Interactive Document Intelligence for ESG¶
Overview¶
Business Case¶
Financial service firms have a large document corpus (both digitized and native images) with valuable opportunities from harnessing insights and trends within this unstructured data. Many organizations rely on individuals to read sections of these documents, or search for relevant materials in an ad hoc manner, with no systematic way of categorizing and understanding the information and trends.
This solution automatically consolidates unstructured document data into a unified, searchable and automatically categorized database, with insight accessible via a powerful and easy to use dashboard. The project accepts any document set as input, and each document is sent through a modular and reusable pipeline to automatically digitize documents, extract text, and consolidate data. Multiple NLP techniques are applied to this data based on theme of interest (in this project: ESG), with additional theme modules available. If interested, roll-out and customization services can be offered on demand.
Technical Requirements¶
To leverage this solution, you must meet the following requirements:
Have access to a DSS 9.0+ instance.
A Python 3.6 code environment named
solution_document-intelligencewith the following required packages:
fitz
PyMuPDF
regex
pyldavis
dash
nltk
torch
transformers
weasyprint
seaborn
scikit-learn>=0.20,<0.21
wordcloud
pyspellchecker
Alternatively, the code environment can be imported directly as a zip file (Download
here) and installed after import by selecting Update in the code env settings.-
Tesseract must be installed on the server or machine running Dataiku.
(Optional) Google Cloud NLP Plugin
This plugin requires a google API key and is a paid service. Tesseract is the default OCR tool for this project and is free to use.
Installation¶
Once your instance has been prepared, you can install this solution in one of two ways:
On your Dataiku instance click + New Project > Sample Projects > Solutions > Interactive Document Intelligence for ESG.
Download the .zip project file and upload it directly to your Dataiku instance as a new project.
Data Requirements¶
The project initially includes SEC data from EDGAR to demonstrate functionality. This can be replaced or supplemented by the document soure of choice by changing the flow. Roll-out and customization services can be offered on demand.
Workflow Overview¶
You can follow along with the sample project in the Dataiku gallery.
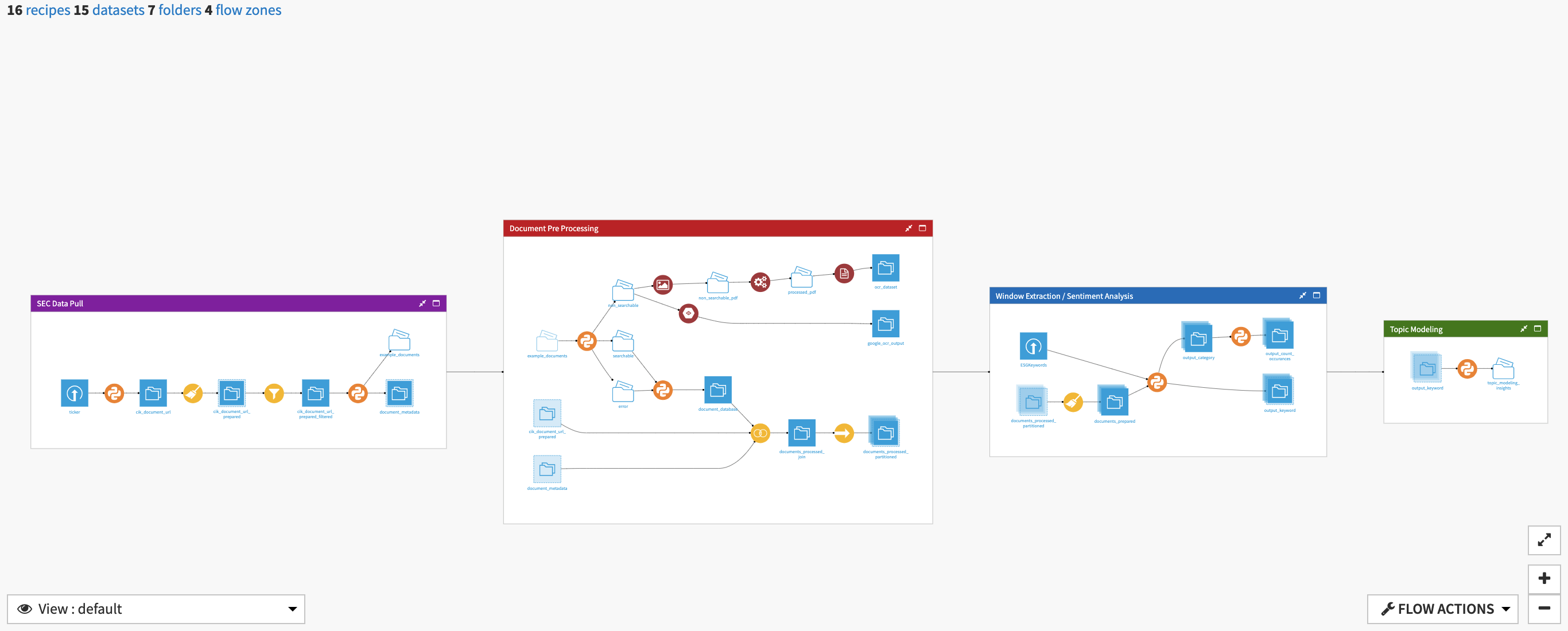
The solution has the following high level steps:
Pull public data and process documents
Extract Windows from documents and apply Sentiment Analysis
Unveil abstract “topics” occuring in the document corpus
Enable business users with Interactive Mode
Conduct real-world analysis with Demonstration Mode
Walkthrough¶
Note
In addition to reading this document, it is recommended to read the wiki of the project before beginning in order to get a deeper technical understanding of how this solution was created, the different types of data enrichment available, longer explanations of solution specific vocabulary, and suggested future direction for the solution.
Digitize, analyze and consolidate thousands of documents¶
The underlying flow upon which the interactive dashboards are built is comprised of 4 flow zones. The full flow and its individual flow zones can be cutomized based on the specific needs of the user. Specific details on how to change the flow and the impact of possible changes can be understood via the project wiki.
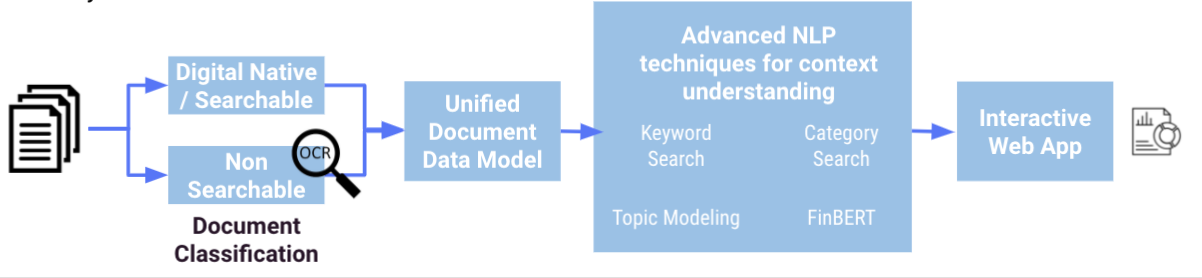
The SEC Data Pull flow zone is used to get sample documents from the EDGAR database to run through the flow. If you have your own corpus of documents to process, they can be subbed in to this section in lieu of the SEC data. The output of this zone, example_documents is passed along to the next flow zone for analysis.
Within the document pre-processing flow zone, the processed folder of documents is classified based on whether it is digital, a native image, or unable to be processed. Text is extracted from digital documents using PyMuPDF while the Google Vision OCR and Tesseract Plugins are used to perform optical character recognition (OCR) on native images. This part of the flow can be changed to instead use your preferred OCR tool.
A unified data repository documents_processed_join is passed from the last flow zone to the window extraction and sentiment analysis flow zone. Here we search through the document to extract windows based on a key word list or a catagory list before applying FinBERT to analyze sentiment of the window. This project has been designed with keywords pertaining to Environmental, Social, and Governance.
Finally, the topic modeling flow zone unveils abstract “topics” that occur in the document corpus. This particular flow has ben built to run LDA topic modelling. Users of this solution should view this final flow zone as an example of an NLP downstream analysis that can be performed on a document database.
Interactive search and insight generation for Business users¶
Business user can easily and interactively consume the NLP module results with the pre-built interactive document intelligence dashboard consisting of 4 main features.
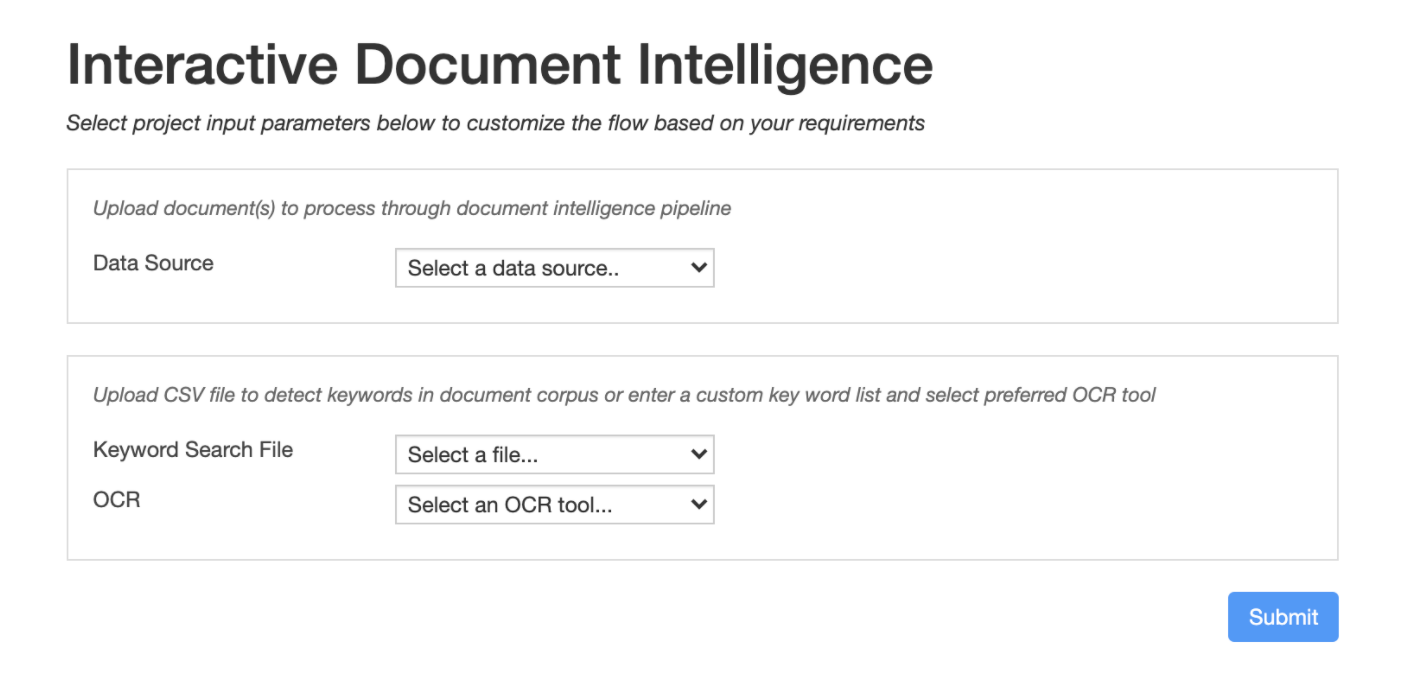
The first tab, Document Intelligence Parameter Tuning contains a WebApp through which users can upload documents to the flow for processing and analysis. Further changes to the flow can be made by inputing a list of key words to be searched, uploading a key word search file, and selecting your preferred OCR tool. Once these parameters are saved with the WebApp, the flow can be re-run using the Flow Build scenario.
Users interested in analyzing high level trends and aggregated insights will benefit from the Interactive Dashboard: FinBERT Sentiment Analysis tab of the Dashboard. Here, we can search for a company name and select multiple categories from the initial category list to see the resulting Sentiment Analysis of each document in the corpus. We can also drilldown even further from here into subcategories to view the extracted windows (on which sentiment analysis was applied) and their associated sentiment score. The solution also provides users with a document viewer in this tab so that we can easily refer back to the originating document when viewing sentiment scores.

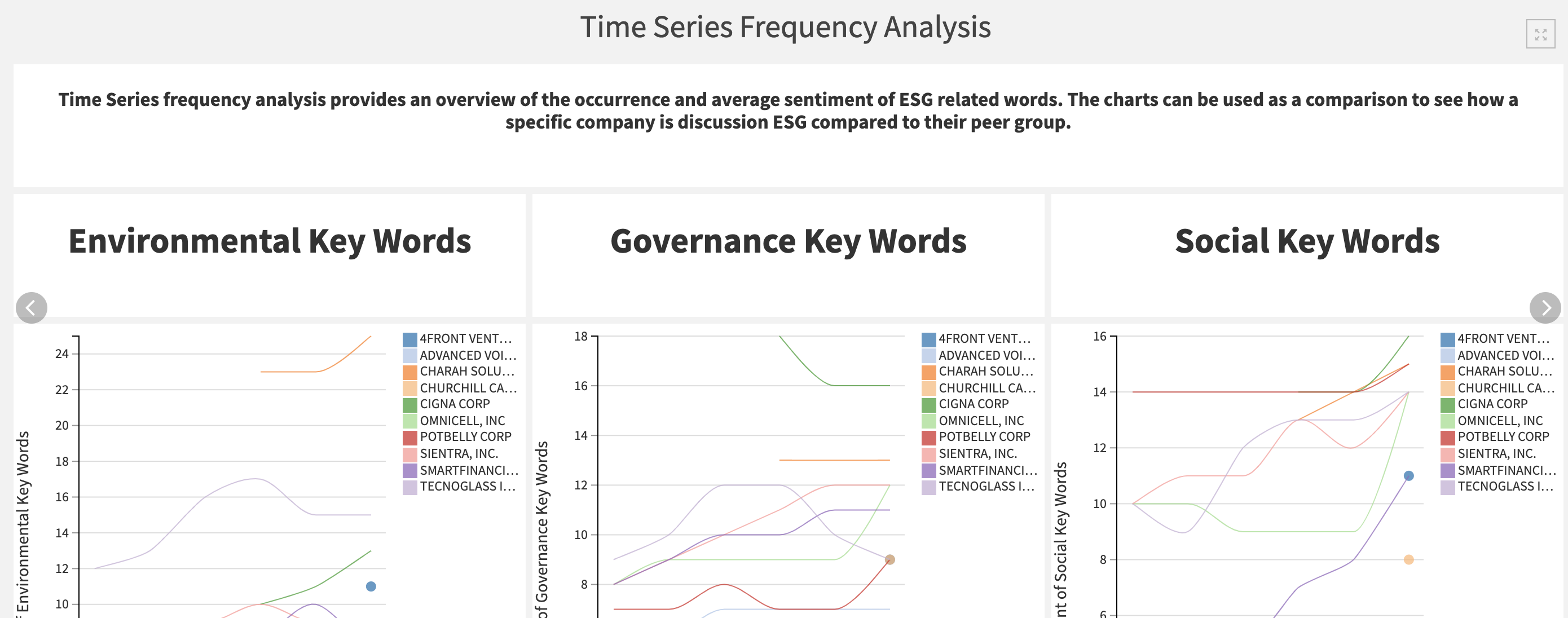
The Time Series Frequency Analyis tab delivers several charts with which we can track the frequency of key words and sentiment over time. The charts includes all companies so they can be compared to one another by altering the filters.
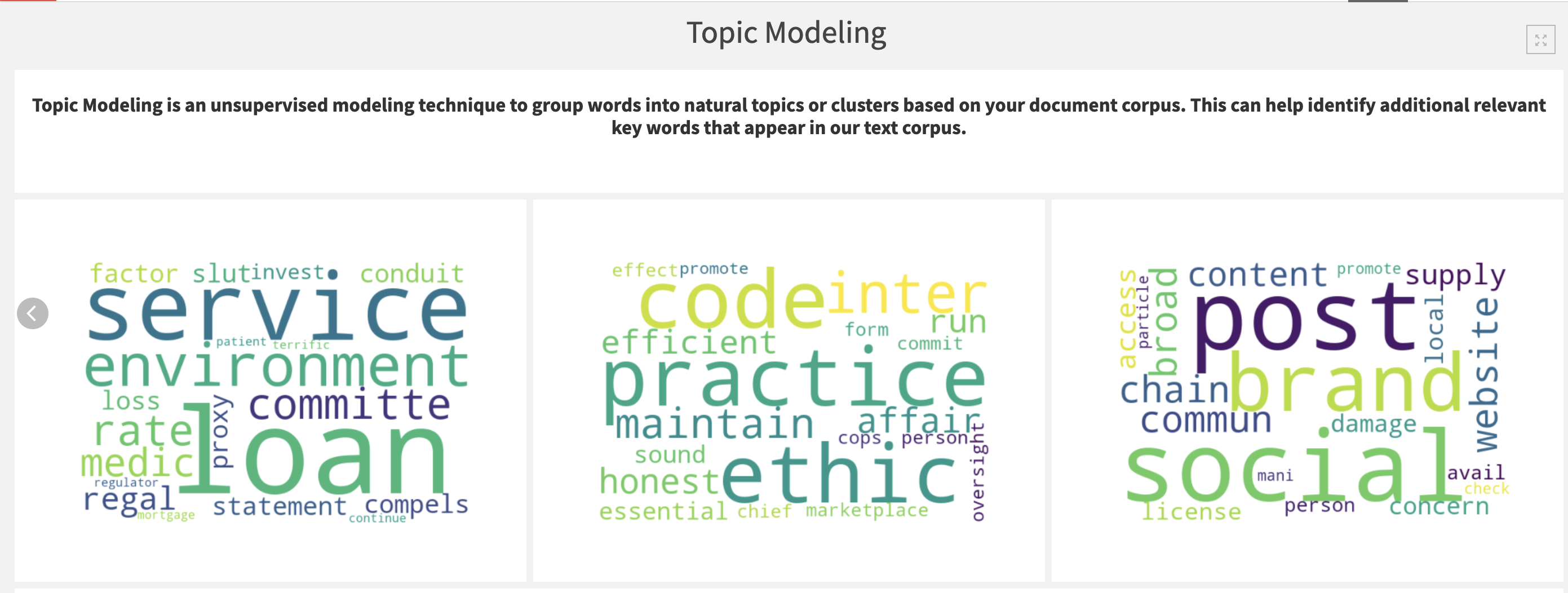
Lastly, several important visualizations are made available in the Topic Modeling tab. From the topic modeling flow zone, a word cloud is generated for each topic found by the LDA model. With this cloud we can visualize the most common words per topic. Below the word clouds we can interactively visualize the top 30 words found per topic and conduct exploratory analysis in an easy-to-understand visual manner.
Demonstrate the full pipeline with real-world data¶
In addition to having a modular and adaptable pipeline, this solution is capable of running its full flow as-is. By default, demonstration mode with process data for a sample subset of 73 documents pre-populated in the example_documents folder. If you’d like to alter the default population of the flow, please edit the sampling recipe or drag and drop new documents in the example_documents folder.
Note
Please note, the reprocessing of the flow (via the Flow Build scenario) is memory intensive, and may take 5-12 hours depending on the specifications of your DSS server and the size of your input document corpus.
To run the project with sample data in demo mode:
Ensure the necessary project requirements are met (see Technical Requirements above).
Run the Populate Demo Mode scenario.
View and analyze results with the last 3 tabs of the interactive document intelligence dashboard