Build Datasets¶
The Flow is the visual representation of a data pipeline, showing datasets and their transformations (through what we call Recipes). Thanks to the Flow, Dataiku is aware of the dependencies each dataset has and can optimally rebuild datasets whenever one of the parent datasets or recipes has been modified. Note that the dependency of the data can be set using a finer granularity than the dataset using partitions to minimize computation time.
Building a single dataset¶
Click on the build icon in the Actions menu. A modal appears to set the build options:
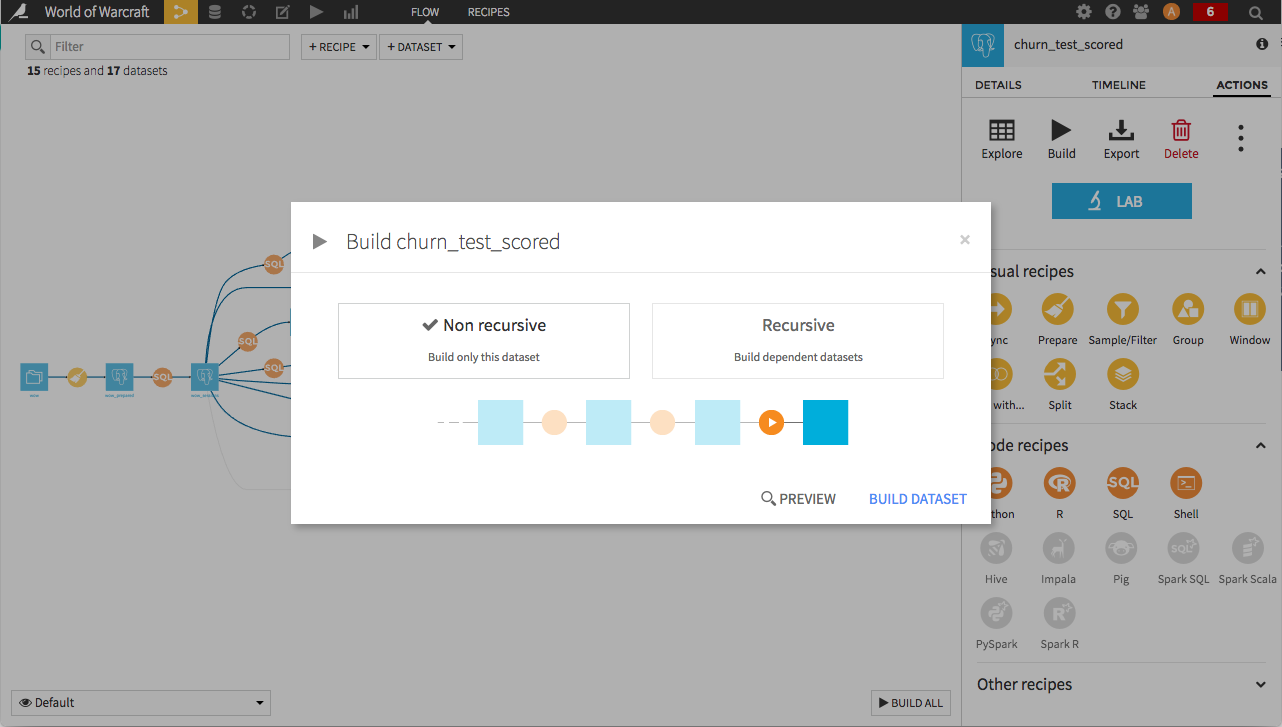
The first option will run the recipe outputting the dataset. This is used when one wants to recompute only the current dataset for example after modifying the recipe or the dataset schema. It does not take into account any changes upstream of the dataset.
The second option “Recursive” will recompute whatever is necessary upstream, depending on what has changed recently. Three sub-options are available :
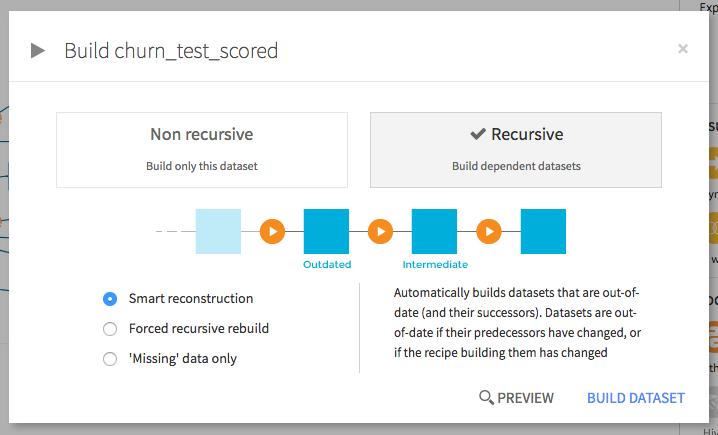
Smart reconstruction is aware of changes made upstream and first rebuilds any dataset that requires an update due to changes in the Flow. These changes could be the edition of a recipe or the addition of new data into one of the data sets. Then, it rebuilds the selected dataset.
Force recursive rebuild rebuilds all of the dependencies of the selected datasets going back to the start of the flow.
Missing data only builds any missing dependent datasets. This option does not rebuild dependencies affected by changes in the Flow. Instead, it only rebuilds the datasets that are completely missing. This option is useful if you have flushed some intermediary dataset upstream and you want to recompute datasets downstream.
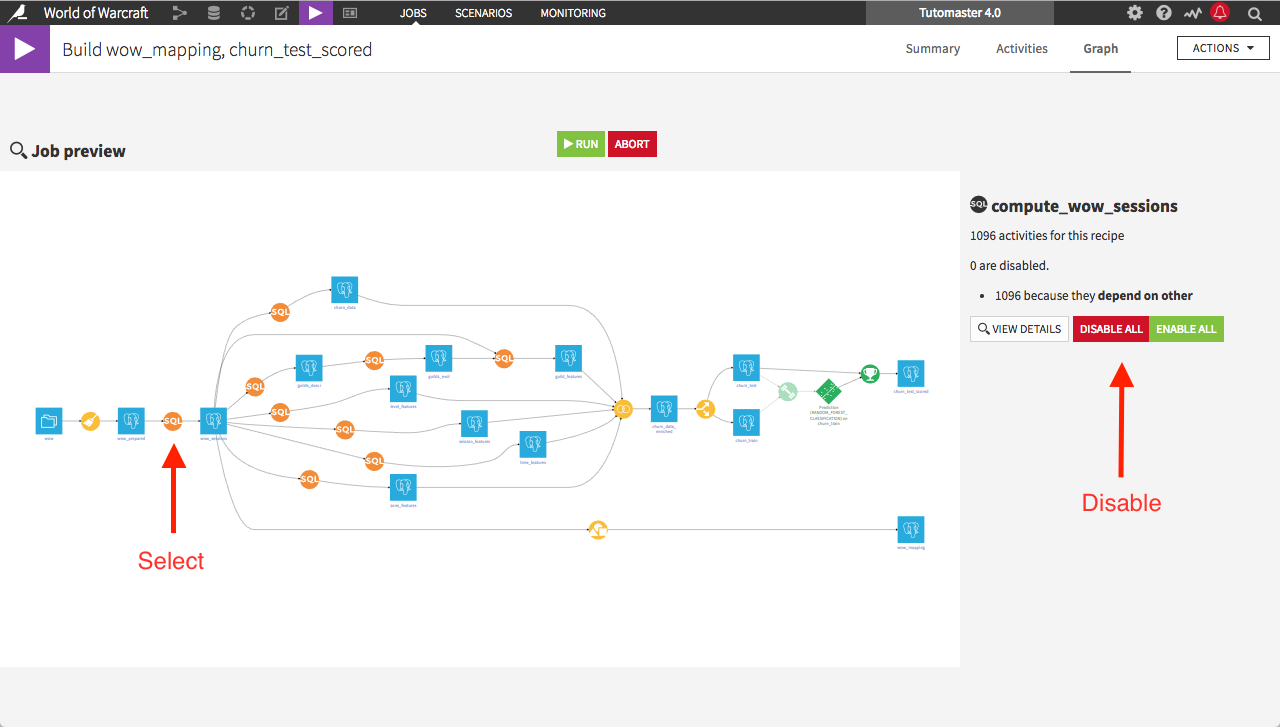
When one wants to pick more precisely which upstream datasets to build or not, she can set an option above and click on the Preview button.

The dependencies graph will then be analyzed to compute the precise activities required. The user will then be able disable the unnecessary processes one by one either in the list of activities or in the graph view.
Build the final datasets¶
When one wants to build all the datasets of a project, she can click on the build all button at the bottom right of the flow or right-click on a dataset in the flow and select the option rebuild from here in the menu Tools.
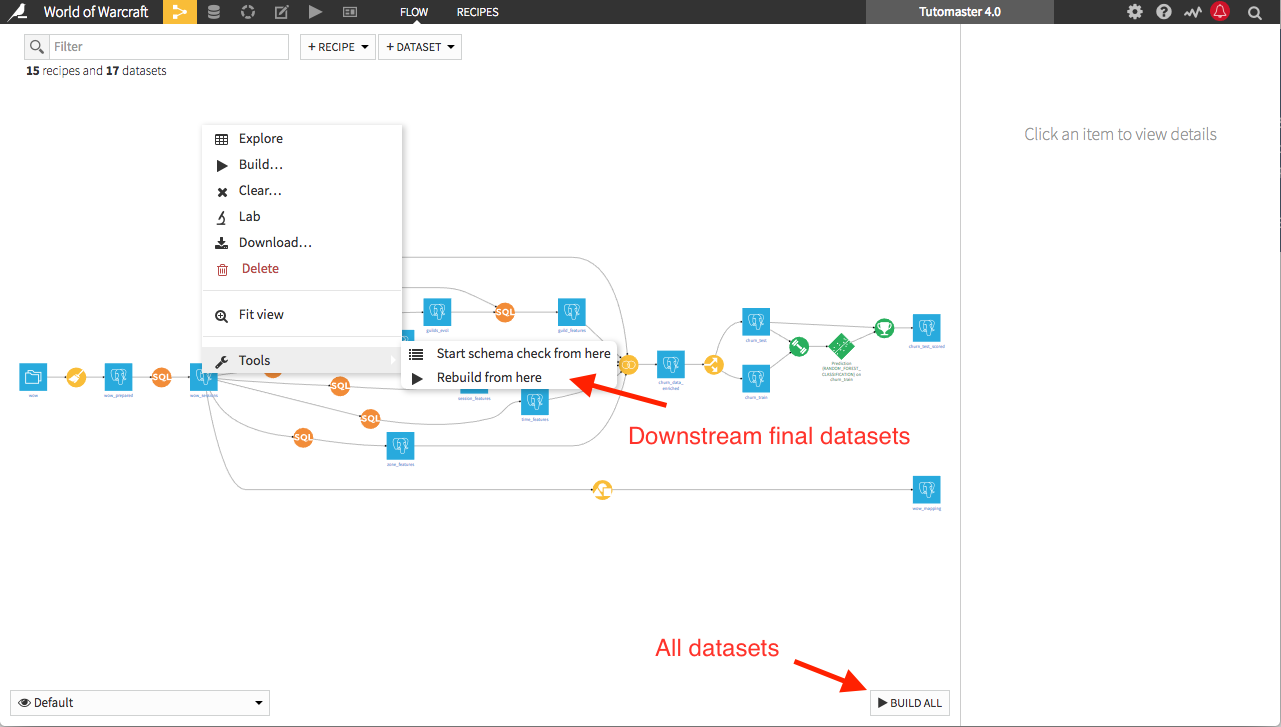
Note: Using the rebuild from here tool, the datasets required to built those final datasets may include datasets upstream of the original one.
Automating the rebuild¶
Note that you can schedule or automate reconstruction using complex triggers thanks to our scenario system. Please refer to the Automation course for more details.