Concept: Group Recipe¶
Tip
This content is also included in the free Dataiku Academy course, Basics 102, which is part of the Core Designer learning path. Register for the course there if you’d like to track and validate your progress alongside concept videos, summaries, hands-on tutorials, and quizzes.
Note
The Group recipe allows you to aggregate the values of some columns by the values of one or more keys.
At many times during an analytics process, you’ll want to perform various kinds of aggregations based on the values of a particular column or columns.
For example, in a dataset of transactions, you might want to sum the value of transactions according to certain groups, such as individual customers, certain product categories, a specific time period like a month, or a geographic unit like a state or country.
The Group recipe is capable of taking a dataset like the one on the left and producing the one on the right.
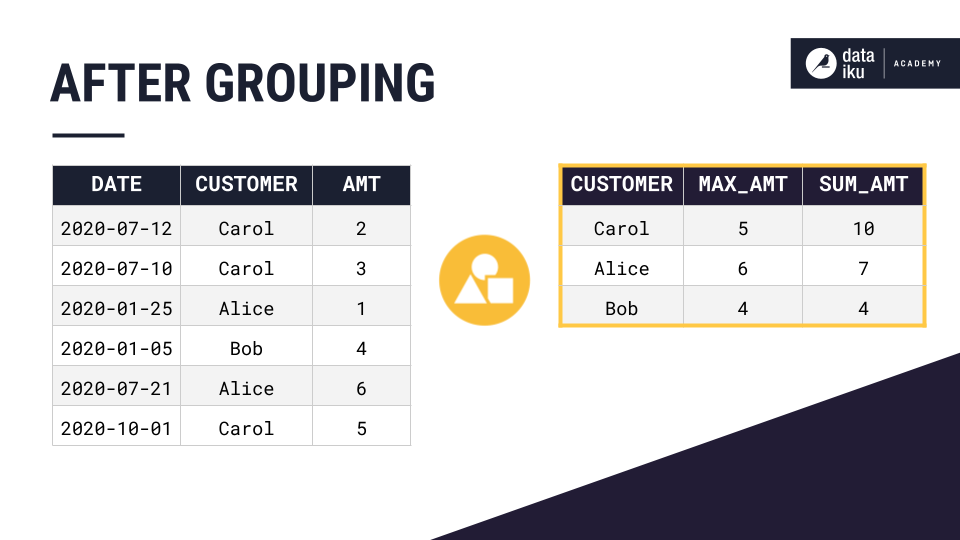
In the case above, we are grouping by all of the unique values of the customer column on the left and aggregating them in various ways on the right, so that each unique customer only appears once.
Grouping¶
The concept of grouping has two important components:
The first is choosing which column (or columns) will serve as the group key.
The output dataset will have the same number of rows as unique combinations of values in the group key columns.
In the table above, the customer column was the group key.
The second component is defining the aggregations.
For each unique value in the group key column, what do you want to calculate?
In the table above, this was the maximum and sum of the sale amount for each customer.
Grouping within DSS¶
Within DSS, the Group recipe is an obvious choice to perform a grouping transformation.
After initiating a recipe, you first need to choose the group key. In the previous table, customer values served as the group key. In the example shown below, tshirt_category is selected as the group key.
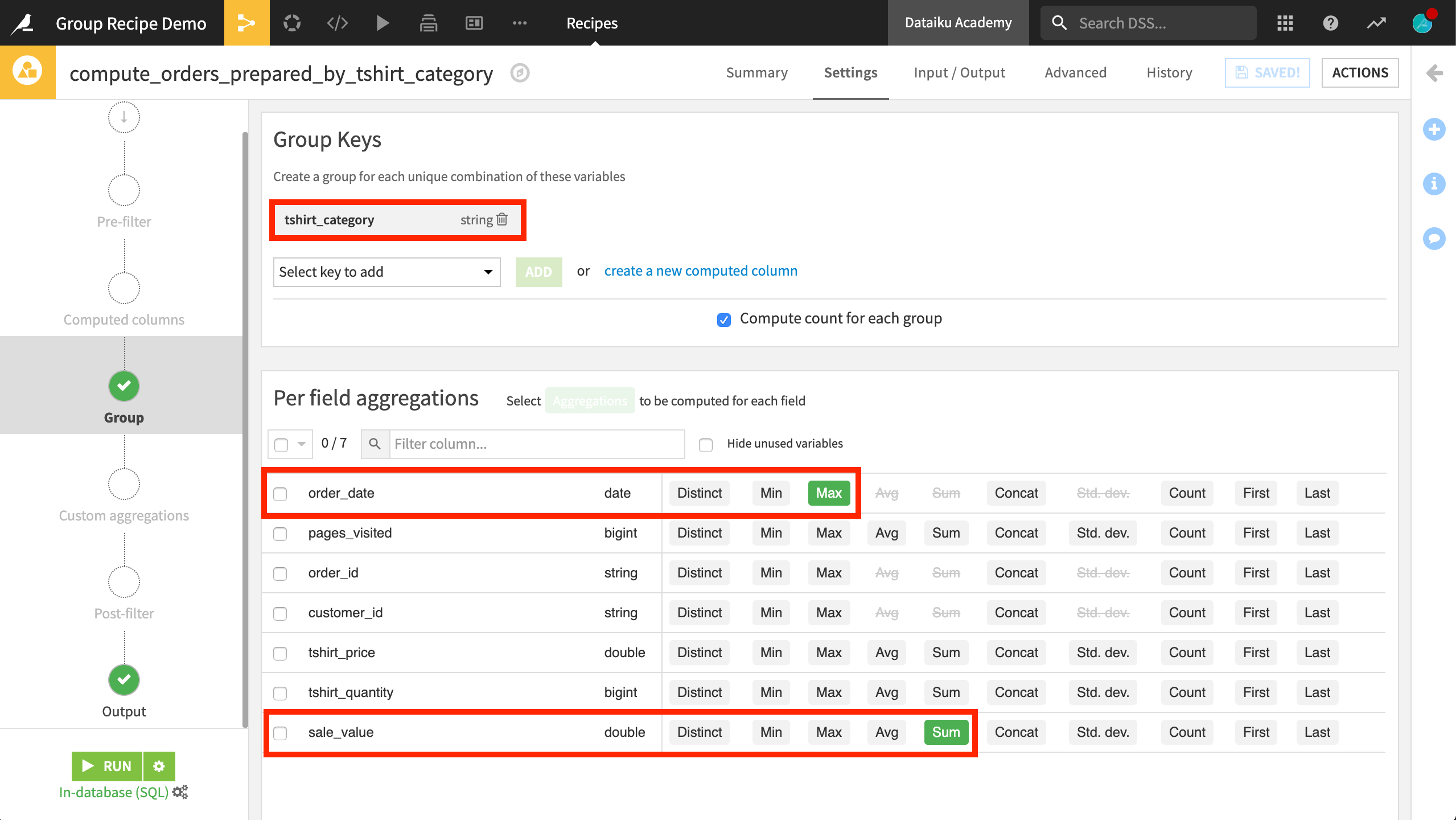
Once choosing this key, you know that the output dataset will have one row corresponding to each unique value in this column.
In the example above, a single column serves as the group key, but it is possible to have more. For example, if grouping orders by month, columns for year and month might both be needed to serve as the key. In which case, the number of rows would be equal to the number of unique combinations of values in both key columns.
After setting the group key, the next step is to choose the aggregations.
Several kinds of aggregations are natively available. As shown above, checking the maximum for order_date and the sum of sale_value will calculate, for each category defined by the group key, the most recent purchase and the total amount spent.
If no aggregations are set for a particular variable, that variable will be excluded from the output set.
If none of these native aggregations meet your needs, you can also define custom aggregations in SQL code on the Custom aggregations step.
Checking the Output step, you can see that four columns will be included in the output dataset. One for the group key, one for the count of records each value in the key column appears, which is included by default, and two more for the two requested aggregations. At this point, you can also rename the columns, which are auto-generated to include the type of aggregation.
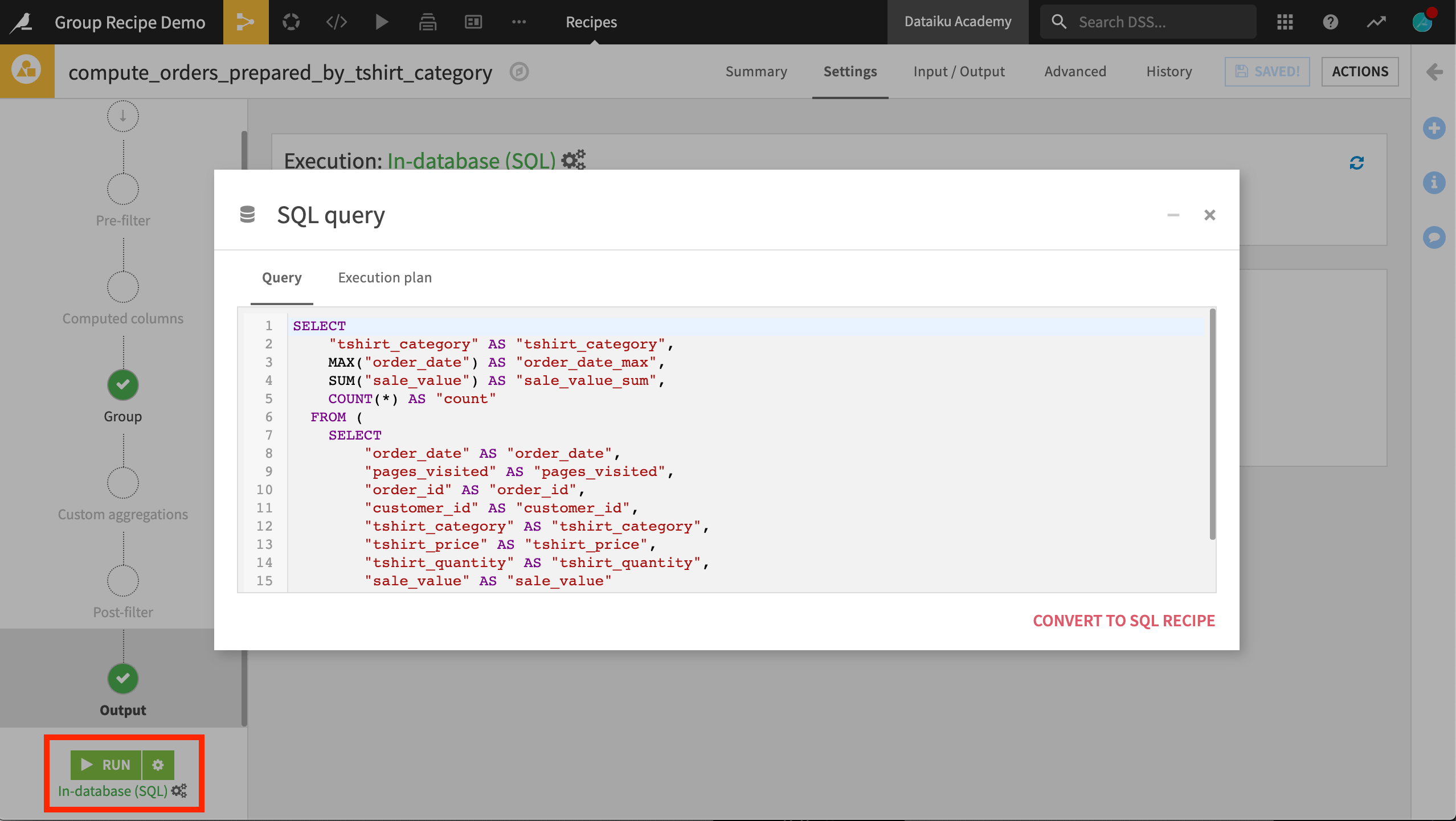
If you are familiar with SQL, you may recognize that the Group recipe is the equivalent of a SQL “group by” statement. In fact, for eligible in-database computations, you can view the SQL query underneath the visual layer of the Group recipe.
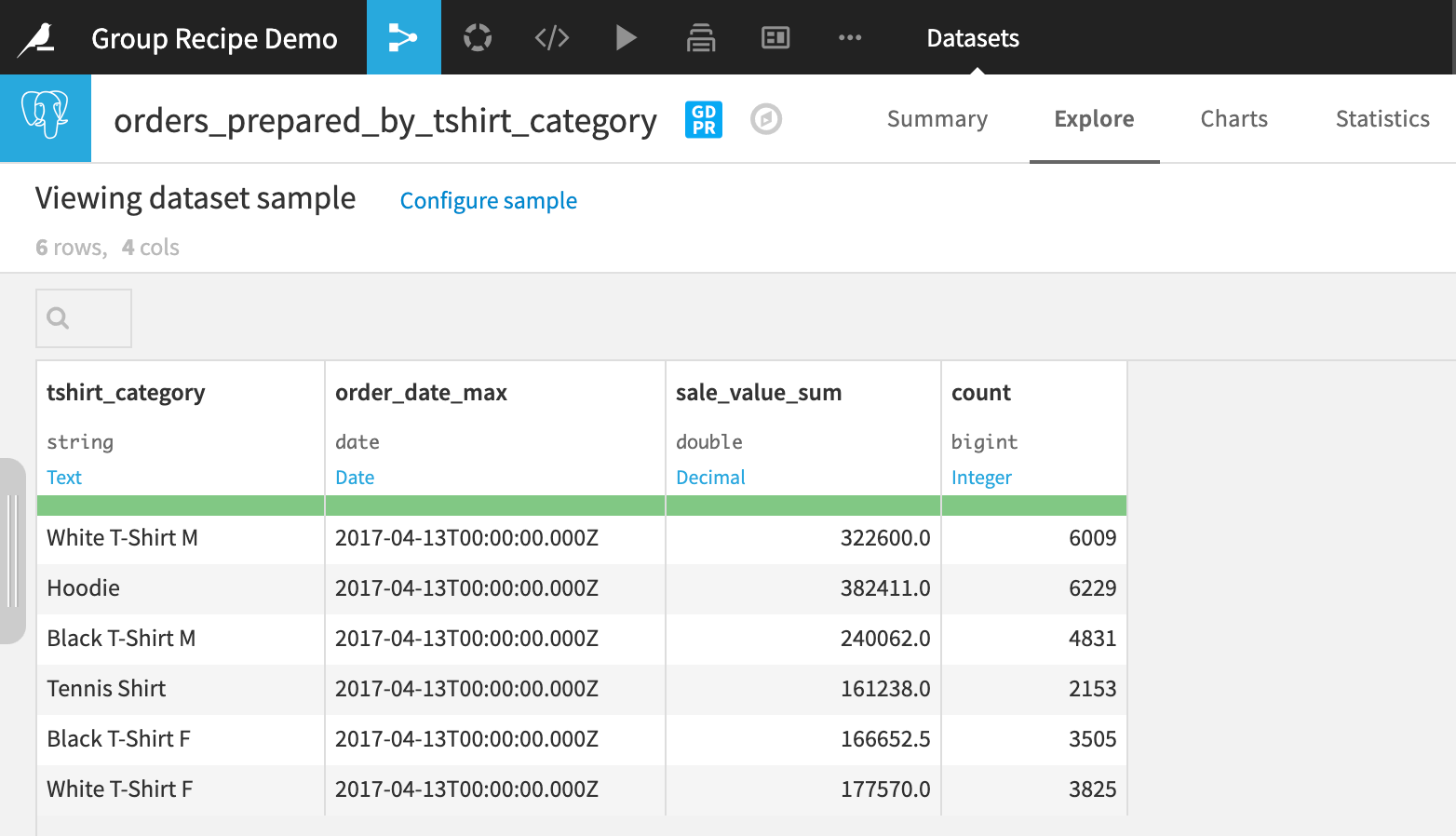
After running the recipe, you are left with only the unique combinations of the group key and the requested aggregations for each.
Learn More¶
In this lesson, you learned to to perform group-wise aggregations using the Group visual recipe. Continue learning about the Basics of Dataiku DSS by visiting Concept: Flow.