Events Aggregator (Plugin)¶
Feature Factory is our global initiative for automated feature engineering. It aims to reduce the countless hours data scientists spend building insightful features.
The first outcome of this initiative is the EventsAggregator plugin, which works with data where each row records a specific action, or event, and the timestamp of when it occurred. Web logs, version histories, medical and financial records, and machine maintenance logs are all examples of events data.
The plugin can generate more than 20 different types of aggregated features per aggregation group, such as the frequency of the events, recency of the events, the distribution of the features, etc., over several time windows and populations that you can define. The generated features can outperform raw features when training machine learning algorithms.
Events Aggregator Settings¶
To use the plugin, there are critical pieces of information you need to provide:
A column that records the timestamp of when each event in the dataset occurred
One or more columns (aggregation keys) that define the group the event belongs to. For example, in an order log, the customer id provides a natural grouping.
The level of aggregation. The examples below will go into greater detail of how to use the level of aggregation.
In the By group case, the features are aggregated by group and the output will have one row per group.
In the By event case, for each event, all events before this event will be aggregated together. The output will contain one row per event.
Install the Plugin¶
Install the EventsAggregator plugin. This requires Administrator privileges on the Dataiku DSS instance.
How to Generate Features by Group¶
In this mode, features are aggregated by group and the output will have one row per group.
For example, we may have a dataset recording customer activity on an e-commerce website. Each row corresponds to an event at a specific timestamp. For a given fixed date, we want to predict who is most likely to churn. So we need to group the input dataset by user. The output dataset will then have one row per user.
For reference, the final flow will look like the following.
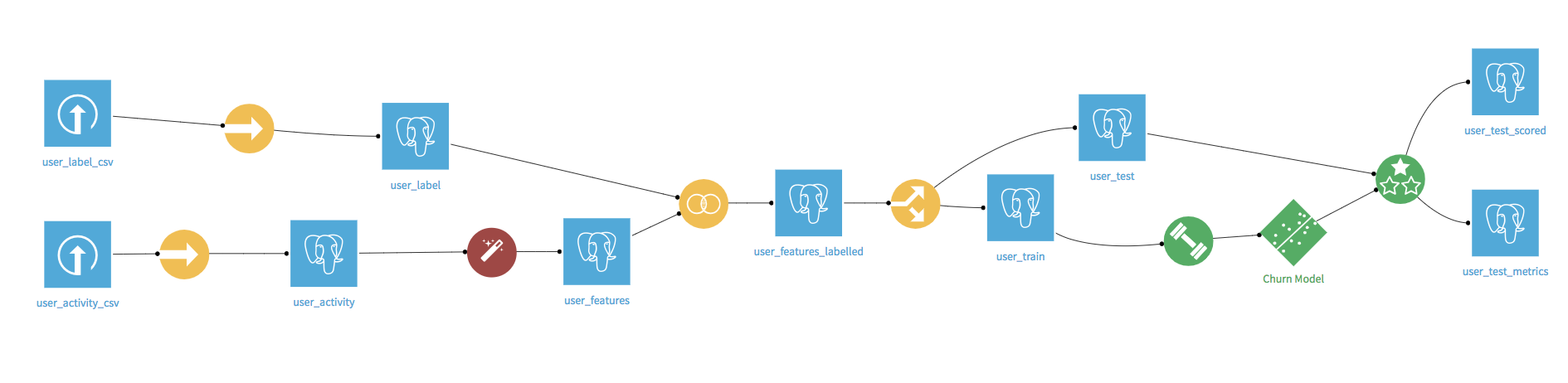
Preparing for the Events Aggregator¶
The flow begins with two CSV source files. Download the archive containing these files, extract them from the archive, and use them to create two new Uploaded Files datasets.
While creating each dataset, go to the Schema tab and click Infer types from data.
Next, we need to Sync these datasets to SQL datasets, because the plugin works on SQL datasets. Now the user_activity SQL dataset is ready for the Events Aggregator.
Applying the Events Aggregator¶
In the Flow, select +Recipe > Feature factory: events-aggregator to open the plugin recipe. Set user_activity as the input dataset, create user_features as the output dataset, and create the recipe.
We want to aggregate features for each customer, ending with a dataset that has one row per customer, so we define the groups by user_id and select By group as the level of aggregation. We also select event_timestamp as the column that defines when the events occurred.
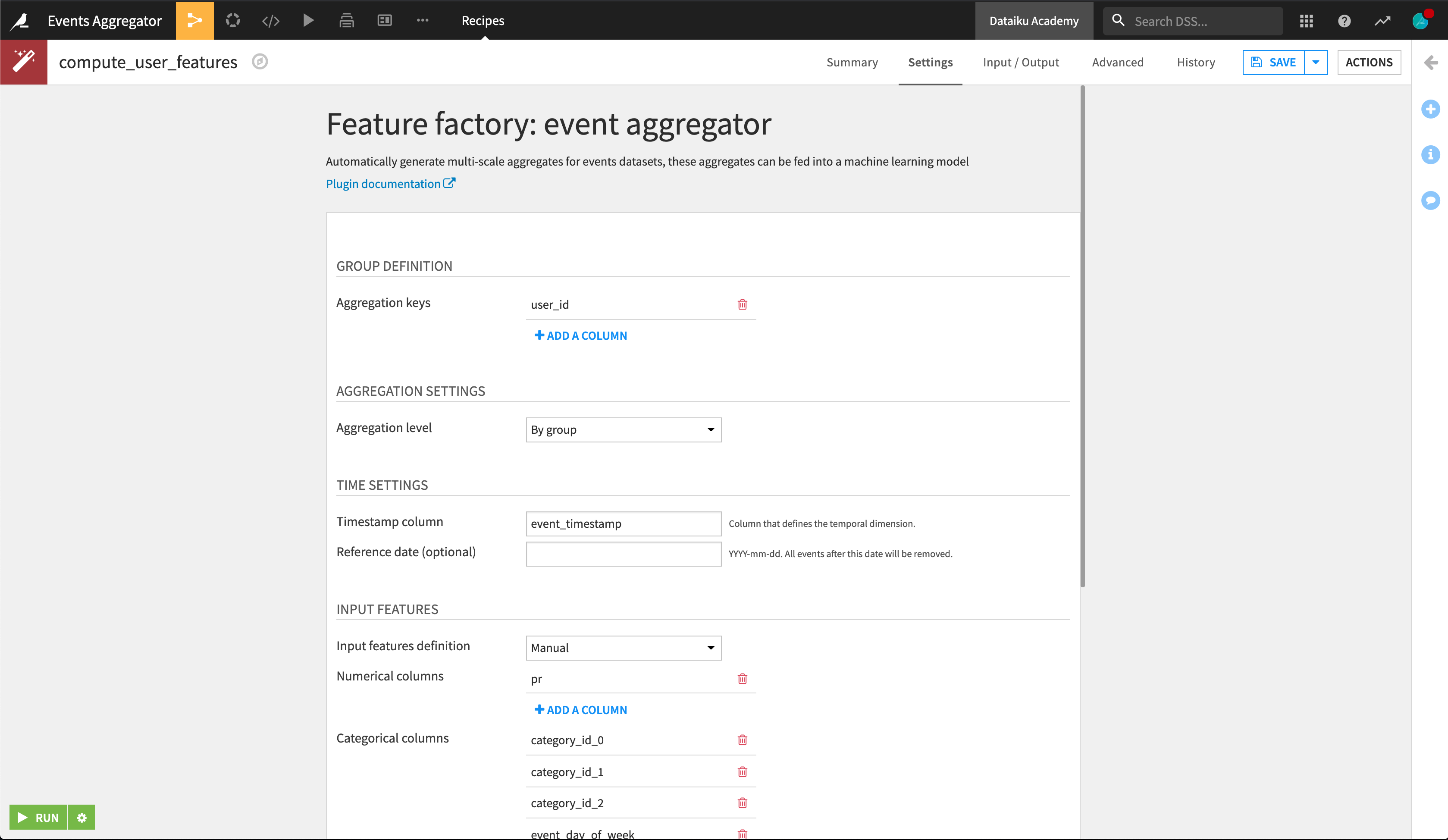
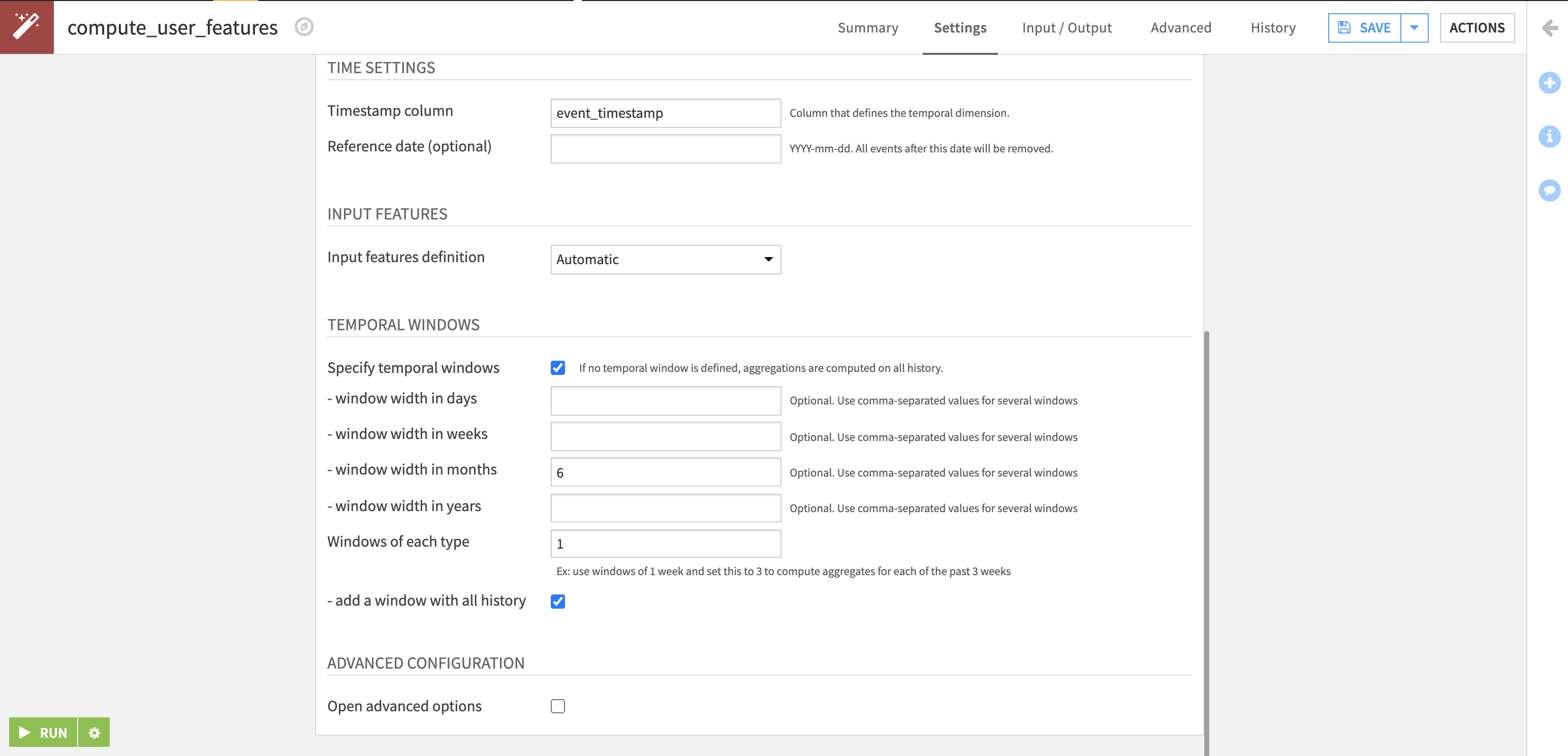
We chose to allow input feature definition to be automatic. The chosen columns are used to generate the output aggregated features.
In order to capture the mid-short term trend, we chose to add a temporal window with a window width in months of 6, and checked the box to add a window with all history. This means that in addition to computing features on the entire event history, the recipe will generate features for events in the 6 months prior to the present.
If we wanted to generate features for each 6 month window going back for a year, we would change the setting of Windows of each type from 1 to 2.
Machine Learning¶
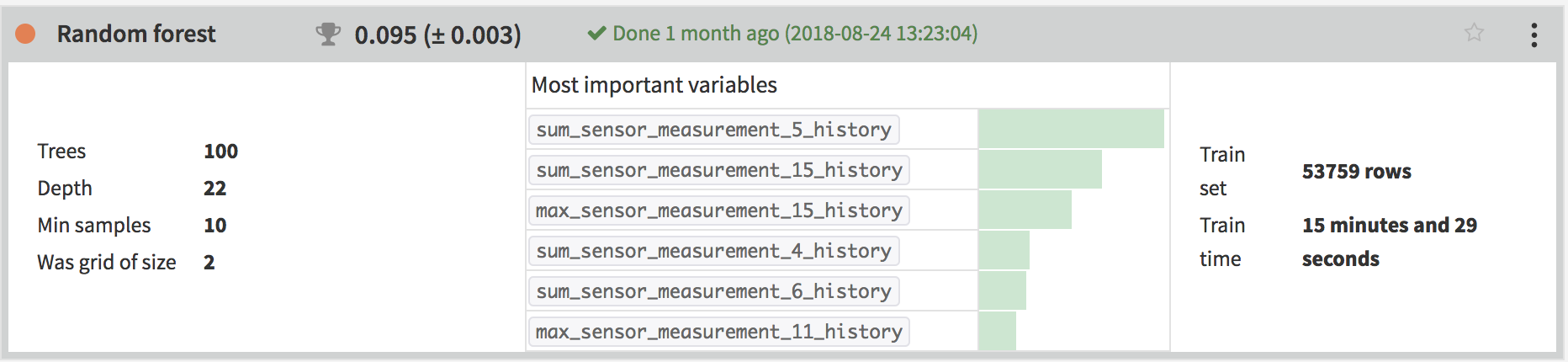
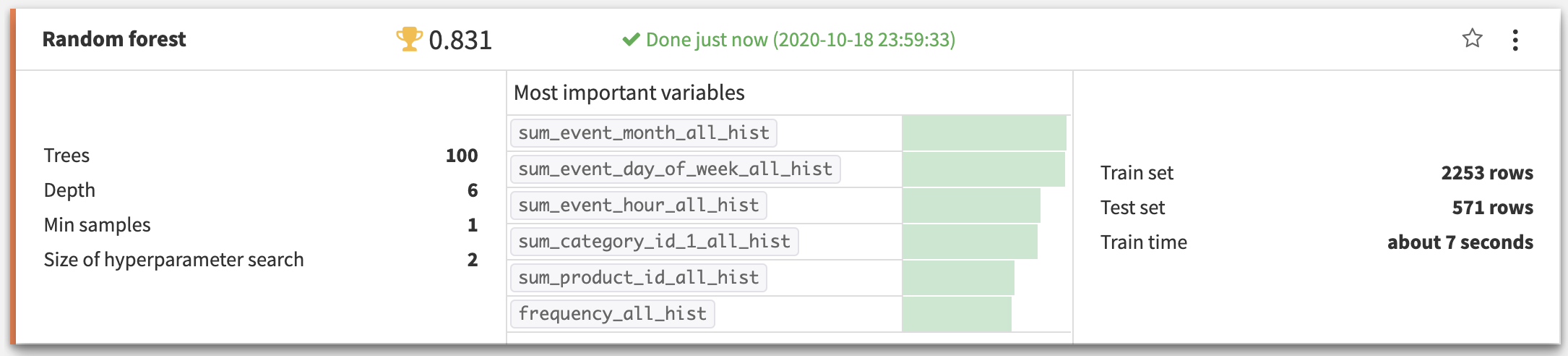
The output dataset now contains dozens of features. We join this dataset with the user_label dataset, split the resulting dataset with a 70/30 random split into train and test sets, and can now directly use the new features for predicting the target column in the Visual Machine Learning interface. We deployed a Random Forest to the flow, and used it to score the test set.
How to Generate Features by Event¶
In this mode, for each event, all events before this event will be aggregated together. The output will contain one row per event.
For example, we may have a dataset recording sensor activity for different machines. Each row corresponds to an event at a specific timestamp. For any given time, we want to predict how long it will be until the machine will fail. So we need to group the input dataset by machine, and aggregate by event. The output dataset will then have one row per engine and timestamped event.
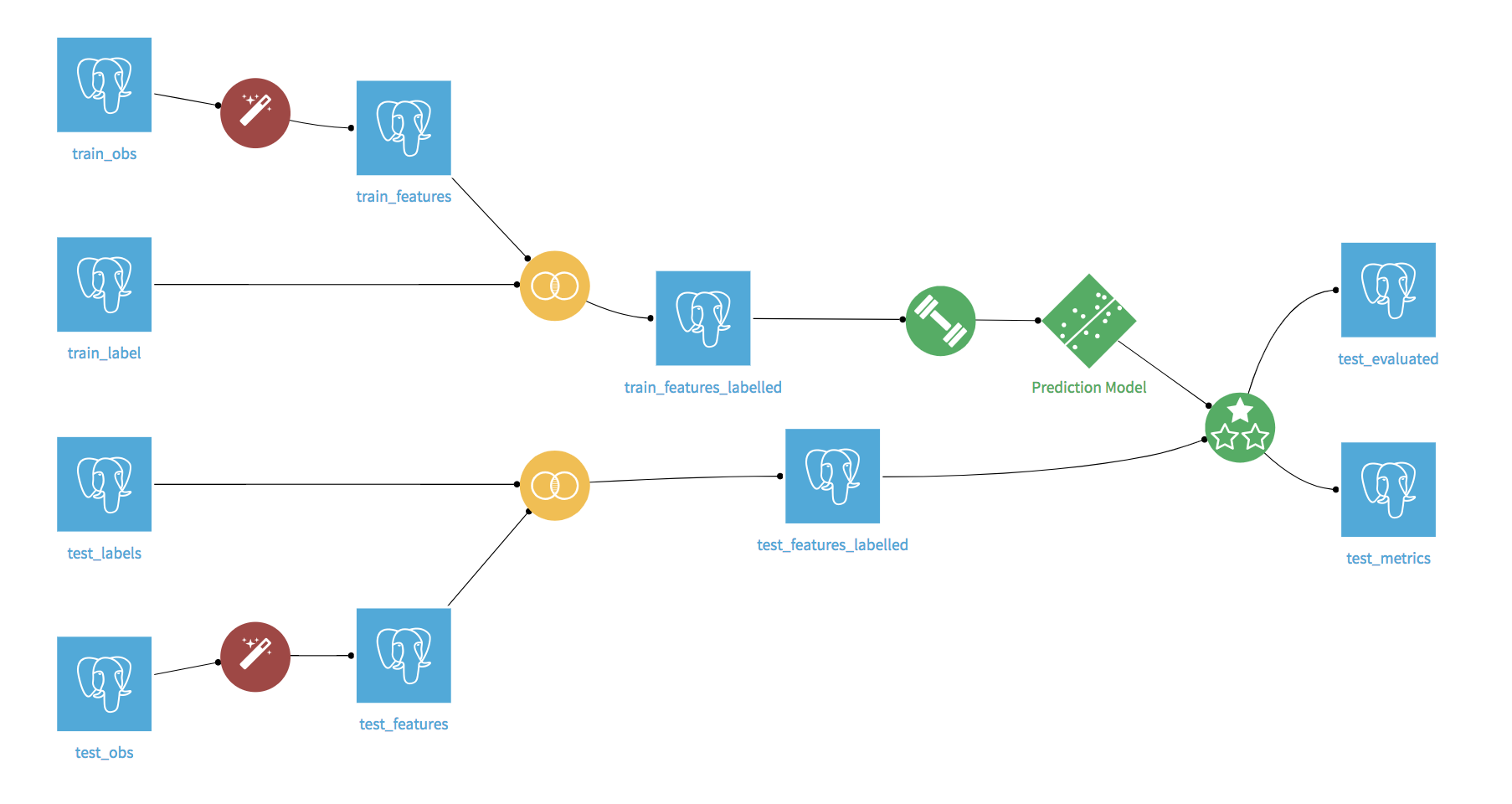
For reference, the final flow will look like the following. Note: in the flow below, we loaded the data into PostgreSQL tables, so the flow begins with PostgreSQL datasets, rather than Uploaded Files datasets.
Preparing for Events Aggregation¶
The flow begins with four datasets: train observations, test observations, and their corresponding label datasets. Both the train and test observation datasets contain sensor measurements of the engines as well as operational settings conditions. The label datasets contain information on how long it will be before a given engine at a given timestamp will require maintenance.
These datasets are based on data simulated by NASA to better understand engine degradation under different operational conditions. We have modified the FD002 sets to include a time column. You can download the archive containing our modified files, extract them from the archive, and use them to create four new Uploaded Files datasets. For each dataset, go to the Schema tab and click Infer types from data.
Next, we can use Sync recipes to sync each of these datasets to SQL datasets, because the plugin works on SQL datasets. Now the train_obs and test_obs SQL datasets are ready for the Events Aggregator.
Applying the Events Aggregator¶
In the Flow, select +Recipe > Feature factory: events-aggregator to open the plugin recipe. Set train_obs as the input dataset, create train_features as the output dataset, and create the recipe.
We want to build rolling features for each engine, ending with a dataset that has one row per event per engine, so we define the groups by engine_no and select By event as the level of aggregation. We also select time as the column that defines when the events occurred.
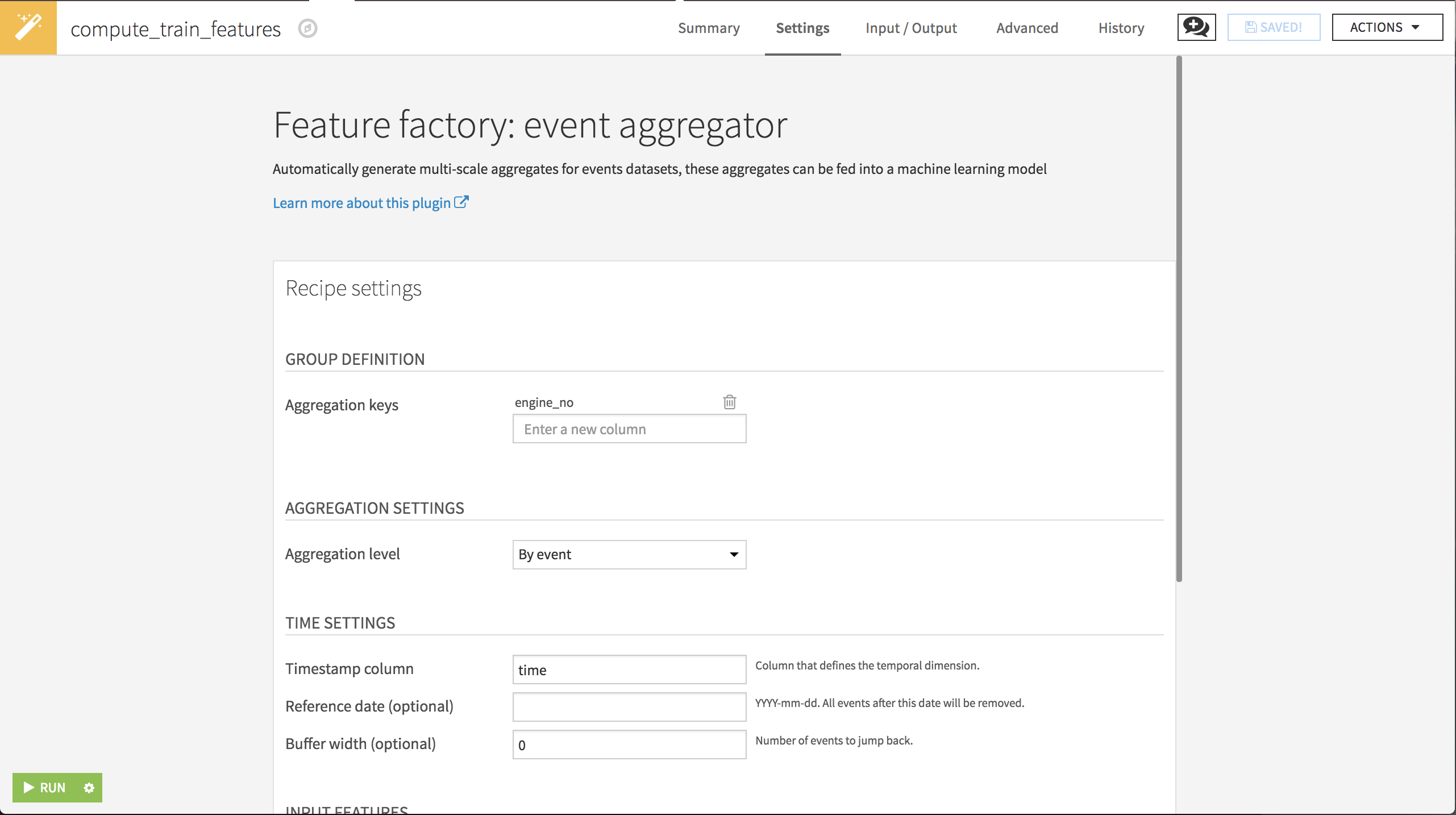
We’ll allow the recipe to automatically select the raw features, and we won’t define any temporal windows.
Repeat the process, using the test_obs dataset as the input and creating test_features as the output.
Machine Learning¶
The output datasets now have over 100 features. We join the observations datasets with the labeled datasets, and can now directly use the new features for predicting the label in the Visual Machine Learning interface. We deployed a Random Forest to the flow, and used it to score the test set.