Deploying Multiple Models to the API Node for A/B Testing¶
Deploying a Model to the API Node¶
Once you have successfully trained a machine learning model in Dataiku DSS, you may want to deploy it as an API service.
Deploying to an API node exposes a REST API that you can query to get scoring results. You can request an URL with a list of features to get a single score, or send in a batch and receive multiple scores in a row.
Note
You can learn more on deploying an API service by reading our documentation on the matter.
Multiple generation¶
In this tutorial, we will go further than what was covered in the video. The tutorial taught you how to deploy an endpoint package and how to query it.
Here we will cover what happens when you upload a newer version of your endpoint, how you can switch to that newer version, and also how to run multiple generations at once.
Managing versions: update¶
When you have updated your model within the flow of your project, you may want to expose the new version in your API node.
Create a new package, increment the version name (this should be done automatically), and download the package.
Copy or upload the package to a location your API node can access and use:
./bin/apinode-admin service-import-generation <SERVICE_ID> <PATH TO ZIP FILE>
Then to switch to this newer version of the endpoint, you can use
./bin/apinode-admin service-switch-to-newest <SERVICE_ID>
When this command returns, the API node service is active and runs on the latest generation of the package.
Checking what version is running¶
You can check what generation is running by using the command:
./bin/apinode-admin service-list-generations <SERVICE_ID>
You will see a result looking like this:
Gen. Tag Created Mounted Mapped % ---------- ------------------- --------- ---------- v1 2017-04-24 17:30:58 False 0 v2 2017-04-24 17:31:01 True 100
This indicates that only the latest version is active, and thus used 100% of the time. What if you wanted to have multiple active generations?
This is possible by specifying a mapping and enabling multiple versions with a given probability to be used for each query received by the node. The only constraint is that the probabilities of using each version must sum to 1.
Activating multiple versions¶
To specify a mapping you will use the command apinode-admin service-switch-to-newest.
The mapping is written in the JSON format and contains entries, each specifying a generation and the corresponding proba.
An example mapping could be:
{"entries":
[
{"generation": "v1",
"proba": 0.5
},
{"generation": "v2",
"proba": 0.5
}
]
}
This mapping is read by the command as a standard input, not as an argument. To use it you would write in your terminal:
echo '{"entries":
[
{"generation": "v1",
"proba": 0.5
},
{"generation": "v2",
"proba": 0.5
}
]
}' | ./bin/apinode-admin service-set-mapping <SERVICE_ID>
And this would result in a list of active generations looking like this:
Gen. Tag Created Mounted Mapped % ---------- ------------------- --------- ---------- v1 2017-04-24 17:30:58 True 50 v2 2017-04-24 17:31:01 True 50
Preparing for A/B testing¶
Now that multiple generations of your model are active simultaneously, they will be selected at random to score each of your requests to the server.
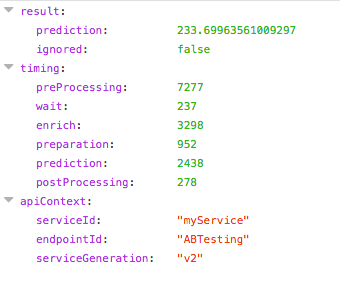
The response from the server will contain the generation of the endpoint that was used for predicting that particular call, under the apiContext, serviceGeneration key. Here is an extract of an example response:
Reading query logs¶
The API node includes powerful logging capabilities, to see the full extent please read the reference on logging and auditing.
You can import the logs in Dataiku DSS as a dataset and A/B test your models! An example project illustrating this will be made available soon.