Concept: Metrics & Checks¶
In this lesson, we introduce the:
challenges of automation,
the nature of metrics and checks,
why they are crucial for automation, and
how to leverage them in Dataiku DSS.

Tip
This content is also included in a free Dataiku Academy course on Automation, which is part of the Advanced Designer learning path. Register for the course there if you’d like to track and validate your progress alongside concept videos, summaries, hands-on tutorials, and quizzes.
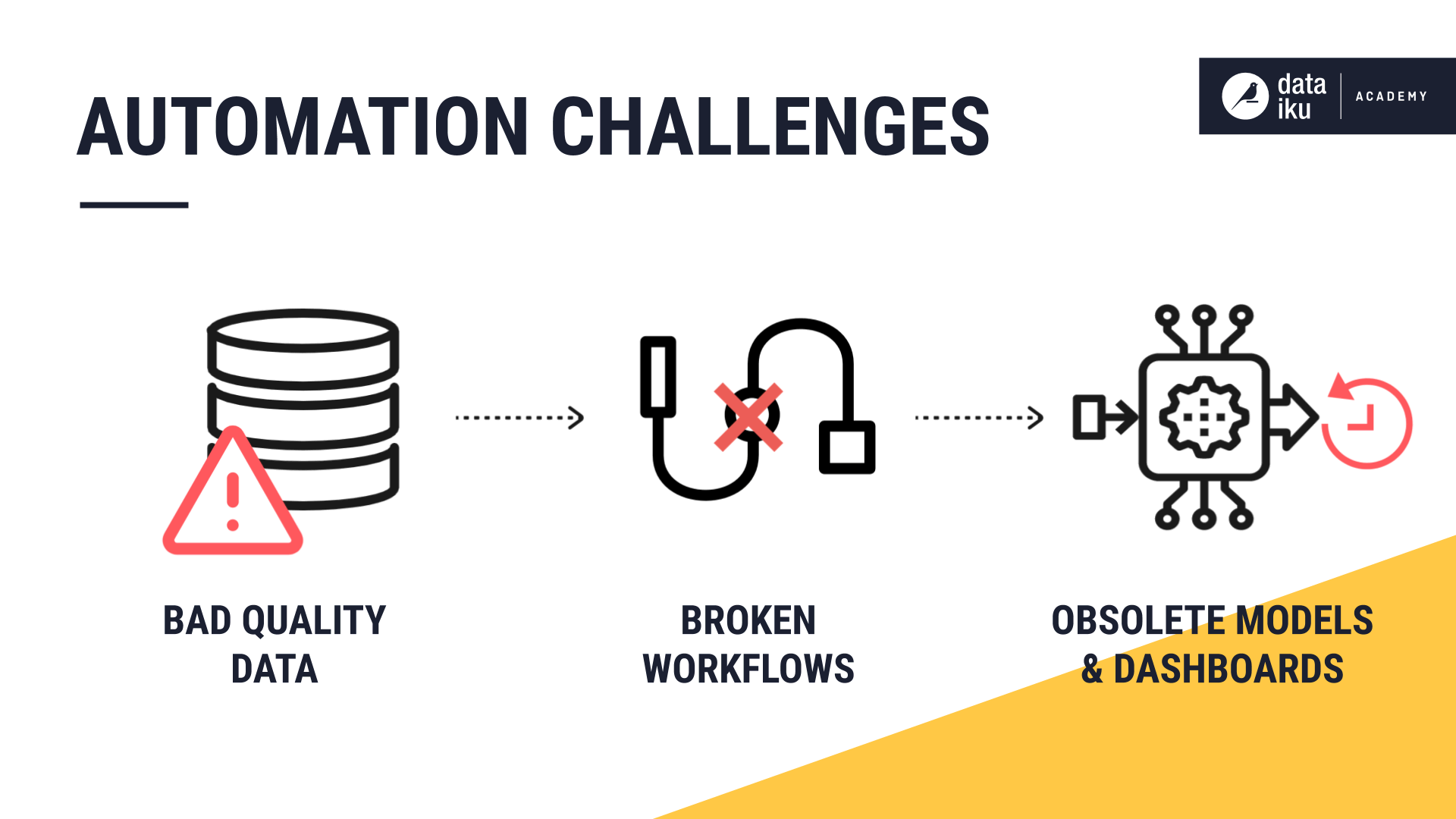
Automation Challenges¶
The lifecycle of a data or machine learning project doesn’t end once a Flow is complete. To maintain our workflows and improve our models, we must continuously feed them new data. Automation allows us to do this more efficiently by reducing the amount of manual supervision.
However, as we automate workflows, we are exposed to some risks, such as ingesting poor quality data without knowing it, which could affect output datasets, models, and dashboards.
For instance, our workflow could become broken as an extra column is added to an input dataset. Or, our model could stop capturing the pattern in the data and become obsolete.
While automation promises to save time, it also creates the need to implement key metrics and checks, so that our project doesn’t break and remains relevant.
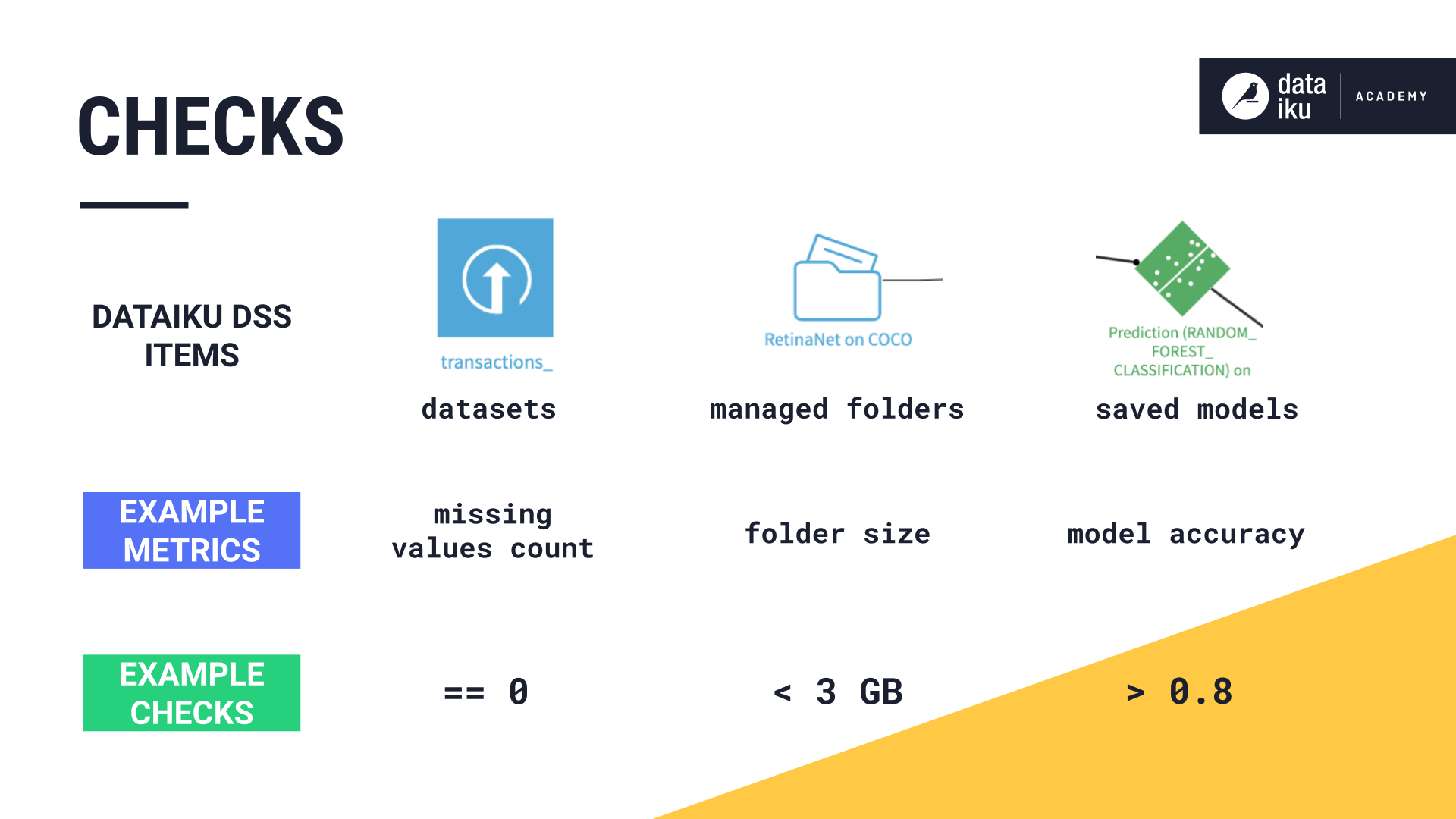
Defining Metrics¶
Metrics are metadata used to take measurements on the following Flow items:
datasets,
managed folders, and
saved models.
They allow us to monitor the evolution of a Dataiku DSS item. For example, we could compute:
the number of missing values of a column,
the size of a folder, or
the accuracy of a model.
Metrics can also be set on partitioned objects and be computed on a per-partition basis.
Defining Checks¶
Metrics are often used in combination with checks to verify their evolution.
For instance, we could:
check that there are no missing values for a given column,
that the size of a folder does not exceed 3GB, or
that the model accuracy does not fall below 0.8.
Checks return one of the four following status updates after each run:
EMPTY if the metrics value hasn’t been computed;
ERROR if the check condition has not been respected;
WARNING if the check fails a “soft” condition but not a “hard” one;
OK if the check should not raise any concern.

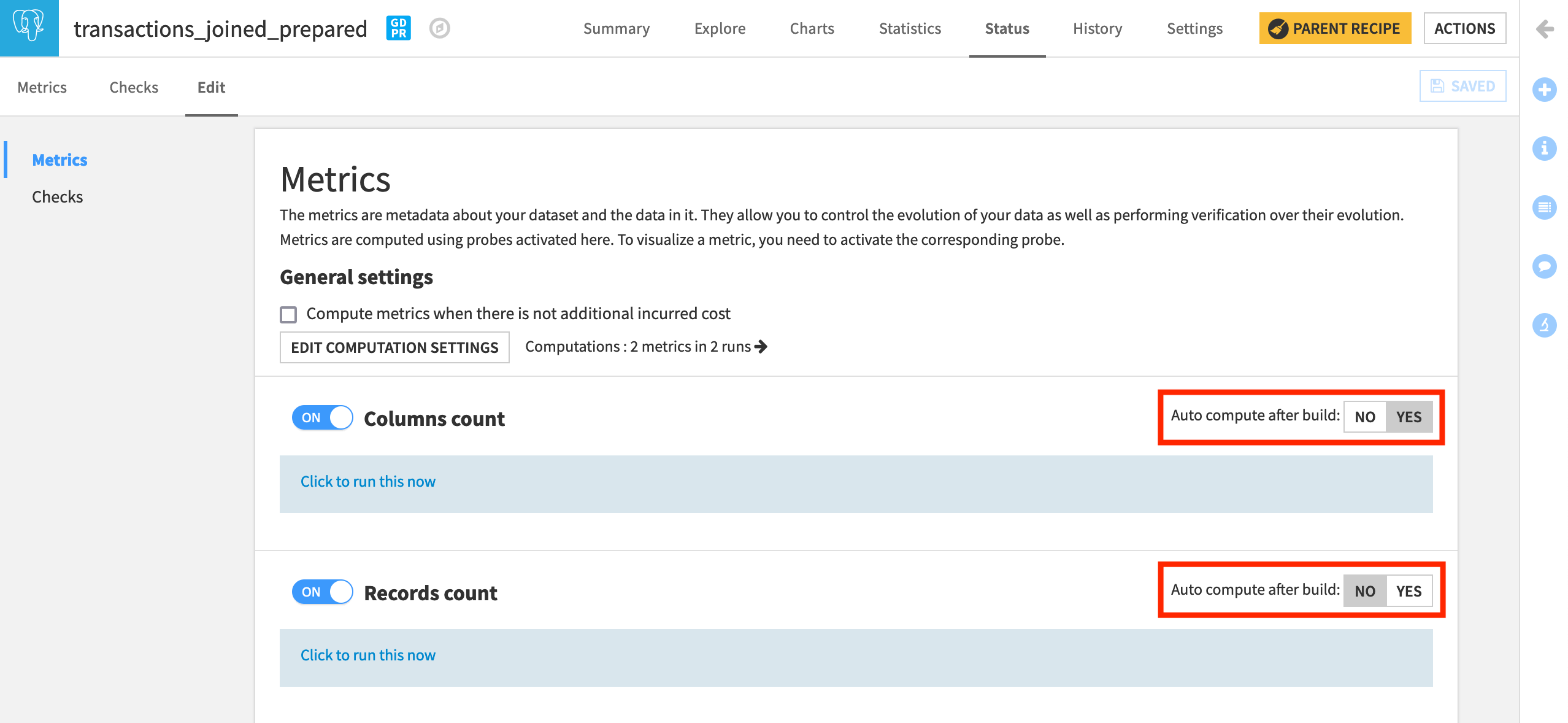
Metrics and checks can be set to be computed automatically after a rebuild, if desired.
Depending on the outcome of the checks, some actions could be triggered, such as, for example:
retraining a model,
sending a report,
refreshing a dashboard, etc.
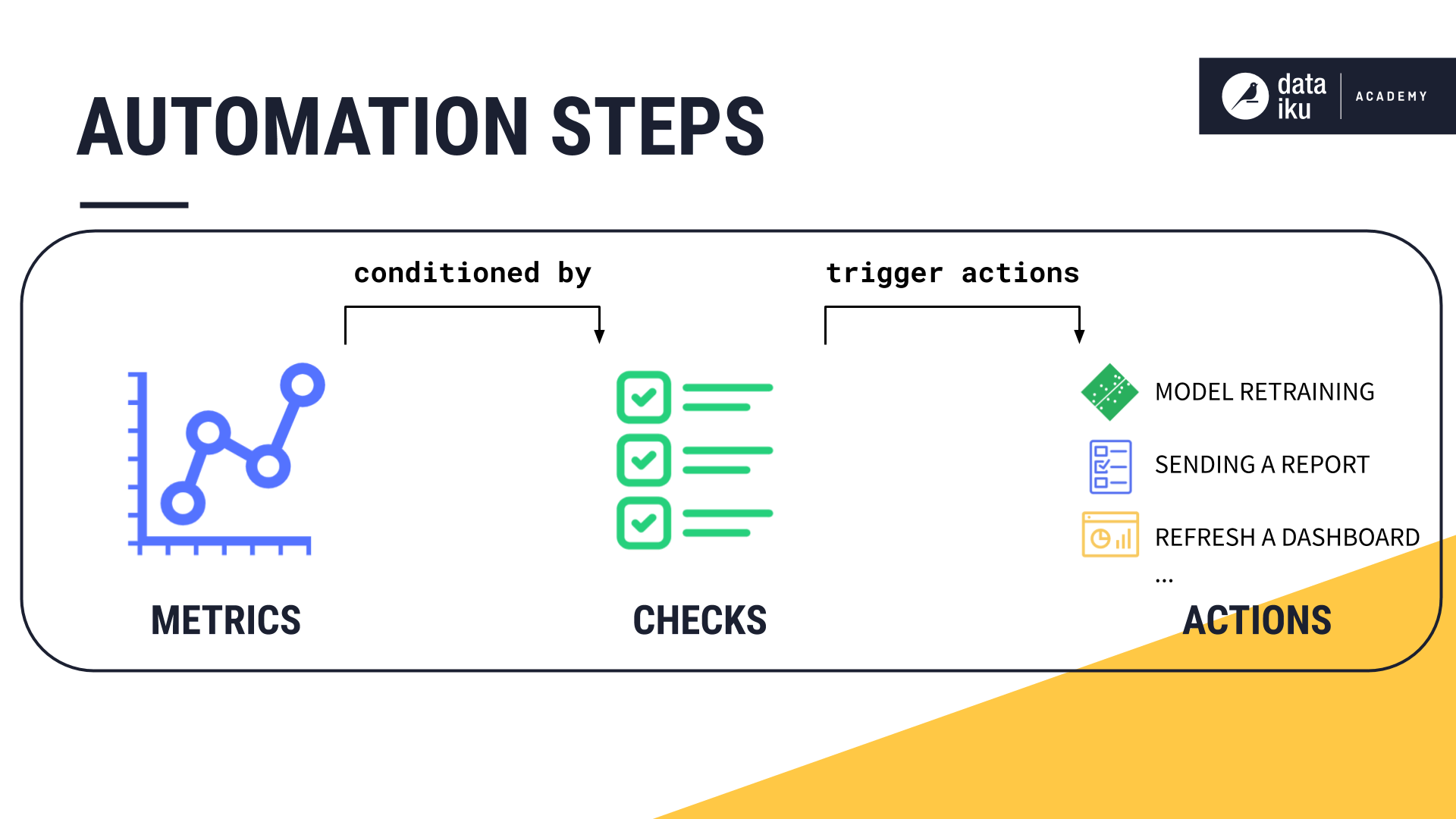
This can be achieved through scenarios. The scope of the scenario will be presented in the next lesson.
Viewing Metrics¶
Now let’s see in practice how we can leverage metrics and checks in Dataiku DSS. We’ll work on a dataset containing credit card transaction data.
Metrics and checks can be accessed from the Status tab on a dataset, a managed folder, or a machine learning model.
When you enter the Status tab, you are presented with the default “Last Value” view of the metrics, which is a “tile view” displaying the latest value of each selected metric.
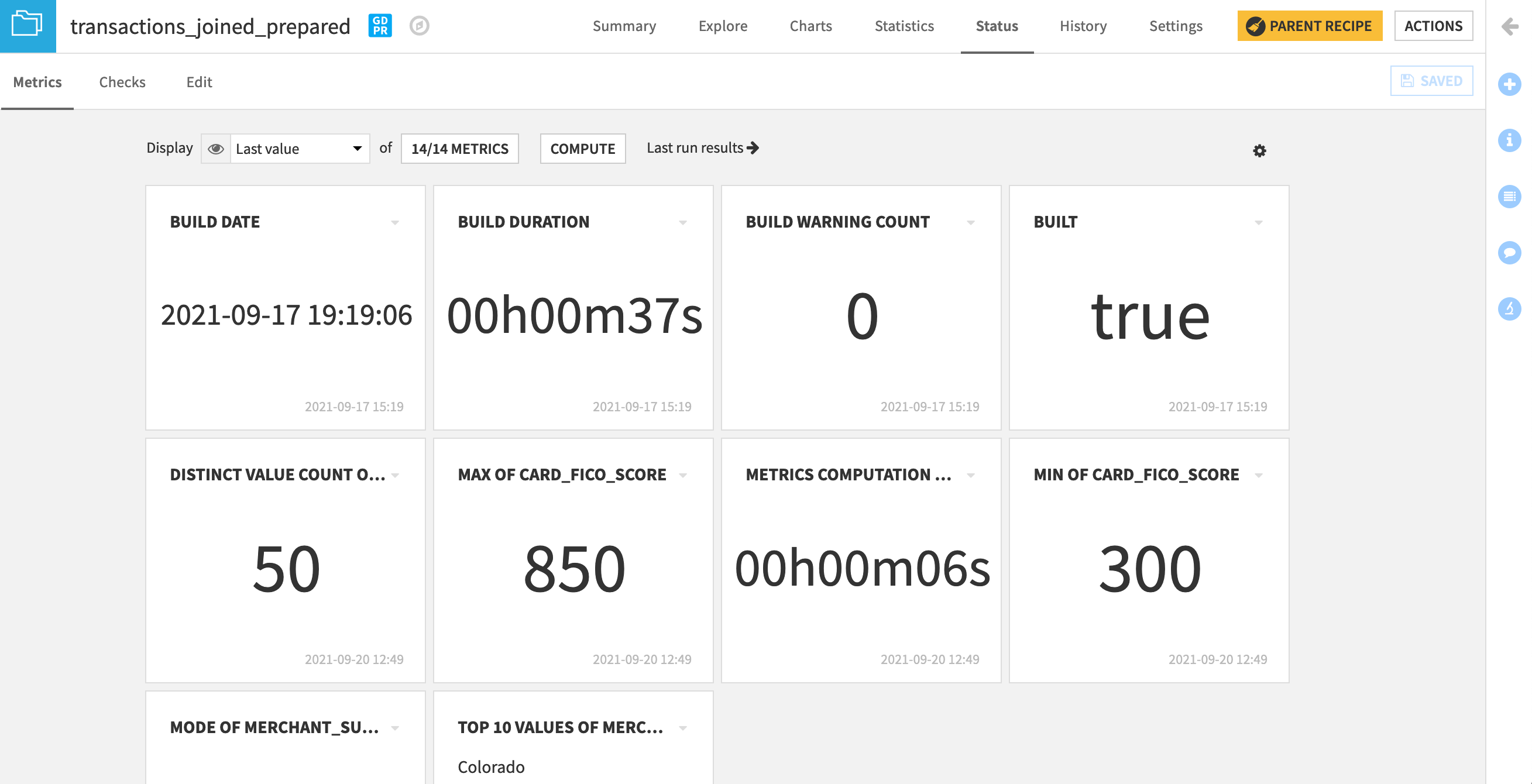
Clicking on the value of a metric will bring up a modal box with the history of this value.
We can also switch to other views of the metrics, such as the History view, which is a “ribbon” view displaying the history of all selected metrics.
For partitioned datasets, we will have more views to visualize metrics on a per-partition basis.
Since there can be a lot of available metrics on an item, we must select the metrics we want to add to the displayed screen tiles on the Metrics page.
Adding Metrics¶
Within the Status tab of a dataset, there is an “Edit” subtab. From here, the list of available metrics can be customized and extended using:
built-in probes
custom code, or
plugins.
For now, we will focus on built-in probes. We will explore building probes with custom code or via plugins in another lesson.
A probe is a component that can compute several metrics on an item. Each probe has a configuration that indicates what should be computed for this probe.
For instance, the Column statistics probe can compute the minimum and maximum value of a column, such as purchase_amount.
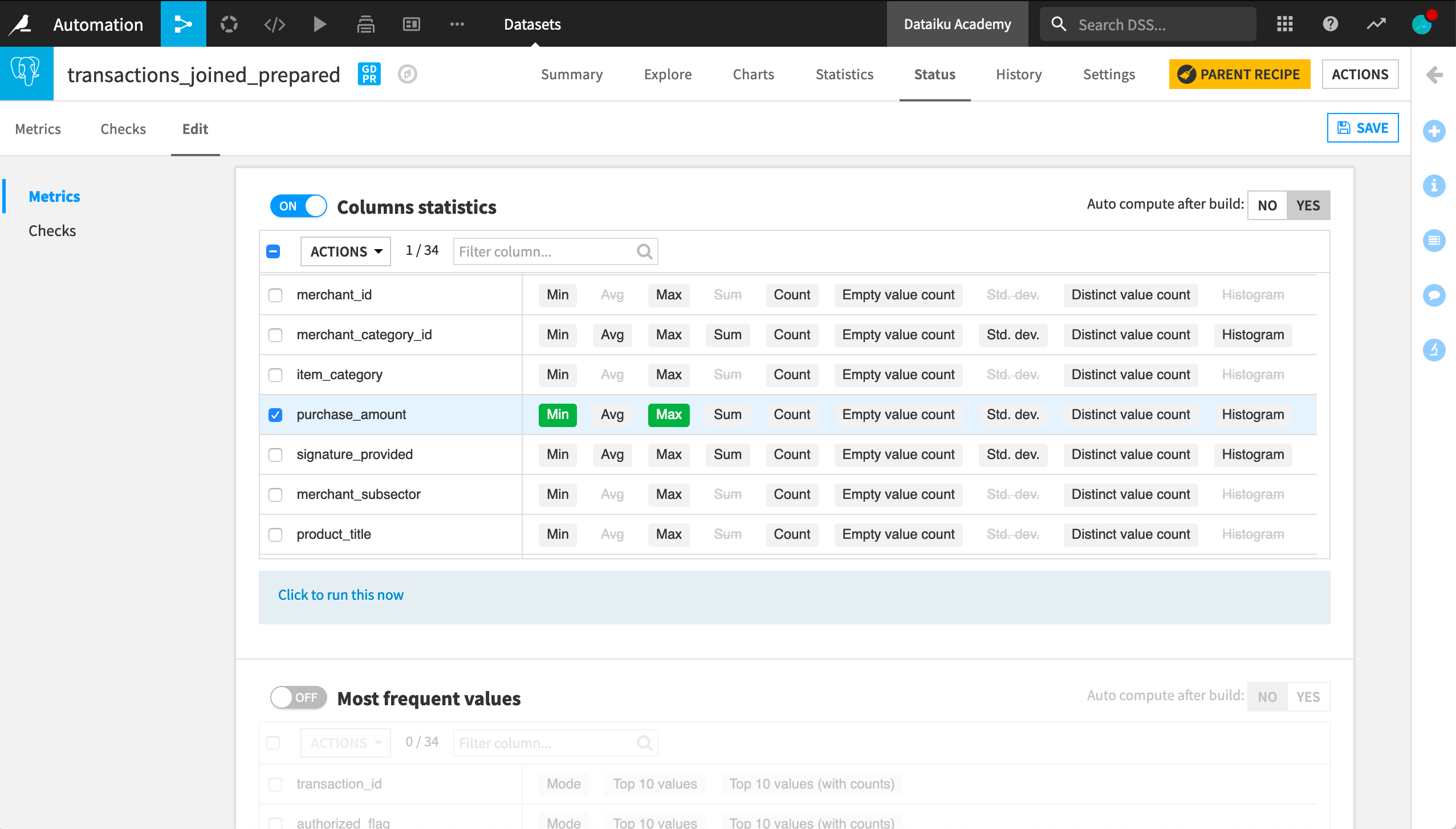
In addition to column statistics, you can also find probes to compute the most frequent values of a specific column, the percentiles of a specific column, or statistics about data validity.
Data validity metrics are to be used in association with user-defined meanings which complement the description of the column and optionally provide a list or a pattern for the valid values.
You can also use a cell value probe to retrieve the values of one or more cells from the dataset as metrics, with historization. This allows you to filter the rows on specific conditions and display dataset values for selected columns.
More customized metrics can be defined using Python code or via a plugin. The use of these custom metrics will be detailed in a later lesson on custom metric, checks, and scenarios.
The engine computation settings used to compute the metrics can also be edited.
Adding Checks¶
Now that we have defined our metric, we can set checks to validate that our latest computed value does not raise any concerns.
The Checks page is similar to the Metrics page. We can choose between different views of the checks status, and select which checks we want to display.
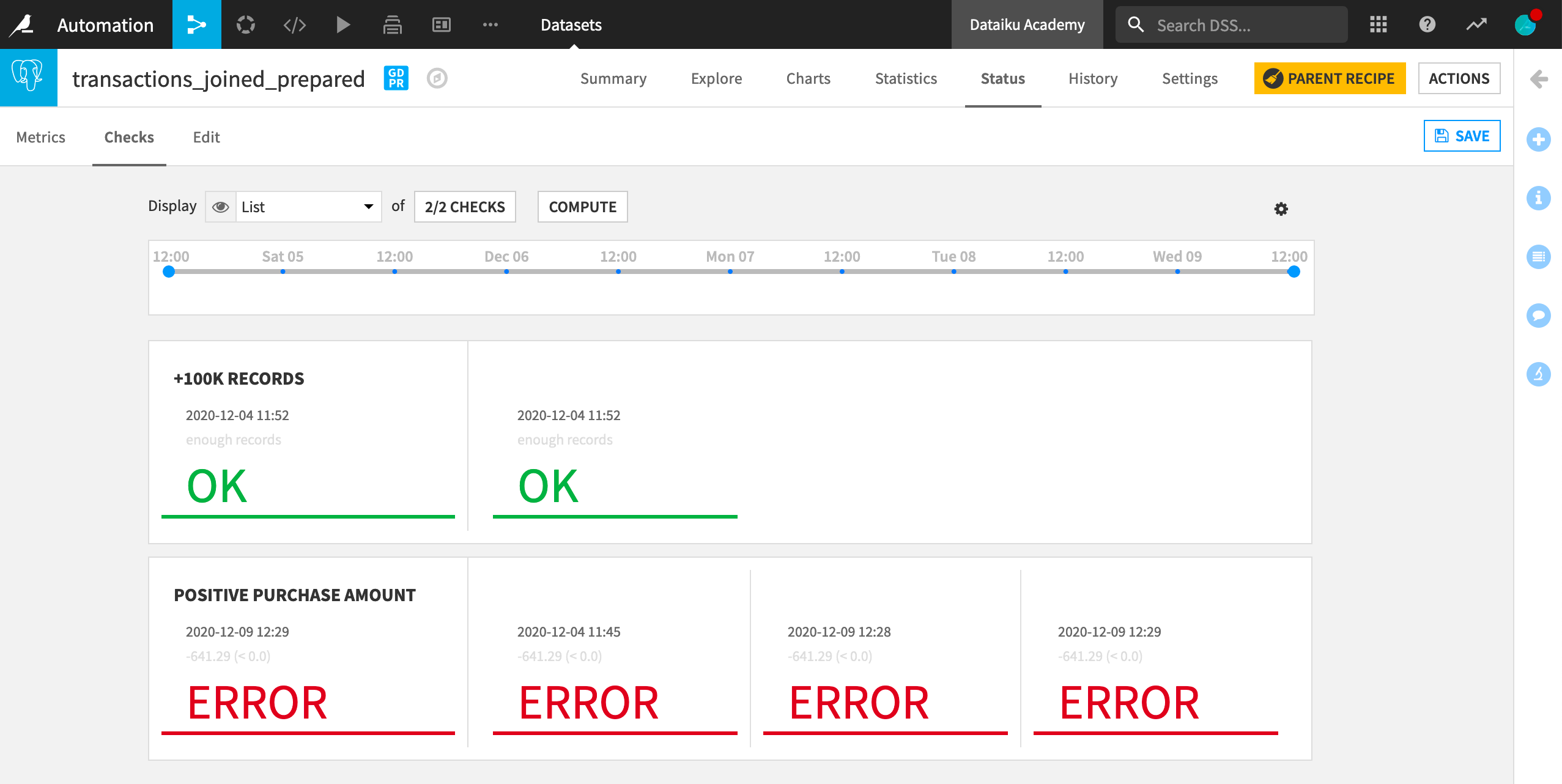
Similar to metrics, checks can be built from the Edit tab, from built-in visual probes, custom code, or plugins.
In our case, we want to check that the minimum value of purchase_amount is positive, as this was our initial assumption. We do this with a numerical range check on the metric “Min of purchase_amount”.
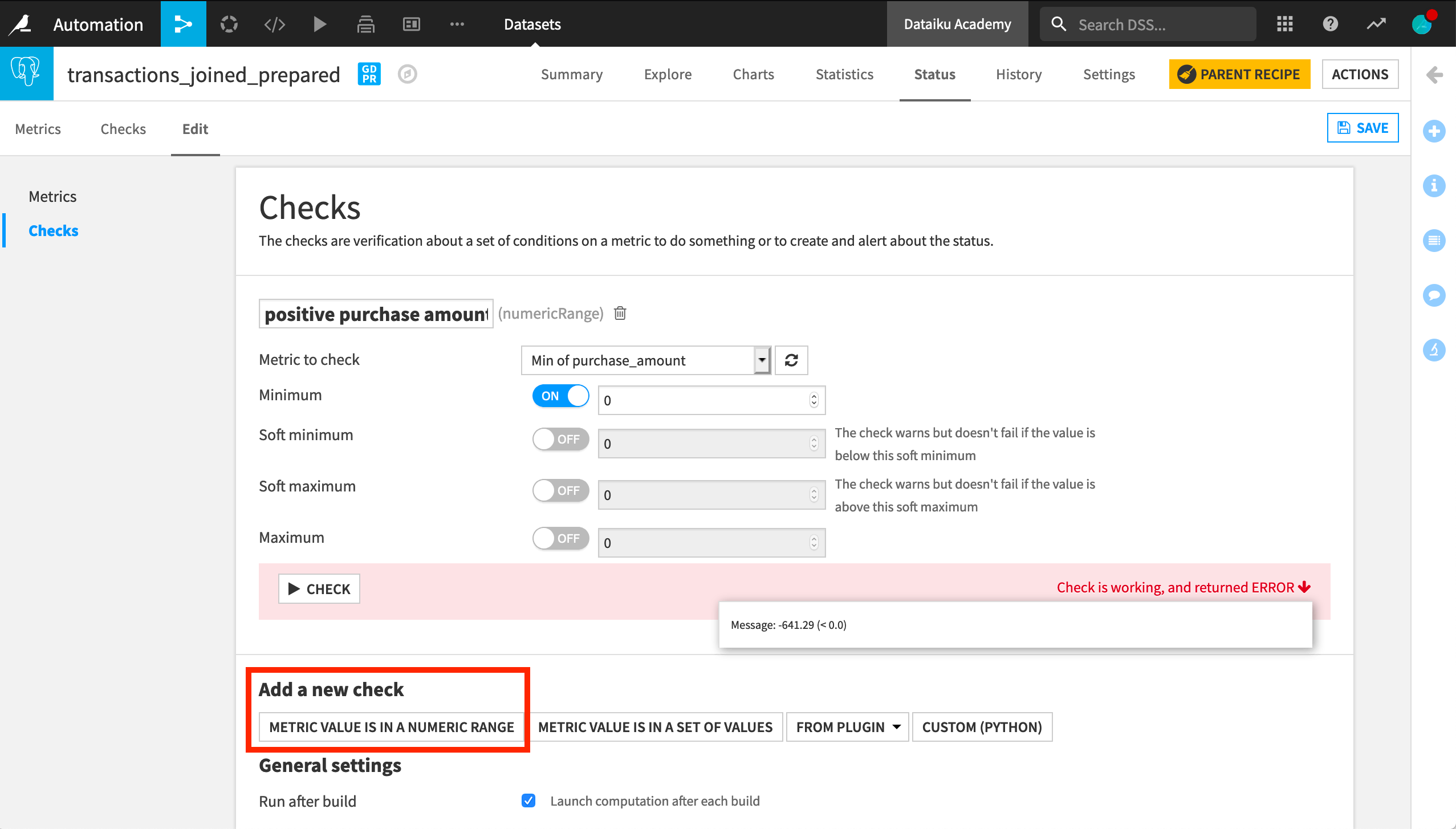
We can set a soft minimum to return a warning if not respected or a hard minimum to trigger an error.
As for a metric, we can set the option to automatically run the check after each rebuild, if desired.
We can now save our settings and test the check. We can see that it’s working, but it returns an error. We had incorrectly assumed that the purchase_amount value is always positive, while in fact the minimum of purchase_amount is negative.
This could mean that we have unconsciously ingested invalid data, or, in our case, simply that we have made an incorrect assumption about the nature of the data. Either way, the failed check brings attention to a potential inconsistency in our data.
Metrics & Checks on Other Objects¶
Although not covered in this lesson, metrics and checks can also be used on managed folders and saved models. The nature of metrics and checks in those use cases will differ from the one we’ve seen with datasets. However, the rationale remains similar.

Learn More¶
To learn more about metrics and checks, including through hands-on exercises, please register for the free Academy course on this subject found in the Advanced Designer learning path.
You can also learn more about metrics and checks in the product documentation.