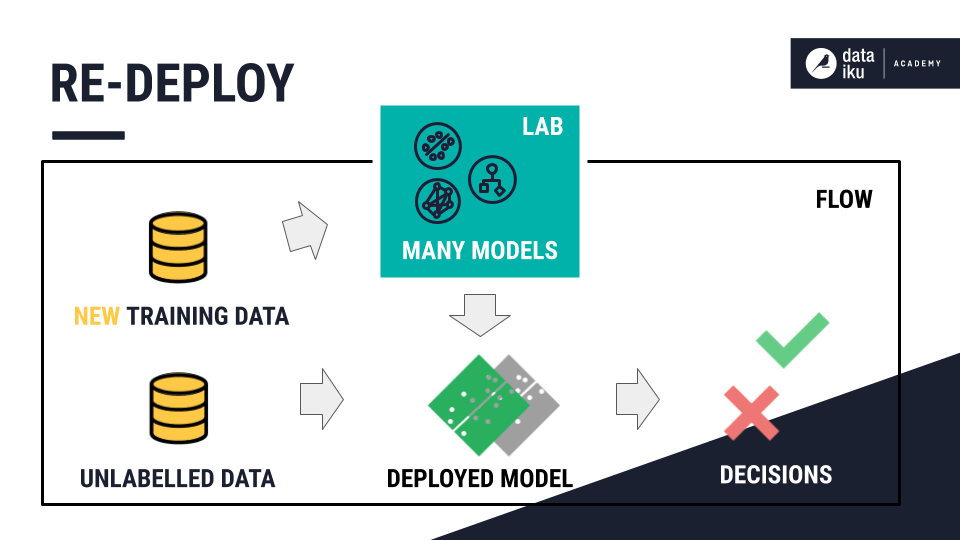
In our example, new patients continue to arrive at the hospital. Some are readmitted, and some never return. It is possible that the distributions and relationships between features and the target in the data change over time. Maybe the hospital has changed policies? Maybe a pandemic is keeping patients away? To prevent the model from becoming stale, it is good practice to retrain the model regularly when fresh training data becomes available.
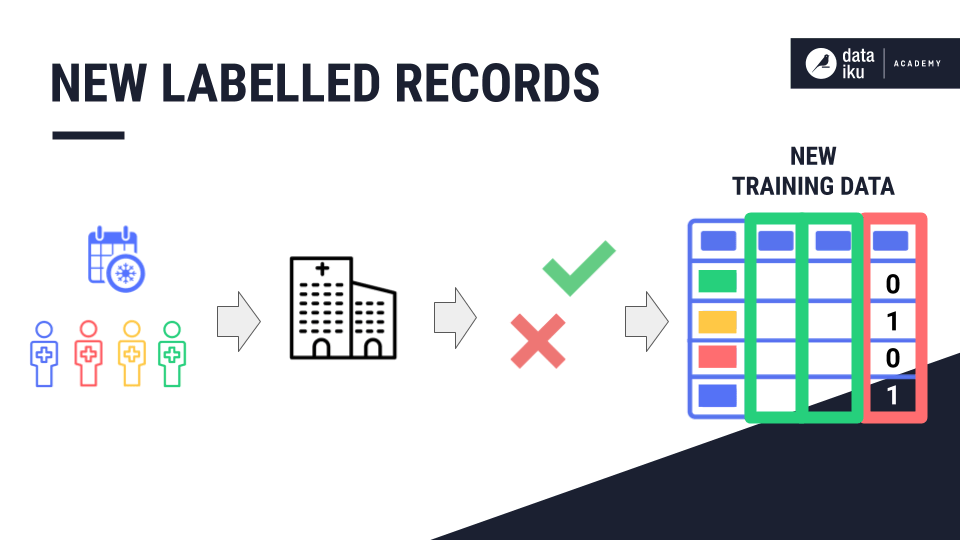
A Validation Set¶
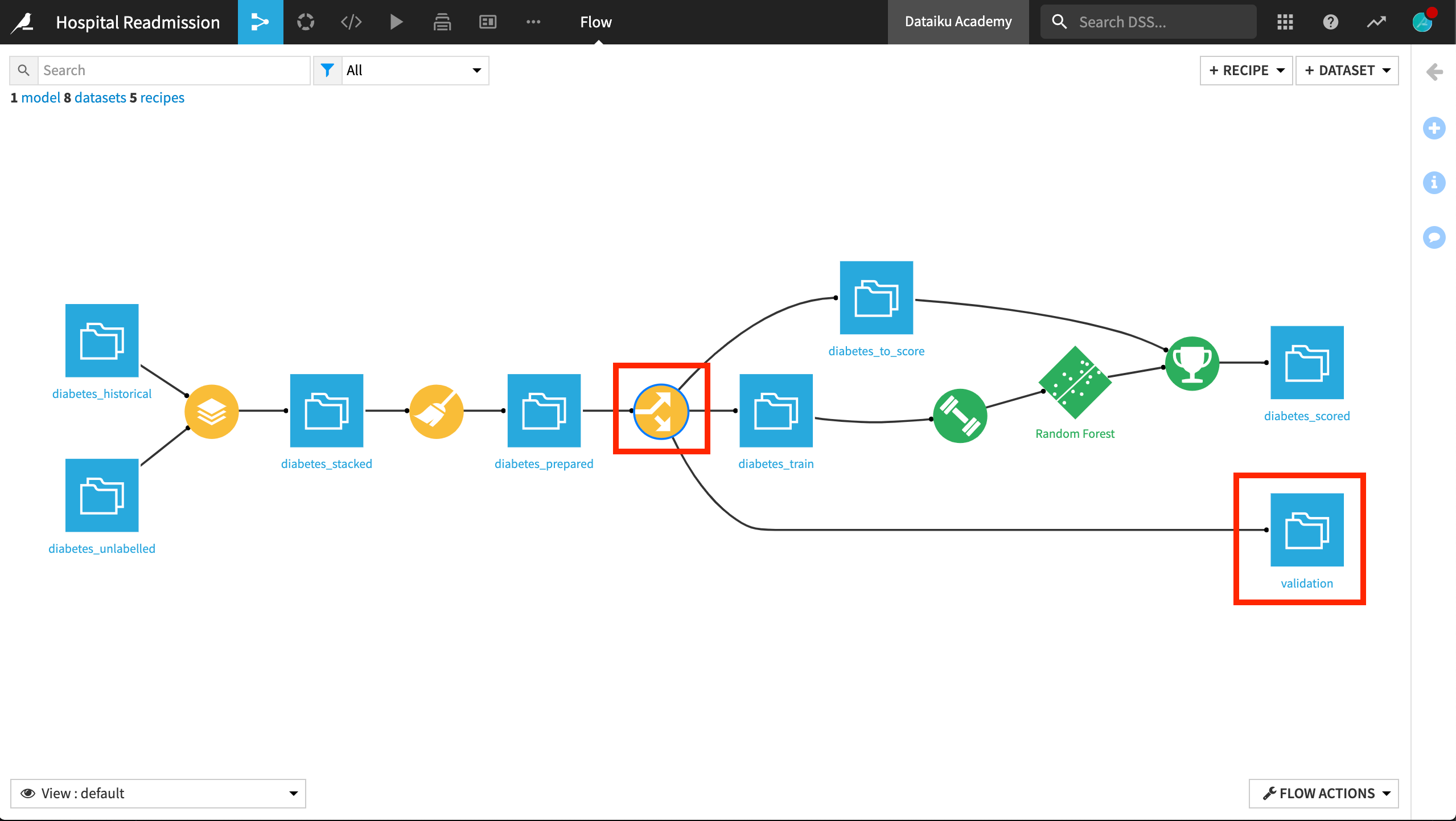
How can we design a Flow that lets us manage the model lifecycle? One way is to adjust the Split recipe to carve out a validation set from the labelled training data.
A validation set gives us an unbiased evaluation of model fit.
Model Retraining¶
Now let’s retrain the model on the new, slightly smaller training data that excludes all records in the validation set. Alternatively, we could create a scenario to automatically retrain the model. For more information about scenarios, visit the reference documentation.
We can retrain the model by running the Train recipe again. Or, the same operation can be found by clicking on the saved model and choosing “Retrain”.
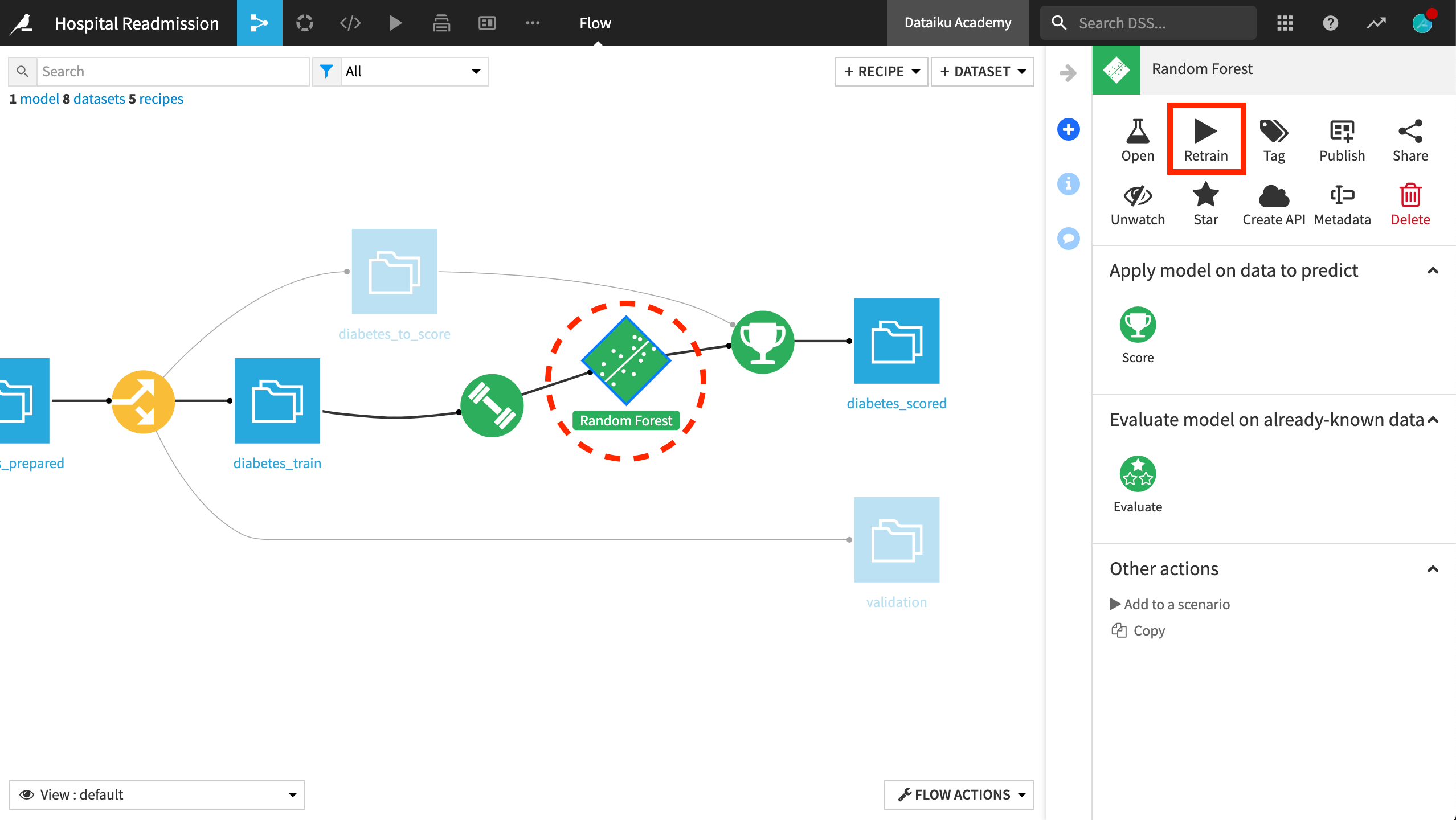
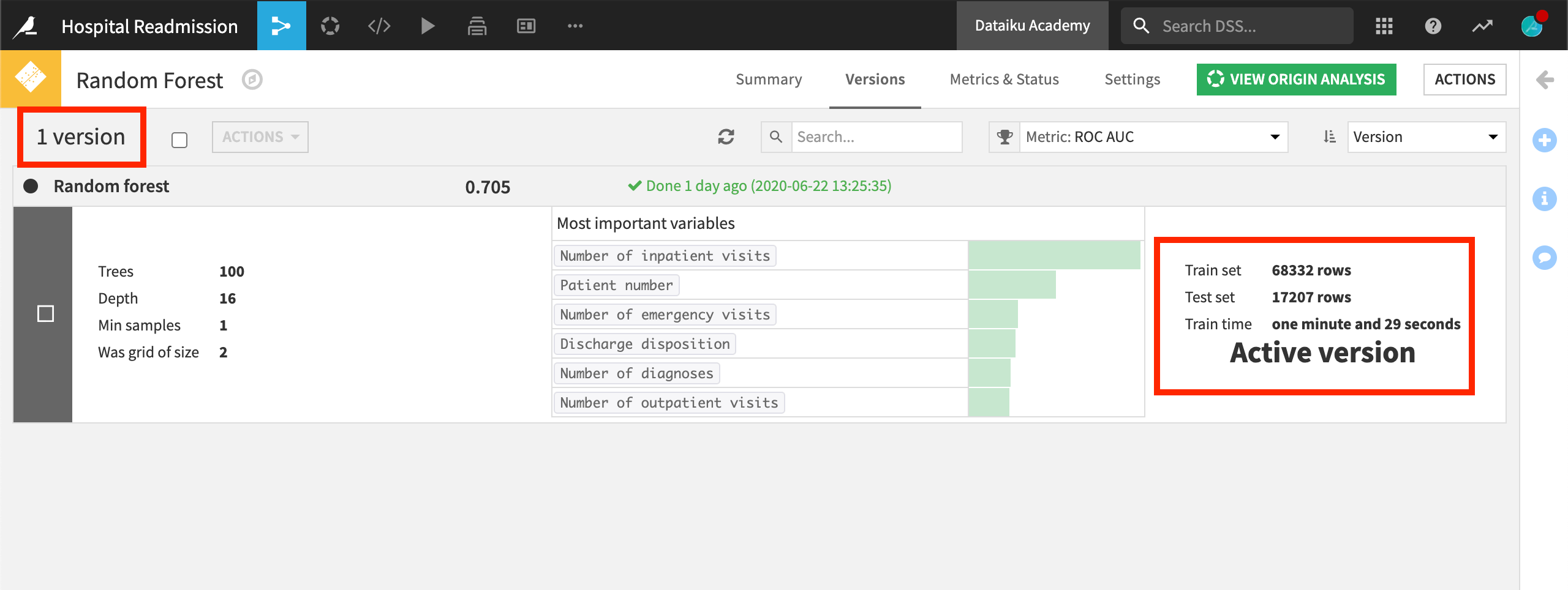
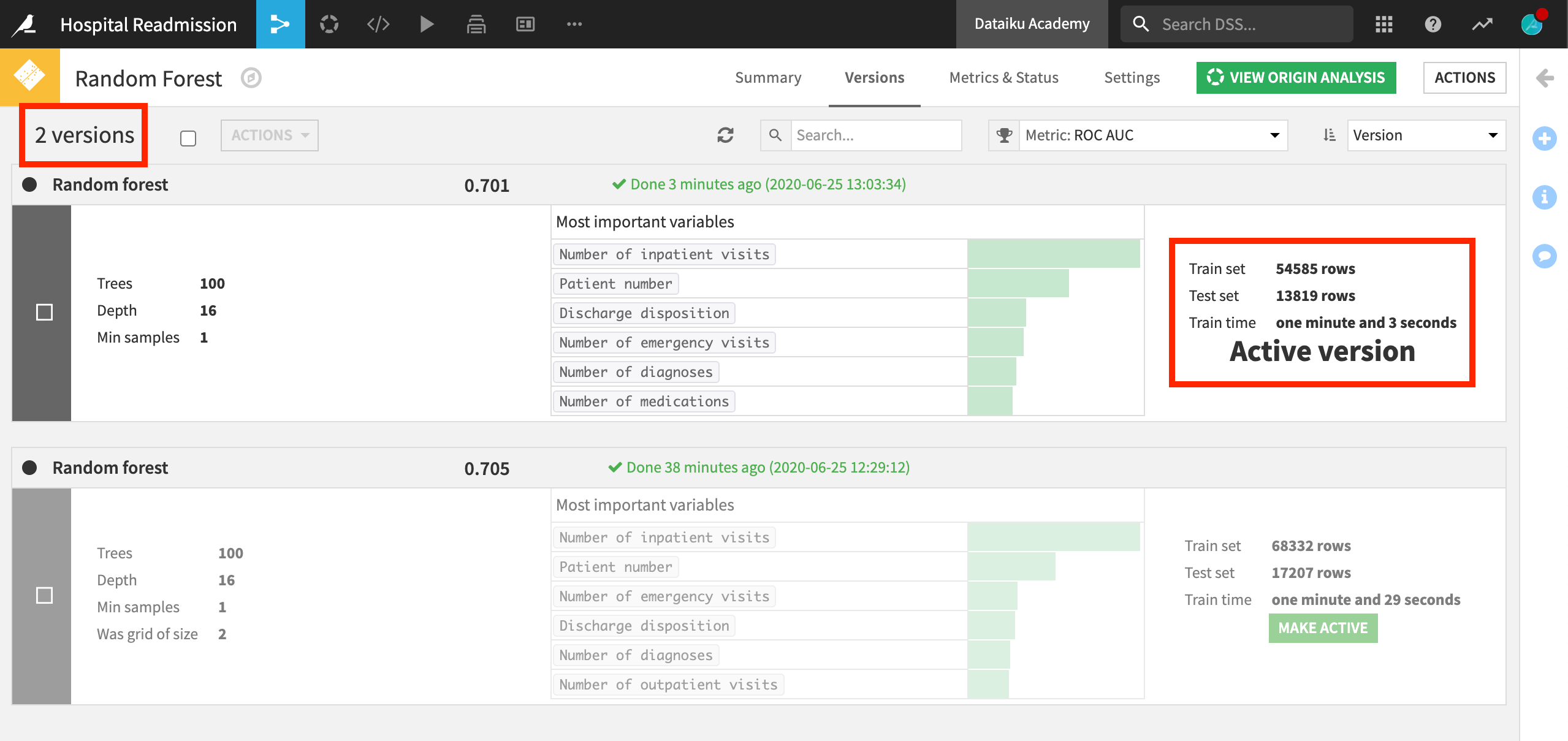
After completion of the model training, we can see the new version of the model by clicking on the saved model in the Flow. During retraining, all of the settings in the model design–the algorithm, hyperparameters, and feature handling–will be kept identical to the active model. But the model will be fitted to the new data.
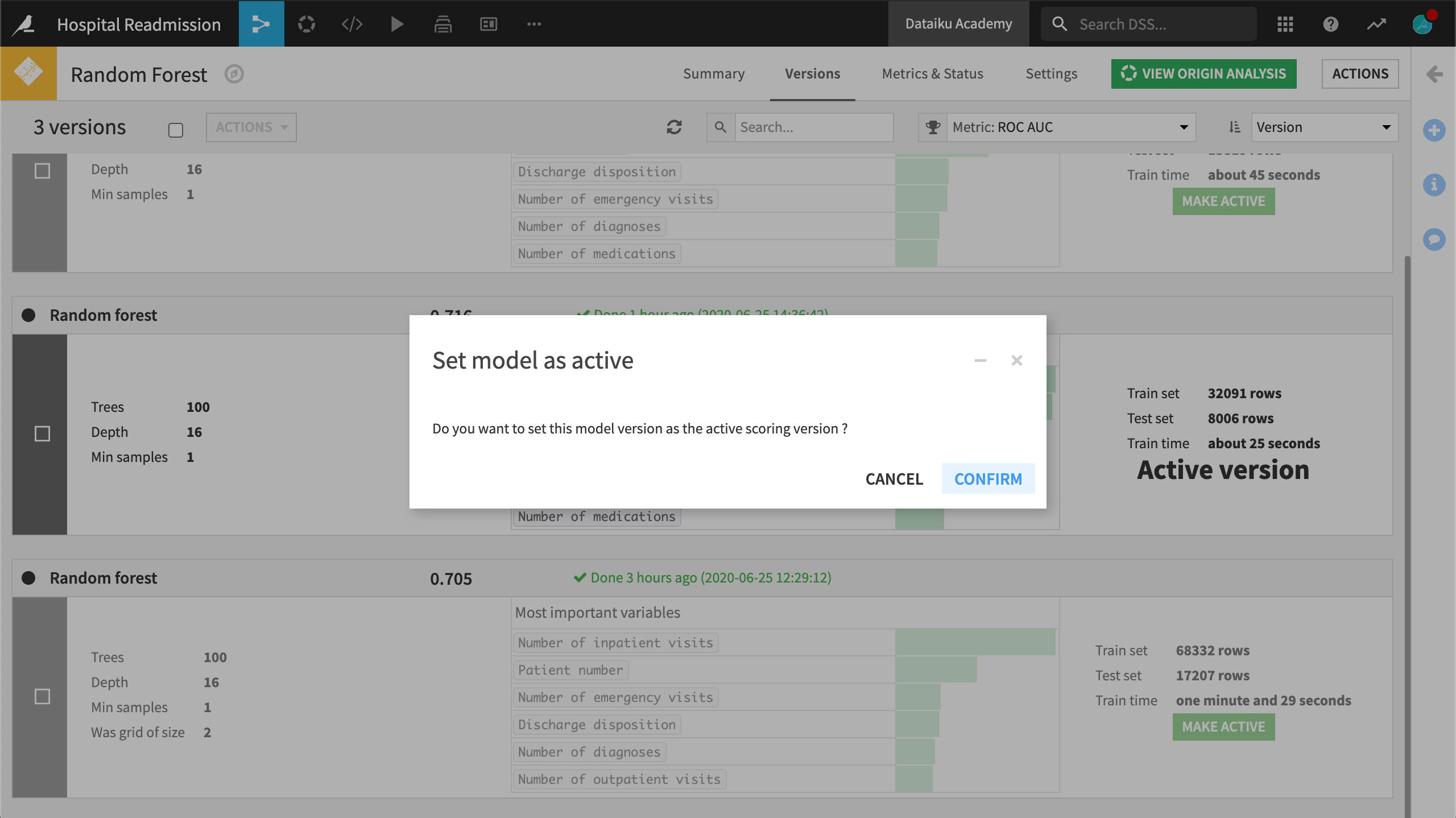
By default, the retrained model becomes the new, active version. We could also change settings to require manual activation of any new model version. From this page, we can activate a new version of the model or roll back to a previous version of the model.
The Evaluate Recipe¶
But how do we know if the new version of the model is better than the previous one? That’s a job for the Evaluate recipe.
As we update the active version of the model, we’ll be able to compare a model’s performance against previous versions using data that was never seen during training.
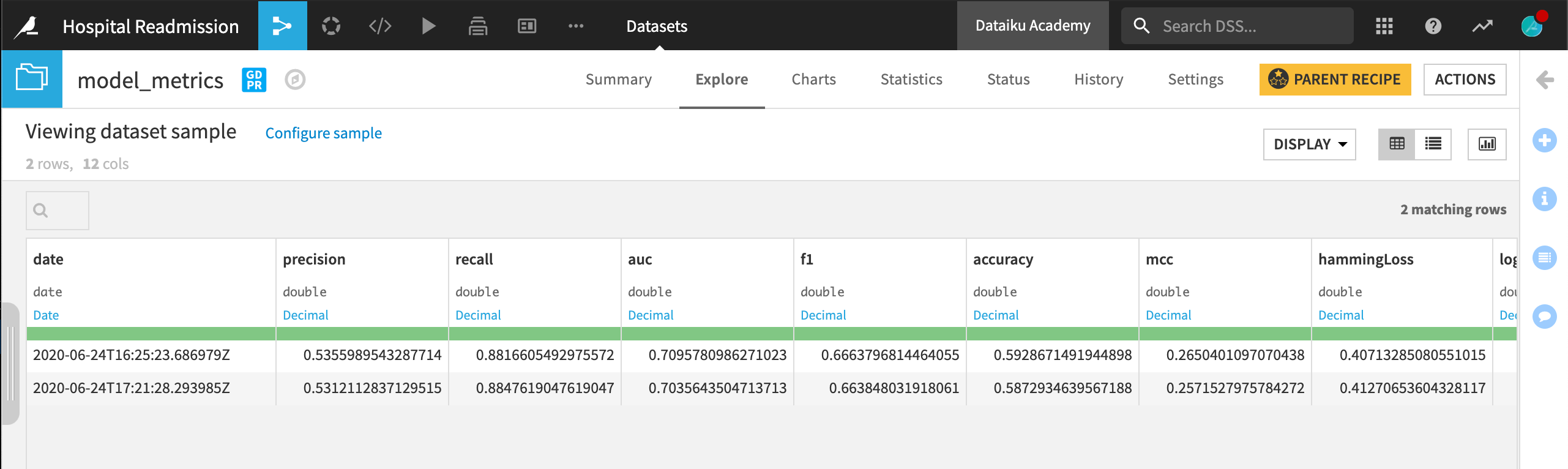
The Evaluate recipe requires two inputs: a labelled dataset and a deployed prediction model. It produces two outputs: the scored input dataset and another dataset of model metrics.
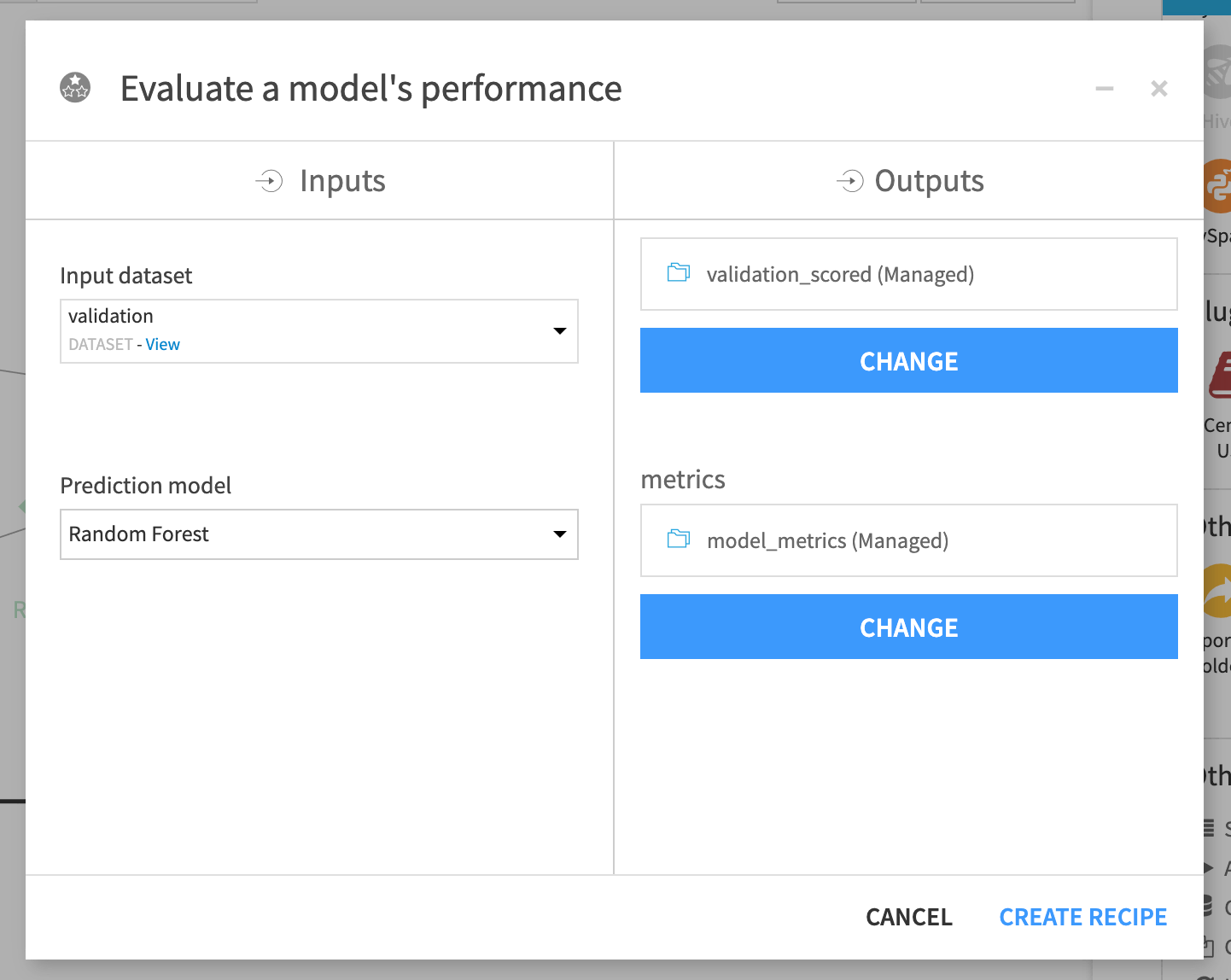
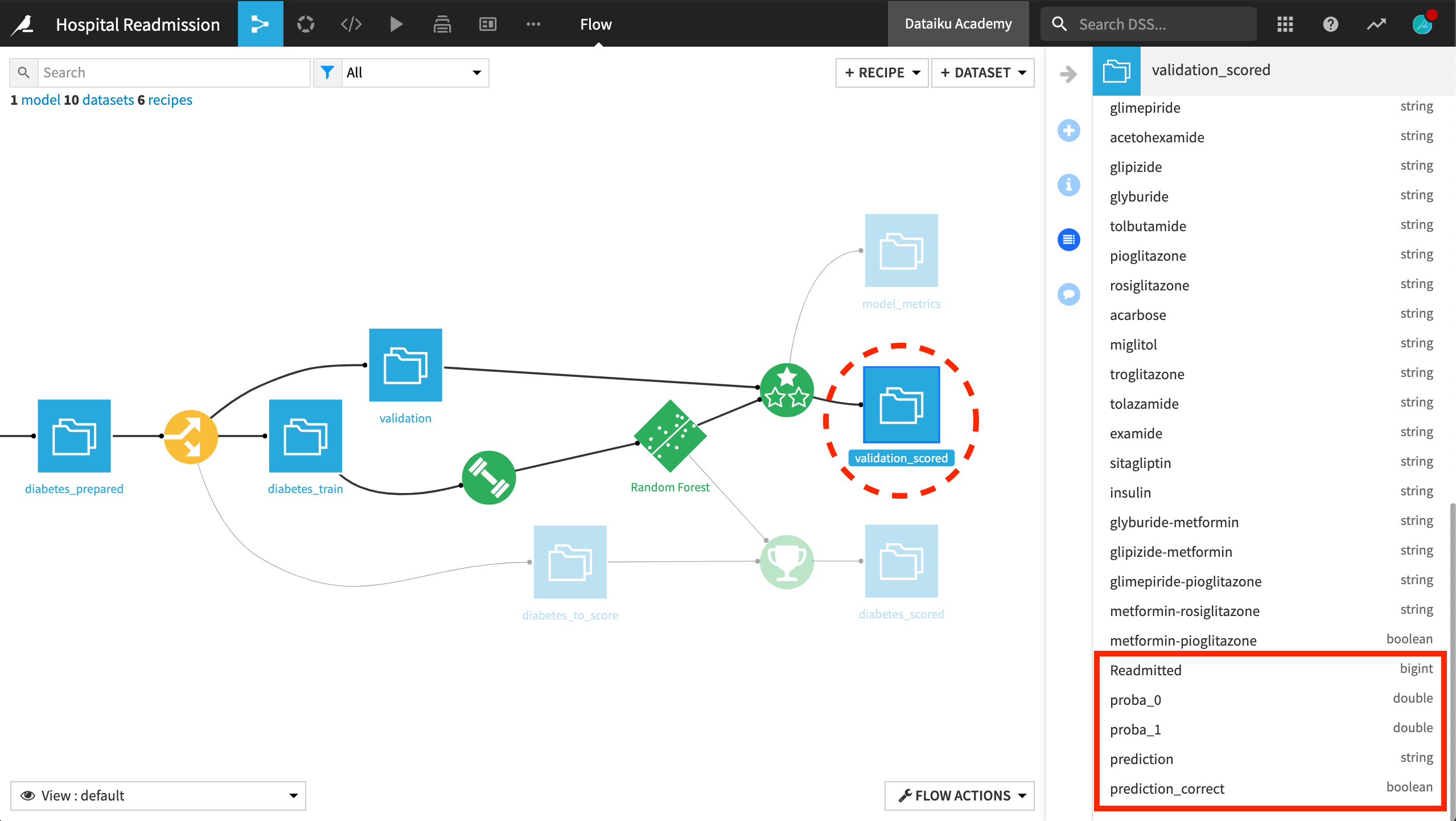
The scored validation set (validation_scored) produced by the Evaluate recipe is similar to the output of the Score recipe. The “Readmitted” variable was already present, but we can now compare it against the class probabilities and predictions according to the active version of the model.
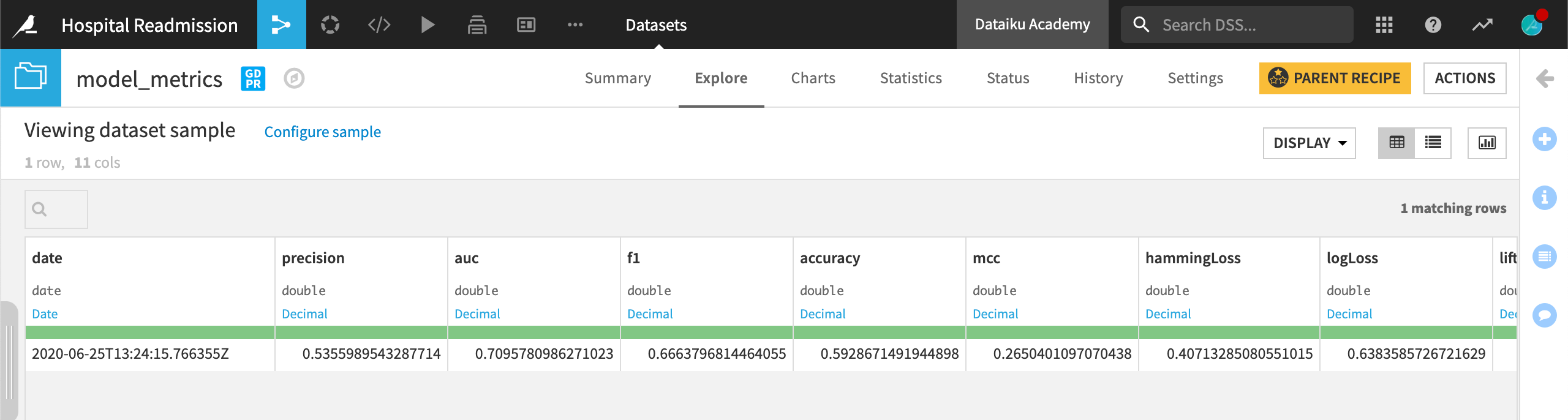
After running the Evaluate recipe one time, we have only one row in the model metrics dataset. After each update to the active version of the model, we’ll re-run the Evaluate recipe and see a new row of metrics added.
Retraining for New Historic Data¶
With this evaluation plan in place, consider a case sometime in the near future where our historic data has changed. After it travels through our data pipeline, we have new, labelled training and validation sets recording which patients were readmitted.
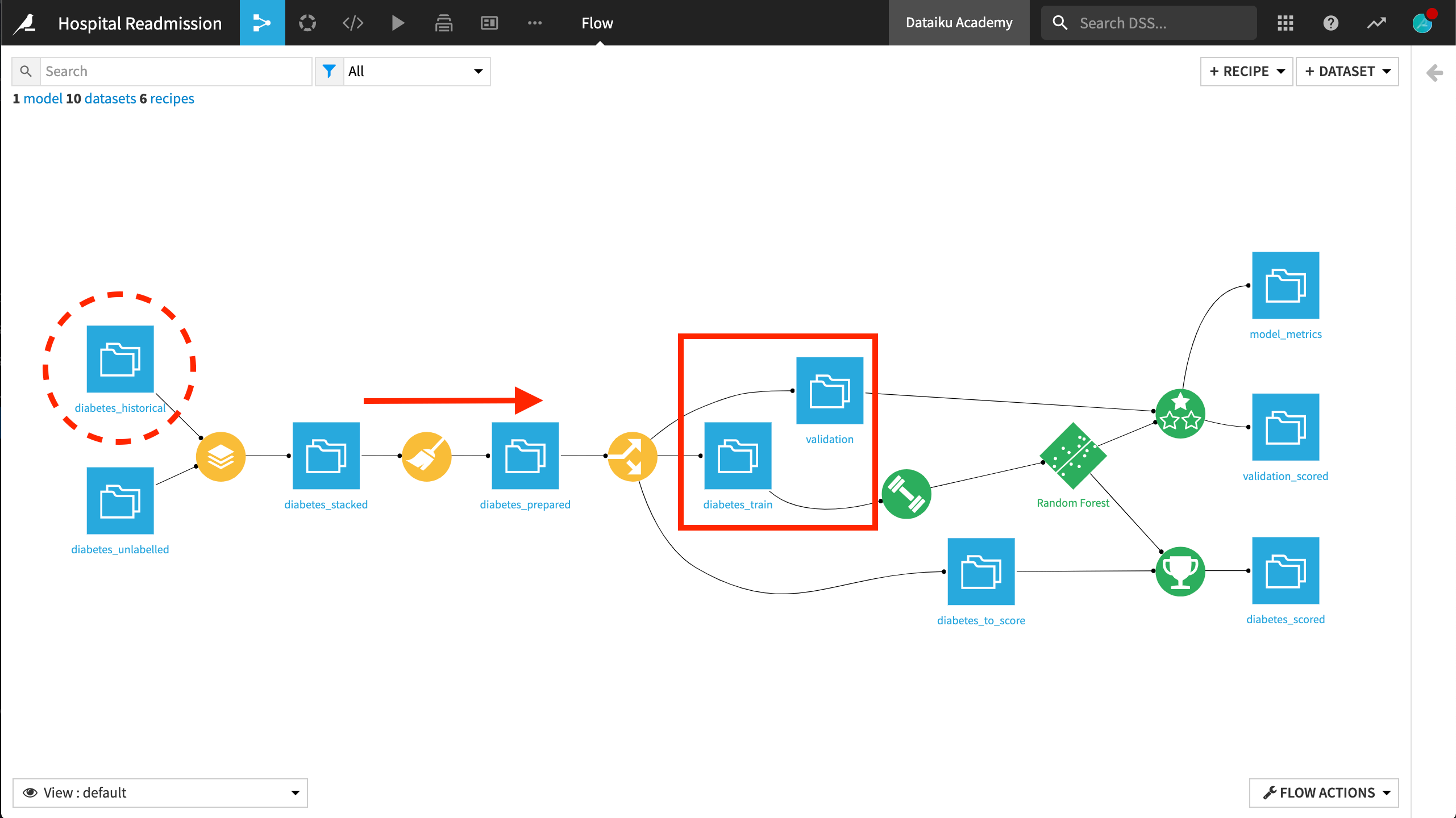
Once again, let’s retrain the model on the new training data.
The model we just trained on our new data is now the active version of the model. ROC AUC has slightly improved, but we can get a fairer assessment against the validation set.
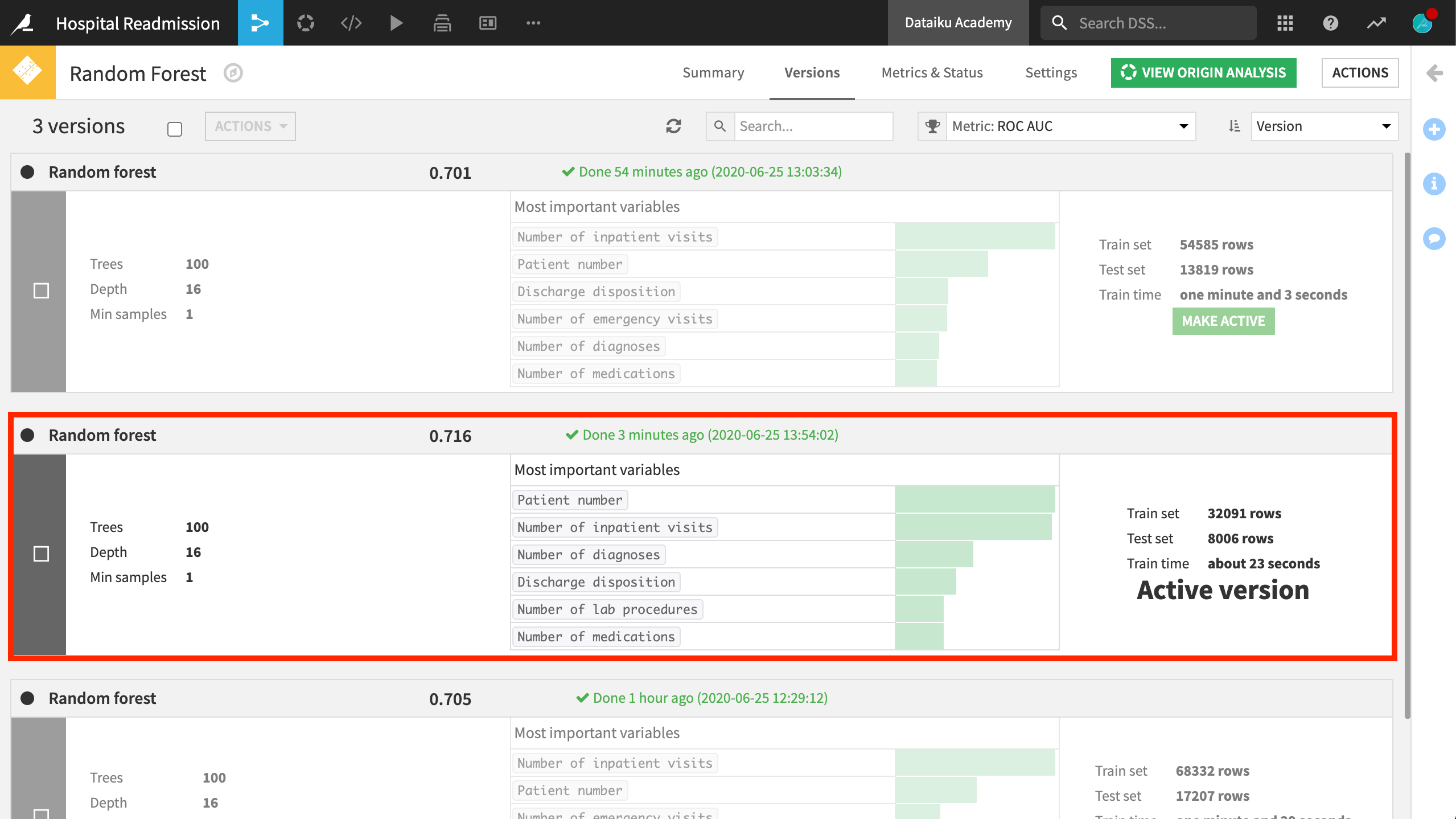
With a fresh active version of the model, let’s re-run the Evaluate recipe.
We have a new row in the model metrics dataset recording the performance on the newly trained model. The metrics are quite close. It looks like the model is performing the same on the new labelled data as it did on the older data.
Perhaps we should keep this model as the active version? If not, we can always roll back to a previous version.
What’s next?¶
In this course, you’ve seen how to deploy a model to the Flow to predict new data.
You’ve also seen how Dataiku DSS lets you version your model in order to keep improving it over time, while keeping track of its history.
In other courses, we’ll learn about this process in greater detail, including how to automate this cycle with scenarios, metrics, and checks.