Model Lifecycle¶
Modeling is about capturing patterns in a moving and complex world. Working with live data, one must monitor the performance of the model over time and update it accordingly. Dataiku provides many capabilities to handle the whole lifecycle of a model in production.
Retraining models and versioning¶
When the design of a model is finished in a Visual Analysis, one has to deploy the model in the flow in order to score new data.
Deploying a model creates a “saved” model in the flow together with its lineage: it is the output of a train recipe which takes as input the original training data that was used while designing the model.
The “saved” model contains the model that was built within the Visual Analysis. Suppose that the data is changing over time. In order to capture the latest trends, one can retrain the “saved model” from the Actions menu on the right. A new version of the model will be created in the “saved model”:
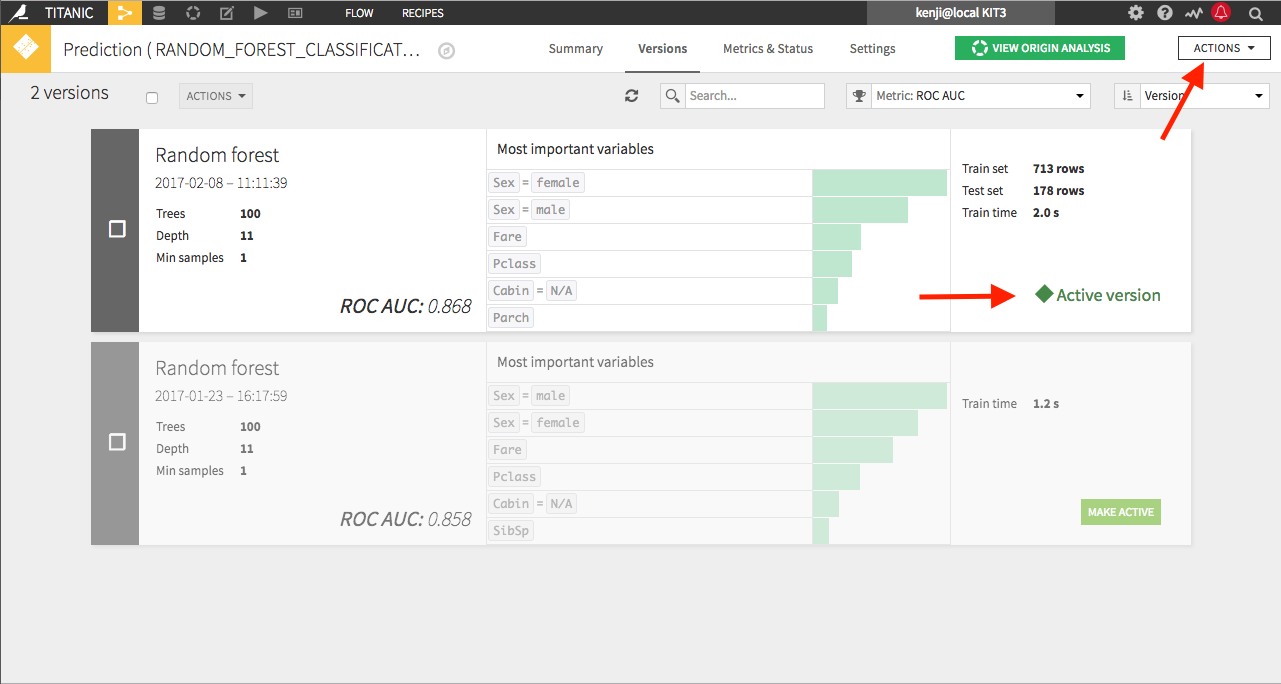
The new version of the model is activated, meaning it will be used when data is being scored with that “saved model”. Note that the old version of the model is kept so that you can rollback to this version if the new one is not satisfactory.
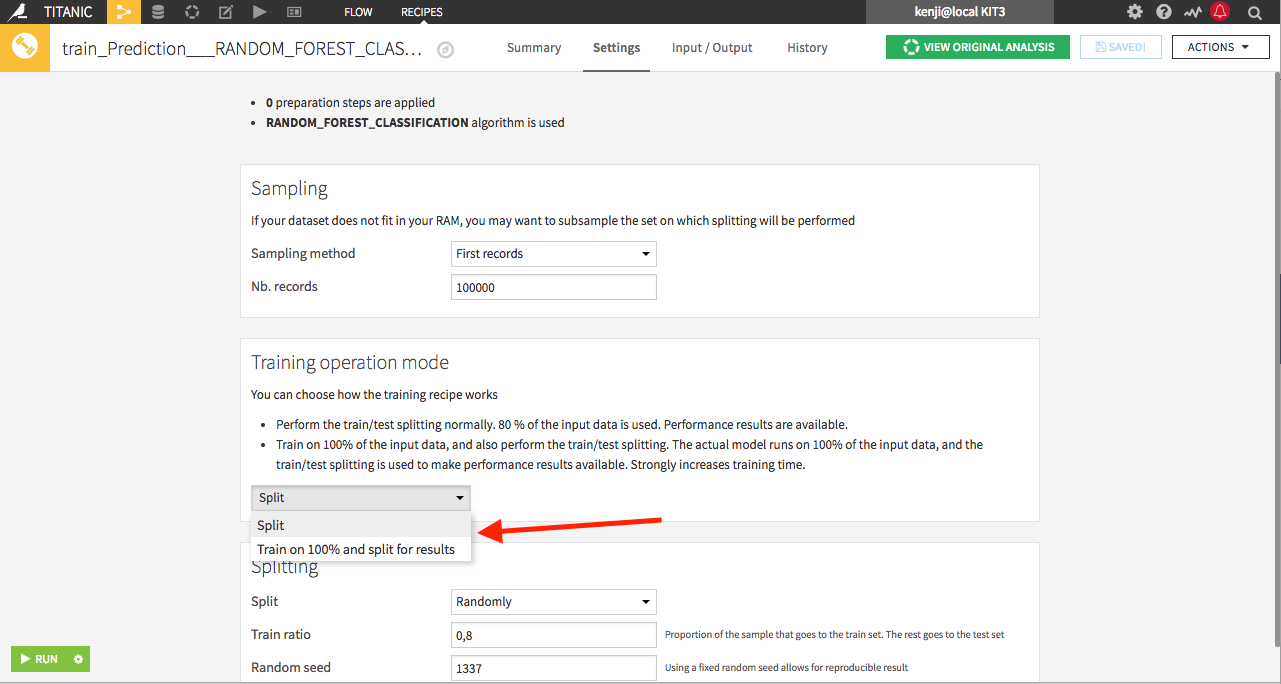
The train recipe does a lot more than just training a new model. When a new version is trained, Dataiku DSS automatically computes its associated performance metrics. The train recipe splits its input dataset into two datasets used for training and validation. By default, the model trained this way is used. If you want to use a model trained on the full input dataset, you can change the setting of the train recipe:
Monitoring a model and raising alerts¶
During the design and the training stage of a model, data scientists are validating its quality through metrics measuring the difference between its predictions and the actual values observed in the past.
When put into production, the model starts scoring data it has never seen. One can imagine a situation where because the train & validation of the design and train stages has not been set properly, the model in production scores badly. It is thus important to create a validation feedback loop to verify that the newly scored data achieves the original goal of the model.
In order to do so, one creates a new validation set composed of newly labeled data. Its rows contain both the score given in production by the model and the final observed values. One then uses an evaluation recipe to compute the true performance of the “saved model” against this new validation dataset:
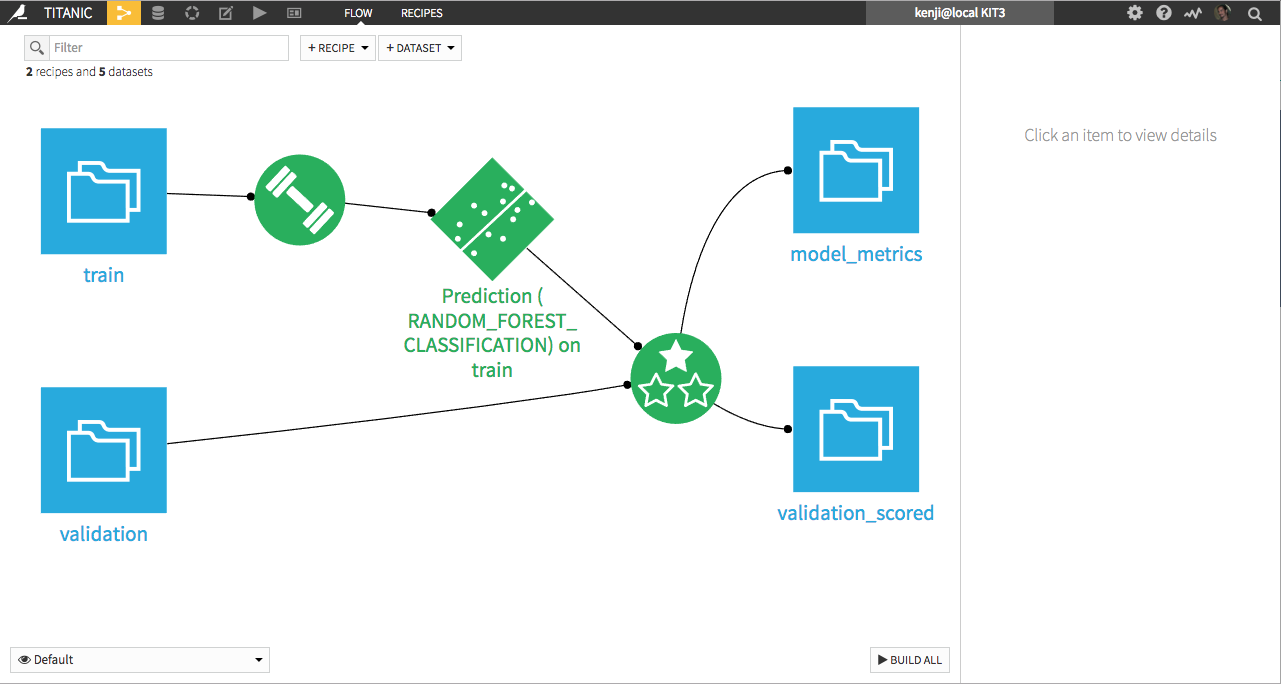
By frequently updating feedback loop validation data, one can monitor the model performance drift in time.
Automating all the above and monitoring everything¶
Note that you can use Scenarios to:
Automate the retraining of “saved models” on a regular basis, and only activate the new version if the performance is improved.
Rebuild the feedback loop validation dataset regularly and relaunch the evaluation recipe to get the most recent performance of the model.
Implement ad-hoc alerts raised when a given performance metric crosses a predefined threshold. You just need to define checks on metrics and upon check fail, Dataiku DSS will send an alert by email or to any centralized supervision tool!
Use metrics history on Dataiku Dashboards to create interfaces dedicated to the monitoring of your global pipeline.
Include the visual insights of the current active version of a “saved model” on the dashboard to allow the monitoring of model drifting by business users.