Dataiku DSS Memory Optimization tips: Backend, Python/R, Spark jobs¶
Sometimes, users running Dataiku DSS jobs and processes can get the following error:
“OutOfMemoryError: Java Heap Space” or
“GC overhead limit exceeded”
This happens when a Java process (like the Dataiku DSS backend, or a Spark job) exceeds its maximum memory allocation, called the “Xmx”.
In this article, we try to present a few explanations on the way DSS works with regards to memory allocation and offer some recommendations to optimize.
DSS Processes¶
First, it is important to remember the key moving parts of a Dataiku DSS system.
The DSS backend is a single main Java process whose Xmx is controlled by “backend.xmx”. The backend needs memory for the size of config, concurrent users, loading explore samples, etc. Typical values range from 6g to 20g for large production instances. If the backend fails because of Xmx (i.e crashes), you will get the “Disconnected” overlay, and jobs will be aborted. The backend, like most key Java processes in DSS (nginx, ipython) are configured to automatically restart after a few seconds if they die because of memory issues.
If the backend fails often, you can increase the backend.xmx value in the install.ini file in the DSS data_directory (link to the doc)
The JEK is a process that runs a job. There is one JEK per job, and its Xmx is controlled by “jek.xmx”. Unless you are processing a large number of partitions or working with a large number of files, this rarely needs to be changed. The JEK will do mostly some orchestration, and also runs the visual recipes in the DSS stream engine. If the JEK crashes because of Xmx, the job fails with “Job process killed (maybe out of memory)”, and usually leads to seeing “OutOfMemoryError” when you download a full job log.
If you see JEK crashes due to memory errors, you may need to increase it from 2g (the default) to 3 or 4g, but very rarely more.
The FEK is a process that runs various things, and its Xmx is controlled by “fek.xmx”. You should almost never change “fek.xmx” unless explicitly directed by Dataiku support. The FEK is designed to crash and sacrifice itself in order to protect the backend.
Spark Jobs¶
When a JEK runs a Spark activity, a Spark activity is made of:
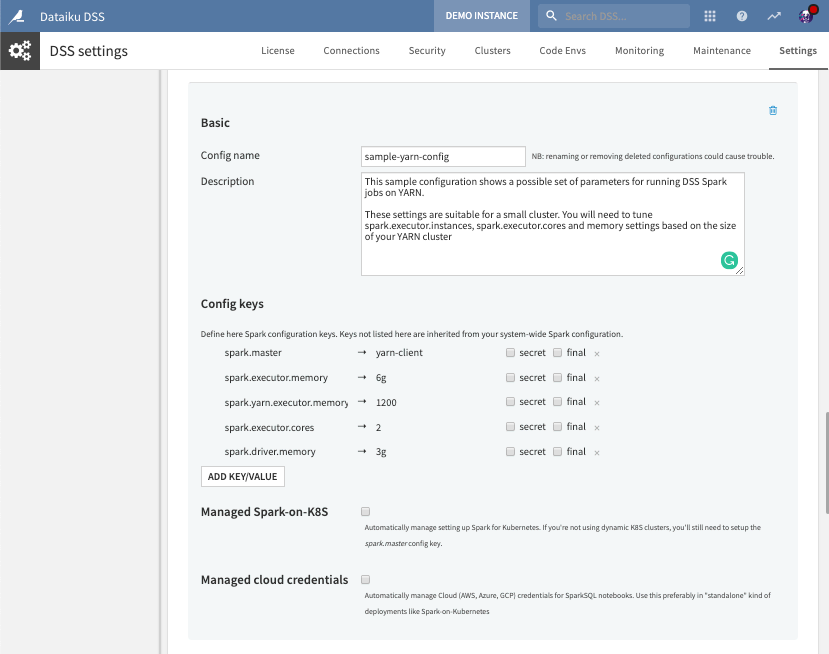
A single Java process called the driver, which does mostly orchestration, and sometimes needs memory for collecting local results. The Xmx of the driver is controlled by the Spark configuration key spark.driver.memory and rarely needs to be changed.
Many other Java processes called the executors which do the actual work. Their default memory allocation is 2g in Spark, 2.4g in DSS.
If you encounter “Lost task … java.lang.OutOfMemoryError: GC overhead limit exceeded” or “Lost task … java.lang.OutOfMemoryError: Java Heap space” errors while running Spark jobs, you need to increase spark.executor.memory.
Since Yarn also takes into account the executor memory and overhead, if you increase spark.executor.memory a lot, don’t forget to also increase spark.yarn.executormemoryOverhead. You can also have multiple Spark configs in DSS to manage different workloads.
Python / R recipes and notebooks¶
When Dataiku DSS runs a Python or R recipe, a corresponding Python or R process is created, and logs for these processes appear directly in the job logs.
When a user creates a notebook, a specific process is created (Python process for Python notebooks, R process for R notebooks…) that holds the actual computation state of the notebook, and is called a “Jupyter kernel”.
Memory allocation for kernels and recipe processes can be controlled using the cgroups integration capabilities of Dataiku DSS. This allows you to restrict the usage of memory or CPU by different processes, for example by process type, user or project…
See detailed documentation for cgroups integration.
Note
This does not apply if you are using containerized execution for the recipes or notebooks.