How to identify clusters and name them¶
Introduction¶
In this article we will study in details the machine learning aspect of our Geographic clustering sample project.
The aim of this project is to segment neighborhoods of Manhattan and Paris based on the type of locations and events that are present. Based on data from Open Street Map and Foursquare, we aggregate points of interest by type and count how many venues are present in each neighborhood.
This data serves as the basis for a clustering algorithm that will classify neighborhoods by type.
If you want to see how we achieve this, especially regarding data ingestion and preparation you can find details in the project’s description.
Another interesting aspect of this project is data visualization. You can see on the dashboard a map that uses the built-in chart engine, as well as a custom built web app. If you are interested in building web apps featuring maps, refer to our tutorial using SFPD data to build a crime map of the city of San Francisco.
Unsupervised algorithms for clustering¶
There are a variety of unsupervised machine learning algorithms for clustering tasks.
A clustering task consists of creating groups of objects that have high intraclass similarity and low interclass similarity. In other words, objects are similar to other objects in the same cluster, but dissimilar to objects in other clusters.
A usage example for clustering algorithms would be anomaly detection. This task can be seen as finding two classes in your data, separating the bulk of your observations from outliers. These will be identified as abnormal events because they do not resemble your usual data.
In that case, the algorithm will separate your data in two very unbalanced classes. Most of your data is going to be clustered together as usual events, while anomalies are going to be detected as outliers.
Unsupervised algorithms can also be used when you want to create subgroups within your data. You can train several clustering algorithms by varying the number of clusters, and see how many subgroups the algorithm can distinguish.
Important note about unsupervised algorithms¶
The most important thing to remember about unsupervised machine learning algorithms is that they can only be as good as the data they are provided! The algorithm will do its best to separate clusters based on the features it is given. So if your features are very varied in terms of real-life meaning or practical significance, you will get very heterogeneous results.
Let us think of an example here. If you are trying to cluster users coming to your website based on their browser settings, e.g. language, installed plugins, window size, country of origin, number of visits, OS… the algorithm will separate these the best it can, and you may end up with a cluster for “US mobile users using iOS”, and another for “desktop users that speak French or Spanish and reached your website for the first time”.
Well, it is pertinent, and objectively the best it could do with your data, but is this clustering going to help you take concrete business decisions? What actions can you take that target these groups? In this example, it would be better to keep similar features only, which will help separate your users into groups that have meaning for your business.
Geographic clustering features¶
In the sample project we associate points of interest from Open Street Map and Foursquare to the neighborhoods of the cities of Paris and Manhattan, NYC.
We chose to keep two types of features:
The first one is the number of locations based on their type, for both Open Street Map and Foursquare. This means we compute aggregated numbers for e.g. the number of restaurants in the area according to OSM and Foursquare. Some of the types of organizations are “Food”, “Universities”, “Events”, “Shops”, “Transportation”… You can see the aggregating recipe for the Foursquare data here.
The second one comes from Foursquare only, and is the aggregated number of checkins for this neighborhood.
Based on these two types of features, we can expect our clustering algorithm to create clusters mixing these two types. However, this heterogeneity is not problematic, as the first type of features is more about density of venues, while the second type is linked to popularity and frequency.
Selecting the number of clusters¶
We train multiple k-means models, trying with 4, 5, 6 or 7 clusters. We did not try with larger numbers of clusters as we wanted to keep things simple, and the final visualization would be harder to read with too many clusters.
After training, on the complete data for the borough of Manhattan, we decide that the most appropriate clustering model is able to differentiate 7 clusters. For the city of Paris, this number is 5.
Your decision can be helped by deploying your model to the flow and scoring the dataset you used for training. In the example of the city of Paris, the silhouette score is clearly in favor of the k=5 model.
Now that we have chosen the number of clusters and our model is deployed, we can start renaming the clusters.
Naming clusters¶
Summary information¶
When looking at the currently deployed model, you will see on the summary page a list of clusters. When you select a cluster, you will see a summary of its most prominent properties. The top characteristic features will guide you in naming your clusters.

Let’s take the example of cluster_2, which was renamed “Residential”. Its top three properties are:
nb_ShopService is in average 38.85% smaller
nb_TravelTransport is in average 42.49% smaller
nb_NightlifeSpot is in average 54.65% smaller
These properties indicate neighborhoods that don’t feature a lot of activity, and are not densely packed with shops or public transportation, nor places to go out. This information has to be understood in the context of what we are studying. Here, our subject is cities, and it is thanks to our knowledge, be it intuitive or professional, of urban design and of how cities are made that we can properly name this cluster.
Because we understand these neighborhoods are probably not too central, should have more housing and fewer offices, and are not popular places to go out, we decide to name the cluster “Residential”. This can of course be refined later when we have named all our clusters.
The takeaway message here is that it is your expertise that will let you properly name clusters. Try to read the properties of each cluster and to see the bigger picture! Try to think about the meaning, not just the numbers. And be aware of your own biases, do not try to find a cluster you are subjectively certain should be there…
Numerical heatmap¶
If you want to dig further into the meaning of the clusters, and the top three properties are just not enough, you can head to the “Numerical heatmap” section of the model. This will provide additional information about your clusters. Here is a screenshot of the heatmap in our example:
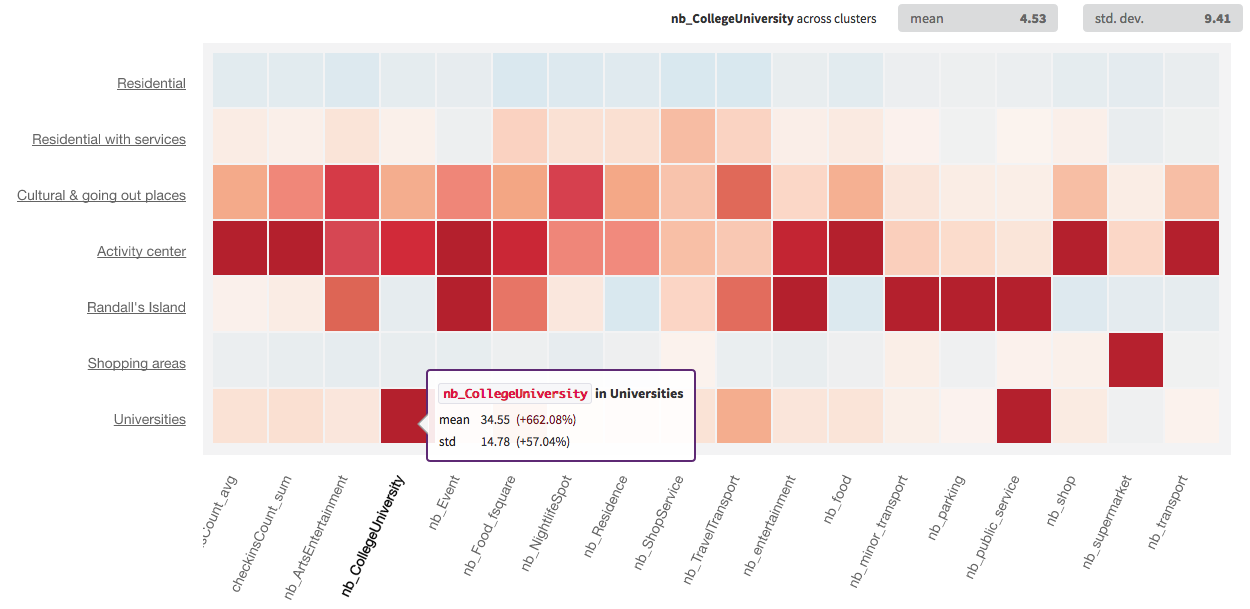
By looking at this heatmap, we see that the cluster we renamed “Residential” is indeed comprised of neighborhoods with very low activity.
Using visualization¶
Visualizing the data on a map of Paris and Manhattan also helped in naming some of the clusters, like Randall’s Island which was alone and an outlier!