Hands-On: Cleaning Text Data¶
In the previous hands-on exercise, we created a baseline model to classify movie reviews into positive and negative reviews. At this point, you should have an existing visual analysis on the prepared training data.
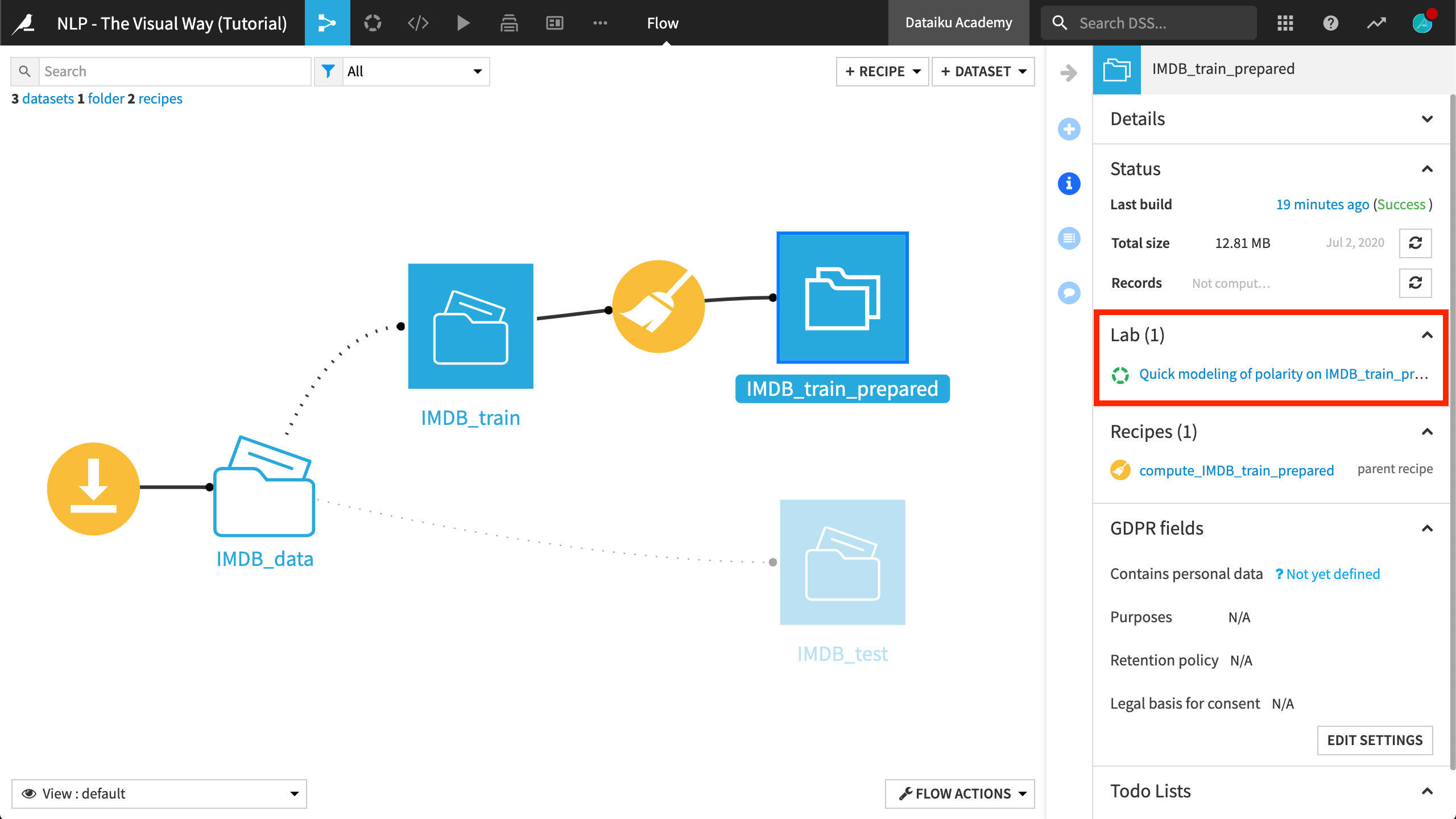
In this exercise, let’s try to improve performance with some simple text cleaning steps.
The Simplify Text Processor¶
Returning to our project in Dataiku DSS, open the Prepare recipe that produces the IMDB_train_prepared dataset.
Dataiku DSS recognizes the meaning of the text column to be “Natural language”. Accordingly, we can take advantage of the suggested transformation steps.
From the context menu of the column header, choose to Simplify text.
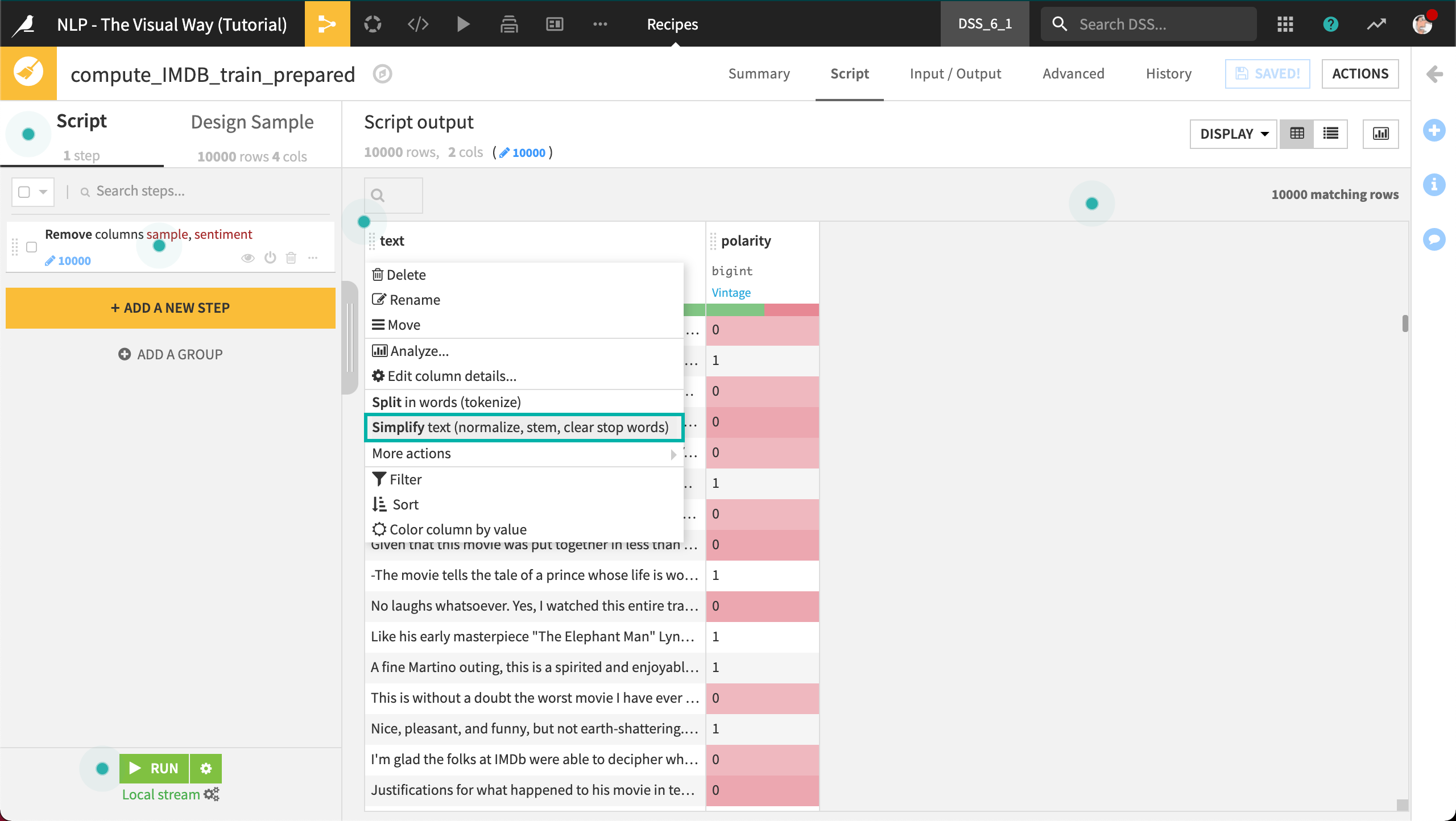
This option adds the Simplify text processor to the script.
Leave the output column blank to transform the text in the same column.
Select the options to “Stem words” and “Clear stop words”.
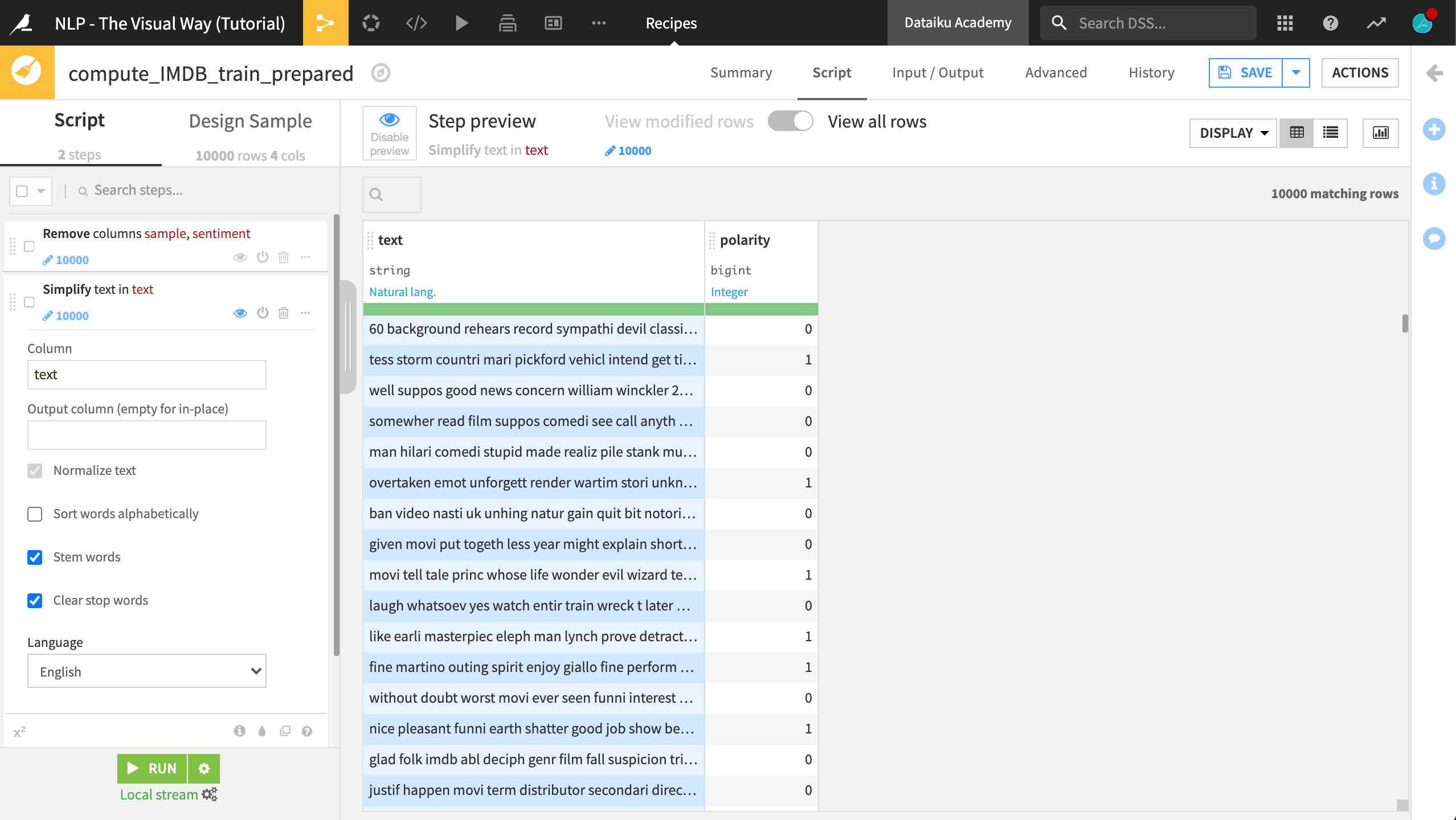
Run the Prepare recipe to produce a new version of IMDB_train_prepared.
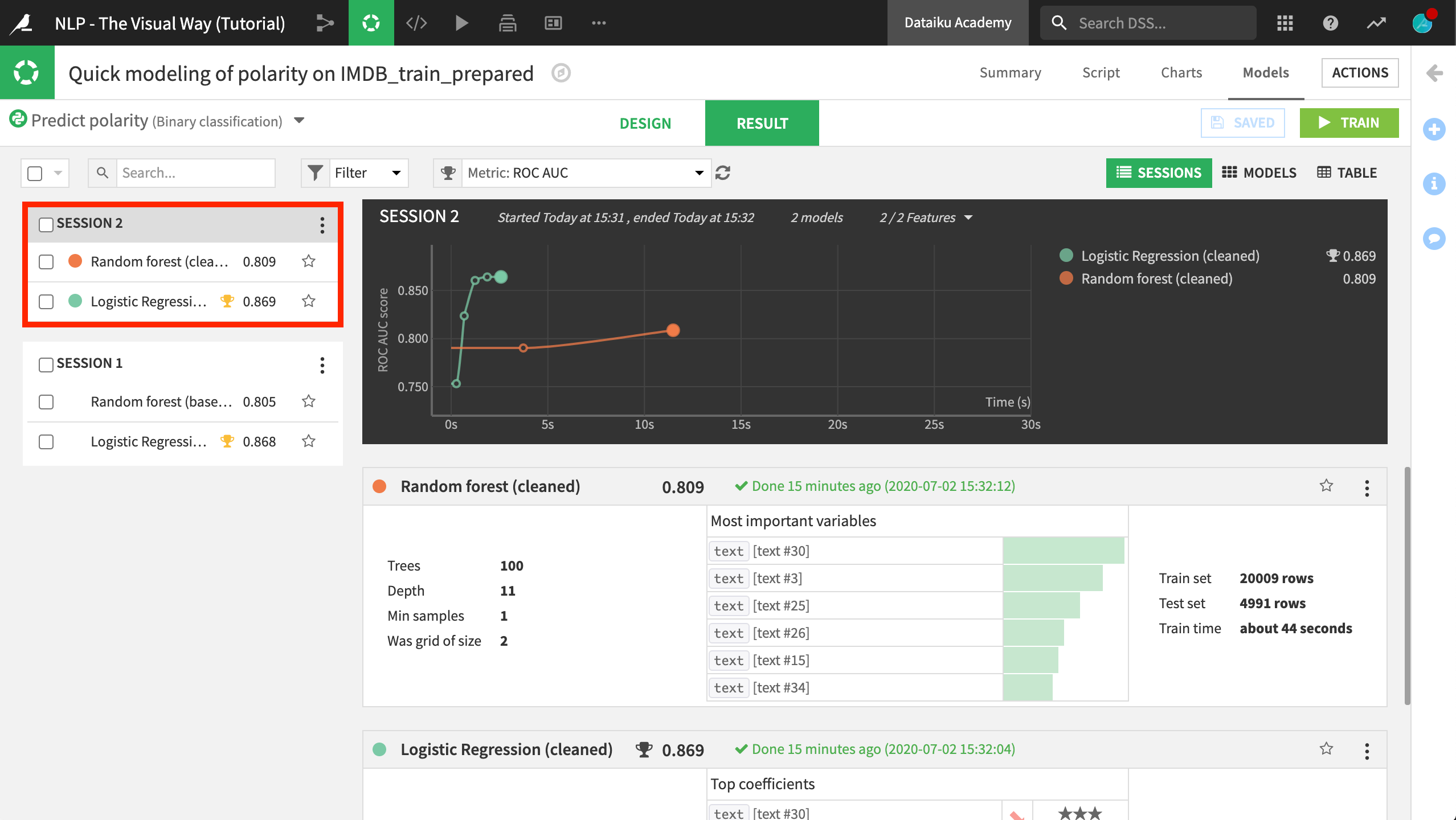
Return to the previous modeling task, Quick modeling of polarity on IMDB_train_prepared.
Click Train again, giving the session a name like
cleaned.
In this case, cleaning the text led to only very minimal improvements over the baseline effort. This does not mean, however, that this was not a worthwhile step. We still significantly reduced the feature space without any loss in performance.
Formulas¶
Next, let’s try some feature engineering. Return to the Prepare recipe.
Add a new Formula step.
Name the output column
length.Use the expression
length(text)to calculate the length in characters of the movie review.Click “Run” and update the schema.
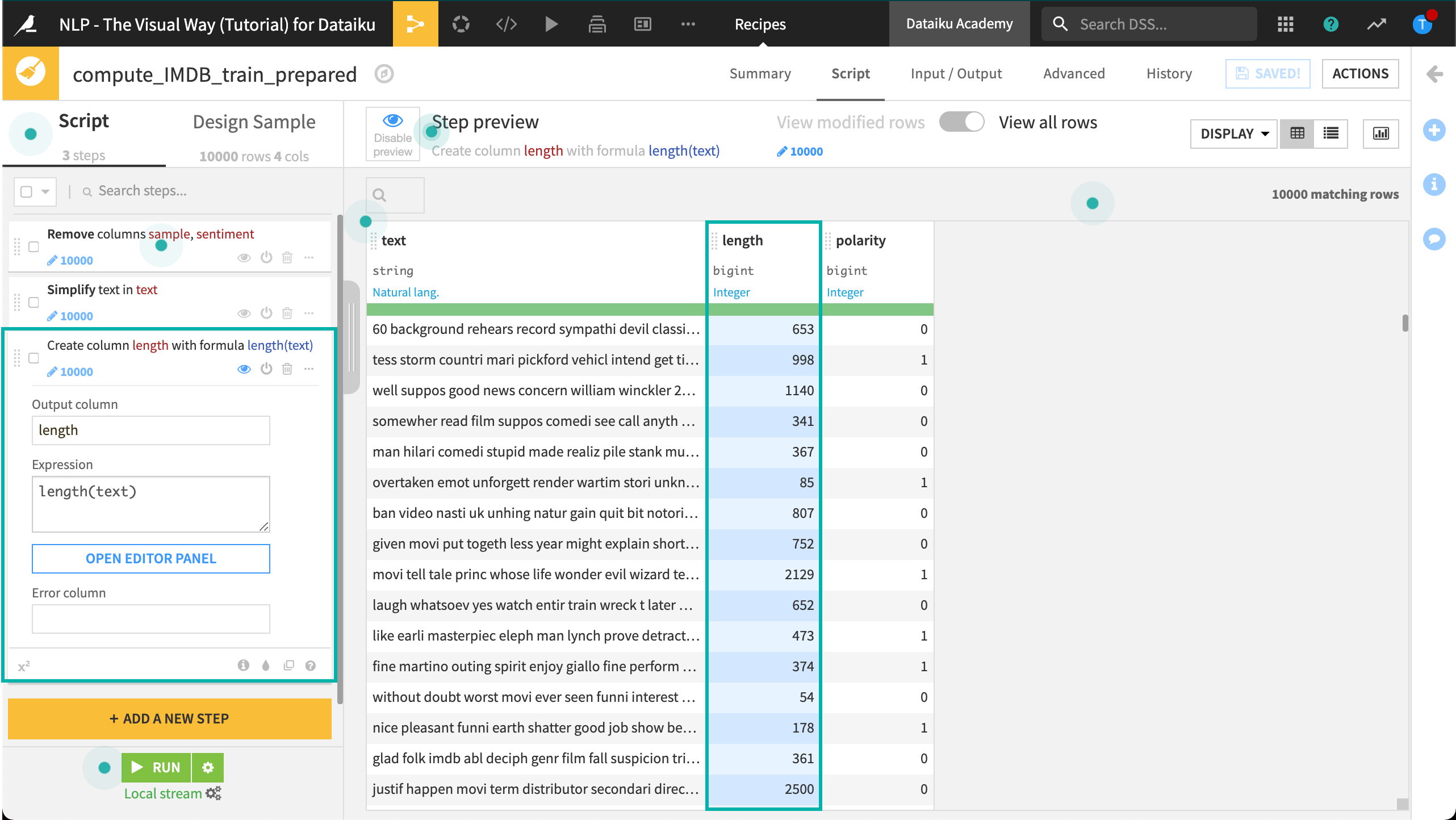
Note
You can use the Analyze tool on the new length column to see its distribution from the Prepare recipe. You could also use the Charts tab in the output dataset to examine if there is a relationship between the length of a review and its polarity.
With this new feature included in the IMDB_train_prepared dataset, return to the dataset’s associated modeling task. If we check the Features handling pane in the Design tab, we’ll see the new length feature included for training in the model.
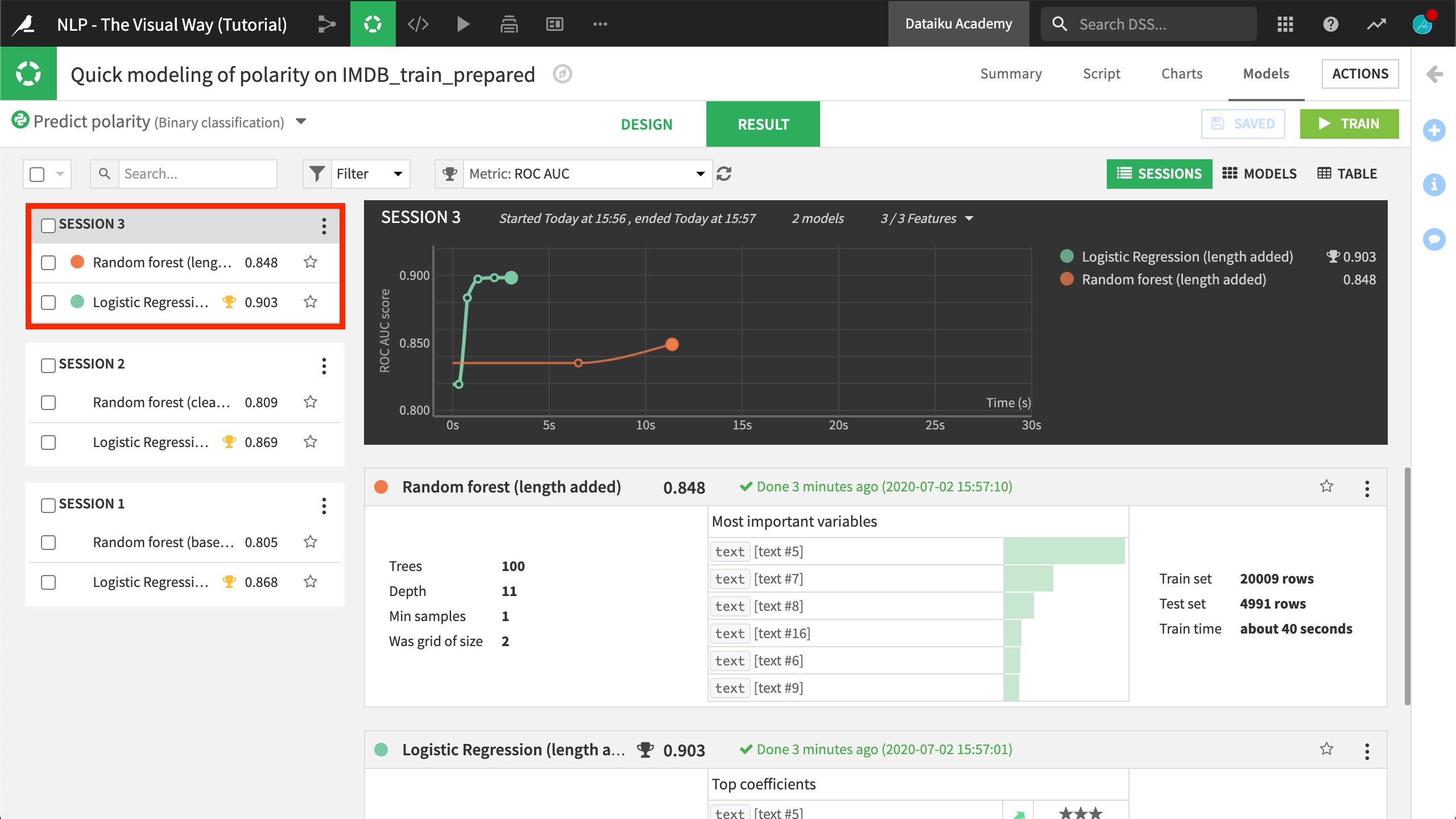
Click Train, providing the session name
length added.
We see a bit more improvement in both the logistic regression and random forest models.
Feel free to experiment by adding new features on your own. For example, you might try:
Use more formulas to calculate the ratio of the string length of the raw and simplified text column.
Use the Extract numbers processor to identify which reviews have numbers.
Use the Count occurrences processor to count the number of times some indicative word appears in a review.
What’s Next?¶
Aside from the specific results we witnessed here, the larger takeaway is the value that text cleaning and feature engineering can bring to any NLP modeling task.
However, these are not the only tools at our disposal. In the next hands-on lesson, we’ll experiment with different text handling strategies in the model design.