How to use spaCy models in Dataiku DSS¶
Greetings fellow Linguists,
To use spaCy models in Dataiku DSS, you can start by installing it like any other Python package in Dataiku DSS:
by creating a code environment and adding “spacy” to your package requirements.
To do so, follow this documentation.
However, some functionalities of spaCy, such as language-specific tokenizers, rely on models that are not bundled in the library itself. To use these models, you need an additional download step. Typically, this can create issues on shared DSS nodes where users do not have write access to shared locations on the server (see User Isolation Framework).
To overcome this challenge, you can use spaCy dedicated pip delivery mechanism. For instance, in your code-env requirement setting, add https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-2.2.5/en_core_web_sm-2.2.5.tar.gz.
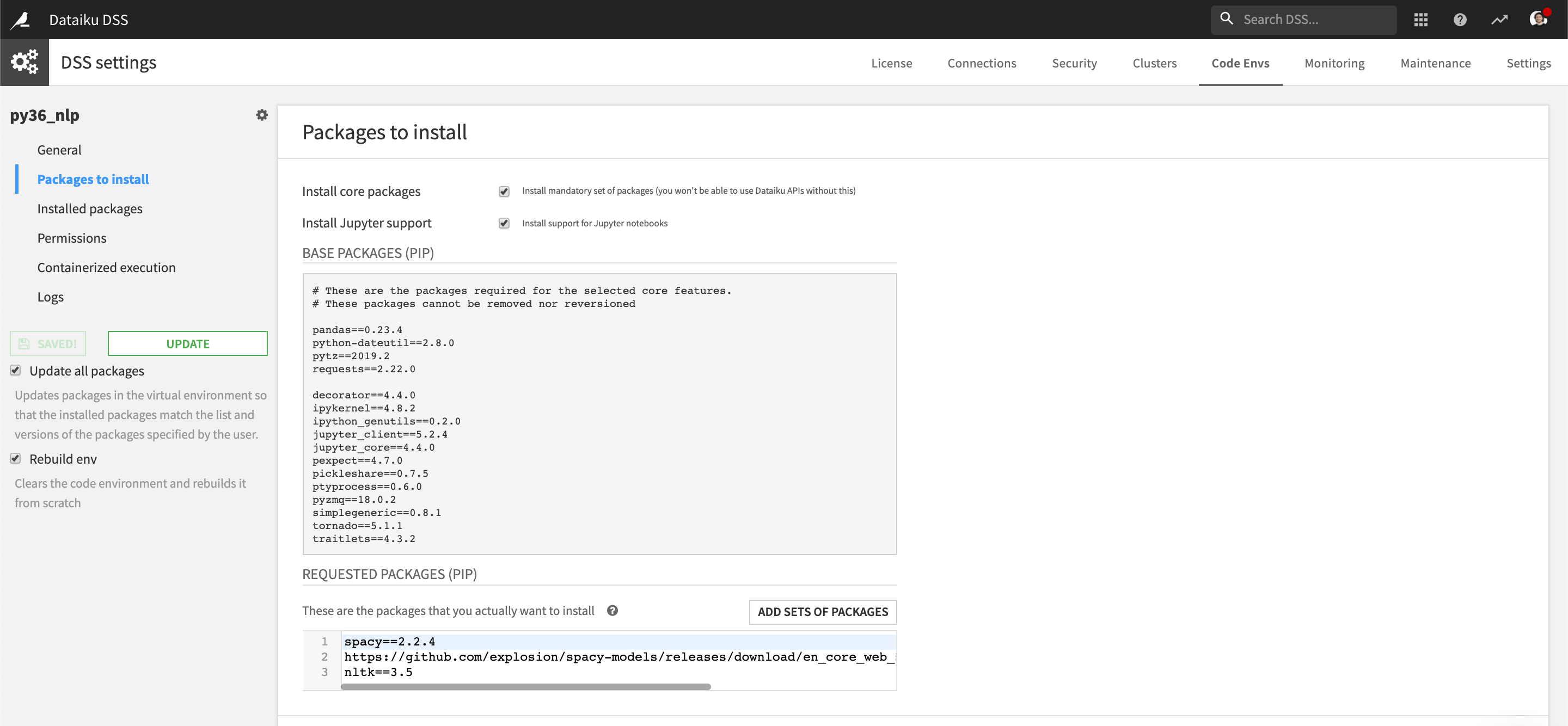
After adding this link, rebuild your code environment. To test that it works correctly, run the following code in a notebook using this code environment.
import spacy
nlp = spacy.load("en_core_web_sm")
Voila! You can now use spaCy along with its dedicated English language model.
Happy natural language processing!